

Il y a quelques mois, l’un de nos utilisateurs m’a posé une question qui m’a fait interrompre ma gorgée de café : « Si je collecte les prix publics des produits sur Coupang, est-ce que je vais finir devant un tribunal coréen ? » Honnêtement, je n’avais pas de réponse toute faite — et la plupart des guides juridiques que j’ai trouvés en ligne non plus.
Cette question m’est restée en tête, parce que c’est la même que se posent discrètement, chaque semaine, des milliers d’acteurs du e-commerce, d’équipes commerciales et de fondateurs SaaS. Le marché mondial des services de web scraping a atteint environ 1,03 milliard de dollars US en 2024 et croît rapidement. Plus d’entreprises que jamais collectent des données web — et de plus en plus se demandent où se situent les limites légales en Corée. La Corée n’interdit pas le scraping de manière générale.
Mais quatre grands textes peuvent s’appliquer selon ce que vous extrayez, comment vous le faites et pourquoi. L’affaire phare que tout le monde cite est la décision Yanolja de la Cour suprême coréenne (2021Do1533, rendue le 12 mai 2022), qui a relaxé un outil de scraping concurrent sur le plan pénal — puis, dans une procédure civile distincte, a condamné la même société à environ 1 milliard de KRW de dommages-intérêts. Ce double résultat est la chose la plus importante à comprendre pour un non-juriste sur le droit coréen du scraping, et c’est le socle de ce guide. Pas besoin de diplôme de droit — seulement d’un cadre pratique d’évaluation du risque que vous pouvez vraiment utiliser.
Niveau : Débutant (aucune base juridique ou technique nécessaire)
Temps requis : ~15 minutes de lecture ; une référence utile dans la durée
Ce qu’il vous faut : Une compréhension de base du web scraping (si vous avez besoin d’un rappel, consultez notre article sur ce qu’est le web scraping)
Le web scraping est-il légal en Corée ? Réponse courte
Le web scraping en lui-même n’est pas illégal en Corée. C’est une technologie neutre — comme un navigateur web ou une formule de tableur. Les tribunaux coréens ont systématiquement mis l’accent non pas sur l’outil, mais sur les comportements liés à son utilisation.
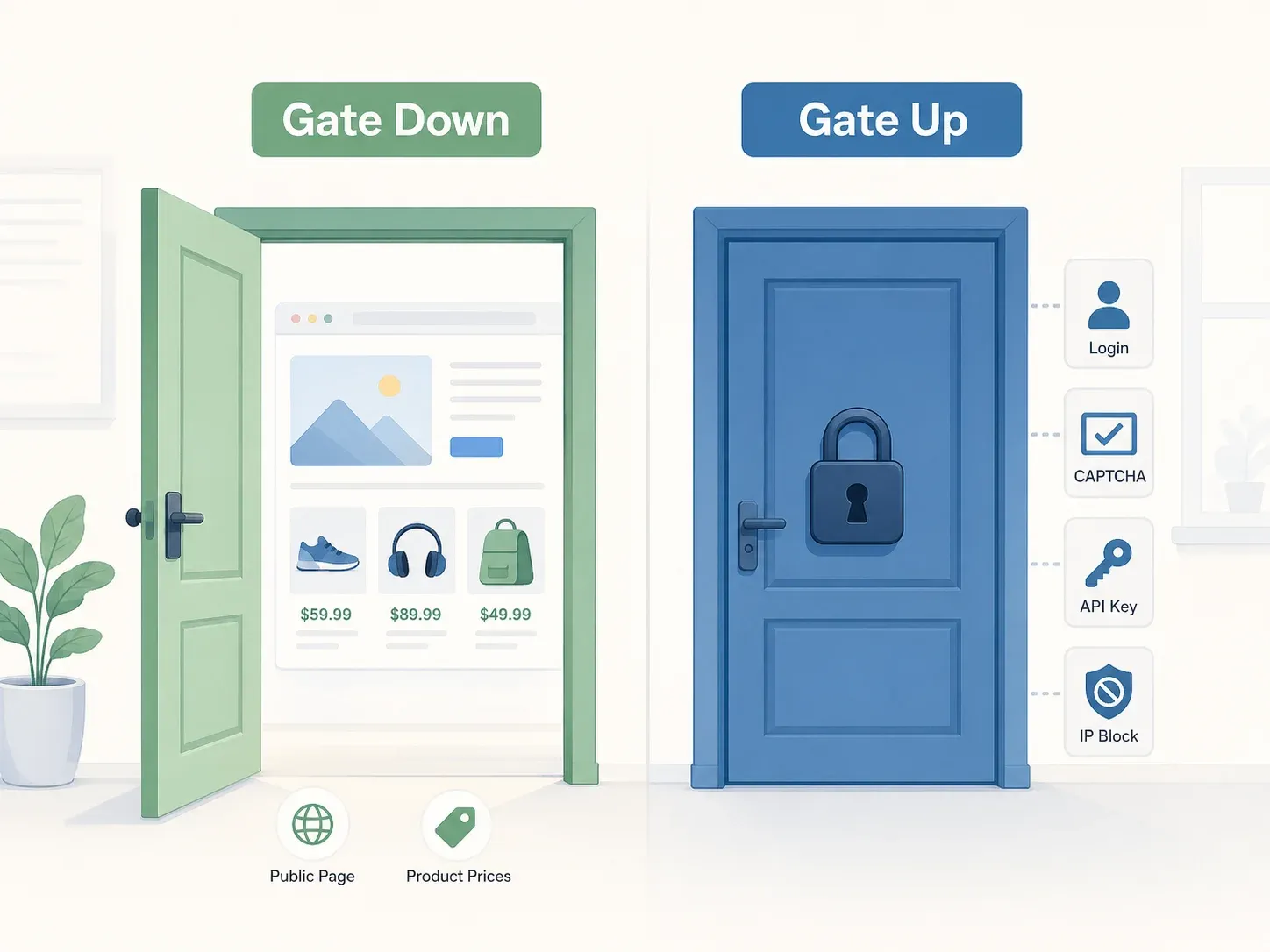
Le meilleur modèle mental vient de la décision Yanolja de la Cour suprême : le principe « porte ouverte vs porte fermée ». Si un site n’impose aucune restriction objective d’accès — pas de mur de connexion, pas de CAPTCHA, pas d’exigence de clé API, pas de blocage IP — la porte est « ouverte », et l’accès à des données librement accessibles n’est généralement pas une infraction pénale au titre de la loi coréenne sur les réseaux d’information et de communications (ICNA). La Cour a examiné précisément si les « mesures de protection, les conditions d’utilisation et d’autres circonstances objectivement révélées » restreignaient l’accès, et a constaté que le serveur API de Yanolja était librement accessible via l’application publique.
