Si vous avez déjà essayé de construire une grille de prix concurrentielle, de suivre de nouvelles annonces immobilières ou simplement de garder un œil sur un vaste catalogue e-commerce, vous connaissez le problème : des heures passées à copier, coller et nettoyer des données brouillonnes, pour finir avec des informations déjà obsolètes au moment où vous avez terminé. En 2025, alors que le web gagne chaque année des milliards de nouvelles pages, la collecte manuelle de données ne peut tout simplement pas suivre. Les entreprises prennent conscience d’une nouvelle réalité : les données web structurées ne sont pas un simple « plus » ; elles sont la colonne vertébrale d’une prise de décision intelligente, de la vente au marketing, en passant par les opérations et la stratégie produit.
C’est là qu’entrent en jeu les crawlers de listings et l’extraction automatisée de listings. J’ai pu constater de première main à quel point des équipes qui utilisent des outils pilotés par l’IA comme transforment des recherches fastidieuses et sujettes aux erreurs en un processus rapide, évolutif et presque amusant. Voyons ce que signifie vraiment le crawling de listings, comment fonctionnent les dernières solutions basées sur l’IA, et comment vous pouvez les utiliser pour donner un sérieux avantage à votre entreprise, sans écrire une seule ligne de code ni perdre la raison.
Qu’est-ce qu’un crawler de listings ? Les bases de l’extraction automatisée de listings
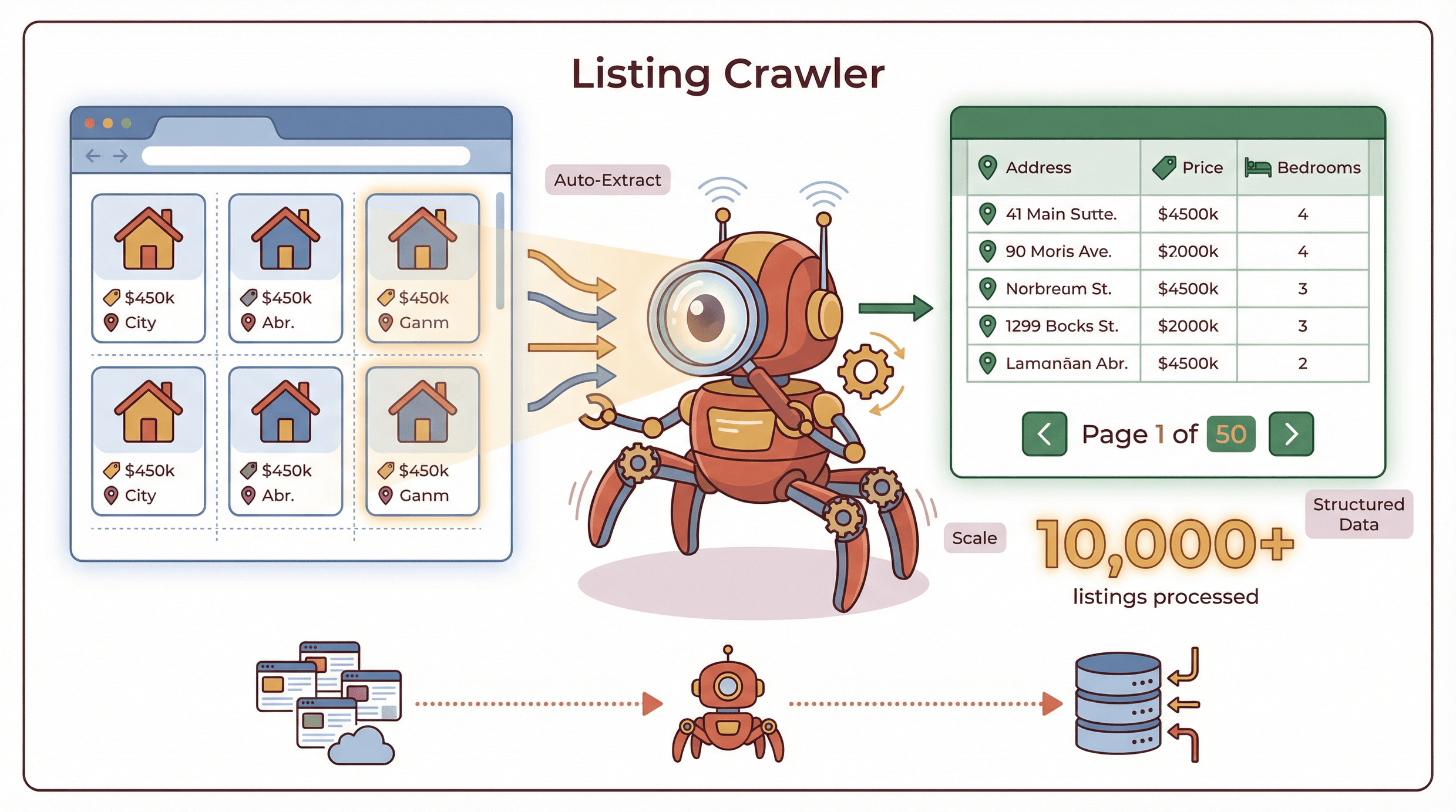 Un crawler de listings est un outil spécialisé conçu pour extraire des données structurées à partir de pages web qui affichent plusieurs éléments dans un format cohérent — pensez catalogues de produits, annonces immobilières, offres d’emploi ou annuaires d’entreprises. Contrairement aux extracteurs web généralistes, qui peuvent récupérer des données depuis n’importe quelle page, structurée ou non, un crawler de listings se concentre sur le contenu répétitif et structuré, et peut passer à l’échelle sur plusieurs pages en gérant facilement la pagination et les sous-pages ().
