Si vous avez déjà essayé d’extraire des données d’un site web moderne — qu’il s’agisse d’un portail immobilier, d’une boutique e-commerce ou même de votre fil de réseaux sociaux préféré — vous vous êtes sans doute heurté à un mur. Vous chargez la page, jetez un œil au HTML, et… rien. Les informations intéressantes que vous cherchez (prix, annonces, avis) n’y sont tout simplement pas. C’est parce qu’aujourd’hui, le web ne repose plus seulement sur le HTML : il est alimenté par JavaScript, et près de 99 % des sites web utilisent désormais des scripts côté client pour afficher le contenu (). Les crawlers traditionnels, c’est un peu comme essayer de regarder un film en lisant le scénario : ils passent à côté de l’action en temps réel.
J’ai passé des années dans le SaaS et l’automatisation, et j’ai vu de mes propres yeux à quel point cette évolution a laissé les utilisateurs métier, les équipes commerciales et les chercheurs perplexes. Mais la bonne nouvelle, c’est que maîtriser le crawling JavaScript n’est plus réservé aux développeurs. Avec la bonne approche — et un peu d’aide d’outils d’IA comme — n’importe qui peut extraire des données, même depuis les sites les plus dynamiques et interactifs. Voyons ensemble ce qu’est le crawling JavaScript, pourquoi c’est important et comment commencer, sans écrire une seule ligne de code.
Qu’est-ce que le crawling JavaScript ? Pourquoi est-ce important pour l’extraction de données web moderne ?
Commençons par les bases. Le crawling JavaScript consiste à utiliser un outil ou un bot capable de charger une page web, d’exécuter tout son JavaScript et d’extraire le contenu qui apparaît après l’exécution des scripts. C’est une avancée majeure par rapport au scraping HTML « à l’ancienne », qui se contente de récupérer le code source brut envoyé par le serveur. Sur le web d’aujourd’hui, ce HTML brut n’est souvent qu’un squelette : le vrai contenu (listes de produits, avis, prix) est injecté par JavaScript, parfois seulement après avoir fait défiler la page, cliqué ou interagi.
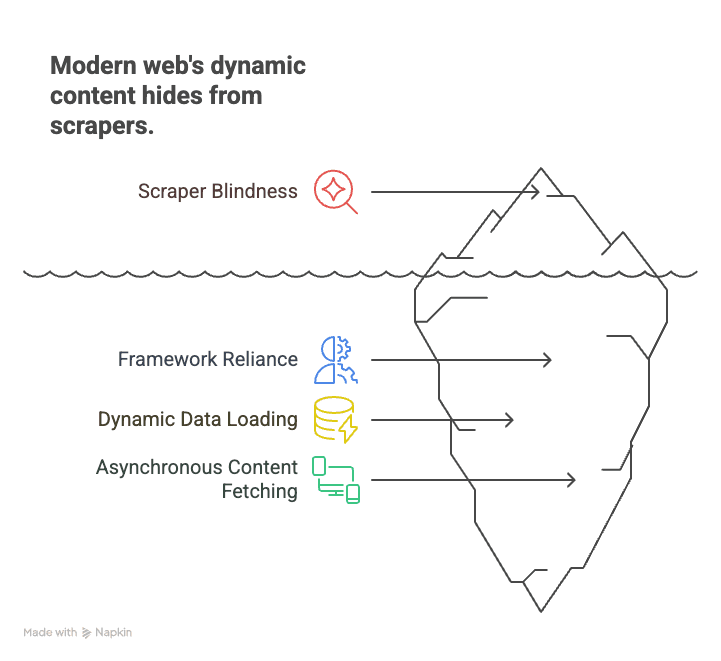
Pourquoi est-ce important ? Parce que le web moderne repose sur des frameworks comme React, Angular et Vue. Ces applications monopage (SPA) chargent les données à la volée, ce qui rend les scrapers statiques « aveugles » à la plupart du contenu. Par exemple :
- E-commerce : les prix des produits et les niveaux de stock ne s’affichent qu’après un défilement ou la sélection d’un filtre.
- Immobilier : les annonces apparaissent au fur et à mesure du défilement, avec des détails chargés dynamiquement.
- Réseaux sociaux : les publications, commentaires et mentions J’aime sont récupérés de façon asynchrone et n’apparaissent pas dans le HTML initial.
