

« Est-ce qu'on a le droit d'extraire des données sur les sites web ? » Dans les échanges avec les équipes commerciales, marketing ou opérationnelles, cette question revient plus souvent que toutes les autres. L'extraction web s'est glissée partout — génération de leads, veille concurrentielle, analyse de marché — et chacun aimerait une réponse tranchée. Le droit ne la donne pas. Un tribunal valide l'extraction de données publiques ; ailleurs, une décision qualifie la même pratique de collecte illicite. De quoi hésiter avant de se lancer.
Les chiffres, eux, ne laissent pas de place au doute : plus des deux tiers des entreprises s'appuient sur l'extraction web pour leurs analyses ou leurs projets IA, et 78 % des acteurs de l'e-commerce y recourent pour surveiller les prix. Mais des affaires très commentées, comme LinkedIn contre hiQ Labs, ont fait monter la pression. Comment exploiter la richesse des données web sans se retrouver dans un dossier juridique ? Ce guide passe en revue les règles, les points de conformité et les réflexes à adopter — et montre en quoi Thunderbit facilite une extraction conforme.
L'extraction de données web est-elle légale ? Ce que dit vraiment le droit
Implications juridiques de l'extraction web Découvrez les aspects légaux de l'extraction web et la manière de rester en conformité. Get Started Free
Autant l'énoncer d'emblée : la légalité d'une extraction dépend de ce que vous récupérez, de la façon dont vous procédez et du pays où vous vous trouvez. Aucun texte universel ne pose un « c'est autorisé » ou « c'est interdit » définitif. Le sujet se joue à la croisée de plusieurs corps de règles — lois anti-piratage, vie privée, droit d'auteur, conditions d'utilisation des sites (Thunderbit Blog).
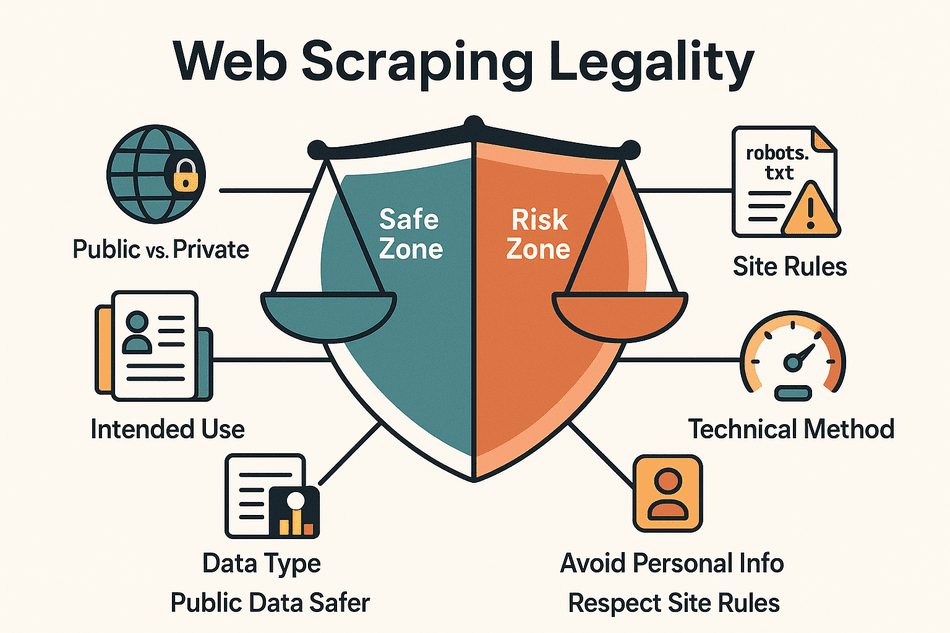
Cinq critères permettent de situer votre projet :
- Public ou privé : ce qui est accessible à tous, sans compte ni paiement, se récupère plus sereinement. Passer derrière une authentification, c'est entrer en zone sensible.
