Le rythme de l’actualité numérique aujourd’hui donne presque le vertige. Chaque minute, des milliers de titres sont publiés, mis à jour ou modifiés discrètement — dans les grands médias, les blogs de niche et les fils sociaux.
Pour donner un ordre de grandeur, ingère plus de 4 millions d’articles de presse chaque jour, tandis que le suit l’actualité dans plus de 100 langues et met à jour son flux mondial toutes les 15 minutes.
Pour toute personne travaillant dans les médias, la recherche ou la veille stratégique, essayer de suivre ce torrent à la main, c’est un peu comme écoper un navire en train de couler avec une tasse à café.
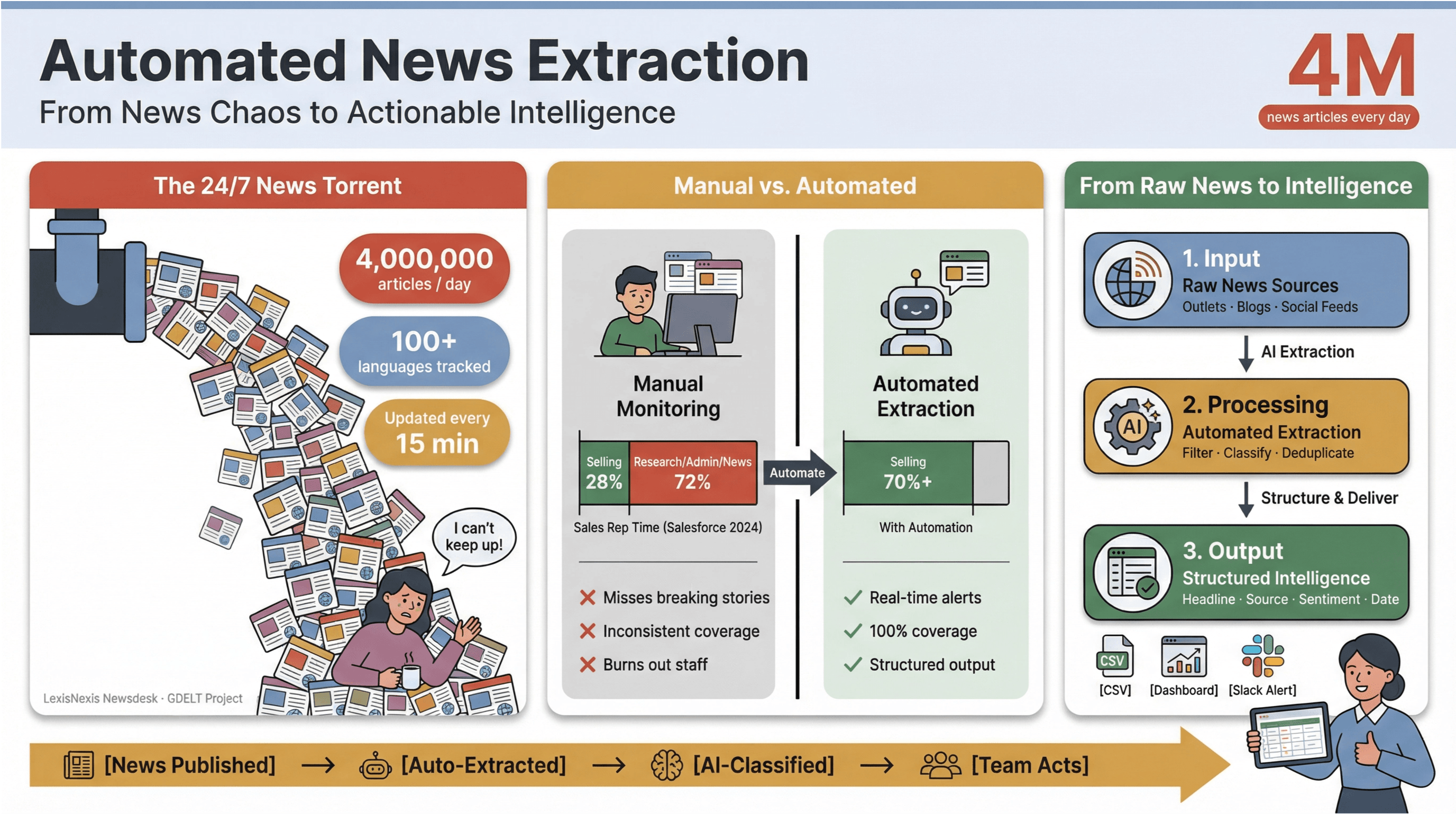
J’ai pu constater de première main à quel point la veille manuelle de l’actualité consomme du temps et des ressources. Les équipes commerciales passent moins d’un tiers de leur semaine à vraiment vendre — — le reste étant absorbé par la recherche, l’administratif et, oui, le jonglage sans fin entre les onglets d’actualité.
