

Vous avez déjà passé un après-midi à relever à la main les prix d'un produit, les avis d'un concurrent ou une liste de prospects ? Le refrain est connu : clic, copier, coller, on recommence… jusqu'à épuisement de la patience. L'extraction de données web est devenue l'atout discret des équipes commerciales, opérationnelles et marketing. Le gain de temps est considérable, mais ce n'est que la surface : c'est surtout la clé pour accéder à des informations stratégiques, automatiser les tâches ingrates et décider plus vite que la concurrence.
J'ai vu un bon processus d'extraction ramener une semaine de travail manuel à cinq minutes chrono. Que vous débutiez ou cherchiez à passer un cap, ce tutoriel vous guide pas à pas : des fondamentaux aux pièges à éviter, en passant par des méthodes concrètes, classiques ou propulsées par l'IA comme Thunderbit. Prêt à faire du web votre mine d'or ?
C'est quoi l'extraction de données web ? Les bases
L'extraction de données web (ou web scraping) consiste à récupérer automatiquement des informations sur des sites pour les ranger dans un format propre — tableau ou base de données — afin de les analyser ou de les exploiter en entreprise. Fini le copier-coller manuel : un extracteur web est un assistant numérique qui parcourt les pages, repère les données qui vous intéressent (prix, noms, e-mails, avis…) et les classe au cordeau (Thunderbit Blog).
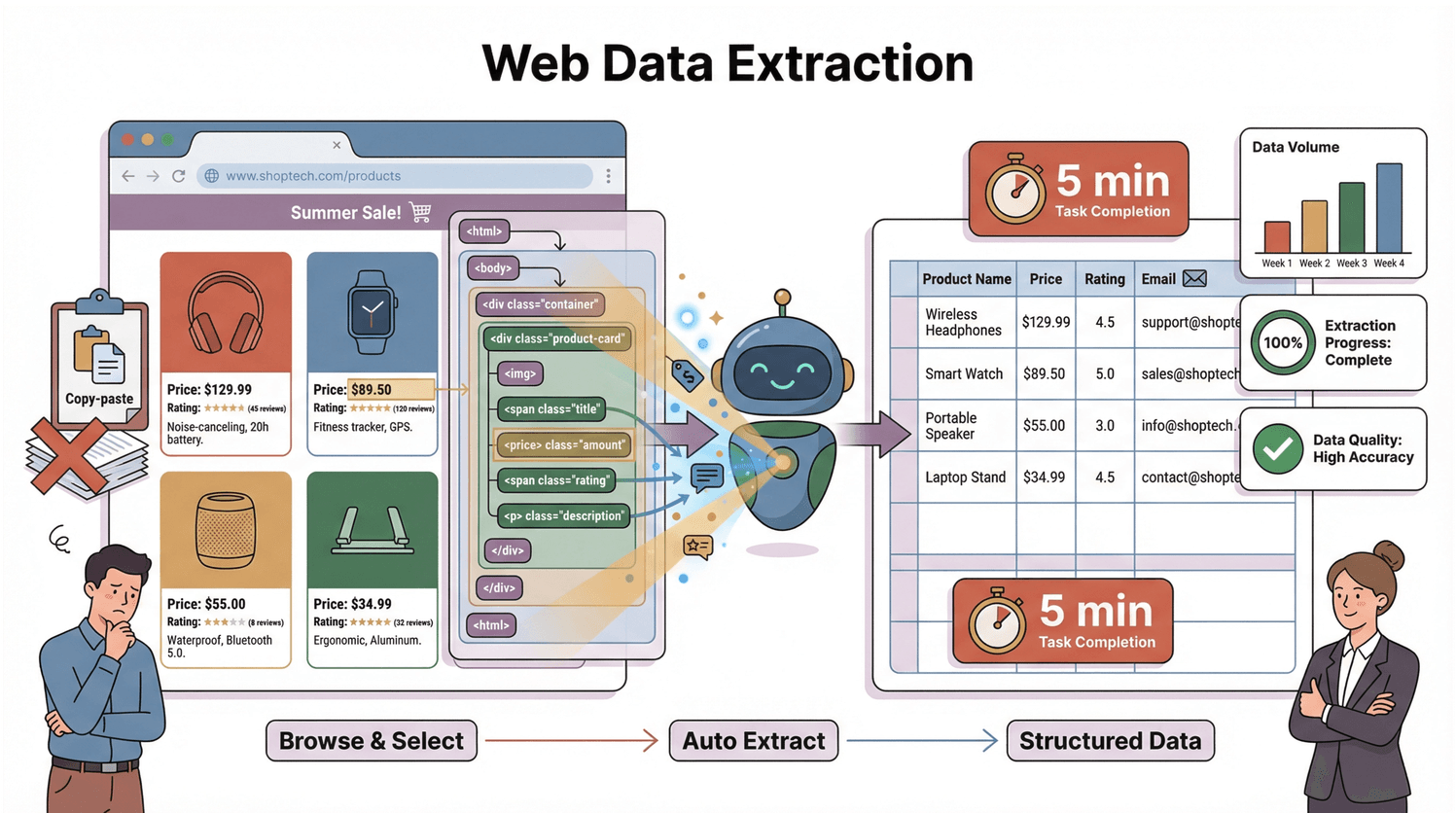
Concrètement, comment ça fonctionne ? Chaque page web repose sur une structure appelée DOM (Document Object Model) — le plan qui indique à votre navigateur, et à tout extracteur, où se trouve chaque élément. L'extracteur lit ce plan, vise ce qui vous intéresse et range le tout en lignes et en colonnes. Un assistant méthodique qui ne fatigue jamais.
Pourquoi l'extraction de données web est devenue indispensable pour les ventes et les opérations
Qu’est-ce que le data scraping et comment le faire en 2025 Get Started Free
Soyons clairs : l'extraction de données web n'est pas un caprice de geek, c'est un levier pour l'entreprise. Voici pourquoi les équipes commerciales, opérationnelles et marketing s'y mettent sans réserve :
