Je me rappelle encore la toute première fois où j’ai voulu extraire des infos sur une trentaine de pages produits pour un projet perso. J’étais installé avec mon café, un tableur ouvert, plein d’énergie… et deux heures plus tard, j’étais toujours là à faire du copier-coller, le regard perdu, les doigts en compote à force de marteler Ctrl+C/Ctrl+V. Si tu as déjà tenté de récupérer des données sur une longue liste de pages web, tu sais à quel point c’est fastidieux : c’est lent, tu fais vite des erreurs, et franchement, ça te coupe toute motivation.
C’est pour ça que je suis devenu accro au scraping en masse — et pourquoi, chez , on s’est donné pour mission de rendre l’extraction web sur des dizaines, des centaines, voire des milliers d’URLs aussi simple que possible. Dans ce guide, je t’explique ce qu’est le scraping en masse, pourquoi c’est devenu incontournable pour les pros, comment la pratique a évolué, et comment Thunderbit te permet de passer d’une « liste de 200 URLs » à « mon tableur prêt à l’emploi » en quelques clics. Pas besoin de coder, pas de modèles à créer, zéro prise de tête.
Scraping en Masse : Les Bases de l’Extraction Web à Grande Échelle
On commence par l’essentiel. Le scraping en masse (aussi appelé list crawling ou scraping d’URL) consiste à extraire des données à partir d’une liste entière de pages web — au lieu de le faire page par page, à la main. Plutôt que d’ouvrir chaque lien, de copier les infos et de les coller dans un tableur (jusqu’à ce que tu craques), le scraping en masse te permet de confier ta liste d’URLs à un outil qui fait tout le boulot à ta place.
En gros, c’est comme si tu embauchais un assistant super rapide et infatigable qui va visiter chaque lien de ta liste et te ramène toutes les infos utiles dans un tableur. C’est l’extraction web, mais version XXL. Ça change du web scraping classique, qui cible souvent une seule page ou qui explore un site page par page. Avec le scraping d’URL, tu dis à l’outil : « Voilà ma liste — va me chercher les infos sur chacune de ces pages. »
Pour te donner une image, c’est comme la différence entre copier une ligne d’un tableur et importer tout le fichier d’un coup. Le scraping en masse, c’est ce bouton « importer » pour le web.
Pour aller plus loin, jette un œil à .
Pourquoi le Scraping en Masse Change la Donne pour les Pros
Soyons clairs : personne n’a envie de passer sa journée à copier-coller des infos de 100 pages web. Pourtant, pour les équipes commerciales, e-commerce, opérations ou recherche, récupérer des données sur le web, c’est le quotidien. Le scraping en masse, ce n’est pas juste un buzzword — c’est un vrai booster de productivité.
Pourquoi c’est devenu indispensable :
- Rapidité : Ce qui prenait des heures (voire des jours) se fait maintenant en quelques minutes, parfois même en secondes ().
- Fiabilité : L’automatisation limite les erreurs humaines et assure la cohérence des données.
- Échelle : Tu veux extraire des infos de 200 pages produits ? 500 annonces immo ? Le scraping en masse rend ça possible.
- ROI : Les boîtes qui adoptent des extracteurs IA modernes gagnent 30 à 40 % de temps sur la collecte de données ().
Quelques exemples concrets :
| Cas d’usage | Problème (manuel) | Avantage du scraping en masse |
|---|---|---|
| Génération de leads | Copier les contacts un à un, c’est lent | Extraire des milliers de leads d’un coup, remplir un fichier avec noms, emails, téléphones |
| Veille tarifaire | Vérifier les prix concurrents chaque jour | Suivre tous les URLs produits pour détecter les changements de prix, réagir rapidement |
| Veille marché/contenu | Lire chaque article/avis à la main | Extraire les données de plusieurs articles ou avis d’un coup pour des analyses à jour |
| Gestion de données produits | Fusionner des infos de sources variées = erreurs | Rassembler specs, stocks, etc. de tous les fournisseurs dans un fichier homogène |
| Annonces immobilières | Agréger les annonces à la main prend des heures | Extraire des dizaines d’annonces sur plusieurs sites pour une vue globale et actualisée |
En résumé : le scraping web en masse, c’est le turbo de la productivité et de la prise de décision basée sur la donnée pour la vente, le marketing, les opérations, etc. ().
Tour d’Horizon des Solutions de Scraping en Masse : Du Manuel à l’IA
Le scraping en masse a bien changé. Voici les grandes méthodes, de la vieille école aux outils IA — et pourquoi Thunderbit sort du lot.
