

Mon tableau de bord OpenRouter affichait 47 $ dépensés avant même le déjeuner, un mardi. J’avais à peine lancé une douzaine de tâches de code — rien d’extravagant, juste un peu de refactoring et quelques corrections de bugs. C’est là que j’ai compris que les réglages par défaut d’OpenClaw redirigeaient discrètement chaque interaction, y compris les pings de fond, vers Claude Opus à plus de 15 $ par million de tokens.
Si vous avez déjà vécu ce genre de mauvaise surprise — et d’après les forums, vous n’êtes clairement pas seul (« I already spend 40 dollars and doesn't even use it much », écrivait un utilisateur) — ce guide vous montre la méthode complète d’audit et d’optimisation que j’ai utilisée pour faire baisser ma facture mensuelle d’environ 90 %. Pas juste « passer à un modèle moins cher », mais une vraie analyse systématique pour voir où les tokens partent vraiment, comment les suivre, quels modèles budget tiennent la route pour du vrai travail agentique, et trois configurations prêtes à copier-coller que vous pouvez utiliser tout de suite. Tout le processus m’a pris un après-midi.
Qu’est-ce que l’usage des tokens OpenClaw, et pourquoi est-il si élevé par défaut ?
Les tokens sont l’unité de facturation de toute interaction IA dans OpenClaw. Imagine-les comme de petits blocs de texte — environ 4 caractères anglais par token. Chaque message envoyé, chaque réponse reçue, chaque tâche en arrière-plan déclenchée : tout est facturé en tokens.
Le souci, c’est que les paramètres par défaut d’OpenClaw sont pensés pour la performance maximale, pas pour le coût minimum. Dès l’installation, le modèle principal est réglé sur anthropic/claude-opus-4-5 — l’option la plus chère disponible. Les pings de heartbeat ? Ils tournent eux aussi sur Opus. Les sous-agents lancés pour gérer des tâches annexes ? Eux aussi utilisent Opus. Utiliser Opus pour un simple ping de heartbeat, c’est un peu comme embaucher un neurochirurgien pour poser un pansement. Techniquement possible, mais totalement absurde côté budget.
La plupart des utilisateurs ne se rendent pas compte qu’ils paient le tarif premium pour des tâches de fond minuscules. La configuration par défaut part du principe que tu veux le meilleur modèle pour tout, tout le temps — et elle te facture en conséquence.
Pourquoi réduire l’usage des tokens OpenClaw permet d’économiser bien plus que de l’argent
L’avantage le plus évident, c’est évidemment la baisse des coûts. Mais il y a aussi des bénéfices secondaires qui s’accumulent avec le temps.
Les modèles moins chers sont souvent plus rapides. Gemini 2.5 Flash-Lite tourne à environ 214 tokens par seconde contre 51 pour Opus — soit près de 4 fois plus vite à chaque interaction. GPT-OSS-120B sur Cerebras atteint 1 917 tokens par seconde — environ 35 fois plus rapide qu’Opus. Dans une boucle agentique avec plus de 50 allers-retours d’appels d’outils, cette différence veut dire terminer en quelques minutes au lieu d’attendre le pénible délai d’Opus de 13,6 secondes avant le premier token à chaque requête.
Tu gagnes aussi de la marge avant d’atteindre les limites de débit, tu subis moins de sessions bridées, et tu peux augmenter l’usage sans sentir ton stress grimper à chaque facture.
Économies estimées selon différents profils d’usage :
| Profil utilisateur | Dépense mensuelle estimée (par défaut) | Après optimisation complète | Économies mensuelles |
|---|---|---|---|
| Léger (~10 requêtes/jour) | ~100 $ | ~12 $ | ~88 % |
| Modéré (~50 requêtes/jour) | ~500 $ | ~90 $ | ~82 % |
| Intensif (~200+ requêtes/jour) | ~1 750 $ | ~220 $ | ~87 % |
Ce ne sont pas des chiffres théoriques. Un développeur a documenté une baisse de 600–750 $/mois à 3–4 $/jour — soit une réduction réelle de 90 % — en combinant le routage des modèles avec les correctifs de fuites cachées décrits plus loin dans ce guide.
Anatomie de l’usage des tokens OpenClaw : où part vraiment chaque token
C’est la partie que la plupart des guides d’optimisation sautent, alors que c’est probablement la plus importante. On ne corrige pas ce qu’on ne voit pas.