Mais « pas pénal » ne veut pas dire « sans risque ».
La responsabilité civile est une question totalement distincte. Vous pouvez échapper à des poursuites pénales tout en faisant l’objet d’une condamnation à un milliard de wons de dommages-intérêts. L’affaire Yanolja l’a démontré avec une clarté douloureuse.
Quatre lois coréennes peuvent s’appliquer au web scraping :
- ICNA (Information and Communications Network Act) — la règle du « défense d’entrer »
- Copyright Act — les droits du producteur de base de données
- PIPA (Personal Information Protection Act) — les règles de collecte des données personnelles
- UCPA (Unfair Competition Prevention Act) — le fourre-tout du « ne pas profiter gratuitement du travail d’autrui »
Le reste de ce guide relie ces lois à des scénarios concrets afin que vous puissiez déterminer où se situe réellement votre projet de scraping.
Le cadre de risque vert-jaune-rouge pour le web scraping en Corée
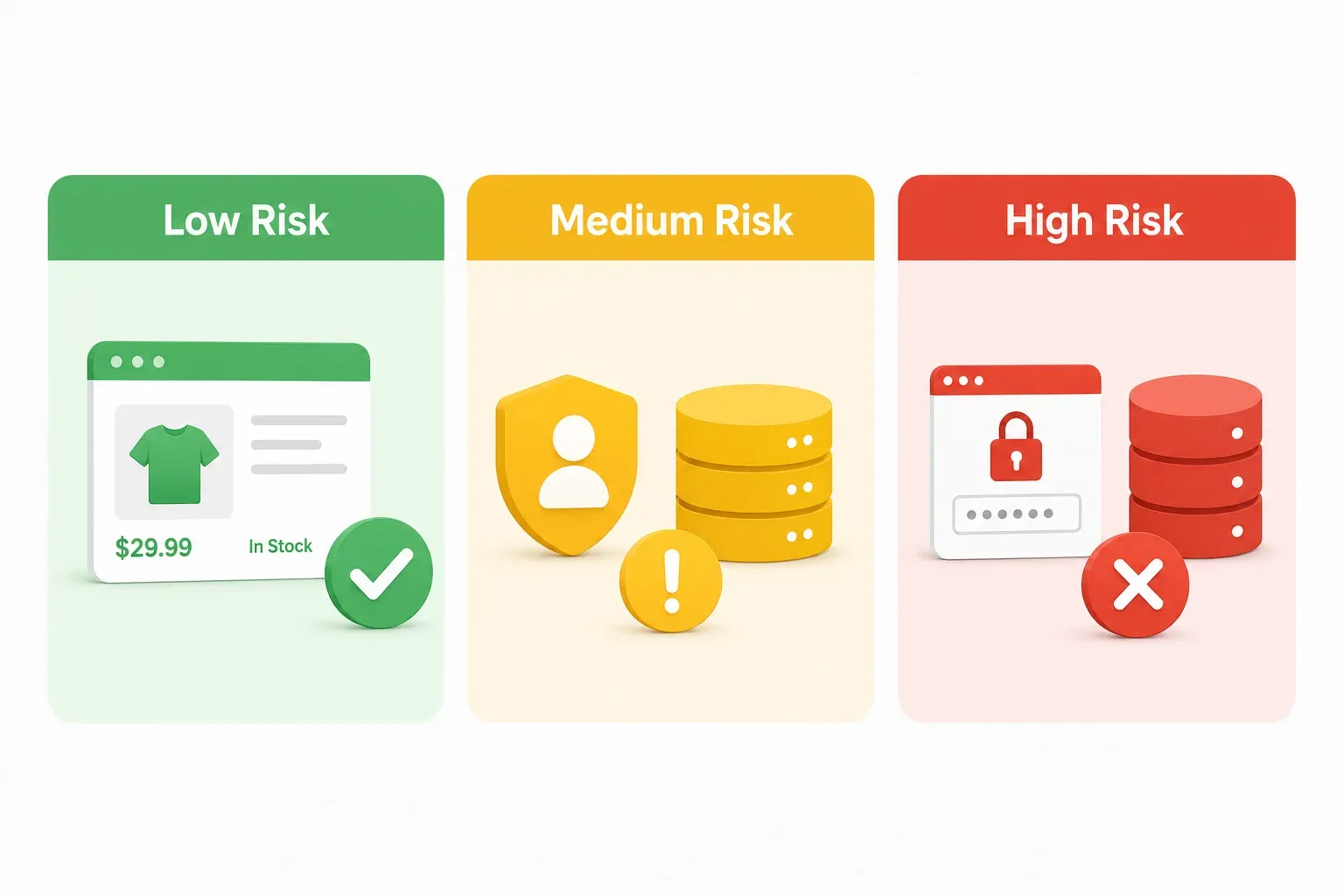
Tous les articles juridiques que j’ai trouvés sur le scraping en Corée donnent l’impression d’avoir été écrits pour des avocats. Si vous êtes responsable des opérations e-commerce ou fondateur SaaS, vous n’avez pas besoin d’une analyse statutaire de 40 pages — vous avez besoin d’un moyen rapide d’évaluer le risque avant de lancer un projet. Voyez cela comme un feu tricolore. Vert signifie avancez (avec la prudence habituelle). Jaune signifie ralentissez et regardez dans vos rétroviseurs. Rouge signifie stop, puis appelez un avocat.
