

Le web déborde de données, et l’envie de les extraire ne cesse de grandir — même si, quand on cherche un chiffre unique sur la taille du marché, on tombe sur des estimations qui vont du simple au décuple selon que l’analyste compte les logiciels, les services, les proxys, ou les trois à la fois. En toute honnêteté, le web scraping s’est imposé comme un rouage discret, mais essentiel, de la chaîne de traitement des données.
Que vous soyez analyste métier, marketeur ou simple débutant curieux, savoir extraire des données d’un site web devient vite une compétence incontournable. Et si vous êtes comme moi, vous voulez sans doute éviter les interminables copier-coller et aller droit au but : obtenir des insights exploitables, des tableaux propres, et peut-être même un peu de magie de l’automatisation.
C’est là qu’entre en jeu Python. C’est le couteau suisse du monde des données — assez simple pour les débutants, mais assez puissant pour tout gérer, d’une seule page à l’exploration de milliers de pages. Dans ce tutoriel pratique, je vais vous guider à travers les bases du web scraping avec Python, vous montrer comment gérer les sites dynamiques et vous présenter Thunderbit, notre extracteur web sans code propulsé par l’IA, qui rend l’extraction de données aussi simple que de commander un repas à emporter. Que vous soyez là pour apprendre à coder ou simplement pour aller plus vite, vous êtes au bon endroit.
Qu’est-ce que le web scraping et pourquoi utiliser Python pour extraire des données d’un site web ?
Extraire des données de n’importe quel site web avec l’IA Get Started Free
Le web scraping est le processus automatisé qui consiste à extraire des informations de sites web pour les convertir en un format structuré — tableaux, CSV ou bases de données — afin de les analyser ou de les exploiter en entreprise (PromptCloud). Au lieu de copier-coller les données manuellement, un scraper reproduit ce qu’un humain ferait, mais à une vitesse et à une échelle bien supérieures.
Pourquoi est-ce si précieux ? Parce qu’aujourd’hui, dans le monde des affaires, la prise de décision fondée sur les données est devenue la norme. Plus votre entreprise grandit, plus vous cherchez à appuyer vos décisions sur des chiffres réels plutôt que sur des intuitions — et une grande partie de ces chiffres naît d’abord sur la page web de quelqu’un d’autre.
Imaginez pouvoir suivre chaque jour les prix des concurrents, agréger des annonces immobilières ou constituer une liste de prospects sur mesure — sans lever le petit doigt.
Alors, pourquoi Python ? Voici pourquoi c’est le langage de référence pour le web scraping :
- Lisibilité et simplicité : la syntaxe de Python est claire et accessible aux débutants, ce qui facilite l’écriture et la compréhension des scripts de scraping (PromptCloud).
- Écosystème riche : des bibliothèques comme
requests,BeautifulSoup,ScrapyetSeleniumrendent le scraping, l’analyse et l’automatisation des actions dans le navigateur très simples. - Communauté active : Python figure régulièrement comme le langage de programmation le plus populaire au monde, ce qui signifie une abondance de tutoriels, de forums et d’exemples de code pour vous aider.
- Évolutivité : Python peut tout gérer, du script ponctuel simple au crawler à grande échelle.
En bref : Python est votre ticket d’entrée dans l’univers des données web, que vous soyez débutant complet ou analyste chevronné.
