
Le web évolue à une allure folle, c’est presque inimaginable. En 2024, on recense plus de 1,1 milliard de sites web, et déjà 149 zettaoctets de données qui circulent en ligne (on prévoit même 181 ZB l’an prochain). Autant dire qu’il y a de quoi se perdre dans les menus de pizzerias ! Mais le plus fou, c’est que seulement 4 % du contenu en ligne est indexé par les moteurs de recherche. Tout le reste appartient au fameux « deep web », totalement invisible lors de nos recherches classiques. Alors, comment font les moteurs de recherche et les entreprises pour s’y retrouver dans cette jungle numérique ? C’est là qu’intervient l’extracteur web.
Dans ce guide, je vais t’expliquer ce qu’est le crawling web, comment ça marche et pourquoi c’est crucial — pas seulement pour les pros de la tech, mais pour toute personne qui veut exploiter la richesse des données en ligne. On va aussi voir la différence entre le crawling et l’extraction de données (ce n’est pas la même chose !), des exemples concrets d’utilisation, et des solutions avec ou sans code (y compris mon outil préféré, Thunderbit). Que tu sois novice curieux ou pro en quête d’efficacité, tu es au bon endroit.
Qu’est-ce qu’un Extracteur Web ? Les Bases du Crawling
On commence simple. Un extracteur web (aussi appelé spider, bot ou crawler) est un programme automatisé qui parcourt le web de façon méthodique, récupère les pages et suit les liens pour découvrir de nouveaux contenus. Imagine un robot bibliothécaire qui part d’une liste de livres (URLs), les lit un par un, puis suit chaque référence pour en trouver d’autres. C’est exactement le principe du crawler — sauf qu’il s’agit de pages web, et que la bibliothèque, c’est tout Internet.
Le fonctionnement de base, c’est :
- Démarrer avec une liste d’URLs (appelées « seeds »)
- Visiter chaque page, télécharger son contenu (HTML, images, etc.)
- Repérer les liens sur ces pages et les ajouter à la file d’attente
- Répéter — visiter les nouveaux liens, découvrir d’autres pages, et ainsi de suite
Le rôle principal d’un extracteur web, c’est de découvrir et répertorier les pages. Pour les moteurs de recherche, les crawlers copient le contenu des pages pour l’indexer et l’analyser. Dans d’autres cas, des extracteurs spécialisés peuvent extraire des données précises (c’est là que l’extraction de données entre en jeu — on y revient juste après).
À retenir :
Le crawling web sert à cartographier et explorer le web, pas seulement à collecter des données. C’est la base du fonctionnement des moteurs de recherche comme Google ou Bing.
