
Les robots d’exploration web sont les héros discrets d’Internet. Chaque fois que vous cherchez une nouvelle recette, consultez les derniers prix de vos baskets préférées ou comparez des hôtels pour vos prochaines vacances, il y a de grandes chances qu’un robot d’exploration soit déjà passé par là, en collectant et en organisant sans bruit les informations que vous voyez. En fait, on estime qu’environ la moitié du trafic Internet est aujourd’hui générée par des bots et des robots d’exploration, et non par des humains — des enquêtes récentes du secteur situent la part des bots entre 49 et 51 %. Oui, pendant que vous dormez, ces éclaireurs numériques cartographient sans relâche le web pour que l’information mondiale reste à portée de clic.
Mais qu’est-ce qu’un robot d’exploration web, exactement ? Pourquoi est-il si important pour les entreprises, les chercheurs et toute personne qui dépend de données à jour ? Et comment des outils modernes comme Thunderbit ont-ils rendu l’exploration web accessible à tout le monde, pas seulement aux développeurs ou aux géants de la tech ? Après des années passées à créer des outils d’automatisation et d’IA, j’ai pu voir de près comment les robots d’exploration sont passés du statut de mystérieuses « araignées » à celui d’outils indispensables au quotidien des entreprises. Entrons dans le vif du sujet et démystifions l’univers des robots d’exploration web : ce qu’ils sont, comment ils fonctionnent et pourquoi ils constituent la colonne vertébrale d’un accès plus intelligent aux données en 2026.
Les robots d’exploration web sont les éclaireurs de données d’Internet
Extraire des données de n’importe quel site web grâce à l’IA Get Started Free
Alors, qu’est-ce qu’un robot d’exploration web, au juste ? À la base, les robots d’exploration web (aussi appelés spiders ou bots) sont des programmes automatisés qui parcourent Internet de manière méthodique, visitant une page après l’autre et collectant des informations au fil de leur progression. Voyez-les comme les stagiaires de recherche les plus infatigables du monde — sauf qu’ils ne dorment jamais, ne se plaignent jamais et peuvent visiter des millions de pages en une seule journée.
Un robot d’exploration web commence avec une liste d’adresses web (appelées « seeds »), visite chacune d’elles, puis suit les liens qu’il trouve pour découvrir de nouvelles pages. Au fur et à mesure de son exploration, il copie du contenu, indexe des données et construit une carte d’un web en constante évolution (Cloudflare). C’est ainsi que les moteurs de recherche comme Google savent ce qui existe en ligne, et que les comparateurs de prix ou les outils d’étude de marché gardent leurs données à jour.
En termes simples : les robots d’exploration web sont les éclaireurs qui rendent Internet consultable, comparable et exploitable.
Les multiples visages des robots d’exploration web : types et fonctions essentielles
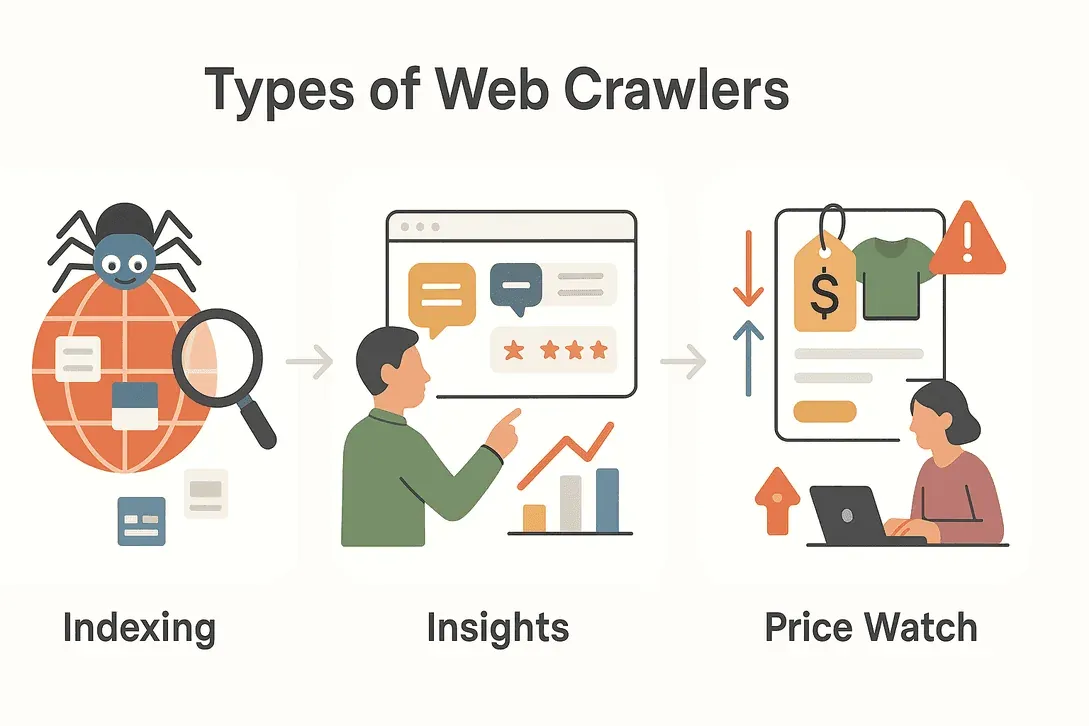 Tous les robots d’exploration web ne jouent pas le même rôle. Selon leur mission, ils se déclinent en plusieurs catégories, chacune avec sa spécialité. Voici un tour d’horizon rapide des principaux types que vous rencontrerez :
