
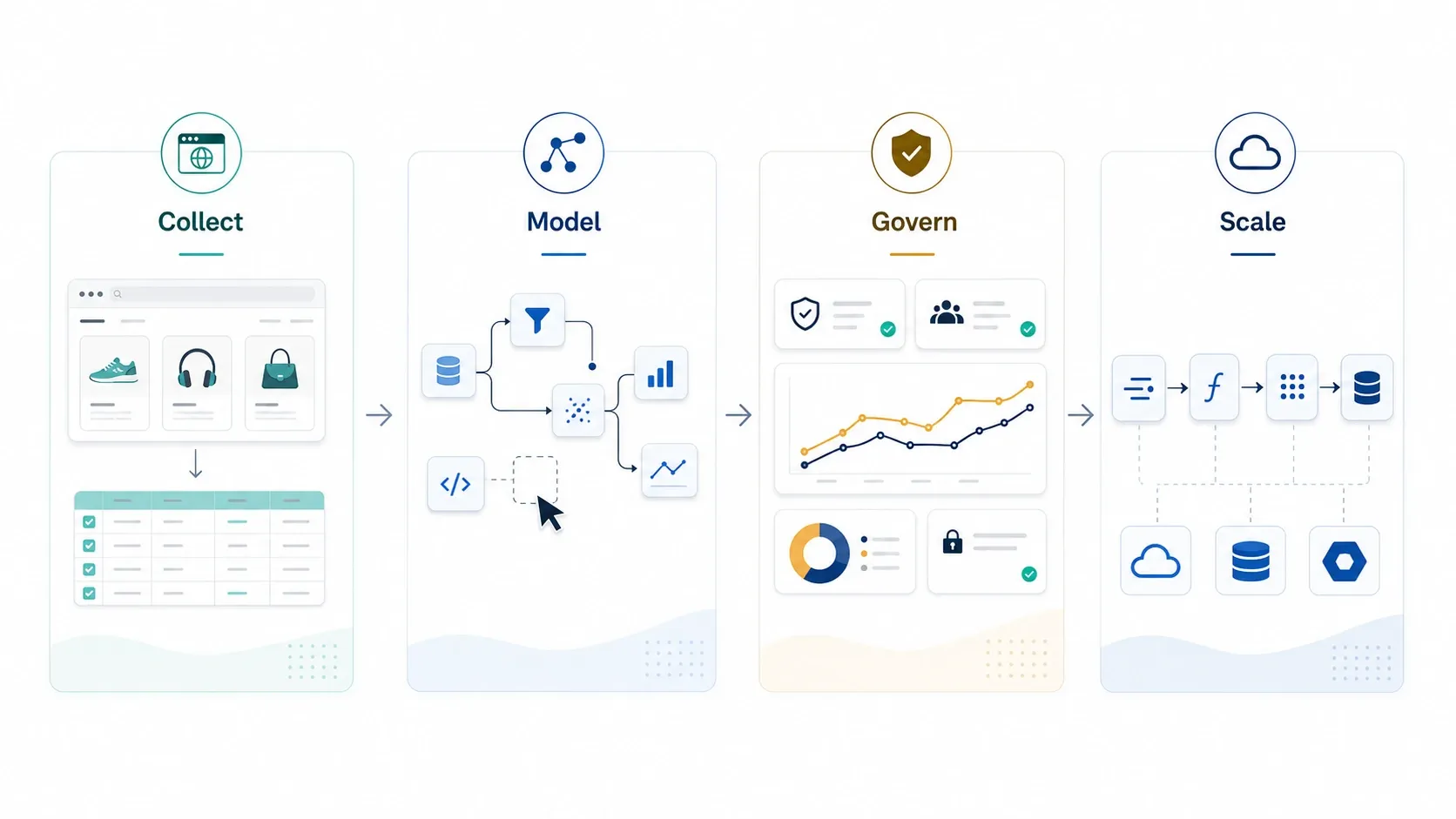
En 2026, les entreprises ne manquent pas de données. Elles manquent de workflows adaptés. Le que la création mondiale de données devait atteindre 181 zettaoctets en 2025, tandis qu’IBM estime que . C’est cet écart qui explique pourquoi les logiciels d’exploration de données restent indispensables : non pas comme un mot à la mode, mais comme la couche pratique qui transforme des enregistrements bruts, des documents, des données de sites web et des flux d’événements en schémas réellement exploitables.
