Laisse-moi te partager un petit secret : Internet, c’est la plus grande bibliothèque de la planète… mais la plupart des bouquins sont sous clé. Tous les jours, je discute avec des entrepreneurs, des marketeurs ou des équipes commerciales qui savent que les sites web regorgent de trésors — fiches produits, tarifs des concurrents, avis clients, contacts — mais pour mettre la main sur ces infos ? Là, ça se corse. Après des années à bosser dans l’automatisation SaaS, j’en ai vu passer : des marathons de copier-coller, des scripts Python bricolés à la va-vite… Heureusement, aujourd’hui, extraire du texte d’un site web n’a jamais été aussi simple (et sans prise de tête), grâce aux extracteurs web IA nouvelle génération et aux extensions malines pour navigateur.
Dans ce guide, je te dévoile toutes les méthodes efficaces que j’ai testées — du bon vieux copier-coller aux solutions IA dernier cri comme (oui, c’est notre bébé, mais je te donne le vrai tableau, avec les points forts ET les limites). Que tu sois un as du tableur, un développeur chevronné ou juste lassé de perdre des heures à fouiller des pages web, tu trouveras ici la méthode qui colle à tes besoins. Prêt à déverrouiller ces livres numériques et à récupérer les infos qui comptent ? On y va !
Extraire du texte d’un site web : c’est quoi exactement ?
Quand on parle d’« extraire du texte d’un site web », il s’agit tout simplement de récupérer les infos visibles (et parfois cachées) sur une page web, pour les réutiliser dans un format pratique — tableur, base de données, ou même un document Word bien propre. Mais tous les textes web ne se ressemblent pas :
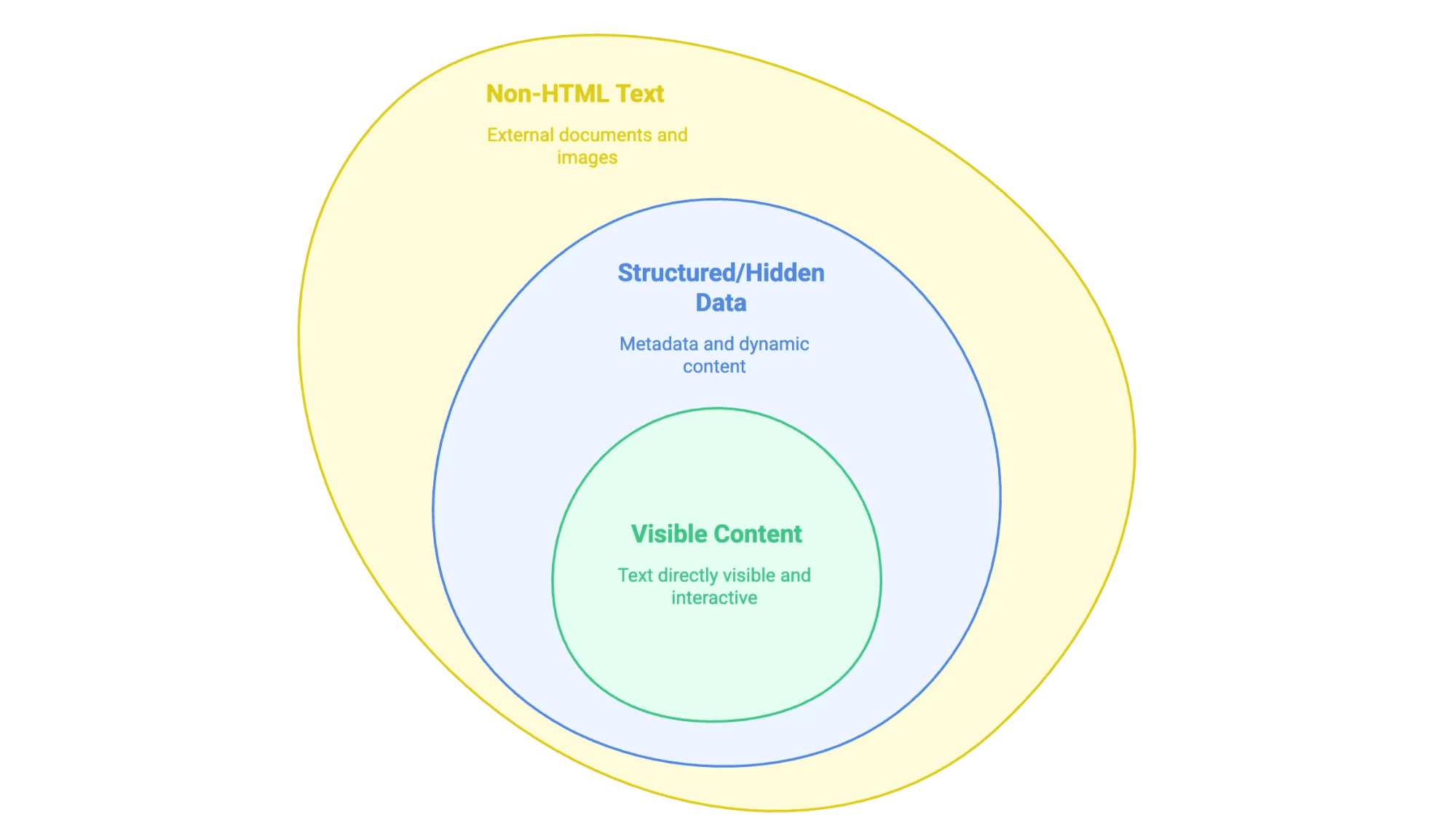
- Contenu visible : Ce que tu peux sélectionner à la souris — texte principal, titres, listes, tableaux, descriptions produits, articles de blog, etc.
