
Positionnement du lecteur
Ce rapport s’adresse à toutes celles et ceux qui composent avec les effets d’un stack DTC moderne : responsables growth, managers ecommerce, spécialistes du performance marketing, équipes lifecycle, marketing operations, SEO technique, ingénieurs frontend, responsables analytics et fondateurs qui se demandent sans arrêt pourquoi le site paraît lent alors que chaque outil semble indispensable.
Le benchmark initial des sites DTC montrait quels outils les marques utilisaient. Cette étude pose une autre question : quel est le coût opérationnel de l’empilement de ces outils sur la vitrine ?
La réponse n’est pas « les outils sont mauvais ». Les marques DTC utilisent des outils d’analytics, de rétention, d’attribution, d’avis, de chat, de support, de paiement, d’upsell et d’expérimentation parce qu’ils résolvent de vrais problèmes de revenus. Le vrai sujet, c’est que chaque couche supplémentaire entraîne un coût frontend, un coût QA, un coût de consentement, un coût de qualité des données et un coût de maintenance. Les stacks de croissance créent de la capacité de croissance, mais aussi de l’inertie infrastructurelle.
Pour les rédacteurs SEO et ecommerce, ce rapport offre un angle bien plus utile que « les marques DTC utilisent beaucoup d’outils ». Le vrai récit, le voici : le playbook de croissance DTC par défaut est devenu un problème de performance et de gouvernance.
Résumé exécutif
Sur 1 238 domaines DTC notés, la page d’accueil médiane de cet échantillon contient 52 balises script et référence 8 domaines tiers. Ce ne sont pas de simples détails techniques abstraits. Les scripts et les domaines tiers sont, côté navigateur, la preuve du stack de croissance d’une marque : analytics, pixels, outils de rétention, chat, avis, personnalisation, paiement, upsell, expérimentation, consentement et support.
Le coût devient évident lorsqu’on regroupe les marques par profondeur analytics et marketing :
| Tranche de profondeur analytics | Échantillon | Scripts médians | Domaines tiers médians | Profondeur moyenne du stack | Couverture d’un gestionnaire de consentement |
|---|---|---|---|---|---|
| 0 outil analytics | 157 | 1 | 0 | 0,0 | 0,0 % |
| 1-2 outils analytics | 336 | 30 | 6 | 2,2 | 3,6 % |
| 3-4 outils analytics | 352 | 54 | 8 | 4,9 | 14,8 % |
| 5+ outils analytics | 393 | 69 | 11 | 8,2 | 14,0 % |
L’écart est frappant. Les marques avec 0 à 2 outils analytics ont un médian de 16 scripts et 4 domaines tiers lorsqu’on combine les deux premières tranches. Les marques avec 5 outils analytics ou plus ont un médian de 69 scripts et 11 domaines tiers. Autrement dit, le stack de croissance le plus lourd porte plus de quatre fois la charge de scripts du groupe le moins analytics.
Les données de corrélation confirment la même histoire. La profondeur du stack présente une corrélation de 0,731 avec le nombre de scripts et de 0,547 avec le nombre de domaines tiers. Le nombre d’outils analytics présente une corrélation de 0,658 avec le nombre de scripts et de 0,557 avec les domaines tiers. Le nombre d’outils de rétention corrèle lui aussi de manière significative avec le nombre de scripts, à 0,611. Il ne s’agit pas de quelques cas isolés. C’est un schéma structurel : à mesure que le stack de croissance public s’élargit, la complexité côté navigateur augmente.
Le rapport met aussi en évidence un angle mort en matière de confidentialité et de gouvernance. La gestion du consentement, mesurée ici via des signaux visibles de type Cookiebot / OneTrust, n’apparaît que sur 9,6 % des domaines notés. Parmi les marques avec 5 outils analytics ou plus, la couverture d’un gestionnaire de consentement est de 14,0 %. Cela ne prouve pas que les autres marques sont non conformes, car les outils de consentement peuvent être implémentés d’une manière que cette détection ne repère pas. En revanche, cela montre que de nombreux sites fortement trackés n’exposent pas de signal évident de gestion du consentement dans le HTML capturé.
Enfin, 16,2 % des domaines entrent dans le niveau extreme de charge de scripts, défini ici comme plus de 75 balises script. C’est un bon repère pour le SEO technique, les opérations growth et les équipes frontend. Si une page d’accueil DTC dépasse 75 scripts, ce n’est plus seulement une page marketing. C’est une surface d’infrastructure qui doit être pilotée.
La conclusion centrale : la maturité de la croissance DTC et la complexité de la vitrine augmentent ensemble. Le prochain avantage ne consiste pas à ajouter davantage d’outils, mais à gouverner le stack existant.
Les enseignements les plus partageables
-
La page d’accueil DTC médiane de cet échantillon contient 52 balises script et 8 domaines tiers.
-
Les marques avec 5 outils analytics ou plus ont un médian de 69 scripts et 11 domaines tiers.
-
Les marques avec 0 à 2 outils analytics ont un médian de 16 scripts et 4 domaines tiers.
-
16,2 % des domaines notés entrent dans la tranche extrême de charge de scripts.
-
La visibilité de la gestion du consentement n’est que de 9,6 % au total, et de 14,0 % même parmi les marques avec 5 outils analytics ou plus.
-
La profondeur du stack est fortement corrélée au nombre de scripts, à hauteur de 0,731.
-
Le stack de croissance DTC n’est plus seulement un stack marketing. C’est une infrastructure frontend.
1. Pourquoi le coût du growth stack compte
Les équipes DTC évaluent généralement les outils à travers leur potentiel de gain : meilleure attribution, plus de revenus email, AOV plus élevé, meilleur support, avis plus propres, personnalisation renforcée, meilleure rétention, optimisation paid media améliorée ou hausse du taux de conversion. C’est logique. Les équipes growth sont payées pour faire croître l’activité.