: l’exploration de données utilise le machine learning et l’analyse statistique pour faire émerger des informations utiles à partir de grands ensembles de données. En pratique, cela signifie que les acheteurs évaluent aujourd’hui une pile bien plus large que ne le laisse entendre l’ancienne définition de salle de classe. Certaines équipes ont besoin d’outils de modélisation visuelle. D’autres ont besoin d’analyses d’entreprise gouvernées. D’autres encore ont besoin de ML à l’échelle du cloud et d’une infrastructure de streaming. Et certaines ont simplement besoin de capturer des données web complexes avant même de pouvoir commencer l’analyse.
Sélection rapide par flux de travail
- Vous devez collecter rapidement des données de sites web avant de les analyser ? Commencez avec .
- Vous avez besoin d’une plateforme de data science visuelle sans code ? Retenez et .
- Vous cherchez le point de départ open source le plus simple pour apprendre ou prototyper ? Regardez et .
- Vous avez besoin d’analyses prédictives d’entreprise avec gouvernance ? Comparez , et .
- Vous avez besoin de ML cloud natif et de déploiement ? Examinez , et .
- Vous avez besoin de pipelines à grande échelle ou d’analyses in-database ? Concentrez-vous sur et .
Qu’est-ce qui compte comme logiciel d’exploration de données en 2026 ?
Ce mot-clé couvre désormais quatre grands types d’achats :
- Outils d’acquisition de données : produits qui vous aident à collecter ou structurer les données brutes avant le début de l’analyse.
- Outils de workflows visuels : plateformes qui permettent aux analystes de nettoyer les données, créer des modèles et évaluer les résultats sans beaucoup coder.
- Suites statistiques et prédictives d’entreprise : systèmes gouvernés destinés aux grandes organisations et aux équipes soumises à réglementation.
- Couches cloud et infrastructure : plateformes qui prennent en charge l’entraînement à grande échelle, le déploiement ou le traitement en temps réel.
C’est pourquoi cette liste est volontairement mélangée. Si votre équipe passe encore des heures à copier des champs depuis des sites web, un outil de capture de données pensé d’abord pour le navigateur peut créer plus de valeur métier qu’une suite de modélisation sophistiquée que vous n’adoptez jamais vraiment. À l’inverse, si votre goulot d’étranglement concerne le déploiement gouverné des modèles ou le traitement à l’échelle d’un entrepôt de données, c’est l’inverse qui est vrai.