Pour commencer : bases du tutoriel Python de web scraping
Avant de plonger dans le code, voyons le flux de travail de base pour extraire des données d’un site web avec Python :
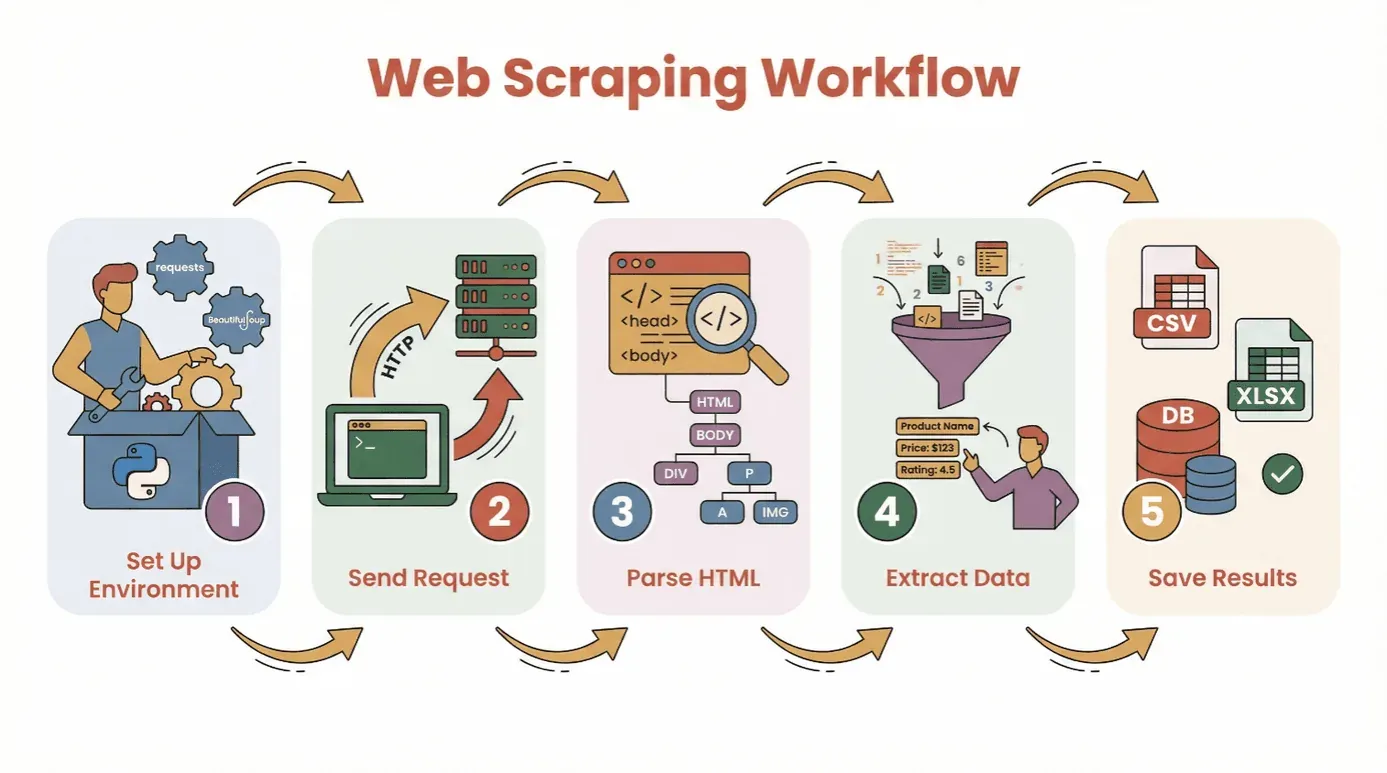
- Préparer votre environnement : installez Python et les bibliothèques nécessaires (
requests,BeautifulSoup, etc.). - Envoyer une requête : utilisez Python pour récupérer le contenu HTML de votre page cible.
- Analyser le HTML : utilisez un parseur pour naviguer dans la structure de la page.
- Extraire les données : repérez et récupérez les informations dont vous avez besoin.
- Enregistrer les résultats : stockez vos données dans un fichier CSV, Excel ou une base de données pour les analyser.
Pas besoin d’être un as du code pour commencer. Si vous savez installer Python et exécuter un script, vous avez déjà fait la moitié du chemin. Pour les débutants complets, je recommande d’utiliser un environnement virtuel ou un notebook Jupyter, mais vous pouvez aussi utiliser n’importe quel éditeur de texte basique.
Bibliothèques essentielles :
requests— pour récupérer des pages webBeautifulSoup— pour analyser le HTMLpandas— pour enregistrer et nettoyer les données (facultatif, mais fortement recommandé)
Choisir la bonne bibliothèque Python de web scraping : BeautifulSoup, Scrapy ou Selenium ?
Tous les outils de scraping Python ne se valent pas. Voici un aperçu rapide des trois options les plus populaires :
| Outil | Idéal pour | Points forts | Inconvénients |
|---|---|---|---|
| BeautifulSoup | Pages simples et statiques ; débutants | Facile à utiliser, configuration minimale, excellente documentation | Peu adapté aux grands crawls ou au contenu dynamique |
| Scrapy | Exploration à grande échelle, multi-pages | Rapide, asynchrone, pipelines intégrés, gère l’exploration et le stockage des données | Courbe d’apprentissage plus raide, excessif pour les petits besoins, ne gère pas JavaScript |
| Selenium | Sites dynamiques, très riches en JavaScript, automatisation | Peut rendre le JS, simuler des actions utilisateur, prend en charge les connexions et les clics | Plus lent, gourmand en ressources, configuration plus complexe |
BeautifulSoup : le choix idéal pour l’analyse HTML simple
BeautifulSoup est parfait pour les débutants et les petits projets. Il permet d’analyser le HTML et d’extraire des éléments en seulement quelques lignes de code. Si votre site cible est surtout statique (sans chargement JavaScript sophistiqué), BeautifulSoup + requests suffit largement.
