
Une étude fondée sur le crawl des sites les plus visités, qui examine comment ils publient des consignes lisibles par machine pour les grands modèles de langage, à quoi ressemblent les premières implémentations et pourquoi mesurer l’adoption demande plus que de compter les réponses HTTP 200.
- Jeu de données :
data/llms_probe_results_top_10000.csv - Liste Tranco téléchargée : 6 mai 2026
- Périmètre :
/llms.txtet/llms-full.txtà la racine
Indicateurs clés
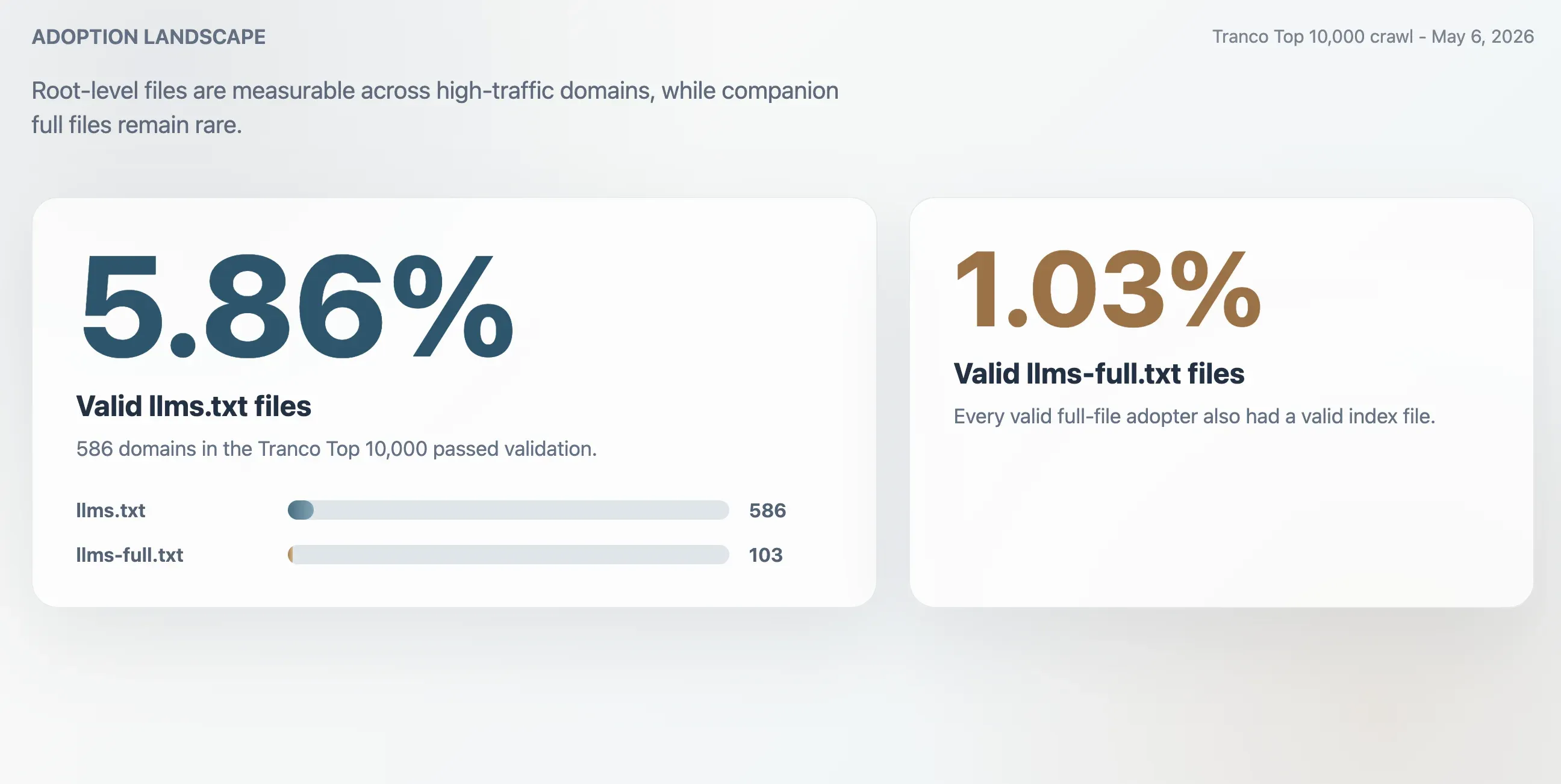
- 5,86 % : adoption valide de
llms.txtsur le Top 10 000 de Tranco, soit 586 domaines. - 1,03 % : adoption valide de
llms-full.txt, soit 103 domaines. Tous les adopteurs valides du fichier complet avaient aussi un fichier d’index valide. - 63,51 % : part des réponses HTTP 200 pour
/llms.txtqui ont échoué à la validation. - 2,74x : surestimation approximative si l’on mesurait l’adoption uniquement à partir des réponses HTTP 200 brutes.
Résumé exécutif
llms.txt reste une convention web émergente, mais ce n’est plus une expérimentation marginale. Lors d’un crawl effectué le 6 mai 2026 sur les 10 000 domaines du Top Tranco, cette étude a identifié 586 fichiers llms.txt valides, soit un taux d’adoption observé de 5,86 %. Le fichier compagnon llms-full.txt était nettement moins courant : 103 domaines disposaient d’un fichier complet valide, pour un taux d’adoption de 1,03 %.
Le résultat méthodologique le plus important est que les codes d’état sont un mauvais proxy de l’adoption. Le crawler a observé 1 606 réponses HTTP 200 pour /llms.txt, mais seulement 586 ont passé la validation. Les 1 020 restantes étaient surtout des redirections hors cible, des pages HTML génériques, des corps vides ou d’autres réponses invalides. Un crawler naïf qui compterait chaque réponse 200 comme une adoption surestimerait l’adoption valide d’environ 2,74 fois.