Mais chaque outil crée aussi des coûts. Certains sont visibles : abonnement, travail d’implémentation et gestion contractuelle. D’autres sont plus difficiles à voir : pages plus lentes, davantage de JavaScript, plus d’appels tiers, plus d’états à tester en QA, plus de logique de consentement, plus de conflits de balises, plus d’écarts d’attribution, davantage de revues privacy et plus de questions sur la propriété des vendors.
Ce rapport se concentre sur le coût caché. Il utilise le nombre de scripts, le nombre de domaines tiers, la profondeur du stack, les catégories d’outils, les groupes de plateformes et les groupes de catégories comme proxys de la complexité. Il ne prétend pas qu’un grand nombre de scripts est toujours mauvais. Une marque performante peut rationnellement supporter plus de scripts si chacun soutient une fonction de revenus. Mais une forte complexité sans gouvernance est dangereuse.
La bonne question n’est pas « comment supprimer chaque outil ? ». La bonne question est : quels outils méritent encore leur place sur la page ?
2. La base de référence : 52 scripts et 8 domaines tiers

La page d’accueil médiane de l’échantillon affiche :
- 52 balises script
- 8 domaines tiers
Les valeurs p75 issues de la recherche de performance sous-jacente sont plus élevées : 69 scripts et 12 domaines tiers. Le nombre maximal de scripts est bien plus élevé, mais le rapport se concentre sur la distribution plutôt que d’utiliser les valeurs extrêmes comme contre-exemples négatifs.
Pour les opérateurs, la médiane suffit déjà à illustrer le point. Une page d’accueil DTC n’est rarement juste du HTML, du CSS, des visuels produit et un parcours checkout. C’est une couche de coordination pour de nombreux systèmes : analytics, pixels, tag management, enregistrement de session, avis, support, quiz, pop-ups, abonnements, personnalisation, paiements, consentement et expériences.
Le coût caché apparaît à plusieurs niveaux :
Coût de performance. Plus de scripts peuvent retarder le rendu, monopoliser le main thread, augmenter les requêtes réseau et affecter les Core Web Vitals.
Coût QA. Chaque script de vendor ajoute des cas à tester : desktop, mobile, consentement accepté, consentement refusé, connecté, déconnecté, état du panier, parcours checkout, domaine régional et différences entre navigateurs.
Coût d’attribution. Plus de balises ne signifie pas forcément de meilleures données. Cela peut produire des chiffres contradictoires, des événements dupliqués ou des désaccords sur le crédit des canaux.
Coût privacy. Plus de surfaces de tracking créent davantage de questions de consentement et de conformité.
Coût d’ownership. Les outils survivent souvent à la personne qui les a installés. Un script peut rester sur le site longtemps après que l’équipe a cessé d’utiliser le tableau de bord.
C’est pourquoi le stack de croissance doit être géré comme une infrastructure, et non comme une pile d’add-ons marketing.
3. La profondeur analytics est le facteur de coût le plus clair
Le tableau le plus parlant de la recherche est la ventilation par profondeur analytics :

| Tranche de profondeur analytics | Échantillon | Scripts médians | Scripts moyens | Domaines tiers médians | Domaines tiers moyens | Profondeur moyenne du stack |
|---|---|---|---|---|---|---|
| 0 outil analytics | 157 | 1 | 3,1 | 0 | 1,3 | 0,0 |
| 1-2 outils analytics | 336 | 30 | 35,0 | 6 | 6,5 | 2,2 |
| 3-4 outils analytics | 352 | 54 | 51,1 | 8 | 9,1 | 4,9 |
| 5+ outils analytics | 393 | 69 | 69,1 | 11 | 11,3 | 8,2 |
Ce tableau transforme une inquiétude vague en benchmark concret. Passer de 1-2 outils analytics à 3-4 outils fait presque doubler le nombre médian de scripts, de 30 à 54. Passer à 5 outils ou plus fait encore monter le médian à 69.
La tranche à 0 outil ne doit pas être interprétée comme meilleure. Beaucoup de ces sites peuvent être incomplets, mis en attente, très simples, fortement rendus côté client ou simplement sous-détectés. La comparaison utile se situe entre les groupes d’exploitation courants : 1-2, 3-4 et 5+ outils analytics.
Le groupe 5+ outils analytics est particulièrement important. Ce sont les marques les plus investies dans la mesure et les opérations de croissance. Elles se soucient probablement d’acquisition payante, de rétention, d’attribution, de comportement de session, de support, d’avis ou d’optimisation de conversion. Mais elles portent aussi la charge de dépendances la plus lourde.
C’est le paradoxe du growth stack : les marques les plus sérieuses sur la mesure sont aussi celles les plus exposées au surcoût de cette mesure.
4. Corrélations : c’est structurel, pas anecdotique
La matrice de corrélation montre que la complexité du stack n’est pas aléatoire.