Les crawlers traditionnels récupèrent la page, voient une coquille vide et ratent tout ce qui compte. Le crawling JavaScript, en revanche, revient à ouvrir la page dans Chrome, laisser tous les scripts s’exécuter, puis récupérer ce que vous voyez — comme le ferait un humain.
En résumé : si vous voulez extraire des données de presque n’importe quel site moderne en 2025, vous devez maîtriser le crawling JavaScript. Sinon, vous passez à côté de l’essentiel ().
Principaux défis du crawling JavaScript (et comment les surmonter)
Le crawling JavaScript, ce n’est pas juste « du scraping avec plus d’étapes ». Il s’accompagne de ses propres obstacles. Voici ce qui vous attend — et comment vaincre chaque difficulté.
Rendu de contenu dynamique
Le défi : la plupart du contenu n’est pas du tout dans le HTML. Il est chargé via JavaScript après l’ouverture de la page — parfois après un défilement, un clic ou un appel réseau. Si vous récupérez seulement le HTML, vous obtenez des espaces réservés ou des conteneurs vides.
La solution : utilisez un navigateur headless — un outil qui simule un vrai navigateur, exécute tous les scripts et attend que le contenu apparaisse. Des outils comme et sont les références du secteur. Ils vous permettent de :
- Ouvrir une page et laisser JavaScript s’exécuter.
- Attendre le chargement d’éléments précis (comme « .product-list »).
- Extraire le contenu entièrement rendu depuis le DOM.
Cette approche est désormais la référence pour extraire des sites dynamiques ().
Anti-bot et barrières à l’automatisation
Le défi : les sites deviennent plus malins pour bloquer les bots. Attendez-vous à voir :
- CAPTCHA
- des bannissements d’IP ou du rate limiting
- le fingerprinting du navigateur (vérification de votre statut d’utilisateur réel)
- des pièges honeypot (faux liens conçus pour attraper les bots)
La solution : explorez les données de manière responsable et imitez le comportement humain :
- Respectez le fichier robots.txt et les conditions d’utilisation.
- Limitez le rythme de vos requêtes — ajoutez des délais aléatoires, n’inondez pas le serveur.
- Faites tourner les IP si vous extrayez des données à grande échelle (mais faites-le de manière éthique).
- Utilisez des en-têtes de navigateur réels et évitez les signatures de bot trop évidentes.
- N’extrayez pas de données derrière une connexion et ne contournez pas les CAPTCHA sans autorisation.
Thunderbit, par exemple, encourage ses utilisateurs à n’extraire que des données accessibles publiquement et intègre les bonnes pratiques de conformité ().
Défilement infini et événements déclenchés par l’utilisateur
Le défi : de nombreux sites utilisent le défilement infini ou exigent des clics pour charger davantage de données. Si votre scraper ne récupère que ce qui est visible au départ, vous manquerez la majorité du contenu.
La solution : utilisez l’automatisation du navigateur pour :
- Simuler le défilement (charger plus de résultats comme le ferait un utilisateur).
- Cliquer sur les boutons « Charger plus » ou sur les onglets.
- Attendre l’apparition du nouveau contenu avant d’extraire.
L’IA de Thunderbit peut détecter ces schémas et gérer le défilement ou la pagination pour vous, sans que vous ayez à écrire de scripts personnalisés ().
Maintenir les performances et passer à l’échelle
Le défi : exécuter un navigateur headless pour chaque page consomme beaucoup de ressources. Extraire des centaines ou des milliers de pages peut être lent et lourd pour votre ordinateur.
La solution : utilisez le crawl concurrent — exécutez plusieurs navigateurs ou onglets en parallèle. Ou, mieux encore, déléguez le travail au cloud. L’accélérateur de scraping cloud de Thunderbit, aussi appelé Lightning Network, peut extraire jusqu’à 50 pages à la fois, ce qui accélère énormément les gros volumes ().
Thunderbit : rendre le crawling JavaScript simple et puissant
Soyons honnêtes : la plupart des utilisateurs métier ne veulent pas écrire de code, déboguer des sélecteurs ou surveiller des scripts. C’est pour cela que nous avons créé — un Extracteur Web alimenté par l’IA, conçu pour les non-développeurs qui ont besoin de données provenant de sites dynamiques et riches en JavaScript.
