
Résumé exécutif
Les opérateurs DTC parlent de marque, de communauté, de création, de fidélisation et d’expérience client. Derrière tout cela se cache une réalité plus discrète : la plupart des sites DTC modernes reposent désormais sur une pile opérationnelle étonnamment similaire. Dans cette étude, nous sommes partis de 1 597 marques DTC candidates, avons résolu 1 431 domaines et mené une analyse au niveau de la page d’accueil pour 1 238 sites de marques le 11 mai 2026. L’objectif n’était pas de classer les marques. Il s’agissait de répondre à une question plus utile pour les opérateurs : lorsque l’on examine les sites publics de marques visibles dans les écosystèmes d’outils e-commerce, quels schémas d’infrastructure apparaissent réellement ?
Le constat le plus net est que la base de la pile opérationnelle DTC s’est standardisée. Google Analytics 4 apparaît sur 84,2 % des échantillons complets. Klaviyo Onsite apparaît sur 47,9 %. Google Tag Manager apparaît sur 41,4 %. Côté paiement, Shop Pay apparaît sur 57,4 % et PayPal sur 48,9 %. Parmi les 1 083 marques où au moins un outil a été détecté, GA4 + Shop Pay coapparaissent dans 65,6 % des cas, GA4 + PayPal dans 56,0 %, PayPal + Shop Pay dans 55,6 % et GA4 + Klaviyo dans 54,6 %. Pour les opérateurs, la conclusion est directe : la pile DTC par défaut n’est plus un secret stratégique. C’est le strict minimum.

Cette uniformité n’est pas l’aspect le plus intéressant. L’important, c’est là où l’uniformité se brise. Les sites DTC paraissent matures sur l’analytics de base, le paiement et l’infrastructure e-mail, mais beaucoup moins sur la préparation à la recherche IA, les données produit structurées, le SEO international, la gouvernance des performances et le lien entre trafic du site et surfaces sociales détenues. Ce sont ces écarts qui créent des benchmarks utiles pour les équipes e-commerce et des angles utiles pour les rédacteurs SEO, les newsletters et les médias spécialisés.
Le résultat le plus contre-intuitif sur la recherche IA est une séparation entre préparation passive et préparation active. llms.txt apparaît sur 57,9 % des échantillons complets, ce qui laisse penser à une large adoption de la préparation à l’IA. Mais 50,8 points de pourcentage de ce total proviennent de fichiers générés automatiquement par Shopify, tandis que seulement 7,1 % des marques disposent d’un signal llms.txt manuel. Dans le même temps, le schéma JSON-LD Product n’apparaît que sur 0,9 % des 1 240 échantillons de page d’accueil récupérés. Cela signifie que de nombreuses marques disposent d’une nouvelle porte d’entrée lisible par l’IA parce que leur plateforme la leur a fournie, mais que très peu exposent des faits produit structurés d’une manière que les moteurs de recherche et les systèmes d’IA peuvent interpréter de façon fiable.
Le deuxième résultat contre-intuitif est que la profondeur de l’outillage n’est pas la principale différence entre les marques les plus visibles et la longue traîne. Le groupe de tête de cet échantillon, défini comme les marques apparaissant dans au moins trois collections sources, affiche en moyenne 4,5 outils d’analytics et de marketing détectés. Le groupe de queue à une seule source affiche en moyenne 4,1. L’écart est faible. Les différences les plus marquées concernent plutôt les signaux de maturité spécifiques : attribution avancée, adoption du frontend headless, analytics comportementale, conformité privacy et architecture de plateforme volontaire.
Le troisième constat est que les sites DTC supportent une vraie dette de performance. Dans les 1 240 échantillons de page d’accueil où les champs de performance étaient disponibles, la médiane est de 52 balises script et 8 domaines tiers. Les valeurs p75 sont de 69 scripts et 12 domaines tiers. Le champ de taille en octets de la page d’accueil est plafonné par les contraintes de collecte et ne doit pas être utilisé comme constat, mais les décomptes de scripts et de domaines tiers restent des indicateurs utiles de densité des dépendances. Beaucoup d’équipes DTC ont échangé vitesse et simplicité contre visibilité marketing, attribution, personnalisation, consentement, chat, support, pixels et outils de test.
Le quatrième constat est que le positionnement DTC « vert » est beaucoup moins visible dans le texte de la page d’accueil que ne le suggère la conversation sectorielle. Dans le texte lisible des pages d’accueil de 1 240 échantillons, free shipping apparaît sur 26,2 %, best seller sur 24,4 %, et le langage de presse ou « vu sur » sur 22,6 %. En revanche, sustainable apparaît sur 4,6 %, eco-friendly sur 1,3 % et cruelty free sur 1,0 %. Cela ne prouve pas que les marques ne sont pas durables. Cela montre simplement que beaucoup d’entre elles ne font pas de la durabilité le principal levier de conversion visible sur la page d’accueil.
Le cinquième constat touche aux réseaux sociaux, mais il est important pour les opérateurs e-commerce : plus de la moitié des échantillons complets de page d’accueil n’affichent aucun lien visible vers les plateformes sociales suivies dans le balisage statique de la page. Ce chiffre comporte des réserves importantes, car les pieds de page rendus côté client et les menus dynamiques peuvent échapper à la détection. Il reste néanmoins un bon signal opérationnel. Si une marque investit dans Instagram, TikTok, YouTube, Pinterest ou X, le site officiel ne devrait pas rendre ces destinations difficiles à trouver.
Ce rapport s’adresse à trois publics. Les équipes DTC et e-commerce peuvent s’en servir comme benchmark opérationnel. Les spécialistes SEO et les créateurs de contenu e-commerce peuvent utiliser les chiffres comme données originales prêtes à être citées, avec les réserves nécessaires. Les rédacteurs spécialisés peuvent y voir une photographie de l’endroit où la pile DTC se standardise, et où le prochain avantage concurrentiel pourrait émerger.
Les cinq enseignements les plus partageables
-
Le DTC a désormais une pile par défaut. Dans cet échantillon, GA4, Klaviyo, Shop Pay et PayPal constituent la base pratique. Le prochain avantage ne consiste pas à « installer des outils », mais à mieux gouverner les données et à mener de meilleures expériences.
-
La préparation à l’IA est surtout passive. llms.txt apparaît sur 57,9 % des échantillons complets, mais la majeure partie est générée par la plateforme. llms.txt manuel n’apparaît que dans 7,1 % des cas, et Product schema dans seulement 0,9 %.
-
La longue traîne a largement rattrapé le volume d’outils. Les marques de tête affichent en moyenne 4,5 outils d’analytics et de marketing détectés, contre 4,1 pour les marques de queue. L’écart ne porte pas sur « combien d’outils », mais sur « quels outils de maturité et comment ils sont utilisés ».
-
De nombreuses pages d’accueil DTC dépendent d’une forte pile de dépendances. La médiane de la page d’accueil dans l’échantillon de performance est de 52 balises script et 8 domaines tiers. La visibilité marketing a un coût en vitesse.
-
Le texte de la page d’accueil est plus commercial que fondé sur les valeurs. « Free shipping » et « best seller » apparaissent bien plus souvent que le vocabulaire de durabilité. C’est utile pour les équipes de contenu, car cela va à l’encontre de l’image que le DTC donne souvent de lui-même.
1. Lire correctement l’échantillon
Ce rapport ne doit pas être lu comme un recensement de toutes les marques DTC du marché. Le pool de départ provenait de sources publiques e-commerce et DTC où les marques avaient des chances d’être visibles : bibliothèques d’études de cas d’outils, contenus liés à l’écosystème Shopify, index DTC publics et listes e-commerce connexes. Cela crée un échantillon de marques repérables via l’écosystème d’outils e-commerce, et non une enquête aléatoire sur le marché.