Exemple :
import requests
from bs4 import BeautifulSoup
url = "https://example.com"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
titles = [h2.text for h2 in soup.find_all('h2', class_='product-title')]
print(titles)
Quand l’utiliser : extractions ponctuelles, blogs simples, pages produit ou annuaires.
Scrapy : pour l’exploration structurée ou à grande échelle
Scrapy est un véritable framework pour explorer des sites entiers ou traiter des milliers de pages. Il est asynchrone (donc rapide), prend en charge des pipelines pour nettoyer et enregistrer les données, et peut suivre automatiquement les liens.
Exemple :
import scrapy
class ProductSpider(scrapy.Spider):
name = "products"
start_urls = ["https://example.com/products"]
def parse(self, response):
for item in response.css('div.product'):
yield {
'name': item.css('h2::text').get(),
'price': item.css('span.price::text').get()
}
Quand l’utiliser : grands projets, extractions planifiées ou besoins de vitesse et de structure.
Selenium : gérer les sites dynamiques et riches en JavaScript
Selenium contrôle un vrai navigateur (comme Chrome ou Firefox), ce qui lui permet de gérer les sites qui chargent les données avec JavaScript, exigent une connexion ou nécessitent des clics sur des boutons.
Exemple :
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://example.com/login")
driver.find_element(By.NAME, "username").send_keys("myuser")
driver.find_element(By.NAME, "password").send_keys("mypassword")
driver.find_element(By.XPATH, "//button[@type='submit']").click()
dashboard = driver.find_element(By.ID, "dashboard").text
print(dashboard)
driver.quit()
Quand l’utiliser : réseaux sociaux, sites boursiers, défilement infini, ou tout site qui semble vide quand vous consultez le code source.
Étape par étape : comment extraire des données d’un site web avec Python (tutoriel débutant)
Voyons un exemple concret avec requests et BeautifulSoup. Nous allons extraire d’un site simple de livres les titres, auteurs et prix.
Étape 1 : préparer votre environnement Python
Commencez par installer les bibliothèques nécessaires :
pip install requests beautifulsoup4 pandas
Puis importez-les dans votre script :
import requests
from bs4 import BeautifulSoup
import pandas as pd
Étape 2 : envoyer une requête au site web
Récupérez le contenu HTML :
url = "http://books.toscrape.com/catalogue/page-1.html"
response = requests.get(url)
if response.status_code == 200:
html = response.text
else:
print(f"Échec de la récupération de la page : {response.status_code}")
Étape 3 : analyser le contenu HTML
Créez un objet BeautifulSoup :
soup = BeautifulSoup(html, 'html.parser')
Repérez tous les conteneurs de livres :
books = soup.find_all('article', class_='product_pod')
print(f"{len(books)} livres trouvés sur cette page.")
Étape 4 : extraire les données dont vous avez besoin
Parcourez chaque livre et récupérez les détails :
data = []
for book in books:
title = book.h3.a['title']
price = book.find('p', class_='price_color').text
data.append({"Title": title, "Price": price})
Étape 5 : enregistrer les données pour l’analyse
Convertissez-les en DataFrame et enregistrez :
df = pd.DataFrame(data)
df.to_csv('books.csv', index=False)
Vous avez maintenant un fichier CSV propre, prêt à être analysé !
Conseils de dépannage :
- Si vous obtenez des résultats vides, vérifiez si les données sont chargées par JavaScript (voir la section suivante).
- Inspectez toujours la structure HTML avec les outils de développement de votre navigateur.
- Gérez les données manquantes avec
get_text(strip=True)et des vérifications conditionnelles.
Gérer le contenu dynamique : extraire des données de sites rendus en JavaScript
Les sites modernes adorent JavaScript. Parfois, les données que vous cherchez ne figurent pas dans le HTML initial — elles se chargent après l’affichage de la page. Si votre scraper ne renvoie rien, vous êtes peut-être face à du contenu dynamique.