- Nature des données : les informations personnelles (noms, e-mails, profils sociaux) et les contenus protégés (articles, images) exposent bien plus que des données factuelles comme des prix, des fiches produits ou des annuaires d'entreprises.
- Finalité : un usage interne (analyse, recherche) pèse beaucoup moins lourd qu'une republication ou une revente.
- Règles du site : ignorer les conditions d'utilisation ou le robots.txt peut poser problème, y compris sur des données publiques.
- Méthode technique : rester à un rythme humain et ne franchir aucune protection (CAPTCHA, blocage d'IP) vous maintient sur un terrain plus sûr.
 (https://strapi.thunderbit.com/uploads/webscrapinglegalitysafevsriskzones_6ee3935a34.png)
La ligne directrice tient en une phrase : extraire des données publiques et non personnelles pour un usage interne est largement toléré dans de nombreux pays, mais les exceptions comptent — en particulier autour de la vie privée, du droit d'auteur et de l'intensité de l'extraction (Thunderbit Blog).
(https://strapi.thunderbit.com/uploads/webscrapinglegalitysafevsriskzones_6ee3935a34.png)
La ligne directrice tient en une phrase : extraire des données publiques et non personnelles pour un usage interne est largement toléré dans de nombreux pays, mais les exceptions comptent — en particulier autour de la vie privée, du droit d'auteur et de l'intensité de l'extraction (Thunderbit Blog).
Quelles réglementations encadrent l'extraction à travers le monde ?
 Un tour d'horizon des grands régimes juridiques s'impose.
Un tour d'horizon des grands régimes juridiques s'impose.
États-Unis : CFAA, droit d'auteur et contrats
- Computer Fraud and Abuse Act (CFAA) : cette loi anti-piratage interdit l'accès non autorisé à un système informatique. Les tribunaux ont toutefois considéré que l'extraction de sites publics ne l'enfreint pas, faute d'« autorisation » requise pour y accéder (California Lawyers Association).
- Décision de référence : dans hiQ Labs v. LinkedIn, la cour a jugé que l'extraction de profils publics ne violait pas la CFAA. LinkedIn conservait néanmoins la possibilité d'agir pour non-respect des conditions d'utilisation ou contrefaçon.
- Autres risques : une extraction trop agressive — comme le bot d'eBay v. Bidder's Edge et ses 100 000 requêtes par jour — expose à une action pour « atteinte à la propriété », c'est-à-dire pour avoir perturbé les serveurs d'un tiers (Wikipedia).
Union européenne : RGPD et droit des bases de données
- RGPD : le Règlement Général sur la Protection des Données couvre aussi les données personnelles rendues publiques. Collecter des informations identifiantes suppose une base légale — consentement ou intérêt légitime — et le respect de règles strictes.
- Directive sur les bases de données : l'UE protège également les bases en tant que telles. Extraire une « partie substantielle » d'une base structurée (par exemple l'ensemble des biens d'un portail immobilier) peut porter atteinte à ces droits, même quand les faits pris isolément ne sont pas protégés (Thunderbit Blog).
Royaume-Uni : UK GDPR et Data Protection Act
- UK GDPR : depuis le Brexit, le régime britannique reste calqué sur celui de l'UE. L'extraction de données publiques et non personnelles est généralement admise, mais la collecte de données personnelles demeure très encadrée.
- Computer Misuse Act : à l'image de la CFAA, ce texte sanctionne l'accès non autorisé.
Chine : PIPL et loi sur la sécurité des données
- Personal Information Protection Law (PIPL) : impose le consentement pour toute collecte de données personnelles. Extraire de telles données sur des sites chinois sans autorisation est formellement prohibé.
- Loi sur la sécurité des données : vise l'extraction qui lèse les détenteurs de données ou fausse la concurrence.
Autres régions
- Canada, Australie, APAC : la plupart de ces pays disposent de lois anti-piratage et de règles de confidentialité proches de celles de l'UE et du Royaume-Uni. Renseignez-vous systématiquement sur le droit local avant d'extraire.