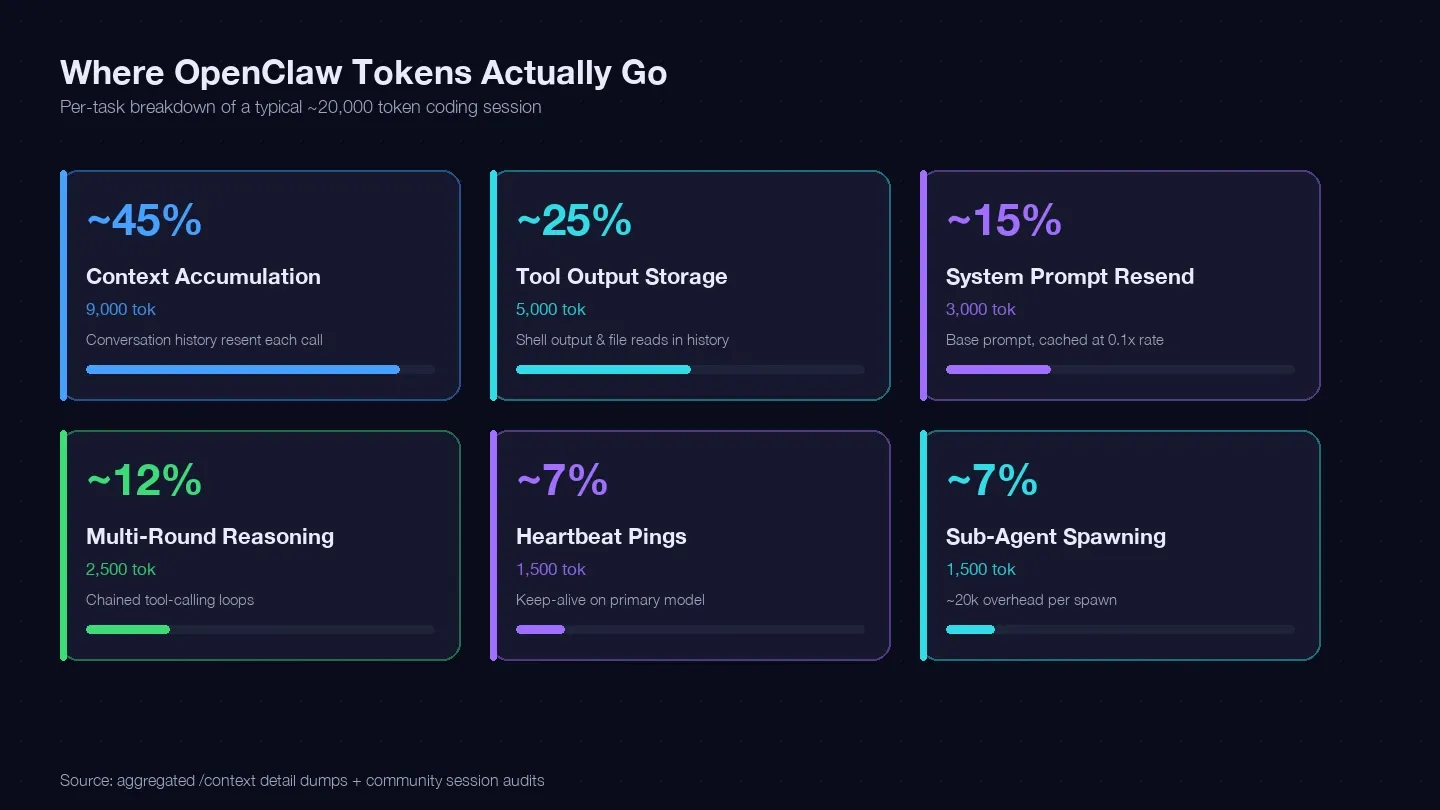
J’ai audité plusieurs sessions et croisé les données avec le guide d’optimisation des coûts de LaoZhang ainsi que des dumps /context de la communauté pour établir un relevé des tokens sur une tâche de code typique. Voilà où sont partis environ 20 000 tokens :
| Catégorie de tokens | Pourcentage typique du total | Exemple (1 tâche de code) | Contrôlable ? |
|---|---|---|---|
| Accumulation du contexte (historique renvoyé à chaque appel) | ~40–50 % | ~9 000 tokens | Oui — /clear, /compact, sessions plus courtes |
| Stockage des sorties d’outils (sortie shell, lectures de fichiers conservées dans l’historique) | ~20–30 % | ~5 000 tokens | Oui — lectures plus ciblées, périmètre d’outils réduit |
| Renvoi du prompt système (~15K de base) | ~10–15 % | ~3 000 tokens | Partiellement — cache à 0,1x |
| Raisonnement multi-tours (boucles d’appels d’outils en chaîne) | ~10–15 % | ~2 500 tokens | Choix du modèle + meilleurs prompts |
| Pings de heartbeat / maintien de connexion | ~5–10 % | ~1 500 tokens | Oui — changement de config |
| Appels de sous-agents | ~5–10 % | ~1 500 tokens | Oui — routage des modèles |
Le plus gros poste — l’accumulation du contexte — correspond à l’historique de conversation renvoyé à chaque appel API. Un vrai dump de session montrait 185 400 tokens rien que dans la catégorie Messages, alors que le modèle n’avait même pas encore répondu. Le prompt système et les outils ajoutaient encore environ 35 800 tokens de surcharge fixe par-dessus.