| Cas d’usage | Bénéfice métier | Impact concret |
|---|---|---|
| Génération de leads | Remplir rapidement votre pipeline de prospects qualifiés | 70% de ROI en 6 mois ; 40% de leads de meilleure qualité ; des centaines d’heures économisées (Grepsr) |
| Veille tarifaire | Prix dynamiques, marges préservées | 65% de ROI en 6 mois ; +12% de ventes ; 75% de travail manuel en moins (Grepsr) |
| Analyse concurrentielle | Veille marché en temps réel | 55% de ROI pour les compagnies aériennes ; 68% pour le e-commerce (Grepsr) |
| Suivi opérationnel | Anticiper les ruptures, optimiser la chaîne d’approvisionnement | 62% de ROI pour un distributeur mondial ; fin des pénuries surprises (Grepsr) |
Et le ROI n'est qu'une part de l'histoire. Automatiser la collecte libère vos équipes pour la stratégie plutôt que les tableurs. Certaines entreprises ont réduit leurs coûts de collecte de 40% (Browsercat), et le marché mondial du web scraping s'apprête à décoller : de 5 milliards en 2023 à plus de 140 milliards d'ici 2032 (Browsercat). Une déferlante de données, et d'opportunités.
Comment ça marche : du DOM au tableau de données
Voyons ce qui se joue sous le capot :
- Requête : L'extracteur interroge le site et récupère le code HTML brut.
- Analyse : Il lit le DOM de la page — cette structure en arbre qui organise chaque élément.
- Extraction : Il vise les infos voulues (prix, noms, e-mails…) et les range dans un tableau structuré (CSV, Excel, Google Sheets…) (Thunderbit Blog).
Comprendre le DOM : la base de l'extraction de données web
Le DOM, c'est l'arbre généalogique d'une page web. Tout en haut, le document, puis les branches <html>, <head>, <body>, etc. — jusqu'à chaque <div>, <span> et bout de texte (Dataprixa). Chaque nœud est un élément que vous pouvez viser.
Pour attraper le prix d'un produit, l'extracteur va chercher un <span class="price"> niché dans un <div> du <body>. C'est comme dire à votre assistant : « Va dans la cuisine, ouvre le frigo, trouve le lait. » Le DOM, c'est la carte ; l'extracteur, l'explorateur.