Comment Fonctionne un Moteur de Recherche ? Le Rôle des Crawlers
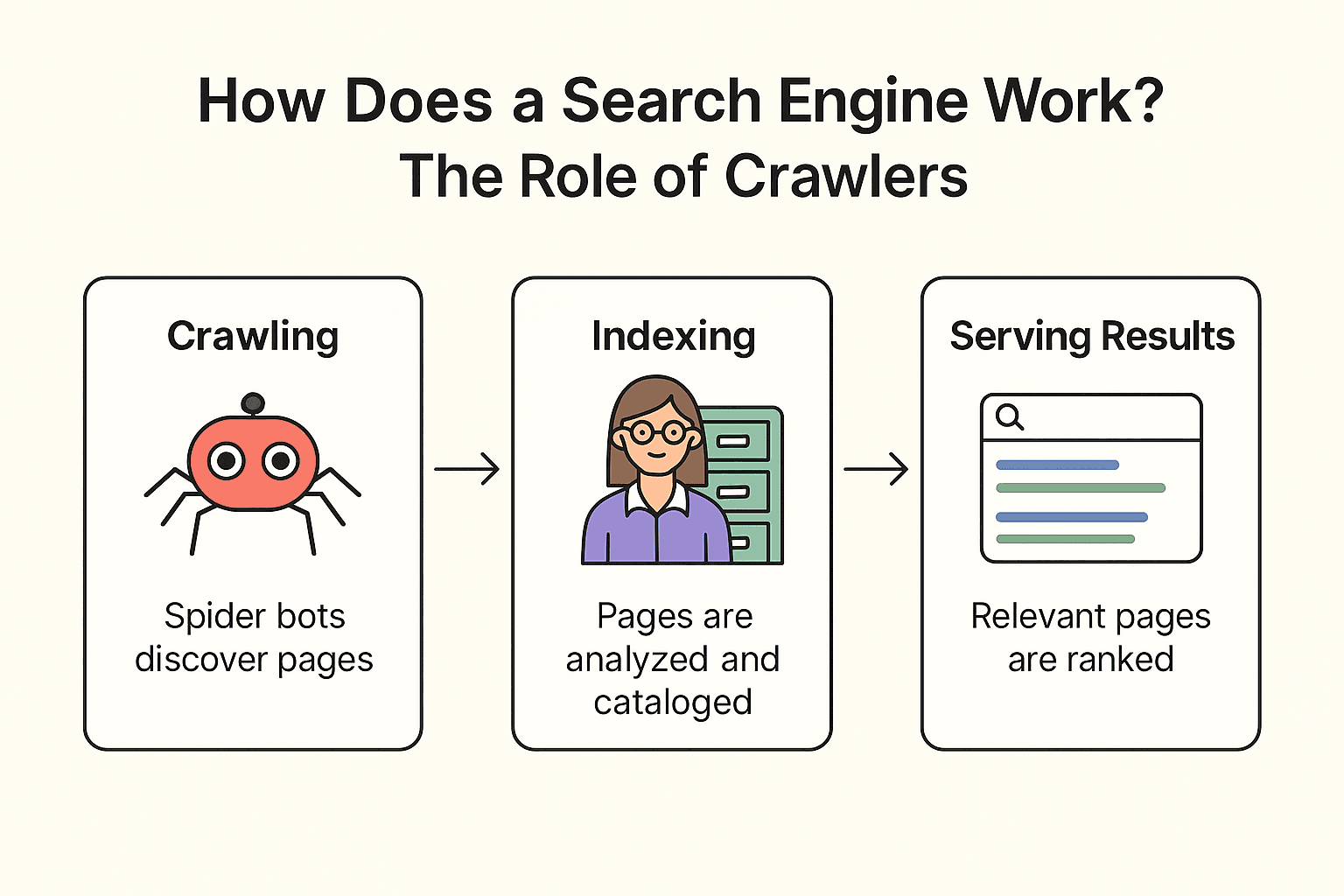
Alors, comment Google (ou Bing, ou DuckDuckGo) s’y prend concrètement ? C’est un processus en trois temps : crawling, indexation et affichage des résultats (voir la doc officielle de Google).
Prenons la métaphore de la bibliothèque (parce qu’elle marche toujours !) :
-
Crawling :
Le moteur de recherche envoie ses « robots araignées » (comme Googlebot) explorer le web. Ils partent de pages connues, récupèrent leur contenu et suivent les liens pour découvrir de nouvelles pages — comme un bibliothécaire qui vérifie chaque étagère et suit les références pour trouver d’autres livres.
-
Indexation :
Une fois la page trouvée, le moteur de recherche analyse son contenu, comprend de quoi il s’agit et stocke les infos clés dans un immense catalogue numérique (l’index). Toutes les pages ne sont pas retenues — certaines sont ignorées si elles sont bloquées, de mauvaise qualité ou en double.
-
Affichage des résultats :
Quand tu tapes « meilleure pizza près de chez moi », le moteur consulte son index et classe les pages pertinentes selon des centaines de critères (mots-clés, popularité, fraîcheur, etc.). Résultat : une liste ordonnée de pages web, prêtes à être consultées.
Le savais-tu ?
Les moteurs de recherche ne parcourent pas toutes les pages du web. Les pages protégées par un identifiant, bloquées par robots.txt ou sans liens entrants peuvent rester invisibles. C’est pour ça que les entreprises soumettent parfois directement leurs URLs ou sitemaps à Google.
Crawling vs. Extraction de Données : Quelle Différence ?
C’est là que ça se complique. Beaucoup confondent « crawling » et « extraction de données », mais ce sont deux choses bien distinctes.
| Aspect | Crawling (Exploration) | Extraction de Données |
|---|---|---|
| Objectif | Découvrir et indexer un maximum de pages | Extraire des données précises de pages web |
| Métaphore | Bibliothécaire qui catalogue tous les livres | Étudiant qui prend des notes ciblées dans quelques livres |
| Résultat | Liste d’URLs ou contenu de pages (pour l’indexation) | Jeu de données structuré (CSV, Excel, JSON) avec les infos ciblées |
| Utilisateurs | Moteurs de recherche, auditeurs SEO, archivistes web | Équipes commerciales, marketing, recherche, etc. |
| Échelle | Massive (millions/milliards de pages) | Ciblée (dizaines, centaines ou milliers de pages) |
Voir une comparaison visuelle ici.