À retenir : si tu ne vides pas les sessions entre des tâches sans lien entre elles, tu paies pour retransmettre tout ton historique de conversation à chaque tour.
Comment suivre l’usage des tokens OpenClaw (on ne peut pas réduire ce qu’on ne voit pas)
Avant de changer quoi que ce soit, commence par obtenir de la visibilité sur l’endroit où vont tes tokens. Passer direct à « utiliser un modèle moins cher » sans suivi, c’est comme vouloir maigrir sans jamais monter sur une balance.
Consultez votre tableau de bord OpenRouter
Si vous passez par OpenRouter, la page Activity est le tableau de bord le plus simple, sans configuration. Tu peux filtrer par modèle, fournisseur, clé API et période. La vue Usage Accounting détaille les tokens de prompt, de completion, de raisonnement et mis en cache pour chaque requête. Un bouton Export (CSV ou PDF) est disponible pour une analyse sur une période plus longue.
Ce qu’il faut surveiller : quel modèle a consommé le plus de tokens, et si les requêtes heartbeat ou sub-agent apparaissent comme des lignes de coût anormalement élevées.
Auditez vos logs API locaux
OpenClaw stocke les données de session dans ~/.openclaw/agents.main/sessions/sessions.json, avec le champ totalTokens par session. Vous pouvez aussi lancer openclaw logs --follow --json pour un suivi en temps réel de chaque requête.
Point important à connaître : sessions.json totalTokens n’est pas mis à jour après la compaction, donc le tableau de bord peut afficher des valeurs obsolètes d’avant compaction. Fiez-vous à /status et /context detail plutôt qu’aux totaux enregistrés.
Utilisez un outil tiers de suivi (pour les utilisateurs modérés à intensifs)
LiteLLM proxy vous donne un point de terminaison compatible OpenAI devant plus de 100 fournisseurs et journalise automatiquement les dépenses par clé virtuelle, modèle, utilisateur et équipe. Son gros avantage : des budgets stricts par clé qui survivent à /clear — un sous-agent incontrôlé ne peut pas dépasser le plafond défini.
Helicone est encore plus simple — un changement d’URL de base en une ligne qui vous fournit une vue Sessions regroupant les requêtes liées. Une seule requête « corrige ce bug » qui se propage en plus de 8 appels de sous-agents apparaît comme une seule ligne de session avec le vrai coût total. Offre gratuite : 10 000 requêtes/mois.
Vérifications rapides directement dans OpenClaw
Pour le suivi au quotidien, quatre commandes en session suffisent :
/status— affiche l’usage du contexte, les derniers tokens d’entrée/sortie et le coût estimé/usage full— pied de page d’usage par réponse/context detail— détail des tokens par fichier, compétence et outil/compact [guidance]— compaction forcée avec chaîne d’orientation optionnelle
Lancez /context detail avant et après vos changements de configuration. C’est comme ça que vous mesurez si vos optimisations fonctionnent vraiment.
Le comparatif du modèle OpenClaw le moins cher : quels LLM budget gèrent vraiment le travail agentique ?
La plupart des guides se plantent à cet endroit. Ils affichent un tableau de prix, désignent la ligne la moins chère, et s’arrêtent là. Les benchmarks ne prédisent pas les performances réelles en mode agentique — un point que la communauté rappelle bruyamment et souvent. Comme l’a dit un utilisateur : « benchmarks aren't doing any justice to understand which one works best for agentic AI. »
L’idée clé : le modèle le moins cher n’est pas forcément le résultat le moins cher. Un modèle qui plante et recommence quatre fois coûte plus cher qu’un modèle milieu de gamme qui réussit du premier coup. Dans les systèmes d’agents en production, il faut prévoir un taux de retry de 5 à 10 % — et si cinq appels LLM s’enchaînent et que l’étape 4 échoue, un retry naïf relance les cinq étapes.