En pratique, l'option la plus sûre reste l'extraction de données publiques et non personnelles pour un usage interne, doublée d'une vérification des règles en vigueur dans votre pays (Thunderbit Blog).
Comment vérifier que votre extraction reste conforme
Avant de démarrer, déroulez cette checklist :
- Lisez les conditions d'utilisation : si elles interdisent l'extraction, renoncez ou demandez une autorisation (Thunderbit Blog).
- Restez sur du public : rien derrière une authentification ou un paywall sans accord explicite.
- Consultez le robots.txt : rendez-vous sur
site.com/robots.txtpour repérer les zones fermées aux robots. Sans valeur juridiquement contraignante, mais c'est une marque de respect. - Écartez les données personnelles : ni noms, ni e-mails, ni informations sensibles sans base légale et plan de confidentialité.
- Ne recopiez pas de contenu créatif : tenez-vous-en aux faits et aux données brutes. Republier des articles, des images ou de longs extraits peut vous exposer.
- Préférez les API officielles quand elles existent : plus sûres, souvent plus stables.
- Restez mesuré : n'inondez pas les serveurs. Extrayez à un rythme humain, sans contourner les protections techniques.
- Documentez votre démarche : consignez ce que vous extrayez, quand et pourquoi. Précieux en cas de contrôle.
- Prévoyez de pouvoir arrêter : face à une mise en demeure, stoppez sur-le-champ et réévaluez.
L'approche conforme de Thunderbit : extraire en toute sécurité
Dès sa conception, Thunderbit a placé la conformité au centre du produit. Ce qui vous aide à rester dans les clous :
- Extraction via le navigateur : Thunderbit ne récupère que ce qui s'affiche dans votre navigateur — aucun appel API dissimulé, aucun contournement de connexion. Ce que vous ne voyez pas, Thunderbit ne l'extrait pas (Thunderbit Blog).
- Alertes intégrées : dès qu'une tentative vise un site très protégé, Thunderbit vous prévient — comme un référent conformité posté à côté de vous.
- Suggestions de champs par IA : l'IA analyse la page et ne propose que les champs pertinents, ce qui évite de collecter par inadvertance des données sensibles ou superflues (Thunderbit Blog).
- Rythme humain : en local comme dans le cloud, Thunderbit ajuste la cadence pour ne pas saturer les serveurs.
- Aucune donnée conservée sur nos serveurs : les données extraites vous appartiennent — Thunderbit n'en garde aucune copie, au bénéfice de la confidentialité.
- Exports pensés pour un usage interne : envoi direct vers Google Sheets, Excel, Airtable ou Notion.
- Sous-pages et pagination : Thunderbit parcourt les sites comme un internaute, en cliquant sur les pages et sous-pages, sans forcer l'accès.
- Extraction programmée raisonnable : planifiez des extractions à intervalles espacés, sans solliciter le site à l'excès.
- Interface multilingue : disponible en 34 langues, pour rendre la conformité accessible partout.
Autrement dit, Thunderbit « intègre la conformité au produit » et guide vers une extraction responsable, même sans formation juridique (Thunderbit Blog).
Essayez Thunderbit pour une extraction conforme
Extraire ou réutiliser : où se situe la frontière légale ?
 Extraire pour un usage interne n'a rien de comparable au fait de republier, revendre ou diffuser les données. La frontière se dessine nettement :
Extraire pour un usage interne n'a rien de comparable au fait de republier, revendre ou diffuser les données. La frontière se dessine nettement :
- Usage interne : exploiter des données publiques pour de l'analyse interne (prospection, veille tarifaire) est généralement sans danger, tant qu'aucune donnée personnelle n'entre en jeu.
- Redistribution ou revente : republier des données extraites — sur votre site, dans un produit, à la vente — peut déclencher une action pour droit d'auteur, droit des bases de données ou rupture de contrat.
- Droit d'auteur et bases de données : aux États-Unis, les faits ne sont pas protégés, mais la sélection et l'organisation des données peuvent l'être. Dans l'UE et au Royaume-Uni, extraire une « partie substantielle » d'une base peut enfreindre le droit sui generis.