Parmi les adopteurs valides, la qualité d’implémentation est supérieure à ce qu’un simple récit de fichiers de substitution laisserait entendre. Le fichier valide médian pesait environ 7,1 Ko, 61,77 % des fichiers valides dépassaient 5 Ko, 70,82 % comprenaient six sections Markdown ou plus, et 77,47 % contenaient 11 liens Markdown ou plus. Le groupe des premiers adopteurs inclut Cloudflare, Azure, GitHub, DigiCert, WordPress.org, Adobe, Dropbox, PayPal, Stripe, Salesforce, Slack, Zendesk, Okta, Datadog et Cloudinary.
llms.txts’entend mieux comme un signal explicatif et de navigation à destination des systèmes d’IA, et non comme un remplacement derobots.txt. Sa valeur ne tient pas seulement à l’existence du fichier, mais à sa capacité à aider les machines à trouver des informations autoritatives, concises et à jour.
Contexte : le web ajoute des signaux destinés à l’IA
Depuis longtemps, les sites web utilisent robots.txt pour exprimer des préférences de crawl, sitemap.xml pour faciliter la découverte d’URL, et les données structurées pour aider les moteurs de recherche et les plateformes à interpréter les pages. L’IA générative introduit un problème différent. Le contenu peut servir à l’entraînement, à la recherche, à la synthèse, à la navigation agentique, à l’aide au code, au support client et à la génération de réponses. Cela crée deux besoins simultanés : les éditeurs veulent davantage de contrôle sur les usages automatisés, mais ils souhaitent aussi que les systèmes d’IA trouvent la bonne information canonique lorsqu’ils interagissent avec leurs sites.
, introduite par Jeremy Howard en 2024, présente le fichier comme un document Markdown placé à la racine d’un site web afin de fournir, au moment de l’inférence, des informations adaptées aux LLM. La proposition soutient que les pages HTML contiennent souvent de la navigation, de la publicité, des scripts et d’autres éléments parasites qui compliquent le traitement par les modèles de langage. Un fichier Markdown concis peut orienter les modèles vers les pages, la documentation, les API, les exemples, les politiques et les informations produit les plus importantes.
La recherche externe sur le web apporte un contexte plus large. de la Data Provenance Initiative décrit une augmentation rapide des restrictions liées à l’IA dans robots.txt et les conditions d’utilisation, et soutient que les mécanismes existants de consentement web n’ont pas été conçus pour une réutilisation massive des données par l’IA. a également rendu visibles les schémas des robots d’exploration IA et de robots.txt au niveau des 10 000 principaux domaines. Dans cet environnement, llms.txt se situe du côté constructif du signalement à l’IA : non pas « n’explorez pas ceci », mais « si vous devez comprendre ce site, commencez ici ».
Données externes et débat sur l’adoption
Le débat public autour de llms.txt se partage entre deux affirmations. L’argument optimiste dit que le fichier offre aux systèmes d’IA un chemin plus propre et plus efficace vers un contenu autoritatif. L’argument sceptique dit qu’aucun grand fournisseur de LLM ne s’est engagé publiquement à l’utiliser comme signal de classement, de crawl ou de citation, si bien que les éditeurs ne devraient pas attendre de gains de trafic du seul fait du fichier. Les trois références externes examinées pour cette mise à jour conduisent à une conclusion plus nuancée : llms.txt est une infrastructure utile, mais les preuves d’un impact direct sur le trafic restent limitées et dépendantes du contexte.
Les repères externes d’adoption évoluent vite
indiquait un taux d’adoption de 0,3 % sur les 1 000 premiers sites au 22 juin 2025, soit 3 sites sur 1 000. Il décrit une analyse automatisée mensuelle de domain.com/llms.txt, avec une validation qui exclut les redirections et les réponses HTML. Cette méthodologie est globalement proche de l’approche prudente de validation utilisée dans cette étude.
L’écart de résultats est important : cette étude a trouvé 75 fichiers llms.txt valides dans le Top 1 000 de Tranco au 6 mai 2026, soit 7,50 %. Il ne faut pas traiter ces deux chiffres comme une série temporelle stricte, car la source du classement, les détails d’implémentation, la logique de validation et le moment du crawl peuvent différer. Néanmoins, le contraste suggère que l’adoption a sensiblement évolué entre la mi-2025 et mai 2026, en particulier chez les sites centrés sur les développeurs, le SaaS, le cloud, la sécurité et la documentation.
| Source | Instantané | Échantillon | Adoption valide annoncée | Interprétation |
|---|---|---|---|---|
| Rankability | 22 juin 2025 | 1 000 premiers sites web | 0,3 % | Premier repère public montrant une adoption minimale à la mi-2025. |
| Cette étude | 6 mai 2026 | Top 1 000 de Tranco | 7,50 % | Crawl plus récent montrant une adoption visible parmi les sites à fort trafic. |
| Cette étude | 6 mai 2026 | Top 10 000 de Tranco | 5,86 % | Échantillon plus large montrant que l’adoption est mesurable, mais pas encore dominante. |
Les expériences sur le trafic restent contrastées
a publié en janvier 2026 une analyse portant sur 10 sites, suivis 90 jours avant et 90 jours après l’implémentation. L’article rapporte que deux sites ont enregistré des hausses du trafic IA de 12,5 % et 25 %, que huit n’ont pas montré d’amélioration mesurable et qu’un a reculé de 19,7 %. Son interprétation principale était de rester prudent sur la causalité : les deux cas présentés comme des réussites avaient aussi lancé de nouveaux templates, reconstruit des centres de ressources, ajouté des tableaux comparatifs extractibles, obtenu une couverture presse, corrigé des problèmes techniques ou publié de nouveaux contenus de type FAQ. Dans cette lecture, llms.txt documentait un travail de contenu et de technique plus solide ; il ne semblait pas être, à lui seul, la cause de la croissance.
aboutit à une conclusion plus positive à partir d’une observation de plus petite échelle. Elle compare deux périodes de quatre mois dans Yandex.Metrica après l’ajout de llms.txt et de llms-full.txt. Les sessions de renvoi issues des LLM sont passées de 75 à 92, soit une hausse de 23 %, tandis que les utilisateurs sont passés de 51 à 64. Les sessions venant de Perplexity ont augmenté de 29 à 55, tandis que celles venant de ChatGPT ont diminué de 31 à 26. Le même billet précise aussi que le trafic total de renvoi a progressé plus vite, de 160 à 290 sessions, si bien que la part du trafic LLM est passée de 47 % à 32 %.
