Le web, c’est un vrai terrain de chasse aux données, et toutes les boîtes veulent en profiter à fond. Mais soyons francs : recopier à la main des infos sur des centaines de pages web, c’est aussi palpitant que regarder l’herbe pousser (et franchement, niveau productivité, on repassera). C’est là que l’extraction web avec Node change la donne. Depuis quelques années, j’ai vu de plus en plus d’équipes – que ce soit en vente, en opérations ou en études de marché – se tourner vers l’automatisation pour collecter des infos précieuses à grande échelle. D’ailleurs, le marché mondial de l’extraction web devrait dépasser les , et ce ne sont pas que les géants de la tech qui en profitent. De la veille tarifaire à la génération de leads, l’extraction web avec Node devient vite une compétence indispensable pour rester dans la course.
Tu te demandes comment extraire des données de sites web avec Node.js – ou pourquoi Node.js cartonne pour collecter des infos sur des sites dynamiques bourrés de JavaScript ? Ce guide est fait pour toi. Je vais t’expliquer ce qu’est l’extraction web avec Node, pourquoi c’est devenu un must pour les pros, et comment monter ton propre workflow d’extraction de A à Z. Et si tu es plutôt du genre « je veux du résultat tout de suite », je te montrerai aussi comment des outils comme peuvent t’économiser un temps fou en automatisant tout le process. Prêt à transformer le web en mine d’or de données ? On y va !
C’est quoi l’extraction web avec Node ? Le sésame de l’automatisation des données
En bref, l’extraction web avec Node, c’est utiliser Node.js (le fameux environnement JavaScript côté serveur) pour aller chercher automatiquement des infos sur des sites web. Imagine un robot super-rapide qui visite des pages, lit leur contenu et te ramène pile les données qu’il te faut – que ce soit des prix, des contacts ou les derniers titres d’actu.
Comment ça marche ?
- Ton script Node.js envoie une requête HTTP à un site (comme ton navigateur).
- Il récupère le code HTML brut de la page.
- Avec des bibliothèques comme Cheerio, il analyse le HTML et te permet de « viser » les données que tu veux (un peu comme avec jQuery).
- Pour les sites où le contenu est généré par JavaScript (les applis web modernes et interactives), tu peux utiliser Puppeteer pour piloter un vrai navigateur en arrière-plan, afficher la page et extraire les données une fois tous les scripts chargés.
Pourquoi Node.js ? Parce que JavaScript, c’est la langue du web, et Node.js te permet de l’utiliser hors du navigateur. Tu peux donc gérer aussi bien des sites statiques que dynamiques, automatiser des interactions complexes (connexion, clics, etc.) et traiter les données à la vitesse de l’éclair. En plus, l’architecture asynchrone et non bloquante de Node facilite l’extraction de plein de pages en même temps – parfait pour passer à la vitesse supérieure.
Les outils incontournables pour l’extraction web avec Node :
- Axios : Pour récupérer les pages web (requêtes HTTP).
- Cheerio : Pour analyser et interroger le HTML des sites statiques.
- Puppeteer : Pour automatiser un navigateur réel sur les sites interactifs ou blindés de JavaScript.
Si tu imagines une armée de navigateurs robots qui bossent pendant que tu bois ton café… tu n’es pas loin de la vérité.
Pourquoi l’extraction web avec Node, c’est un vrai atout pour les équipes métier ?
