
Résumé exécutif
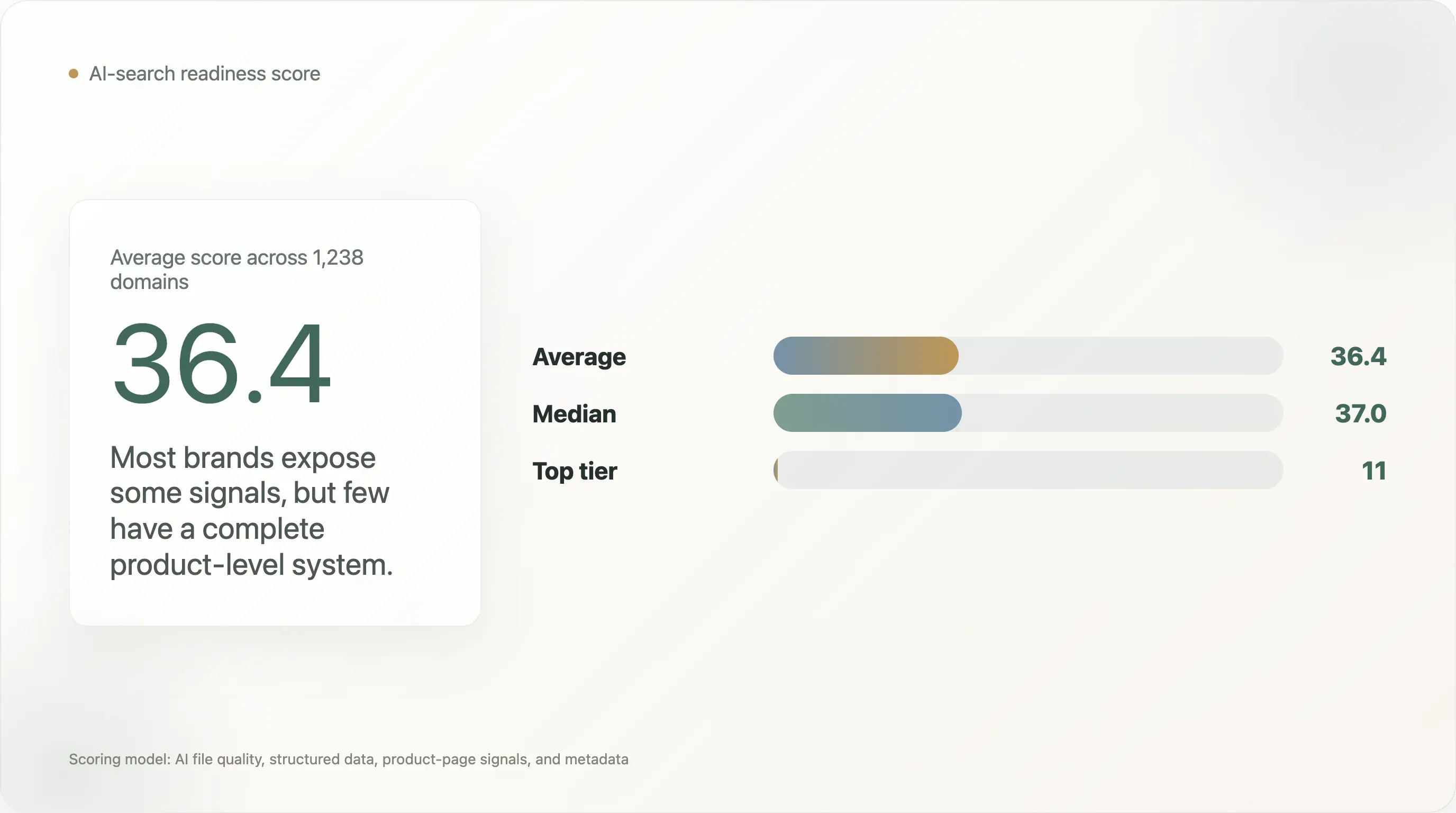
Cette étude évalue 1 238 domaines DTC sur leur niveau de préparation à la recherche IA à partir de quatre couches : qualité du fichier IA, données structurées générales, signaux structurés au niveau des pages produits et métadonnées. Le score moyen est de 36,4 sur 100, et la médiane de 37,0. Seuls 11 domaines ont atteint le niveau ai_ready selon ce modèle de notation.
Le constat principal, c’est le fossé entre la découvrabilité en surface et la compréhension au niveau produit. La plus grande catégorie de qualité llms.txt est platform_default, avec 629 domaines. Autrement dit, de nombreuses marques ont un fichier lisible par l’IA de base, simplement parce que leur plateforme l’a généré. Mais le schéma Product sur la page d’accueil n’apparaît que sur 0,9 % des domaines notés, et le schéma Product sur les pages produits n’apparaît que sur 39,2 % des domaines notés lorsque des pages produits ont été testées. Les signaux de prix sur les pages produits apparaissent sur 48,1 %, et les signaux d’avis ou de note sur 43,5 %.
La répartition par niveau montre à quel point le marché en est encore au début :
| Niveau de préparation à l’IA | Domaines |
|---|---|
| Pas prêt | 435 |
| Partiellement prêt | 425 |
| Découvrabilité de base | 367 |
| Prêt pour l’IA | 11 |
Cette répartition est utile, car elle distingue trois notions qu’on mélange souvent. Une marque peut être découvrable. Une marque peut avoir des métadonnées. Une marque peut avoir un llms.txt. Mais être découvrable n’est pas la même chose qu’être comprise au niveau produit.
