

Les données du web, c’est un peu le pétrole de notre époque — mais elles sont disséminées partout, cachées dans des pages HTML parfois bien chaotiques, et souvent protégées par des CAPTCHAs ou des scripts anti-bot bien costauds. Si tu as déjà passé des heures à copier-coller des prix, des infos sur la concurrence ou des leads à la main, tu sais à quel point c’est chronophage et frustrant. C’est pour ça que le web scraping est devenu un vrai must-have pour les boîtes qui veulent avancer vite. D’ailleurs, le marché des données alternatives (où le web scraping a une grosse part) pesait déjà 4,9 milliards de dollars en 2023 et ça ne fait qu’exploser.

Mais voilà le twist : alors que Python est souvent le réflexe des débutants, Go (ou Golang pour les puristes) propulse en douce certains des extracteurs web les plus rapides et solides du marché. Son secret ? Une gestion de la concurrence ultra-efficace, une bibliothèque standard hyper complète et des perfs qui font rêver les devs backend. J’ai vu des équipes diviser par deux leur temps de scraping en passant sur Go — et avec les bons outils, pas besoin d’être un crack de chez Google pour s’y mettre.
Envie de faire de Go ton arme secrète pour l’extraction de données ? Suis ces cinq étapes clés — de l’installation aux techniques avancées — avec des exemples concrets, des tips pratiques et un aperçu de comment des outils IA comme Thunderbit peuvent vraiment booster ta productivité.
Pourquoi miser sur Go pour le Web Scraping ? Les vrais avantages business
Extraire des données de n'importe quel site avec l'IA Get Started Free
Soyons clairs : quand il s’agit de collecter des milliers (voire des millions) de pages, chaque seconde compte. Go a été pensé pour ce genre de mission intensive. Voilà pourquoi de plus en plus d’entreprises misent sur Go pour le web scraping :
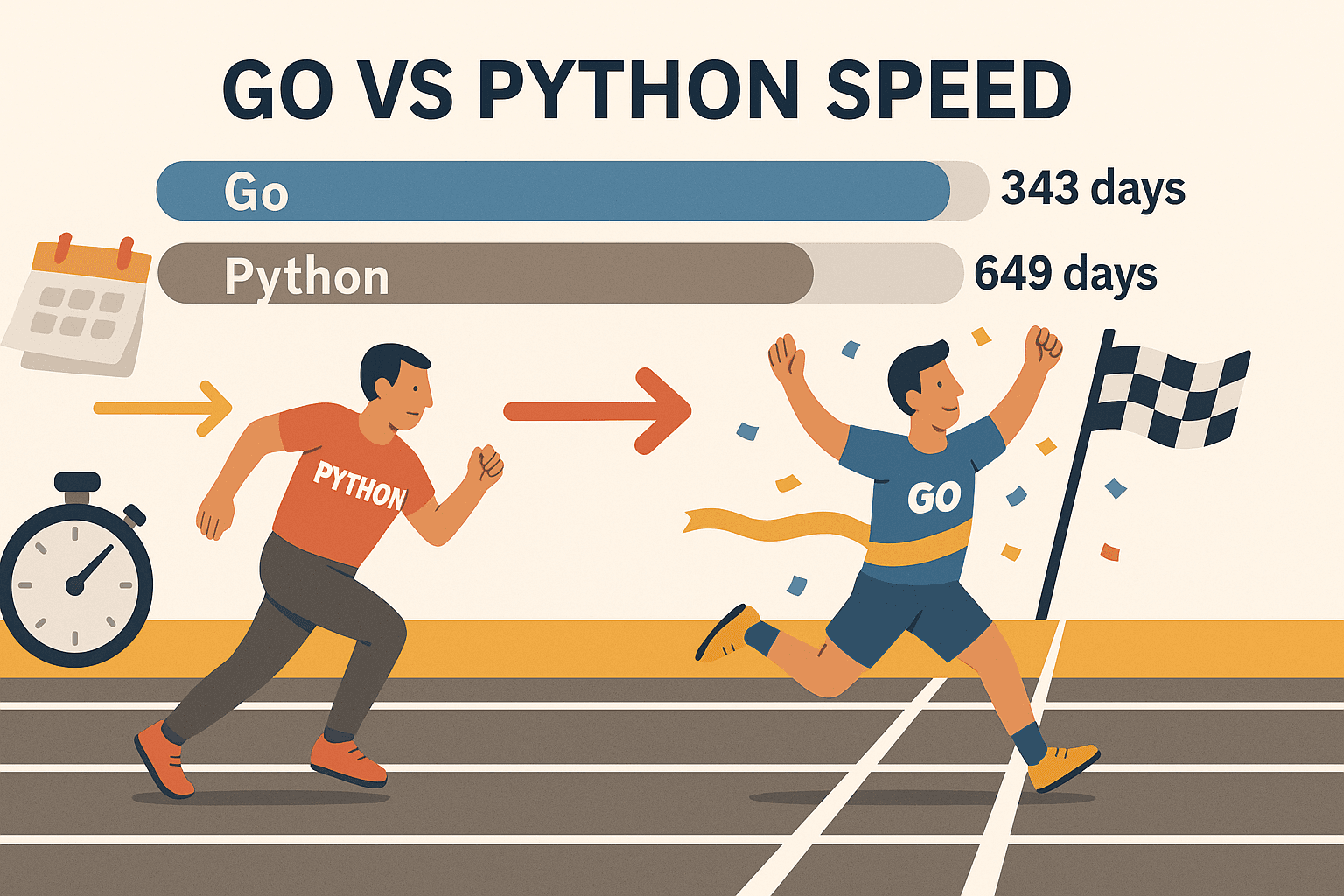
- Concurrence massive : Les goroutines de Go (des threads super légers) permettent de traiter des centaines de pages en même temps — sans faire chauffer ton ordi. Dans un benchmark, Go a extrait 500 millions d’URLs en 343 jours, alors que Python en a mis 649 pour le même taf. C’est pas juste plus rapide, c’est carrément un autre monde.