Un crawler de listings est un outil spécialisé conçu pour extraire des données structurées à partir de pages web qui affichent plusieurs éléments dans un format cohérent — pensez catalogues de produits, annonces immobilières, offres d’emploi ou annuaires d’entreprises. Contrairement aux extracteurs web généralistes, qui peuvent récupérer des données depuis n’importe quelle page, structurée ou non, un crawler de listings se concentre sur le contenu répétitif et structuré, et peut passer à l’échelle sur plusieurs pages en gérant facilement la pagination et les sous-pages ().
Comment ça marche ? Imaginez que vous consultez un site immobilier avec 50 logements par page. Un crawler de listings peut automatiquement reconnaître les informations de chaque bien (adresse, prix, nombre de chambres, etc.), les extraire dans un tableau propre, puis « cliquer » sur la page suivante pour continuer, sans aucune copie manuelle. Les crawlers avancés peuvent même suivre les liens vers les pages de détail (sous-pages) pour récupérer des informations supplémentaires, comme les coordonnées de l’agent ou la description du bien.
Différence clé : les crawlers de listings sont pensés pour l’échelle et la structure. C’est un peu comme avoir un stagiaire robot qui ne se fatigue jamais, ne fait jamais de faute de frappe et peut traiter des milliers de listings en quelques minutes.
Pourquoi l’extraction automatisée de listings compte pour l’entreprise
Allons à l’essentiel : pourquoi autant d’équipes — de la vente au produit, en passant par les opérations — se soucient-elles de l’extraction automatisée de listings ? Voici quelques-uns des principaux cas d’usage et la valeur business qu’ils débloquent :
| Cas d’usage | Fonction métier | Bénéfice |
|---|---|---|
| Génération de leads (scraping d’annuaires) | Ventes / Développement biz | Alimentez votre CRM avec des leads frais et qualifiés en quelques minutes, pas en semaines |
| Suivi des prix des concurrents (scraping de catalogues) | Marketing / Produit | Intelligence tarifaire en temps réel, pivots stratégiques plus rapides, hausse du chiffre d’affaires |
| Suivi des stocks et des fournisseurs | Opérations / Chaîne logistique | Données de stock à jour, prévention des ruptures, détection immédiate des changements d’approvisionnement |
| Études de marché (agrégation d’annonces/avis) | Stratégie / Analytics | Analyse des tendances à grande échelle, meilleures décisions produit, vision globale du marché |
| Suivi des annonces immobilières | Immobilier / Investissement | Alertes rapides sur les nouvelles opportunités, évolutions de prix, comparables — flux de transactions plus rapide |
Le retour sur investissement est réel : les entreprises qui utilisent des crawlers de listings automatisés rapportent 30 à 40 % de temps gagné sur la collecte de données (), ainsi que des taux de précision allant jusqu’à 99 % — contre un taux d’erreur manuel jusqu’à 8 fois plus élevé (). Ce qui prenait auparavant une semaine prend désormais quelques minutes, et les données sont prêtes à être analysées, au lieu de dormir dans un simple tableur.
Crawler de listings traditionnel vs. piloté par l’IA : quelle différence ?