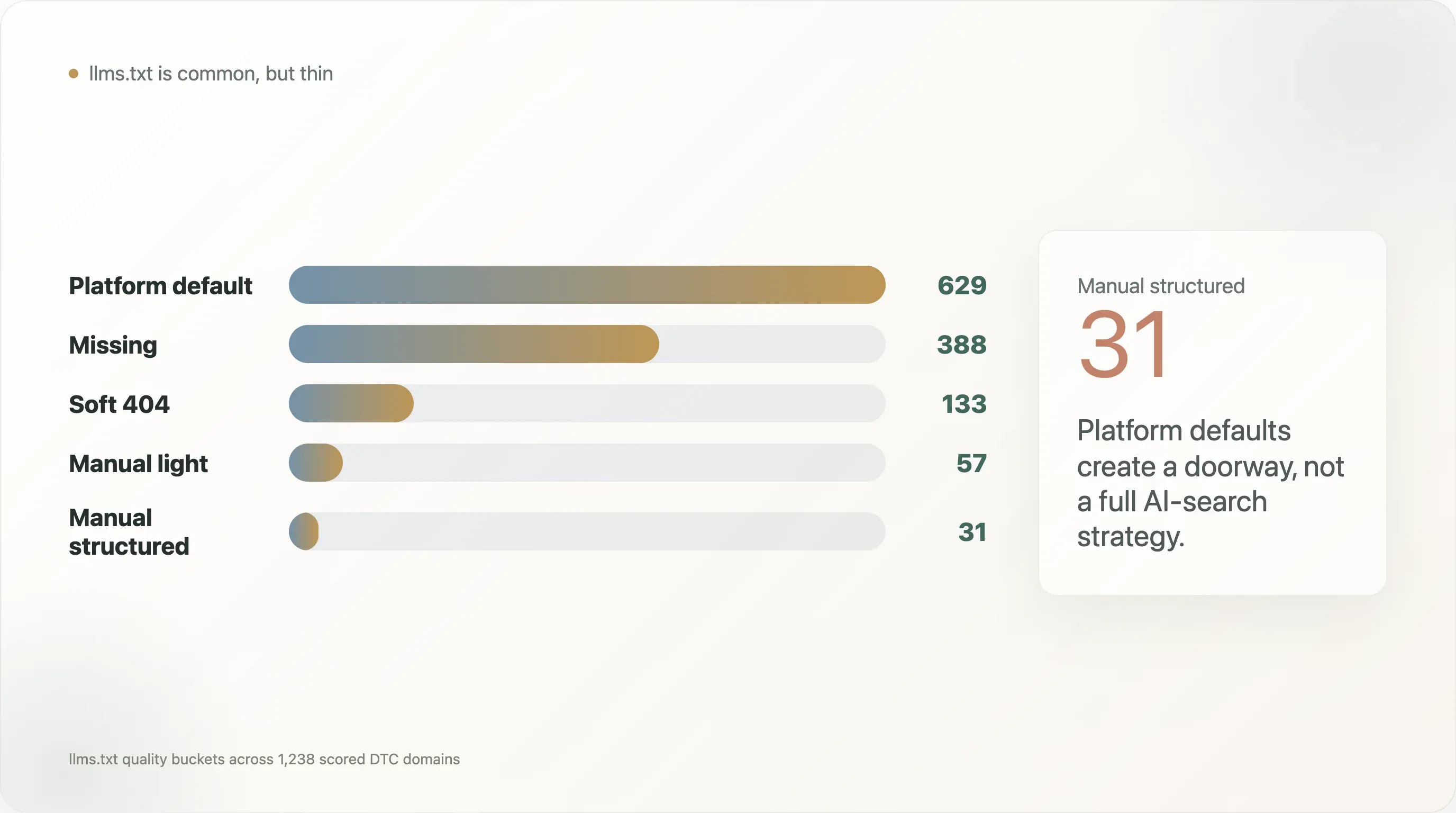
La distribution de la qualité de llms.txt le montre encore plus clairement :
| Catégorie de qualité llms.txt | Domaines |
|---|---|
| Valeur par défaut de la plateforme | 629 |
| Manquant | 388 |
| Faux 404 | 133 |
| Manuel léger | 57 |
| Manuel structuré | 31 |
L’angle le plus fort du rapport n’est donc pas : « les marques DTC ont un llms.txt ». Ce titre serait trop superficiel. L’angle plus juste est le suivant : les valeurs par défaut des plateformes ont créé une première couche fine de découvrabilité pour l’IA, mais la plupart des marques DTC n’ont pas construit la couche de données structurées au niveau produit nécessaire au shopping IA et aux moteurs de réponse.
Les exemples positifs montrent à quoi peut ressembler une meilleure préparation. Le niveau ai_ready comprend des marques comme Mokobara, Magic Mind, Le Petit Ballon, Maine Lobster Now, Yo Mama's Foods, La Maison Convertible, Unbloat, NuRange Coffee, Three Ships Beauty et Manukora. Ces exemples comptent, car ils montrent que la préparation à l’IA n’est pas réservée à une seule catégorie ni à un seul type de marque. L’alimentation, la beauté, le bien-être, le mobilier, l’habillement et le commerce de niche peuvent tous améliorer leur couche de produits lisible par machine.
Les enseignements les plus partageables
-
Le score moyen de préparation à l’IA pour le DTC n’est que de 36,4/100.
-
Seulement 11 des 1 238 domaines notés ont atteint le niveau
ai_ready. -
llms.txt est courant, mais le plus souvent généré par la plateforme. La plus grande catégorie de qualité est la valeur par défaut de la plateforme, avec 629 domaines.
-
Le llms.txt structuré manuellement est rare. Seulement 31 domaines se trouvent dans la catégorie manuelle structurée.
-
Le schéma Product sur la page d’accueil est presque absent. Il n’apparaît que sur 0,9 % des domaines notés.
-
Le schéma Product sur les pages produits est meilleur, mais reste incomplet. Il apparaît sur 39,2 % des domaines notés lorsque des pages produits ont été testées.
-
La préparation au shopping IA exige des faits produit, pas seulement un accès au crawler. Le prix, l’offre, les avis, la disponibilité et les signaux de schéma Product comptent davantage qu’un simple fichier mince.
1. Pourquoi la préparation à la recherche IA diffère des bases du SEO
Le SEO traditionnel demande si une page peut être explorée, indexée, classée et cliquée. La recherche IA ajoute une autre couche : le système peut-il comprendre la marque, le produit, l’offre, le prix, les avis, la disponibilité, les politiques et les relations entre entités assez bien pour répondre à des questions ou recommander des produits ?
Cette différence compte pour le DTC, car les pages e-commerce regorgent de détails qu’un humain comprend facilement, mais qu’une machine peut trouver confus. Un acheteur peut regarder une fiche produit et comprendre le nom du produit, le prix, la taille, l’option d’abonnement, la remise, les avis, le stock et la politique de retour. Un crawler ou un agent IA a besoin que ces informations soient présentées de manière cohérente.
Les métadonnées aident. Open Graph aide. Les balises canoniques aident. llms.txt peut aider les crawlers à trouver le contenu important. Mais la structure au niveau produit est le vrai test. Si un assistant shopping IA compare cinq poudres protéinées, produits de soin, bougies, robes ou abonnements café, il a besoin de faits structurés. Sans ces faits, la marque peut être visible, mais pas comprise de manière fiable.