Cela compte surtout pour l’interprétation des plateformes. Shopify est surreprésenté, car de nombreuses listes sources sont liées à des outils de l’écosystème Shopify ou à des études de cas e-commerce. Dans l’échantillon complet, Shopify apparaît sur 789 des 1 238 sites, soit 63,7 %. Ce chiffre décrit cet échantillon, il ne prétend pas décrire tous les sites DTC. Il ne doit pas être cité comme part de marché sectorielle.
La même prudence s’applique à toute conclusion spécifique à une plateforme. Si un chiffre concerne un outil ou une plateforme qui dispose d’un écosystème solide d’études de cas, il peut être gonflé par la manière dont le pool de marques a été constitué. C’est pourquoi ce rapport insiste moins sur « Shopify domine » et davantage sur des signaux opérationnels toujours utiles dans l’échantillon : cooccurrence des outils, écarts de préparation à l’IA, schémas de paiement, écarts de schéma, visibilité sociale, catégories et dette de performance.
Le rapport mesure aussi des signaux publics du site web, et non la qualité opérationnelle interne. Une marque peut utiliser un outil chargé après consentement de l’utilisateur, injecté via un tag manager, masqué par un rendu côté client ou absent des premiers 256 Ko de HTML récupérés. Les moyens de paiement comme Apple Pay et Google Pay sont particulièrement susceptibles d’être sous-comptés, car ils se chargent souvent dynamiquement. Les taux d’installation d’outils doivent donc être lus comme des bornes inférieures.
Cette limite ne rend pas la donnée inutile. Elle la rend concrète. Nous regardons ce qu’un crawl public peut voir à partir des sites de marques, c’est-à-dire la même surface de visibilité que celle dont disposent les moteurs de recherche, les crawlers d’IA, les outils SEO, les outils de veille concurrentielle et de nombreux journalistes en recherche documentaire rapide. Pour les équipes e-commerce et SEO, cette couche de visibilité publique mérite à elle seule d’être améliorée.
2. La pile DTC par défaut est là
Sur les 1 238 échantillons complets, le site moyen affiche 3,39 outils d’analytics et de marketing détectés, avec une médiane de 3. Ce chiffre couvre le champ des outils d’analytics et de marketing détectés, et non toutes les couches opérationnelles du site. Une fois les signaux de paiement et de checkout ajoutés, la base opérationnelle DTC devient plus large : analytics, fidélisation, coordination des balises, checkout en un clic et au moins un portefeuille ou moyen de paiement familier.
Les principaux outils détectés dessinent la forme de la base DTC moderne :
| Outil | Couverture de l’échantillon complet |
|---|---|
| Google Analytics 4 | 84,2 % |
| Klaviyo Onsite | 47,9 % |
| Google Tag Manager | 41,4 % |
| Microsoft Clarity | 20,6 % |
| Gorgias | 19,1 % |
| Triple Whale | 15,3 % |
| Bing UET | 11,7 % |
| Cookiebot / OneTrust | 9,6 % |
| Rebuy | 9,0 % |
| Attentive | 8,9 % |
L’histoire côté opérateur est simple. GA4 est désormais une instrumentation de base. Klaviyo est la couche de fidélisation DTC. GTM est la couche de coordination des pixels et des balises. Microsoft Clarity, Gorgias, Triple Whale, Cookiebot, Rebuy et Attentive ne sont pas universels, mais ils indiquent différentes formes de maturité opérationnelle : analytics comportementale, support client, attribution, consentement, upsell et SMS.
Le benchmark le plus utile n’est pas un taux d’installation isolé. C’est le schéma de cooccurrence. Parmi les 1 083 marques ayant au moins un outil détecté, les paires les plus fréquentes sont :
| Paire | Cooccurrence |
|---|---|
| GA4 + Shop Pay | 65,6 % |
| GA4 + PayPal | 56,0 % |
| PayPal + Shop Pay | 55,6 % |
| GA4 + Klaviyo Onsite | 54,6 % |
| Klaviyo Onsite + Shop Pay | 51,2 % |
| GA4 + Google Tag Manager | 44,9 % |
| Klaviyo Onsite + PayPal | 44,1 % |
C’est la preuve la plus claire de l’existence d’une pile DTC par défaut : analytics, fidélisation, checkout en un clic et option de portefeuille connue. Pour un nouvel opérateur DTC, c’est utile, car cela réduit l’incertitude. La première tâche n’est pas d’inventer une pile exotique. La première tâche consiste à faire fonctionner proprement la base, avec des événements exacts, un suivi conscient du consentement, un parcours de capture e-mail/SMS opérationnel et un flux de checkout que les clients reconnaissent déjà.
Pour les éditeurs d’outils et les opérateurs SaaS, cela crée un marché plus difficile. Un nouvel outil ne peut pas gagner en se contentant de promettre l’exhaustivité fonctionnelle. La base est déjà encombrée, et les outils leaders sont intégrés dans les workflows. L’opportunité se situe dans la résolution de problèmes que la pile de base gère mal : meilleure attribution sous contraintes de privacy, meilleurs tests de cycle de vie, identité multicanale plus propre, meilleure vente additionnelle post-achat ou conformité internationale moins contraignante.
Les exemples de marques rendent la logique plus concrète. Dans le crawl, des marques comme Beekman 1802, Princess Polly, Fresh Clean Threads et Rare Beauty affichent des piles détectées relativement matures qui combinent analytics, fidélisation, support, consentement, attribution ou outils d’expérience client. L’idée n’est pas que chaque marque doive copier chaque outil. L’idée est que les opérations DTC matures empilent souvent des outils spécialisés au-dessus de la même base, plutôt que de remplacer entièrement cette base.
3. L’écart de recherche IA : llms.txt est partout, Product schema presque nulle part
Le constat le plus cit-able du rapport est l’écart entre llms.txt et les données produit structurées.