Si vous voulez une courte vidéo d’orientation avant de comparer les outils, cette présentation d’IBM reste la meilleure introduction à fort signal, car elle explique où se situe l’exploration de données par rapport à l’analytique, au machine learning et à l’amélioration des processus :
Tableau comparatif rapide : meilleurs logiciels d’exploration de données en 2026
| Outil | Idéal pour | Ce qui le distingue | Signal de tarification |
|---|---|---|---|
| Thunderbit | Équipes business qui ont besoin de données web brutes avant l’analyse | Suggestion de champs par IA, sous-pages, pagination, export vers Sheets / Excel / Airtable / Notion | Formule gratuite ; offres payantes en libre-service ; formules entreprise |
| Altair AI Studio | Workflows ML visuels sans gros effort de code | Conception par glisser-déposer, AutoML, préparation interactive des données ; anciennement RapidMiner Studio | Essai gratuit ; éditions commerciales |
| KNIME | Analytique de workflows open source et automatisation | Pipelines par nœuds, forte communauté, nombreuses extensions | Plateforme gratuite ; produits business payants |
| Orange | Débutants et exploration visuelle orientée apprentissage | Widgets visuels très accessibles et flux d’exploration | Gratuit et open source |
| Weka | Expérimentation d’algorithmes et enseignement | Large bibliothèque de méthodes ML classiques dans une interface légère | Gratuit et open source |
| IBM SPSS Modeler | Équipes d’analytique prédictive en entreprise | Flux visuels, analytique textuelle, déploiement adapté à la gouvernance | Sur devis / entreprise |
| SAS Enterprise Miner | Secteurs réglementés et équipes centrées sur SAS | Profondeur de modélisation mature, traitement de gros volumes, intégration SAS | Sur devis / entreprise |
| Azure Machine Learning | Analytique et ML cloud pour les équipes Microsoft | AutoML, MLOps, intégration Azure, déploiement managé | Tarification cloud à l’usage |
| Alteryx | Analystes qui automatisent la préparation et l’analytique en libre-service | Préparation par glisser-déposer, workflows répétables, large adoption métier | Essai puis tarification entreprise |
| Spotfire Statistica | Profondeur statistique et contrôles d’entreprise | Analyses avancées, workflows réutilisables, surveillance orientée conformité | Sur devis / entreprise |
| Teradata | Analyses in-database à très grande échelle | Excellentes performances sur d’immenses ensembles de données et environnements gouvernés | Entreprise / contrat |
| Rattle | Apprentissage basé sur R et prototypage à faible coût | Interface graphique au-dessus des workflows R avec visibilité du code | Gratuit et open source |
| Dataiku | Équipes data science transverses | Collaboration no-code + code, automatisation, gouvernance | Édition gratuite ; tarification entreprise |
| H2O.ai | AutoML et création de modèles à grande échelle | Modélisation rapide, explicabilité, solide écosystème ML | Open source + offres entreprise |
| Google Cloud Dataflow | Traitement de données en temps réel et grands lots | Pipelines Apache Beam managés, autoscaling, prise en charge du streaming | Tarification cloud à l’usage |
Les 15 meilleurs outils de logiciel d’exploration de données pour les entreprises en 2026
Meilleurs pour la collecte rapide de données et l’exploration de workflows visuels
1. Thunderbit
mérite sa place dans cette liste, car de nombreux projets d’exploration de données en entreprise échouent avant même le début de la modélisation. Les données se trouvent sur des sites web, des PDF, des pages de recherche internes, des portails ou des annonces très visuelles. Si vous ne pouvez pas les collecter proprement, votre pile analytique ne change rien.
Thunderbit est particulièrement performant lorsque le travail commence dans un navigateur et que l’équipe veut rapidement un résultat structuré. Sa suggestion de champs par IA, son scraping de sous-pages, sa gestion de la pagination et ses exports directs en font une bonne solution pour les équipes commerciales, e-commerce, opérations, recrutement et études de marché qui ne veulent pas d’abord construire un pipeline de scraping.
- Idéal pour : l’acquisition de données web pour les utilisateurs métier.
- Ce qui le distingue : AI Suggest Fields, enrichissement de sous-pages, exécution dans le navigateur ou dans le cloud, exports vers Sheets / Excel / Airtable / Notion.
- Pourquoi il figure dans la liste : il supprime le goulet d’étranglement de la collecte qui bloque l’analyse en aval.
- Signal de tarification : formule gratuite, offres payantes en libre-service et options entreprise disponibles.
2. Altair AI Studio
est l’un des changements les plus importants à bien distinguer si vous connaissez cette catégorie à travers d’anciens classements : c’est le nom actuel du produit que de nombreux acheteurs connaissent encore sous le nom de RapidMiner Studio. Altair le présente comme un outil de conception de data science visuel par glisser-déposer, avec AutoML, préparation interactive des données et prise en charge des workflows d’IA plus récents comme du machine learning classique.