Ce rapport distingue quatre couches de préparation :
- Couche fichier IA : existence de llms.txt et qualité du fichier, avec les états manquant, faux 404, valeur par défaut de la plateforme, manuel léger ou manuel structuré.
- Couche de données structurées générales : JSON-LD, Organization, WebSite, BreadcrumbList et schéma Product.
- Couche page produit : schéma Product, signaux d’offre ou de prix, signaux d’avis ou de note et signaux de disponibilité.
- Couche métadonnées : canonique, méta-description, image Open Graph, carte Twitter, hreflang et contexte lisible par machine similaire.
Ce modèle en couches est important, car il évite une conclusion trop rapide. Une marque avec un llms.txt mais sans faits produit n’est pas aussi prête qu’elle en a l’air. Une marque sans llms.txt mais avec un schéma riche sur ses pages produits peut être plus compréhensible que ne le laisse penser la couche fichier.
2. L’histoire de llms.txt : une couche fine, surtout créée par les plateformes
L’audit llms.txt a produit cinq catégories de qualité :
| Catégorie de qualité | Domaines | Interprétation |
|---|---|---|
| Valeur par défaut de la plateforme | 629 | Fichier standard généré par la plateforme, généralement léger mais valide |
| Manquant | 388 | Aucun fichier exploitable trouvé |
| Faux 404 | 133 | Réponse trompeuse ou inutile |
| Manuel léger | 57 | Fichier créé par un humain ou personnalisé, mais avec une structure limitée |
| Manuel structuré | 31 | Fichier manuel plus substantiel, avec titres, liens, produits ou termes de politique |
C’est la nuance la plus importante du rapport. En surface, l’adoption de llms.txt semble forte, parce que les fichiers de valeur par défaut de la plateforme sont courants. Mais une valeur par défaut de la plateforme n’est pas la même chose qu’une stratégie réfléchie de recherche IA. Il s’agit souvent d’une simple couche de liens.
Cela ne rend pas les fichiers par défaut de la plateforme inutiles. Ils peuvent aider les crawlers à trouver les chemins importants. Ils montrent aussi à quelle vitesse des décisions prises au niveau de la plateforme peuvent faire évoluer le marché. Une plateforme peut fournir à des centaines de boutiques un nouveau fichier lisible par machine avant même que la plupart des équipes de marque aient discuté d’opérations de recherche IA.
Mais la catégorie manuelle structurée est bien plus petite : 31 domaines. Parmi les exemples relevés dans l’audit figurent des fichiers manuels structurés de marques comme Dermalogica, Ad Hoc Atelier, DKNY, ainsi que plusieurs exemples ai_ready comme Magic Mind, Le Petit Ballon, Maine Lobster Now, Yo Mama's Foods et Three Ships Beauty. Ce sont de bons exemples positifs, car ils montrent ce que signifie aller au-delà d’un fichier par défaut : davantage de liens, davantage de titres, davantage de termes liés aux produits, davantage de termes liés aux politiques et une structure plus réfléchie.
La catégorie faux 404 est également importante. Un faux 404 signifie que la requête renvoie quelque chose, mais pas un fichier llms.txt utile. Cela peut tromper les audits simples. Pour la préparation à la recherche IA, vérifier seulement l’existence ne suffit pas. La qualité compte.
3. La structure au niveau produit est le véritable écart
Le plus grand écart dans les données concerne le schéma Product.
Le schéma Product sur la page d’accueil n’apparaît que sur 0,9 % des domaines notés. Le schéma Product sur les pages produits apparaît sur 39,2 % des domaines notés lorsque des pages produits ont été testées. Les signaux de prix sur les pages produits apparaissent sur 48,1 %, et les signaux d’avis ou de note sur 43,5 %.
Ces chiffres racontent une histoire claire. Les faits produit de base ne sont pas systématiquement lisibles par machine, même lorsque la marque dispose d’une boutique e-commerce.
C’est important, car la recherche IA et le shopping IA devraient récompenser la clarté. Si une page produit expose le schéma Product, les offres, le prix, la disponibilité, les signaux d’avis et les liens vers les politiques, elle fournit aux machines des informations plus fiables. Si ces faits sont enfouis dans du JavaScript, des modèles incohérents, des images ou des widgets dynamiques, les machines risquent de mal interpréter ces éléments, voire de les ignorer.
L’écart de préparation ne concerne pas seulement le classement. Il concerne la représentation. Quand des systèmes IA résument une catégorie de produits, comparent des options, répondent à des questions du type « le meilleur pour », ou génèrent des recommandations d’achat, les marques disposant de faits produit plus propres peuvent être incluses plus facilement et plus précisément.
Les exemples positifs du groupe ai_ready illustrent ce point :
- Mokobara a obtenu le score le plus élevé de la sortie, avec 83.
- Magic Mind, Le Petit Ballon et Maine Lobster Now ont chacun obtenu 81.
- Yo Mama's Foods a obtenu 80.
- La Maison Convertible, Unbloat, Vinocheepo et NuRange Coffee ont obtenu 79.
- Three Ships Beauty a obtenu 77.
- Manukora a obtenu 75.
Ces exemples couvrent plusieurs catégories. La préparation à l’IA n’est pas seulement un sujet beauté ou tech. Elle compte pour l’alimentaire, le bien-être, le mobilier, l’habillement, les produits de niche et toute catégorie où un acheteur peut demander à un système IA des recommandations, des comparaisons ou des explications.