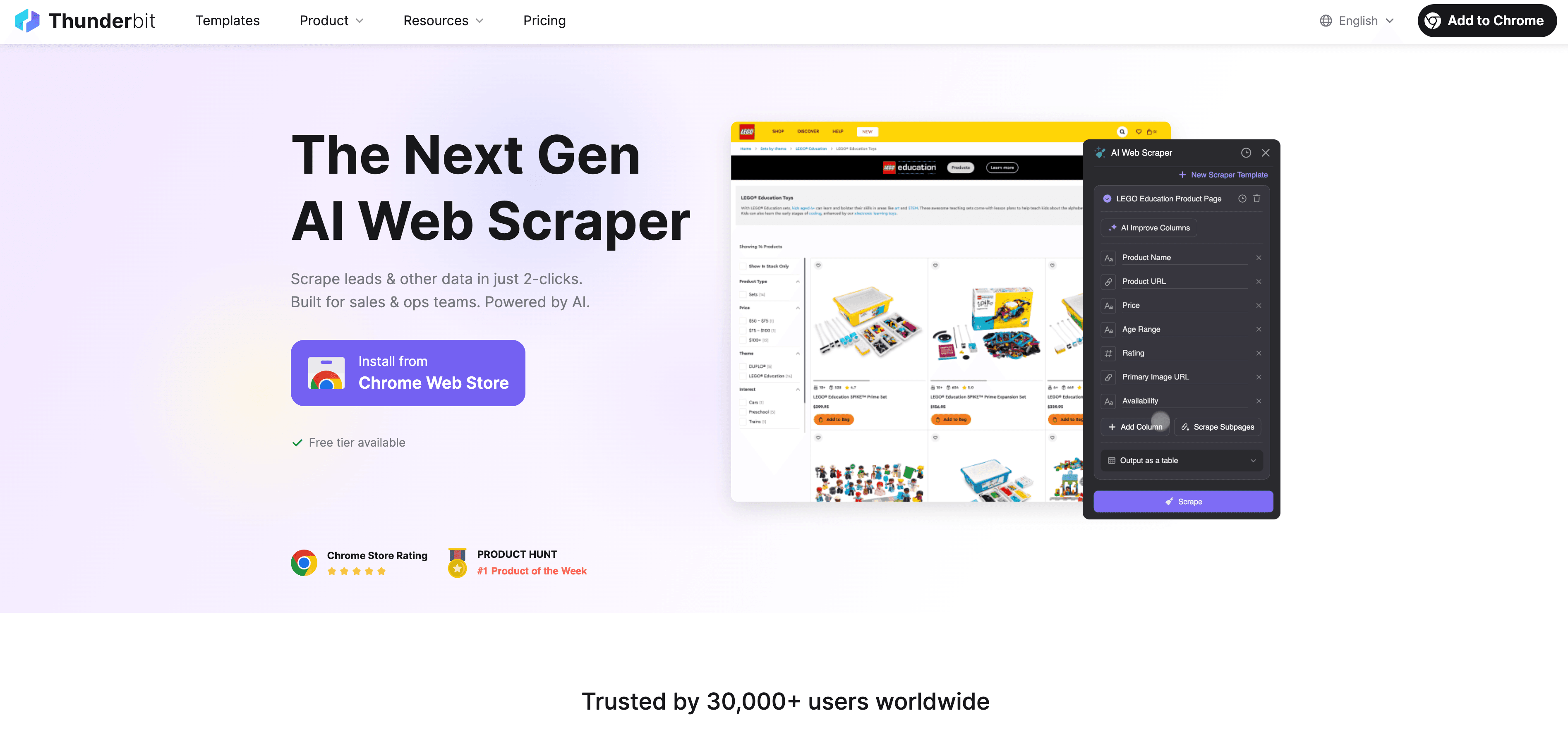
Voici comment Thunderbit simplifie le crawling JavaScript :
- Suggestion de champs par IA : cliquez simplement sur « Suggestion de champs par IA », et l’IA de Thunderbit analyse la page, recommande les meilleures colonnes à extraire et définit les bons types de données. Plus besoin de deviner ou de tâtonner.
- Extraction en langage naturel : décrivez ce que vous voulez en français courant (« Récupérer le nom du produit, le prix et la note »), et Thunderbit trouve comment l’obtenir.