C’est pourquoi l’extraction automatisée d’actualités est devenue l’arme secrète des équipes modernes : c’est le seul moyen de transformer le chaos du cycle de l’information 24 h/24 en intelligence structurée et exploitable — sans épuiser vos équipes ni manquer les informations les plus importantes.
Voyons ce que signifie réellement l’extraction automatisée d’actualités, pourquoi elle est indispensable pour toute personne qui se soucie de données d’actualité en temps réel, et comment mettre en place un workflow robuste et conforme grâce aux meilleurs outils — notamment comment rend l’ensemble du processus incroyablement simple, même pour les non-techniciens comme ma mère.
Extraction automatisée d’actualités : pourquoi elle est essentielle pour les rédactions modernes
L’extraction automatisée d’actualités, c’est exactement ce que son nom laisse entendre : utiliser un logiciel pour collecter automatiquement du contenu d’actualité et le transformer en données structurées et consultables — pensez lignes et colonnes plutôt que pages web en désordre ou PDF. En pratique, cela vous permet de surveiller des centaines, voire des milliers de sources, d’extraire des champs clés comme le titre, l’horodatage, l’auteur et le texte de l’article, puis d’alimenter des tableaux de bord, des alertes ou des analyses en aval — sans jamais toucher à Ctrl+C/Ctrl+V.
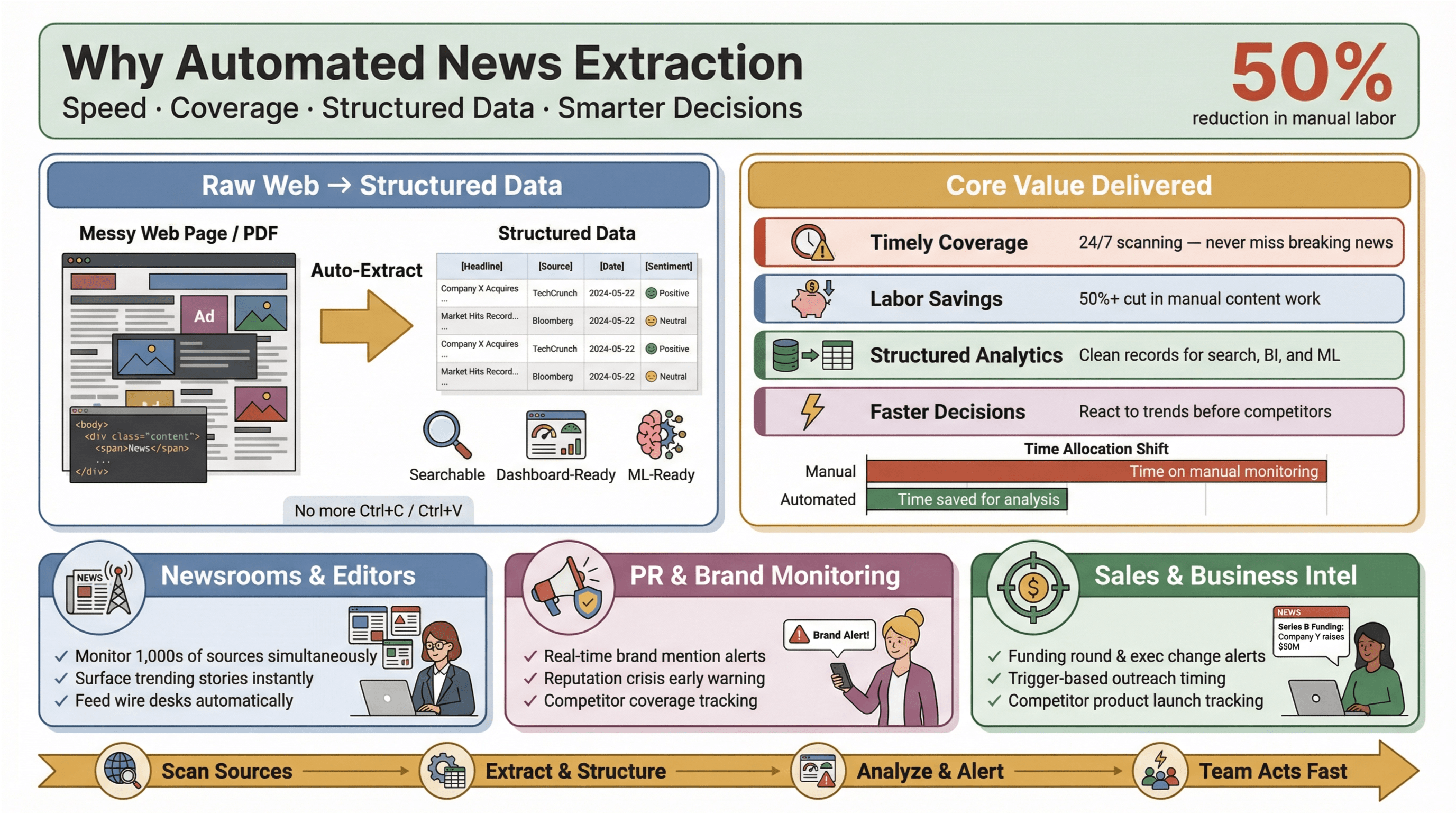 Pourquoi est-ce important ? Parce que, dans le paysage médiatique actuel, la vitesse est primordiale. Que vous soyez rédacteur en chef, responsable RP à l’affût des mentions de marque ou analyste business suivant les mouvements des concurrents, être le premier informé peut faire toute la différence entre saisir une opportunité et courir derrière les autres. Les outils d’extraction automatisée permettent même aux petites équipes de jouer dans la cour des grands — en collectant des données d’actualité en temps réel sur le web, en réduisant la charge manuelle et en faisant ressortir les informations qui comptent vraiment.