- Fiabilité béton : Le typage fort et la gestion de mémoire efficace font de Go un choix royal pour les extracteurs qui tournent longtemps et à grande échelle. Fini les scripts qui plantent en pleine nuit.
- Réseau intégré : La bibliothèque standard de Go a tout ce qu’il faut pour les requêtes HTTP, le parsing HTML et la gestion du JSON — pas besoin de courir après des paquets externes pour démarrer.
- Déploiement easy : Go compile tout dans un seul binaire, exécutable partout — pas de virtualenv, pas de galère de dépendances.
- Adopté par les gros : Go est maintenant le langage n°1 pour les requêtes API automatisées (devant Node.js), et il est utilisé par des géants comme Google, Uber ou Netflix.
Bien sûr, Python reste top pour des scripts rapides ou si tu as besoin de bibliothèques de machine learning. Mais pour la vitesse, la montée en charge et la fiabilité, Go est difficile à battre — surtout avec des bibliothèques comme Colly ou Goquery.
Étape 1 : Préparer ton environnement Go pour le Web Scraping
Avant de te lancer dans l’extraction de données, il faut installer Go. Bonne nouvelle : c’est super simple.
1. Installer Go
- Va sur la page officielle de téléchargement de Go et choisis l’installateur qui va bien (Windows, macOS ou Linux).
- Lance l’installation et suis les instructions. Sous Linux, tu peux aussi passer par ton gestionnaire de paquets.
- Ouvre un terminal et tape :
Si tu vois un message du genrego versiongo version go1.21.0 darwin/amd64, c’est tout bon.
Dépannage : Si la commande go n’est pas reconnue, vérifie que ta variable PATH est bien configurée. Sous Linux/macOS, ajoute si besoin export PATH=$PATH:/usr/local/go/bin à ton ~/.bash_profile ou ~/.zshrc.
2. Initialiser un nouveau projet Go
- Crée un dossier pour ton extracteur :
mkdir mon-scraper && cd mon-scraper - Initialise un module Go :
Ça crée un fichiergo mod init github.com/tonpseudo/mon-scrapergo.modpour gérer tes dépendances.
3. Choisir un éditeur
- VS Code avec l’extension Go, c’est le top (auto-complétion, linting, débogage).
- JetBrains GoLand est aussi très apprécié des devs Go.
- Vim/Neovim avec les bons plugins si tu es old school.
4. Tester ton installation
Crée un fichier main.go tout simple :
package main
import "fmt"
func main() {
fmt.Println("Go est installé et fonctionne !")
}
Lance-le :
go run main.go
Si le message s’affiche, tu es prêt à passer à la suite.