- Gestion du contenu dynamique : Thunderbit fonctionne dans un vrai navigateur (votre Chrome ou dans le cloud), donc il exécute tout le JavaScript et attend le chargement du contenu — comme un humain.
- Support des sous-pages et de la pagination : besoin d’extraire plusieurs pages ou de suivre des liens vers des sous-pages (comme des fiches produits) ? Thunderbit le fait automatiquement et rassemble toutes les données dans un seul tableau.
- Accélération cloud : pour les gros volumes, le Lightning Network de Thunderbit extrait jusqu’à 50 pages à la fois dans le cloud, sans faire souffrir votre ordinateur.
- Interface sans code et simple d’utilisation : si vous savez utiliser Excel, vous pouvez utiliser Thunderbit. Tout se fait par clics, sans configuration technique.
- Export gratuit des données : exportez vos données vers Excel, Google Sheets, Airtable, Notion ou JSON, sans frais supplémentaires.
Thunderbit est utilisé par plus de 30 000 personnes dans le monde, des équipes commerciales aux opérateurs e-commerce, en passant par les professionnels de l’immobilier ().
Suggestion de champs par IA et extraction en langage naturel
C’est ici que Thunderbit brille vraiment. Au lieu de fouiller dans le HTML ou d’écrire des sélecteurs XPath, vous cliquez simplement sur un bouton, et l’IA de Thunderbit fait le travail le plus lourd. Elle lit la page, comprend sa structure et recommande exactement quoi extraire. Si vous voulez quelque chose de précis, saisissez simplement votre demande en français courant — l’IA de Thunderbit la traduit vers les bons éléments.
C’est une vraie révolution pour les débutants. Vous n’avez pas besoin de connaître le HTML, le CSS ou JavaScript. Dites simplement ce que vous voulez, et laissez l’IA s’occuper du reste ().
Pagination et crawl des sous-pages
Thunderbit n’est pas limité à une seule page. Il peut :
- Détecter et gérer la pagination (cliquer sur « Suivant » ou faire défiler pour charger davantage).
- Extraire des sous-pages (comme des fiches produits, des profils d’auteur ou des avis) et fusionner les données dans votre tableau principal.
- Gérer le défilement infini en simulant les actions de l’utilisateur, pour récupérer toutes les données, pas seulement celles visibles au départ.
Par exemple, vous voulez extraire une catégorie e-commerce sur 20 pages de produits ? Thunderbit cliquera automatiquement sur chaque page et combinera les résultats. Besoin des détails de chaque fiche produit ? Utilisez l’extraction des sous-pages, et Thunderbit visitera chaque lien, récupérera les informations supplémentaires et enrichira votre jeu de données ().
Lightning Network et accélération cloud : passer à l’échelle dans le crawling JavaScript
Quand vous devez extraire des centaines ou des milliers de pages, le faire une par une n’est tout simplement pas pratique. C’est là qu’intervient le Lightning Network de Thunderbit.
- Scraping cloud : déléguez les tâches lourdes aux serveurs cloud de Thunderbit (aux États-Unis, en Europe et en Asie). Le cloud peut extraire jusqu’à 50 pages à la fois, ce qui accélère considérablement les gros traitements.
- Crawl concurrent : au lieu d’attendre le chargement de chaque page dans votre navigateur, le cloud de Thunderbit répartit le travail entre plusieurs agents. Extraire 1 000 pages produits ? Le cloud peut finir en quelques minutes, pas en plusieurs heures.
- Scraping planifié : vous devez surveiller les prix ou les annonces chaque jour ? Configurez une extraction planifiée en langage courant (« tous les jours à 9 h »), et Thunderbit lancera la tâche automatiquement, en exportant les données vers votre Google Sheet ou votre base de données ().
C’est une bouée de sauvetage pour les équipes commerciales, e-commerce et opérations qui ont besoin de données fraîches à grande échelle — sans recruter de développeur ni gérer de serveurs.
Extraction multi-page et en masse
Thunderbit facilite :
- l’extraction de répertoires ou de catalogues entiers (par exemple, tous les produits d’une catégorie, toutes les annonces d’une région).
- l’export des résultats vers Excel, Google Sheets, Airtable ou Notion en un clic.