- Données structurées ou cachées : Par exemple, les métadonnées dans les balises
<meta>, les scripts JSON-LD, ou les infos chargées dynamiquement en JavaScript (qui n’apparaissent qu’après un clic ou un scroll). - Texte non-HTML : Fichiers PDF, documents Word, ou images contenant du texte (contrats scannés, infographies) intégrés ou liés sur le site.
L’astuce, c’est de bien cibler le type de contenu à extraire, car chaque cas demande une approche différente.
Pourquoi extraire du texte d’un site web ? Avantages et cas d’usage business
Soyons francs : personne ne s’amuse à extraire du texte de sites web juste pour le fun (sauf si c’est ton hobby caché !). Les boîtes le font parce que le retour sur investissement est bien réel. Le marché des logiciels d’extraction de données web a dépassé , et la tendance ne fait que s’accélérer. Pourquoi ?
| Équipe | Exemple d’utilisation | Bénéfice |
|---|---|---|
| Commercial | Extraire des annuaires pour trouver des leads & contacts | Prospection plus rapide et enrichie |
| Marketing | Récupérer les articles de blogs concurrents & données SEO | Analyse de contenu, veille tendances |
| Opérations | Suivre les prix sur les sites e-commerce | Tarification dynamique, suivi des stocks |
| Immobilier | Agréger les annonces & détails de biens | Analyse de marché, génération de leads |
| Support | Collecter les avis clients & forums | Analyse de sentiment, détection précoce des problèmes |
Quelques exemples concrets :

- Génération de leads : Un fournisseur dans la restauration a en quelques minutes au lieu de plusieurs jours.
- Veille concurrentielle : Des enseignes comme John Lewis ont grâce à l’analyse automatisée des prix.
- Analyse SEO : Les équipes extraient balises et mots-clés pour .
Et avec les outils dopés à l’IA, les entreprises économisent sur la collecte de données par rapport aux méthodes classiques.
Méthodes manuelles : les bases du copier-coller de texte web
On commence par le plus basique. Parfois, il suffit de récupérer un extrait vite fait — pas besoin d’outil compliqué.
Comment extraire manuellement du texte
- Copier-coller : Ouvre la page, sélectionne le texte, puis Ctrl+C (ou clic droit > Copier). Colle ensuite dans ton document ou tableur.
- Enregistrer la page : Dans le navigateur, Fichier > Enregistrer sous. Choisis « Page web, HTML uniquement » pour le code source, ou .txt pour le texte brut.
- Imprimer en PDF : Utilise la fonction d’impression du navigateur pour « Enregistrer en PDF ». Ouvre ensuite le PDF et copie le texte (ou utilise « Enregistrer en texte » dans ton lecteur PDF).
- Outils développeur : Clic droit > Inspecter ou F12 pour ouvrir les DevTools. Tu peux y voir le code HTML, repérer les balises meta ou les scripts JSON, et copier ce qui t’intéresse.
Limites
Le manuel, c’est bien pour un besoin ponctuel, mais dès qu’il y a du volume, c’est la galère. C’est . J’ai vu des stagiaires passer des journées entières à recopier des tableaux ligne par ligne… Personne ne veut de ce job !