Pourquoi est-ce important ? Parce que, dans le paysage médiatique actuel, la vitesse est primordiale. Que vous soyez rédacteur en chef, responsable RP à l’affût des mentions de marque ou analyste business suivant les mouvements des concurrents, être le premier informé peut faire toute la différence entre saisir une opportunité et courir derrière les autres. Les outils d’extraction automatisée permettent même aux petites équipes de jouer dans la cour des grands — en collectant des données d’actualité en temps réel sur le web, en réduisant la charge manuelle et en faisant ressortir les informations qui comptent vraiment.
Et l’impact est bien réel : des études montrent que l’automatisation peut réduire d’au moins 50 % le travail manuel lié aux mises à jour de contenu, libérant ainsi du temps pour l’analyse et la prise de décision.
La valeur essentielle de l’extraction automatisée d’actualités dans le secteur des médias
Soyons concrets. Que fournit réellement l’extraction automatisée d’actualités aux rédactions et aux équipes métier ?
- Couverture rapide et exhaustive : fini les informations manquées parce que quelqu’un a oublié de vérifier un flux. Les outils automatisés scrutent les sources 24 h/24, pour ne rien laisser passer.
- Économies de main-d’œuvre et de coûts : les petites et moyennes équipes peuvent surveiller autant de sources que les grands groupes — sans embaucher une armée de stagiaires.
- Données structurées pour l’analyse : au lieu de parcourir des articles non structurés, vous obtenez des enregistrements propres et structurés, prêts pour la recherche, les tableaux de bord et le machine learning.