Tous les robots d’exploration web ne jouent pas le même rôle. Selon leur mission, ils se déclinent en plusieurs catégories, chacune avec sa spécialité. Voici un tour d’horizon rapide des principaux types que vous rencontrerez :
| Type | Fonction principale | Cas d’usage typique |
|---|---|---|
| Robots d’exploration des moteurs de recherche | Indexer le web pour les résultats de recherche | Googlebot, Bingbot indexant de nouveaux sites web |
| Robots d’exploration pour l’exploration de données | Collecter de vastes ensembles de données pour l’analyse | Études de marché, recherches universitaires |
| Robots d’exploration pour la surveillance des prix | Suivre les prix et la disponibilité des produits | Comparaison de prix e-commerce, tarification dynamique |
| Robots d’exploration d’agrégation de contenu | Collecter des articles, des actualités ou des publications pour les agréger | Portails d’actualités, curation de contenu |
| Robots d’exploration pour la génération de leads | Extraire des coordonnées et des données d’entreprise | Prospection commerciale, annuaires B2B |
Décomposons-en quelques-uns plus en détail :
Robots d’exploration des moteurs de recherche
Quand vous tapez une question dans Google, vous vous appuyez sur le travail des robots d’exploration des moteurs de recherche. Ces bots parcourent le web 24 h/24 et 7 j/7, découvrent de nouvelles pages, mettent à jour les anciennes et indexent le contenu afin qu’il apparaisse dans les résultats de recherche. Sans eux, les moteurs de recherche avanceraient à l’aveugle : impossible de savoir ce qui est nouveau, ce qui a changé ou même ce qui existe (TechTarget).
Robots d’exploration pour l’exploration de données et les études de marché
Les entreprises et les chercheurs utilisent des robots d’exploration pour collecter d’énormes volumes de données à des fins d’analyse. Vous voulez savoir combien de fois la marque d’un concurrent est mentionnée en ligne ? Ou suivre le sentiment autour du lancement d’un nouveau produit ? Les robots d’exploration pour l’exploration de données peuvent scanner des forums, des avis, les réseaux sociaux et bien plus encore, transformant le chaos du web en insights structurés (DataHut).
Robots d’exploration pour la surveillance des prix et le suivi des produits
Dans l’univers ultrarapide du e-commerce, les prix et les informations produits évoluent en permanence. Les robots d’exploration pour la surveillance des prix suivent les concurrents et alertent les entreprises en cas de baisse de prix, de changement de stock ou de lancement de nouveau produit. Cela permet des stratégies de tarification dynamique et aide les entreprises à rester compétitives (AIMultiple).
Pourquoi les robots d’exploration web sont essentiels à l’accès moderne aux données
Soyons honnêtes : Internet est bien trop vaste pour être suivi manuellement par des humains. Il existe aujourd’hui plus de 1,4 milliard de sites web (et ce chiffre continue de grimper), avec environ un million de nouveaux sites ajoutés chaque jour. Les robots d’exploration web permettent de :
- Passer à l’échelle pour la collecte de données : visiter des millions de pages en quelques heures, et non en plusieurs mois.