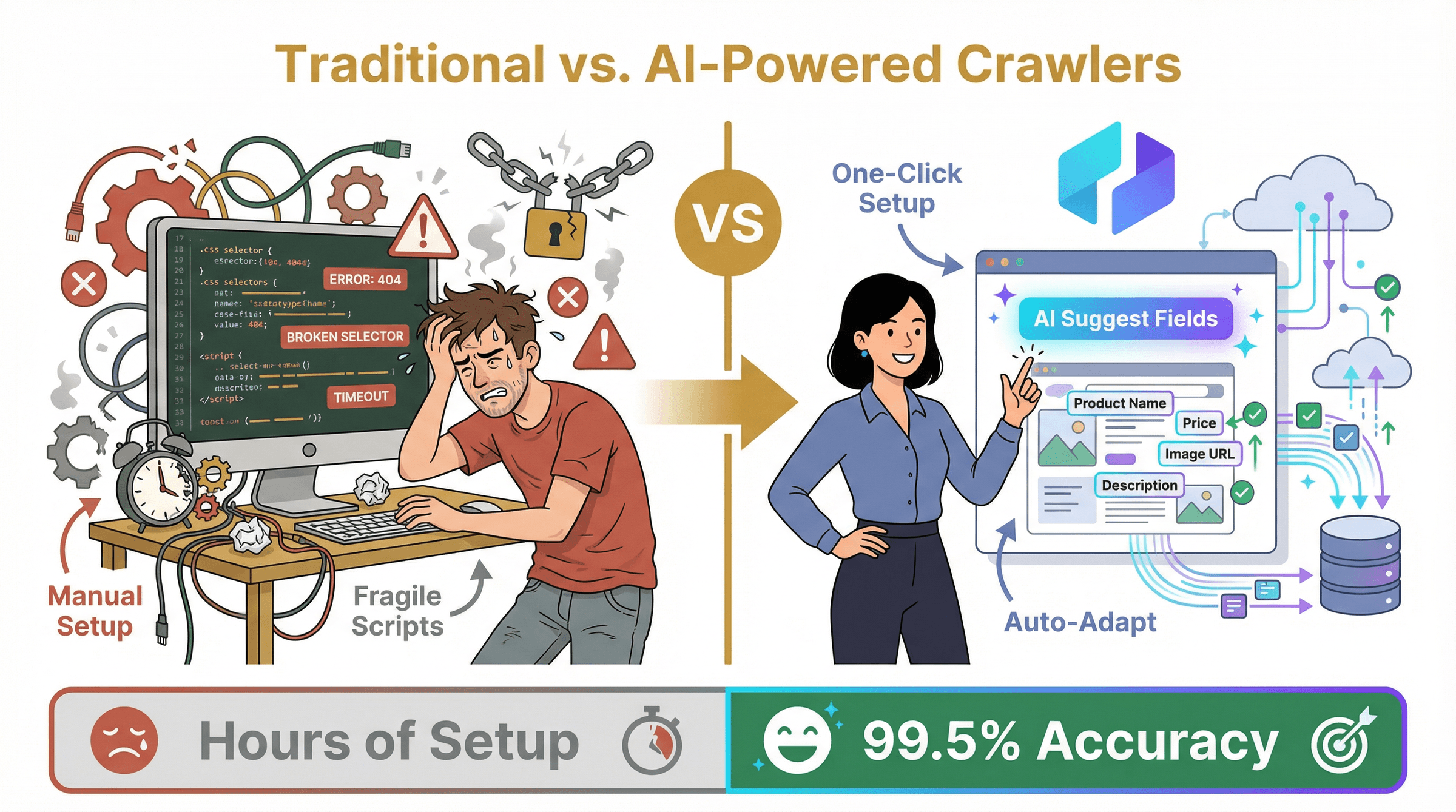 Soyons honnêtes : les crawlers de listings traditionnels (pensez Scrapy, BeautifulSoup, ou même certains outils « no-code ») peuvent faire le travail, mais ils s’accompagnent d’un certain nombre de contraintes :
Soyons honnêtes : les crawlers de listings traditionnels (pensez Scrapy, BeautifulSoup, ou même certains outils « no-code ») peuvent faire le travail, mais ils s’accompagnent d’un certain nombre de contraintes :
- Configuration manuelle : vous devez définir des sélecteurs CSS, écrire des scripts ou créer des modèles pour chaque champ à extraire.
- Processus fragiles : si le site modifie sa mise en page ou ses noms de classes, votre scraper casse — et vous devez repartir de zéro.
- Gestion limitée du contenu dynamique : défilement infini, contenu AJAX ou éléments interactifs ? Préparez-vous à de longues soirées de débogage.