- Décisions plus rapides et plus pertinentes : des données d’actualité en temps réel vous permettent de réagir avant vos concurrents aux évolutions du marché, aux crises RP ou aux tendances émergentes.
Prenons les relations publiques et la communication : des plateformes comme et présentent la veille médiatique en temps réel comme indispensable pour protéger la réputation et réagir rapidement à des retombées nuisibles. En vente, les alertes d’actualité en temps réel deviennent des « cartes de contexte » pour la prospection — pensez levées de fonds, changements de dirigeants ou lancements de produits qui déclenchent une prise de contact au bon moment.
Choisir les bons outils d’extraction d’actualités selon les cas d’usage
Tous les outils d’extraction d’actualités ne se valent pas. Le bon choix dépend de vos objectifs, de votre aisance technique et des types d’actualités qui vous intéressent. Voici un cadre pour vous aider à choisir la solution la plus adaptée :
Évaluer la facilité d’utilisation et l’accessibilité
Pour la plupart des utilisateurs métier et des journalistes, la facilité d’utilisation n’est pas négociable. Vous voulez un outil qui fonctionne immédiatement, sans code ni configuration compliquée. Les plateformes no-code et low-code comme , et vous permettent de créer des extracteurs visuellement — il suffit de pointer, cliquer et extraire.
Thunderbit se distingue notamment par son processus en deux étapes : décrivez ce que vous voulez, laissez l’IA suggérer les champs, puis cliquez sur « Extraire ». Même des utilisateurs non techniques peuvent mettre en place un pipeline de données d’actualité en quelques minutes, et non en quelques heures.
Considérations de sécurité et de confidentialité des données
À grande valeur de données, grande responsabilité. Les outils d’extraction d’actualités accèdent souvent à des contenus sensibles, donc la sécurité et la conformité doivent être prioritaires. Recherchez :
- Le chiffrement des données (en transit et au repos)
- Des politiques de confidentialité claires (Thunderbit, par exemple, indique ne pas vendre les données des utilisateurs et n’accéder qu’au contenu que vous choisissez d’extraire)
- Des autorisations granulaires (surtout pour les extensions de navigateur — vérifiez toujours à quelles données l’outil peut accéder)
- Le respect des lois locales (RGPD, CCPA et, pour les utilisateurs de l’UE, la )
Pour plus de tranquillité d’esprit, choisissez des fournisseurs reconnus, vérifiez les autorisations de l’extension et limitez l’accès au strict nécessaire.
Adapter les outils aux types d’actualités et aux besoins métier
Certains outils excellent dans des domaines d’actualité spécifiques :
- Finance : des API comme et offrent du clustering, de l’analyse de sentiment et la détection d’événements pour l’actualité financière.
- Tech et startups : l’extraction personnalisée avec Thunderbit ou Octoparse permet de cibler des blogs de niche, des communiqués de presse ou des listes d’événements.
- Politique et réglementation : des bases de données sous licence comme et donnent accès à des sources premium et à des archives.
Si vous devez surveiller un mélange de sources grand public, de niche et internationales — y compris celles sans API — des extracteurs flexibles pilotés par l’IA comme Thunderbit sont votre meilleur choix.
Les avantages uniques de Thunderbit pour l’extraction de données d’actualité en temps réel
Parlons maintenant de ce qui fait de un choix remarquable pour l’extraction automatisée d’actualités — surtout si vous voulez des données d’actualité en temps réel sans les tracas techniques.
Thunderbit est une extension Chrome d’extraction web propulsée par l’IA conçue pour les utilisateurs métier, les journalistes et les analystes qui ont besoin de contenu d’actualité à jour et structuré provenant de n’importe quel site web. Voici pourquoi c’est devenu mon outil de prédilection :
- AI Suggest Fields : Thunderbit lit la page d’actualité et suggère automatiquement les meilleures colonnes à extraire — titre, horodatage, auteur, résumé, etc. Pas besoin de manipuler des sélecteurs ou des modèles.