Dans l’échantillon complet de sites, 717 marques disposent de llms.txt, soit 57,9 %. À première vue, cela donne l’impression d’une adoption rapide des pratiques de recherche IA par le DTC. Mais la répartition compte :
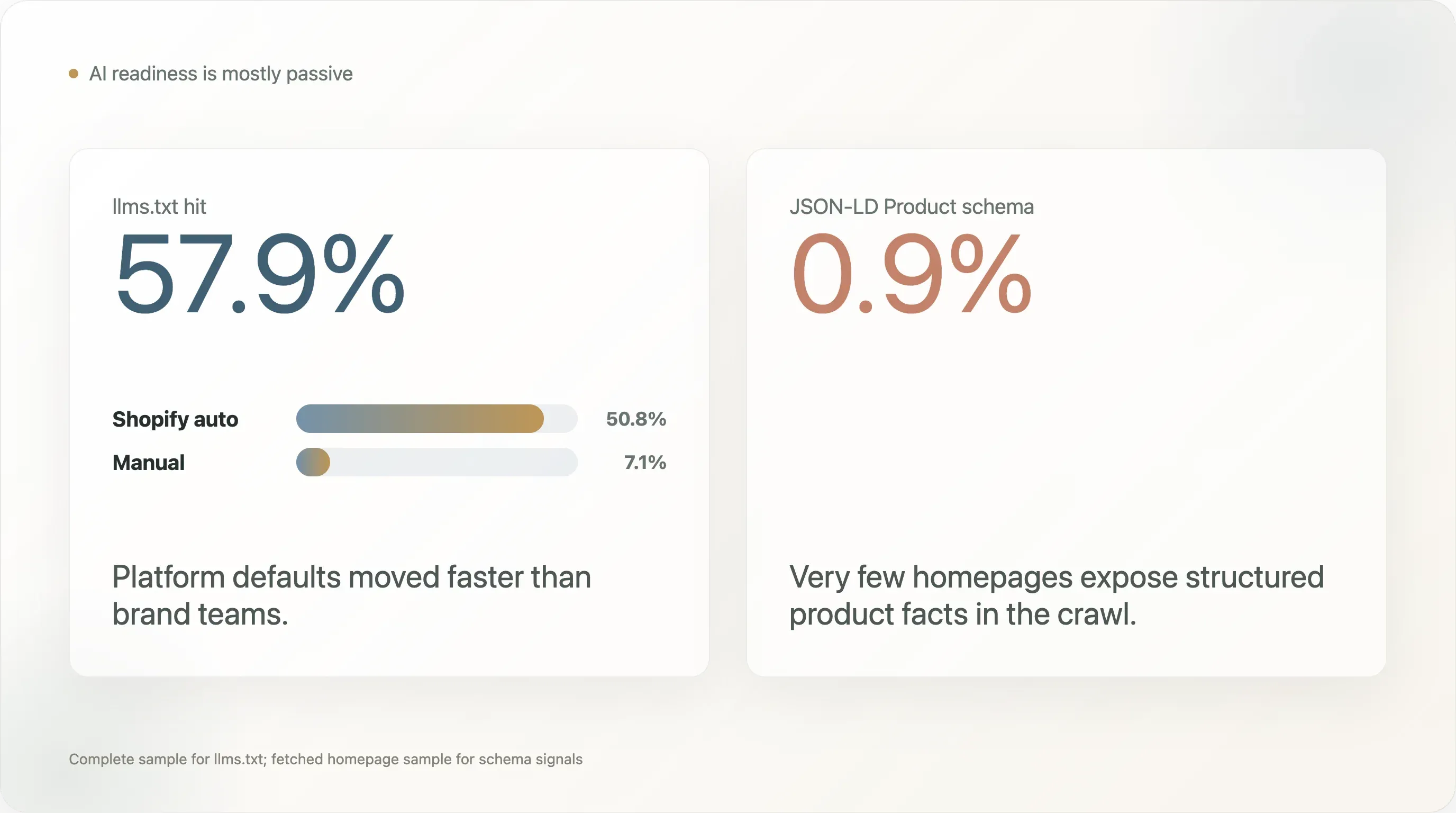
| Statut llms.txt | Nombre | Part de l’échantillon complet |
|---|---|---|
| Détection totale de llms.txt | 717 | 57,9 % |
| Généré automatiquement par Shopify | 629 | 50,8 % |
| Manuel | 88 | 7,1 % |
| Soft 404 | 137 | 11,1 % |
| Non configuré | 383 | 30,9 % |
La conclusion n’est pas que « les marques DTC sont devenues expertes de la recherche IA ». Une meilleure conclusion serait : les réglages par défaut des plateformes peuvent faire évoluer le marché plus vite que les équipes de marque. Lorsqu’une plateforme ajoute automatiquement un nouveau fichier public, de nombreuses marques en bénéficient sans prendre de décision stratégique active. C’est utile, mais ce n’est pas la même chose qu’une optimisation volontaire de la recherche IA.
L’écart le plus important apparaît dans les données structurées. Dans les 1 240 échantillons avec contenu de page d’accueil récupéré, tout JSON-LD confondu apparaît sur 48,4 %, Organization schema sur 39,5 %, WebSite schema sur 36,0 %, BreadcrumbList sur 12,7 % et Product schema sur seulement 0,9 %.
| Signal SEO / schema | Couverture |
|---|---|
| meta viewport | 90,3 % |
| meta description | 84,4 % |
| canonical | 81,2 % |
| og:title | 79,1 % |
| twitter:card | 70,0 % |
| og:image | 65,2 % |
| JSON-LD, tout type | 48,4 % |
| JSON-LD Organization | 39,5 % |
| JSON-LD WebSite | 36,0 % |
| hreflang | 31,5 % |
| JSON-LD BreadcrumbList | 12,7 % |
| manifest | 10,9 % |
| flux RSS | 4,3 % |
| JSON-LD Product | 0,9 % |
Product schema est important, car il aide les moteurs de recherche et les systèmes d’IA à comprendre les entités produit : nom, prix, disponibilité, SKU, avis, images et faits connexes. Une marque peut avoir une belle rédaction et une pile e-commerce moderne, mais si les crawlers publics ne peuvent pas analyser proprement les faits produit, la marque laisse de la découvrabilité sur la table.
Les exemples positifs dans le crawl incluent des marques comme Curie, Manukora, Mokobara, MoxieLash, Unbloat et Viva, apparues parmi le petit groupe de détections Product schema. Elles ne doivent pas être considérées comme les seules marques à faire du travail de produit structuré, car la méthode est centrée sur la page d’accueil et conservatrice. Mais elles constituent des exemples utiles du type de signal structuré que la plupart des pages d’accueil DTC publiques n’exposaient pas dans ce crawl.
Pour les équipes SEO, c’est l’élément le plus actionnable de tout le rapport. Ajouter ou valider Product schema sur les pages produit coûte généralement bien moins cher que de lancer un nouveau canal, reconstruire un site ou ajouter un autre fournisseur d’analytics. C’est aussi facile à expliquer en interne : si la recherche IA et les rich results ont besoin de faits produit structurés, alors la page produit doit publier ces faits dans un format lisible par machine.
Pour les créateurs de contenu, le titre s’écrit presque tout seul : les marques DTC ont obtenu un fichier de recherche IA par défaut, mais presque aucune n’expose Product schema dans le crawl. Ce contraste est plus intéressant qu’une histoire générique du type « la recherche IA arrive », car il pointe un écart concret.
4. Checkout : Shop Pay est la norme, le BNPL reste un signal minoritaire
Le checkout est l’une des couches les plus standardisées de l’échantillon.
