

Optimiser les requêtes de listes Apollo n’est pas juste un sujet technique : c’est une vraie compétence clé pour toute personne qui s’appuie sur des données à jour en temps réel, sur l’extraction automatique d’informations ou sur des workflows commerciaux et opérationnels à gros volume. J’ai pu le voir de mes propres yeux : une requête de liste trop lente peut transformer un tableau de bord fluide en véritable goulot d’étranglement, avec des équipes commerciales bloquées devant des écrans de chargement à rallonge et des équipes ops obligées de bricoler des contournements dans des tableurs. Dans un contexte où 60 % du temps des commerciaux est déjà absorbé par des tâches qui ne vendent pas, chaque milliseconde compte.
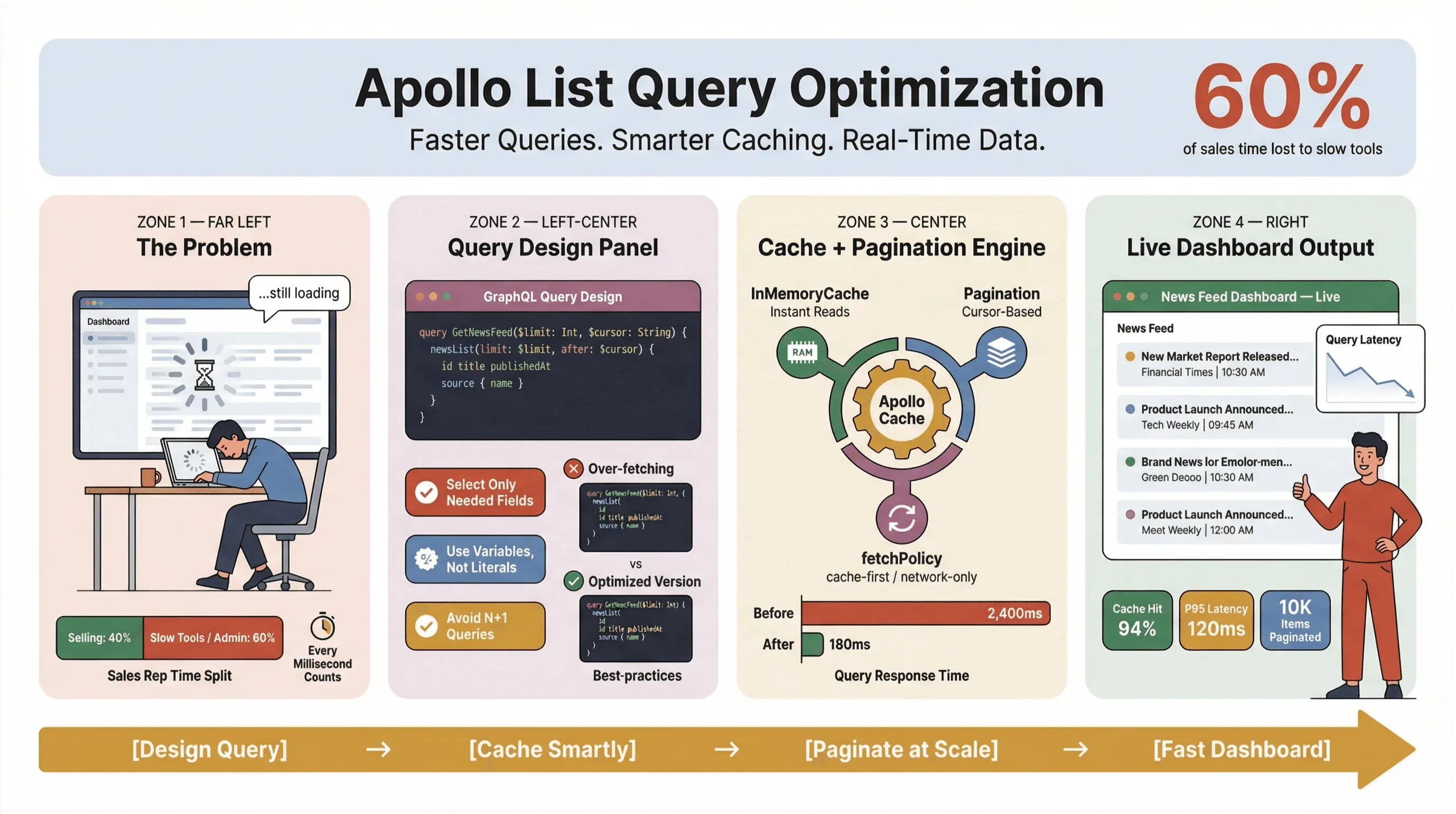
Alors, comment garder des requêtes de listes Apollo Client rapides, fiables et cohérentes à grande échelle — surtout quand vous extrayez des actualités, suivez des leads ou alimentez des tableaux de bord stratégiques ? Dans ce guide, je vais passer en revue les bonnes pratiques qui tiennent vraiment en production : conception des requêtes, cache, pagination et intégration d’outils no-code comme Thunderbit pour automatiser la partie la plus pénible de l’extraction d’actualités.