This paragraph contains content that cannot be parsed and has been skipped.
Ce que le débat clarifie
Les données externes affinent l’interprétation de cet ensemble de données. Un fichier llms.txt bien structuré peut réduire les frictions d’analyse machine, en particulier pour la documentation développeur, les références d’API et les bases de connaissances. Mais les cas de trafic les plus solides semblent toujours dépendre d’un contenu utile, extractible, autoritatif et découvrable en dehors du fichier. Pour cette raison, la vraie question n’est pas « llms.txt a-t-il de la valeur ? » pris isolément. C’est de savoir si le fichier fait partie d’un système de contenu plus large, lisible par l’IA.
Interprétation mise à jour :
llms.txtdoit être déployé comme une infrastructure à faible coût tournée vers l’IA. Il ne doit pas être présenté comme un substitut à une meilleure documentation, à un contenu structuré, à l’accessibilité technique, aux citations, aux liens ou à l’autorité de marque.
Méthodologie
Cette étude s’appuie sur le Top 10 000 des domaines de Tranco. Tranco est un classement de recherche des principaux sites, conçu pour être plus stable et moins vulnérable aux manipulations que de nombreuses listes traditionnelles. Le fichier source de Tranco a été téléchargé le 6 mai 2026, avec un horodatage Last-Modified source du 5 mai 2026 à 22:17:59 GMT.
Le crawler a testé deux chemins à la racine pour chaque domaine :
https://example.com/llms.txt, avec repli HTTP si nécessaire.https://example.com/llms-full.txt, avec repli HTTP si nécessaire.
Pour chaque requête, le crawler a enregistré le code d’état, l’URL finale, la méthode de récupération, les octets de la réponse, le type de contenu, le message d’erreur, le temps écoulé et le résultat de validation. Les corps de réponses réussies ont été sauvegardés dans raw_llms_txt/ pour examen et analyse secondaire.
Règles de validation
Une réponse n’était comptée comme fichier valide que si elle renvoyait un corps de réponse exploitable et ne ressemblait pas à un fallback web générique. Le chemin final de l’URL devait rester /llms.txt ou /llms-full.txt. Les corps vides étaient rejetés. Les documents HTML évidents et les app shells étaient rejetés. Le type de contenu était considéré comme un indice supplémentaire, et non comme la seule règle, car un petit nombre de fichiers textuels valides étaient servis avec des types de contenu inhabituels.
Panorama de l’adoption
Le crawl a trouvé 586 fichiers llms.txt valides dans le Top 10 000 de Tranco. Cela donne un taux d’adoption valide de 5,86 %. Le fichier compagnon plus petit, llms-full.txt, était présent et valide sur 103 domaines, soit 1,03 % de l’échantillon.
| Indicateur | Nombre | Part du Top 10 000 |
|---|---|---|
| Domaines explorés | 10 000 | 100,00 % |