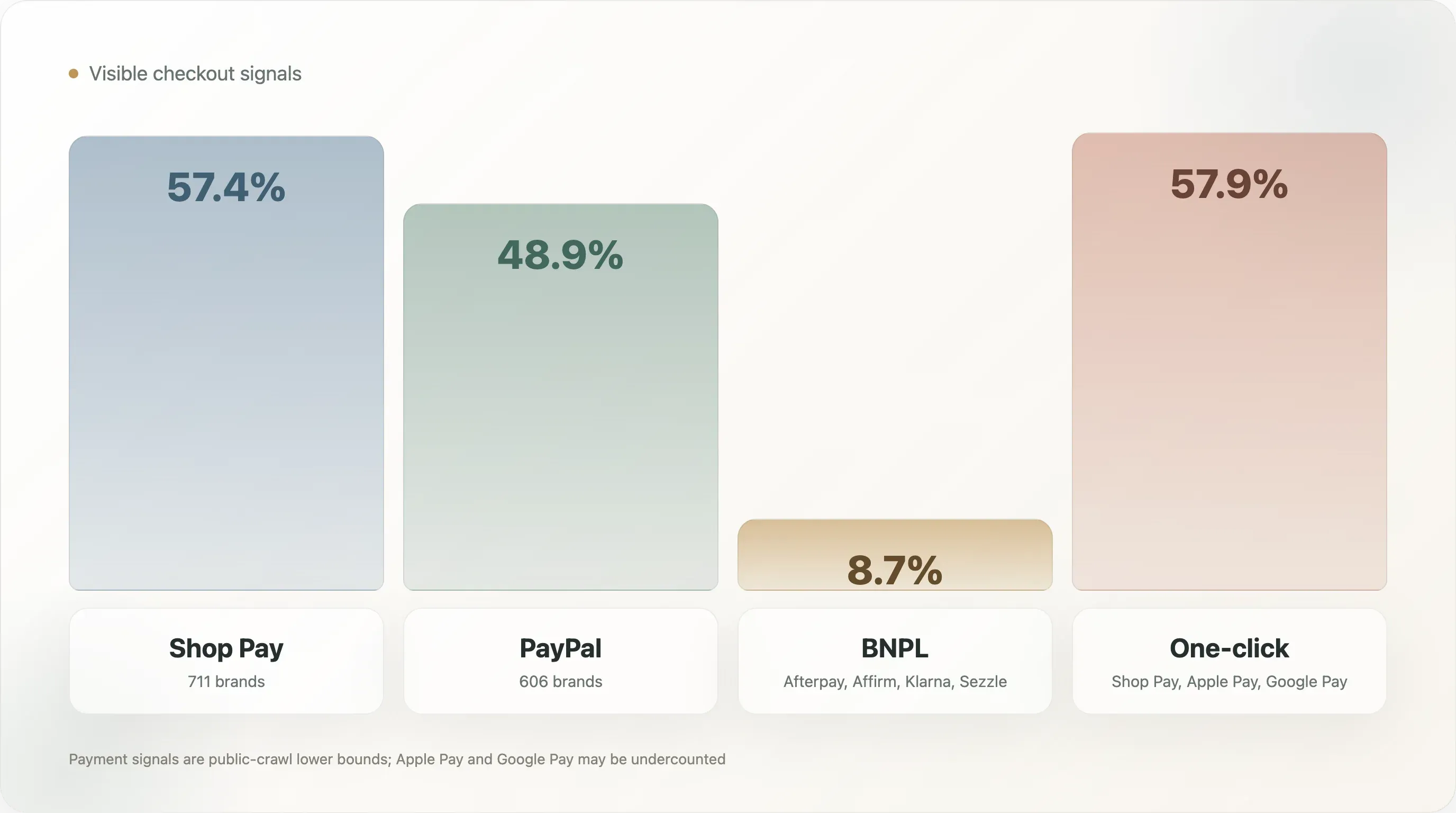
| Moyen de paiement | Marques | Couverture |
|---|---|---|
| Shop Pay | 711 | 57,4 % |
| PayPal | 606 | 48,9 % |
| Afterpay | 73 | 5,9 % |
| Affirm | 24 | 1,9 % |
| Amazon Pay | 16 | 1,3 % |
| Klarna | 14 | 1,1 % |
| Google Pay | 9 | 0,7 % |
| Apple Pay | 5 | 0,4 % |
Le checkout en un clic, défini ici comme Shop Pay, Apple Pay ou Google Pay, apparaît sur 57,9 % des échantillons complets. Le BNPL, défini comme Afterpay, Affirm, Klarna ou Sezzle, apparaît sur 8,7 %.
Apple Pay et Google Pay sont probablement sous-comptés, car ils se chargent souvent via des scripts de checkout dynamiques plutôt que dans le HTML statique de la page d’accueil. Shop Pay et PayPal sont plus faciles à détecter dans cette méthode. La conclusion prudente n’est pas qu’Apple Pay est peu important. La conclusion prudente est que Shop Pay et PayPal sont les signaux de checkout les plus visibles dans ce crawl public.
Le chiffre du BNPL est stratégiquement utile parce qu’il est suffisamment bas pour imposer une décision. Dans cet échantillon, le BNPL n’est pas un standard DTC universel. Il apparaît plus sélectivement selon la catégorie et le niveau de prix. Pour des catégories à panier moyen élevé comme l’habillement, la chaussure, le mobilier, l’équipement ou la beauté premium, le BNPL peut réduire la friction d’achat. Pour des consommables à panier moyen plus faible, l’intérêt peut être moindre.
La question opérateur n’est donc pas « faut-il que chaque marque DTC ajoute le BNPL ? » mais « notre panier moyen, notre structure de marge, l’âge de nos clients, le comportement de retour et le cycle de considération de la catégorie justifient-ils un moyen de paiement supplémentaire ? » Pour les marques au-dessus d’environ 80 $ de panier moyen, le test vaut souvent la peine. Pour les consommables par abonnement, tout dépend de savoir si le BNPL améliore la conversion du premier achat sans affaiblir l’économie de la fidélisation.
Des exemples positifs dans l’écosystème checkout plus large sont faciles à trouver chez des marques DTC matures qui proposent aux clients plus d’une voie de paiement de confiance. Glossier apparaît dans le crawl avec Afterpay, PayPal et Shop Pay. Saatva apparaît avec Affirm dans le champ de paiement. Ces exemples sont utiles car ils montrent différentes logiques par catégorie : la beauté utilise le paiement flexible comme partie intégrante d’une expérience de checkout grand public ; les matelas et les biens d’équipement utilisent le financement pour réduire la friction sur les achats plus importants.
5. Le headless reste un signal de maturité, pas la norme
Dans les 1 238 échantillons complets, les frameworks frontend modernes apparaissent comme suit :
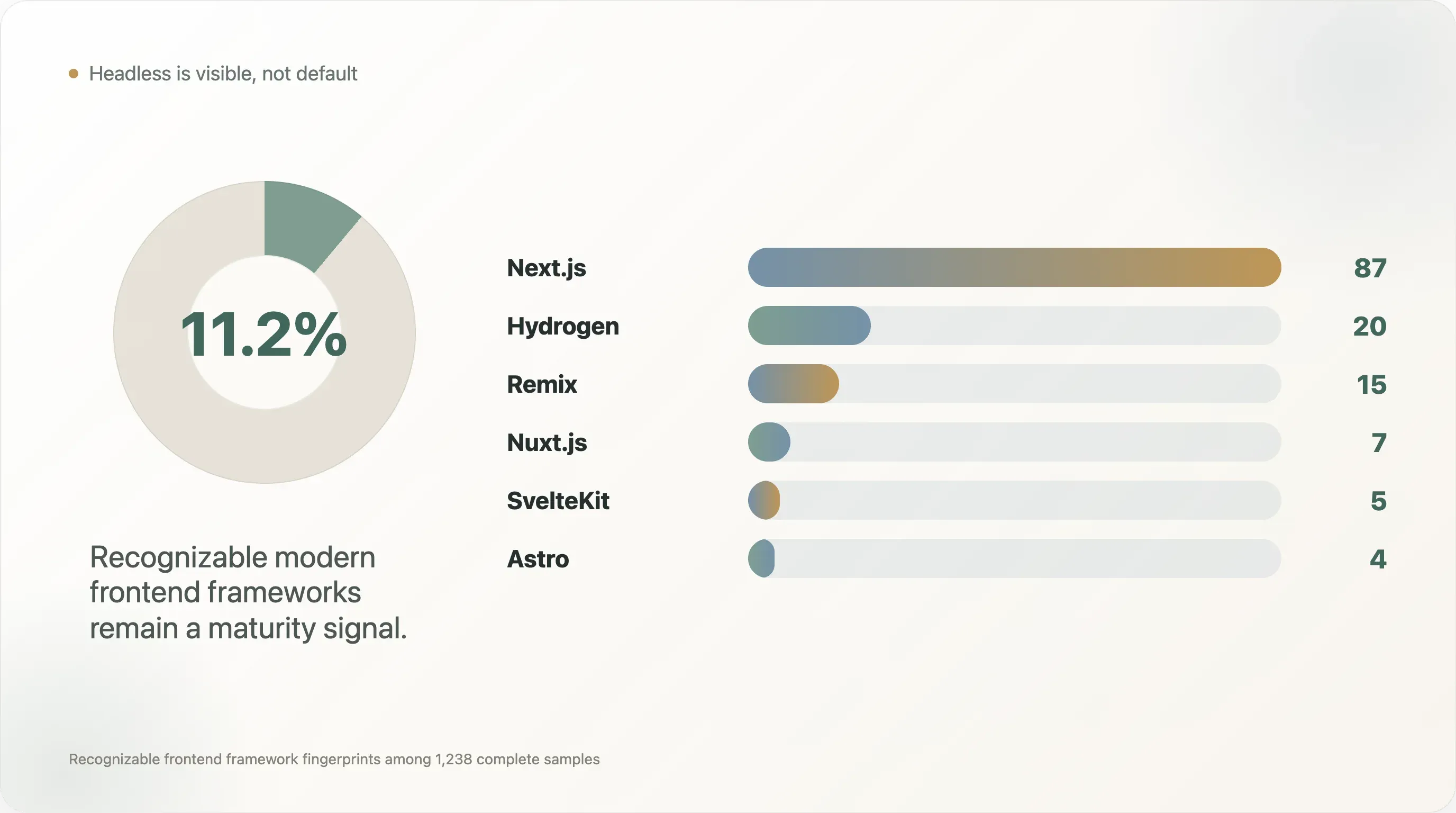
| Frontend | Marques | Part |
|---|---|---|
| Next.js | 87 | 7,0 % |
| Hydrogen | 20 | 1,6 % |
| Remix | 15 | 1,2 % |
| Nuxt.js | 7 | 0,6 % |
| SvelteKit | 5 | 0,4 % |
| Astro | 4 | 0,3 % |
| Gatsby | 1 | 0,1 % |
Pris ensemble, ces frameworks frontend modernes reconnaissables apparaissent sur environ 139 marques, soit 11,2 % de l’échantillon complet. La véritable part du headless peut être plus élevée, car de nombreuses boutiques React ou SPA personnalisées n’exposent pas d’empreintes de framework reconnaissables lors d’un crawl simple.