Attention toutefois : beaucoup de sites modernes s'appuient sur JavaScript pour charger leur contenu à la volée. Les données recherchées ne figurent parfois pas dans le HTML de base ; elles n'apparaissent qu'une fois la page chargée et les scripts exécutés. Votre extracteur doit donc analyser le DOM rendu, et non le seul HTML brut (Dataprixa). C'est là que bien des outils classiques calent, et que les solutions modernes creusent l'écart.
Les pièges classiques de l'extraction de données web (et comment les esquiver)
Le web scraping n'est pas toujours un long fleuve tranquille. Voici les difficultés les plus fréquentes, et comment passer au travers :
- Contenu dynamique & scroll infini : Beaucoup de sites chargent leurs données à la volée ou imposent de scroller. Un extracteur limité au HTML de base laisse filer la moitié des infos. La parade : des outils qui gèrent le JavaScript ou simulent le scroll (Thunderbit le fait d'office) (Thunderbit Blog).
- Pagination & sous-pages : Les infos s'étalent parfois sur plusieurs pages ou se cachent dans des pages de détail. Vérifiez que votre outil sait cliquer sur « Suivant » et explorer les sous-pages : la fonction « Extraire les sous-pages » de Thunderbit est faite pour ça (Thunderbit Blog).
- Changements de structure du site : Un remaniement de mise en page peut casser les extracteurs classiques. Les outils IA comme Thunderbit s'ajustent d'eux-mêmes, fini les scripts à réparer en boucle (Thunderbit Blog).
- Anti-scraping : CAPTCHA, blocages d'IP, limitations de requêtes… peuvent vous couper net. Extrayez avec mesure (ralentissez, variez les requêtes), privilégiez les outils qui imitent la navigation humaine, et respectez les conditions du site (Medium).
- Données désordonnées ou incohérentes : Tous les sites ne sont pas bien rangés. Des instructions IA ou des règles sur mesure sont parfois nécessaires pour extraire la bonne information (le Field AI Prompt de Thunderbit excelle là-dessus).
Gérer les pages dynamiques et le rendu JavaScript
Certaines pages ne livrent pas tout d'un coup — elles s'appuient sur JavaScript pour charger davantage d'infos au fil de votre scroll ou de vos clics. Les extracteurs classiques passent à côté, mais les extensions navigateur (comme Thunderbit) voient ce que vous voyez et récupèrent tout, même sur du scroll infini ou des pop-ups (ScrapingBee).
Contourner les protections anti-scraping
En cas de blocage ou de CAPTCHA, ralentissez vos requêtes, changez d'IP et misez sur des outils qui simulent la navigation humaine. Et vérifiez toujours les conditions d'utilisation et le robots.txt du site (ScrapingBee).
Comparatif des outils d'extraction de données web : Thunderbit vs solutions classiques
Il existe mille façons d'extraire des données, certaines plus simples que d'autres. Voici un comparatif des principales méthodes :
| Solution | Temps de mise en place | Compétences requises | Maintenance | Fonctionnalités & export |
|---|---|---|---|---|
| Copier-coller manuel | Aucun | Aucune | Manuel permanent | Pas d’automatisation ; erreurs fréquentes |
| Code personnalisé (Python, etc.) | Heures à jours | Programmation + HTML | Élevée | Flexible ; export partout ; courbe d’apprentissage importante |
| Outils no-code classiques | ~1h/site | Quelques notions tech | Moyenne | Interface visuelle ; gère la pagination ; apprentissage modéré |
| Thunderbit (IA no-code) | Quelques minutes | Aucune (français simple) | Faible (IA s’adapte) | Détection IA des champs ; sous-pages ; planification ; export vers Sheets/Excel/Notion |
Thunderbit tire son épingle du jeu auprès des professionnels par sa simplicité. Aucun code : vous expliquez votre besoin, l'IA prend le relais (Thunderbit Blog).
Pourquoi Thunderbit est parfait pour les utilisateurs métier
- Ultra-simple en deux clics : « IA : suggérer les champs », puis « Extraire ». Point.
- Reconnaissance IA des champs : L'IA analyse la page et propose les meilleures colonnes — plus besoin de deviner.
- No-code, langage naturel : Tapez ce que vous voulez (« Récupérer tous les noms et prix des produits »), Thunderbit s'en charge.