- Fair use : le droit américain admet parfois cet usage équitable (commentaire, analyse), mais recopier de larges extraits ne s'y rattache presque jamais.
- Attribution : citez toujours vos sources en cas de publication, en gardant à l'esprit qu'une attribution ne rend pas légal ce qui ne l'était pas.
- Pas de vente de données brutes : revendre des jeux de données non retravaillés est particulièrement risqué. Servez-vous-en pour produire des analyses, pas comme un produit fini.
Le principe à retenir : réservez les données extraites à l'intelligence interne et à la décision. Si vous devez les partager, agrégez-les ou transformez-les, et vérifiez au préalable si une autorisation s'impose (Thunderbit Blog).
Trois affaires qui éclairent la gestion du risque juridique
Rien ne vaut l'expérience des autres pour saisir les enjeux de conformité.
LinkedIn vs hiQ Labs
- Contexte : hiQ Labs a extrait des profils publics LinkedIn pour analyser le turnover des salariés. LinkedIn a cherché à couper l'accès, mais la cour a estimé que l'extraction de données publiques n'enfreignait pas la CFAA.
- Enseignement : extraire du public est défendable aux États-Unis, à condition de rester vigilant sur les conditions d'utilisation et la vie privée (California Lawyers Association).
eBay vs Bidder's Edge
- Contexte : Bidder's Edge a aspiré massivement les annonces eBay — 100 000 requêtes par jour — au mépris des conditions et du robots.txt. La cour a ordonné l'arrêt pour « atteinte à la propriété ».
- Enseignement : même sur des données publiques, une extraction trop agressive ou contraire aux règles du site peut devenir illégale (Wikipedia).
Facebook (Meta) vs Power Ventures
- Contexte : Power Ventures a extrait des données Facebook avec l'accord des utilisateurs, puis a poursuivi son activité après le blocage décidé par Facebook. La cour y a vu un « accès non autorisé ».
- Enseignement : quand le propriétaire du site vous demande d'arrêter, la seule option est de cesser immédiatement, sous peine d'enfreindre la loi.
Des exemples de conformité qui tiennent
De nombreux comparateurs de prix européens opèrent en toute légalité : ils se limitent aux données factuelles, respectent les refus et n'aspirent jamais la base entière. L'absence de contentieux le confirme — respecter les données publiques, non personnelles, et les règles du site, ça marche.
Ce que Thunderbit apporte
Les alertes, les limites de fréquence et l'approche « navigateur » de Thunderbit auraient permis d'éviter bon nombre de ces faux pas, en signalant les sites à risque et en imposant par défaut une extraction respectueuse.
Auto-audit : votre projet d'extraction en entreprise est-il conforme ?
Une grille pratique pour passer votre prochain projet au crible :
- Les données sont-elles publiques ? (Aucune connexion requise)
- Que disent les conditions du site ? (Une clause anti-extraction ?)
- Avez-vous consulté le robots.txt ? (Une section ciblée interdite ?)
- Collectez-vous des données personnelles ? (Si oui, avec quel plan de confidentialité ?)
- Extrayez-vous une large part du site ? (Évitez d'aspirer toute la base)
- Quel est l'objectif ? (Usage interne = plus sûr ; réutilisation publique = plus risqué)
- L'extraction est-elle mesurée ? (Rythme humain, sans contournement technique)
- Avez-vous cherché une API ? (À privilégier si elle existe)
- Prêt à arrêter sur demande ? (Un plan en cas de mise en demeure)
- Comment stockez-vous les données ? (Accès limité, confidentialité assurée)
- Documentez-vous votre démarche ? (Pour la conformité)
Au moindre « non » ou au moindre doute, marquez une pause et clarifiez avant de poursuivre (Thunderbit Blog).