Comment gérer cela :
- Selenium : simule un vrai navigateur, attend le chargement du contenu et peut cliquer ou faire défiler la page.
- Playwright/Puppeteer : plus avancés, mais avec la même logique (navigateurs sans interface).
Mini-guide Selenium :
- Installez Selenium et un pilote de navigateur (par exemple ChromeDriver).
- Utilisez des attentes explicites pour laisser le contenu se charger.
- Extrayez le HTML rendu et analysez-le avec BeautifulSoup si nécessaire.
Exemple :
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get("https://example.com/dynamic")
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, "dynamic-content"))
)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
# Extraire les données comme précédemment
driver.quit()
Quand avez-vous besoin de Selenium ?
- Si
requests.get()renvoie un HTML sans données, alors que vous les voyez dans votre navigateur. - Si le site utilise le défilement infini, des pop-ups ou exige une connexion.
Simplifier le web scraping avec l’IA : utiliser Thunderbit pour extraire des données d’un site web
Essayez l’extracteur web IA Thunderbit Extrayez des données de n’importe quel site en 2 clics — sans code. Get Started Free
Soyons honnêtes : parfois, vous voulez juste les données, pas le code. C’est là qu’intervient Thunderbit. Thunderbit est une extension Chrome propulsée par l’IA qui vous permet d’extraire des données de n’importe quel site en quelques clics seulement — sans Python.
Comment fonctionne Thunderbit :
- Installez l’extension Chrome Thunderbit.
- Ouvrez votre site cible.
- Cliquez sur l’icône Thunderbit puis sur « Suggestion de champs IA ». L’IA de Thunderbit analyse la page et recommande les données à extraire (par exemple : noms de produits, prix, emails).
- Ajustez les champs si besoin, puis cliquez sur « Extract ».
- Exportez vos données directement vers Excel, Google Sheets, Notion ou Airtable.
Pourquoi Thunderbit est génial :
- Aucun code requis. Même ma mère peut l’utiliser (et pourtant elle m’appelle encore pour les problèmes de Wi‑Fi).
- Gère les sous-pages et la pagination. Vous devez extraire des fiches produit sur plusieurs pages ? Thunderbit peut cliquer à votre place et fusionner les données.
- Instructions en langage naturel. Dites simplement ce que vous voulez (« extraire tous les titres et prix des produits ») et laissez l’IA s’en charger.
- Modèles instantanés pour les sites populaires. Amazon, Zillow, LinkedIn et bien d’autres — un clic et c’est terminé.
- Export de données gratuit. Téléchargez en CSV, Excel, ou envoyez directement vers vos outils préférés.
Thunderbit est utilisé par plus de 100 000 utilisateurs dans le monde. Il existe une version gratuite que vous pouvez essayer sans payer — consultez la page des tarifs pour connaître les limites actuelles, car elles ont bougé plusieurs fois. Pour les utilisateurs métier, c’est un vrai gain de temps ; pour les adeptes de Python, c’est un excellent moyen de cadrer un besoin avant de décider s’il vaut la peine d’écrire son propre scraper.
Essayez Thunderbit gratuitement – sans code
Après le scraping : nettoyer et analyser les données avec Pandas et NumPy
Extraire les données n’est que la première étape. Les données web brutes sont souvent sales — doublons, valeurs manquantes, formats étranges. C’est là que pandas et NumPy brillent.
Tâches courantes de nettoyage :
- Supprimer les doublons :
df.drop_duplicates(inplace=True) - Gérer les valeurs manquantes :
df.fillna('Unknown')oudf.dropna() - Convertir les types de données :
df['Price'] = df['Price'].str.replace('$','').astype(float) - Analyser les dates :
df['Date'] = pd.to_datetime(df['Date']) - Filtrer les valeurs aberrantes :
df = df[df['Price'] > 0]
Analyse de base :
- Statistiques descriptives :
df.describe() - Regrouper par catégorie :
df.groupby('Category')['Price'].mean() - Graphiques rapides :
df['Price'].hist()oudf.groupby('Category')['Price'].mean().plot(kind='bar')
Pour les calculs plus avancés ou les opérations rapides sur des tableaux, NumPy est votre allié. Mais pour la plupart des utilisateurs métier, pandas couvre 95 % des besoins.
Ressources : si vous découvrez pandas, consultez le guide 10 Minutes to pandas.