Voici ma matrice de capacités, avec un « Real Agentic Score » basé sur des retours réels d’utilisateurs plutôt que sur des benchmarks synthétiques :
| Modèle | Entrée $/1M | Sortie $/1M | Fiabilité des appels d’outils | Raisonnement multi-étapes | Score agentique réel (1–5) | Idéal pour |
|---|---|---|---|---|---|---|
| Gemini 2.5 Flash-Lite | $0,10 | $0,40 | Mitigée — boucles occasionnelles | Basique | ⭐2,5 | Heartbeats, recherches simples |
| GPT-OSS-120B | $0,04 | $0,19 | Correcte | Correcte | ⭐3,0 | Expérimentation à petit budget, tâches sensibles à la vitesse |
| DeepSeek V3.2 | $0,26 | $0,38 | Inconstante (6 issues ouvertes) | Bonne | ⭐3,0 | Raisonnement intensif, peu d’appels d’outils |
| Kimi K2.5 | $0,38 | $1,72 | Bonne (via :exacto) | Correcte | ⭐3,5 | Codage simple à intermédiaire |
| MiniMax M2.5 / M2.7 | $0,28 | $1,10 | Bonne | Bonne | ⭐4,0 | Modèle quotidien pour le code général |
| Claude Haiku 4.5 | $1,00 | $5,00 | Excellente | Bonne | ⭐4,5 | Fallback milieu de gamme fiable |
| Claude Sonnet 4.6 | $3,00 | $15,00 | Excellente | Excellente | ⭐5,0 | Tâches complexes multi-étapes |
| Claude Opus 4.5/4.6 | $5,00 | $15,00 | Excellente | Excellente | ⭐5,0 | À réserver aux problèmes les plus difficiles |
Mise en garde sur DeepSeek et Gemini Flash pour les appels d’outils
DeepSeek V3.2 a l’air excellent sur le papier — 72 à 74 % sur SWE-Bench, 11 à 36 fois moins cher que Sonnet. En pratique, six issues GitHub distinctes dans Cline, Roo Code, Continue et NVIDIA NIM documentent un comportement cassé des appels d’outils. Le verdict de Composio en face-à-face : « DeepSeek V3.2 built parts of the app but stumbled on execution, speed, and reliability. » La formule de Zvi Mowshowitz : « okay and cheap, but. »
Gemini 2.5 Flash montre un écart similaire. Un fil du Google AI Developers Forum intitulé « Very frustrating experience with Gemini 2.5 function calling performance » commence ainsi : « the function calling behavior of Gemini models has become completely unreliable and unpredictable. »
OpenRouter a signalé une nuance essentielle : « the propensity of a model to call tools and the accuracy of those calls can vary dramatically across hosts of the same weights. » Si vous routez des modèles bon marché via OpenRouter, surveillez le tag :exacto — un changement silencieux de fournisseur peut transformer du jour au lendemain un modèle économique fiable en boucle de retry coûteuse.
Quand utiliser chaque modèle
- Gemini Flash-Lite : Heartbeats, pings de maintien, Q&R simples. Jamais pour des appels d’outils multi-étapes.
- MiniMax M2.5/M2.7 : Votre modèle quotidien pour les tâches de code générales. SWE-Pro 56.22, Terminal-Bench 2 57,0 % à une fraction du prix de Sonnet.
- Claude Haiku 4.5 : Le fallback fiable quand les modèles bon marché peinent sur les appels d’outils. Excellente fiabilité, environ 3 fois moins cher que Sonnet.
- Claude Sonnet 4.6 : Pour les travaux agentiques complexes en plusieurs étapes. C’est là que vous en avez pour votre argent.
- Claude Opus : À réserver aux problèmes les plus difficiles. Ne le laissez jamais comme modèle par défaut.
(Les prix des modèles changent souvent — vérifiez les tarifs actuels sur OpenRouter ou sur les pages des fournisseurs avant d’adopter une configuration.)