--- Que vous soyez développeur, chef de produit ou simplement la personne qu’on pointe du doigt quand le tableau de bord rame, voici votre feuille de route pour booster les performances des listes Apollo GraphQL.
Essayez Thunderbit pour l’extraction automatisée d’actualités
Pourquoi optimiser les requêtes de listes Apollo ? (performances des listes Apollo Client, optimiser les requêtes de listes Apollo)
Soyons clairs : personne n’a envie d’attendre le chargement de titres d’actualité ou de leads commerciaux. Dans les environnements métiers — surtout ceux qui s’appuient sur l’extraction automatisée d’actualités ou sur des données en temps réel — des requêtes de listes Apollo trop lentes ne font pas qu’irriter les utilisateurs ; elles coûtent de l’argent, retardent les décisions et renvoient les équipes vers des process manuels. Des recherches régulières de Slack Workforce Lab montrent que les salariés de bureau passent souvent environ un tiers — et, dans des rapports plus récents, près de 40 % — de leur journée sur des tâches répétitives à faible valeur, souvent parce que leurs outils dispersent le travail sur des interfaces lentes.
Voilà ce qui se passe quand les requêtes de liste ne sont pas optimisées :
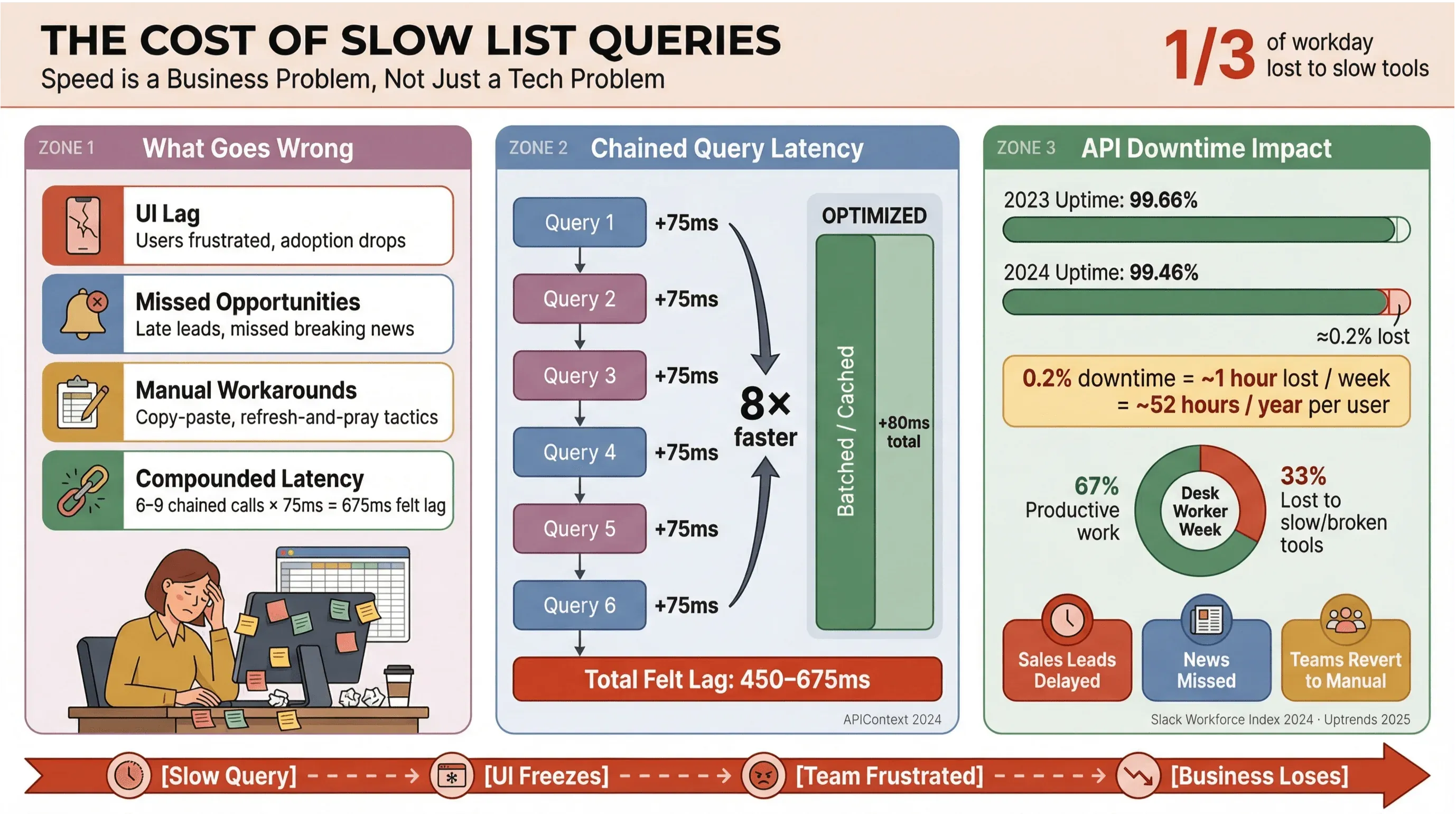
- Interface qui rame : les utilisateurs subissent des délais, ce qui crée de la frustration et freine l’adoption.