Soyons clairs : l’extraction web, ce n’est plus réservé aux hackers ou aux data scientists. C’est devenu un vrai super-pouvoir pour les entreprises. Tous secteurs confondus, les boîtes utilisent Node pour :
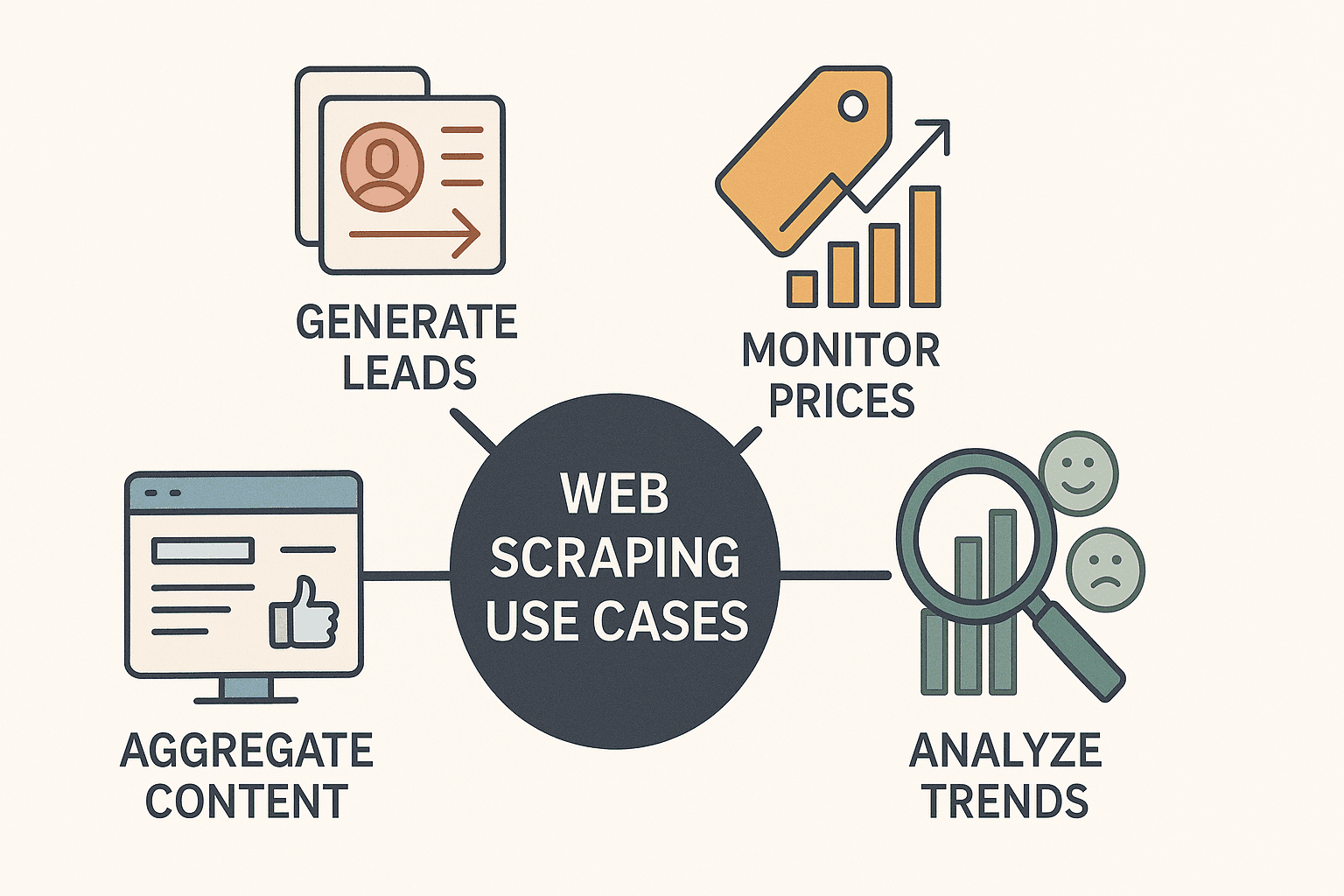
- Générer des leads : Extraire des contacts depuis des annuaires ou LinkedIn pour la prospection.
- Surveiller les prix des concurrents : Suivre les offres produits et ajuster ses tarifs en temps réel (plus de surveillent les prix de la concurrence chaque jour).
- Agrégation de contenu : Créer des dashboards d’actualités, d’avis ou de mentions sur les réseaux sociaux.
- Analyser les tendances du marché : Collecter des avis, forums ou offres d’emploi pour flairer les opportunités.
Le top ? Node.js rend tout ça plus rapide, flexible et facile à automatiser que jamais. Grâce à son fonctionnement asynchrone, tu peux traiter des dizaines (voire des centaines) de pages en même temps, et sa compatibilité JavaScript en fait l’outil parfait pour les sites modernes.