4. Les niveaux de préparation à l’IA : la plupart des marques restent sous la ligne
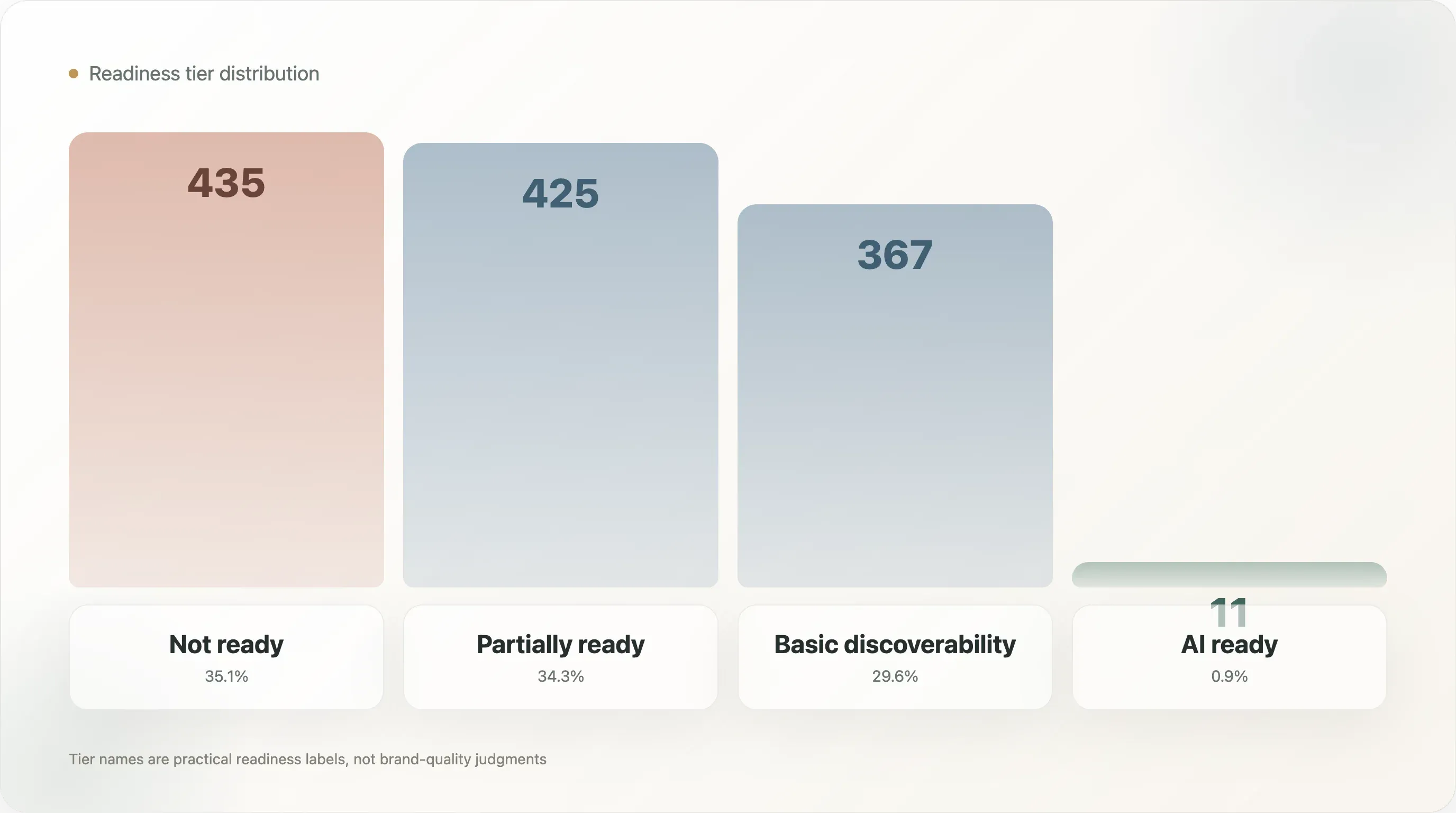
La répartition par niveau est la suivante :
| Niveau | Domaines | Part de l’échantillon |
|---|---|---|
| Pas prêt | 435 | 35,1 % |
| Partiellement prêt | 425 | 34,3 % |
| Découvrabilité de base | 367 | 29,6 % |
| Prêt pour l’IA | 11 | 0,9 % |
Les noms sont volontairement simples. Pas prêt ne veut pas dire que la marque est mauvaise. Cela veut dire que les signaux publics utilisés par ce modèle ne montrent pas assez de préparation à la recherche IA. Partiellement prêt signifie que certains éléments existent, mais que des couches importantes manquent. Découvrabilité de base signifie que la marque est plus visible pour les machines, mais qu’elle peut encore manquer d’exhaustivité au niveau produit. Prêt pour l’IA signifie que le domaine montre une combinaison plus forte de qualité de fichier, de données structurées, de faits produit et de métadonnées.
Seuls 11 domaines ont atteint le niveau supérieur. C’est le titre principal, mais l’enseignement le plus utile tient à la forme du milieu. L’échantillon est presque également réparti entre pas prêt, partiellement prêt et découvrabilité de base. Le marché n’est pas vide. Il est en transition. Beaucoup de marques ont quelques signaux, mais peu disposent d’un système complet.
Cela crée une opportunité à court terme. La préparation à la recherche IA est encore assez tôt pour qu’une marque puisse passer de la moyenne au solide avec un travail très concret : améliorer llms.txt, valider le schéma, exposer les faits produit, nettoyer les métadonnées et rendre les pages produits plus faciles à analyser pour les machines.