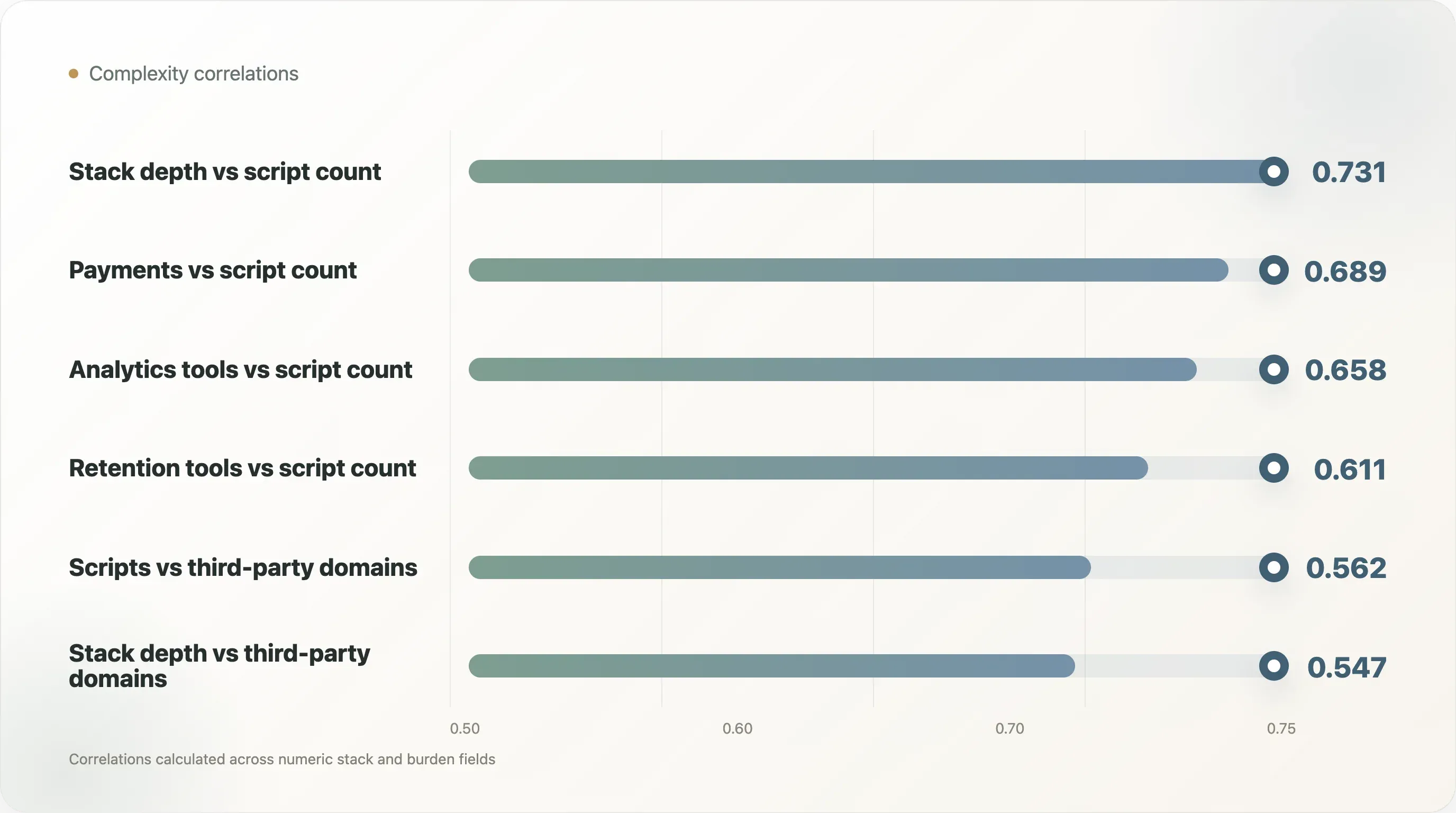
| Paire | Corrélation |
|---|---|
| Profondeur du stack vs nombre de scripts | 0,731 |
| Outils analytics vs nombre de scripts | 0,658 |
| Paiements vs nombre de scripts | 0,689 |
| Outils de rétention vs nombre de scripts | 0,611 |
| Profondeur du stack vs domaines tiers | 0,547 |
| Outils analytics vs domaines tiers | 0,557 |
| Nombre de scripts vs domaines tiers | 0,562 |
La profondeur du stack présente la relation la plus forte avec le nombre de scripts. C’est attendu, mais important, car la profondeur du stack est souvent perçue comme un progrès. Plus d’outils signifie plus de capacités. Mais cela signifie aussi plus de poids frontend.
Les paiements affichent une corrélation étonnamment forte avec le nombre de scripts, à 0,689. Cela ne signifie pas que les moyens de paiement sont mauvais. Cela signifie que l’optionnalité du checkout et les intégrations de paiement font partie du tableau de complexité. Une marque qui prend en charge plusieurs parcours de paiement peut améliorer la conversion, surtout dans les catégories à AOV élevé, mais ces intégrations doivent tout de même figurer dans la cartographie de gouvernance technique.
Le nombre d’outils de rétention corrèle à 0,611 avec le nombre de scripts. C’est intuitif. Les outils lifecycle ajoutent souvent des formulaires onsite, des pop-ups, des scripts d’identification, de la capture SMS, de la personnalisation et de la collecte d’événements. La rétention ne vit pas uniquement dans l’email. Elle vit aussi sur la vitrine.
L’implication en matière de gouvernance est claire : la performance ne peut pas être résolue par l’ingénierie seule. Le marketing, le lifecycle, la rétention, le paid media et l’ecommerce placent tous du code sur la page. Ils doivent tous participer à la gouvernance de la performance.
5. Patterns de plateforme : les sites Shopify portent un stack visible plus lourd
Les comparaisons par plateforme doivent être interprétées avec prudence, car l’échantillon est biaisé en faveur des écosystèmes d’outils ecommerce, et Shopify est surreprésenté. Cela dit, le tableau par plateforme reste utile comme benchmark de signaux publics.