Zone verte : scénarios de scraping à faible risque
| Scénario | Niveau de risque | Texte(s) clé(s) | Pourquoi |
|---|---|---|---|
| Extraction de fiches produits publiques (sans connexion, sans CAPTCHA) | 🟢 Faible | ICNA, Copyright Act | Décision Yanolja : pas de restriction d’accès = pas de violation de l’ICNA ; les données factuelles (prix, disponibilité) ne relèvent pas de l’expression créative |
| Extraction de prix publics à des fins d’analyse interne uniquement | 🟢 Faible | UCPA, Copyright Act | Données factuelles, périmètre limité, pas de redistribution concurrentielle |
| Collecte de faits non personnels et non protégés par le droit d’auteur depuis des pages publiques | 🟢 Faible | ICNA, Copyright Act | Aucun contournement de barrière d’accès ; les faits isolés ne sont pas protégés |
La décision pénale Yanolja sert de point d’ancrage à cette zone. La Cour suprême a conclu à l’absence d’intrusion au titre de l’ICNA, car le serveur API était librement accessible — les utilisateurs ordinaires pouvaient y accéder via l’application, avec ou sans adhésion, et aucune mesure de protection distincte ne bloquait l’accès à l’API.
Pour les utilisateurs de Thunderbit, c’est le scénario idéal. Si vous extrayez des pages e-commerce ou immobilières publiques en mode cloud scraping — en collectant les noms de produits, les prix, la disponibilité ou les métadonnées d’annonces tout en excluant les champs de données personnelles — vous évoluez généralement en zone verte. (Cela dit, « généralement » ne veut pas dire « toujours », et j’expliquerai les nuances ci-dessous.)
Essayez Thunderbit pour l’extraction de données publiques
Zone jaune : scénarios de scraping à risque moyen
| Scénario | Niveau de risque | Texte(s) clé(s) | Pourquoi |
|---|---|---|---|
| Extraction de données personnelles (noms, e-mails, numéros de téléphone), même depuis des pages publiques | 🟡 Moyen | PIPA, ICNA | La PIPA s’applique indépendamment du caractère public ; les modifications de 2023 ont durci les règles de consentement |
| Extraction de volumes importants pouvant constituer une « part substantielle » de la base de données d’un concurrent | 🟡 Moyen | Copyright Act, UCPA | Test quantitatif + qualitatif en droit coréen |
| Ignorer les signaux robots.txt | 🟡 Moyen | Preuve de mauvaise foi | Pas une infraction en soi, mais cela peut être retenu contre vous devant un tribunal |
| Extraire des données publiques puis les utiliser pour concurrencer directement la source | 🟡 Moyen | UCPA | Profiter gratuitement de l’investissement d’une autre plateforme |
Les données personnelles sont le principal déclencheur de la zone jaune.
Même si un numéro de téléphone ou une adresse e-mail est visible sur une page publique, la PIPA s’applique toujours. La réforme de 2023 de la PIPA a élargi les droits des personnes concernées et durci les exigences de consentement. Et en 2024, la Commission coréenne de protection des informations personnelles (PIPC) a publié des lignes directrices visant spécifiquement les informations personnelles accessibles publiquement dans le contexte de l’IA et de la collecte de données — précisant clairement que l’accessibilité publique ne vaut pas autorisation générale.
Le volume compte aussi. La Cour suprême dans l’affaire Yanolja a indiqué que des facteurs quantitatifs et qualitatifs permettent de déterminer si vous avez copié une « part substantielle » d’une base de données. Comparez la portion copiée à l’ensemble de la base, et demandez-vous si elle reflète l’investissement substantiel du producteur.
Zone rouge : scénarios de scraping à haut risque
| Scénario | Niveau de risque | Texte(s) clé(s) | Pourquoi |
|---|---|---|---|
| Extraction derrière un mur de connexion ou contournement des contrôles d’accès | 🔴 Élevé | ICNA art. 48 | « Porte fermée » = accès non autorisé ; risque pénal élevé |
| Contournement des CAPTCHA, bannissements IP ou systèmes de détection de bots | 🔴 Élevé | ICNA art. 48(4) | La modification de 2024 vise spécifiquement les outils/dispositifs de contournement |
| Copie et revente de la base de données complète d’un concurrent | 🔴 Élevé | Copyright Act (droits DB), UCPA | Reproduction substantielle + profit illégitime commercial |
| Collecte d’informations personnelles sans base légale à des fins de marketing/prospection | 🔴 Élevé | PIPA | Jusqu’à 5 ans / 50 millions de KRW d’amende ; sanctions administratives jusqu’à 3 % du chiffre d’affaires |
Un ajout de 2024 à l’ICNA — l’article 48(4) — interdit désormais spécifiquement d’installer, de transférer ou de distribuer des programmes ou dispositifs techniques contournant des « procédures normales de protection ou d’authentification » sans motif légitime.
Par ailleurs, une décision de la Cour suprême de novembre 2024 (2021Do5555) a confirmé qu’une intrusion non autorisée dans un réseau peut exister même sans destruction physique des mesures de protection. L’utilisation des identifiants d’une autre personne ou de commandes inappropriées pour contourner les limites d’accès suffit.