- Rester à jour : surveiller en continu les changements, les nouveaux contenus ou les actualités de dernière minute.
- Accéder à des informations dynamiques et en temps réel : réagir aux évolutions du marché, aux variations de prix ou aux sujets tendance au moment où ils se produisent.
- Faciliter les décisions fondées sur les données : alimenter tout, des moteurs de recherche à l’étude de marché, en passant par la gestion des risques et la modélisation financière (DEV Community).
Dans un monde où les données sont la colonne vertébrale de la stratégie commerciale numérique, les robots d’exploration web sont les moteurs qui maintiennent ce flux de données.
Cas d’usage courants des robots d’exploration web selon les secteurs
Les robots d’exploration web ne servent pas qu’aux géants de la tech ou aux moteurs de recherche. Voici comment différents secteurs les utilisent :
| Secteur | Cas d’usage | Avantage |
|---|---|---|
| Ventes | Génération de leads | Constituer des listes de prospects ciblées à partir d’annuaires |
| E-commerce | Surveillance des prix | Suivre les prix, les stocks et les changements de produits des concurrents |
| Marketing | Agrégation de contenu | Sélectionner des actualités, des articles et des mentions sur les réseaux sociaux |
| Immobilier | Agrégation d’annonces immobilières | Regrouper des annonces provenant de plusieurs sources |
| Voyage | Comparaison des tarifs et des hôtels | Surveiller les prix, la disponibilité et les conditions |
| Finance | Surveillance des risques | Suivre l’actualité, les dépôts et le sentiment pour les investissements |
Exemple concret :
Une agence immobilière utilise des robots d’exploration pour extraire les détails des biens, les photos et les équipements depuis plusieurs sites d’annonces, offrant à ses clients une vue unifiée et à jour du marché (DataHut).
Une équipe e-commerce met en place des robots d’exploration pour surveiller les références produits et les prix des concurrents, ajustant sa propre stratégie en temps réel (AIMultiple).
Comment fonctionnent les robots d’exploration web : vue d’ensemble étape par étape
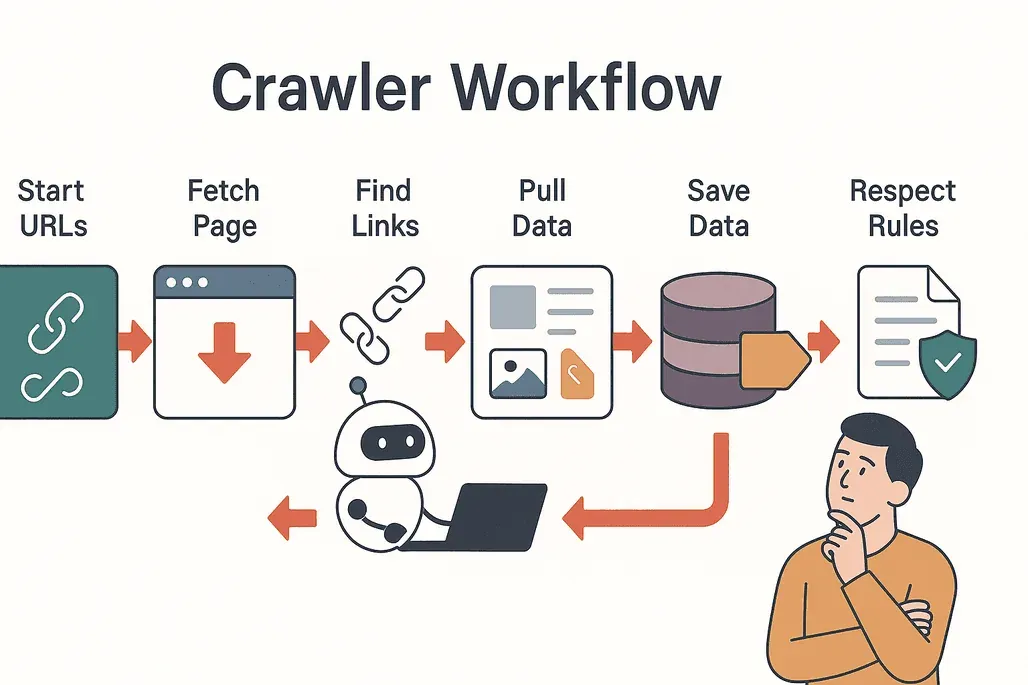 Démystifions le processus. Voici comment fonctionne un robot d’exploration web typique :
Démystifions le processus. Voici comment fonctionne un robot d’exploration web typique :
- Commencer avec des seeds : le robot d’exploration démarre avec une liste d’URL initiales.