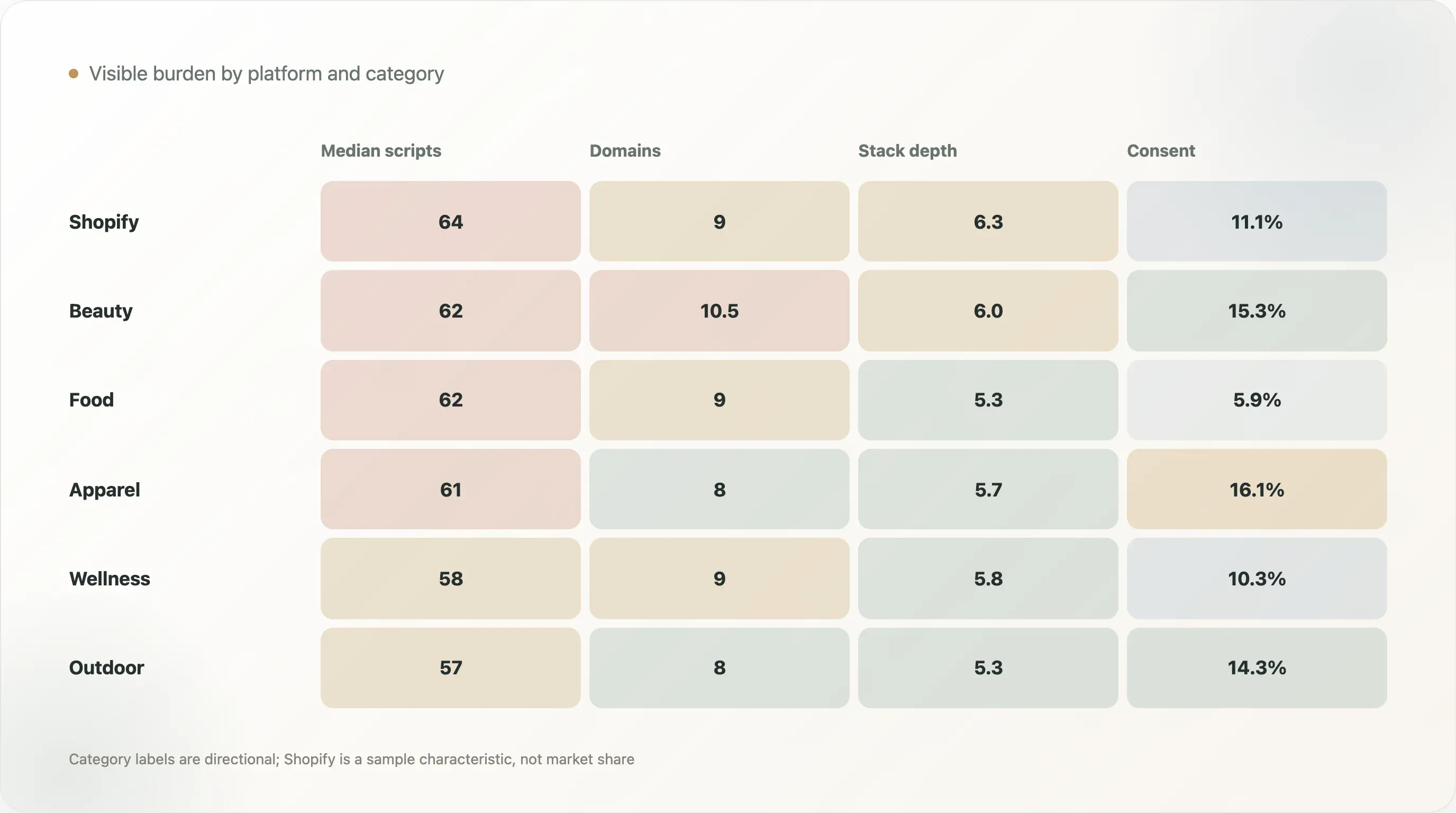
| Plateforme | Échantillon | Scripts médians | Domaines tiers médians | Profondeur moyenne du stack | Couverture d’un gestionnaire de consentement |
|---|---|---|---|---|---|
| Shopify | 783 | 64 | 9 | 6,3 | 11,1 % |
| Inconnue | 324 | 6 | 2 | 1,2 | 7,1 % |
| WordPress | 23 | 24 | 6 | 2,3 | 13,0 % |
| Salesforce Commerce Cloud | 10 | 47 | 10 | 3,9 | 30,0 % |
| Magento / Adobe Commerce | 6 | 55,5 | 7,5 | 3,8 | 0,0 % |
| BigCommerce | 3 | 55 | 9 | 3,7 | 0,0 % |
Les sites Shopify de l’échantillon affichent un médian de 64 scripts et 9 domaines tiers, avec une profondeur moyenne de stack de 6,3. Il ne faut pas en conclure que « Shopify provoque les scripts ». L’interprétation la plus plausible est que les marques Shopify de cet échantillon sont fortement exposées aux app ecosystems, aux intégrations checkout, aux outils lifecycle, aux outils d’avis, aux outils support et aux vendors de croissance.
Le groupe Inconnue présente un médian de 6 scripts et 2 domaines tiers, mais cela ne signifie pas nécessairement que ces sites sont plus légers d’un point de vue stratégique. Beaucoup de sites à plateforme inconnue peuvent masquer leurs empreintes, être headless, être sous-détectés ou exposer moins de markup rendu côté serveur. La bonne lecture est celle de la visibilité publique, pas de la stack interne complète.
Le tableau des plateformes est surtout utile pour le benchmark interne. Si un site DTC Shopify compte 90 scripts, il est au-dessus du médian Shopify de cet échantillon. S’il en compte 40, il est en dessous. L’objectif n’est pas de stigmatiser les sites à fort nombre de scripts. L’objectif est de fournir un repère pour la revue.
6. Patterns par catégorie : beauté, food, apparel et wellness portent des stacks lourds
Le tableau par catégorie montre que les catégories DTC à forte croissance ont tendance à porter une charge de scripts élevée.
| Catégorie | Échantillon | Scripts médians | Domaines tiers médians | Profondeur moyenne du stack | Couverture d’un gestionnaire de consentement |
|---|---|---|---|---|---|
| Beauté & soins de la peau | 98 | 62 | 10,5 | 6,0 | 15,3 % |
| Alimentation & boissons | 118 | 62 | 9 | 5,3 | 5,9 % |
| Vêtements & chaussures | 149 | 61 | 8 | 5,7 | 16,1 % |
| Santé & bien-être | 58 | 58 | 9 | 5,8 | 10,3 % |
| Maison & mobilier | 48 | 58,5 | 9 | 5,4 | 8,3 % |
| Outdoor & sports | 49 | 57 | 8 | 5,3 | 14,3 % |
| Bébé & enfants | 27 | 57 | 9 | 4,7 | 7,4 % |
Beauté & soins de la peau, Alimentation & boissons, Vêtements & chaussures et Santé & bien-être affichent tous un nombre médian de scripts proche ou supérieur à la médiane globale. Ces catégories sont compétitives, riches en contenu et souvent pilotées par le lifecycle. Elles s’appuient sur l’éducation, les avis, l’acquisition payante, la découverte via les créateurs, les abonnements, la fidélité, les quiz et la personnalisation. Cela crée une attraction naturelle vers davantage d’outils.