Les quatre lois coréennes applicables au web scraping
| Loi | Ce qu’elle protège | Quand elle s’applique aux scrapers |
|---|---|---|
| ICNA article 48 | Stabilité du réseau, autorisation d’accès | Contournement de connexion, CAPTCHA, authentification, blocages IP, limites de clé API |
| Copyright Act (art. 93) | Œuvres créatives + droits du producteur de base de données | Copie de contenus expressifs, d’images, ou de tout ou partie substantielle d’une base de données |
| PIPA | Informations personnelles, droits des personnes concernées | Collecte de noms, numéros de téléphone, e-mails, identifiants — même depuis des pages publiques |
| UCPA (art. 2(1)(k) et (m)) | Concurrence loyale, données à valeur commerciale | Profiter de l’investissement en données d’une autre plateforme pour votre propre activité concurrente |
ICNA article 48 : la règle du « défense d’entrer »
L’article 48(1) de l’ICNA dispose que nul ne doit pénétrer dans un réseau d’information et de communications « sans autorité d’accès légitime ou au-delà de l’autorité d’accès autorisée ». En termes de scraping : si le site comporte des restrictions d’accès que vous contournez, vous êtes en infraction. S’il n’y a pas de restrictions — page publique, aucune connexion — vous êtes probablement en règle.
La sanction encourue pour violation va jusqu’à cinq ans d’emprisonnement ou une amende pouvant atteindre 50 millions de KRW, en vertu de l’article 71 de l’ICNA.
Une nuance mérite d’être soulignée : la Cour suprême coréenne a toujours traité les restrictions des conditions d’utilisation comme différentes des restrictions d’accès. Les conditions de l’application Yanolja limitaient la réutilisation commerciale et interdisaient les programmes automatisés qui chargeaient le serveur, mais la Cour a estimé que ces clauses ne restreignaient pas objectivement l’accès au serveur API lui-même.
Copyright Act : droits du producteur de base de données
La loi coréenne sur le droit d’auteur protège séparément les producteurs de bases de données, indépendamment du droit d’auteur portant sur des contenus individuels. En vertu de l’article 93, reproduire « la totalité ou une partie substantielle » d’une base de données est illégal — même si les données individuelles sont des faits publics.
Le test est à la fois quantitatif (quelle proportion avez-vous copiée par rapport à l’ensemble ?) et qualitatif (la portion copiée reflète-t-elle l’investissement substantiel du producteur dans la constitution, la vérification ou la maintenance de la base ?). La copie répétée ou systématique de petites portions peut aussi être retenue si elle produit en pratique le même résultat que la copie d’une part substantielle.
Sanction pour atteinte aux droits du producteur de base de données : jusqu’à trois ans ou 30 millions de KRW en vertu de l’article 136(2)(3). Les dommages-intérêts légaux prévus à l’article 125-2 peuvent atteindre 10 millions de KRW par œuvre, ou 50 millions de KRW par œuvre en cas d’atteinte intentionnelle à but lucratif.
PIPA : Personal Information Protection Act
La PIPA encadre la collecte des données personnelles — noms, coordonnées, identifiants — même lorsqu’elles sont visibles publiquement. La réforme de 2023 a été importante : elle a élargi les droits des personnes concernées, durci les exigences de consentement, introduit des règles sur la prise de décision automatisée et fixé des sanctions administratives pouvant atteindre 3 % du chiffre d’affaires total pour certaines violations.
Les lignes directrices 2024 du PIPC sur l’IA et les données publiques mentionnent directement les données obtenues par « web crawling et scraping » dans le contexte des informations personnelles accessibles publiquement. Les lignes directrices précisent que l’intérêt légitime peut, dans certains contextes, servir de base, mais qu’il faut une mise en balance, des garanties, la protection des droits et une gouvernance appropriée.
Et la tendance se durcit. En mars 2026, la presse coréenne a fait état d’un amendement de la PIPA portant les sanctions maximales pour les infractions graves et répétées liées aux fuites de données jusqu’à 10 % du chiffre d’affaires, avec entrée en vigueur plus tard en 2026.
UCPA : le « fourre-tout » de la concurrence déloyale
L’UCPA est le texte qui a piégé GC Company dans l’affaire civile Yanolja. La loi actuelle contient deux dispositions pertinentes :
- Article 2(1)(k) : vise les utilisations déloyales de données techniques ou commerciales accumulées et gérées électroniquement qui ne sont pas secrètes
- Article 2(1)(m) : le fourre-tout plus large visant l’utilisation, pour son propre business et sans autorisation, des résultats d’autrui obtenus grâce à un investissement ou des efforts substantiels, contrairement aux pratiques commerciales loyales
Ces dispositions de l’UCPA relèvent uniquement du civil — aucune sanction pénale — mais elles peuvent entraîner des injonctions en vertu de l’article 4, des dommages-intérêts en vertu de l’article 5, et même des dommages-intérêts triples dans certains cas intentionnels visés par l’article 14-2. L’affaire civile Yanolja a abouti à environ 1 milliard de KRW sur cette base.
L’affaire Yanolja : pourquoi vous pouvez gagner au pénal mais perdre au civil
C’est l’affaire que tout utilisateur professionnel en Corée doit comprendre. Je vais la raconter comme une seule histoire, parce que c’est ainsi qu’elle s’est déroulée — et parce que l’issue divergente en est précisément le point central.
Ce qui s’est passé : GC Company a scrapé les données voyage de Yanolja
GC Company exploitait une plateforme de voyage en ligne concurrente. L’entreprise a développé un crawler interne qui accédait au serveur API de l’application Baro Reservation de Yanolja, en apprenant les URL de l’API et les commandes de requête, puis en les envoyant au serveur. Le scraper collectait des informations d’hébergement — noms de partenaires, adresses, prix, disponibilités et images. GC Company a utilisé ces données en interne pour le marketing et le positionnement concurrentiel.