| Fichiers llms.txt valides | 586 | 5,86 % |
| Fichiers llms-full.txt valides | 103 | 1,03 % |
| Réponses HTTP 200 pour /llms.txt | 1 606 | 16,06 % |
| Réponses HTTP 200 rejetées comme invalides | 1 020 | 10,20 % |
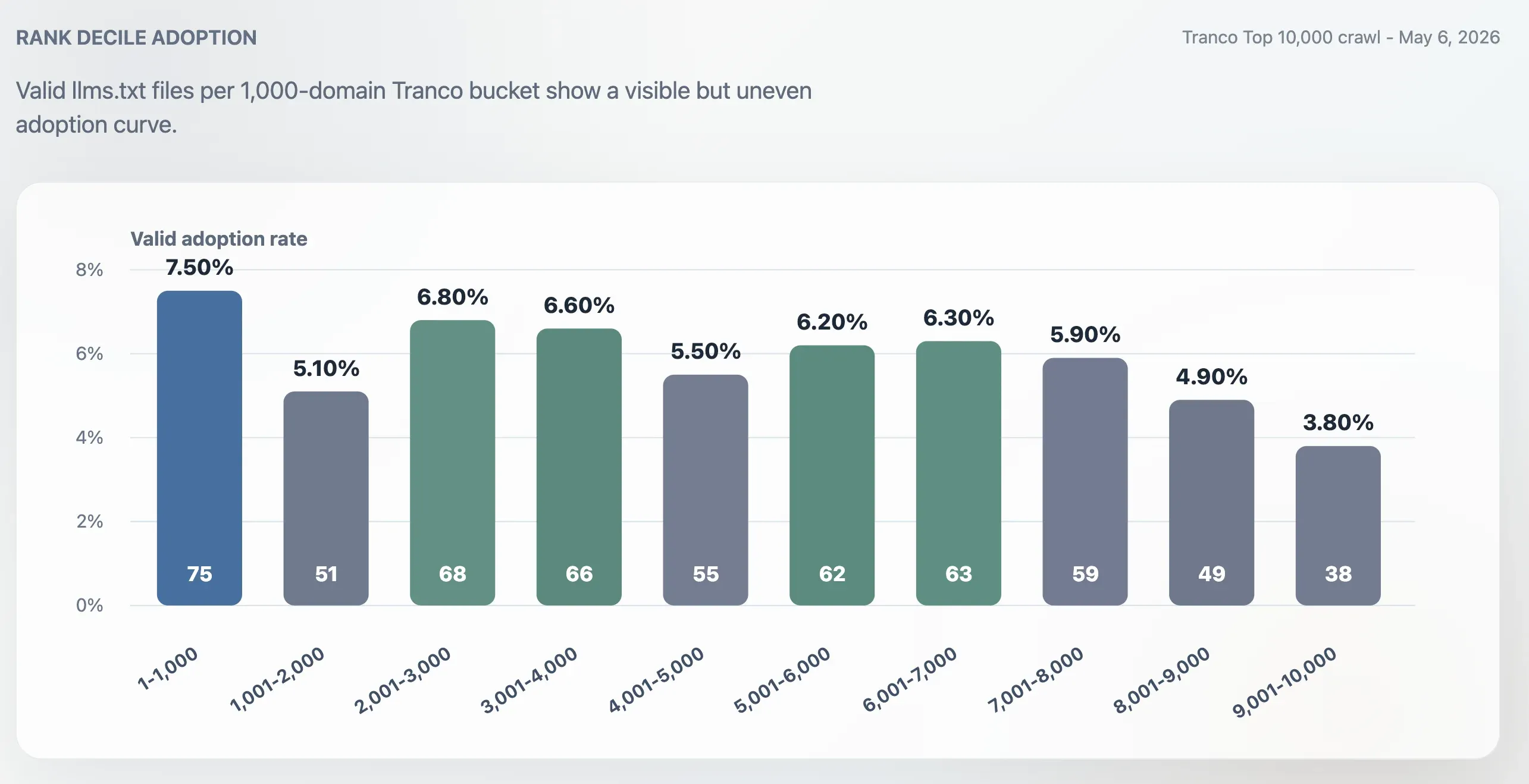
L’adoption n’est pas uniquement concentrée tout en haut
L’adoption était plus forte dans le Top 1 000 que dans l’ensemble du Top 10 000, mais elle ne se limitait pas aux sites les plus grands. Le taux d’adoption du Top 1 000 atteignait 7,50 %. Le dernier groupe de 1 000 domaines, rangs 9 001 à 10 000, tombait à 3,80 %. Le milieu du classement restait actif : les tranches 2 001-3 000, 3 001-4 000, 5 001-6 000 et 6 001-7 000 se situaient toutes autour de 6 %.
Premiers adopteurs
L’adopteur valide le mieux classé était Cloudflare, au rang Tranco 4. Parmi les autres adopteurs bien classés figuraient Azure, GitHub, DigiCert, WordPress.org, Adobe, Sentry, Dropbox, PayPal, Shopify, Taboola, Avast, Weather.com, Oxylabs, SourceForge, Cisco, Stripe, Slack, Dell, NVIDIA, Indeed, Zendesk, Calendly, Palo Alto Networks, Okta, Braze, Klaviyo, Intercom, Datadog, Cloudinary, ClassLink et OneSignal.
Ces adopteurs ne sont pas aléatoires. Ils ont tendance à disposer d’une vaste surface documentaire, de gammes de produits qui demandent des explications, d’API ou d’écosystèmes développeurs, de contenus d’assistance, de pages tarifaires, de contenus liés à la sécurité et à la confidentialité, ainsi que d’une autorité de marque suffisante pour se soucier de la manière dont les systèmes d’IA interprètent leur site.
| Rang | Domaine | Taille du fichier | Schéma observé |
|---|---|---|---|
| 4 | cloudflare.com | 4 225 o | Index compact des produits, développeurs, entreprise et tarifs. |
| 26 | azure.com | 47 037 o | Outils développeur, IA, calcul, stockage, sécurité, supervision et ressources facultatives. |
| 28 | github.com | 27 108 o | Accès programmatique, Copilot, MCP, API REST, Actions, dépôts et liens CLI. |
| 248 | stripe.com | 64 229 o | Paiements, Connect, Checkout, Billing, Tax, Atlas, Radar et documentation développeur. |
| 265 | salesforce.com | 1,02 Mo | Vaste catalogue de liens produits et Agentforce, sans titres de section Markdown. |
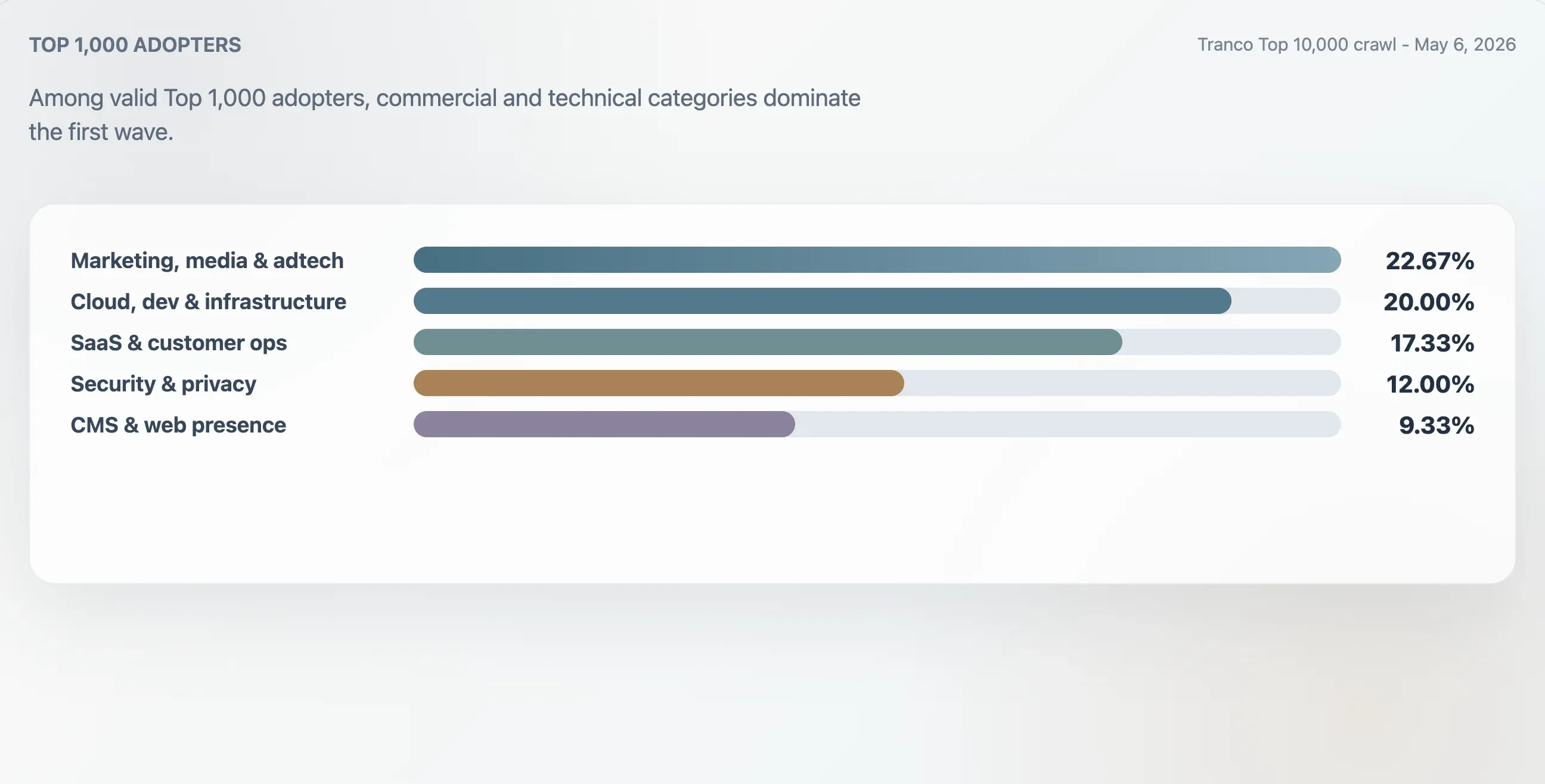
Catégories des adopteurs du Top 1 000
Cette étude a classé les 75 adopteurs valides du Top 1 000 de Tranco à l’aide du contexte de domaine, des premiers titres, de la structure brute des fichiers et de mots-clés de contenu. Le groupe le plus important était le marketing, les médias et l’adtech, avec 22,67 %. Les sites cloud, développeur et infrastructure représentaient 20,00 %. Les sites SaaS, productivité et opérations clients représentaient 17,33 %. Les sites sécurité, identité et confidentialité représentaient 12,00 %.