- Occasions ratées : en vente ou en veille info, quelques secondes de retard peuvent faire passer à côté d’un lead chaud ou d’une info importante.
- Bidouilles manuelles : les équipes retombent sur le copier-coller, les tableurs ou la stratégie du « rafraîchir et prier ».
- Latence cumulée : chaque appel API lent s’additionne — si votre workflow lance 6 à 9 requêtes dépendantes, un simple retard de 75 ms par appel peut grimper à 450–675 ms de latence ressentie (APIContext).
Et le problème ne se limite pas à la vitesse. Les pannes d’API augmentent, avec une disponibilité moyenne passée de 99,66 % à 99,46 % en seulement un an — soit presque une heure de productivité perdue par semaine pour les applis très dépendantes des listes. Quand votre activité repose sur des données d’actualité en temps réel, c’est un risque que vous ne pouvez pas vous permettre.
Choisir la bonne structure de données et les bons champs (bonnes pratiques Apollo GraphQL pour les listes)
L’une des erreurs les plus courantes que je vois — et oui, je l’ai moi-même faite — consiste à traiter chaque requête de liste comme une requête de détail. Avec GraphQL, vous avez la liberté exacte de récupérer seulement ce qu’il vous faut : autant en profiter. Demander trop de données est l’ennemi de la performance, surtout dans les outils d’extraction d’actualités et les tableaux de bord en temps réel.