Alimentation & boissons est intéressante car elle présente un nombre médian de scripts élevé, mais une visibilité relativement faible du gestionnaire de consentement, à 5,9 %. Cela ne prouve pas un problème de conformité, mais cela soulève une question de gouvernance pour les marques alimentaires ou boissons fortement trackées, surtout si elles opèrent à l’international.
Vêtements & chaussures affiche la couverture de gestionnaire de consentement la plus élevée parmi les grandes catégories présentées, à 16,1 %. Beauté & soins de la peau suit de près avec 15,3 %. Ces catégories peuvent avoir une exposition internationale plus forte, des opérations paid media plus sophistiquées ou des stacks ecommerce plus matures dans l’échantillon.
La leçon à retenir n’est pas qu’une catégorie serait « mauvaise ». La leçon est que la gouvernance de la performance doit tenir compte de la catégorie. Une marque beauté avec des avis, des quiz, des abonnements, de la capture SMS et de l’attribution n’aura naturellement pas la même structure qu’un site catalogue à faible complexité. Le benchmark doit aider à prioriser, pas imposer un objectif universel.
7. Gestion du consentement : l’écart entre tracking et gouvernance
La gestion du consentement apparaît sur 9,6 % des domaines notés au total. Parmi les marques avec 5 outils analytics ou plus, elle apparaît sur 14,0 %.
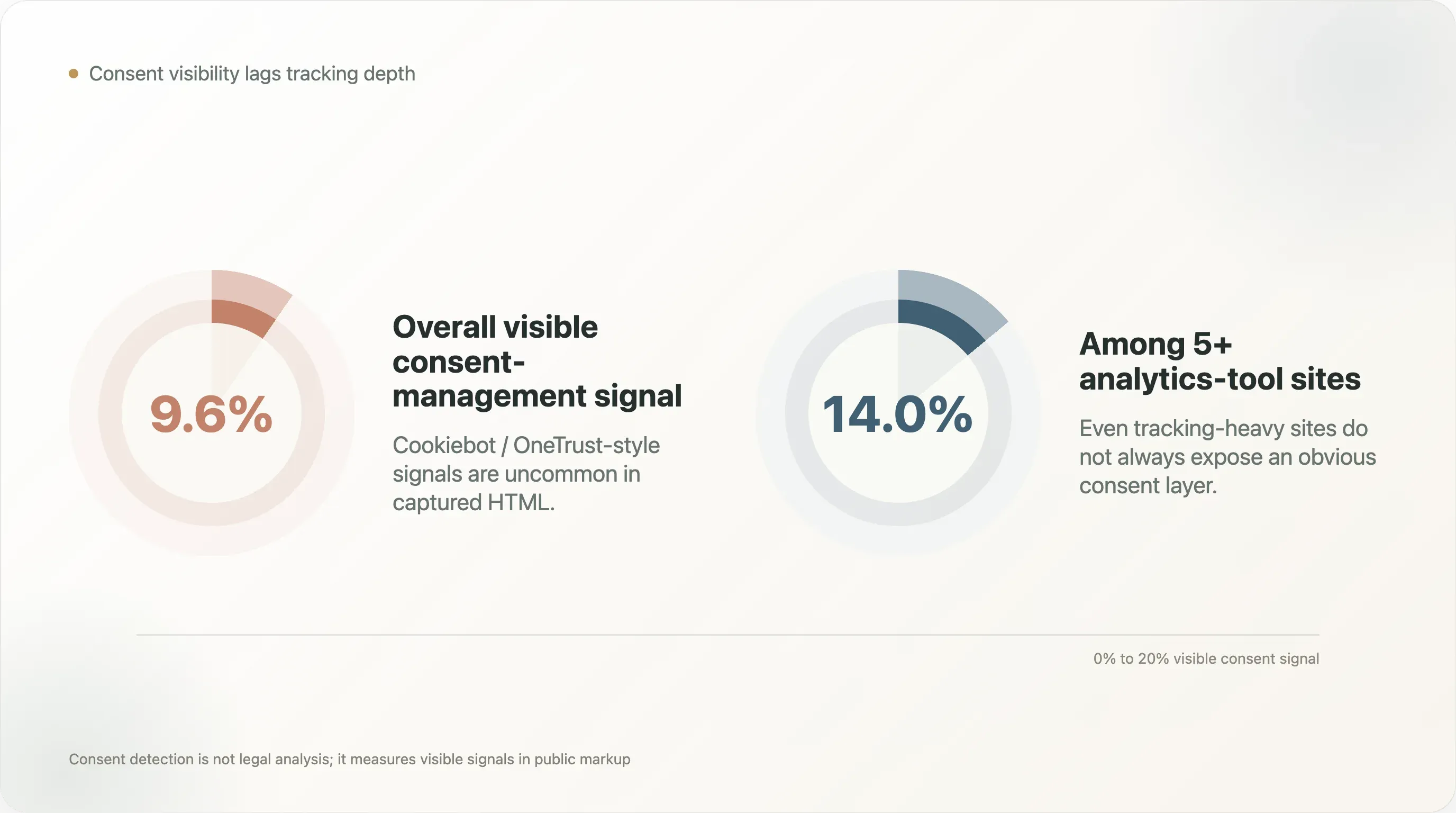
C’est l’un des résultats les plus importants, car il relie l’instrumentation growth à la gouvernance privacy. Plus le stack est lourd, plus la logique de consentement devient critique. Pourtant, les signaux visibles de type Cookiebot / OneTrust restent relativement peu fréquents.
Cette métrique comporte des réserves. Une marque peut utiliser un gestionnaire de consentement que la détection ne couvre pas. Elle peut implémenter le consentement via une solution personnalisée. Elle peut charger ses scripts de consentement de manière dynamique. Elle peut opérer principalement sur des marchés aux exigences de conformité différentes. Il ne faut donc pas citer ce chiffre comme « seulement 9,6 % respectent la loi sur la vie privée ». Ce serait trop fort et probablement faux.