Yanolja a déposé à la fois une plainte pénale et une action civile.
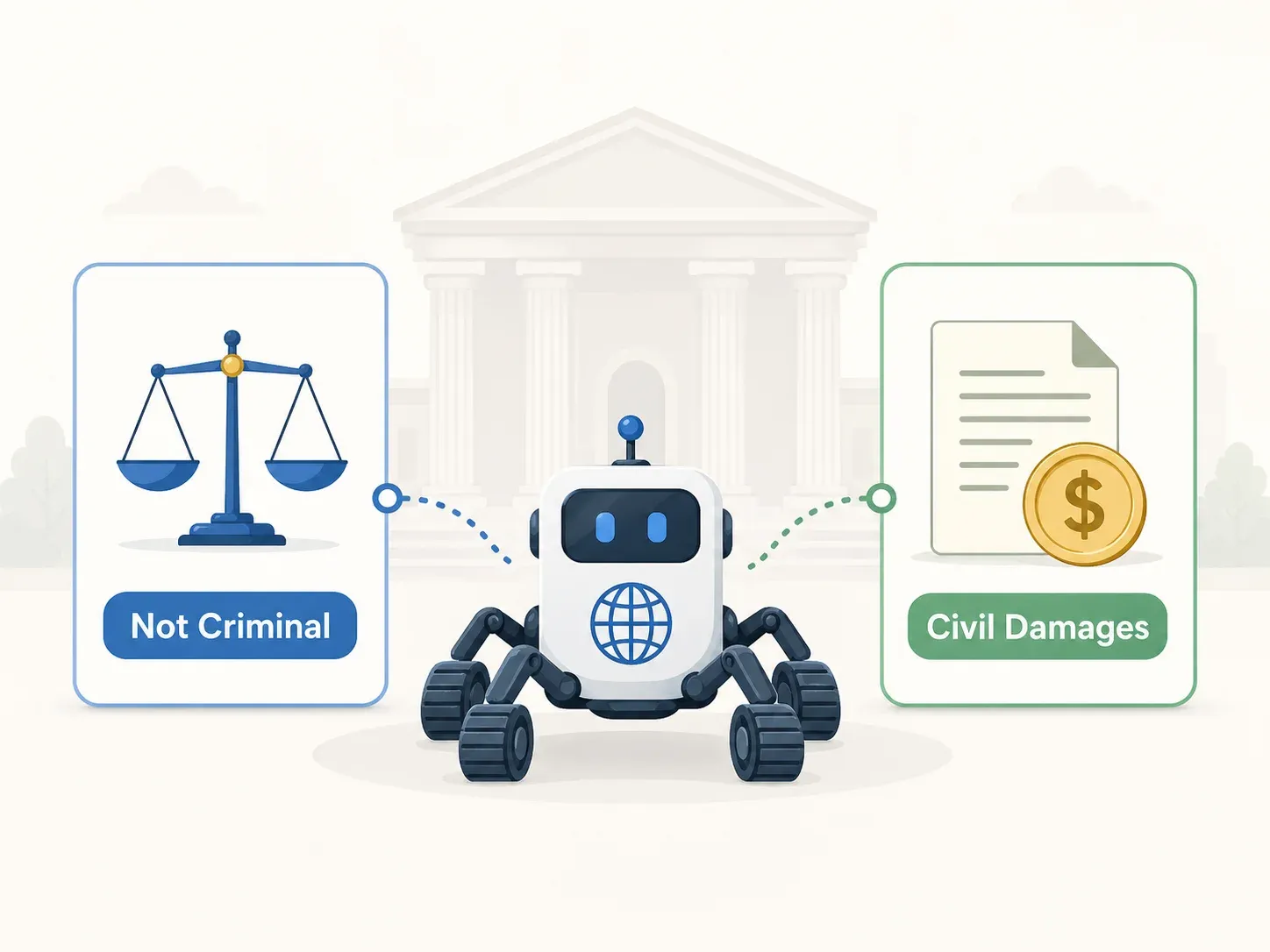
Verdict pénal : non coupable sur tous les chefs (Cour suprême 2021Do1533)
La Cour suprême a confirmé l’acquittement prononcé en appel le 12 mai 2022 sur les trois chefs :
- ICNA article 48 (intrusion) : aucune restriction d’accès n’existait. Le serveur API était accessible publiquement via le navigateur et l’application mobile. Aucun blocage technique n’était en place. Les clauses des conditions d’utilisation limitaient l’usage, pas l’accès.
- Copyright Act (droits du producteur de base de données) : les défendeurs n’ont pas reproduit « la totalité ou une partie substantielle » de la base. Les données copiées étaient déjà connues du public, et les éléments du dossier ne prouvaient pas que la portion copiée reflétait l’investissement substantiel de Yanolja.
- Code pénal, article 314 (entrave aux activités) : aucune perturbation réelle du fonctionnement du serveur API de Yanolja n’a été prouvée. Aucune modification des données. Aucune intention coupable d’entrave aux affaires.
La règle à retenir est formulée ainsi : les restrictions d’accès doivent être appréciées à travers les « mesures de protection, les conditions d’utilisation et d’autres circonstances objectivement révélées ». Si la porte est ouverte, passer par cette porte n’est pas une intrusion.
Verdict civil : 1 milliard de KRW de dommages-intérêts au titre de l’UCPA
C’est là que l’histoire bascule. Le tribunal de district central de Séoul — puis la Cour d’appel de Séoul (affaire 2021Na2034740, arrêt du 25 août 2022) — ont jugé que GC Company avait violé la clause générale de l’UCPA. Le tribunal a accordé environ 1 milliard de KRW (~800 000 USD) de dommages-intérêts compensatoires et ordonné l’arrêt de toute duplication ultérieure des données.