Le titre n’est pas « tout le monde passe au headless ». Le titre est plus subtil : le headless est suffisamment visible pour compter, mais encore assez rare pour signaler la maturité. La plupart des équipes DTC ne reconstruisent pas leur storefront sur Next.js ou Hydrogen. Les marques qui le font résolvent généralement des problèmes précis : vitesse, contrôle visuel, flexibilité contenu-commerce, architecture internationale, pages d’atterrissage complexes ou contrôle SEO plus fin.
Parmi les exemples positifs du crawl figurent Warby Parker et Stitch Fix avec Next.js, Dr. Squatch, Blueland, Liquid I.V. et Chubbies avec Hydrogen, Hedley Bennett et Harry's avec Remix, et Cocunat et Biossance avec Astro. Ces noms comptent parce que les opérateurs préfèrent des exemples concrets. Ils montrent que le headless n’est pas une tendance abstraite de l’ingénierie ; c’est un schéma visible dans l’optique, les soins personnels, l’alimentation, l’habillement, la beauté et les biens de consommation.
Pour la plupart des marques, cependant, le headless ne doit pas être la première priorité opérationnelle. Un frontend headless peut améliorer les performances et l’expérience de marque, mais il augmente aussi les coûts de maintenance. La marque a besoin de capacité d’ingénierie, de discipline QA, de gouvernance analytics, de gestion des workflows de contenu et de processus de déploiement fiables. Une petite marque sans configuration analytics propre, sans schéma de cycle de vie e-mail, sans implémentation du schéma et sans culture de test du checkout ne devrait pas se lancer directement dans une refonte frontend.
L’échelle de maturité la plus pratique ressemble à ceci :
- Faire fonctionner la base : GA4, fidélisation, checkout, consentement et événements propres.
- Ajouter des données produit structurées et des fondations SEO crawlables.
- Réduire les scripts inutiles et les dépendances tierces.
- Ajouter de l’analytics comportementale ou de l’attribution seulement lorsque l’équipe peut agir sur les données.
- Envisager le headless lorsque la marque a un vrai besoin de vitesse, de contrôle design, d’internationalisation ou de flexibilité contenu-commerce.
Cette échelle est utile parce qu’elle replace le headless dans son contexte. Ce n’est pas un badge. C’est un choix opérationnel.
6. Dette de performance : la page d’accueil devient un hub de fournisseurs
Les champs de performance montrent une tension DTC récurrente. Les équipes marketing veulent visibilité, attribution, pop-ups, avis, personnalisation, support, pixels sociaux, consentement, tests et retargeting. Les équipes d’ingénierie et SEO veulent de la vitesse, moins de dépendances et des pages plus propres. La page d’accueil se situe au milieu.
Dans les 1 240 échantillons de page d’accueil avec métriques de performance :
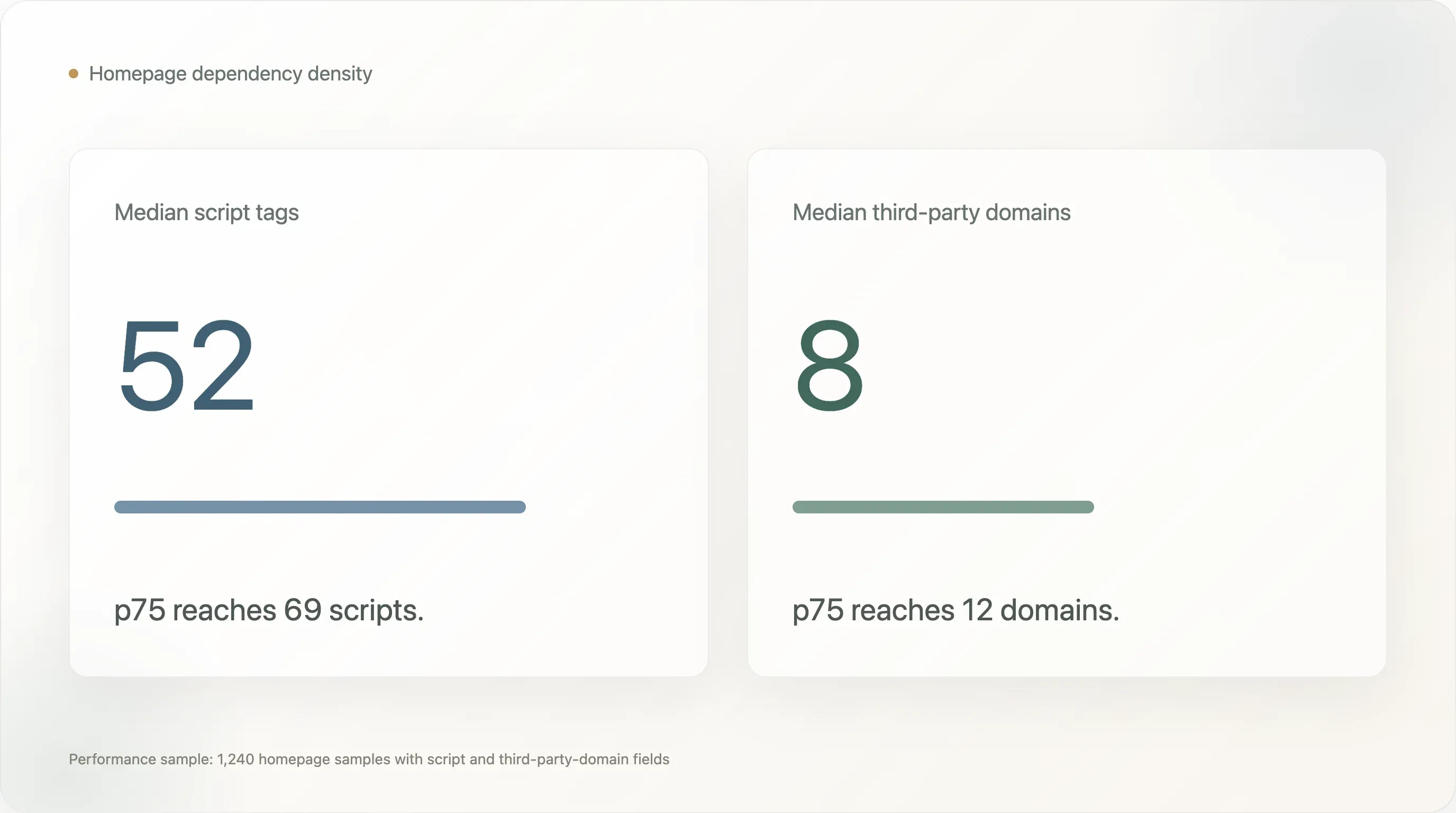
| Métrique | Médiane | p75 | Max |
|---|---|---|---|
| Balises script | 52 | 69 | 305 |
| Domaines tiers | 8 | 12 | 41 |
Le champ de taille en octets de la page d’accueil n’est pas un constat fiable, car le processus de récupération plafonnait les lectures à 256 Ko. Mais le nombre de scripts et le nombre de domaines tiers restent des indicateurs utiles. Une médiane de 52 balises script signifie que la page d’accueil complète typique de l’échantillon n’est pas un document léger. C’est un point de coordination pour de nombreux fournisseurs et comportements côté navigateur.