Extensions de navigateur et outils en ligne pour extraire du texte d’un site web
Envie de passer à la vitesse supérieure ? Les extensions de navigateur et outils en ligne sont la solution rêvée pour la plupart des pros : pas de code, pas de prise de tête, juste quelques clics.
Pourquoi utiliser ces outils ?

- Bien plus rapide que le copier-coller manuel
- Aucune compétence technique nécessaire
- Gère les tableaux, listes, et parfois même les fichiers
- Export direct vers Excel, Google Sheets, CSV, etc.
Voyons les options les plus populaires.
Thunderbit : Extracteur Web IA pour une extraction rapide et précise
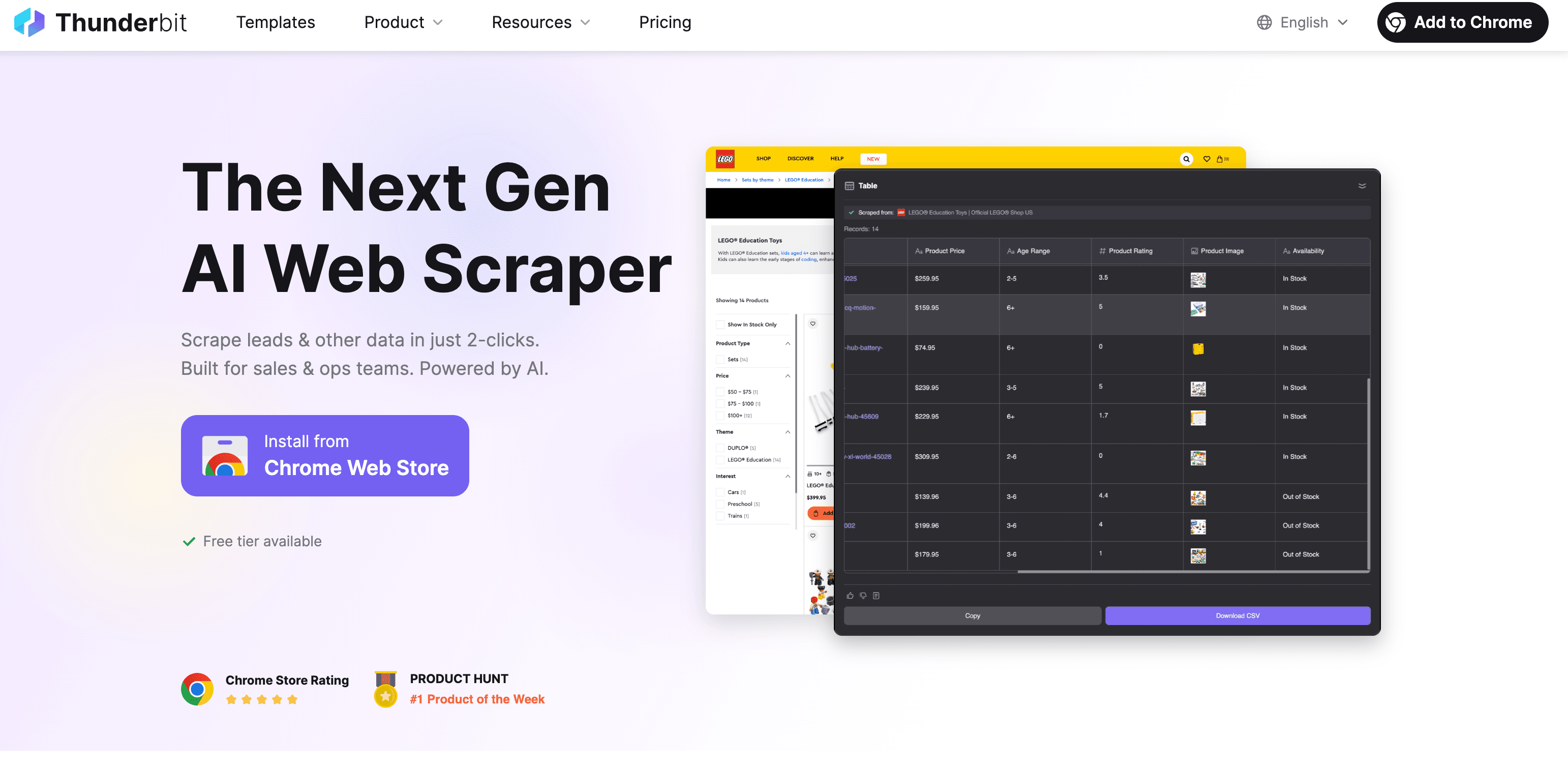
Je ne vais pas te mentir, je prêche un peu pour ma paroisse, mais a vraiment été pensé pour rendre l’extraction de texte web aussi simple que commander une pizza. Voici comment ça marche :
Pas à pas : extraire du texte avec Thunderbit
- Installe l’extension Chrome : sur le Chrome Web Store.