En résumé :
- Le crawling sert à trouver des pages (cartographier le web)
- L’extraction de données consiste à récupérer les informations voulues sur ces pages (pour les mettre dans un tableau)
La plupart des pros (surtout en vente, e-commerce ou marketing) s’intéressent surtout à l’extraction de données — obtenir des données structurées pour analyse — plutôt qu’à l’exploration de tout le web. Le crawling est essentiel pour les moteurs de recherche et la découverte à grande échelle, tandis que l’extraction vise la collecte ciblée d’informations.
Pourquoi Utiliser un Extracteur Web ? Exemples Concrets en Entreprise
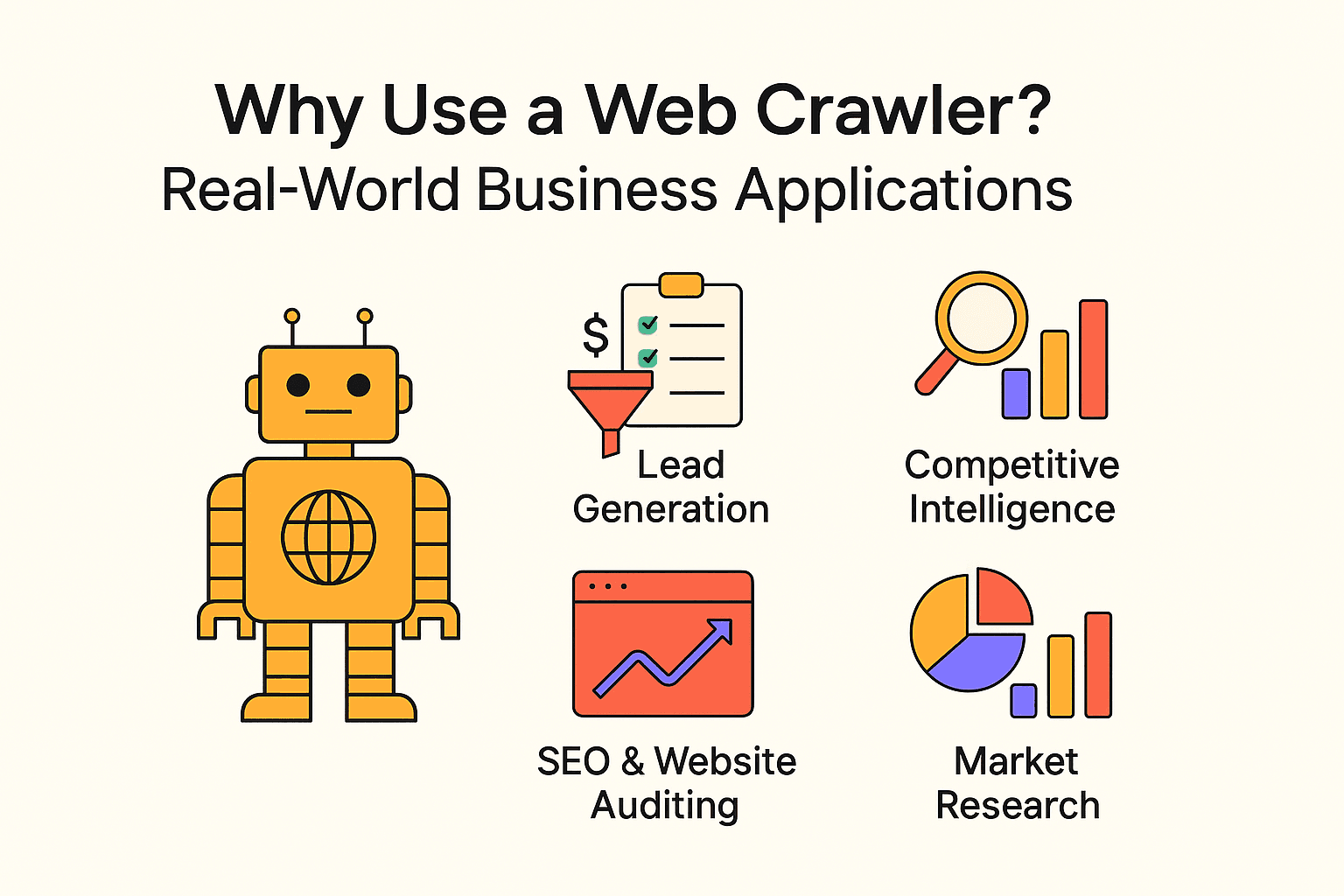
Le crawling n’est pas réservé aux moteurs de recherche. Les entreprises de toutes tailles utilisent extracteurs et outils d’extraction pour obtenir des infos stratégiques et automatiser des tâches répétitives. Voici quelques exemples concrets :
| Cas d’usage | Utilisateur cible | Bénéfice attendu |
|---|---|---|
| Génération de leads | Équipes commerciales | Automatiser la prospection, alimenter le CRM en nouveaux contacts |
| Veille concurrentielle | Retail, e-commerce | Suivre les prix, stocks et nouveautés des concurrents |
| SEO & Audit de site | Marketing, SEO | Détecter les liens cassés, optimiser la structure du site |
| Agrégation de contenu | Médias, recherche, RH | Rassembler des actualités, offres d’emploi ou jeux de données publics |
| Études de marché | Analystes, chefs de produit | Analyser les avis, tendances ou sentiments à grande échelle |
- Groupon a doublé ses leads entrants grâce à l’automatisation de la prospection via le crawling.