5. Tendances par catégorie : la beauté et l’habillement sont en avance, mais aucune catégorie n’est achevée
La classification par catégorie est indicative, pas exacte. Malgré cela, le tableau par catégorie révèle des tendances utiles :
| Catégorie | Échantillon | Préparation moyenne à l’IA | llms manuel ou structuré | Schéma sur la page produit | Taux de schéma sur la page produit |
|---|---|---|---|---|---|
| Beauté & soins de la peau | 98 | 46,2 | 3 | 56 | 57,1 % |
| Habillement & chaussures | 149 | 45,7 | 6 | 79 | 53,0 % |
| Bijoux & accessoires | 34 | 44,5 | 0 | 20 | 58,8 % |
| Animaux de compagnie | 15 | 43,5 | 0 | 8 | 53,3 % |
| Bébé & enfants | 27 | 42,6 | 1 | 15 | 55,6 % |
| Alimentation & boissons | 118 | 42,5 | 5 | 58 | 49,2 % |
| Maison & mobilier | 48 | 42,3 | 0 | 23 | 47,9 % |
| Santé & bien-être | 58 | 40,7 | 6 | 27 | 46,6 % |
| Plein air & sport | 49 | 39,8 | 1 | 23 | 46,9 % |
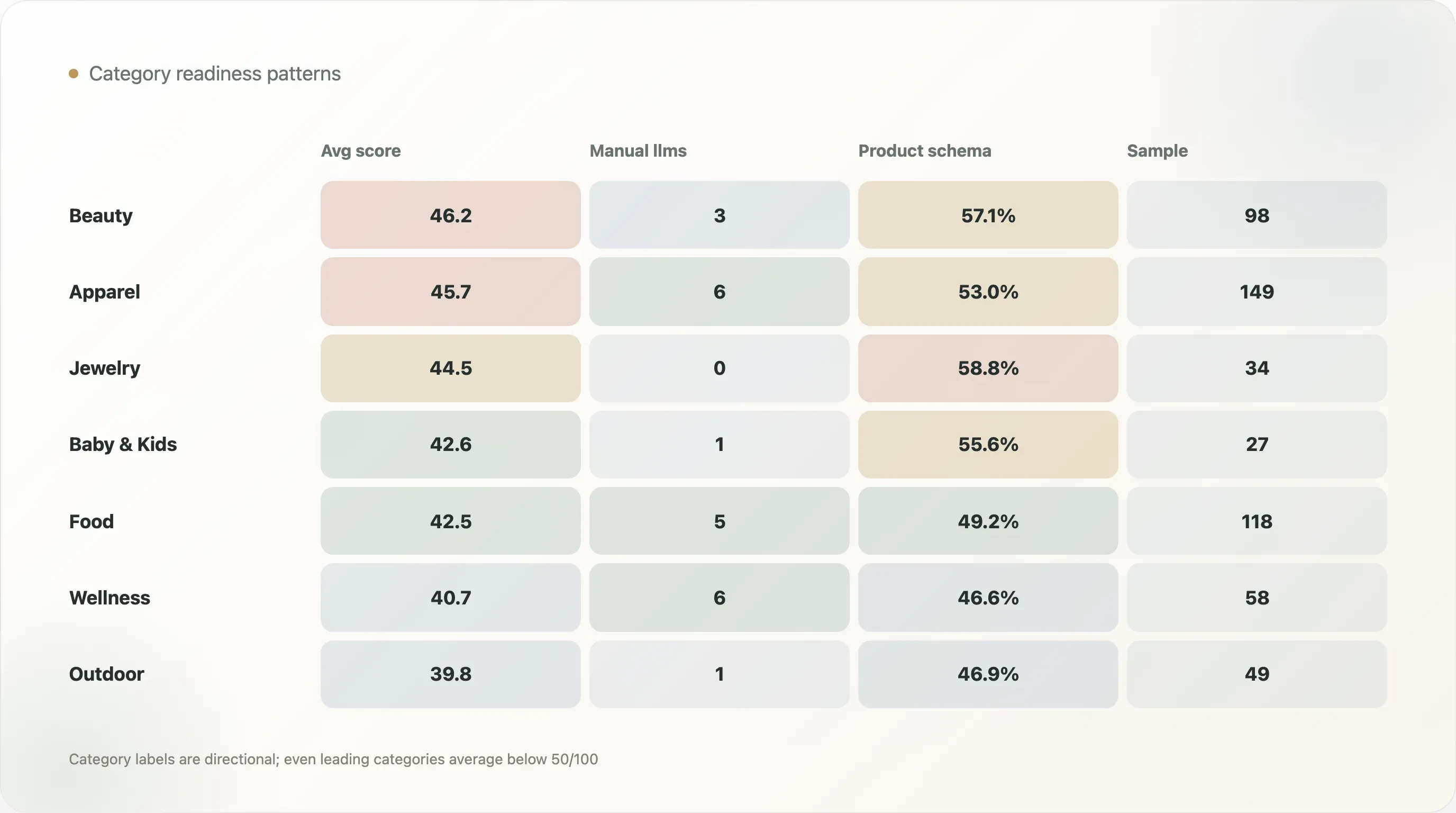
Beauté & soins de la peau affiche le score moyen de préparation à l’IA le plus élevé, à 46,2. Habillement & chaussures suit avec 45,7. Ces catégories disposent souvent de modèles e-commerce solides, de catalogues produits riches, d’avis, de variantes, d’éléments visuels et de besoins éditoriaux importants. Elles peuvent donc bénéficier plus vite du travail structuré sur les produits.
Bijoux & accessoires affiche un taux élevé de schéma sur les pages produits, à 58,8 %, mais aucun détecteur de llms.txt manuel ou structuré dans le tableau de catégorie. Cela montre pourquoi la préparation doit être pensée par couches. Une catégorie peut être forte sur le schéma produit et faible sur la qualité du fichier IA.
Alimentation & boissons comprend plusieurs exemples positifs forts, notamment Maine Lobster Now, Yo Mama's Foods, NuRange Coffee et Manukora. C’est important, car les produits alimentaires et boissons exigent souvent des faits très clairs : ingrédients, nutrition, portion, abonnement, origine, livraison, stockage, avis et disponibilité. Les systèmes IA ne peuvent représenter ces détails avec précision que si le site les expose proprement.
Santé & bien-être affiche un taux de llms manuel ou structuré de 10,3 %, le plus élevé parmi les grandes catégories du tableau, mais un score moyen de 40,7. Cela suggère que certaines marques de la catégorie expérimentent activement des fichiers lisibles par l’IA, tandis que la structure des pages produits peut encore être améliorée. Vu les enjeux de confiance et d’éducation dans le bien-être, cette catégorie devrait être l’une des plus offensives sur les faits structurés.
Aucune catégorie n’est achevée. Même les catégories en tête restent sous 50/100 en moyenne. Cela fait du contenu sur la préparation à l’IA par catégorie une excellente opportunité pour les rédacteurs SEO et les consultants.
6. À quoi ressemble un bon niveau : les schémas positifs des marques prêtes pour l’IA
Le groupe ai_ready est petit, mais il est utile, car il montre des schémas à reproduire.
Mokobara a obtenu 83, le score le plus élevé de la sortie. Il apparaît comme un exemple de bonne préparation globale plutôt que comme une victoire sur un seul signal.
Magic Mind, Le Petit Ballon et Maine Lobster Now ont chacun obtenu 81 et appartiennent à la catégorie llms structurée manuellement. C’est important, car cela montre un travail volontaire au niveau du fichier, et pas seulement des valeurs par défaut de la plateforme.
Yo Mama's Foods a obtenu 80, également avec des llms structurés manuellement. Les marques alimentaires peuvent bénéficier d’une structure lisible par l’IA, car les systèmes IA peuvent être interrogés sur les ingrédients, les saveurs, les cas d’usage, les recettes, l’adéquation à certains régimes et les comparaisons.
Three Ships Beauty a obtenu 77 avec des llms structurés manuellement. La beauté est une catégorie idéale pour une préparation structurée à l’IA, car les acheteurs posent des questions sur le type de peau, les ingrédients, les routines, la texture, les avis et les alternatives.