La bonne formulation est plus étroite : seulement 9,6 % des domaines notés exposent un signal de gestion du consentement de type Cookiebot / OneTrust dans le HTML capturé. C’est déjà utile. Cela suggère que de nombreux sites fortement trackés ne rendent pas la gouvernance du consentement évidente dans le crawl public.
Pour les opérateurs, l’action est simple : n’attendez pas un audit juridique pour inventorier le tracking. Construisez une cartographie des balises qui inclut la finalité, le responsable, le vendor, les données collectées, la catégorie de consentement et la condition de chargement. Les équipes growth doivent savoir quelles balises se déclenchent avant consentement, après consentement et sur quelles pages.
8. La tranche extrême de scripts : quand une page marketing devient une infrastructure
Cette étude définit la tranche extreme de charge de scripts comme plus de 75 balises script. Avec cette définition, 16,2 % des domaines notés entrent dans la tranche extrême.
Extreme ne veut pas dire automatiquement mauvais. Certaines marques ont des besoins complexes : routage multi-région, infrastructure d’avis lourde, contenu produit riche, personnalisation, multiples régies publicitaires, analytics, support, expérimentation et intégrations checkout. Une marque complexe peut raisonnablement nécessiter une page complexe.
Mais un niveau extrême doit déclencher une gouvernance. Au-delà de 75 scripts, une page d’accueil n’est plus un simple asset marketing. C’est une infrastructure. Elle a besoin de :
- Une liste des responsables des scripts
- Une politique de chargement des balises
- Une cartographie des catégories de consentement
- Un suivi des performances
- Un nettoyage régulier des vendors
- Des parcours QA pour le panier et le checkout
- Des règles de déduplication des événements
- Un plan de retour arrière pour les vendors défaillants
Le script le plus dangereux n’est pas forcément le plus lourd. C’est le script orphelin : un snippet de vendor dont personne dans l’équipe actuelle n’est propriétaire, qui alimente un dashboard que personne n’ouvre et ralentit une page que personne n’audite.
9. Le playbook opérateur : comment gouverner le growth stack
La réponse pratique à ce rapport n’est pas un nettoyage brutal des outils. C’est un workflow de gouvernance.
Étape 1 : inventorier tous les scripts. Exportez toutes les sources de scripts de la page d’accueil, des pages produit, des pages de collection, du panier et des pages proches du checkout. Incluez les scripts inline lorsque c’est possible.
Étape 2 : attribuer la propriété. Chaque script doit avoir un responsable métier et un responsable technique. Si personne ne peut nommer le propriétaire, le script est un candidat à la suppression.
Étape 3 : classifier la finalité. Acquisition, rétention, attribution, avis, support client, paiements, personnalisation, expérimentation, consentement, analytics, monitoring ou legacy.
Étape 4 : cartographier le comportement de consentement. Déterminez si chaque script est essentiel, analytics, marketing, personnalisation ou support. Confirmez quand il se déclenche.
Étape 5 : vérifier l’usage réel. Le dashboard est-il actif ? Le vendor est-il toujours sous contrat ? Les rapports sont-ils consultés ? L’outil influence-t-il les décisions ?
Étape 6 : mesurer l’impact. Testez la performance de page avec et sans les vendors lourds lorsque c’est possible. Suivez les Core Web Vitals, le délai d’interaction et le blocage du main thread.
Étape 7 : consolider. Si deux outils remplissent la même fonction, n’en gardez qu’un. Les outils d’attribution et d’analytics en double créent souvent plus de débat que de clarté.
Étape 8 : revoir chaque trimestre. Le stack de croissance doit avoir un cycle de nettoyage, tout comme les comptes publicitaires et les flows email.
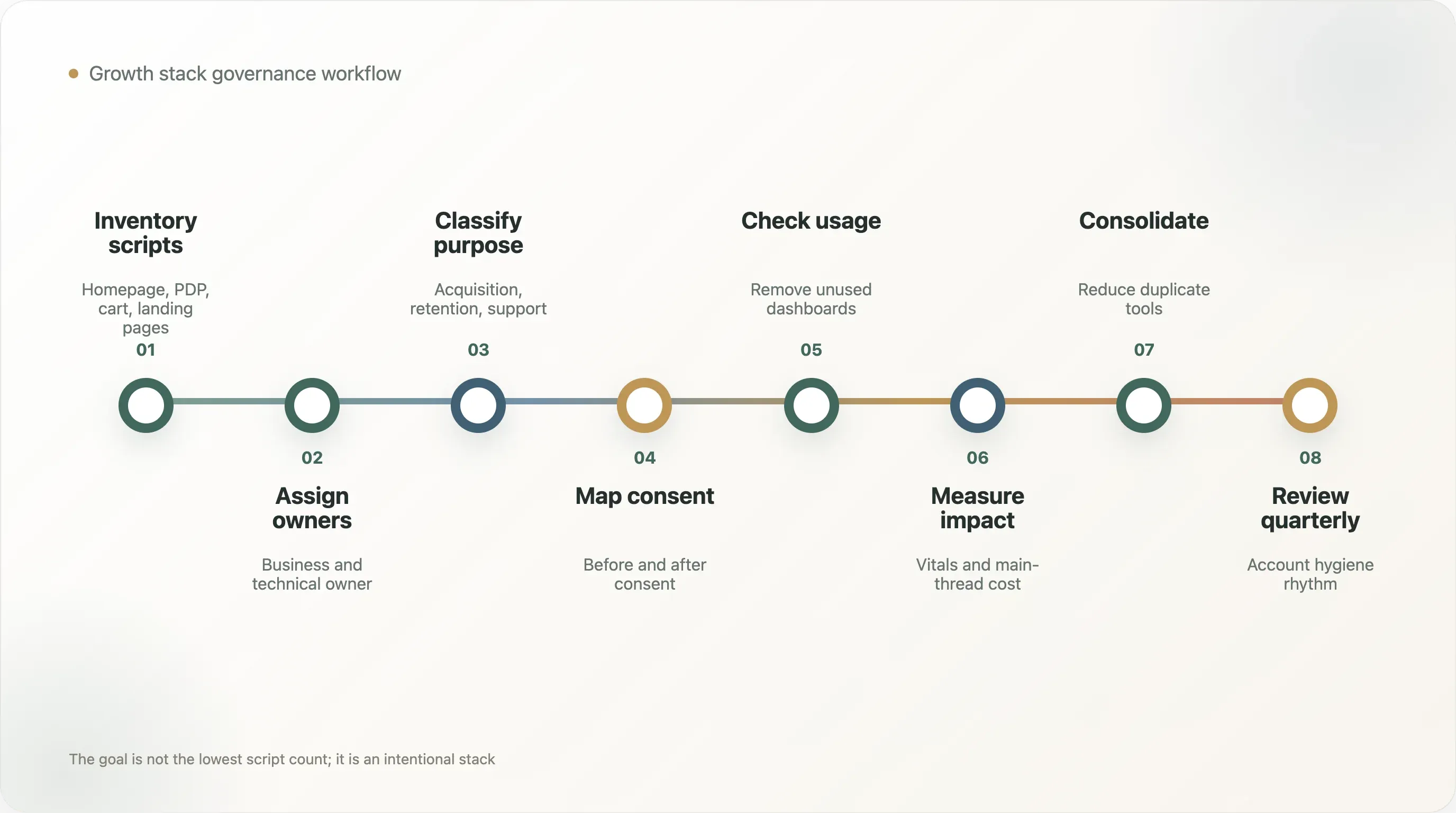
Ce workflow transforme la performance d’une plainte d’ingénierie en discipline opérationnelle.