Scraping Manuel : L’Ancienne Méthode
Tu te souviens de mon marathon copier-coller ? Voilà, c’est ça le scraping manuel. On ouvre chaque page, on copie les infos, on colle dans Excel, et on recommence. Pour 5 URLs, ça passe. Pour 50 ? C’est interminable, tu fais des erreurs, et tu rates facilement des mises à jour ().
Outils à Modèles et Scripts de Code
Ensuite, il y a les scripts (Python + BeautifulSoup, par exemple) et les outils à modèles. Si tu sais coder, tu peux écrire un script qui boucle sur tes URLs et extrait ce qu’il faut. Puissant, mais il faut des compétences techniques — et au moindre changement du site, tout peut casser. La maintenance devient vite un vrai casse-tête.
Les outils à modèles te permettent de sélectionner visuellement les champs sur une page, puis d’appliquer ce « modèle » à une liste de pages similaires. Pratique si tu ne codes pas, mais il faut créer un modèle pour chaque site ou type de page. Si tes URLs viennent de sites différents ou que les pages ne se ressemblent pas, ça se complique.
L’Avantage Thunderbit : Scraping en Masse en Un Clic
C’est là que Thunderbit fait la différence. Notre approche : tu colles ta liste d’URLs, tu cliques, et tu récupères des données structurées — sans modèle, sans code, sans prise de tête. L’IA devine quoi extraire selon tes colonnes ou suggestions. Même si les pages sont différentes, Thunderbit s’adapte.
Comparatif :
| Méthode | Facilité d’utilisation | Flexibilité | Compétence technique requise | Temps de configuration | Vitesse | Gère pages variées ? |
|---|---|---|---|---|---|---|
| Copier-coller manuel | Faible | Élevée | Aucune | Long | Lent | Oui (mais pénible) |
| Script de code | Faible | Très élevée | Élevée | Long | Rapide | Oui (si codé pour) |
| Outil à modèle | Moyenne | Moyenne | Faible | Moyen | Rapide | Uniquement si pages similaires |
| Thunderbit (IA en masse) | Très élevée | Élevée | Aucune | Court | Ultra rapide | Oui |
Exemple concret : extraire 100 URLs produits prendrait des heures à la main, environ une heure avec un outil à modèle, mais seulement quelques minutes avec Thunderbit ().
Tutoriel : Scraper une Liste d’URLs en Masse avec Thunderbit
Passons à la pratique. Voici comment extraire des données en masse avec — zéro compétence technique requise.
Étape 1 : Installe l’Extension Chrome Thunderbit
Commence par installer l’. Cherche « Thunderbit AI Web Scraper » sur le Chrome Web Store ou va sur notre . Clique sur « Ajouter à Chrome », confirme, et c’est parti. Plus de font déjà confiance à Thunderbit.
Tu devras peut-être créer un compte ou te connecter — pas de panique, l’offre gratuite te permet de tester le scraping en masse tout de suite.
Étape 2 : Prépare ta Liste d’URLs
Rassemble tes URLs. Tu peux :
- Les exporter depuis un CRM ou un tableur
- Copier les liens produits d’un site concurrent
- Récupérer des URLs de profils LinkedIn pour la prospection
- Copier manuellement les liens à extraire
Formate-les en liste simple — une URL par ligne dans un fichier texte ou tableur. Exemple :
1https://www.example.com/product/123
2https://www.example.com/product/456
3https://www.example.com/product/789Astuce : enlève les doublons et vérifie que les pages sont accessibles (si une page demande une connexion, Thunderbit doit aussi être connecté).
Étape 3 : Colle les URLs et Lance le Scraping en Masse
C’est là que ça devient fun :
- Clique sur l’icône Thunderbit dans la barre Chrome.
- Choisis la source de données « URLs » ou « Liste d’URLs ».
- Colle ta liste d’URLs dans la zone prévue (ou importe un CSV si besoin).
- Clique sur « Suggestions de colonnes IA » — l’IA de Thunderbit analyse une page et propose les champs pertinents (ex : « Nom du produit », « Prix », « Email », etc.).
- Ajuste les colonnes proposées ou ajoute les tiennes.
- Clique sur « Extraire ». Thunderbit visite chaque URL, extrait les données et les compile dans un tableau.
Tu peux continuer à bosser sur d’autres onglets pendant l’extraction. Pour les grandes listes, Thunderbit utilise plusieurs threads et respecte les limites de vitesse pour éviter d’être bloqué.
Étape 4 : Vérifie et Exporte tes Données
Une fois l’extraction terminée, Thunderbit affiche les résultats dans un tableau. Chaque ligne = une page, chaque colonne = un champ défini.