- Extraction de sous-pages : Vous avez besoin de l’article complet, pas seulement du titre ? Thunderbit peut visiter chaque lien d’actualité, extraire le texte, les entités et les balises, puis tout fusionner dans un tableau unique et structuré.
- Export en masse et mises à jour instantanées : exportez vos données d’actualité directement vers Excel, Google Sheets, Airtable ou Notion en un clic. Finies les marathons de copier-coller ou les manipulations de CSV.
- Extraction planifiée : configurez des tâches récurrentes (horaire, quotidien ou à intervalle personnalisé) pour garder votre pipeline d’actualités à jour — idéal pour l’actualité chaude, la veille de marché ou la recherche continue.
- Adaptabilité : l’IA de Thunderbit s’adapte aux changements de mise en page et aux sites d’actualité de longue traîne, ce qui vous fait passer moins de temps à réparer des extracteurs cassés et plus de temps à analyser les données.
Avec plus de et une note de 4,8 étoiles, Thunderbit est utilisé par des équipes du monde entier pour tout, de la veille RP à l’intelligence concurrentielle.
Détection de champs pilotée par l’IA et extraction de sous-pages
L’une des fonctionnalités les plus puissantes de Thunderbit est sa détection de champs pilotée par l’IA. Cliquez simplement sur « AI Suggest Fields », et l’outil analyse la page d’actualité en identifiant les champs clés comme le titre, la date, l’auteur et le résumé. Vous pouvez ajuster ou ajouter des champs personnalisés (par exemple : « étiqueter cet article comme “résultats” s’il mentionne les résultats trimestriels »), et l’IA de Thunderbit s’occupe du reste.
L’extraction de sous-pages change la donne pour l’actualité : extrayez les titres d’une page d’accueil ou d’une rubrique, puis laissez Thunderbit visiter chaque URL d’article pour récupérer le texte complet, les entités et même les images. Vous obtenez ainsi des enregistrements d’actualité complets et enrichis — prêts pour la recherche, les tableaux de bord ou l’analyse IA en aval.
Export en masse et mises à jour instantanées
Thunderbit simplifie l’export des données d’actualité. En un clic, vous pouvez envoyer votre flux d’actualité structuré vers Google Sheets, Airtable ou Notion, ou le télécharger au format CSV/Excel. Pour les équipes qui travaillent dans des tableurs ou des outils BI, c’est un gain de temps considérable.
Et comme Thunderbit prend en charge l’extraction planifiée, vous pouvez le faire tourner toutes les heures, tous les jours ou selon votre propre calendrier — pour que vos données d’actualité soient toujours à jour. Plus besoin d’attendre que Google Alerts indexe des articles plusieurs jours en retard.
Surmonter les défis opérationnels des solutions de données d’actualité en temps réel
Même avec les meilleurs outils, l’extraction d’actualités en temps réel s’accompagne de défis spécifiques. Voici comment aborder les plus courants :
Gérer la latence et la fraîcheur des données
- Planifiez les extractions selon la vitesse de l’actualité : pour les informations urgentes, faites tourner les extracteurs toutes les 15 à 30 minutes (en phase avec le ). Pour des sujets plus lents, une fréquence quotidienne ou horaire peut suffire.
- Surveillez le décalage entre la publication et la récupération : mesurez l’écart entre le moment où un article est publié et celui où votre système le récupère. Si ce délai augmente, vérifiez les blocages ou ralentissements.
- Relancez une extraction pour capter les « modifications silencieuses » : les articles de presse sont souvent mis à jour après publication. Programmez une seconde extraction 24 heures plus tard pour récupérer les corrections ou modifications discrètes ().
Gérer les limites d’API et la variabilité des sources
- Respectez les quotas d’API : si vous utilisez des API d’actualité, surveillez les limites de débit — étalez les requêtes dans le temps et mettez en cache les résultats lorsque c’est possible ().
- Dédupliquez et canonisez : les mêmes informations apparaissent souvent sur plusieurs URL ou sont mises à jour. Capturez les URL canoniques et utilisez des hachages (par exemple titre + date) pour éviter les doublons ().
- Gérez le contenu dynamique : pour les sites à défilement infini ou à chargement différé, utilisez des outils qui prennent en charge le rendu dynamique et surveillez les changements de mise en page ().