Les drains cachés de tokens que la plupart des guides passent sous silence
Les utilisateurs sur les forums disent souvent que désactiver certaines fonctions réduit énormément les coûts, mais aucun guide que j’ai trouvé ne propose une checklist unifiée de tous les drains cachés avec leur impact réel en tokens. Voici le démontage complet :
| Drain caché | Coût en tokens par occurrence | Comment corriger | Clé de config |
|---|---|---|---|
| Heartbeat par défaut sur Opus | ~100 000 tokens par exécution sans isolement | Override vers Haiku + isolatedSession | heartbeat.model, heartbeat.isolatedSession: true |
| Création de sous-agents | ~20 000 tokens par spawn avant tout travail | Router les sous-agents vers Haiku | subagents.model |
| Chargement complet du contexte du codebase | ~3 000–15 000 tokens par auto-exploration | .clawignore pour node_modules, dist, lockfiles | .clawrules + .clawignore |
| Auto-résumé mémoire | ~500–2 000 tokens/session | Désactiver ou réduire la fréquence | memory: false ou memory.max_context_tokens |
| Accumulation de l’historique de conversation | ~500+ tokens/tour (cumulatif) | Démarrer de nouvelles sessions entre tâches sans lien | Discipline avec /clear |
| Surcharge des outils MCP | ~7 000 tokens pour 4 serveurs ; 50 000+ pour 5+ | Garder un MCP minimal | Supprimer les MCP inutilisés |
| Initialisation des skills/plugins | 200–1 000 tokens par skill chargé | Désactiver les skills inutilisés | skills.entries.<name>.enabled: false |
| Agent Teams (mode plan) | ~7x le coût d’une session standard | À utiliser seulement pour du vrai travail parallèle | Préférer le séquentiel |
Le drain du heartbeat mérite qu’on s’y attarde. Par défaut, les heartbeats partent sur le modèle principal (Opus) toutes les 30 minutes. Définir isolatedSession: true fait passer ce coût d’environ 100 000 tokens par exécution à 2 000–5 000 tokens — soit une réduction de 95 à 98 % sur ce seul poste.
Trois gains rapides qui économisent le plus de tokens en moins de deux minutes
Les trois sont sans risque et prennent moins de deux minutes :
-
/clearentre les tâches sans lien (5 secondes). C’est l’économie la plus importante. Le consensus des forums l’estime à 50–70 % de réduction rien qu’en effaçant l’historique de session avant de commencer un nouveau travail. Tu te souviens du bloc Messages de 185k tokens dans le dump /context ?/clearl’efface. -
/model haiku-4.5pour le travail répétitif (10 secondes). Changer de modèle de façon tactique permet 60–80 % de réduction de coût sur les tâches courantes. Haiku gère très bien la plupart des tâches de codage simples, les recherches de fichiers et les messages de commit. -
Réduire
.clawrulesà moins de 200 lignes + ajouter.clawignore(90 secondes). Ton fichier de règles est chargé à chaque message. À 200 lignes, cela représente environ 1 500–2 000 tokens par tour ; à 1 000 lignes, 8 000–10 000 tokens qui plombent chaque requête en continu. Combiné à un.clawignorequi exclutnode_modules/,dist/, les lockfiles et le code généré, un développeur affirme avoir obtenu une réduction de 92 % des tokens grâce à cette seule discipline.
Étape par étape : trois configurations prêtes à copier pour réduire drastiquement l’usage des tokens OpenClaw

Voici trois configurations complètes et commentées de openclaw.json — de « je veux juste démarrer » à « stack d’optimisation complète ». Chacune inclut des commentaires en ligne et une estimation du coût mensuel.
Avant de commencer :
- Niveau de difficulté : Débutant (Config A) → Intermédiaire (Config B) → Avancé (Config C)
- Temps requis : ~5 minutes pour la Config A, ~15 minutes pour la Config C
- Ce qu’il vous faut : OpenClaw installé, un éditeur de texte, accès à
~/.openclaw/openclaw.json
Config A : Débutant — simplement économiser de l’argent
Cinq lignes. Zéro prise de tête. Remplace le modèle par défaut d’Opus par Sonnet, désactive la surcharge mémoire et isole les heartbeats sur Haiku.
// ~/.openclaw/openclaw.json
{
"agents": {
"defaults": {
"model": { "primary": "anthropic/claude-sonnet-4-6" }, // c’était Opus — économies immédiates de 3 à 5x
"heartbeat": {
"every": "55m", // aligné sur un TTL de cache d’1h pour maximiser les hits
"model": "anthropic/claude-haiku-4-5", // Haiku pour les pings, pas Opus
"isolatedSession": true // ~100k → 2-5k tokens par exécution
}
}
},
"memory": { "enabled": false } // économise ~500–2k tokens/session
}
Ce que tu devrais voir après l’avoir appliqué : Lance /status avant et après. Ton coût par requête devrait baisser nettement, et les entrées heartbeat dans ta page Activity OpenRouter devraient afficher Haiku au lieu d’Opus.