Options d’export :
- Copier dans le presse-papiers ou télécharger en CSV (pour Excel ou Google Sheets)
- Exporter direct vers Google Sheets, Airtable ou Notion (en un clic)
- Télécharger en JSON (pour les devs ou workflows avancés)
Tu peux aussi sauvegarder ton modèle d’extraction pour la prochaine fois.
Étape 5 : Conseils et Astuces pour un Scraping en Masse Efficace
Même avec l’IA, le scraping web peut parfois coincer. Quelques tips :
- Certaines URLs n’ont pas été extraites ? Vérifie si elles demandent une connexion ou ont une structure bizarre. Essaie le « mode navigateur » de Thunderbit pour les pages complexes.
- Données manquantes dans une colonne ? Mets un nom de colonne plus explicite, ou utilise la fonction « Instruction personnalisée » de Thunderbit pour guider l’IA.
- Listes volumineuses lentes ? Découpe-les (ex : 200 URLs à la fois) ou utilise l’option de scraping cloud de Thunderbit.
- Évite d’être bloqué : Ne scrape pas trop vite. Respecte les délais et les règles
robots.txtet conditions d’utilisation des sites. - Besoin de données sur des sous-pages ? Active le scraping de sous-pages pour suivre les liens internes (ex : avis produits ou bio d’auteur).
Pour plus d’aide, la et le support sont là pour toi.
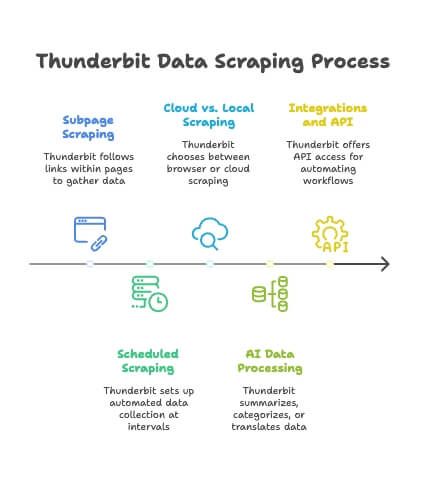
Fonctions Avancées : Sous-pages, Programmation, et Plus
Thunderbit ne s’arrête pas à l’extraction ponctuelle. Voici quelques fonctions avancées qui rendent le scraping en masse encore plus puissant :
- Scraping de sous-pages : Thunderbit peut suivre les liens internes (onglets « Avis », profils auteurs, etc.) et fusionner ces données dans ton tableau principal. L’IA s’adapte aux différents formats de sous-pages — sans rien configurer ().
- Scraping Programmé : Tu veux des données fraîches chaque jour ? Programme des extractions régulières (toutes les heures, tous les jours, chaque semaine). Ton Google Sheet ou ta base de données se met à jour tout seul.
- Cloud vs Local : Par défaut, Thunderbit tourne dans ton navigateur, mais tu peux aussi utiliser le cloud pour des extractions plus rapides et massives.
- Traitement IA des Données : Thunderbit peut résumer, catégoriser ou traduire les données à la volée, pour des jeux de données enrichis sans effort.
- Intégrations et API : Pour les utilisateurs avancés, Thunderbit propose une API et des intégrations pour automatiser tes workflows d’extraction.
Pour en savoir plus, consulte la .
Scraping en Masse pour Tous : Commercial, E-commerce, Immobilier, etc.
Le scraping en masse, ce n’est pas réservé aux experts data (même si on est cools !). Voici comment différentes équipes s’en servent :
- Commercial : Extraire des profils LinkedIn ou d’annuaires pour la prospection. Constituer une liste de prospects avec noms, postes, emails, etc., prête à importer dans le CRM.
- E-commerce : Suivre les prix, stocks et détails produits chez les concurrents sur des centaines de pages. Programmer des extractions pour ajuster ta stratégie tarifaire.
- Veille marché : Agréger articles, avis ou posts de forums pour analyser les tendances. Plus de données, plus fraîches = meilleures analyses.
- Opérations : Collecter specs, infos conformité ou données fournisseurs sur plusieurs sites — automatiquement et à intervalle régulier.
- Immobilier : Agréger les annonces de sites comme Zillow ou . Obtenir une vue globale du marché dans un seul tableur.
Astuce : pour les tâches récurrentes, sauvegarde tes modèles et programme les extractions. Pour une recherche ponctuelle, colle tes URLs et lance l’extraction.
Bonnes Pratiques : Organisation et Respect des Règles
Avec un grand pouvoir d’extraction vient une grande responsabilité. Voici comment rester carré et éthique :
- Organise tes données : Utilise des noms de fichiers clairs (ex :
leads_scraped_Août2025.csv), ajoute des dates, et garde trace des sources. - Nettoie et déduplique : Supprime les doublons, vérifie la cohérence, corrige les erreurs avant analyse.