Cette conclusion est facile à mal interpréter pour les opérateurs. La réponse n’est pas « supprimer tous les outils ». Beaucoup d’outils existent parce qu’ils génèrent du chiffre d’affaires. La meilleure réponse consiste à attribuer une responsabilité. Chaque script doit avoir un propriétaire métier, une raison d’exister, une stratégie de chargement, un comportement vis-à-vis du consentement et un cycle de revue. Sans propriétaire, un script devient une dette de performance.
La bonne question opérateur est : quelles balises justifient encore leur coût ? Un pixel qui soutient un grand canal payant peut valoir le compromis sur la performance. Une balise de test héritée d’un fournisseur que l’équipe n’utilise plus, non. Un outil d’analytics comportementale peut être pertinent si quelqu’un analyse les sessions chaque semaine. Si personne ne regarde les enregistrements, le script est juste un poids.
Pour les équipes SEO, c’est un sujet de passerelle utile. Les Core Web Vitals et le SEO technique sont souvent traités comme des problèmes d’ingénierie, tandis que les balises sont traitées comme des outils marketing. En pratique, ils relèvent du même système opérationnel. Une équipe DTC ne peut pas améliorer les performances sans gouvernance des balises, et elle ne peut pas gouverner les balises sans participation du marketing.
7. Privacy, observabilité et opérations avancées
Plusieurs catégories d’outils dans l’échantillon sont moins fréquentes que la pile de base, mais plus révélatrices lorsqu’elles sont présentes.
Cookiebot / OneTrust apparaît sur 9,6 % des échantillons complets. C’est un signal de gestion du consentement. Il apparaît souvent lorsque les marques opèrent dans des juridictions plus strictes en matière de privacy ou prennent la conformité au sérieux. Si une marque DTC se développe en Europe, au Canada ou dans d’autres marchés sensibles à la privacy, la gestion du consentement devient une exigence pratique plutôt qu’un simple plus.
Microsoft Clarity apparaît sur 20,6 %, tandis que Hotjar apparaît sur 8,3 %. C’est un écart frappant, car les deux sont associés à l’analytics comportementale. Le positionnement gratuit et plus respectueux de la privacy de Clarity lui donne probablement un avantage dans un marché sensible aux coûts. Pour les opérateurs, cela suggère que l’analytics comportementale n’est pas seulement une activité d’entreprise. Les équipes DTC mid-market peuvent observer le comportement des utilisateurs sans acheter une plateforme de recherche coûteuse.
Gorgias apparaît sur 19,1 %. C’est important, car le support client est l’un des domaines où le DTC se distingue du simple e-commerce. Retours, modifications de commande, questions d’expédition, abonnements, marchandises endommagées et éducation produit relient le support au chiffre d’affaires. Un outil de support connecté aux données e-commerce peut devenir une partie du système de conversion et de fidélisation, et pas seulement une boîte de tickets.
Triple Whale apparaît sur 15,3 % et Northbeam sur 5,1 %. Ce sont des signaux de maturité en attribution. Lorsqu’une marque investit sur Meta, Google, TikTok, les influenceurs, les affiliés, l’e-mail et le SMS, GA4 seul ne répond pas forcément à la question qui intéresse les opérateurs : quelle dépense est réellement rentable ? L’apparition d’outils d’attribution natifs DTC suggère que le problème de l’attribution est passé du statut de préoccupation de niche à celui de douleur grand public des équipes croissance.
Rebuy apparaît sur 9,0 %. C’est un signal de post-achat et d’upsell. La faible part suggère que de nombreuses marques ont encore de la marge pour améliorer la valeur de commande et la monétisation post-achat. Pour les marques dont les produits sont réapprovisionnables ou comportent des SKU complémentaires, l’upsell post-achat peut être plus efficace que la chasse à un nouveau trafic.
Ces outils ne sont pas des recommandations pour chaque marque. Ce sont des marqueurs de maturité. Une marque ne devrait pas installer Triple Whale avant d’avoir suffisamment de dépenses payantes pour justifier une meilleure attribution. Elle ne devrait pas installer d’analytics comportementale si personne n’analyse les sessions. Elle ne devrait pas ajouter Rebuy si son catalogue n’a aucune logique d’achat complémentaire. Le benchmark est utile parce qu’il montre à quel moment ces outils entrent dans la pile visible, et non parce qu’il dit que tout le monde en a besoin.
8. Différences par catégorie : beauté et bien-être utilisent des piles plus profondes
La classification par catégorie dans cette étude repose sur des règles et reste imparfaite. Plus de la moitié du pool total de marques entre dans « Other », donc les résultats par catégorie doivent être lus comme des tendances. Néanmoins, les catégories labellisées révèlent des schémas utiles parmi les groupes disposant d’un nombre suffisant d’échantillons.
| Catégorie | Échantillon | Part Shopify dans l’échantillon | Nb moyen d’outils détectés | TikTok | |
|---|---|---|---|---|---|
| Apparel & Footwear | 141 | 95,0 % | 4,2 | 48,2 % | 31,2 % |
| Food & Beverage | 103 | 88,3 % | 4,3 | 55,3 % | 31,1 % |
| Beauty & Skincare | 87 | 94,3 % | 4,7 | 43,7 % | 26,4 % |
| Health & Wellness | 48 | 87,5 % | 4,9 | 39,6 % | 25,0 % |
| Outdoor & Sports | 42 | 92,9 % | 4,0 | 47,6 % | 23,8 % |
Beauty & Skincare et Health & Wellness ont les piles détectées les plus profondes dans ce tableau. Cela a du sens. Ces catégories impliquent souvent de l’éducation, de la confiance, des ingrédients, des abonnements, des routines, des avis, de la prudence réglementaire et des achats récurrents. Une marque bien-être peut avoir besoin de contenu, d’éducation par e-mail, de quiz, d’abonnements, d’attribution, de support et d’analytics comportementale pour faire passer un client sceptique de la découverte à l’achat répété.
Food & Beverage affiche la plus forte couverture Instagram dans cette vue. Cela colle aussi à la catégorie. La nourriture est visuelle, ritualisée, liée aux occasions et facile à montrer dans un contexte lifestyle. Apparel & Footwear affiche la plus forte couverture TikTok, à peu près à égalité avec Food & Beverage, ce qui correspond bien aux essais en format court, au styling, aux hauls et au contenu des créateurs.