| Niveau d’usage | Par défaut (Opus) | Config A (Sonnet + heartbeats Haiku) | Économies |
|---|---|---|---|
| Léger (~10 requêtes/jour) | ~100 $ | ~35 $ | 65 % |
| Modéré (~50 requêtes/jour) | ~500 $ | ~250 $ | 50 % |
| Intensif (~200 requêtes/jour) | ~1 750 $ | ~900 $ | 49 % |
Config B : Intermédiaire — routage intelligent à trois niveaux
Sonnet en principal pour le vrai travail. Haiku pour les sous-agents et la compaction. Gemini Flash-Lite comme fallback économique quand Claude est limité. Les chaînes de fallback gèrent automatiquement les pannes de fournisseur.
{
"agents": {
"defaults": {
"model": {
"primary": "anthropic/claude-sonnet-4-6",
"fallbacks": [
"anthropic/claude-haiku-4-5", // si Sonnet est limité
"google/gemini-2.5-flash-lite" // ultime recours ultra-économique
]
},
"models": {
"anthropic/claude-sonnet-4-6": {
"params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
}
},
"heartbeat": {
"every": "55m", // 55 min < TTL cache 1h = hits de cache
"model": "google/gemini-2.5-flash-lite", // quelques centimes par ping
"isolatedSession": true,
"lightContext": true // contexte minimal dans les appels heartbeat
},
"subagents": {
"maxConcurrent": 4, // au lieu de 8 par défaut
"model": "anthropic/claude-haiku-4-5" // les sous-agents n’ont pas besoin de Sonnet
},
"compaction": {
"mode": "safeguard",
"model": "anthropic/claude-haiku-4-5", // résumés de compaction via Haiku
"memoryFlush": { "enabled": true }
}
}
}
}
Résultat attendu : Les entrées de sous-agents dans vos logs devraient maintenant être facturées au tarif Haiku. Les heartbeats devraient coûter presque rien. Votre chaîne de fallback garantit qu’une panne Claude ne bloque pas la session — elle bascule proprement sur Gemini.
| Niveau d’usage | Par défaut | Config B | Économies |
|---|---|---|---|
| Léger | ~100 $ | ~20 $ | 80 % |
| Modéré | ~500 $ | ~150 $ | 70 % |
| Intensif | ~1 750 $ | ~500 $ | 71 % |
Config C : Utilisateur avancé — stack d’optimisation complète
Assignation de modèle par sous-agent, compaction du contexte verrouillée sur Haiku, routage vision vers Gemini Flash, .clawrules + .clawignore serrés, skills inutilisés désactivés. C’est la configuration qui permet d’atteindre 85 à 90 % d’économies.
{
"agents": {
"defaults": {
"workspace": "~/clawd",
"model": {
"primary": "anthropic/claude-sonnet-4-6",
"fallbacks": [
"openrouter/anthropic/claude-sonnet-4-6", // autre fournisseur en secours
"minimax/minimax-m2-7", // fallback économique pour usage quotidien
"anthropic/claude-haiku-4-5" // dernier recours
]
},
"models": {
"anthropic/claude-sonnet-4-6": {
"params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
},
"minimax/minimax-m2-7": {
"params": { "maxTokens": 8192 }
}
},
"heartbeat": {
"every": "55m",
"model": "google/gemini-2.5-flash-lite",
"isolatedSession": true,
"lightContext": true,
"activeHours": "09:00-19:00" // pas de heartbeats la nuit
},
"subagents": {
"maxConcurrent": 4,
"model": "anthropic/claude-haiku-4-5"
},
"contextPruning": { "mode": "cache-ttl", "ttl": "1h" },
"compaction": {
"mode": "safeguard",
"model": "anthropic/claude-haiku-4-5",
"identifierPolicy": "strict",
"memoryFlush": { "enabled": true }
},
"bootstrapMaxChars": 12000, // au lieu de 20000 par défaut
"imageModel": "google/gemini-3-flash" // tâches vision via modèle économique
}
},
"memory": { "enabled": true, "max_context_tokens": 800 }, // mémoire minimale
"skills": {
"entries": {
"web-search": { "enabled": false },
"image-generation": { "enabled": false },
"audio-transcribe": { "enabled": false }
}
}
}
Exemple d’override par sous-agent — à coller dans ~/.openclaw/agents/lint-runner/SOUL.md :
---
name: lint-runner
description: Runs lint/format checks and applies trivial fixes
tools: [Bash, Read, Edit]
model: anthropic/claude-haiku-4-5
---
.clawignore minimal viable — à lui seul, il fait généralement passer les bootstraps de 150k caractères à 30–50k :
node_modules/
dist/
build/
.next/
coverage/
.venv/
vendor/
*.lock
package-lock.json
yarn.lock
pnpm-lock.yaml
*.min.js
*.min.css
**/__snapshots__/
**/*.snap
| Niveau d’usage | Par défaut | Config C | Économies |
|---|---|---|---|
| Léger | ~100 $ | ~12 $ | 88 % |
| Modéré | ~500 $ | ~90 $ | 82 % |
| Intensif | ~1 750 $ | ~220 $ | 87 % |
Ces chiffres collent avec deux retours indépendants d’utilisateurs réels : la baisse documentée de Praney Behl, de 600–750 $/mois à 3–4 $/jour (réduction de 90 %), et les études de cas LaoZhang montrant 943 $ → 347 $ (63 %), 1 750 $ → 1 000 $ (64 %), 200 $ → 70 $ (65 %) avec une optimisation partielle.