- Automatisation sous-pages & pagination : Toutes les pages et les liens de détail en un clic.
- Export éclair : Les données direct vers Excel, Google Sheets, Notion ou Airtable — sans frais cachés.
- Mode cloud ou navigateur : Extraction rapide dans le cloud, ou dans votre navigateur pour les pages qui exigent une connexion.
Thunderbit est pensé pour la vraie vie : sites qui bougent, données pas toujours nettes, utilisateurs qui veulent des résultats plutôt que des galères.
Tutoriel pas à pas : extraire des données web avec Thunderbit
Prêt à passer à l'action ? Voici comment extraire des données de n'importe quel site avec Thunderbit :
Étape 1 : Installez l'extension Chrome Thunderbit
Rendez-vous sur le Chrome Web Store et ajoutez Thunderbit. Créez un compte gratuit — l'offre de base suffit pour tester sur quelques pages.
Essayer Thunderbit gratuitement
Étape 2 : Allez sur le site cible
Ouvrez le site à extraire. Connectez-vous si besoin, scrollez ou cliquez pour faire apparaître toutes les données voulues.
Étape 3 : Ouvrez Thunderbit et décrivez votre besoin
Cliquez sur l'icône Thunderbit. Deux options :
- « IA : suggérer les champs » pour laisser l'IA analyser la page et proposer les colonnes.
- Ou une instruction sur mesure : « Extraire le nom du produit, le prix et les avis. »
Thunderbit affiche un aperçu des champs trouvés. Libre à vous de renommer, supprimer ou ajouter des colonnes selon vos besoins.
Étape 4 : Lancez l'extraction
Cliquez sur « Extraire ». Thunderbit rassemble les données dans un tableau. En présence de plusieurs pages ou sous-pages, il propose de tout extraire — acceptez.
Étape 5 : Vérifiez et exportez
Contrôlez le résultat. S'il manque des données, reformulez votre instruction ou vérifiez que tout le contenu est affiché. Une fois satisfait, cliquez sur « Exporter » pour télécharger en CSV ou envoyer direct vers Google Sheets, Excel, Notion ou Airtable.
Exemple concret : extraire les avis Amazon avec Thunderbit
Supposons que vous vouliez analyser les avis d'un produit concurrent sur Amazon. Voici comment Thunderbit vous mâche le travail.
- Allez sur la page produit Amazon et cliquez sur « Voir tous les avis ».
- Activez Thunderbit. Si le modèle Amazon Reviews Scraper apparaît, prenez-le : il est déjà calé sur les bons champs (Thunderbit Amazon Reviews Scraper).
- Cliquez sur « Extraire ». Thunderbit récupère noms, notes, textes et dates des avis… sur toutes les pages.
- Exportez. Vous obtenez un tableau prêt pour l'analyse de sentiment, la veille concurrentielle ou un point rapide sur les attentes clients.
Envie de personnaliser ? Passez par une instruction en langage naturel : « Extraire le nom du rédacteur, la note, la date et le texte de l'avis. » L'IA de Thunderbit s'adapte, même si Amazon retouche sa page.
Astuces avancées : personnaliser et automatiser l'extraction de données web
Une fois les bases en main, les fonctions avancées de Thunderbit décuplent votre productivité :
- Field AI Prompts : Des instructions sur mesure pour chaque champ (ex. : « Extraire uniquement les avis 1 ou 2 étoiles » ou « Traduire le texte en anglais »).
- Extraction programmée : Planifiez des extractions régulières (quotidiennes, hebdo…) pour garder vos données à jour — parfait pour la veille tarifaire ou la génération de leads (Thunderbit Blog).
- Auto-remplissage IA : Automatisez le remplissage de formulaires ou les workflows multi-étapes (pratique quand un site réclame une recherche ou une connexion).
- Extraction cloud : Pour les gros volumes, lancez l'extraction dans le cloud, plus rapide et plus fiable.
- Modèles instantanés : Partez de modèles prêts à l'emploi pour les sites populaires comme Amazon, Zillow, Yelp, LinkedIn, etc. (Thunderbit Blog).
Vous pouvez même brancher Thunderbit à vos outils : export vers Google Sheets, partage des résultats ou connexion à d'autres solutions pour automatiser vos flux.