Les crawlers de listings pilotés par l’IA (comme Thunderbit) changent complètement l’approche. Au lieu de dire à l’outil comment extraire les données, vous lui montrez simplement la page (ou vous décrivez votre objectif), et l’IA se charge du reste. Elle reconnaît les schémas, s’adapte aux changements de mise en page et peut même gérer le contenu dynamique et les sous-pages — le tout avec une configuration minimale.
Principaux avantages de l’extraction automatisée de listings pilotée par l’IA
- Mise en route plus rapide : un clic sur « AI Suggest Fields » et l’outil propose toutes les colonnes pertinentes — sans sélecteurs ni code.
- Précision plus élevée : les modèles d’IA reconnaissent les données dans leur contexte, en les nettoyant et en les dédupliquant au passage. Les taux de précision peuvent atteindre 99,5 %, même sur des pages mal structurées ().
- Résistance aux changements : si un site modifie son HTML, l’IA s’adapte — plus de scripts cassés ni de maintenance sans fin ().
- Gestion du contenu dynamique : défilement infini, pop-ups ou AJAX ? Les crawlers IA peuvent interagir avec la page comme un humain et ne rien laisser passer.
- Passage à l’échelle : les crawlers IA basés sur le cloud peuvent traiter des milliers de pages en parallèle, avec planification et automatisation intégrées.
Thunderbit Listing Crawler : accélérez votre extraction automatisée de listings
Je suis peut-être un peu biaisé — mais pour de bonnes raisons. a été conçu pour rendre le crawling de listings aussi simple que de commander un repas à emporter. Voici comment cela fonctionne :
- Installez l’ : l’installation se fait en deux clics, et vous êtes prêt.
- Accédez à une page de listing : ouvrez n’importe quel site — e-commerce, immobilier, annuaire, peu importe.
- Cliquez sur « AI Suggest Fields » : l’IA de Thunderbit analyse la page et suggère les meilleures colonnes à extraire (par exemple, nom du produit, prix, image, URL).
- Personnalisez les colonnes si besoin : renommez, ajoutez ou supprimez des champs. Ajoutez des prompts IA personnalisés pour des étiquetages ou des formats avancés.
- Cliquez sur « Scrape » : Thunderbit récupère toutes les données, gère la pagination et peut même visiter les sous-pages pour obtenir des détails supplémentaires.
- Exportez instantanément : envoyez vos données vers Excel, Google Sheets, Notion, Airtable, ou téléchargez-les en CSV/JSON — totalement gratuit.
Thunderbit propose aussi des modèles instantanés pour les sites les plus populaires (Amazon, Zillow, Shopify, Instagram, et bien d’autres), ce qui vous permet de vous passer entièrement de configuration pour les cas d’usage courants. Et si vous devez extraire des PDF ou des images, l’IA de Thunderbit sait aussi le faire.
Thunderbit vs. autres crawlers de listings : comparaison côte à côte
Voici comment Thunderbit se positionne face à d’autres outils populaires :
| Fonctionnalité | Thunderbit | Octoparse | Scrapy | Firecrawl | LinkUp |
|---|---|---|---|---|---|
| Suggestion de champs IA | ✅ | ⚠️ (basique) | ❌ | ✅ | ✅ |
| Configuration sans code | ✅ | ⚠️ | ❌ | ⚠️ | ⚠️ |
| Scraping de sous-pages | ✅ | ⚠️ | ⚠️ | ✅ | ✅ |
| Modèles préconçus | ✅ | ✅ | ❌ | ❌ | ❌ |
| Export vers Sheets/Excel | ✅ | ✅ | ⚠️ | ⚠️ | ⚠️ |
| Export de données gratuit | ✅ | ⚠️ | ✅ | ⚠️ | ⚠️ |
| Scraping planifié | ✅ | ✅ | ⚠️ | ✅ | ✅ |
| Maintenance requise | Minimale | Modérée | Élevée | Faible | Faible |
| Tarification (démarrage) | 15 $/mois | ~119 $/mois | Gratuit* | Variable | Variable |
*Scrapy est gratuit, mais nécessite du temps de développement et une infrastructure.
Le point fort de Thunderbit ? Il a été pensé pour les utilisateurs métiers non techniques qui veulent des résultats rapides — sans courbe d’apprentissage abrupte, sans frais d’export cachés et sans casse-tête quand les sites web évoluent.