Étape 2 : Faire ta première requête HTTP en Go
C’est le moment de récupérer ta première page web ! Le package net/http de Go rend ça super facile.
Exemple de requête GET basique :
package main
import (
"fmt"
"io"
"net/http"
)
func main() {
resp, err := http.Get("https://example.com")
if err != nil {
fmt.Println("Erreur lors de la récupération de l’URL :", err)
return
}
defer resp.Body.Close()
body, err := io.ReadAll(resp.Body)
if err != nil {
fmt.Println("Erreur lors de la lecture de la réponse :", err)
return
}
fmt.Println(string(body))
}
À retenir :
- Toujours checker les erreurs après
http.Get. - Utiliser
defer resp.Body.Close()pour libérer les ressources. - Utiliser
io.ReadAllpour lire toute la réponse.
Tips :
- Pour mettre des headers personnalisés (genre un User-Agent de navigateur), utilise
http.NewRequest:req, _ := http.NewRequest("GET", "https://example.com", nil) req.Header.Set("User-Agent", "Mozilla/5.0") client := &http.Client{} resp, err := client.Do(req) - Vérifie toujours
resp.StatusCode— 200 c’est OK, 403 ou 404 c’est bloqué ou inexistant.
Étape 3 : Analyser le HTML et extraire les données avec Go
Récupérer le HTML, c’est juste le début. Maintenant, il faut extraire ce qui t’intéresse : noms de produits, prix, liens, etc.
Goquery à la rescousse : Cette bibliothèque Go te donne des sélecteurs façon jQuery pour parser le HTML facilement.
Installer Goquery :
go get github.com/PuerkitoBio/goquery
Exemple : extraction de noms et prix de produits
package main
import (
"fmt"
"net/http"
"github.com/PuerkitoBio/goquery"
)
func main() {
resp, err := http.Get("https://example.com/products")
if err != nil {
panic(err)
}
defer resp.Body.Close()
doc, err := goquery.NewDocumentFromReader(resp.Body)
if err != nil {
panic(err)
}
doc.Find("div.product").Each(func(i int, s *goquery.Selection) {
name := s.Find("h2").Text()
price := s.Find(".price").Text()
fmt.Printf("Produit %d : %s - %s\n", i+1, name, price)
})
}
Comment ça marche :
doc.Find("div.product")sélectionne tous les blocs produits.- À l’intérieur,
s.Find("h2").Text()chope le nom, ets.Find(".price").Text()le prix.
Expressions régulières : Pour des motifs simples (emails, etc.), le package regexp de Go est rapide et efficace. Pour le reste, Goquery fait le job.
Étape 4 : Booster ton extracteur avec les bibliothèques Go (Colly & Gocolly)
Envie de passer à la vitesse supérieure ? Colly est le framework de référence pour le web scraping en Go. Il gère le crawling, la concurrence, les cookies, etc. — tu peux te concentrer sur la donnée, pas sur la plomberie.
Pourquoi Colly est top :
- API simple : Tu définis des callbacks pour les éléments à extraire.
- Concurrence : Scrape des centaines de pages en parallèle avec
colly.Async(true). - Crawling automatique : Suivi des liens et pagination facilités.
- Anti-bot : Headers personnalisés, rotation des user agents, gestion des cookies.
- Gestion des erreurs : Hooks intégrés pour les requêtes qui plantent.
Installer Colly :
go get github.com/gocolly/colly/v2
Exemple d’extracteur Colly basique :
package main
import (
"fmt"
"github.com/gocolly/colly/v2"
)
func main() {
c := colly.NewCollector(
colly.AllowedDomains("example.com"),
colly.Async(true),
)
c.OnHTML(".product-list-item", func(e *colly.HTMLElement) {
name := e.ChildText("h2")
price := e.ChildText(".price")
fmt.Printf("Produit : %s - %s\n", name, price)
})
c.OnRequest(func(r *colly.Request) {
r.Headers.Set("User-Agent", "Mozilla/5.0")
})
c.OnError(func(r *colly.Response, err error) {
fmt.Println("Échec de la requête :", r.Request.URL, "->", err)
})
c.Visit("https://example.com/products")
c.Wait()
}
Comparatif des fonctionnalités : Goquery vs. Colly
| Fonctionnalité | Goquery | Colly |
|---|---|---|
| Parsing HTML | Oui | Oui (utilise Goquery) |
| Requêtes HTTP | Manuel | Intégré |
| Concurrence | Manuel (goroutines) | Facile (Async(true)) |
| Crawling/Suivi de liens | Manuel | Automatique |
| Anti-bot | Manuel | Intégré |
| Gestion des erreurs | Manuel | Intégré |
Colly te fait gagner un temps fou dès que le scraping devient un peu costaud.