Adapter les champs pour l’extraction automatisée d’actualités
Imaginez que vous construisez un fil d’actualité. Avez-vous vraiment besoin du texte complet des articles, de tous les tags, des commentaires et des bios des auteurs dans votre requête de liste ? Probablement pas. Voici la différence :
Requête de liste efficace :
query NewsFeed($after: String, $first: Int) {
newsFeed(after: $after, first: $first) {
edges {
cursor
node {
id
title
url
sourceName
publishedAt
}
}
pageInfo { endCursor hasNextPage }
}
}
Requête de liste inefficace (à éviter) :
query NewsFeedTooHeavy($after: String, $first: Int) {
newsFeed(after: $after, first: $first) {
edges {
node {
id title url publishedAt
fullText
summary
entities { ... }
relatedArticles { ... }
}
}
}
}
La première requête est légère et efficace — parfaite pour le tri, le filtrage et l’affichage des lignes. La seconde ? C’est une requête de détail déguisée, qui transporte des charges utiles énormes et ralentit tout le reste (spécification GraphQL, bonnes pratiques Apollo).
Astuce pro : adoptez une approche en deux temps — récupérez seulement les champs légers dans la liste, puis chargez les détails lourds (comme le texte intégral ou l’enrichissement NLP) uniquement quand l’utilisateur ouvre un élément ou le survole.
Exploiter le cache d’Apollo Client pour accélérer les requêtes (performances des listes Apollo Client)
Le cache d’Apollo Client est le levier le plus puissant pour améliorer les performances des requêtes de liste. Bien configuré, il vous permet de :
- Servir instantanément les requêtes répétées (sans aller-retour réseau)
- Réduire la charge serveur et les coûts API
- Offrir une navigation avant/arrière fluide et des changements de filtres sans friction
Mais le cache n’est pas magique : il demande un minimum de configuration et de rigueur.
Définir des politiques de cache efficaces
Apollo prend en charge plusieurs politiques de récupération :
| Politique | Ce qu’elle fait | Meilleur cas d’usage pour des listes d’actualités |
|---|---|---|
| cache-first | Lit d’abord dans le cache, puis interroge le réseau si nécessaire | Revoir une liste, changer de filtre, naviguer avant/arrière |
| network-only | Récupère toujours les données depuis le réseau | Actualisation manuelle, « dernières actualités » |
| cache-and-network | Renvoie d’abord le cache, puis met à jour avec la réponse réseau | Premier affichage rapide + mise à jour en arrière-plan (idéal pour un fil d’actualité) |
| no-cache | Récupère toujours sans rien stocker dans le cache | Requêtes sensibles ponctuelles (rare pour des listes) |
Pour des données d’actualité en temps réel, j’aime bien cache-and-network : l’utilisateur voit quelque chose tout de suite, puis les données se rafraîchissent en arrière-plan. Attention quand même aux effets de scintillement si vos données se réorganisent au moment du rafraîchissement (ticket GitHub).
Conseils de configuration du cache :
- Utilisez des identifiants stables (
idou_id) pour la normalisation (documentation du cache Apollo). - Ajustez la taille du cache et le garbage collection pour les grandes listes (gestion mémoire).
- Évitez de stocker d’énormes blocs non normalisés sous
ROOT_QUERY— cela peut ralentir votre application (retour de la communauté).
Mettre en place la pagination et limiter le nombre d’éléments (bonnes pratiques Apollo GraphQL pour les listes)
Si vous chargez des centaines ou des milliers d’articles d’actualité ou de leads d’un coup, vous vous exposez à des soucis. La pagination n’est pas seulement un confort UX : c’est une nécessité pour garder de bonnes performances.