Le raisonnement : la base de données d’hébergements de Yanolja avait une valeur commerciale et reflétait un investissement substantiel — collecte, vérification et mise à jour des données d’hébergement. GC Company a profité gratuitement de cet investissement. La décision civile a été définitivement arrêtée au niveau de la Cour d’appel de Séoul.
Conclusion pratique : l’acquittement pénal n’équivaut pas à une sécurité civile
C’est la leçon la plus contre-intuitive du droit coréen du scraping. Un accès licite au pénal n’a pas immunisé contre un usage commercialement déloyal. « Puis-je être poursuivi au pénal ? » et « Puis-je être attaqué en justice ? » sont deux questions différentes, avec des réponses potentiellement opposées.
Pour les utilisateurs professionnels : même si votre méthode de scraping se situe clairement en zone verte sur le plan pénal, l’usage que vous faites des données — surtout s’il concurrence directement la source — détermine votre risque civil.
Corée vs États-Unis vs UE : comparaison des règles de web scraping
Je n’ai trouvé aucun autre guide qui mette cela dans un seul tableau — ce qui est surprenant vu le nombre d’entreprises qui scrapent au-delà des frontières.
| Dimension | Corée du Sud | États-Unis | UE / EEE |
|---|---|---|---|
| Texte central | ICNA art. 48, Copyright Act | CFAA (18 U.S.C. §1030), lois des États | RGPD, directive Bases de données (96/9/CE) |
| Affaire phare | Yanolja c. GC Company (Cour suprême 2021Do1533, 2022) | hiQ c. LinkedIn (9e cir., 2022), Van Buren c. US (2021) | Ryanair c. PR Aviation (CJUE C-30/14, 2015) |
| Scraping de données publiques | Légal s’il n’existe pas de barrière objective d’accès (« porte ouverte ») | Légal selon le raisonnement hiQ (données publiques) ; Van Buren a limité le CFAA | Dépend des droits sur la base, du contrat, du droit d’auteur, du RGPD, et du droit national |
| Règles sur les données personnelles | PIPA (modifiée en 2023) — consentement ou base légale | Sectoriel : CCPA (Californie), lois sur la vie privée des États | RGPD — consentement strict / intérêt légitime ; amende max 20 M€ ou 4 % du chiffre d’affaires mondial |
| Violation des CGU = crime ? | Non (les tribunaux considèrent que CGU ≠ violation de l’ICNA) | Non (Van Buren 2021 : CGU ≠ CFAA) | Généralement non, mais rupture contractuelle possible (Ryanair) |
| Protection des bases de données | Droits du producteur de base de données au titre du Copyright Act | Pas de droit fédéral général sur les bases de données | Droit sui generis sur les bases de données |
| Sanction pénale maximale | Jusqu’à 5 ans / 50 M KRW (ICNA) | Jusqu’à 10 ans / 250 k$ (CFAA) | Variable selon l’État membre |
Différences clés qui comptent pour votre activité
- La Corée n’a pas d’exception générale de text and data mining (TDM) comme la directive DSM de l’UE. Si vous entraînez des modèles d’IA sur des données coréennes scrapées, vous ne bénéficiez pas d’une exemption légale automatique.
- La clause générale de l’UCPA en Corée est plus large et moins prévisible que le droit américain de la concurrence déloyale. L’issue civile de Yanolja serait beaucoup plus difficile à reproduire sous le droit américain.
- Les trois juridictions s’accordent : la seule violation des Conditions d’utilisation n’est pas une infraction pénale.
- La protection des bases de données en Corée est statutaire (comme dans l’UE), alors que les États-Unis n’ont pas de droit fédéral général sur les bases de données. Cela donne aux plateformes coréennes davantage d’outils civils.
- Si vous scraperez au-delà des frontières, la loi la plus stricte applicable gouverne. Un projet touchant des données coréennes, américaines et européennes doit satisfaire les trois régimes.
Scénarios sectoriels : le web scraping est-il légal en Corée pour votre activité ?
Le profil de risque varie fortement selon le secteur, et aucun guide que j’ai trouvé ne relie le droit coréen du scraping à des verticales précises. J’ai donc recollé les pièces moi-même.
E-commerce : suivi des prix et données produits

Extraire les prix publics de produits sur Coupang, Gmarket ou 11Street est l’exemple le plus propre de la zone verte — limitez-vous aux champs factuels (prix, disponibilité, nom du produit), évitez les zones réservées à la connexion, ne contournez pas les blocages techniques, et utilisez les données en interne pour le benchmarking.
Le risque augmente lorsque vous extrayez les descriptions de produits (contenu créatif → droit d’auteur), les coordonnées des vendeurs (PIPA), les images (droit d’auteur) ou un catalogue entier (droits du producteur de base de données + UCPA).
Je n’ai pas trouvé de grande action coréenne en scraping e-commerce comparable à Yanolja. Le précédent le plus développé concerne le voyage et le recrutement — mais l’absence de procès ne signifie pas l’absence de risque.
Le scheduled scraper de Thunderbit et son mode de scraping cloud sont conçus précisément pour ce type d’usage : vérifications récurrentes des prix et des stocks sur des pages publiques, avec AI Suggest Fields qui vous permet de sélectionner les colonnes souhaitées et d’exclure les champs de données personnelles.
Immobilier : annonces de biens
L’immobilier se situe naturellement en zone jaune. Les annonces sur des plateformes comme Zigbang ou Naver Real Estate mélangent données factuelles (prix, surface, quartier) et noms d’agents, numéros de téléphone de bureaux, numéros mobiles, photos et bases de données de plateforme curatées.
L’extraction des détails publics d’un bien peut être moins risquée. Mais la collecte des colonnes de contact des agents déclenche immédiatement la PIPA — et l’extraction de toutes les annonces d’une région commence à ressembler à une copie substantielle de base de données.