| Catégorie | Domaines | Part des adopteurs du Top 1 000 | Score de qualité médian | Liens médians |
|---|---|---|---|---|
| Marketing, médias et adtech | 17 | 22,67 % | 94 | 25 |
| Cloud, développement et infrastructure | 15 | 20,00 % | 94 | 62 |
| SaaS, productivité et opérations clients | 13 | 17,33 % | 94 | 46 |
| Sécurité, identité et confidentialité | 9 | 12,00 % | 98 | 78 |
| CMS, hébergement et présence web | 7 | 9,33 % | 100 | 24 |
Répartition par TLD
Les domaines de premier niveau ne sont pas des étiquettes sectorielles, mais ils donnent des indications utiles. Parmi les TLD comptant au moins 50 domaines dans l’échantillon, .io affichait le taux d’adoption valide le plus élevé, à 14,44 %. .com suivait avec 8,19 %. L’adoption plus faible de .gov, .edu et .net suggère que la base des premiers adopteurs est plus commerciale et technique qu’institutionnelle.
Qualité d’implémentation
Une adoption valide ne signifie pas une qualité d’implémentation uniforme. Certains fichiers sont des index courts et bien structurés. D’autres sont surtout du texte. Certains sont de simples catalogues de liens bruts. D’autres encore sont des fichiers de substitution presque vides. D’autres enfin sont des déversements de contenu de plusieurs mégaoctets, peut-être complets mais coûteux à récupérer et à analyser.
Parmi les fichiers llms.txt valides, 362 faisaient plus de 5 Ko, soit 61,77 % des adopteurs valides. La taille médiane était d’environ 7,1 Ko. Le P90 était de 156 Ko, le P95 de 356 Ko, le P99 de 2,54 Mo, et le plus grand fichier observé atteignait 7,97 Mo.
Signaux de contenu courants
Une analyse par mots-clés des fichiers valides a montré que de nombreux sites ne se contentent pas de publier une déclaration ; ils orientent les modèles vers du contenu réellement utile sur le plan opérationnel. Des termes liés au support ou à l’aide apparaissaient dans 70,31 % des fichiers valides. Des termes blog, guide ou tutoriel apparaissaient dans 67,92 %. Des termes liés à la sécurité, la confidentialité, la conformité ou les conditions d’utilisation apparaissaient dans 61,43 %. Les tarifs apparaissaient dans 53,92 %, la documentation dans 52,22 %, les termes liés aux API dans 33,96 %, et les signaux de changelog ou de version dans 27,30 %.
Score de qualité et archétypes
Pour passer de la présence à la maturité, cette étude a créé un score léger d’implémentation. Ce score prend en compte le type de contenu, la taille du fichier, la structure Markdown, le nombre de liens, la couverture thématique et des signaux d’alerte comme l’absence de titres, l’absence de liens Markdown, des types de contenu inhabituels, des fichiers minuscules, des fichiers très volumineux et les comportements de type « dump de liens ». Ce n’est pas une norme officielle. C’est un modèle de scoring de recherche pour comparer des implémentations observées.