Manukora a obtenu 75. Le miel et les produits alimentaires proches du bien-être nécessitent souvent des explications sur l’origine, la qualité, les bénéfices, les certifications et l’usage, ce qui rend les signaux structurés de produit et de politique particulièrement précieux.
L’idée n’est pas que chaque marque doive être identique. L’idée est que la préparation à l’IA est un système :
- un fichier llms.txt utile
- des métadonnées propres
- des données structurées Organization et WebSite
- un schéma sur les pages produits
- des signaux de prix et d’offre
- des signaux d’avis ou de note
- des signaux de disponibilité
- une clarté sur les politiques et le support
Chaque couche aide. C’est leur combinaison qui crée la préparation.
7. Pourquoi llms.txt seul ne suffit pas
llms.txt est devenu un raccourci pratique pour parler de préparation à l’IA. C’est compréhensible, car c’est visible, facile à vérifier et assez récent pour sembler stratégique. Mais cette étude montre pourquoi il ne faut pas le considérer comme la totalité du sujet.
Un llms.txt généré par défaut par une plateforme peut créer une porte d’entrée basique. Il peut orienter les crawlers vers les pages importantes. Il peut indiquer aux machines que le site dispose d’un point d’entrée lisible par l’IA. Mais si les pages produits n’exposent pas clairement les faits produit, la porte d’entrée mène à une pièce en désordre.
Le problème de la recherche IA n’est pas seulement : « le crawler peut-il trouver le site ? » C’est aussi :
- le crawler peut-il identifier le produit ?
- peut-il identifier la marque ?
- peut-il analyser le prix ?
- peut-il analyser la disponibilité ?
- peut-il identifier les avis ou les notes ?
- peut-il distinguer le contenu produit du contenu marketing ?
- peut-il comprendre les politiques ?
- peut-il comparer les variantes ?
- peut-il citer la bonne page canonique ?
llms.txt aide à la navigation et à la priorisation. Les données produit structurées aident à la compréhension. La préparation à l’IA exige les deux.
8. Le playbook opérateur : comment améliorer la préparation à la recherche IA
Pour les équipes DTC et e-commerce, le flux de travail pratique est simple.
Étape 1 : vérifier la couche fichier IA. Le domaine a-t-il un llms.txt ? Est-il réel, ou s’agit-il d’un faux 404 ? Est-il généré par défaut par la plateforme, manuel léger ou structuré ? Renvoie-t-il vers des pages utiles ?
Étape 2 : auditer les métadonnées. Vérifiez les balises canoniques, les méta-descriptions, les images Open Graph, les cartes Twitter, le hreflang quand c’est pertinent, et le viewport mobile. Ce n’est pas glamour, mais cela aide les machines à construire le contexte.
Étape 3 : valider le JSON-LD. Vérifiez les schémas Organization, WebSite, BreadcrumbList et Product. Le schéma Product est le principal angle mort du e-commerce.
Étape 4 : auditer les pages produits, pas seulement la page d’accueil. Le shopping IA se concentrera sur les pages produits. Confirmez le nom du produit, la description, l’image, le prix, l’offre, la disponibilité, le SKU, les avis, les notes, les variantes et la politique de retour.
Étape 5 : stabiliser les faits produit. Évitez d’enfouir les informations critiques uniquement dans des images, des onglets qui ne s’affichent pas proprement ou des widgets JavaScript que les crawlers risquent de ne pas analyser.
Étape 6 : améliorer la clarté des politiques. Les conditions de livraison, les retours, les abonnements, les garanties, les certifications et les allégations de sécurité doivent être faciles à trouver et à analyser.
Étape 7 : retester après les changements de modèle. Le schéma casse souvent lors des refontes, des changements de thème, des changements d’apps et des migrations headless. Traitez les données structurées comme une partie du QA.
Étape 8 : prendre la responsabilité du système. La préparation à l’IA ne doit pas relever uniquement du SEO. Elle touche l’e-commerce, le produit, le contenu, l’ingénierie, le juridique et le support client.
9. Ce que les équipes SEO et contenu peuvent citer
Cette étude fournit plusieurs angles de citation solides :
« Seuls 11 des 1 238 domaines DTC notés ont atteint le niveau prêt pour l’IA. » C’est l’accroche la plus large.
« llms.txt est courant, mais surtout généré par la plateforme. » La catégorie de valeur par défaut de la plateforme contient 629 domaines, tandis que les fichiers manuels structurés n’en comptent que 31.
« Le schéma Product sur la page d’accueil n’apparaît que sur 0,9 % des domaines notés. » C’est l’écart de données structurées le plus net.
« Le schéma Product sur les pages produits apparaît sur 39,2 % lorsque des pages produits ont été testées. » Cela apporte de la nuance : les pages produits sont meilleures que les pages d’accueil, mais restent incomplètes.
« Beauté et habillement dominent le tableau des catégories, mais restent sous 50/100 en moyenne. » Cela crée un angle par catégorie.
« La préparation à l’IA est multi-couche. » C’est le point pédagogique le plus important pour les lecteurs qui pourraient sinon assimiler llms.txt à la préparation.
La réserve est essentielle : les données reflètent les signaux publics de sites web dans cet échantillon, et non l’adoption totale du secteur ni les performances de recherche internes.
10. Ce que le shopping IA change pour les équipes DTC
La découverte e-commerce traditionnelle reposait sur les pages, les classements, les publicités et les clics. Un acheteur effectuait une recherche, comparait les résultats, ouvrait des pages, lisait des avis et prenait une décision. Le shopping IA et les moteurs de réponse compressent ce parcours. Un acheteur peut demander « la meilleure sauce faible en sucre pour des pâtes en semaine », « un sac à dos cabine à moins de 200 € avec de bons avis » ou « un nettoyant doux pour peau sensible sans parfum ». Le système IA peut résumer les options avant même que l’acheteur voie la page d’une marque.
Cela change le rôle de la page produit. La page doit toujours convaincre les humains, mais elle doit aussi décrire le produit assez clairement pour que les machines puissent le comparer. Le ton de marque ne suffit pas. De belles images ne suffisent pas. Un nom de produit malin ne suffit pas. La machine a besoin de faits : ce que c’est, pour qui c’est, combien cela coûte, s’il est disponible, quelles variantes existent, ce que disent les avis, quelles allégations sont étayées, quels ingrédients ou matériaux comptent, et quelles politiques s’appliquent.