Voici quelques exemples concrets :
| Cas d’usage | Description & Exemple | Avantage Node.js |
|---|---|---|
| Génération de leads | Extraire des emails, noms et numéros depuis des annuaires professionnels. | Extraction rapide et parallèle ; intégration facile avec les CRM et API. |
| Veille tarifaire | Suivre les prix des concurrents sur les sites e-commerce. | Requêtes asynchrones pour de gros volumes ; planification simple pour des vérifications régulières. |
| Analyse de tendances | Agréger des avis, forums ou posts sociaux pour l’analyse de sentiment. | Gestion polyvalente des données ; écosystème riche pour le traitement de texte. |
| Agrégation de contenu | Centraliser des articles ou billets de blog dans un tableau de bord unique. | Mises à jour en temps réel ; intégration fluide avec Slack, email, etc. |
| Analyse concurrentielle | Extraire catalogues produits, descriptions et notes utilisateurs des sites rivaux. | Analyse JavaScript pour sites complexes ; code modulaire pour crawler plusieurs pages. |
Node.js est particulièrement efficace pour extraire des sites très dynamiques, là où Python et d’autres langages peuvent galérer. Avec la bonne config, tu passes de « j’aimerais avoir ces données » à « voici mon tableau Excel » en quelques minutes.
Les essentiels de l’extraction web avec Node : outils et bibliothèques
Avant de plonger dans le code, petit tour d’horizon des outils clés pour l’extraction web avec Node.js :
1. Axios (Client HTTP)

- À quoi ça sert : Récupérer des pages web via des requêtes HTTP.
- Quand l’utiliser : Dès que tu veux choper le HTML brut d’une page.
- Ses atouts : API simple basée sur les promesses ; gère facilement les redirections et les en-têtes.
- Installation :
npm install axios
2. Cheerio (Analyseur HTML)

- À quoi ça sert : Analyser le HTML et utiliser des sélecteurs façon jQuery pour trouver les données.
- Quand l’utiliser : Pour les sites statiques où les données sont dans le HTML de base.
- Ses atouts : Rapide, léger, et très familier si tu connais jQuery.
- Installation :
npm install cheerio
3. Puppeteer (Automatisation de navigateur headless)

- À quoi ça sert : Piloter un vrai navigateur Chrome en arrière-plan, interagir avec les pages comme un utilisateur.
- Quand l’utiliser : Pour les sites blindés de JavaScript ou interactifs (scroll infini, connexion, pop-ups).
- Ses atouts : Peut cliquer, remplir des formulaires, scroller et extraire les données après exécution des scripts.
- Installation :
npm install puppeteer
Bonus : Il existe aussi Playwright (multi-navigateurs) ou Crawlee d’Apify pour des workflows plus costauds, mais Axios, Cheerio et Puppeteer, c’est le trio gagnant pour commencer.
Pré-requis : Assure-toi d’avoir Node.js installé. Lance un nouveau projet avec npm init -y, puis installe les bibliothèques ci-dessus.
Pas à pas : crée ton premier extracteur web Node de zéro
On passe à la pratique ! On va créer un extracteur simple avec Axios et Cheerio pour récupérer des infos de livres sur le site de démo .
Étape 1 : Récupérer le HTML de la page
1import axios from 'axios';
2import { load } from 'cheerio';
3const startUrl = 'http://books.toscrape.com/';
4async function scrapePage(url) {
5 const resp = await axios.get(url);
6 const html = resp.data;
7 const $ = load(html);
8 // ...extraction des données ensuite
9}Étape 2 : Analyser et extraire les données
1$('.product_pod').each((i, element) => {
2 const title = $(element).find('h3').text().trim();
3 const price = $(element).find('.price_color').text().replace('£', '');
4 const stock = $(element).find('.instock').text().trim();
5 const ratingClass = $(element).find('p.star-rating').attr('class') || '';
6 const rating = ratingClass.split(' ')[1];
7 const relativeUrl = $(element).find('h3 a').attr('href');
8 const bookUrl = new URL(relativeUrl, startUrl).href;
9 console.log({ title, price, rating, stock, url: bookUrl });
10});Étape 3 : Gérer la pagination
1const nextHref = $('.next > a').attr('href');
2if (nextHref) {
3 const nextUrl = new URL(nextHref, url).href;
4 await scrapePage(nextUrl);
5}Étape 4 : Sauvegarder les données
Une fois les données collectées, tu peux les enregistrer dans un fichier JSON ou CSV avec le module fs de Node.
1import fs from 'fs';
2// Après l’extraction :
3fs.writeFileSync('books_output.json', JSON.stringify(booksList, null, 2));
4console.log(`Scraping terminé : ${booksList.length} livres extraits.`);Et voilà, tu as un extracteur web Node.js qui tourne ! Cette méthode est parfaite pour les sites statiques, mais comment faire avec les pages dynamiques ?