- l’économie de plusieurs heures, voire plusieurs jours, de travail manuel — un utilisateur a extrait des centaines d’annonces immobilières, avec les coordonnées des agents, en moins de 10 minutes.
Guide pas à pas : comment commencer le crawling JavaScript avec Thunderbit
Prêt à essayer ? Voici comment démarrer avec Thunderbit — même si vous n’avez jamais extrait de données d’un site web auparavant.
Configuration de votre premier crawl
- Installez Thunderbit : téléchargez . Créez un compte gratuit.
- Choisissez votre cible : rendez-vous sur le site que vous souhaitez extraire. S’il nécessite une connexion, connectez-vous d’abord (Thunderbit fonctionne dans le contexte de votre navigateur).
- Ouvrez Thunderbit : cliquez sur l’icône Thunderbit dans la barre d’outils de Chrome. Choisissez votre source de données (page actuelle, liste d’URL ou import de fichier).
- Choisissez le mode d’exécution : pour les petits traitements ou les sites nécessitant une connexion, utilisez le mode Navigateur. Pour les traitements à grande échelle, passez en mode Cloud pour un scraping parallèle.
- Suggestion de champs par IA : cliquez sur « Suggestion de champs par IA ». L’IA de Thunderbit analysera la page et recommandera les colonnes à extraire (comme « Nom du produit », « Prix », « URL de l’image »).
- Ajustez les colonnes : renommez, ajoutez ou supprimez des champs selon vos besoins. Ajoutez des instructions IA personnalisées si vous souhaitez formater ou classer les données.
- Configurez la pagination/le défilement : si le site utilise la pagination ou le défilement infini, activez l’option correspondante dans les paramètres de Thunderbit.
- Cliquez sur « Extraire » : Thunderbit chargera la ou les pages, exécutera tout le JavaScript et extraira les données dans un tableau.
Extraction et export des données
- Prévisualisez les résultats : Thunderbit affiche vos données dans un tableau. Vérifiez rapidement l’exhaustivité et la précision.
- Exportez : cliquez sur « Exporter » pour télécharger au format Excel, CSV ou JSON, ou envoyez directement vers Google Sheets, Airtable ou Notion.
- Validez : comparez quelques lignes avec le site en direct pour vous assurer que tout correspond.
- Dépannage : s’il vous manque des données, essayez d’abord de faire défiler la page, d’ajuster les instructions IA ou de passer en mode Cloud pour de meilleures performances.
Pour des guides plus détaillés, consultez ou .
Bonnes pratiques pour un crawling JavaScript sûr et conforme
Avec un grand pouvoir d’extraction viennent de grandes responsabilités. Voici comment rester du bon côté de la loi — et de l’éthique :
- Respectez robots.txt et les conditions d’utilisation : vérifiez toujours si le site autorise le scraping. S’il indique « pas de bots », ne tentez pas le diable ().
- Évitez d’extraire des données personnelles : le RGPD et le CCPA considèrent les noms, e-mails et profils comme des données protégées, même s’ils sont publics. N’extrayez des informations personnelles que si vous avez une raison légitime et un consentement.
- Ne contournez pas les connexions ou les CAPTCHA : c’est une zone juridique grise, voire pire. Restez sur les données publiques.
- Limitez vos requêtes : ne surchargez pas les serveurs. Le mode Cloud de Thunderbit espace les requêtes et fait tourner les IP pour éviter les bannissements.
- Utilisez les données de manière éthique : ne republiez pas de contenu protégé par le droit d’auteur et n’abusez pas des informations extraites.
- Supprimez les données sur demande : si quelqu’un vous demande de retirer ses données, faites-le.
Thunderbit est conçu pour encourager la conformité — données publiques uniquement, aucun piratage, et des options d’export claires pour une utilisation responsable.
Éviter les risques juridiques
- Limitez-vous aux données publiques et non personnelles.
- N’extrayez pas les sites qui l’interdisent explicitement.
- En cas de doute, demandez l’autorisation ou utilisez l’API officielle du site.
- Conservez des journaux de ce que vous avez extrait et à quel moment.
- Respectez immédiatement les mises en demeure d’arrêt.
Pour aller plus loin, consultez .