Atténuation du risque : exclure les colonnes personnelles, réduire le périmètre géographique, documenter une finalité commerciale légitime, respecter les limites de fréquence, et éviter de reproduire un service concurrent d’annonces. L’IA de Thunderbit peut être configurée pour n’extraire que les champs immobiliers dont vous avez besoin — prix, mètres carrés, localisation — tout en ignorant les données de contact personnelles.
Recrutement : offres d’emploi
Le recrutement est le secteur à haut risque, sans ambiguïté. La Corée a un précédent direct : JobKorea c. Saramin. Saramin a extrait la base d’offres d’emploi de JobKorea et a été reconnu responsable d’une atteinte aux droits sur la base de données et d’une concurrence déloyale. Les données de recrutement combinent souvent investissement de plateforme (annonces curées et vérifiées), copie massive de base de données, et informations personnelles ou coordonnées de recruteurs.
Ma recommandation : évitez en général de scraper une plateforme d’emploi concurrente pour construire ou enrichir une base d’offres rivale. Si le cas d’usage est limité, faites relire le projet par un juriste avant la collecte, minimisez le volume, supprimez les contacts personnels et ne redistribuez pas les résultats.
Référence complète des sanctions : ce que vous risquez si le web scraping tourne mal en Corée
| Texte coréen | Type de violation | Sanction pénale maximale | Recours civil/admin maximal | Changement clé 2023–2026 |
|---|---|---|---|---|
| ICNA art. 48 | Accès non autorisé / entrave | 5 ans / 50 M KRW d’amende | Dommages-intérêts + injonction | 2024 : ajout de l’art. 48(4) visant les outils de contournement |
| Copyright Act (droits DB, art. 93) | Reproduction substantielle d’une base de données | 3 ans / 30 M KRW d’amende | Dommages-intérêts légaux jusqu’à 50 M KRW/œuvre (intentional for-profit) | — |
| PIPA | Collecte illicite de données personnelles | 5 ans / 50 M KRW d’amende | Sanction administrative jusqu’à 3 % du chiffre d’affaires total ; action collective possible | Réforme 2023 ; ligne directrice 2024 sur l’IA et les données publiques ; tendance 2026 vers 10 % pour les fuites répétées |
| UCPA art. 2(1)(k)/(m) | Acquisition / utilisation déloyale de données | Civil uniquement (pas de pénal pour la clause générale) | Dommages-intérêts + injonction ; dommages triples dans certains cas intentionnels | Loi-cadre sur les données 2022 : dispositions renforcées |
| Code pénal art. 314 | Entrave commerciale par moyens techniques | 5 ans / 15 M KRW d’amende | — | Yanolja : aucune perturbation réelle prouvée |
Le point crucial : les voies pénale et civile fonctionnent indépendamment. Vous pouvez être exposé aux deux simultanément — et gagner l’une tout en perdant l’autre.
Votre checklist de conformité en 10 points pour le web scraping en Corée
Voici dix questions oui/non à passer en revue avant de lancer un projet de scraping. Imprimez-les, ajoutez-les à vos favoris, scotchez-les à votre écran — tout ce qui fonctionne.
- Le site cible ne nécessite-t-il aucune connexion pour accéder aux données voulues ? Si une connexion, un jeton ou un compte est nécessaire, le risque bascule nettement vers l’article 48 de l’ICNA.
- N’existe-t-il aucune restriction technique d’accès ? Les CAPTCHA, blocages IP, clés API, limites de requêtes et murs anti-bots sont des signaux forts de zone rouge.
- Avez-vous examiné le fichier robots.txt du site ? Il n’est pas juridiquement contraignant en soi dans la jurisprudence coréenne, mais il constitue une preuve utile des attentes du site et de votre bonne foi.
- Collectez-vous des données personnelles ? Si des noms, numéros de téléphone, e-mails, identifiants ou coordonnées individuelles sont en périmètre, une analyse PIPA est nécessaire.
- Copiez-vous une « part substantielle » de la base de données du site ? Posez-vous des questions quantitatives et qualitatives — combien, et la portion copiée reflète-t-elle l’investissement de la source ?
- Avez-vous défini votre finalité ? L’analyse interne est moins risquée que la redistribution ou la création d’une base concurrente. (Mais Yanolja montre qu’un usage concurrent en interne n’est pas un bouclier total.)
- Avez-vous documenté par écrit votre finalité commerciale légitime ? La documentation aide dans la mise en balance de l’intérêt légitime au titre de la PIPA et comme preuve de bonne foi.
- Avez-vous supprimé ou anonymisé les champs de données personnelles avant stockage/utilisation ? L’exclusion des coordonnées fait souvent sortir le scraping immobilier, le recrutement et les annuaires du schéma PIPA le plus dangereux.
- Utilisez-vous des intervalles de requêtes raisonnables ? Évitez la surcharge serveur — les risques liés à l’article 314 du Code pénal et à l’article 48(3) de l’ICNA augmentent lorsque le scraping perturbe le service.
- Avez-vous consulté un conseil juridique coréen pour les projets à fort volume, commerciaux ou transfrontaliers ? Le droit coréen, plus le RGPD ou les lois américaines sur la vie privée / l’accès informatique, peuvent tous s’appliquer.
⚠️ Avertissement : cette checklist sert d’orientation, pas de conseil juridique. Consultez toujours un avocat local en Corée pour les situations spécifiques.
Comment Thunderbit vous aide à scraper des sites coréens de manière responsable
Transparence totale : je travaille dans l’équipe marketing de Thunderbit. Mais je pense sincèrement que l’adéquation produit-réglementation est utile ici, et pas seulement comme argument commercial.