- 82 % des entreprises e-commerce et 71 % des sociétés financières s’appuient sur l’extraction de données pour leurs décisions.
- L’extraction de données peut réduire de 90 % les coûts d’infrastructure et de 60 % le temps par rapport à la collecte manuelle.
En clair : Si tu n’exploites pas les données du web, tes concurrents le font déjà.
Coder un Extracteur Web en Python : Ce Qu’il Faut Savoir
Si tu es à l’aise avec le code, Python est la référence pour créer des extracteurs web sur mesure. La recette de base :
- Utiliser requests pour récupérer les pages web
- Utiliser BeautifulSoup pour analyser le HTML et extraire liens/données
- Écrire des boucles (ou de la récursivité) pour suivre les liens et explorer d’autres pages
Avantages :
- Flexibilité et contrôle total
- Possibilité de gérer des logiques complexes, des flux personnalisés, et d’intégrer des bases de données
Inconvénients :
- Il faut savoir coder
- Maintenance parfois pénible : si le site change, le script peut casser
- À toi de gérer les protections anti-bot, les délais et les erreurs
Exemple simple d’extracteur Python :
Voici un script qui récupère des citations et auteurs sur quotes.toscrape.com :
import requests
from bs4 import BeautifulSoup
url = "<http://quotes.toscrape.com/page/1/>"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
for quote in soup.find_all('div', class_='quote'):
text = quote.find('span', class_='text').get_text()
author = quote.find('small', class_='author').get_text()
print(f"{text} --- {author}")
Pour parcourir plusieurs pages, il suffit d’ajouter une logique pour cliquer sur « Suivant » et boucler jusqu’à la fin.
Pièges fréquents :
- Oublier de respecter robots.txt ou les délais (ne sois pas ce genre de personne)
- Se faire bloquer par les systèmes anti-bot
- Tomber dans des boucles infinies (ex : calendriers sans fin)
Guide Pratique : Créer un Extracteur Web Simple en Python
Envie de te lancer ? Voici les grandes étapes pour coder un crawler basique.
Étape 1 : Préparer son Environnement Python
Assure-toi d’avoir Python installé. Puis, installe les bibliothèques nécessaires :
pip install requests beautifulsoup4
En cas de souci, vérifie ta version de Python (python --version) et que pip fonctionne.
Étape 2 : Écrire la Logique de Base du Crawler
Voici un schéma simple :
import requests
from bs4 import BeautifulSoup
def crawl(url, depth=1, max_depth=2, visited=None):
if visited is None:
visited = set()
if url in visited or depth > max_depth:
return
visited.add(url)
print(f"Crawling: {url}")
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# Extraire les liens
for link in soup.find_all('a', href=True):
next_url = link['href']
if next_url.startswith('http'):
crawl(next_url, depth + 1, max_depth, visited)
start_url = "<http://quotes.toscrape.com/>"
crawl(start_url)
Conseils :
- Limite la profondeur pour éviter les boucles infinies
- Garde une trace des URLs déjà visitées
- Respecte robots.txt et ajoute des délais (time.sleep(1)) entre les requêtes
Étape 3 : Extraire et Sauvegarder les Données
Pour sauvegarder les données, écris-les dans un fichier CSV ou JSON :
import csv
with open('quotes.csv', 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(['Citation', 'Auteur'])
# Dans ta boucle de crawl :
writer.writerow([text, author])
Ou utilise le module json de Python pour un export JSON.
Bonnes Pratiques et Points de Vigilance pour le Crawling
Le crawling, c’est puissant, mais il faut l’utiliser avec bon sens (et éviter de se faire bannir !). Voici quelques règles à suivre :
- Respecte le robots.txt : Vérifie toujours ce que le site autorise ou interdit.
- Va doucement : Ajoute des délais entre les requêtes (au moins quelques secondes). N’encombre pas les serveurs.