Il reste un excellent choix pour les équipes qui veulent une vraie capacité de modélisation sans devoir construire chaque workflow dans des notebooks. Par rapport aux outils purement pédagogiques, il offre un meilleur passage vers une utilisation métier répétable.
- Idéal pour : les analystes et experts métier qui veulent des workflows ML visuels guidés.
- Ce qui le distingue : canevas par glisser-déposer, AutoML, préparation interactive, connectivité étendue des données.
- À surveiller : le positionnement commercial est plus marqué que celui des options open source, donc les achats et validations comptent davantage.
3. KNIME Analytics Platform

reste l’outil de workflows open source le plus polyvalent de cette liste. Son interface basée sur des nœuds est assez accessible pour les analystes, mais suffisamment profonde pour les équipes qui veulent combiner préparation des données, analyse statistique, ML, automatisation et extensions dans un seul pipeline répétable.
KNIME fonctionne particulièrement bien lorsque la transparence est essentielle. Les utilisateurs peuvent examiner chaque étape d’un workflow, le partager et l’étendre avec des intégrations Python, R, bases de données et autres outils.
- Idéal pour : les équipes d’abord orientées open source et les analystes à forte logique de workflow.
- Ce qui le distingue : pipelines réutilisables, vaste écosystème d’extensions, forte adoption communautaire.
- À surveiller : la flexibilité est excellente, mais l’interface peut sembler plus orientée ingénierie que les outils légers pour débutants.
4. Orange
reste l’environnement d’exploration de données le plus accueillant pour les utilisateurs qui veulent apprendre en voyant. Son interface à widgets rend la classification, le clustering, la visualisation et l’exploration de texte beaucoup plus faciles à comprendre que les outils centrés sur la ligne de commande.
Pour les équipes business, Orange est surtout utile comme outil de prototypage rapide ou d’apprentissage, pas comme plateforme d’entreprise lourde et gouvernée.
- Idéal pour : débutants, enseignants, ateliers et exploration en phase initiale.
- Ce qui le distingue : interface visuelle accessible et excellente visualisation exploratoire.
- À surveiller : ce n’est pas le meilleur choix pour un déploiement d’entreprise ou une industrialisation lourde.
5. Weka
reste un classique pour une bonne raison. Il propose un large ensemble d’algorithmes de machine learning dans une interface compacte, facile à utiliser pour l’expérimentation, les comparaisons et les travaux pédagogiques.
Son intérêt métier est plus limité qu’avant, mais il garde de la valeur pour les tests rapides, l’apprentissage et les petits ensembles de données lorsque vous voulez une couverture large d’algorithmes sans déployer une plateforme plus lourde.
- Idéal pour : la comparaison d’algorithmes, l’enseignement et l’expérimentation à petite échelle.
- Ce qui le distingue : large couverture des méthodes ML classiques et interface légère.
- À surveiller : il paraît daté face aux produits de workflows plus récents et n’est pas conçu pour le MLOps moderne.
Si vous voulez voir à quoi ressemble un produit moderne de workflow visuel avant d’en sélectionner un, cette présentation officielle de l’interface d’Altair AI Studio est un bon point de passage au milieu de l’article :
Meilleurs pour l’analytique prédictive d’entreprise et la modélisation gouvernée
6. IBM SPSS Modeler
reste l’option la plus sûre à retenir pour les organisations qui veulent de l’analytique prédictive d’entreprise sans obliger chaque analyste à utiliser des outils très orientés code. Son interface visuelle en flux a bien résisté au temps, car elle rend la construction de modèles, la préparation et le scoring compréhensibles pour les parties prenantes métier.
- Idéal pour : les grandes organisations qui veulent une analytique prédictive accessible avec gouvernance.