Pour les content marketers, cette section est une excellente opportunité de réutilisation. Un benchmark global est utile, mais les rapports par catégorie circulent souvent plus loin. « Ce que les marques DTC beauté installent réellement » ou « Pourquoi le DTC food surindexe sur Instagram » performera probablement mieux dans ces communautés verticales qu’une histoire générale sur la pile DTC.
9. Le texte de la page d’accueil : le DTC est plus transactionnel que ne le laisse penser son image
L’analyse des propositions de valeur s’est appuyée sur le texte lisible de la page d’accueil après suppression des scripts et des styles. Le but n’était pas d’évaluer la qualité des marques. Il s’agissait de voir quelles expressions apparaissent assez souvent pour représenter le positionnement public.
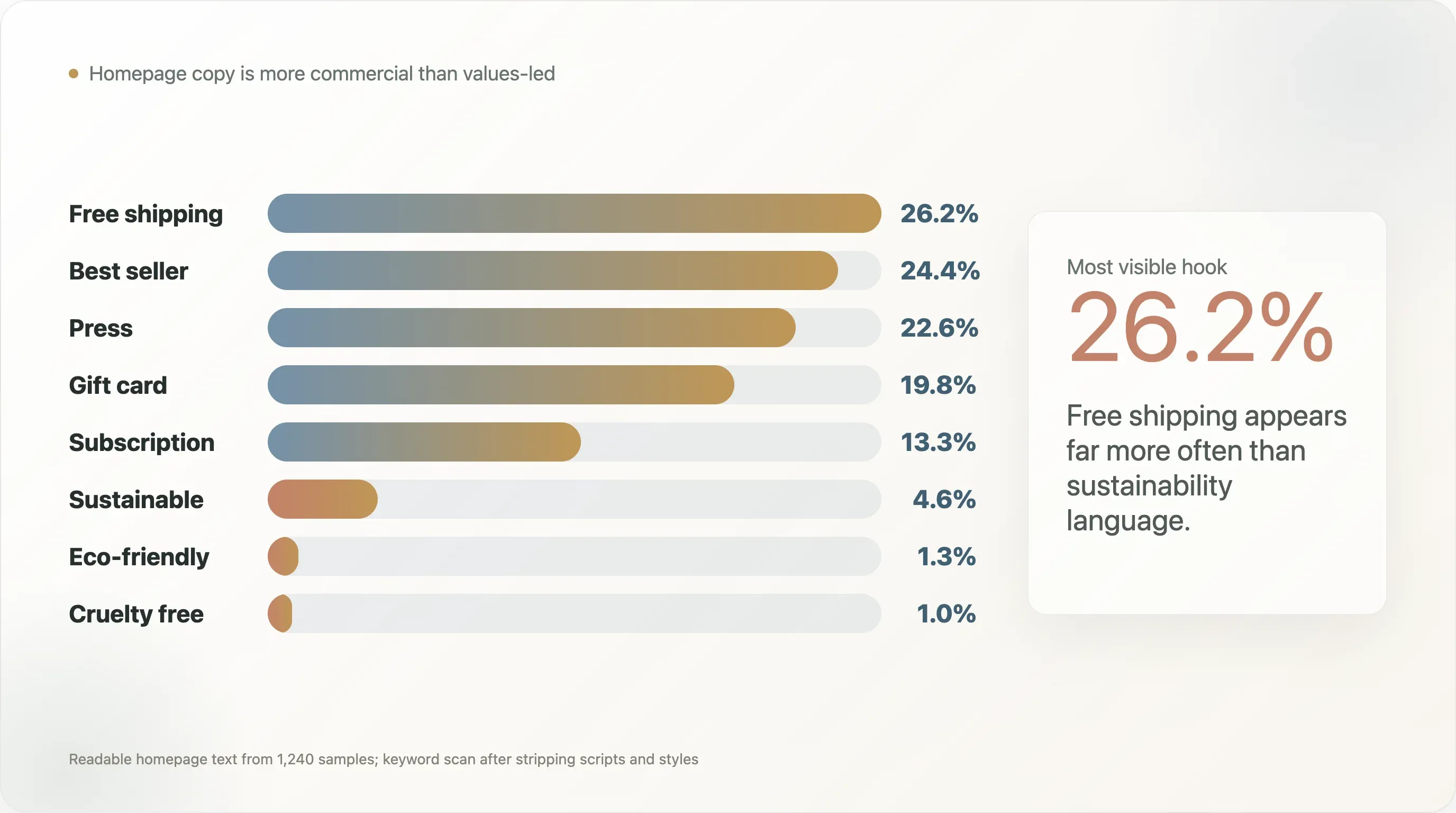
| Mot-clé ou thème | Couverture |
|---|---|
| free shipping | 26,2 % |
| best seller | 24,4 % |
| press / as seen on | 22,6 % |
| gift card | 19,8 % |
| exclusive | 14,3 % |
| subscription | 13,3 % |
| craft / artisan | 11,5 % |
| luxury | 5,7 % |
| organic | 4,9 % |
| vegan | 4,7 % |
| sustainable | 4,6 % |
| eco-friendly | 1,3 % |
| cruelty free | 1,0 % |
Les messages les plus visibles sont pratiques et commerciaux : livraison gratuite, meilleures ventes, crédibilité presse, cartes cadeaux, exclusivité et abonnements. Les termes liés à la durabilité sont bien moins fréquents. Cela ne veut pas dire que les marques DTC ne sont pas durables. Cela signifie que la durabilité n’est pas le principal langage de conversion de la page d’accueil dans cet échantillon.
C’est un contre-récit utile pour les médias et les newsletters, car le DTC est souvent décrit à travers les valeurs, la mission, la durabilité et la communauté. Le texte public de la page d’accueil dans cet échantillon est davantage orienté conversion. Les marques doivent toujours réduire la friction, prouver la demande, afficher leur crédibilité et faire avancer les visiteurs vers l’achat.
« Press / as seen on » à 22,6 % est particulièrement utile pour les équipes RP. Cela suggère que les retombées presse ne servent pas qu’à la notoriété. Elles deviennent un actif de confiance réutilisable sur la page d’accueil. Un bon article de presse peut vivre dans le parcours de conversion longtemps après sa publication.
« Gift card » à 19,8 % est également plus intéressant qu’il n’y paraît. Les cartes cadeaux peuvent servir d’outil de chiffre d’affaires, d’acquisition, de fidélisation et de trésorerie. Ce n’est pas seulement un complément de fin d’année. Pour les marques DTC avec un fort potentiel cadeau, un module de carte cadeau peut réduire la friction de décision pour les clients qui aiment la marque mais ne connaissent pas la taille, le goût, la teinte ou le besoin exact du destinataire.
10. Tête contre queue : le nombre d’outils n’est pas le fossé concurrentiel
La séparation tête/queue utilise la visibilité des sources, et non le chiffre d’affaires. « Tête » signifie qu’une marque est apparue dans au moins trois collections sources. « Queue » signifie qu’elle est apparue dans une seule collection source. C’est un proxy de visibilité dans les sources publiques.
| Dimension | Groupe tête | Groupe queue |
|---|---|---|
| Taille de l’échantillon | 89 | 708 |
| Part Shopify dans l’échantillon | 93,3 % | 84,7 % |
| Nb moyen d’outils d’analytics détectés | 4,5 | 4,1 |
| Médiane d’outils d’analytics détectés | 4 | 4 |
| Shop Pay | 82,0 % | 77,1 % |
| PayPal | 75,3 % | 64,8 % |
| Afterpay | 11,2 % | 7,3 % |
L’écart de profondeur de pile est faible. C’est important. Cela signifie que des marques plus petites ou moins visibles peuvent accéder à la plupart des mêmes infrastructures que des marques mieux connues. Un opérateur e-commerce moderne n’a pas besoin d’une énorme équipe pour installer GA4, Klaviyo, Shop Pay, PayPal, Microsoft Clarity ou des pixels de base.