Apollo prend en charge la pagination par offset et la pagination par curseur. Voici comment elles se comparent :
| Type de pagination | Avantages | Inconvénients | Le mieux adapté à |
|---|---|---|---|
| Par offset | Simple, facile à mettre en œuvre | Peut sauter ou dupliquer des éléments si les données bougent | Listes petites ou immuables |
| Par curseur | Stable, gère bien les changements de données | Légèrement plus complexe | Fils d’actualité, grandes listes |
Pour la plupart des listes d’actualité en temps réel ou de leads, la pagination par curseur est la meilleure option. Elle garde les données cohérentes même quand de nouveaux éléments arrivent ou que d’anciens disparaissent (GraphQL Foundation).
Conseils de pagination Apollo :
- Configurez
keyArgspour contrôler les clés de cache des champs paginés (docs). - Implémentez une fonction
mergepour fusionner les pages dans le cache. - Utilisez
fetchMorepour charger des pages supplémentaires sans écraser les résultats précédents.
Modèles pratiques de pagination pour les outils d’extraction d’actualités
Une interface classique d’extraction d’actualités va généralement :
- Afficher les 20 à 50 derniers titres (avec seulement des champs légers)
- Charger plus au scroll ou via un clic sur « page suivante »
- Récupérer les détails uniquement quand c’est nécessaire
Résultat : une interface rapide, une API préservée et des utilisateurs plus efficaces.
Intégrer Thunderbit pour l’extraction automatisée d’actualités
Parlons maintenant du cœur du sujet : d’où viennent toutes ces données d’actualité structurées ? C’est là que Thunderbit entre en scène.
Obtenez l’extension Chrome Thunderbit Get Started Free
Thunderbit est une extension Chrome d’extracteur Web IA sans code capable d’extraire des titres d’actualité, des URL, des sources, des auteurs, des dates de publication, des résumés et des images depuis presque n’importe quel site web — sans écrire une seule ligne de code. J’ai vu des équipes utiliser Thunderbit pour automatiser tout le processus d’extraction d’actualités, en transformant des pages web non structurées en données propres et structurées, directement exploitables dans une base de données ou une API GraphQL.
Combiner Thunderbit avec Apollo pour des données d’actualité en temps réel
Voici un workflow que j’aime beaucoup pour les équipes commerciales et ops qui ont besoin d’infos à jour :
- Couche d’extraction : utilisez le modèle News Scraper de Thunderbit pour extraire automatiquement des données d’actualité structurées depuis les sites ciblés selon un planning.
- Couche de stockage : enregistrez les données extraites dans une base optimisée pour un accès rapide.
- Couche GraphQL : exposez un champ de liste
newsFeedet un champ de détailnewsArticle(id)via votre API. - Couche client : utilisez Apollo Client pour récupérer la liste (champs légers, paginée), puis les détails uniquement quand il le faut.
Ce pipeline « extraire → stocker → interroger » garantit que vos requêtes Apollo travaillent toujours sur des données fraîches et structurées — sans copier-coller manuel ni scripts fragiles.
Bonus : Thunderbit peut aussi enrichir vos listes avec des champs supplémentaires (comme le sentiment ou la catégorie) grâce à ses suggestions de champs alimentées par l’IA, pour un fil d’actualité encore plus intelligent.
Guide étape par étape : optimiser les requêtes de listes Apollo
Prêt à passer à l’action ? Voici ma checklist de référence pour optimiser les requêtes de listes Apollo :
-
Allégez vos requêtes
- Ne demandez que les champs nécessaires à l’affichage de la liste (titre, URL, horodatage, etc.).
- Réservez les champs lourds (texte intégral, images, enrichissement) aux requêtes de détail.
-
Mettez en place la pagination
- Utilisez la pagination par curseur pour les grandes listes ou les listes dynamiques.
- Configurez
keyArgset les fonctionsmergepour garantir un cache correct.
-
Tirez parti du cache Apollo
- Normalisez les entités avec des identifiants stables.
- Choisissez la bonne politique de récupération (
cache-and-networkest très efficace pour l’actualité). - Ajustez la taille du cache et le garbage collection en fonction du volume de données.