- Ce qui le distingue : flux visuels, prise en charge de l’analytique textuelle, options de déploiement entreprise.
- À surveiller : il s’agit d’un achat de plateforme, pas d’un outil d’équipe occasionnel.
7. SAS Enterprise Miner
reste surtout pertinent dans les environnements réglementés et centrés sur SAS. Ce n’est pas l’outil le plus tendance de la catégorie, mais il reste crédible là où l’auditabilité, la confiance institutionnelle et l’infrastructure SAS existante comptent davantage que l’effet de mode.
- Idéal pour : la finance, la santé, l’assurance et les autres flux réglementés.
- Ce qui le distingue : profondeur de modélisation mature, adéquation à l’écosystème SAS, traitement de gros volumes.
- À surveiller : les équipes sans investissement SAS existant peuvent trouver des plateformes plus récentes plus faciles à adopter.
8. Microsoft Azure Machine Learning
est l’option la plus solide pour les équipes qui vivent déjà dans la pile cloud de Microsoft et qui veulent un seul environnement pour l’expérimentation, l’AutoML, le déploiement et la supervision.
- Idéal pour : les organisations d’abord Azure qui veulent du ML cloud avec des opérations intégrées.
- Ce qui le distingue : AutoML, gestion des modèles, outils de déploiement, intégration à l’écosystème Microsoft.
- À surveiller : la flexibilité du cloud est un atout, mais la maîtrise des coûts devient importante lorsque l’usage augmente.
9. Alteryx

mérite sa place parce qu’une grande partie de l’exploration de données en entreprise consiste encore, au fond, à nettoyer, combiner et industrialiser des tâches de données qui vivaient autrefois dans des tableurs. Alteryx est depuis longtemps l’outil que les analystes achètent quand ils veulent arrêter de refaire à la main, chaque semaine, les mêmes transformations pénibles.
- Idéal pour : les analystes métier qui automatisent des workflows lourds en préparation.
- Ce qui le distingue : préparation par glisser-déposer, workflows analytiques répétables, forte adoption par les utilisateurs métier.
- À surveiller : puissant, mais ce n’est généralement pas l’option la moins chère pour les petites équipes.
10. Spotfire Statistica
reste l’une des meilleures options pour les organisations qui ont besoin de méthodes statistiques avancées et d’un usage opérationnel contrôlé. Le positionnement actuel de Spotfire met l’accent sur l’analytique avancée, les workflows réutilisables et une gouvernance adaptée à la conformité.
- Idéal pour : la fabrication, la santé, la qualité et les équipes analytiques orientées conformité.
- Ce qui le distingue : profondeur statistique mature, workflows de modèles réutilisables, supervision et gouvernance.
- À surveiller : mieux adapté aux programmes d’entreprise structurés qu’à l’expérimentation légère.
Meilleurs pour les plateformes de données avancées, la collaboration et l’échelle
11. Teradata
figure ici pour une raison : lorsque votre problème d’exploration de données se situe dans un immense patrimoine de données gouverné, la performance et l’architecture comptent autant que les algorithmes. Teradata reste pertinent pour les analyses in-database, l’entrepôt de données à grande échelle et les charges d’entreprise que des outils plus ciblés ne peuvent pas absorber confortablement.
- Idéal pour : les très grands ensembles de données d’entreprise et l’analytique in-database.
- Ce qui le distingue : l’échelle, la performance et l’adéquation aux environnements de données d’entreprise.
- À surveiller : surdimensionné pour la plupart des PME et des équipes intermédiaires.
12. Rattle
reste une passerelle utile pour les équipes ou les apprenants qui veulent l’écosystème de modélisation de R avec moins de script au départ. Il vaut mieux le considérer comme un environnement de prototypage et d’apprentissage à faible coût, et non comme une plateforme moderne de collaboration.
- Idéal pour : les apprenants de R et le prototypage léger.
- Ce qui le distingue : interface graphique au-dessus des workflows R avec visibilité du code.