Analyse intelligente des données d’actualité : le rôle de l’IA et du machine learning
Extraire l’actualité n’est que la première étape. La vraie valeur vient de l’analyse et de l’action sur ces données — et c’est là que l’IA et le machine learning brillent.
- Extraction d’entités : utilisez le NLP pour extraire les personnes, organisations et lieux mentionnés dans chaque article ().
- Classification thématique : attribuez automatiquement des thèmes, du sentiment ou un niveau d’urgence aux articles — pour alimenter des tableaux de bord et des alertes plus intelligents ().
- Clustering d’événements : regroupez les articles dupliqués ou liés entre plusieurs médias, afin de voir la vue d’ensemble et non une pluie de titres presque identiques.
- Personnalisation et ciblage : exploitez les données d’actualité en temps réel pour segmenter les audiences, améliorer le ciblage publicitaire ou recommander du contenu — et ainsi stimuler l’engagement et le ROI.
Par exemple, les équipes RP utilisent l’analyse d’actualité en temps réel pour repérer les crises émergentes avant qu’elles ne deviennent virales, tandis que les équipes commerciales enrichissent leurs listes de prospects avec des « événements déclencheurs » comme des levées de fonds ou des recrutements de dirigeants.
Checklist des bonnes pratiques pour l’extraction automatisée d’actualités
Voici une checklist rapide pour garder votre pipeline d’extraction d’actualités fluide :
| Bonne pratique | Pourquoi c’est important | Comment l’appliquer |
|---|---|---|
| Planifier des extractions fréquentes | Réduire le décalage des données, capter l’actualité chaude | Adapter la fréquence de mise à jour à la vitesse de l’actualité (par ex. toutes les 15 min pour les sujets rapides) |
| Utiliser une extraction pilotée par l’IA | S’adapter aux changements de mise en page, réduire le temps de configuration | Des outils comme Thunderbit, Diffbot, Zyte API |
| Dédupliquer et canoniser | Éviter les alertes en double, garantir des données propres | Capturer les URL canoniques, utiliser des hachages pour la déduplication |
| Surveiller la qualité de l’extraction | Repérer les champs manquants, les dérives ou les échecs | Suivre le % d’enregistrements complets, la latence et les taux d’erreur |
| Respecter les limites légales et de conformité | Éviter les risques juridiques, maintenir la confiance | Privilégier les API/flux officiels, relire les conditions, minimiser les données personnelles |
| Exporter vers des formats structurés | Faciliter l’analyse en aval | CSV, Excel, Sheets, Notion, Airtable |
| Programmer des ré-extractions pour les modifications | Détecter les changements après publication | Revenir sur les articles après 24 h / 1 sem. (modèle GDELT) |
| Sécuriser votre pipeline | Protéger les données sensibles | Chiffrement, contrôles d’accès, outils reconnus |
Construire un workflow robuste d’extraction automatisée d’actualités
Prêt à construire votre propre « boîte noire » pour les données d’actualité ? Voici un workflow étape par étape :
- Identifiez vos sources : dressez la liste des sites d’actualité, blogs ou API que vous souhaitez surveiller.
- Mettez en place l’extraction : utilisez Thunderbit ou l’outil de votre choix pour définir les champs (AI Suggest Fields simplifie énormément la tâche).
- Planifiez les extractions : définissez la fréquence selon la vitesse de l’actualité — horaire pour les informations urgentes, quotidienne pour les sujets plus lents.
- Enrichissement des sous-pages : pour chaque titre, extrayez l’article complet pour récupérer le texte, les entités et les balises.
- Dédupliquez et normalisez : capturez les URL canoniques, hachez les enregistrements et standardisez les champs.
- Exportez et intégrez : envoyez les données structurées vers Excel, Google Sheets, Airtable ou Notion pour analyse.
- Surveillez et adaptez : suivez la qualité de l’extraction, surveillez les changements de mise en page et ajustez si nécessaire.
- Restez conforme : relisez les conditions d’utilisation, respectez robots.txt et minimisez les données personnelles.