C’est pourquoi la structure au niveau produit compte davantage qu’un fichier IA générique. llms.txt peut aider un crawler à savoir où regarder. Le schéma Product et des faits propres au niveau de la page produit l’aident à comprendre ce qu’il a trouvé.
Le risque pour les marques DTC n’est pas seulement d’être exclues. C’est d’être mal représentées. Si une page produit manque de clarté, une réponse IA peut résumer la mauvaise caractéristique, manquer un différenciateur clé, omettre une politique importante ou comparer le produit de manière injuste avec des concurrents mieux structurés. En ce sens, la préparation à l’IA est aussi une question de protection de la marque.
Pour les catégories aux parcours de considération complexes, les enjeux sont plus élevés. Les acheteurs beauté demandent le type de peau, les ingrédients, les routines, la sensibilité et les résultats. Les acheteurs alimentaires demandent la nutrition, les allergènes, l’origine, la saveur, les recettes et l’adéquation à un régime. Les acheteurs d’habillement demandent la coupe, la taille, les matières, les retours et le style. Les acheteurs bien-être demandent les preuves, l’usage, la sécurité et la confiance. Les acheteurs maison demandent les dimensions, les matériaux, la livraison, le montage et la durabilité. Ce sont autant de problèmes de contenu lisible par machine que de problèmes marketing.
L’opportunité, c’est que la plupart des marques en sont encore aux débuts. Le score moyen de préparation n’est que de 36,4/100, et seuls 11 domaines ont atteint le niveau ai_ready. Une marque n’a pas besoin d’attendre une refonte complète du site. Elle peut commencer par les modèles, le schéma, la clarté des politiques et les faits produit.
11. Un plan de préparation à l’IA, département par département
La préparation à l’IA ne doit pas relever uniquement du SEO. Elle concerne plusieurs équipes.
Le SEO prend en charge la découvrabilité et la validation du schéma. Les équipes SEO doivent auditer les balises canoniques, les métadonnées, les données structurées, le schéma Product, les fils d’Ariane, le hreflang et l’explorabilité. Elles doivent aussi surveiller si le schéma Product survit aux changements de thème et aux mises à jour d’applications.
L’e-commerce prend en charge les faits de la page produit. Les noms de produits, les prix, les variantes, la disponibilité, les bundles, les abonnements, les avis, les conditions de livraison et les détails de retour doivent être clairs et cohérents. Si ces faits sont fragmentés entre widgets, onglets, images et scripts, les machines peuvent avoir du mal.
Le contenu prend en charge la profondeur explicative. Les systèmes IA valorisent les pages qui répondent clairement aux questions. Les guides d’achat, les tableaux comparatifs, les explications d’ingrédients, les pages par cas d’usage, les conseils de taille et les sections FAQ peuvent aider à la fois les humains et les machines.
L’ingénierie prend en charge la qualité d’implémentation. Le schéma doit être valide, stable et piloté par les modèles. Les faits produit ne doivent pas dépendre uniquement d’un rendu côté client fragile. Les modèles de pages produits doivent être testés après les mises en production.
Le juridique et la conformité prennent en charge les allégations. Si un produit fait des allégations de santé, de durabilité, de sécurité, d’ingrédients ou de performance, elles doivent être exactes, démontrables et faciles à interpréter. Les systèmes IA peuvent amplifier des allégations floues.
Le support client prend en charge les questions récurrentes. Les tickets de support révèlent ce que les acheteurs et les systèmes IA peuvent demander : délai de livraison, taille, ingrédients, compatibilité, retours, annulation d’abonnement, instructions d’entretien et comparaisons de produits. Ces questions devraient alimenter le contenu des pages produits.
Le leadership prend en charge la priorisation. La préparation à l’IA entre en concurrence avec beaucoup d’autres projets. L’argument pour la direction est simple : des faits produit structurés soutiennent le SEO, la recherche IA, les flux produits, le shopping payant, la recherche interne, le support et la conversion. Ce n’est pas seulement un projet IA.
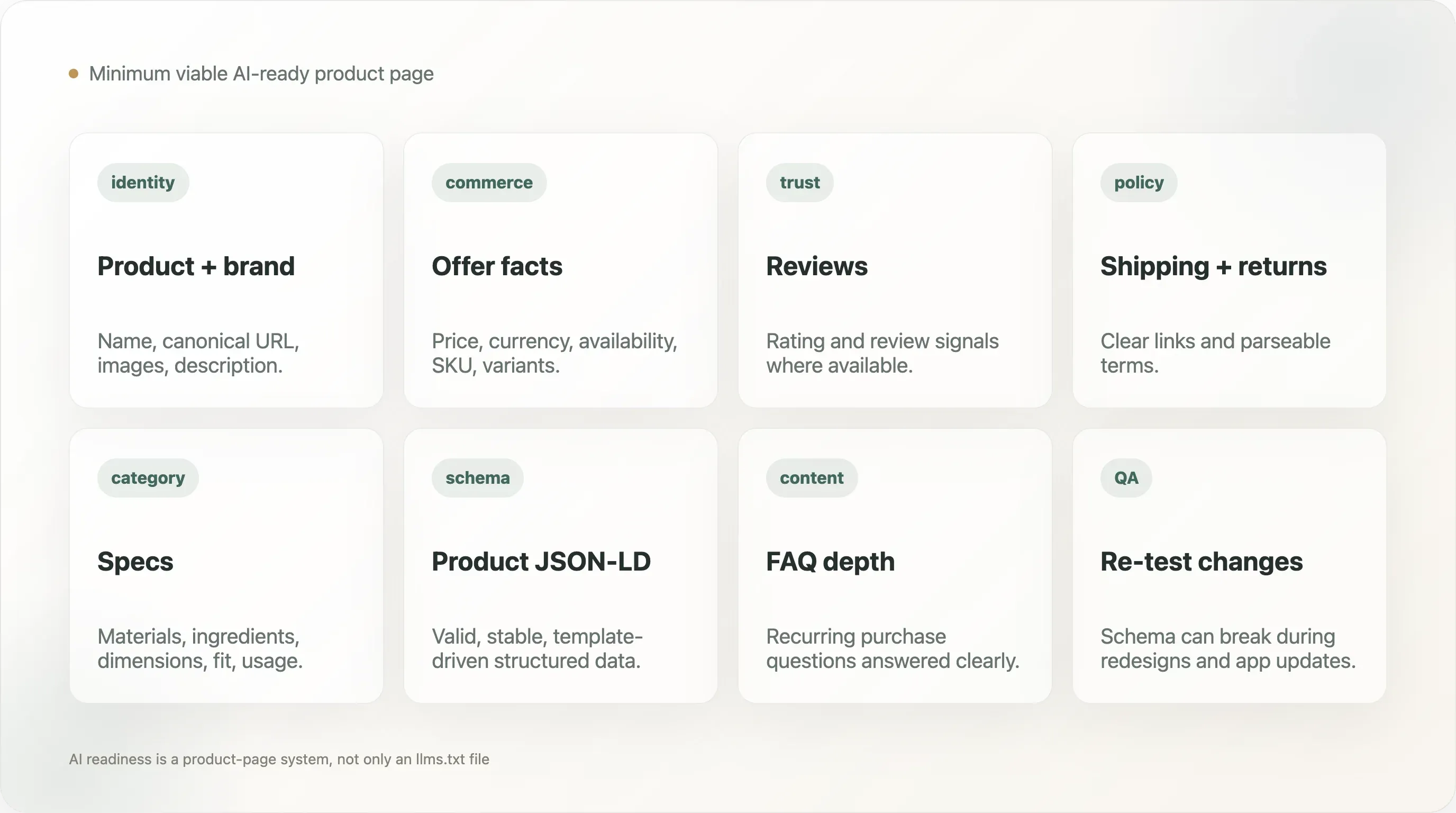
12. La page produit minimale viable prête pour l’IA
Une page produit DTC pratique devrait exposer :
- le nom du produit
- le nom de la marque
- l’URL canonique
- la description du produit
- les images du produit
- le prix
- la devise
- la disponibilité
- les informations sur les variantes
- le SKU ou identifiant produit, le cas échéant
- les signaux d’avis ou de note lorsque disponibles
- les détails de l’offre