L'avenir de l'extraction de données web : tendances IA et impact business
Les meilleurs outils et logiciels d’extraction web en 2025 Get Started Free
L'IA rebat les cartes de l'extraction de données web :
- Robustesse : Les extracteurs pilotés par IA s'ajustent seuls aux changements de sites — moins de maintenance, moins de coupures (GroupBWT).
- Scraping agentif : Les bots naviguent, cliquent et interagissent comme des humains — de nouvelles sources et de nouveaux workflows s'ouvrent.
- Flux de données continus : Les entreprises passent du scraping ponctuel aux pipelines en temps réel.
- Accessibilité : Les outils no-code et en langage naturel comme Thunderbit mettent l'extraction à la portée de tous.
- Analyse instantanée : La prochaine étape ? Extraire et analyser dans la foulée — récupérer les avis concurrents, par exemple, et obtenir directement un résumé des principaux irritants.
En résumé : l'extraction de données web propulsée par l'IA devient aussi incontournable que les tableurs ou les CRM. Les équipes qui la maîtrisent prendront une longueur d'avance, les autres en resteront au copier-coller.
Conclusion & points clés à retenir
- L'extraction de données web transforme Internet en base de données personnelle — leads, prix, avis récupérés automatiquement.
- Le DOM est le plan de chaque page web ; le comprendre, c'est la base pour extraire efficacement.
- Les pièges classiques (contenu dynamique, protections anti-bot, données désordonnées) se gèrent avec les bons outils et un peu d'expérience.
- Thunderbit rend l'extraction accessible à tous : deux clics, détection IA des champs, extraction des sous-pages, export instantané.
- L'IA, c'est l'avenir : une extraction plus rapide, plus intelligente et plus fiable.
Envie de tester ? Télécharge Thunderbit et vois par toi-même à quel point l'extraction peut être simple. Pour plus d'astuces et de cas concrets, fais un tour sur le blog Thunderbit.
Commencer l’extraction avec Thunderbit
FAQ
1. C'est quoi l'extraction de données web et comment ça marche ?
L'extraction de données web (web scraping), c'est automatiser la collecte d'infos sur des sites pour les convertir en données structurées, genre un tableau. Ça fonctionne en lisant le DOM, en visant les données voulues, puis en les exportant pour analyse (Thunderbit Blog).
2. Quels sont les plus gros défis de l'extraction de données web ?
Les principales difficultés : contenu dynamique (données chargées en JavaScript), protections anti-scraping (CAPTCHA, blocages IP) et structures brouillonnes. Les outils modernes comme Thunderbit s'appuient sur l'IA et l'extraction via navigateur pour franchir ces obstacles (Medium).
3. Qu'est-ce qui différencie Thunderbit des autres extracteurs web ?
Thunderbit est un extracteur web IA, sans code, pensé pour les professionnels : config en deux clics (« IA : suggérer les champs », puis « Extraire »), instructions en langage naturel, extraction des sous-pages et export instantané vers Excel, Google Sheets, Notion et Airtable (Thunderbit Blog).
4. Je peux utiliser Thunderbit pour extraire des données de sites dynamiques ou multi-pages ?
Bien sûr. Thunderbit gère automatiquement le contenu dynamique (scroll infini, données JavaScript) et extrait plusieurs pages ou sous-pages en un clic (Thunderbit Blog).
5. L'extraction de données web, c'est légal ?
L'extraction de données publiques est en général autorisée, en particulier pour l'intelligence économique, mais vérifiez toujours les conditions d'utilisation et le robots.txt du site. Évitez les données perso ou privées, et extrayez de façon responsable — sans saturer les sites ni enfreindre leurs règles (ScrapingBee).
Bonne extraction — que vos tableaux soient toujours pleins, vos données fraîches, et le copier-coller un lointain souvenir.
Essayer l’Extracteur Web IA Get Started Free
Pour aller plus loin
- Comment extraire des données d'une page web avec Thunderbit
- Comment maîtriser l'extraction automatisée de données avec Thunderbit
- Comment utiliser Thunderbit pour extraire efficacement des images
- Comment utiliser Thunderbit pour automatiser le scraping de blogs
- Octoparse vs. Thunderbit : comparatif 2025 des extracteurs web no-code