- Visiter et récupérer : il visite chaque page et télécharge le contenu.
- Extraire les liens : le robot repère tous les liens présents sur la page.
- Suivre les liens : il ajoute à sa file d’attente les nouveaux liens encore non visités.
- Extraire les données : les informations pertinentes (texte, images, prix, etc.) sont copiées et structurées.
- Stocker les résultats : les données sont enregistrées dans une base de données ou exportées pour analyse.
- Respecter les règles : le robot vérifie le fichier
robots.txtde chaque site pour savoir ce qui est autorisé et éviter les zones restreintes (Cloudflare).
Bonnes pratiques :
- Explorer poliment (sans surcharger les serveurs).
- Respecter la vie privée et les limites légales.
- Éviter les contenus dupliqués et les requêtes inutiles.
Défis et points de vigilance lors de l’utilisation de robots d’exploration web
L’exploration web n’est pas toujours un long fleuve tranquille. Voici quelques obstacles fréquents :
- Charge serveur : trop de requêtes peuvent ralentir un site ou le faire tomber.
- Contenu dupliqué : les robots peuvent revisiter les mêmes pages ou se retrouver coincés dans des boucles.
- Vie privée et légalité : toutes les données ne sont pas librement exploitables — vérifiez toujours les conditions d’utilisation et les lois sur la vie privée.
- Freins techniques : certains sites utilisent des CAPTCHA, du contenu dynamique ou des mécanismes anti-bot pour bloquer les robots d’exploration (DEV Community).
Conseils pour réussir :
- Adoptez des rythmes d’exploration respectueux.
- Surveillez les changements dans la structure des sites web.
- Restez à jour sur les réglementations relatives à la protection des données.
Thunderbit : rendre les robots d’exploration web accessibles à tout le monde
C’est là que les choses deviennent intéressantes. Traditionnellement, mettre en place un robot d’exploration web signifiait écrire du code, configurer des paramètres et passer des heures à résoudre des problèmes. Mais avec Thunderbit, nous avons changé la donne.
Thunderbit est une extension Chrome d’extracteur web IA conçue pour les utilisateurs métier — sans aucune ligne de code. Voici ce qui le distingue :
- Instructions en langage naturel : décrivez simplement les données que vous voulez (« Récupérez tous les noms et prix des produits de cette page »), et l’IA de Thunderbit s’occupe du reste.
- Suggestions de champs alimentées par l’IA : cliquez sur « AI Suggest Fields » et Thunderbit lit la page pour recommander les meilleures colonnes à extraire.
- Extraction des sous-pages : vous avez besoin de plus de détails ? Thunderbit peut visiter chaque sous-page (comme les fiches produit ou les profils LinkedIn) et enrichir automatiquement votre jeu de données.
- Modèles instantanés : pour les sites populaires (Amazon, Zillow, Shopify, etc.), utilisez des modèles prêts à l’emploi pour extraire des données en un clic.
- Export facile : envoyez vos données directement vers Excel, Google Sheets, Airtable ou Notion — sans étape supplémentaire.
- Export de données gratuit : téléchargez vos résultats au format CSV ou JSON, entièrement gratuitement.
Thunderbit est utilisé par plus de 100 000 utilisateurs dans le monde, des équipes commerciales aux opérateurs e-commerce en passant par les professionnels de l’immobilier.
Essayer gratuitement Thunderbit AI Web Scraper
Thunderbit vs les robots d’exploration web traditionnels
Voyons comment Thunderbit se compare à l’approche classique :
| Fonctionnalité | Thunderbit | Robots d’exploration traditionnels |
|---|---|---|
| Temps de configuration | 2 clics (l’IA gère la configuration) | Des heures ou des jours (configuration manuelle, code) |
| Compétences techniques requises | Aucune (instructions en français courant) | Élevées (code, sélecteurs, scripts) |
| Flexibilité | Fonctionne sur n’importe quel site, s’adapte aux changements | Casse lors des changements de mise en page |
| Extraction des sous-pages | Intégrée, sans configuration supplémentaire | Scripting manuel requis |
| Options d’export | Excel, Sheets, Airtable, Notion, CSV, JSON | En général CSV/JSON uniquement |
| Maintenance | L’IA s’adapte automatiquement | Corrections manuelles fréquentes |
Avec Thunderbit, nul besoin d’être développeur ni de passer des heures à ajuster les paramètres. Il suffit de pointer, cliquer et laisser l’IA faire le gros du travail (Thunderbit Blog).