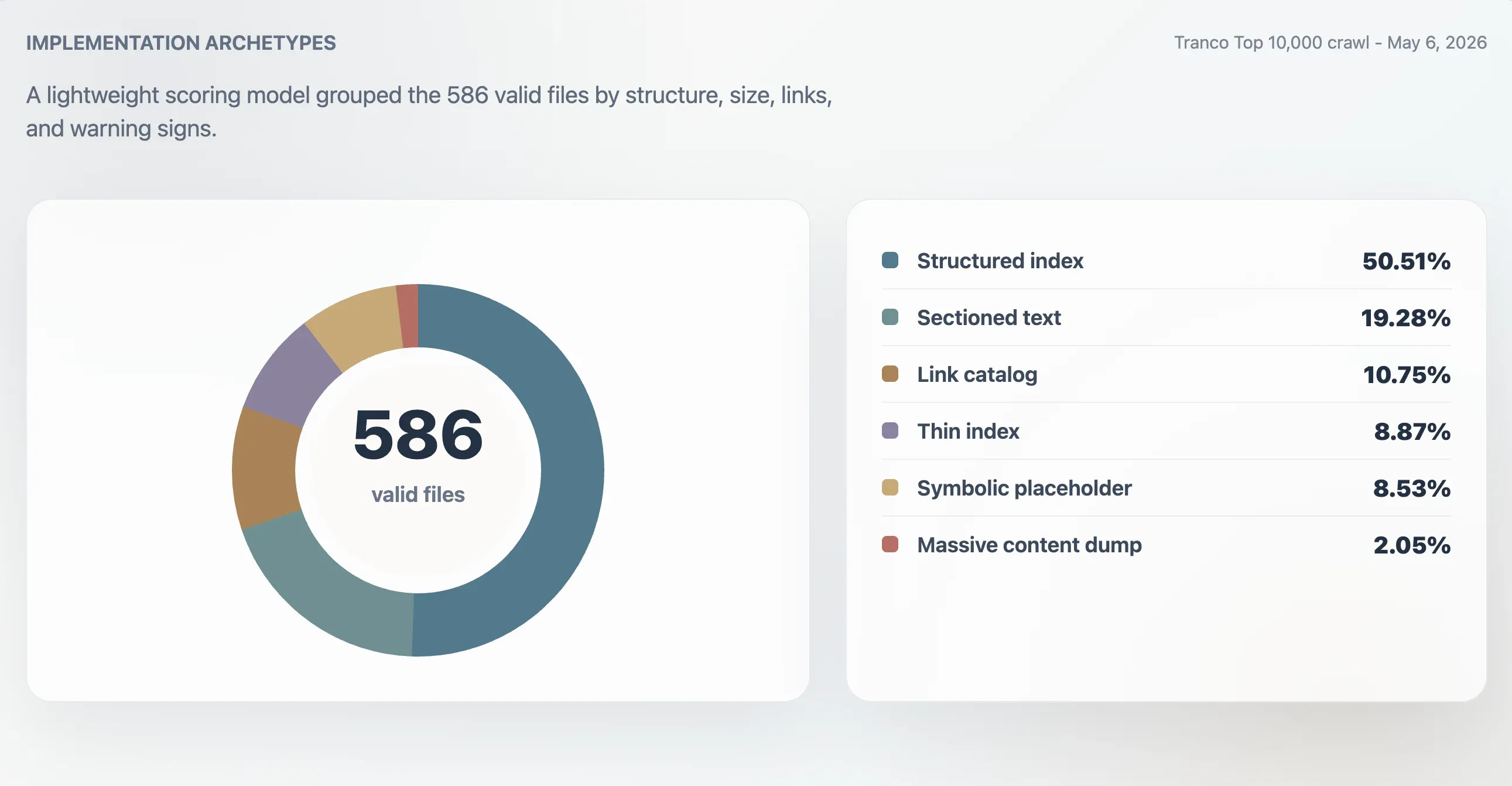
Avec ce modèle, 416 fichiers valides ont été classés comme index structurés solides, 107 comme index utilisables, 24 comme minces ou irréguliers, et 39 comme symboliques ou à faible utilité. Une analyse parallèle par archétypes a identifié 296 index structurés, 113 fichiers textuels sectionnés, 63 catalogues de liens, 52 index minces, 50 fichiers symboliques ou de substitution, et 12 énormes déversements de contenu.