Thunderbit est conçu pour les cas d’usage de la zone verte décrits dans cet article : extraire des données publiquement accessibles sans connexion requise. Voici comment certaines fonctionnalités s’alignent sur le cadre de conformité :
- Mode de scraping cloud pour les sites publics — pas besoin de connexion, pas de session locale requise, et respect du périmètre d’accès public. Cela s’aligne sur le principe Yanolja de la « porte ouverte ».
- AI Suggest Fields vous permet de définir exactement quelles colonnes de données extraire. Vous avez besoin des prix et de la disponibilité, mais pas des numéros de téléphone des vendeurs ? Il suffit d’exclure les colonnes personnelles. C’est le moyen le plus simple d’éviter les déclencheurs PIPA.
- Scheduled scraper pour des contrôles récurrents des prix, stocks ou annonces à intervalles raisonnables — pas besoin de marteler un serveur avec des requêtes constantes.
- Exportation gratuite des données vers Excel, Google Sheets, Airtable et Notion pour les workflows d’analyse interne.
- Scraping des sous-pages pour enrichir les données d’annonces publiques (par exemple en ouvrant les pages individuelles de produits pour les spécifications) sans accéder à des zones réservées à la connexion.
- Adaptation IA de la mise en page — le scraper relit la structure du site à chaque exécution, s’adaptant aux changements de mise en page sans sélecteurs figés fragiles.
Thunderbit prend en charge l’utilisation multilingue dans des dizaines de langues, ce qui est important pour les équipes travaillant avec des sites en coréen. Vous pouvez l’essayer gratuitement via l’extension Chrome Thunderbit.
Aucun outil n’élimine le risque juridique. Mais une configuration responsable — pages publiques, données factuelles, champs personnels exclus, intervalles raisonnables — vous maintient dans le cadre de conformité décrit dans cet article.
Points clés à retenir sur la légalité du web scraping en Corée
Cinq choses à garder en tête :
- La technologie de web scraping en elle-même est légale en Corée. La Cour suprême l’a confirmé dans l’affaire Yanolja.
- Le risque dépend de la méthode d’accès (porte ouverte vs porte fermée), du type de données (personnelles vs factuelles) et de l’usage (interne vs redistribution concurrentielle).
- Acquittement pénal ≠ sécurité civile. L’affaire Yanolja prouve que vous pouvez éviter des poursuites pénales tout en faisant face à des dommages-intérêts d’un milliard de wons.
- Lorsque vous scrapez des données publiques, non personnelles et factuelles pour un usage interne sans barrière d’accès, vous êtes généralement dans la zone sûre. Mais « généralement » a un poids — le périmètre, le volume et la finalité comptent tous.
- Consultez toujours un conseil juridique coréen pour les projets de grande ampleur ou commerciaux. Cet article est destiné à l’orientation, pas au conseil juridique.
Si vous souhaitez commencer à scraper des sites coréens de manière responsable, le plan gratuit de Thunderbit vous permet de tester le workflow à petite échelle. Pour en savoir plus sur le fonctionnement du scraping assisté par IA en pratique, consultez nos guides sur le web scraping IA et le web scraping sans coder. Et si vous voulez voir l’outil en action, notre chaîne YouTube propose des démonstrations pour des cas d’usage courants.
FAQ
1. Est-il légal de scraper des données accessibles publiquement en Corée ?
En général oui sur le plan pénal — selon la décision de la Cour suprême dans l’affaire Yanolja, l’accès à des données sur un site sans restriction objective d’accès ne viole pas l’ICNA. Une responsabilité civile au titre de l’UCPA ou du Copyright Act peut toutefois subsister, selon le volume, l’investissement de la source et votre usage commercial des données.
2. Puis-je être poursuivi en Corée pour web scraping même si ce n’est pas pénal ?
Oui. Les voies pénale et civile sont indépendantes. GC Company a été acquittée de toutes les accusations pénales mais condamnée à payer environ 1 milliard de KRW de dommages-intérêts civils au titre de la clause générale de l’UCPA. Un acquittement pénal n’offre aucune protection contre une action civile.
3. La violation des Conditions d’utilisation d’un site rend-elle le scraping illégal en Corée ?
Les tribunaux coréens ont toujours considéré que la seule violation des CGU ne constituait pas une infraction pénale au titre de l’ICNA — la Cour a distingué entre restriction de l’usage (CGU) et restriction de l’accès (barrières techniques). Cela dit, une violation des CGU peut toujours étayer une action civile en rupture de contrat ou servir de preuve de mauvaise foi dans une analyse de concurrence déloyale.
4. Comment le droit coréen du web scraping se compare-t-il à celui des États-Unis ?
Les deux juridictions protègent le scraping de données publiques (Yanolja en Corée, hiQ c. LinkedIn aux États-Unis) et toutes deux considèrent que la simple violation des CGU n’est pas une infraction pénale (Van Buren aux États-Unis). La différence clé : la Corée dispose d’une protection statutaire plus forte des bases de données et d’une clause générale de concurrence déloyale plus large que les États-Unis, qui n’ont pas de droit fédéral général sur les bases de données. Les plateformes coréennes disposent donc de davantage d’outils civils contre les scrapers.
5. Que se passe-t-il si je scrap des données personnelles sur des sites coréens ?
La PIPA s’applique que l’information soit visible publiquement ou non. La collecte d’informations personnelles — noms, numéros de téléphone, e-mails — sans consentement ni autre base légale constitue une violation. L’amendement de 2023 de la PIPA a renforcé ces protections, et la ligne directrice du PIPC de 2024 sur les informations personnelles accessibles publiquement traite spécifiquement du web crawling et du scraping. Les sanctions peuvent aller jusqu’à 5 ans d’emprisonnement, 50 millions de KRW d’amende, et des sanctions administratives pouvant atteindre 3 % du chiffre d’affaires total.
Essayez Thunderbit pour un web scraping responsable Get Started Free
En savoir plus