Guide étape par étape : utiliser Thunderbit pour l’extraction automatisée de listings
Prêt à l’essayer vous-même ? Voici comment utiliser Thunderbit comme crawler de listings :
1. Installez Thunderbit
Rendez-vous sur le et ajoutez Thunderbit. Créez un compte gratuit (le niveau gratuit vous permet d’extraire jusqu’à 6 pages, ou 10 avec un bonus d’essai).
2. Ouvrez votre page de listing cible
Allez sur le site que vous souhaitez extraire — par exemple une catégorie de produits sur Amazon, une recherche Zillow ou un annuaire professionnel. Appliquez les filtres nécessaires via l’interface du site.
3. Cliquez sur « AI Suggest Fields »
Cliquez sur l’icône Thunderbit dans votre navigateur. Appuyez sur « AI Suggest Fields ». L’IA de Thunderbit lira la page et proposera des colonnes comme nom du produit, prix, URL, image, etc.
4. Personnalisez les colonnes et les prompts
Passez en revue les champs suggérés. Renommez, ajoutez ou supprimez des colonnes selon vos besoins. Pour des besoins avancés, ajoutez un Field AI Prompt (par exemple : « extraire le prix uniquement sous forme de nombre » ou « étiqueter “Luxe” si le prix > 2 000 $ »).
5. Gérez la pagination et les sous-pages
Si votre listing s’étend sur plusieurs pages, Thunderbit peut cliquer automatiquement sur « Suivant » ou accepter une liste d’URL. Pour les pages de détail, cliquez sur « Scrape Subpages » et Thunderbit visitera chaque lien pour récupérer des informations supplémentaires (comme les caractéristiques ou les coordonnées).
6. Lancez l’extraction
Cliquez sur « Scrape ». Regardez Thunderbit remplir un tableau avec vos données, en direct. Pour les gros volumes, utilisez le Cloud Scraping pour aller plus vite (jusqu’à 50 pages à la fois).
7. Exportez vos données
Une fois terminé, exportez directement vers Excel, Google Sheets, Notion ou Airtable. Thunderbit peut même téléverser des images vers Notion/Airtable si nécessaire.
Astuce pro : enregistrez votre configuration comme modèle pour une utilisation future, ou programmez son exécution automatique (voir ci-dessous).
Personnaliser la sortie : définir des filtres et des formats d’export
Thunderbit vous donne un contrôle total sur le résultat :
- Sélectionnez des champs précis : ne gardez que les colonnes dont vous avez besoin.
- Appliquez des filtres : utilisez les filtres du site avant l’extraction, ou ajoutez une logique dans les Field AI Prompts (par exemple : « n’extraire que les listings dont le prix est inférieur à 500 000 $ »).
- Choisissez le format de sortie : exportez vers Excel, CSV, JSON, Google Sheets, Notion ou Airtable.
- Transformation avancée : utilisez les Field AI Prompts pour le formatage, le découpage ou la fusion de champs, l’extraction conditionnelle, la catégorisation ou même la traduction (Thunderbit prend en charge 34 langues).
Par exemple, si vous souhaitez étiqueter des listings comme « Abordable » ou « Luxe » selon le prix, ajoutez simplement une instruction : « Étiqueter Luxe si le prix > 2 000 $, sinon Abordable. » Thunderbit s’occupe du reste pendant l’extraction.
Montée en gamme métier : tirer parti de l’extraction automatisée de listings pour un avantage concurrentiel
Une fois que vous disposez de données de listings structurées, les possibilités sont infinies :
- Analyse concurrentielle : suivez les prix, les nouveaux produits et les stocks des concurrents en temps réel. Un distributeur a augmenté ses ventes de 4 % grâce à des données concurrentielles extraites ().
- Gestion des stocks : surveillez les sites des fournisseurs pour détecter les changements de stock, les hausses de prix ou les nouveaux SKU — automatiquement.
- Génération de leads : constituez des listes ciblées à partir d’annuaires, de LinkedIn ou de sites d’associations — et alimentez-les directement dans votre CRM.
- Études de marché : agrégerez avis, caractéristiques produits ou données immobilières pour l’analyse des tendances et des décisions produit plus intelligentes.
- Agrégation de contenu : alimentez des sites comparatifs, des agrégateurs d’avis ou des projets SEO avec des données toujours fraîches.
Intégrez vos données exportées à des outils d’analyse (Tableau, Power BI, Google Data Studio) pour créer des tableaux de bord, des analyses de tendances ou des modèles prédictifs. Avec Thunderbit, vous ne faites pas que collecter des données : vous construisez un radar concurrentiel en temps réel.