| Archétype | Domaines | Part des fichiers valides | Score médian | Taille médiane du fichier | Liens médians |
|---|---|---|---|---|---|
| Index structuré | 296 | 50,51 % | 98 | 11 241 o | 61,5 |
| Texte sectionné | 113 | 19,28 % | 78 | 4 718 o | 0 |
| Catalogue de liens | 63 | 10,75 % | 86 | 4 160 o | 23 |
| Index mince | 52 | 8,87 % | 66 | 2 814 o | 0 |
| Symbolique ou de substitution | 50 | 8,53 % | 27 | 15 o | 0 |
| Déversement massif de contenu | 12 | 2,05 % | 74 | 2,84 Mo | 7 259,5 |
Les plus gros adopteurs ont des implémentations plus denses
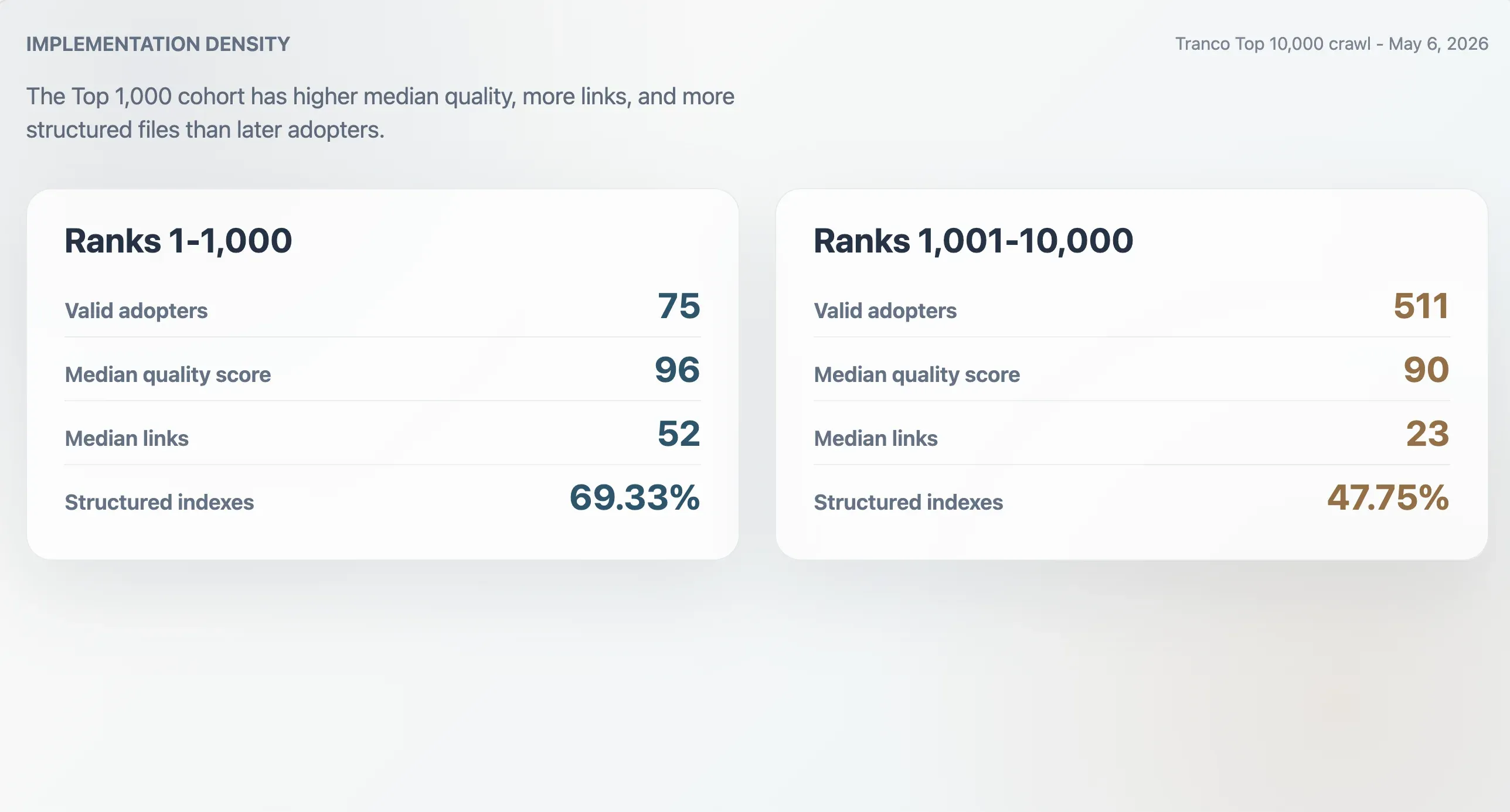
Les 75 adopteurs valides du Top 1 000 de Tranco avaient un score de qualité médian de 96, une taille médiane de fichier de 9 068 octets, un nombre médian de liens Markdown de 52 et un nombre médian de sections de 11. Les 511 adopteurs classés entre 1 001 et 10 000 avaient des médianes plus basses : score de 90, taille de fichier de 6 506 octets, 23 liens Markdown et 9 sections. Les adopteurs du Top 1 000 avaient aussi plus souvent des index structurés : 69,33 % contre 47,75 % dans la cohorte plus basse.
Le problème des faux positifs

Le principal risque de mesure est celui des faux positifs. Sur les 1 606 domaines qui ont renvoyé HTTP 200 pour /llms.txt, 1 020 ont échoué à la validation. La raison invalide la plus fréquente était une redirection hors cible, avec 618 cas. 367 autres réponses étaient des documents HTML génériques. Vingt-neuf renvoyaient un corps vide et six autres étaient des réponses invalides diverses ou non catégorisées.
C’est important, car de nombreux grands sites redirigent les chemins inconnus vers des pages de connexion, des pages d’accueil, des app shells, des pages régionales, des écrans de consentement ou des fallbacks marketing. Ces réponses peuvent paraître saines pour un crawler basé sur les codes d’état, tout en ne contenant aucun signal llms.txt valide.
llms-full.txt : plus rare et plus inégal
Le fichier compagnon llms-full.txt était beaucoup moins courant que llms.txt. Le crawl a trouvé 103 fichiers complets valides, soit 17,58 % des adopteurs valides de llms.txt et 1,03 % du Top 10 000 complet.
Les implémentations du fichier complet étaient inégales. Parmi les 103 adopteurs à double fichier, 57 avaient un llms-full.txt plus volumineux que le fichier d’index, mais 46 avaient soit un fichier complet qui n’était pas plus grand que le fichier d’index, soit un fichier complet de moins de 100 octets. Le ratio médian de taille entre le fichier complet et l’index était de 1,43, mais certains cas extrêmes étaient beaucoup plus élevés. Le fichier complet de Supabase était environ 7 139 fois plus grand que son fichier d’index. Made-in-China.com avait un fichier complet de 89,89 Mo.