- À surveiller : daté face aux produits de collaboration visuelle plus récents.
13. Dataiku
est l’un des produits les plus équilibrés de cette liste lorsque vous avez besoin à la fois de collaboration et d’échelle. Il fonctionne bien parce qu’il n’impose pas un faux choix entre les utilisateurs no-code et les praticiens avancés. Les utilisateurs métier peuvent travailler avec des recettes et des tableaux de bord, tandis que les utilisateurs techniques gardent le contrôle au niveau du code lorsque c’est nécessaire.
- Idéal pour : les équipes transverses d’analytique et de data science.
- Ce qui le distingue : collaboration no-code + code, gouvernance solide, automatisation et prise en charge du déploiement.
- À surveiller : c’est plus une plateforme que ce dont beaucoup de petites équipes ont besoin si leur cas d’usage est étroit.
14. H2O.ai
reste très bien placé pour les organisations qui accordent de l’importance à la modélisation à grande échelle, à l’AutoML et à l’explicabilité. Il est particulièrement attractif lorsque la vitesse et l’itération des modèles comptent plus que la construction de chaque pièce du workflow à partir de zéro.
- Idéal pour : les équipes ML qui veulent itérer vite et automatiser à grande échelle.
- Ce qui le distingue : AutoML, vitesse de modélisation, explicabilité, solide écosystème.
- À surveiller : il est davantage centré sur le ML que ce dont certaines équipes business ont réellement besoin.
15. Google Cloud Dataflow
n’est pas un outil de bureau classique pour l’exploration de données, mais il mérite cette dernière place parce que de nombreux projets modernes dépendent de pipelines de données en temps réel ou de gros lots avant même que l’analyse ne commence. Si votre cas d’usage implique du streaming, du traitement d’événements ou une préparation de variables à grande échelle, Dataflow fait partie de la pile d’exploration réelle.
- Idéal pour : les pipelines de streaming et la préparation de gros lots à grande échelle.
- Ce qui le distingue : Apache Beam managé, autoscaling, forte intégration GCP.
- À surveiller : c’est une infrastructure d’abord, pas un outil analytique pensé d’abord pour les utilisateurs métier.
Comment choisir sans suracheter
L’erreur d’achat la plus fréquente consiste à confondre l’origine de la friction :
- Si le problème est l’accès aux données, commencez par un outil de collecte comme Thunderbit.
- Si le problème est la productivité des analystes, comparez d’abord Altair AI Studio, KNIME, Alteryx et Orange.
- Si le problème est la gouvernance d’entreprise, retenez SPSS Modeler, SAS Enterprise Miner, Spotfire Statistica ou Dataiku.
- Si le problème est les opérations de ML cloud, commencez avec Azure Machine Learning, H2O.ai ou Dataiku.
- Si le problème est le streaming ou une architecture à très grande échelle, orientez-vous vers Teradata ou Dataflow.

Une règle simple aide : achetez l’outil le moins complexe qui élimine réellement votre goulot d’étranglement. Beaucoup d’équipes n’ont pas besoin d’une plateforme massive de data science. Elles ont besoin d’une meilleure collecte de données, d’une préparation plus propre et d’un workflow répétable que leurs analystes utiliseront vraiment.
Si votre présélection inclut la capture de données web dans la pile, cette vidéo de démarrage rapide Thunderbit est l’exemple d’exécution le plus utile, car elle montre le chemin d’une page désordonnée vers un tableau structuré sans détour par de la lourdeur d’ingénierie :
Sélection finale par type d’équipe

- Équipes commerciales, e-commerce et opérations très orientées navigateur : Thunderbit, Alteryx, KNIME.
- Analystes qui veulent des workflows visuels sans dépendre fortement du code : Altair AI Studio, KNIME, Alteryx, Orange.
- Équipes d’analytique prédictive en entreprise : IBM SPSS Modeler, SAS Enterprise Miner, Spotfire Statistica.