Gérer les pages dynamiques : utiliser Puppeteer avec Node
Certains sites cachent leurs données derrière du JavaScript. Si tu essaies de les extraire avec Axios et Cheerio, tu risques de tomber sur une page vide. C’est là que Puppeteer entre en scène.
Pourquoi utiliser Puppeteer ? Il lance un vrai navigateur (en mode headless), charge la page, attend que les scripts s’exécutent, puis te permet de récupérer le contenu affiché – comme si tu étais devant ton écran.
Exemple de script Puppeteer
1import puppeteer from 'puppeteer';
2async function scrapeWithPuppeteer(url) {
3 const browser = await puppeteer.launch({ headless: true });
4 const page = await browser.newPage();
5 await page.goto(url, { waitUntil: 'networkidle2' });
6 await page.waitForSelector('.product_pod'); // Attendre le chargement des données
7 const data = await page.evaluate(() => {
8 let items = [];
9 document.querySelectorAll('.product_pod').forEach(elem => {
10 items.push({
11 title: elem.querySelector('h3').innerText,
12 price: elem.querySelector('.price_color').innerText,
13 });
14 });
15 return items;
16 });
17 console.log(data);
18 await browser.close();
19}Quand utiliser Cheerio/Axios ou Puppeteer ?
- Cheerio/Axios : Rapide, léger, parfait pour le contenu statique.
- Puppeteer : Plus lent, mais indispensable pour les pages dynamiques ou interactives (connexion, scroll infini, etc.).
Astuce : commence toujours par Cheerio/Axios pour la rapidité. Si tu vois qu’il manque des données, passe à Puppeteer.
Aller plus loin : pagination, connexion et nettoyage des données
Une fois les bases en main, tu peux attaquer des scénarios plus avancés.
Gérer la pagination
Parcours les pages en détectant et suivant les liens « suivant », ou en générant les URLs si elles suivent un schéma.
1let pageNum = 1;
2while (true) {
3 const resp = await axios.get(`https://example.com/products?page=${pageNum}`);
4 // ...extraction des données
5 if (!hasNextPage) break;
6 pageNum++;
7}Automatiser la connexion
Avec Puppeteer, tu peux remplir les formulaires de connexion comme un vrai utilisateur :
1await page.type('#username', 'monUtilisateur');
2await page.type('#password', 'monMotDePasse');
3await page.click('#loginButton');
4await page.waitForNavigation();Nettoyer les données
Après extraction, nettoie tes données en :
- Supprimant les doublons (Set ou filtre sur une clé unique).
- Formatant les nombres, dates et textes.
- Gérant les valeurs manquantes (remplir par null ou ignorer les enregistrements incomplets).
Les regex et les méthodes de chaîne JavaScript sont tes meilleures amies ici.
Bonnes pratiques : éviter les pièges et rester efficace
L’extraction web, c’est puissant, mais ça vient avec ses défis. Voici comment éviter les galères classiques :
- Respecte le robots.txt et les conditions d’utilisation : Vérifie toujours si le site autorise l’extraction et évite les zones interdites.
- Modère tes requêtes : N’inonde pas un site de centaines de requêtes par seconde. Ajoute des délais et varie-les pour simuler un comportement humain ().
- Fais tourner les user agents et IP : Utilise des en-têtes réalistes et, pour de gros volumes, change d’adresse IP pour éviter les blocages.
- Gère les erreurs proprement : Attrape les exceptions, relance les requêtes échouées et loggue les erreurs pour le débogage.
- Valide tes données : Vérifie les champs manquants ou mal formés pour repérer vite les changements de structure du site.
- Écris un code modulaire et maintenable : Sépare la récupération, l’analyse et la sauvegarde. Utilise des fichiers de config pour les sélecteurs et URLs.
Et surtout : reste éthique. Le web est une ressource partagée, personne n’aime les robots malpolis.
Thunderbit ou extraction Node sur-mesure : coder ou utiliser un outil ?
La grande question : tu codes ton propre extracteur ou tu utilises un outil comme ?
Extracteur Node.js sur-mesure :
- Avantages : Contrôle total, personnalisation à fond, intégration dans n’importe quel workflow.
- Inconvénients : Faut savoir coder, ça prend du temps à mettre en place, et il faut tout maintenir à chaque changement de site.
Thunderbit Extracteur Web IA :
- Avantages : Aucun code à écrire, détection intelligente des champs, gère les sous-pages et la pagination, export instantané vers Excel, Google Sheets, Notion, etc. (). Zéro maintenance – l’IA s’adapte toute seule aux changements de site.