Démarrer avec les robots d’exploration web grâce à Thunderbit
Prêt à essayer ? Voici comment démarrer avec Thunderbit en quelques minutes :
- Installez l’extension Chrome Thunderbit.
- Ouvrez le site web que vous souhaitez explorer.
- Cliquez sur l’icône Thunderbit et appuyez sur « AI Suggest Fields ». L’IA recommandera les colonnes en fonction du contenu de la page.
- Ajustez les champs si nécessaire, puis cliquez sur « Scrape ». Thunderbit extraira les données, y compris depuis les sous-pages si vous le souhaitez.
- Exportez vos résultats vers Excel, Google Sheets, Airtable, Notion, ou téléchargez-les en CSV/JSON.
Qu’est-ce que le data scraping et comment le faire en 2025 Get Started Free
Et voilà — pas de scripts, pas de code, pas de prise de tête. Que vous suiviez des prix, constituiez une liste de leads ou agrégiez des actualités, Thunderbit permet à la plupart des tâches courantes d’exploration web d’être réalisées par une personne non développeuse en un seul après-midi.
Conclusion : les robots d’exploration web sont la clé d’un accès plus intelligent aux données
Les robots d’exploration web sont les moteurs invisibles qui alimentent notre monde numérique, rendant l’information accessible, consultable et exploitable pour tout le monde. Des moteurs de recherche aux équipes commerciales, du e-commerce à l’immobilier, les robots d’exploration sont devenus des outils essentiels pour toute personne ayant besoin de données fiables et à jour.
Et grâce à des outils modernes dopés à l’IA comme Thunderbit, vous n’avez pas besoin d’être programmeur pour en exploiter la puissance. En quelques clics, chacun peut transformer le web en une ressource structurée et exploitable — et ainsi prendre de meilleures décisions et saisir de nouvelles opportunités.
Curieux de voir ce que les robots d’exploration web peuvent faire pour votre entreprise ? Téléchargez Thunderbit et commencez dès aujourd’hui à explorer les données cachées du web. Pour plus de conseils et d’analyses approfondies, consultez le Thunderbit Blog.
Essayez l’Extracteur Web IA Get Started Free
FAQ
1. Qu’est-ce qu’un robot d’exploration web, exactement ?
Un robot d’exploration web est un programme automatisé (parfois appelé spider ou bot) qui parcourt systématiquement Internet, visite des pages web, suit des liens et collecte des informations à des fins d’indexation ou d’analyse.
2. Quelle est la différence entre un robot d’exploration web et un extracteur web ?
Les robots d’exploration web sont conçus pour découvrir et cartographier de grandes portions du web, souvent en suivant les liens de page en page. Les extracteurs web, eux, se concentrent sur l’extraction de données précises à partir de pages ciblées. De nombreux outils modernes, comme Thunderbit, combinent ces deux fonctions.
3. Pourquoi les robots d’exploration web sont-ils importants pour les entreprises ?
Les robots d’exploration web permettent aux entreprises d’accéder à des informations à jour à grande échelle — qu’il s’agisse de surveiller les prix des concurrents, d’agréger du contenu ou de constituer des listes de prospects. Ils soutiennent la prise de décision en temps réel et aident les entreprises à rester compétitives.
4. Est-il légal d’utiliser des robots d’exploration web ?
L’exploration web est généralement légale lorsqu’elle est menée de manière responsable et conformément aux conditions d’utilisation et aux politiques de confidentialité d’un site. Vérifiez toujours le fichier robots.txt du site et respectez les réglementations relatives à la protection des données.
5. Comment Thunderbit simplifie-t-il l’exploration web ?
Thunderbit utilise l’IA pour automatiser la configuration, la sélection des champs et l’extraction des données. Grâce à des instructions en langage naturel et à des modèles instantanés, n’importe qui peut explorer et extraire des données de sites web — sans code ni compétences techniques. Les données peuvent être exportées directement vers Excel, Google Sheets, Airtable ou Notion pour une utilisation immédiate.
En savoir plus