Un workflow conforme, étape par étape, avec Thunderbit
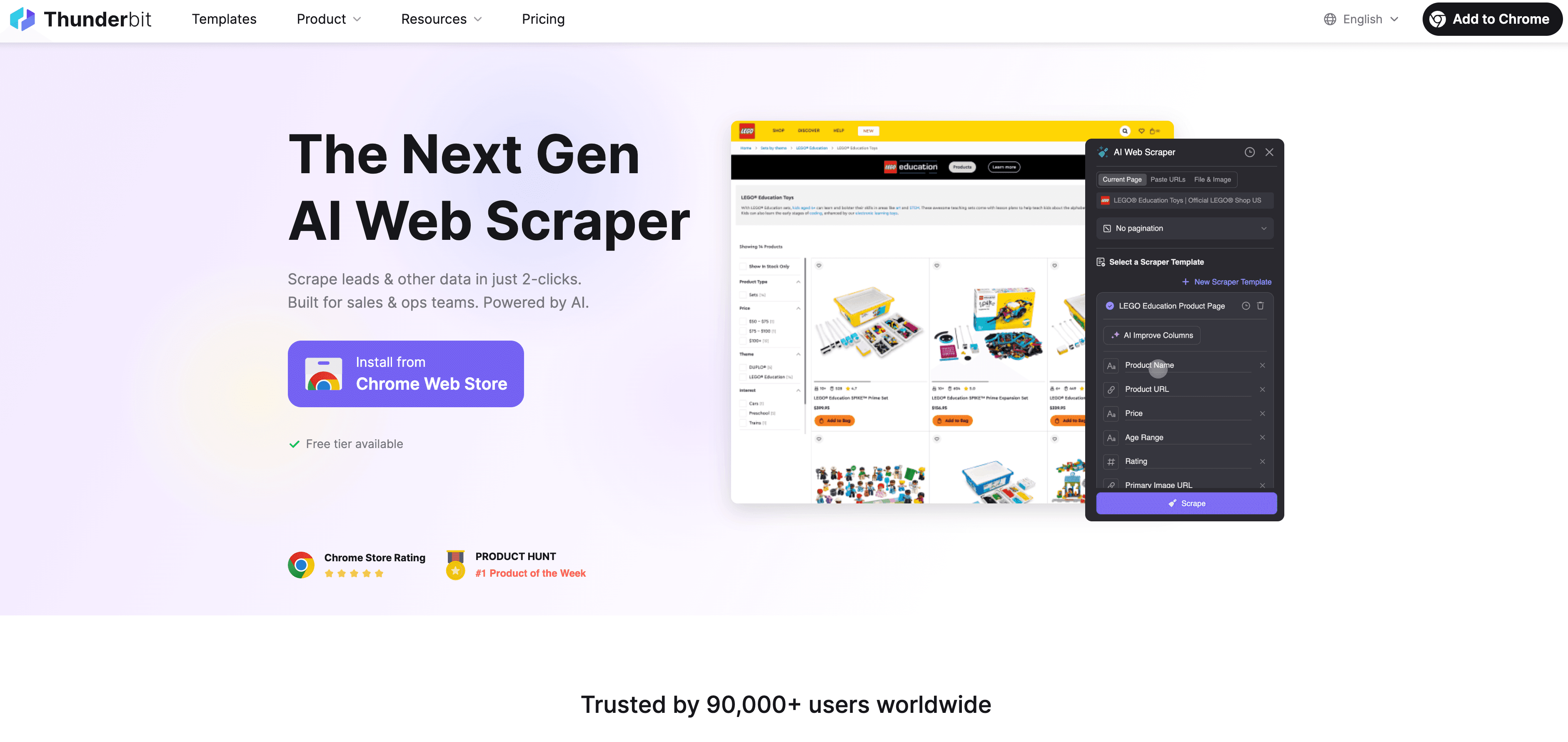 Voici comment se déroule une extraction conforme avec Thunderbit :
Voici comment se déroule une extraction conforme avec Thunderbit :
- Vérification préalable : consultez le robots.txt et les conditions d'utilisation. Aucune interdiction ? Vous pouvez avancer.
- Ouvrez Thunderbit : rendez-vous sur la page cible et lancez l'extension Chrome Thunderbit.