Utiliser la commande /model pour contrôler l’usage des tokens OpenClaw à la volée
La commande /model change le modèle actif pour le prochain tour tout en conservant tout le contexte de conversation — pas de reset, pas d’historique perdu. C’est l’habitude quotidienne qui fait baisser la facture sur la durée.
Flux de travail pratique :
- Tu travailles sur un refactoring compliqué dans plusieurs fichiers ? Reste sur Sonnet.
- Une question rapide du genre « que fait cette regex ? » ?
/model haiku, pose la question, puis/model sonnetpour revenir. - Message de commit ou polissage d’un document ?
/model flash-lite, et c’est réglé.
Vous pouvez créer des alias dans openclaw.json sous commands.aliases pour associer des noms courts (haiku, sonnet, opus, flash) aux chaînes complètes du fournisseur. Quelques frappes en moins à chaque changement.
Le calcul : 50 requêtes/jour sur Sonnet, c’est environ 3 $/jour. Les mêmes 50 requêtes réparties à 70/20/10 entre Haiku/Sonnet/Opus reviennent à environ 1,10 $/jour. Sur un mois, on passe de 90 $ à 33 $ — 63 % de moins sans changer d’outils, juste d’habitudes.
Bonus : suivre les prix des modèles OpenClaw selon les fournisseurs avec Thunderbit
Suivez les prix des modèles selon les fournisseurs avec l’IA Get Started Free
Avec autant de modèles et de fournisseurs — OpenRouter, API Anthropic directe, Google AI Studio, DeepSeek, MiniMax — les prix changent souvent. Anthropic a réduit le prix de sortie d’Opus d’environ 67 % du jour au lendemain. Google a abaissé les limites du niveau gratuit Gemini de 50 à 80 % en décembre 2025. Garder à jour un tableau de prix statique à la main, c’est presque une bataille perdue d’avance.
Thunderbit règle ce problème sans aucune ligne de scraping. C’est une extension Chrome de type extracteur web IA, conçue justement pour ce genre d’extraction de données structurées.
Le flux de travail que j’utilise :
- Ouvre la page des modèles OpenRouter dans Chrome et clique sur « AI Suggest Fields » de Thunderbit. L’outil lit la page et propose des colonnes — nom du modèle, prix d’entrée, prix de sortie, fenêtre de contexte, fournisseur.
- Lance l’extraction, puis exporte directement vers Google Sheets.
- Programme une extraction récurrente en langage naturel — « chaque lundi à 9 h, réextrait la liste des modèles OpenRouter » — et elle s’exécute automatiquement dans le cloud.
À partir de là, ton tracker de prix personnel se met à jour tout seul. Tout modèle qui devient soudain 30 % moins cher — ou tout fournisseur qui obtient un tag Exacto — apparaît dans ta feuille du lundi matin sans que tu aies à lever le petit doigt. Nous avons détaillé d’autres cas d’usage de l’extraction de données IA pour les entreprises sur notre blog.
Si tu compares les prix sur les pages directes des fournisseurs (Anthropic, Google, DeepSeek) ? Le scraping des sous-pages de Thunderbit suit chaque lien de modèle vers sa page de détail et récupère les tarifs par fournisseur — pratique pour savoir si router Kimi K2.5 via OpenRouter revient moins cher que de passer en direct par NVIDIA Build. Consulte les tarifs Thunderbit pour les détails de l’offre gratuite et des abonnements.
Points clés pour réduire l’usage des tokens OpenClaw
La méthode : Comprendre → Surveiller → Router → Optimiser.