10. Ce que les équipes SEO et contenu peuvent citer
Cette recherche fournit plusieurs angles de contenu puissants :
« La page d’accueil DTC médiane contient 52 scripts. » C’est l’accroche performance la plus large.
« Plus le stack analytics est lourd, plus la page l’est aussi. » Les marques avec 5 outils analytics ou plus ont 69 scripts médians, contre 16 pour les marques avec 0 à 2 outils analytics.
« La maturité de croissance crée une dette de performance. » Les marques les plus investies dans la mesure et l’infrastructure lifecycle portent davantage de dépendances frontend.
« La visibilité du consentement est en retard sur la profondeur du tracking. » Même parmi les sites avec 5 outils analytics ou plus, la couverture visible d’un gestionnaire de consentement n’est que de 14,0 %.
« La performance DTC n’est plus seulement un sujet développeur. » Marketing, lifecycle, paid media, support et analytics placent tous du code sur la page.
La réserve est importante : ne présentez pas le nombre de scripts comme la preuve d’une mauvaise performance. Utilisez-le comme proxy de charge de dépendances et de besoin de gouvernance.
11. Comment les différentes équipes doivent lire ce rapport
Le coût caché du growth stack est transversal. C’est pourquoi il est difficile à résoudre. Chaque équipe voit une partie différente du problème.
Les équipes growth voient le gain de revenus. Elles veulent une meilleure attribution, des audiences plus précises, un retargeting plus fort, un feedback de campagne plus clair, de meilleurs tests de landing page et une meilleure capture lifecycle. De leur point de vue, un nouveau script est souvent un petit prix à payer pour davantage de revenus mesurables.
Les équipes frontend voient le coût de dépendance. Elles doivent gérer des pages plus lentes, des décalages de mise en page, des erreurs navigateur, des pannes de tiers, des blocages du main thread, des problèmes d’hydratation et des échecs QA causés par des scripts qu’elles ne possèdent pas forcément. De leur point de vue, les balises marketing se comportent souvent comme des dépendances de production non gérées.
Les équipes SEO voient le coût sur le ranking et le crawl. Elles s’intéressent aux Core Web Vitals, à la rendérisabilité, aux données structurées, à l’efficacité du crawl et à l’expérience utilisateur. Si un site devient plus lent ou plus fragile, la performance SEO peut en pâtir même lorsque le nouveau vendor a été ajouté pour soutenir la croissance paid ou la rétention.
Les équipes data voient le coût de mesure. Plus d’outils peuvent signifier plus de duplication d’événements, plus de désaccords entre tableaux de bord, plus de UTM cassés, plus de débats sur le crédit des canaux et plus d’incertitude sur les chiffres à utiliser pour décider.
Les équipes juridiques et privacy voient le coût de consentement. Plus de tracking signifie plus de revues de vendors, de questions sur le traitement des données, de catégories de consentement, de comportements régionaux et de gestion du risque.
Les dirigeants voient le coût budgétaire et le coût de responsabilité. Chaque outil a un abonnement, mais le coût le plus important peut être le temps passé à réconcilier les données, maintenir les intégrations et corriger les problèmes du site.
La leçon de management la plus importante du rapport est qu’aucune équipe ne possède automatiquement l’ensemble du problème. Le growth stack a besoin d’un modèle d’exploitation partagé. Une version pragmatique consiste en un « stack council » trimestriel avec des représentants growth, lifecycle, ecommerce, SEO, engineering, analytics et privacy. L’ordre du jour doit rester simple : qu’a-t-on ajouté, qu’a-t-on supprimé, qu’est-ce qui est encore utilisé, qu’est-ce qui ralentit le site, qu’est-ce qui est juridiquement sensible et qu’est-ce qui crée une valeur mesurable ?
Cela semble bureaucratique, mais l’alternative est pire : des années de snippets de vendors installés par différentes équipes, sans carte commune ni cycle de nettoyage.
12. Le modèle de revue du stack
Une équipe DTC peut transformer cette recherche en revue trimestrielle à l’aide d’un tableau simple. Chaque ligne correspond à un outil ou à un script.
Nom du vendor ou du script. Qu’est-ce que c’est ?
Responsable métier. Qui l’a demandé et qui l’utilise encore ?
Responsable technique. Qui peut le supprimer ou le modifier en toute sécurité ?