- Suggestions IA : laissez l'IA recommander les champs pertinents et non sensibles. Vérifiez qu'aucune donnée personnelle n'y figure sans base légale.
- Ajustez les champs : affinez colonnes et types de données — ne collectez que l'essentiel.
- Extraction : cliquez sur « Extraire ». Thunderbit collecte à un rythme humain, en respectant la structure du site.
- Sous-pages : au besoin, activez la fonction sous-pages pour enrichir les données — toujours sur des informations publiques.
- Export : envoyez les données directement vers Google Sheets, Excel, Airtable ou Notion, pour une analyse interne.
- Planification (facultatif) : programmez des extractions à intervalles espacés, jamais trop rapprochés.
- Documentation : gardez une trace de ce que vous avez extrait, quand et pourquoi.
À chaque étape, l'interface signale les points de conformité : vous n'avancez jamais à l'aveugle.
En savoir plus sur les fonctionnalités de conformité Thunderbit
En résumé : exploiter la valeur des données sans prendre de risques
L'extraction web nourrit réellement la croissance — sans pour autant être un Far West. Le cadre légal est touffu, et pourtant l'essentiel tient en quelques réflexes :
- Privilégiez l'extraction de données publiques et non personnelles pour un usage interne.
- Vérifiez toujours les conditions du site, le robots.txt et la législation avant de démarrer.
- N'extrayez ni données personnelles ni contenu protégé sans base légale et plan de confidentialité.
- Appuyez-vous sur des outils conformes comme Thunderbit pour cadrer votre démarche et réduire les risques.
- Documentez votre process et tenez-vous prêt à arrêter sur demande.
En faisant de la conformité un automatisme, vous profitez de la valeur des données web sans le tracas juridique. Pour mesurer à quel point une extraction conforme peut être simple, testez Thunderbit. Votre équipe juridique — et votre futur vous-même — vous remerciera.
Pour creuser l'extraction web, la conformité et l'automatisation, faites un détour par le blog Thunderbit.
Essayez l'Extracteur Web IA pour une extraction conforme Get Started Free
FAQ
1. Peut-on extraire des données de n'importe quel site ?
Pas dans tous les cas. Extraire des données publiques et non personnelles pour un usage interne est généralement admis dans bien des pays ; en revanche, récupérer des données personnelles, du contenu protégé ou des informations derrière une authentification peut s'avérer risqué, voire illégal. Vérifiez toujours les conditions du site et le droit local avant de commencer (Thunderbit Blog).
2. Quelle différence entre extraction et réutilisation ?
Extraire, c'est collecter les données ; réutiliser, c'est les publier, les vendre ou les diffuser. L'usage interne est nettement plus sûr. Republier ou vendre des données extraites peut entraîner une action pour droit d'auteur, droit des bases de données ou rupture de contrat (Thunderbit Blog).
3. En quoi Thunderbit aide-t-il à rester conforme ?
Thunderbit n'extrait que ce qui s'affiche dans votre navigateur, vous alerte sur les sites à risque, suggère des champs pertinents et non sensibles, et adapte la cadence pour ménager les serveurs. Il ne stocke pas vos données, et ses options d'export sont taillées pour un usage interne (Thunderbit Blog).
4. Que faire face à une mise en demeure ?
Interrompez aussitôt l'extraction et réévaluez le projet. Poursuivre après une demande expresse peut transformer une zone grise en infraction caractérisée aux lois anti-piratage ou au contrat (Thunderbit Blog).
5. Peut-on extraire des données personnelles si elles sont publiques ?
Pas sans base légale. Les lois sur la vie privée comme le RGPD ou la CCPA s'appliquent y compris aux données personnelles publiques. Il vous faudra un consentement ou un intérêt légitime solide, ainsi qu'un traitement responsable des données (Thunderbit Blog).
Ce guide a une vocation d'information et ne remplace pas un conseil juridique. Pour des projets complexes ou sensibles, consultez un avocat spécialisé en protection des données de votre juridiction.
Pour aller plus loin