- Ouvre le site cible : Va sur la page dont tu veux extraire le texte.
- Clique sur « Suggestion IA » : L’IA de Thunderbit analyse la page et propose automatiquement les champs à extraire (nom, prix, description, etc.).
- Ajuste si besoin : Modifie ou ajoute des champs selon tes besoins.
- Clique sur « Extraire » : Thunderbit collecte les données, y compris sur les sous-pages ou listes paginées.
- Exporte : Télécharge tes données vers Excel, Google Sheets, Airtable, Notion, ou en CSV/JSON. Aucun frais caché pour l’export.
Pourquoi Thunderbit sort du lot ?
- Suggestion de champs par IA : Plus besoin de bidouiller des sélecteurs ou du code. L’IA repère ce qui compte sur la page.
- Gestion des sous-pages & pagination : Besoin de détails sur chaque fiche produit d’une catégorie ? Thunderbit navigue tout seul.
- Extraction depuis PDF, images et documents : Un manuel PDF ou une fiche technique en image ? L’OCR intégré de Thunderbit extrait aussi le texte de ces fichiers.
- Support multilingue : Fonctionne dans 34 langues (on attend toujours le klingon !).
- Export gratuit : Pas de blocage à l’export des données.
- Cas d’usage : Descriptions produits, contacts, contenus de blog, listes de prospects, etc.
Envie de voir Thunderbit en action ? Jette un œil à notre pour des tutos comme .
Autres extensions et outils en ligne
Petit tour d’horizon des autres solutions que tu croiseras sûrement :
- Extracteur Web () : Gratuit, simple à prendre en main, mais demande un peu d’apprentissage. Idéal pour les analystes à l’aise avec la technique, il faut configurer des « sitemaps » et des sélecteurs. Gère la pagination, mais pas les PDF ou images. .
- CopyTables : Ultra simple — copie les tableaux HTML vers le presse-papiers ou Excel. Parfait pour récupérer un tableau ponctuellement, mais limité à une page et aux tableaux. .
- ScraperAPI () : Pour les développeurs. Tu envoies une URL, il renvoie le HTML (gère les proxys, blocages, etc.), mais il faut ensuite parser le texte toi-même. .
Quand utiliser quel outil ?
- Thunderbit : Pour la rapidité, l’aide de l’IA et le support multi-format (y compris PDF/images).
- Extracteur Web : Si tu aimes bidouiller et veux plus de contrôle.
- CopyTables : Pour extraire un tableau vite fait, sans prise de tête.
- ScraperAPI : Si tu développes ton propre extracteur en code.
Extraction automatisée : solutions programmées pour extraire du texte web
Si tu es développeur (ou que tu en as un sous la main), coder ton propre extracteur te donne un contrôle total. Voici le principe :
- Envoyer une requête HTTP : Utilise
requestsen Python (ou équivalent) pour récupérer la page. - Analyser le HTML : Avec
BeautifulSoup,lxmlouScrapypour cibler le texte voulu. - Extraire & exporter : Nettoie et sauvegarde le texte en CSV, JSON ou base de données.
Exemple : Python + Beautiful Soup
1import requests
2from bs4 import BeautifulSoup
3url = "<http://quotes.toscrape.com>"
4response = requests.get(url)
5soup = BeautifulSoup(response.text, 'html.parser')
6quotes = [q.get_text() for q in soup.find_all("span", class_="text")]
7for qt in quotes:
8 print(qt)Avantages & inconvénients
- Avantages : Flexibilité maximale, compatible avec tout type de site ou de données, intégration possible à tes systèmes.
- Inconvénients : Demande des compétences en programmation, maintenance régulière, gestion des protections anti-bots.
Quand choisir cette option ?
- Tu dois extraire des milliers (voire millions) de pages.
- Le site est complexe (connexion, formulaires multi-étapes).