Étape 5 : Gérer les galères du web scraping en Go
Le web scraping dans la vraie vie, c’est pas toujours une promenade. Voilà comment gérer les principaux obstacles :
1. Blocage d’IP
- Alterne les proxies avec
http.Transportde Go ou le support proxy de Colly. - Ralentis tes requêtes avec des délais aléatoires.
2. User-Agent et headers
- Utilise toujours un User-Agent crédible (Chrome, Firefox, etc.).
- Imite les headers d’un vrai navigateur (Accept-Language, etc.).
3. CAPTCHAs
- Si tu tombes sur un CAPTCHA, c’est souvent que tu vas trop vite ou que tu es trop visible.
- Utilise des navigateurs headless (comme Rod) pour les sites qui demandent du JavaScript ou une interaction visuelle.
- Pour les sites vraiment blindés, pense à un service de résolution de CAPTCHA.
4. Pagination
- Avec Colly, suis automatiquement les liens « Suivant » :
c.OnHTML("a.next", func(e *colly.HTMLElement) { e.Request.Visit(e.Attr("href")) })
5. Contenu dynamique (JavaScript)
- Les bibliothèques HTTP de Go n’exécutent pas le JS. Utilise un navigateur headless (Rod, chromedp) ou vise les endpoints API si possible.
6. Quand c’est trop galère… Utilise Thunderbit
Parfois, certains sites sont trop dynamiques ou tu as besoin des données vite fait sans coder. C’est là que Thunderbit entre en jeu. Thunderbit, c’est une extension Chrome d’extracteur web IA qui :
- Utilise l’IA pour détecter et extraire les champs — tu cliques sur « Suggérer des colonnes IA » et c’est parti.
- Gère la navigation sur les sous-pages et la pagination tout seul.
- Fonctionne dans un vrai navigateur (ou dans le cloud), donc compatible avec les sites JavaScript et la plupart des protections anti-bot.
- Exporte direct vers Excel, Google Sheets, Airtable ou Notion — sans écrire une ligne de code.
- Permet de planifier des extractions et d’automatiser la collecte de données pour ton équipe.
Thunderbit, c’est l’allié parfait pour les équipes commerciales, les utilisateurs métier ou toute personne qui veut des données propres sans se prendre la tête avec le code. Et oui, je prêche pour ma paroisse — mon équipe et moi l’avons créé pour régler exactement ces problèmes.
Essayez gratuitement l’Extracteur Web IA Thunderbit
Mixer Go et Thunderbit pour une productivité au top
Le secret : pas besoin de choisir entre Go et Thunderbit. Les équipes les plus efficaces utilisent les deux.
Exemple de workflow :
- Utilise Go (avec Colly) pour parcourir une grosse liste d’URLs ou collecter des données de base à grande échelle.
- Passe les URLs à Thunderbit pour extraire des infos détaillées et structurées — surtout pour les sous-pages, le contenu dynamique ou les sites bien protégés.
- Exporte les données de Thunderbit vers Google Sheets ou CSV.
- Utilise à nouveau Go pour traiter, fusionner ou analyser les données selon tes besoins.
Cette approche hybride te donne la rapidité et le contrôle de Go, combinés à la flexibilité et l’intelligence de l’IA de Thunderbit. C’est comme avoir un couteau suisse et une perceuse dans ta boîte à outils.