- Inconvénients : Moins de flexibilité pour des workflows ultra-spécifiques (mais ça couvre 99% des besoins métier).
Petit comparatif :
| Aspect | Extracteur Node.js sur-mesure | Thunderbit Extracteur Web IA |
|---|---|---|
| Compétences requises | Savoir coder | Aucun code, simple clic |
| Temps de mise en place | De quelques heures à jours | Quelques minutes (suggestions IA) |
| Maintenance | Continue (changements site) | Minime (IA s’adapte automatiquement) |
| Contenu dynamique | Configuration manuelle | Prise en charge native |
| Pagination/sous-pages | Codage manuel | 1 clic pour gérer pagination |
| Export des données | Code manuel | 1 clic vers Excel, Sheets, Notion |
| Coût | Gratuit (temps dev, proxies) | Gratuit de base, crédits à l’usage |
| Idéal pour | Développeurs, logique sur-mesure | Utilisateurs métier, résultats rapides |
Thunderbit, c’est l’allié parfait pour les équipes commerciales, marketing ou opérations qui ont besoin de données tout de suite – pas dans une semaine. Et pour les devs, c’est top pour prototyper ou automatiser les tâches répétitives sans tout recoder.
Conclusion & points clés : lance-toi dans l’extraction web avec Node
L’extraction web avec Node, c’est la clé pour accéder aux données cachées du web – que ce soit pour faire des listes de prospects, surveiller les prix ou booster ton prochain projet innovant. À retenir :
- Node.js + Cheerio/Axios est parfait pour les sites statiques ; Puppeteer est indispensable pour les pages dynamiques et blindées de JavaScript.
- L’impact business est réel : Les boîtes qui misent sur l’extraction web pour piloter leurs décisions voient des résultats concrets, comme ou un doublement des ventes à l’international.
- Commence simple : Monte un extracteur de base, puis ajoute la pagination, l’automatisation de la connexion et le nettoyage des données au fur et à mesure.
- Choisis le bon outil : Pour une extraction rapide et sans code, est imbattable. Pour des workflows sur-mesure, les scripts Node.js te donnent un contrôle total.
- Sois responsable : Respecte les règles des sites, limite la fréquence de tes robots et garde un code propre et maintenable.
Prêt à te lancer ? Essaie de créer ton propre extracteur Node.js, ou pour voir à quel point l’extraction de données web peut être simple. Pour plus d’astuces, va faire un tour sur le pour des tutos détaillés et les dernières nouveautés sur l’extraction web boostée à l’IA.
Bonne extraction – que tes données soient toujours fraîches, bien rangées et en avance sur la concurrence !
FAQ
1. C’est quoi l’extraction web avec Node et pourquoi choisir Node.js ?
L’extraction web avec Node, c’est utiliser Node.js pour automatiser la collecte de données sur les sites web. Node.js est super efficace car il gère les requêtes asynchrones et brille sur les sites blindés de JavaScript grâce à des outils comme Puppeteer.
2. Quand utiliser Cheerio/Axios ou Puppeteer pour l’extraction ?
Utilise Cheerio et Axios pour les sites statiques où les données sont dans le HTML de base. Passe à Puppeteer si tu dois extraire du contenu généré par JavaScript, interagir avec la page (connexion, scroll infini, etc.).
3. Quels sont les principaux cas d’usage métier de l’extraction web avec Node ?
Les usages les plus courants : génération de leads, veille tarifaire, agrégation de contenu, analyse de tendances et extraction de catalogues produits. Node.js rend tout ça rapide et scalable.
4. Quels sont les principaux pièges de l’extraction web avec Node, et comment les éviter ?
Les pièges classiques : blocage par les anti-bots, changements de structure de site et gestion de la qualité des données. Pour les éviter : limite la fréquence des requêtes, fais tourner les user agents/IP, valide tes données et écris un code modulaire.
5. Comment Thunderbit se compare à un extracteur Node.js fait maison ?
Thunderbit propose une solution sans code, boostée par l’IA, qui détecte automatiquement les champs, sous-pages et la pagination. Parfait pour les utilisateurs métier qui veulent des résultats rapides, tandis que l’extraction Node.js sur-mesure est idéale pour les devs qui veulent personnaliser ou intégrer à fond.
Pour plus de guides et d’inspiration, pense à visiter le et à t’abonner à notre pour des tutos pratiques.
En savoir plus