Pour visualiser le workflow, imaginez :
Sources → Extraction (champs IA) → Enrichissement des sous-pages → Déduplication → Export → Analyse/alertes → Supervision
Conclusion et points clés à retenir
L’extraction automatisée d’actualités n’est plus un simple « plus » : c’est devenu indispensable pour toute personne qui doit garder une longueur d’avance dans un monde où l’actualité change à la minute. En suivant les bonnes pratiques et en utilisant les bons outils, vous pouvez transformer le déluge d’actualités numériques en un flux stable d’intelligence structurée et exploitable.
Points clés à retenir :
- L’échelle et la vitesse de l’actualité en ligne imposent l’automatisation : la veille manuelle ne peut tout simplement pas suivre.
- Les outils d’extraction automatisée d’actualités font gagner du temps, réduisent les coûts et permettent aux petites équipes d’atteindre une couverture comparable à celle d’organisations bien plus grandes.
- Choisir le bon outil revient à équilibrer facilité d’utilisation, sécurité et adaptabilité — Thunderbit se distingue par sa simplicité pilotée par l’IA et ses options d’export en temps réel.
- Construisez votre workflow autour de la fraîcheur, de la déduplication, de la conformité et du suivi qualité pour garantir des données d’actualité fiables et exploitables.
- L’IA et le machine learning débloquent encore plus de valeur — avec un ciblage, une personnalisation et une prise de décision plus intelligents.
Si vous copiez-collez encore des titres ou attendez que Google Alerts rattrape le retard, il est temps de passer à la vitesse supérieure. et voyez à quel point l’extraction automatisée d’actualités peut être simple. Pour plus de conseils, de workflows et d’analyses approfondies, consultez le .
FAQ
1. Qu’est-ce que l’extraction automatisée d’actualités et comment fonctionne-t-elle ?
L’extraction automatisée d’actualités consiste à utiliser un logiciel pour collecter des articles de presse et les transformer en données structurées (comme des tableaux ou du JSON) à des fins d’analyse, de recherche ou d’alertes. Des outils comme Thunderbit utilisent l’IA pour identifier les champs clés (titre, horodatage, auteur, texte de l’article) et les extraire automatiquement depuis des pages web ou des API.
2. Pourquoi les données d’actualité en temps réel sont-elles si importantes pour les entreprises ?
Les données d’actualité en temps réel permettent aux entreprises de réagir rapidement aux événements du marché, aux crises RP ou aux mouvements des concurrents. Que vous travailliez dans la vente, les relations publiques ou la recherche, disposer d’actualités à jour vous aide à prendre des décisions plus intelligentes et plus rapides, tout en gardant une longueur d’avance.
3. Comment Thunderbit facilite-t-il l’extraction d’actualités pour les utilisateurs non techniques ?
Thunderbit propose un processus simple en deux étapes : décrivez les données souhaitées, puis laissez l’IA suggérer les champs. Avec des fonctionnalités comme l’extraction de sous-pages et l’export instantané vers Excel ou Google Sheets, même les utilisateurs non techniques peuvent créer en quelques minutes des pipelines de données d’actualité robustes.
4. Quelles sont les considérations juridiques et de conformité pour l’extraction d’actualités ?
Vérifiez toujours les conditions d’utilisation des sites ciblés, privilégiez les API ou flux officiels lorsqu’ils sont disponibles, et respectez les instructions de robots.txt. Évitez d’extraire des contenus nécessitant une connexion ou derrière un paywall sans autorisation, et limitez la collecte de données personnelles pour rester conforme aux lois sur la vie privée.
5. Comment garantir la fiabilité de mon workflow d’extraction d’actualités sur la durée ?
Planifiez des extractions régulières, surveillez la qualité des données extraites et utilisez des outils qui s’adaptent aux changements de mise en page (comme l’extraction pilotée par l’IA de Thunderbit). Dédupliquez les enregistrements, suivez le délai entre publication et extraction, et mettez en place des alertes en cas d’échec ou de champs manquants pour garder votre pipeline sain et à jour.
En savoir plus