- Tu veux intégrer l’extraction directement à tes outils ou applis.
Extraire du texte depuis des formats non-HTML : PDF, Word, images
Les sites web ne se limitent pas au HTML : ils regorgent de PDF, de documents Word et d’images pleines de texte précieux. Voici comment les exploiter :
- PDF textuels : Utilise des outils comme Adobe Acrobat, ou des bibliothèques Python comme
PDFMinerouPyPDF2pour extraire le texte. - PDF scannés : Utilise l’OCR (reconnaissance optique de caractères) avec Tesseract, ou .
Documents Word/Excel
- Word : Utilise
python-docxpour lire les fichiers .docx. - Excel : Utilise
openpyxloupandaspour les fichiers .xlsx.
Images
- Outils OCR : Tesseract en open source, ou des services cloud pour une meilleure précision. Les images de bonne qualité (150–300 DPI) donnent les meilleurs résultats.
L’approche Thunderbit
La fonction « Analyseur d’images/documents » te permet d’importer ou de lier un PDF, une image ou un document, et l’IA extrait le texte (et suggère même des colonnes si elle détecte un tableau). Plus besoin de jongler entre plusieurs outils : traite tes fichiers comme n’importe quelle page web.
Comparatif des méthodes : quelle solution d’extraction choisir ?
Voici un tableau récapitulatif pour t’aider à choisir :
| Méthode | Facilité d’utilisation | Scalabilité | Compétence technique requise | Types de données gérés | Idéal pour |
|---|---|---|---|---|---|
| Manuel (copier-coller) | Très facile | Faible | Aucune | Texte visible uniquement | Petits besoins ponctuels |
| Extensions/outils navigateur | Facile à modéré | Moyenne | Faible à moyenne | HTML, certains tableaux | Non-techniciens, petits à moyens volumes |
| Outils IA (Thunderbit) | Très facile | Élevée | Aucune | HTML, PDF, images, etc. | Pros, contenus variés |
| Programmation (code) | Difficile | Très élevée | Élevée | Tout (avec les bonnes bibliothèques) | Développeurs, gros volumes |
| Extraction non-HTML (OCR) | Moyenne | Faible à moyenne | Moyenne | PDF, images, docs | Quand les fichiers/images sont essentiels |
Pour une solution rapide, flexible et sans prise de tête — surtout en contexte pro — les outils IA comme Thunderbit sont imbattables. Mais si tu veux un contrôle total ou dois traiter des volumes massifs, le développement sur-mesure reste pertinent.
À retenir : commence à extraire du texte web dès aujourd’hui
- Le web regorge de données textuelles précieuses, mais leur extraction n’est pas toujours simple.
- Les méthodes manuelles conviennent aux petits besoins, mais ne sont pas viables à grande échelle.
- Les extensions de navigateur et extracteurs web IA comme rendent l’extraction rapide, fiable et accessible à tous — sans coder.
- Pour les contenus non-HTML (PDF, images), privilégie les outils avec OCR et analyse de documents intégrée.
- Choisis la méthode adaptée aux compétences de ton équipe, à la taille de ton projet et au type de données visées.
Bonne extraction — et que tes sessions de Ctrl+C deviennent de plus en plus rares ! Avec les bons outils, la collecte de données web devient un jeu d’enfant, qui te libère du temps pour des tâches à plus forte valeur ajoutée. Fini les heures perdues à copier-coller, place à l’efficacité et à l’automatisation. En route vers une productivité nouvelle génération !
FAQ
Q1 : Puis-je extraire des données de n’importe quel site ?
R1 : Pas toujours. Certains sites bloquent les extracteurs ou interdisent l’extraction dans leurs conditions d’utilisation. Pense à vérifier la politique du site avant de te lancer.
Q2 : Quelle est la précision des extracteurs web IA ?
R2 : Les extracteurs IA comme Thunderbit sont très fiables, mais peuvent demander quelques ajustements sur des pages complexes ou très dynamiques.
Q3 : Faut-il savoir coder pour utiliser des outils d’extraction web ?
R3 : Non, des outils comme Thunderbit et d’autres extensions sont pensés pour les non-techniciens et ne demandent aucune compétence en programmation.
Q4 : Quels types de données puis-je extraire de PDF ou d’images ?
R4 : Les outils OCR permettent d’extraire du texte, des tableaux, et même des données cachées dans des PDF scannés ou des images, rendant l’extraction bien plus polyvalente.
Pour aller plus loin