-
Intégrez l’extraction automatisée
- Utilisez Thunderbit pour automatiser l’extraction d’actualités et garder vos données à jour.
- Exportez les données structurées directement vers votre base de données ou votre tableur.
-
Surveillez et corrigez
- Utilisez Apollo Client Devtools pour inspecter les requêtes, le cache et les performances.
- Repérez les écritures de cache trop lourdes, les requêtes suivies en trop grand nombre et les ralentissements de l’interface.
- Suivez la latence p95/p99 et les taux d’erreur (New Relic, Uptrends).
Surveiller et diagnostiquer les performances des requêtes
Les Devtools d’Apollo sont ici d’une aide précieuse. Vous pouvez :
- Inspecter les requêtes actives et l’état du cache
- Détecter les doublons de requêtes ou un trop grand nombre d’observateurs
- Identifier les gros blocs de cache ou les problèmes de normalisation
Si vous voyez des lenteurs d’interface ou des mises à jour en retard, vérifiez :
- Des requêtes de liste trop volumineuses (réduisez-les)
- Une mauvaise normalisation du cache (corrigez vos identifiants)
- Des problèmes de fusion de pagination (auditez
keyArgsetmerge)
Et n’oubliez pas de mesurer la latence en queue de distribution — pas seulement les moyennes. C’est là que se cache la vraie gêne utilisateur.
Comparer les approches traditionnelles et les approches d’extraction d’actualités pilotées par l’IA
Soyons honnêtes : extraire des données d’actualité voulait autrefois dire écrire des scripts sur mesure, jongler avec des navigateurs headless et prier pour que la mise en page du site ne change pas du jour au lendemain. Aujourd’hui, avec des outils IA comme Thunderbit, vous pouvez automatiser tout le process — sans code, sans stress.
| Approche | Points forts | Limites pour les utilisateurs métier |
|---|---|---|
| Extraction scriptée | Totalement personnalisable, peu coûteuse à grande échelle | Maintenance élevée, nécessite du temps d’ingénierie |
| Plates-formes d’extraction managées | Démarrage rapide, gestion anti-bot déléguée | Configuration toujours nécessaire, coûts liés à l’usage |
| Extraction pilotée par l’IA (Thunderbit) | Gère les mises en page complexes, sans code | Les résultats nécessitent une validation, intégration à votre schéma |
| Extracteurs visuels no-code | Accessibles aux non-développeurs | Sensibles aux changements d’interface, scalabilité limitée |
| Infrastructure proxy/déblocage | Contourne certains blocages, débit élevé | Nécessite encore la logique d’extraction, risques de conformité |
Note juridique : l’extraction de données publiques est généralement légale, mais il faut toujours respecter les conditions d’utilisation et les limites de fréquence (Reuters).
Points clés à retenir sur les bonnes pratiques Apollo GraphQL pour les listes
Récapitulons l’essentiel :
- Optimisez pour la rapidité et la clarté : allégez les requêtes de liste, paginez et exploitez le cache au maximum.
- La structure compte : ne récupérez que ce dont vous avez besoin — gardez les champs lourds pour les requêtes de détail.
- Le cache est votre allié : utilisez la normalisation et les politiques de récupération d’Apollo pour servir les données instantanément.
- Automatisez l’extraction : des outils comme Thunderbit rendent l’extraction d’actualités et l’enrichissement des listes accessibles à tous.
- Surveillez et améliorez en continu : utilisez les Devtools et les tableaux de bord d’observabilité pour repérer les goulots d’étranglement tôt.
Pour les équipes commerciales, ops et news, ces bonnes pratiques veulent dire moins d’attente, plus d’action — et beaucoup moins de messages Slack du genre « pourquoi c’est si lent ? ».