Comparatif des solutions de web scraping Go : Go natif vs. Colly vs. Thunderbit
Voici un tableau récap pour choisir l’outil qui colle à ton besoin :
| Aspect | Go natif (net/http + html) | Go + Colly (Librairie) | Thunderbit (IA sans code) |
|---|---|---|---|
| Prise en main | Complexe (code requis) | Moyenne (API plus simple) | Ultra simple (IA, sans code) |
| Concurrence | Manuel (goroutines) | Intégré (Async(true)) | Parallélisme cloud/navigateur |
| Contenu dynamique (JS) | Navigateur headless | Support JS partiel, ou Rod | Navigateur complet, gère le JS |
| Anti-bot | Manuel (proxies, headers) | Fonctionnalités intégrées | Automatique, IPs cloud |
| Structuration des données | Code personnalisé | Callbacks, structs | IA, formatage automatique |
| Export | Personnalisé (CSV, DB, etc.) | Personnalisé | Excel, Sheets, Notion, Airtable |
| Maintenance | Élevée (code à mettre à jour) | Moyenne | Faible (IA s’adapte aux changements) |
| Idéal pour | Développeurs, pipelines sur-mesure | Dév, prototypage rapide | Non-codeurs, utilisateurs métier |
Astuce : Utilise Go/Colly pour les projets sur-mesure, à grande échelle ou intégrés au backend. Prends Thunderbit pour la rapidité, la simplicité ou les sites complexes côté front.
À retenir : Démarrer le web scraping avec Go
Comment extraire n'importe quel site avec l'IA Get Started Free
- Go, c’est la référence pour le web scraping — surtout pour la vitesse, la concurrence et la fiabilité.
- Commence simple : Installe Go, fais tes premières requêtes HTTP et parse le HTML avec Goquery.
- Passe à la vitesse supérieure avec Colly : Pour le crawling, la concurrence et les astuces anti-bot, Colly est incontournable.
- Gère les vraies galères : Alterne les proxies, configure les headers, et utilise des navigateurs headless ou Thunderbit pour les sites coriaces.
- Combine les outils : N’hésite pas à mixer Go et Thunderbit pour profiter du meilleur des deux mondes.
Le web scraping, c’est un vrai accélérateur pour les équipes commerciales, opérationnelles ou de recherche. Avec Go, les bonnes bibliothèques (et une pincée d’IA), tu automatises les tâches répétitives et tu te concentres sur l’essentiel : l’analyse et la prise de décision.
Ressources pour aller plus loin avec le web scraping Go
Envie de creuser ? Voici quelques ressources à ne pas manquer :
- Documentation officielle Go
- Docs du package net/http
- Goquery GitHub & Docs
- Documentation Colly
- Guide ScrapingAnt : Web Scraping avec Go
- ZenRows : Go vs. Python pour le web scraping
- Blog Thunderbit
- Télécharger l’extension Chrome Thunderbit
- Chaîne YouTube Thunderbit
- Forums Go (Stack Overflow, r/golang)
Bon scraping — que tes données soient toujours bien rangées, tes extracteurs rapides et ton café bien serré !
Commencer avec l’Extracteur Web IA Thunderbit
FAQ
1. Pourquoi utiliser Go pour le web scraping plutôt que Python ou JavaScript ?
Go offre une concurrence, une rapidité et une fiabilité au top — surtout pour les projets de scraping à grande échelle ou qui tournent longtemps. Parfait pour extraire des milliers de pages vite fait et obtenir un binaire portable et compilé.
2. Quelle est la façon la plus simple de parser du HTML en Go ?
Utilise la bibliothèque Goquery. Elle propose des sélecteurs façon jQuery pour naviguer dans le DOM et extraire les données facilement.
3. Comment gérer les sites avec du contenu généré en JavaScript en Go ?
Il te faudra une bibliothèque de navigateur headless comme Rod ou chromedp. Sinon, opte pour Thunderbit pour une solution sans code, basée sur navigateur, qui gère le JS nativement.
4. Comment éviter d’être bloqué lors du scraping ?
Alterner les User-Agent, utiliser des proxies, ajouter des délais entre les requêtes et imiter le comportement d’un vrai navigateur. Colly facilite ces astuces, et Thunderbit gère la plupart des protections anti-bot tout seul.
5. Puis-je combiner Go et Thunderbit dans mon workflow ?
Carrément ! Utilise Go pour le crawling à grande échelle ou l’intégration backend, et Thunderbit pour l’extraction IA, le scraping de sous-pages et l’export vers tes outils métier. C’est une combinaison puissante pour les devs comme pour les utilisateurs métier.
Prêt à passer à la vitesse supérieure ? Teste l’extension Chrome gratuite Thunderbit ou va faire un tour sur le Blog Thunderbit pour plus d’astuces, de tutos et d’analyses sur le scraping, l’automatisation et l’IA.
Essayer l’Extracteur Web IA Get Started Free