Actions à plus fort impact, classées :
- Ne laisse pas Opus comme modèle par défaut. Passe ton modèle principal à Sonnet ou MiniMax M2.7. Rien que ça réduit déjà les coûts de 3 à 5 fois.
- Isole les heartbeats. Active
isolatedSession: trueet route les heartbeats vers Gemini Flash-Lite. On passe ainsi d’une fuite d’environ 100k tokens à environ 2–5k. - Route les sous-agents vers Haiku. Chaque lancement charge environ 20k tokens de contexte avant même le début du travail. Évite que ça se fasse sur Opus.
- Utilise
/clearsystématiquement. Gratuit, 5 secondes, et le consensus de la communauté dit que c’est l’action la plus rentable. - Ajoute
.clawignore. Exclurenode_modules, les lockfiles et les artefacts de build réduit fortement le contexte de bootstrap. - Suis avec
/context detailavant et après les changements. Si tu ne mesures pas, tu n’améliores rien.
Le modèle le moins cher dépend de la tâche. Gemini Flash-Lite pour les heartbeats. MiniMax M2.7 pour le codage quotidien. Haiku pour les appels d’outils fiables. Sonnet pour les tâches complexes en plusieurs étapes. Opus seulement pour les problèmes vraiment difficiles — et rien d’autre.
La plupart des lecteurs peuvent obtenir 50 à 70 % d’économies en un seul après-midi avec la Config A ou B. Les 85 à 90 % complets demandent d’empiler tout le reste — routage des modèles, correction des drains cachés, .clawignore, discipline de session — mais c’est faisable, et ça tient dans le temps.
FAQ
1. Combien coûte OpenClaw par mois ?
Cela dépend entièrement de ta configuration, de ton volume d’usage et de tes choix de modèles. Les utilisateurs légers (~10 requêtes/jour) dépensent généralement 5 à 30 $/mois avec optimisation, contre 100 $+ avec les paramètres par défaut. Les utilisateurs modérés (~50 requêtes/jour) se situent entre 90 et 400 $/mois. Les gros utilisateurs peuvent atteindre 600 à 2 000 $+/mois avec les réglages par défaut — un cas extrême documenté a même atteint 5 623 $ en un seul mois. La télémétrie interne d’Anthropic suggère un médian de 13 $/développeur/jour actif.
2. Quel est le modèle OpenClaw le moins cher qui reste bon pour coder ?
MiniMax M2.5/M2.7 est le meilleur modèle quotidien généraliste — fiabilité correcte pour les appels d’outils, SWE-Pro 56,22, pour environ 0,28 $ / 1,10 $ par million de tokens. Pour les heartbeats et les recherches simples, Gemini 2.5 Flash-Lite à 0,10 $ / 0,40 $ est difficile à battre. Claude Haiku 4.5 à 1 $ / 5 $ est le fallback milieu de gamme le plus fiable quand il faut une excellente fiabilité d’appel d’outils sans payer le prix de Sonnet.
3. Puis-je utiliser des modèles gratuits avec OpenClaw ?
Techniquement oui. GPT-OSS-120B est gratuit sur le tag :free d’OpenRouter et sur NVIDIA Build. Gemini Flash-Lite a un niveau gratuit (15 RPM, 1 000 requêtes/jour). DeepSeek offre 5 M de tokens gratuits à l’inscription. Mais les offres gratuites imposent des limites de débit agressives, sont plus lentes et moins fiables en disponibilité. Les modèles payants bon marché — quelques centimes par million de tokens — sont bien plus fiables pour un usage régulier.
4. Changer de modèle en cours de conversation avec /model fait-il perdre le contexte ?
Non. /model conserve tout le contexte de session — la prochaine requête est routée vers le nouveau modèle avec tout l’historique intact. C’est confirmé dans la documentation concepts d’OpenClaw et fonctionne de la même manière dans Claude Code. Tu peux alterner librement entre Haiku pour les questions rapides et Sonnet pour les travaux complexes sans rien perdre.
5. Quel est le moyen le plus rapide de réduire ma facture OpenClaw aujourd’hui ?
Tape /clear entre les tâches sans lien. C’est gratuit, ça prend cinq secondes, et ça efface l’historique de conversation qui est retransmis à chaque appel API. Une vraie session montrait 185 000 tokens d’historique de messages accumulé — tous retransmis et refacturés à chaque tour. Nettoyer ça avant de commencer un nouveau travail est l’habitude la plus rentable que tu puisses adopter.
Essayez Thunderbit pour l’extraction web IA Get Started Free