| Domaine | llms.txt | llms-full.txt | Ratio |
|---|---|---|---|
| made-in-china.com | 4,49 Mo | 89,89 Mo | 20,0x |
| sendbird.com | 281,86 Ko | 11,99 Mo | 42,5x |
| taboola.com | 286,78 Ko | 11,73 Mo | 40,9x |
| supabase.co | 1,26 Ko | 8,98 Mo | 7 139,3x |
| neon.tech | 27,44 Ko | 5,01 Mo | 182,7x |
Recommandation : ne publiez
llms-full.txtque lorsque le site dispose déjà d’un pipeline de documentation stable, d’une discipline de versioning et d’une raison claire d’exposer de gros volumes de contenu dans un seul fichier lisible par machine.
llms.txt, robots.txt et sitemap.xml
llms.txt ne doit pas être considéré comme un nouveau robots.txt. Ce sont tous deux des fichiers lisibles par machine à la racine, mais ils communiquent des choses différentes. robots.txt est un signal de préférence de crawl et de contrôle d’accès. sitemap.xml est un signal de découverte d’URL. llms.txt est un signal explicatif et de navigation.
| Signal | Rôle principal | Lecteur type | Interprétation dans cette étude |
|---|---|---|---|
robots.txt | Définir les préférences de crawl et les restrictions au niveau des chemins. | Robots d’exploration, robots IA, robots d’archivage, bots génériques. | Signal de gouvernance et d’accès. |
sitemap.xml | Lister les URL découvrables pour les systèmes d’indexation. | Moteurs de recherche et pipelines d’indexation. | Signal de découverte. |
llms.txt | Fournir un contexte compact du site, des liens importants, de la documentation, des API, des exemples et des références de politique. | Applications LLM, agents IA, outils développeur, systèmes de recherche/récupération. | Signal d’explication et de navigation. |
Recommandations
Pour les sites qui envisagent llms.txt, les implémentations les plus solides de cet ensemble de données et les preuves externes sur le trafic suggèrent une approche pragmatique :
- Publiez
/llms.txtà la racine et laissez-le accessible sans connexion, sans exécution JavaScript, sans mur de consentement ni redirection hors chemin. - Servez-le si possible en
text/plainoutext/markdown. - Commencez par une brève description du site, puis regroupez les liens par produit, documentation, API, tarifs, changelog, exemples, support, politiques et ressources d’entreprise.
- Préférez des liens canoniques à des listes exhaustives d’URL.
- Évitez les fichiers symboliques vides ; au mieux, ils ne constituent qu’un signal faible.
- Évitez les déversements massifs non différenciés, sauf s’il existe un véritable cas d’usage de consommation machine et un pipeline de génération fiable.
- Validez l’URL finale, le corps de la réponse, le type de contenu, la structure Markdown, le nombre de liens et la taille du fichier après publication.
Les équipes doivent aussi gérer les attentes avec soin. Les expériences publiques disponibles ne prouvent pas que llms.txt augmente indépendamment le trafic de renvoi issu de l’IA. Si une équipe veut tester l’impact business, elle doit suivre ensemble les renvois LLM, les pages citées, les requêtes des bots, la fraîcheur de l’index et les changements de contenu. Une expérience utile comparerait des groupes de pages appariés, maintiendrait les mises à jour de contenu constantes autant que possible et séparerait les trafics spécifiques aux plateformes comme Perplexity, ChatGPT, Gemini, Claude et Bing/Copilot.
Limites
Il s’agit d’un instantané fondé sur le crawl, pas d’une vérité définitive. Les sites peuvent ajouter, supprimer ou modifier leurs fichiers llms.txt à tout moment. Certains domaines peuvent bloquer les requêtes automatisées ou se comporter différemment selon la géographie, la configuration TLS, la logique de redirection, l’agent utilisateur ou les mécanismes d’atténuation des bots. L’étude n’a testé que les fichiers à la racine et n’a pas cherché dans les sous-domaines ni dans des chemins non standard.
Le score de qualité et les archétypes sont des outils de recherche, pas des labels de conformité officiels. L’analyse thématique est fondée sur des mots-clés et doit être lue comme un indicateur directionnel. L’étude ne prouve pas qu’une plateforme d’IA spécifique lit, respecte ou utilise actuellement llms.txt en production.
Les preuves externes sur le trafic examinées dans cette version ont elles aussi leurs limites. L’analyse de Search Engine Land est plus solide comme observation multi-sites appelant à la prudence que comme expérience randomisée. Le résultat d’Alimbekov est utile comme étude de cas transparente à l’échelle d’un site, mais il ne comporte pas de groupe témoin et inclut une période où le trafic total de renvoi a fortement augmenté. Ces références aident à cadrer le débat, mais elles ne transforment pas ce crawl en étude causale du trafic.
Fichiers et reproductibilité
| Fichier | Objectif |
|---|---|
crawl_llms_txt.py | Crawler pour /llms.txt et /llms-full.txt. |
analyze_llms_txt.py | Analyse principale de l’adoption et génération des graphiques. |
deep_analyze_llms_txt.py | Analyse secondaire des déciles de rang, des TLD, des signaux thématiques, des scores de qualité, des archétypes et du comportement à double fichier. |
deep_dive_early_quality.py | Classification des premiers adopteurs et analyse approfondie de la qualité d’implémentation. |
data/llms_probe_results_top_10000.csv | Jeu de données principal issu du crawl. |
data/deep_analysis_top_10000.json | Résumé de l’analyse secondaire. |
data/deep_early_quality_analysis.json | Catégories des premiers adopteurs, comparaison des cohortes de qualité, détails des archétypes et études de cas. |
Sources
- , Jeremy Howard, 2024.
- .
- .
- .
- , Data Provenance Initiative.
- .
- , Search Engine Land, janvier 2026.
- , Rankability, juin 2025.
- , Renat Alimbekov.
Les corrections de méthodologie, les problèmes de jeu de données et les analyses de suivi sont les bienvenus à support@thunderbit.com. Ce rapport est publié indépendamment de toute position commerciale détenue par Thunderbit. Les données de ce rapport se suffisent à elles-mêmes. — L’équipe de recherche Thunderbit, mai 2026.