Comparer les solutions de crawling JavaScript : Thunderbit vs outils traditionnels
| Aspect | Puppeteer/Playwright (code) | Sitebulb (crawler SEO) | Thunderbit (IA sans code) |
|---|---|---|---|
| Temps de configuration | Heures (codage requis) | Modéré (configuration) | Minutes (clics) |
| Compétences requises | Élevées (développeurs uniquement) | Moyennes | Faibles (tout le monde) |
| Gère le contenu JS | Oui (scripts manuels) | Oui (pour le SEO) | Oui (IA, automatique) |
| Pagination/sous-pages | Scripts manuels | Limité | Automatique (détection par IA) |
| Maintenance | Élevée (casse aux moindres changements) | Modérée | Faible (l’IA s’adapte) |
| Scalabilité | Manuelle (écrire du code) | Limitée | Cloud intégré (x50) |
| Options d’export | Manuelles (écrire du code) | CSV/Excel | Excel, Sheets, Notion |
| Idéal pour | Développeurs, flux sur mesure | Audits SEO | Utilisateurs métier, analystes |
Thunderbit est le grand gagnant pour les utilisateurs métier qui veulent des résultats rapides, sans tracas techniques ().
Conclusion et points clés à retenir
Le crawling JavaScript n’est plus une compétence de niche : c’est indispensable pour toute personne qui a besoin de données web en 2025. Avec près de 99 % des sites web qui exécutent des scripts côté client, le scraping traditionnel ne suffit plus (). La bonne nouvelle ? Vous n’avez pas besoin d’être développeur pour le maîtriser.
Voici ce qu’il faut retenir :
- Le contenu dynamique est partout : si vous voulez extraire des sites modernes, il vous faut un outil capable d’exécuter JavaScript.
- Les défis sont réels, mais solubles : les navigateurs headless, l’attente intelligente et l’accélération cloud permettent d’extraire même les données les plus difficiles.
- Thunderbit simplifie tout : grâce à la suggestion de champs par IA, à l’extraction en langage naturel, au support des sous-pages et de la pagination, ainsi qu’à l’accélération cloud, Thunderbit met le crawling JavaScript puissant à la portée de tous.
- Restez conforme : respectez toujours les règles des sites, les lois sur la vie privée et les principes éthiques.
- Commencez dès aujourd’hui : installez Thunderbit, choisissez un site et voyez combien de données vous pouvez débloquer en quelques clics.
Vous voulez aller plus loin ? Consultez pour d’autres guides, ou regardez nos pour des démonstrations pas à pas.
Bon crawling — et que vos données soient toujours dynamiques, complètes et prêtes à l’action.
FAQ
1. Qu’est-ce que le crawling JavaScript et en quoi diffère-t-il du scraping traditionnel ?
Le crawling JavaScript utilise un outil qui charge une page web, exécute tout son JavaScript et extrait le contenu qui apparaît après l’exécution des scripts. Le scraping traditionnel se contente de récupérer le HTML brut, ce qui lui fait manquer la majeure partie du contenu des sites modernes.
2. Pourquoi ai-je besoin du crawling JavaScript pour l’extraction de données métier ?
Parce que presque tous les sites web modernes utilisent JavaScript pour charger le contenu de manière dynamique. Sans crawling JavaScript, vous manquerez les listes de produits, les avis, les prix et d’autres données essentielles.
3. Comment Thunderbit simplifie-t-il le crawling JavaScript pour les débutants ?
Thunderbit utilise l’IA pour suggérer des champs, gérer le contenu dynamique et automatiser la pagination ainsi que l’extraction des sous-pages. Vous pouvez décrire ce que vous voulez en français courant — sans écrire de code.
4. Le crawling JavaScript est-il légal ? À quoi dois-je faire attention ?
Le crawling JavaScript est légal lorsqu’il est effectué de manière responsable — limitez-vous aux données publiques, respectez robots.txt et les conditions d’utilisation, et évitez d’extraire des informations personnelles sans consentement. Thunderbit encourage la conformité et une utilisation responsable.
5. Comment puis-je passer à l’échelle pour de gros volumes de crawling JavaScript ?
Le Lightning Network de Thunderbit (scraping cloud) vous permet d’extraire jusqu’à 50 pages à la fois, ce qui facilite la gestion de gros volumes comme la surveillance des prix ou la génération de leads sur des milliers de pages.
En savoir plus :