Conclusion : prochaines étapes pour optimiser vos requêtes de listes Apollo
Si vous lancez encore des requêtes de liste lourdes, non paginées ou peu adaptées au cache, c’est le moment de faire un audit et de passer à la vitesse supérieure. Commencez petit : réduisez vos champs, ajoutez la pagination et ajustez votre cache. Puis passez à l’étape suivante en intégrant des outils d’extraction automatisée comme Thunderbit pour garder vos données fraîches et exploitables.
Vous voulez aller plus loin ? Consultez la documentation Apollo, le Thunderbit Blog ou rejoignez la communauté Apollo pour des conseils concrets et du dépannage. Et si vous êtes prêt à automatiser votre extraction d’actualités, testez le modèle News Scraper de Thunderbit : c’est un vrai changement d’échelle pour tous ceux qui ont besoin de données en temps réel sans prise de tête.
Utilisez le modèle News Scraper de Thunderbit
Si vous ne faites rien d’autre après cette lecture : réduisez les champs de vos requêtes de liste, ajoutez une pagination par curseur et choisissez une politique de récupération adaptée. Ces trois changements suffisent souvent à faire passer une requête de liste d’un ralentissement « visible » à une latence « imperceptible » — et à vous permettre de vous concentrer sur la donnée, pas sur l’écran de chargement.
FAQ
1. Pourquoi les requêtes de listes Apollo ralentissent-elles dans les tableaux de bord d’actualité ou de ventes en temps réel ?
Les requêtes de listes peuvent devenir lentes si elles récupèrent trop de données, n’utilisent pas de pagination ou ne sont pas correctement mises en cache. Dans les workflows à haute fréquence comme la veille d’actualité, même de petits retards finissent par s’additionner, entraînant des lenteurs d’interface et une baisse de productivité.
2. Quelle est la meilleure façon de structurer les requêtes de listes Apollo pour l’extraction automatisée d’actualités ?
Demandez uniquement les champs nécessaires à l’affichage de votre liste (par exemple : titre, URL, horodatage). Déplacez les champs lourds (comme le texte intégral ou les images) vers les requêtes de détail, et paginez vos résultats pour garder des charges utiles petites et rapides.
3. Comment le cache d’Apollo Client améliore-t-il les performances des listes ?
Le cache d’Apollo enregistre les données déjà récupérées, ce qui permet de répondre instantanément aux requêtes répétées. Une normalisation correcte du cache et de bonnes politiques de récupération (comme cache-and-network) peuvent accélérer considérablement les vues de liste et réduire la charge serveur.
4. Comment Thunderbit peut-il aider à l’extraction d’actualités et à l’intégration avec Apollo ?
Thunderbit est un extracteur Web IA sans code qui extrait des données d’actualité structurées depuis n’importe quel site web. Vous pouvez l’utiliser pour automatiser l’extraction, puis injecter ces données dans votre base ou votre API GraphQL pour les exploiter avec Apollo Client.
5. Quels outils puis-je utiliser pour surveiller et diagnostiquer les performances des requêtes de listes Apollo ?
Les Apollo Client Devtools vous permettent d’inspecter les requêtes, l’état du cache et les performances en temps réel. Combinez-les avec des tableaux de bord d’observabilité (comme New Relic ou Uptrends) pour suivre la latence et les taux d’erreur, puis faites évoluer votre conception de requêtes pour obtenir les meilleurs résultats.
Vous voulez plus de conseils sur l’extraction web, l’automatisation et les workflows de données en temps réel ? Consultez le Thunderbit Blog pour des analyses approfondies, des tutoriels et les dernières nouveautés en matière de productivité assistée par l’IA.
Essayez Thunderbit AI Web Scraper Get Started Free
En savoir plus
- Comment optimiser les listes Apollo pour une gestion des leads efficace
- Enrichissement des données Apollo : fonctionnalités, avantages et apport de l’IA
- Comment maîtriser la prospection Apollo : guide étape par étape
- Comment utiliser la pagination d’un extracteur Web pour une extraction efficace
- Comment utiliser la pagination d’un extracteur Web pour une extraction efficace