Finalité. Acquisition, rétention, attribution, support, avis, personnalisation, paiements, expérimentation, consentement, monitoring ou legacy.
Pages chargées. Page d’accueil, pages produit, pages de collection, panier, pages liées au checkout, blog, landing pages ou global.
Catégorie de consentement. Essentiel, analytics, marketing, personnalisation, support ou inconnu.
Dernière revue. Quand l’équipe a-t-elle confirmé pour la dernière fois que l’outil était toujours utile ?
Preuve de décision. Quelle métrique ou quel workflow en dépend ?
Impact sur la performance. Affecte-t-il de manière significative les scripts, les requêtes tierces, le travail du main thread ou les Core Web Vitals ?
Conserver, différer, consolider ou supprimer. Quelle est la décision ?
Ce modèle ne nécessite pas une plateforme d’ingénierie sophistiquée. Il peut commencer sous forme de tableur. L’important n’est pas le format, mais la responsabilité. Une fois qu’un outil a un propriétaire et une finalité, l’équipe peut faire des arbitrages rationnels. Sans cette carte, toute discussion sur la performance devient politique.
Le meilleur résultat n’est pas le nombre de scripts le plus bas. Le meilleur résultat est un stack intentionnel : moins de vendors abandonnés, un meilleur comportement de consentement, moins de balises en double, des analytics plus fiables et de meilleures performances pour les outils qui comptent vraiment.
13. Le standard minimal viable de gouvernance
Pour les équipes qui ne peuvent pas encore mettre en place un stack council trimestriel complet, il existe une version allégée. Commencez par trois règles.
Premièrement, aucun nouveau script de vendor ne doit être ajouté sans propriétaire, finalité et condition de suppression. La condition de suppression est importante, car beaucoup de scripts sont installés pour une campagne, un test, une migration ou un lancement temporaire, puis deviennent discrètement permanents.
Deuxièmement, chaque balise analytics ou marketing doit avoir une catégorie de consentement avant sa mise en production. Cela n’exige pas la perfection juridique de la part de l’équipe marketing, mais cela exige un chemin de revue privacy documenté.
Troisièmement, l’équipe doit maintenir une source unique de vérité pour les vendors actifs de la vitrine. Si la seule manière de savoir ce qui tourne sur le site est d’inspecter le code source pendant un incident, alors le stack est déjà non géré.
Ces trois règles ne résoudront pas tous les problèmes de performance. En revanche, elles empêcheront le mode de défaillance le plus courant : un growth stack qui continue de s’étendre sans mémoire.
Méthodologie
Cette recherche utilise le jeu de données du double rapport DTC collecté le 11 mai 2026. Elle a noté 1 238 domaines à l’aide de master.csv, perf_metrics.csv et categories.csv.
L’analyse regroupe les domaines par profondeur analytics, plateforme, catégorie, charge de scripts, charge de domaines tiers et composition du stack. Le nombre de scripts et le nombre de domaines tiers servent de proxys publics de la charge de dépendances frontend.
Les catégories d’outils incluent les signaux de tracking, d’observabilité, de rétention, d’expérience client, de paiement et de gestion du consentement. Les corrélations sont calculées sur les champs numériques de stack et de charge.
Limites
-
Le nombre de scripts est un proxy, pas un score complet de performance. Il ne mesure pas directement les Core Web Vitals, le blocage du main thread, le timing réseau ni l’expérience utilisateur.
-
Un nombre élevé de scripts n’est pas automatiquement mauvais. Une marque complexe peut avoir besoin d’une infrastructure complexe. Le problème, c’est la complexité non gouvernée.
-
La détection des outils est une borne inférieure. Certains scripts se chargent dynamiquement, après consentement, via des tag managers ou via un rendu côté client.
-
La détection des gestionnaires de consentement n’est pas une analyse juridique. Le chiffre de 9,6 % reflète des signaux visibles de type Cookiebot / OneTrust dans le HTML capturé, et non la conformité totale.
-
L’échantillon n’est pas un recensement complet du DTC. Il est biaisé vers les marques visibles dans les écosystèmes d’outils ecommerce et les listes publiques DTC.
-
Les labels de catégorie sont indicatifs. Ils sont utiles pour l’analyse de patterns, mais ne constituent pas une taxonomie exacte.
Notes de reproductibilité
Le dossier de livraison comprend :
analyze_growth_stack_cost.py— script d’analyse utilisé pour noter la charge du stack de vitrine, la profondeur analytics, le nombre de scripts, le nombre de domaines tiers, la visibilité du gestionnaire de consentement et les signaux de gouvernance associés.growth_stack_cost_scores.csv— scores de coût du growth stack et métriques de charge au niveau des domaines.by_analytics_depth.csv— charge de scripts et de domaines tiers regroupée par profondeur d’outils analytics.by_platform_stack_cost.csv— comparaison de la charge du stack par plateforme.by_category_stack_cost.csv— comparaison de la charge du stack par catégorie.stack_cost_correlations.csv— matrice de corrélation numérique entre les champs de stack et de charge.highest_script_burden_domains.csv— domaines présentant la plus forte charge de scripts pour revue éditoriale et validation manuelle.summary.json— métriques agrégées principales citées dans ce rapport, notamment le nombre médian de scripts, le nombre médian de domaines tiers, les comparaisons par profondeur analytics, la visibilité du gestionnaire de consentement et la part de charge de scripts extrême.
Les corrections de méthodologie, les problèmes de jeu de données et les analyses de suivi sont les bienvenus à support@thunderbit.com. Ce rapport est publié indépendamment de toute position commerciale détenue par Thunderbit ; nous construisons un extracteur Web propulsé par l’IA, et nous avons un intérêt structurel à ce que les sites ecommerce publics restent suffisamment inspectables pour que les opérateurs, chercheurs, moteurs de recherche et agents IA puissent comprendre ce qui s’y exécute. Le benchmark repose sur 1 238 domaines DTC notés à partir de signaux publics collectés le 11 mai 2026. Les données de ce rapport se suffisent à elles-mêmes. — L’équipe de recherche Thunderbit, mai 2026.