- Respecte les règles des sites : N’extrais que des données publiques, vérifie toujours les conditions d’utilisation et le fichier
robots.txt. - Gère les données perso avec soin : Si tu collectes des emails ou noms, respecte les lois sur la vie privée (RGPD, etc.). N’utilise pas les infos sensibles n’importe comment.
- Sois respectueux : N’inonde pas les sites — adapte la vitesse d’extraction et programme tes scrapes en dehors des heures de pointe.
Pour plus de conseils, consulte .
Conclusion & Points Clés
Le scraping en masse est passé du « petit gadget sympa » à l’outil incontournable pour tous ceux qui ont besoin de données web à grande échelle. Avec Thunderbit, plus besoin d’être codeur, expert en modèles ou pro du tableur. Tu colles tes URLs, tu cliques, et la donnée arrive toute seule.
Les points forts du scraping en masse avec Thunderbit :
- Simplicité : Aucun prérequis technique — il suffit de coller et lancer ().
- Vitesse et échelle : Récupère des milliers de données en quelques minutes, pas en heures ().
- Flexibilité : Fonctionne sur presque tous les sites, l’IA s’adapte aux différents formats ().
- Qualité des données : Extraction pilotée par l’IA pour des résultats précis et exploitables ().
- Autonomie des équipes : Commercial, marketing, opérations, recherche — chacun peut obtenir ses données sans dépendre de l’IT ().
Envie de tester ? , pour essayer le scraping en masse sur une petite liste et voir les résultats par toi-même. Pense à un problème de données que tu as — une liste d’URLs dont tu aimerais extraire les infos — et lance-toi. Tu pourrais régler en quelques minutes une tâche qui traîne depuis des semaines.
Exploiter la donnée web à grande échelle, c’est un vrai avantage compétitif. Avec le scraping en masse et des outils comme Thunderbit, cet avantage est enfin à la portée de tous. Bon scraping — et que tes journées de Ctrl+C/Ctrl+V soient derrière toi !
Envie d’en savoir plus sur le scraping web, le list crawling ou les techniques avancées ? Va faire un tour sur le et découvre nos articles détaillés :
Et pour voir Thunderbit en action, abonne-toi à notre pour des tutos et astuces.
FAQ
1. C’est quoi le scraping web en masse et en quoi c’est différent du scraping classique ?
Le scraping web en masse, aussi appelé scraping d’URL ou list crawling, c’est extraire des données à partir d’une liste prédéfinie de pages web en une seule opération. Contrairement au scraping classique qui explore un site ou extrait page par page, le scraping en masse te permet de coller une liste d’URLs et d’extraire direct les champs que tu veux — parfait pour les pages produits, les annuaires ou les listings.
2. Qui profite le plus du scraping en masse ?
Le scraping en masse est utile à plein de métiers. Les équipes commerciales l’utilisent pour générer des leads à partir de LinkedIn ou d’annuaires. Les e-commerçants surveillent les prix et stocks des concurrents. Les agents immobiliers agrègent les annonces, et les analystes collectent des avis ou articles en volume. Bref, toute équipe qui a besoin de données structurées sur plusieurs URLs y gagne.
3. Qu’est-ce qui différencie Thunderbit des autres outils de scraping en masse ?
Thunderbit se démarque par une expérience sans code, pilotée par l’IA. Contrairement aux outils classiques qui demandent du code ou des modèles, Thunderbit te permet de simplement coller une liste d’URLs et d’extraire les données en un clic. Il gère les pages variées, suggère automatiquement les champs, supporte le scraping de sous-pages et s’intègre direct à Google Sheets, Airtable ou Notion.
4. Quelles données peut-on extraire avec Thunderbit lors d’un scraping en masse ?
Thunderbit peut extraire noms de produits, prix, disponibilité, coordonnées (emails, téléphones), titres, avis, specs, etc. L’IA détecte automatiquement les champs pertinents selon tes colonnes ou la structure de la page. Tu peux même extraire des sous-pages, traduire ou résumer les contenus à la volée.
5. Le scraping en masse est-il légal et sûr pour un usage pro ?
Le scraping en masse est légal s’il est pratiqué de façon responsable et éthique. Il faut se limiter aux données publiques, respecter le fichier robots.txt et les conditions d’utilisation des sites, et éviter de collecter des données personnelles sans consentement. Thunderbit encourage la conformité en limitant la vitesse d’extraction, en supportant le scraping avec connexion si besoin, et en proposant des outils pour organiser et nettoyer les données de façon responsable.