Suivi dynamique : planification et extraction de listings en temps réel
Le web ne dort jamais, et vos données non plus. Le Scheduled Scraper de Thunderbit vous permet d’automatiser une surveillance continue :
- Programmez une fréquence : décrivez simplement le rythme en langage naturel (« tous les jours à 7 h » ou « toutes les 4 heures »). L’IA de Thunderbit gère le reste.
- Saisissez vos URL : extrayez une page ou une liste complète — Thunderbit les récupérera selon le calendrier défini.
- Exportez vers Sheets/Airtable/Notion : gardez vos données à jour et prêtes pour votre équipe chaque matin.
Cas d’usage :
- E-commerce : suivez quotidiennement les prix et les stocks des concurrents — ajustez vos prix instantanément.
- Ventes : recevez chaque semaine une nouvelle liste de leads depuis des annuaires ou des sites d’offres d’emploi.
- Immobilier : surveillez les nouvelles annonces ou les variations de prix toutes les heures — soyez le premier à agir.
Le scraping planifié vous permet de toujours travailler avec les dernières données — fini de naviguer à l’aveugle ou de courir après le retard.
À retenir : faire passer votre extraction de données à l’échelle avec les crawlers de listings
- Les données web structurées sont indispensables pour l’entreprise moderne. Les sociétés qui utilisent des crawlers de listings automatisés prennent des décisions plus rapides et plus intelligentes, avec un vrai retour sur investissement ().
- Des outils pilotés par l’IA comme Thunderbit rendent le crawling de listings accessible à tous. Pas de code, pas de modèles, pas de maintenance pénible — juste des résultats.
- L’extraction automatisée de listings débloque un avantage concurrentiel. De l’intelligence tarifaire à la génération de leads, les données dont vous avez besoin sont à quelques clics seulement.
- La surveillance continue devient la norme. Avec le scraping planifié, votre équipe travaille toujours sur des données à jour — prête à réagir, analyser et gagner.
- Se lancer est facile. Thunderbit propose un niveau gratuit généreux et des exports instantanés — vous pouvez donc l’essayer sur votre prochain projet de données sans aucun risque.
Prêt à reléguer la collecte manuelle de données au passé ? et voyez à quel point l’extraction automatisée et évolutive de listings peut être simple. Et si vous voulez aller plus loin, consultez le pour davantage de guides, de conseils et de cas d’usage concrets.
FAQ
1. Quelle est la différence entre un crawler de listings et un extracteur web général ?
Un crawler de listings se spécialise dans l’extraction de données structurées et répétitives (comme des produits ou des annonces immobilières) depuis des pages web, en gérant la pagination et les sous-pages à grande échelle. Les extracteurs web généralistes peuvent extraire n’importe quel type de données, mais ils demandent souvent plus de configuration manuelle et ne sont pas optimisés pour les grandes listes structurées.
2. Comment le crawler de listings piloté par l’IA de Thunderbit fait-il gagner du temps par rapport aux méthodes manuelles ?
L’IA de Thunderbit détecte automatiquement les champs, gère la pagination et peut visiter les sous-pages — transformant des heures de copier-coller manuel en quelques minutes d’extraction automatisée. Elle s’adapte aussi aux changements de site, ce qui vous évite de reconstruire votre flux de travail à chaque mise à jour.
3. Puis-je utiliser Thunderbit pour surveiller les prix ou les stocks des concurrents en temps réel ?
Absolument. Grâce au scraping planifié de Thunderbit, vous pouvez mettre en place une surveillance quotidienne ou horaire des listings, prix ou stocks des concurrents. Les données peuvent être exportées directement vers Google Sheets, Airtable ou Notion pour des tableaux de bord et alertes en direct.
4. Quels formats d’export Thunderbit prend-il en charge ?
Thunderbit vous permet d’exporter les données vers Excel, CSV, JSON, Google Sheets, Notion et Airtable. Les champs image sont téléversés vers Notion/Airtable pour un affichage correct, et tous les exports sont gratuits — même dans la version gratuite.
5. Ai-je besoin de compétences techniques pour utiliser Thunderbit dans l’extraction automatisée de listings ?
Pas du tout ! Thunderbit est conçu pour les utilisateurs métiers — il suffit d’installer l’extension, de cliquer sur « AI Suggest Fields » et vous êtes prêt à extraire des données. Aucun code, aucun modèle, aucune maintenance requise.
Vous voulez voir Thunderbit en action ? ou parcourez d’autres guides pratiques sur le . Bon crawling !
En savoir plus