La différence porte sur la façon dont ces outils sont utilisés et sur les outils avancés qui viennent ensuite. Une marque de tête n’a pas forcément beaucoup plus d’outils, mais elle a plus de chances d’avoir une attribution plus solide, de meilleures options de checkout, une conformité plus propre, un support plus mature et une meilleure gouvernance. Le fossé concurrentiel ne réside pas dans la liste d’applications. Il réside dans la discipline opérationnelle.
Pour les équipes DTC mid-market, la conclusion est à la fois encourageante et inconfortable. Encourageante, car les outils sont accessibles. Inconfortable, car si tout le monde peut installer les mêmes outils, l’avantage se déplace vers l’exécution : vitesse de test créatif, segmentation e-mail, qualité des pages produit, SEO technique, schéma, vitesse, mesure du cycle de vie et discipline de campagne.
11. Ce que les opérateurs devraient en faire
Le benchmark ne devient utile que s’il se transforme en décisions. Voici un ordre d’action pragmatique.
D’abord, auditez la base. Vérifiez que les événements GA4 sont propres, que le suivi des achats est fiable, que Klaviyo ou la plateforme de fidélisation est correctement connectée, que les options de checkout fonctionnent, que le comportement de consentement est conforme et que tous les pixels payants principaux sont intentionnels. N’ajoutez pas d’outils pour compenser des fondamentaux cassés.
Ensuite, corrigez les bases de la recherche IA et du SEO. Validez la meta description, les balises canonical, Open Graph, hreflang lorsque c’est pertinent, et JSON-LD. La plus grande opportunité concerne Product schema. Si la marque vend des produits en ligne, les faits produit doivent être lisibles par machine sur les pages produit.
Troisièmement, faites un audit des balises. Exportez les scripts et les domaines tiers. Assignez un propriétaire à chacun. Supprimez les fournisseurs abandonnés. Retardez les scripts non critiques. Rendez explicite le comportement lié au consentement. C’est l’une des rares tâches qui aide à la fois le SEO, l’ingénierie, l’analytics et le marketing.
Quatrièmement, examinez la friction au checkout selon la catégorie et le panier moyen. Si le panier moyen est élevé, le BNPL peut valoir la peine d’être testé. Si la marque vend à l’international, PayPal et les attentes locales en matière de paiement comptent. Si Apple Pay ou Google Pay sont présents mais peu visibles dans le crawl, assurez-vous que l’expérience de checkout réelle les met bien en avant.
Cinquièmement, reliez le site aux réseaux sociaux détenus de manière volontaire. Si Instagram, TikTok, YouTube, Pinterest, LinkedIn ou X comptent pour la marque, le site officiel doit y conduire les utilisateurs. Si un canal ne compte plus, supprimez l’icône obsolète.
Sixièmement, traitez les outils avancés comme des engagements opérationnels. Triple Whale, Northbeam, Rebuy, Attentive, Gorgias et les outils d’analytics comportementale peuvent créer de la valeur, mais seulement si l’équipe dispose d’un workflow autour d’eux. Un outil sans propriétaire n’est qu’un script supplémentaire.
Méthodologie
Le pool de départ contenait 1 597 marques DTC candidates constituées à partir de sources publiques e-commerce et DTC, notamment des bibliothèques d’études de cas d’outils, des contenus de l’écosystème Shopify et des index DTC publics. Parmi elles, 1 431 candidates ont été résolues en domaines. Le crawl a mené l’analyse au niveau de la page d’accueil pour 1 238 sites et a récupéré le contenu de page d’accueil pour 1 240 domaines le 11 mai 2026.
Le crawl a tenté d’extraire la page d’accueil, la page produit lorsque détectable, les points d’entrée du sitemap, les candidats llms.txt et les candidats de page À propos. Le HTML brut a été stocké par domaine. La détection utilisait des motifs d’empreintes pour la plateforme e-commerce, le framework frontend, les outils d’analytics et de marketing, les signaux de paiement, les champs SEO/schema, les liens sociaux et les décomptes liés à la performance.
L’analyse reflète principalement le balisage public du site web. Elle n’accède pas aux comptes analytics internes, aux comptes publicitaires, aux paramètres d’administration du checkout, aux performances e-mail, aux données de vente, aux taux de conversion, aux niveaux de trafic ou au chiffre d’affaires. Elle ne prétend pas non plus qu’un outil détecté est correctement configuré ou activement utilisé.
Réserves pour la citation
-
Il ne s’agit pas d’un recensement sectoriel. L’échantillon est biaisé en faveur des marques visibles dans les écosystèmes d’outils e-commerce et les listes DTC publiques. Utilisez une formulation du type « parmi 1 238 échantillons complets de sites DTC dans cette étude », et non « toutes les marques DTC ».
-
Shopify est surreprésenté par conception. La part de Shopify dans l’échantillon doit être considérée comme une caractéristique de l’échantillon, et non comme une part de marché.
-
La détection des outils constitue une borne inférieure. Les scripts dynamiques, les balises soumises au consentement, les méthodes de checkout en ligne et le contenu rendu côté client peuvent être manqués.
-
La taille en octets de la page d’accueil est plafonnée. Le processus de collecte plafonnait les lectures HTML à 256 Ko, donc la taille de la page d’accueil ne doit pas être citée comme constat de performance. Le nombre de scripts et de domaines tiers est plus utile.
-
La visibilité sociale n’est pas l’activité sociale. Les liens sociaux sur la page d’accueil montrent l’orientation du site officiel, et non le nombre d’abonnés, la fréquence de publication, la répartition des créateurs, le paid social ou le chiffre d’affaires social.
-
La classification par catégorie est indicative. La taxonomie repose sur des mots-clés et comporte une vaste catégorie « Other ». Les tableaux par catégorie sont utiles pour repérer des tendances, pas pour un dimensionnement précis du marché.
-
Il s’agit d’une photographie à un instant donné. Les données ont été collectées le 11 mai 2026. Les sites changent souvent, et de futures mises à jour peuvent montrer un déplacement notable.
Notes de reproductibilité
Le dossier de livraison comprend :
00_expand_brand_pool.py— étend le pool initial de marques DTC candidates à partir de listes de sources publiques.01_resolve_domains.py— résout les noms de marques et les entrées sources en domaines canoniques.02_fetch_pages.py— récupère la page d’accueil, la page produit, le sitemap, les candidatsllms.txtet les pages À propos.03_detect_all.py— exécute la détection de la plateforme, des outils analytics, des paiements, du SEO, du schema, des signaux sociaux et des signaux de performance.04_build_master.py— construit le tableau analytique unifié par marque.05_analyze_reports.py— génère les statistiques agrégées utilisées dans le rapport.07_categorize_brands.py— applique le classificateur de catégories basé sur des mots-clés.08_extra_analysis.py— produit des sorties supplémentaires sur le SEO, la performance, les CTA, les propositions de valeur et les cooccurrences.
Les corrections de méthodologie, problèmes de jeu de données et analyses complémentaires sont les bienvenus à support@thunderbit.com. Ce rapport est publié indépendamment de toute position commerciale que Thunderbit pourrait avoir ; nous construisons un extracteur Web alimenté par l’IA, et nous avons un intérêt structurel à ce que les sites e-commerce soient plus lisibles pour les humains, les moteurs de recherche, les systèmes d’analytics et les agents IA. Le benchmark repose sur 1 238 échantillons complets de sites DTC collectés le 11 mai 2026. Les données de ce rapport se suffisent à elles-mêmes. — L’équipe de recherche Thunderbit, mai 2026.