- Limite le périmètre : Ne crawle que ce dont tu as besoin. Fixe des limites de profondeur et de domaine.
- Identifie-toi : Utilise un User-Agent explicite.
- Respecte la loi : N’extrais pas de données privées ou sensibles. Reste sur des contenus publics.
- Sois éthique : N’aspire pas des sites entiers ni n’utilise les données pour du spam.
- Teste progressivement : Commence petit, puis élargis si tout se passe bien.
Pour aller plus loin, consulte ce guide de bonnes pratiques.
Quand Privilégier l’Extraction de Données : Thunderbit pour les Pros
Extraire des données de n'importe quel site avec l'IA Get Started Free
Soyons clairs : sauf si tu construis un moteur de recherche ou que tu dois cartographier la structure complète d’un site, la plupart des pros gagneront à utiliser des outils d’extraction de données.
C’est là que Thunderbit entre en scène. En tant que cofondateur et CEO, je ne suis peut-être pas le plus neutre, mais je pense sincèrement que Thunderbit est la solution la plus simple pour extraire des données web sans aucune compétence technique.
Pourquoi choisir Thunderbit ?
- Configuration express : Clique sur « Suggérer les champs IA » puis « Extraire » — c’est tout.
- IA intégrée : Thunderbit analyse la page et propose automatiquement les colonnes pertinentes (noms de produits, prix, images, etc.).
- Support du bulk & PDF : Extraire des données de la page courante, d’une liste d’URLs ou même de fichiers PDF.
- Export flexible : Télécharge en CSV/JSON, ou envoie directement vers Google Sheets, Airtable ou Notion.
- Zéro code : Si tu sais utiliser un navigateur, tu sais utiliser Thunderbit.
- Extraction sur sous-pages : Besoin de détails ? Thunderbit peut visiter les sous-pages et enrichir tes données automatiquement.
- Planification : Programme des extractions récurrentes en langage naturel (ex : « chaque lundi à 9h »).
Essayez l’extension Chrome Thunderbit gratuitement
Quand utiliser un crawler plutôt qu’un extracteur ?
Si ton objectif est de cartographier l’intégralité d’un site (pour créer un index ou un sitemap), le crawler est l’outil adapté. Mais si tu veux simplement récupérer des données structurées sur des pages précises (listings produits, avis, contacts…), l’extraction est plus rapide, plus simple et plus efficace.
Conclusion & Points Clés à Retenir
En résumé :
- Le crawling web permet aux moteurs de recherche et aux projets big data de découvrir et cartographier le web. C’est une approche « large » — trouver un maximum de pages.
- L’extraction de données vise la « profondeur » — extraire les infos précises qui t’intéressent. La plupart des pros ont besoin d’extraction, pas de crawling.
- Tu peux coder ton propre crawler (Python est top), mais ça demande du temps, des compétences et de la maintenance.
- Les outils no-code et IA comme Thunderbit rendent l’extraction de données accessible à tous — sans programmation.
- Les bonnes pratiques sont essentielles : Respecte toujours les règles des sites, agis de façon responsable et éthique.
Pour commencer, choisis un projet simple — par exemple, extraire des prix de produits ou collecter des leads depuis un annuaire. Essaie un outil comme Thunderbit pour un résultat rapide, ou lance-toi dans Python si tu veux comprendre les rouages techniques.
Le web est une véritable mine d’or d’informations. Avec la bonne méthode, tu peux révéler des insights précieux, gagner du temps et garder une longueur d’avance.
Commencez l’extraction avec Thunderbit
FAQ
- Quelle est la différence entre crawling et extraction de données ?
Le crawling sert à découvrir et cartographier les pages. L’extraction récupère des données précises. Crawling = découverte ; extraction = collecte ciblée.
- L’extraction de données est-elle légale ?
Extraire des données publiques est généralement autorisé si tu respectes le robots.txt et les conditions d’utilisation. Évite les contenus privés ou protégés par le droit d’auteur.
- Faut-il savoir coder pour extraire des données ?
Non. Des outils comme Thunderbit permettent d’extraire des données en quelques clics grâce à l’IA — sans coder.
- Pourquoi tout le web n’est-il pas indexé par Google ?
Parce que la majorité est protégée par des identifiants, des paywalls ou bloquée. Seuls 4 % environ sont réellement indexés.
Pour aller plus loin
- FreeCodeCamp – Web Scraping avec Python et BeautifulSoup
- Tutoriel officiel Scrapy
- Real Python – Utiliser Selenium et Python pour l’extraction web
- Apify Academy : Extraction de données et automatisation
Essayez l’Extracteur Web IA Get Started Free