Bonnes pratiques et conseils pour réussir votre web scraping en Python
Le web scraping est puissant, mais il implique aussi des responsabilités. Voici ma checklist pour scraper comme un pro — sans se faire bloquer ni poursuivre :
- Respectez robots.txt et les conditions d’utilisation. Vérifiez toujours si le site autorise le scraping (PromptCloud).
- Ne surchargez pas les serveurs. Ajoutez des délais entre les requêtes (
time.sleep(2)) et adoptez un rythme humain. - Utilisez des en-têtes réalistes. Définissez une chaîne User-Agent pour imiter un navigateur.
- Gérez les erreurs avec élégance. Utilisez des blocs try/except et relancez les requêtes échouées.
- Faites tourner des proxys si nécessaire. Pour les extractions à grande échelle, envisagez des pools de proxys pour éviter les bannissements d’IP.
- Restez éthique et légal. N’extrayez pas de données personnelles ni de contenu derrière une connexion sans autorisation.
- Documentez votre processus. Notez ce que vous avez extrait, depuis quelle source et à quel moment.
- Utilisez les API officielles quand elles existent. Parfois, il existe une meilleure solution que l’extraction du HTML.
Pour aller plus loin, consultez le Guide ultime du web scraping.
Conclusion et points clés à retenir
Le web scraping avec Python est un superpouvoir pour quiconque veut transformer le chaos du web en données structurées et exploitables. Que vous utilisiez du code (avec requests, BeautifulSoup, Scrapy ou Selenium) ou un outil sans code comme Thunderbit, vous avez tout ce qu’il faut pour extraire des données d’un site web et en tirer de nouveaux enseignements.
À retenir :
- Commencez simplement — extrayez une seule page avant de vous attaquer aux gros projets.
- Choisissez l’outil adapté à votre besoin (BeautifulSoup pour les bases, Scrapy pour l’échelle, Selenium pour les sites dynamiques, Thunderbit pour le no-code).
- Nettoyez et analysez vos données avec pandas et NumPy.
- Faites toujours du scraping de manière responsable et éthique.
Prêt à essayer vous-même ? Commencez par un petit projet — par exemple extraire les titres du jour ou une liste de produits — et voyez à quelle vitesse vous passez d’une page web brute à un tableau propre. Et si vous voulez éviter le code, téléchargez Thunderbit et laissez l’IA faire le gros du travail.
Pour plus de tutoriels, de conseils et de bonnes pratiques sur le web scraping, consultez le blog Thunderbit.
Lire d’autres tutoriels de web scraping
FAQ
1. Qu’est-ce que le web scraping et pourquoi Python est-il si populaire pour cela ?
Le web scraping consiste à extraire automatiquement des données de sites web. Python est populaire pour le web scraping grâce à sa syntaxe lisible, ses bibliothèques puissantes (comme BeautifulSoup, Scrapy et Selenium) et sa forte communauté (PromptCloud).
2. Quelle bibliothèque Python dois-je utiliser pour le web scraping ?
Utilisez BeautifulSoup pour les pages simples et statiques ; Scrapy pour l’exploration à grande échelle ou multi-pages ; et Selenium pour les sites dynamiques ou riches en JavaScript. Chacune a ses atouts selon vos besoins (IPRoyal).
3. Comment gérer les sites qui chargent les données avec JavaScript ?
Pour le contenu rendu par JavaScript, utilisez Selenium (ou Playwright) afin de simuler un navigateur et d’attendre le chargement du contenu avant d’extraire les données. Parfois, vous pouvez repérer un point d’accès API sous-jacent en analysant le trafic réseau.
4. Qu’est-ce que Thunderbit et comment simplifie-t-il le web scraping ?
Thunderbit est une extension Chrome propulsée par l’IA qui vous permet d’extraire des données de n’importe quel site sans coder. Elle utilise l’IA pour suggérer les champs, gérer les sous-pages et la pagination, et exporter les données directement vers Excel, Google Sheets, Notion ou Airtable.
5. Comment nettoyer et analyser des données extraites en Python ?
Utilisez pandas pour supprimer les doublons, gérer les valeurs manquantes, convertir les types de données et effectuer des analyses. NumPy est excellent pour les opérations numériques. Pour la visualisation, pandas s’intègre à Matplotlib pour des graphiques rapides (10 Minutes to pandas).
Bon scraping — et que vos données soient toujours propres, structurées et prêtes à l’emploi.
Essayer l’extracteur web IA Get Started Free
En savoir plus