- Organisations data science transverses : Dataiku, Azure Machine Learning, H2O.ai.
- Équipes d’ingénierie des données et de plateforme : Teradata, Google Cloud Dataflow, Azure Machine Learning.
- Apprenants ou prototypistes soucieux du budget : Orange, Weka, Rattle, KNIME.
Si je devais réduire cette liste au plus petit ensemble vraiment pratique pour la plupart des acheteurs business en 2026, ce serait :
- Thunderbit pour capturer rapidement des données de sites web et de documents avant analyse.
- Altair AI Studio pour la data science visuelle et l’AutoML sans workflow centré sur les notebooks.
- KNIME pour la flexibilité des workflows open source.
- IBM SPSS Modeler pour l’analytique prédictive d’entreprise avec une interface adaptée au métier.
- Dataiku pour les équipes qui ont besoin à la fois de collaboration, de gouvernance et d’échelle.
Conclusion
La vraie question n’est pas de savoir quel produit affiche la plus longue liste de fonctionnalités. C’est de savoir quel outil amène votre équipe de données brutes à une décision défendable avec le moins de friction possible. En 2026, cela signifie généralement séparer les problèmes de collecte, de préparation, de modélisation et de déploiement au lieu de prétendre qu’un seul achat résout chaque couche de la même manière.
Si votre travail commence avec des sites web publics, des PDF et des pages non structurées, commencez avec . S’il commence avec une modélisation d’entreprise gouvernée, partez plus haut dans la pile avec des outils comme SPSS Modeler, Dataiku ou Azure Machine Learning. Et si vous êtes encore en train d’apprendre de quelle catégorie de plateforme vous avez vraiment besoin, KNIME, Orange et Altair AI Studio restent les meilleurs endroits pour obtenir rapidement des signaux utiles.
Lectures associées
FAQ
1. Qu’est-ce qu’un logiciel d’exploration de données, en termes simples pour une entreprise ?
Un logiciel d’exploration de données aide les équipes à trouver des schémas, des segments, des anomalies, des tendances et des signaux prédictifs dans des données brutes. Dans un vrai workflow métier, cela signifie généralement un mélange de collecte de données, nettoyage, création de modèles, scoring et reporting.
2. Un logiciel d’exploration de données est-il réservé aux data scientists ?
Non. Le marché est désormais partagé entre acheteurs techniques et non techniques. Thunderbit, Altair AI Studio, KNIME, Orange et Alteryx abaissent tous la barrière pour les analystes et les équipes business, tandis que des plateformes comme Dataiku, Azure ML et H2O.ai servent aussi des utilisateurs plus avancés.
3. Quel est le meilleur logiciel d’exploration de données pour une équipe non technique ?
Si vos données commencent sur le web, Thunderbit est la première étape la plus rapide. Si vous avez besoin d’analyses visuelles plus larges et de modélisation de workflow, Altair AI Studio, KNIME, Orange et Alteryx sont les options sans code ou à faible code les plus solides de cette liste.
4. Dois-je choisir un outil open source ou une plateforme d’entreprise ?
Choisissez l’open source lorsque vous avez besoin de flexibilité, d’un coût d’entrée plus faible et d’une marge d’expérimentation. Choisissez les plateformes d’entreprise lorsque la gouvernance, le support, les contrôles de déploiement, la conformité et la standardisation entre équipes comptent davantage que la simplicité de licence.
5. Puis-je utiliser plusieurs de ces outils ensemble ?
Oui, et beaucoup d’équipes devraient le faire. Une pile courante consiste à collecter les données avec Thunderbit, à les préparer ou les modéliser dans KNIME ou Alteryx, puis à les industrialiser ou les superviser dans une plateforme cloud ou d’entreprise. La meilleure pile résout généralement différentes couches du workflow au lieu de forcer un seul outil à tout faire.