- les liens vers les politiques de livraison et de retour
- les faits sur les matières, ingrédients ou spécifications, selon la catégorie
- un contenu FAQ ou support pour les questions récurrentes avant achat
La page doit aussi inclure un schéma Product valide et éviter de cacher les faits critiques uniquement dans des images ou des scripts que les crawlers risquent de ne pas analyser. Cela ne veut pas dire qu’il faut des pages produits ennuyeuses. Cela suppose une séparation entre le design persuasif et des faits structurés fiables.
Pour de nombreuses marques, le gain le plus rapide n’est pas de rédiger un long document de stratégie IA. C’est de valider dix pages produits importantes, de corriger le schéma et de vérifier que les faits produit les plus importants sont visibles dans le HTML et les données structurées.
Méthodologie
Cette recherche utilise l’ensemble de données du double rapport DTC collecté le 11 mai 2026. Elle note 1 238 domaines à l’aide de master.csv, detection.csv, seo_signals.csv, des fichiers llms.txt bruts et du HTML brut des pages produits lorsqu’il est disponible.
Le modèle de notation distingue quatre couches :
- Couche fichier IA : existence et qualité de llms.txt.
- Couche de données structurées générales : JSON-LD, Organization, WebSite, BreadcrumbList, Product et signaux structurés associés.
- Couche page produit : schéma Product, signaux d’offre ou de prix, signaux d’avis ou de note et signaux de disponibilité.
- Couche métadonnées : canonique, méta-description, image Open Graph, carte Twitter, hreflang et contexte de page associé.
Le modèle produit un score de préparation à l’IA de 0 à 100 et classe les domaines dans l’un des quatre niveaux suivants : pas prêt, partiellement prêt, découvrabilité de base et ai_ready.
Réserves
-
La préparation à l’IA n’est pas le trafic IA. Le score ne mesure pas les références réelles issues des systèmes de recherche IA ou des agents shopping.
-
Les signaux publics constituent un plancher. Certaines données structurées peuvent se charger dynamiquement ou apparaître d’une manière que le crawl n’a pas captée.
-
La qualité de llms.txt est heuristique. Les fichiers manuels structurés sont identifiés à partir de caractéristiques observables comme les titres, les liens, les termes de produit et les termes de politique.
-
La détection au niveau page produit dépend des récupérations de pages produits tentées. Les pourcentages de schéma sur les pages produits s’appliquent lorsque des pages produits ont été tentées et sont disponibles.
-
L’échantillon n’est pas un recensement complet du DTC. Il est biaisé en faveur des marques visibles dans les écosystèmes d’outils e-commerce et les listes DTC publiques.
-
Les étiquettes de catégorie sont indicatives. Elles sont utiles pour une comparaison large, mais pas pour une taxonomie exacte.
-
Les standards de la recherche IA évoluent encore. Le modèle de notation est conçu comme un benchmark pratique pour 2026, et non comme une définition permanente.
Notes de reproductibilité
Le dossier de livraison comprend :
analyze_ai_search_readiness.py— script de notation utilisé pour évaluer les domaines DTC sur llms.txt, les données structurées, les signaux de page produit et les signaux de métadonnées.ai_search_readiness_scores.csv— scores de préparation à l’IA au niveau des domaines, niveaux et signaux de composants.llms_quality_audit.csv— audit de qualité llms.txt au niveau des domaines, incluant les classifications valeur par défaut de la plateforme, faux 404, manquant, manuel léger et manuel structuré.category_ai_readiness.csv— comparaison de la préparation à l’IA au niveau des catégories.top_ai_ready_brands.csv— domaines les mieux notés pour relecture éditoriale et sélection d’exemples.lowest_ai_ready_brands.csv— domaines les moins bien notés pour analyse des écarts et relecture éditoriale.summary.json— métriques agrégées principales citées dans ce rapport, notamment la taille de l’échantillon, les comptes par niveau, le score moyen, la médiane et les taux de signaux au niveau page produit.
Les corrections de méthodologie, les problèmes de données et les analyses de suivi sont les bienvenus à support@thunderbit.com. Ce rapport est publié indépendamment de toute position commerciale détenue par Thunderbit ; nous construisons un extracteur Web alimenté par l’IA, et nous avons un intérêt structurel à ce que les sites e-commerce publics deviennent plus faciles à comprendre avec précision pour les humains, les moteurs de recherche et les agents IA. Ce benchmark est fondé sur 1 238 domaines DTC notés à partir de signaux de sites publics collectés le 11 mai 2026. Les données de ce rapport se suffisent à elles-mêmes. — L’équipe de recherche Thunderbit, mai 2026.