Tu t’es déjà retrouvé devant un fichier Excel à te demander si « Acme Inc. » et « Acme Incorporated » sont la même boîte ? Rassure-toi, tu n’es pas le seul ! Dans le monde pro, les doublons et les données incohérentes, ce n’est pas juste un petit souci : ça coûte un bras. Aux États-Unis, les entreprises perdent chaque année , soit en moyenne 13 millions de dollars par boîte à cause de doublons, de contacts mal reliés ou d’analyses à côté de la plaque. Plus tu as de sources et de systèmes, plus ça devient galère—la correspondance de données devient alors un passage obligé pour garder la main (et éviter de s’arracher les cheveux).

Mais au fait, c’est quoi la correspondance de données, et pourquoi les équipes commerciales, marketing ou opérationnelles devraient s’en soucier ? Dans ce guide, je t’explique les bases, je te donne des exemples concrets et je te montre comment des outils modernes comme rendent la correspondance de données accessible à tous, même si tu n’es pas un as de la technique. Prêt à transformer le bazar de tes données en quelque chose de clair ? C’est parti !
C’est quoi la correspondance de données ? Explication simple
En gros, la correspondance de données (data matching) c’est le fait d’identifier et de relier des enregistrements qui parlent de la même personne, boîte ou produit, mais dans des bases différentes (). Imagine un boulot de détective pour tes fichiers : repérer que « John Doe » dans ton CRM commercial, c’est la même personne que « Jonathan Doe » dans le support client, même si les infos ne sont pas tout à fait identiques.
Concrètement, ça veut dire :
- Faire matcher les fiches clients entre les bases marketing, commerciales et support.
- Unifier les fiches produits qui existent sous des noms ou références un peu différents.
- Relier les fournisseurs qui ont été saisis plusieurs fois avec des petites variations.
La correspondance de données, ce n’est pas juste trouver des correspondances parfaites. Ça repose sur des règles et des comparaisons intelligentes pour repérer les ressemblances, même avec des fautes de frappe, des surnoms ou des formats différents. Par exemple, « Jon Smith » et « Jonathan Smith » ou « 555-123-9988 » et « (555) 123-9988 » seront reconnus comme identiques grâce à la correspondance de données ().
Le but ? Avoir une vue unique et consolidée de chaque client, produit ou fournisseur—fini les infos éparpillées et les doublons.
Pourquoi la correspondance de données est-elle vitale pour les entreprises ?
Des données propres et unifiées, ce n’est pas juste un bonus : c’est la base pour bosser efficacement et prendre de bonnes décisions. Voilà pourquoi la correspondance de données, c’est précieux :
- Gagner du temps et de l’argent : Les doublons, ça fait exploser les coûts marketing, ça multiplie les relances inutiles et ça oblige à faire du ménage à la main. Les données dupliquées peuvent faire baisser le chiffre d’affaires de .
- Meilleure expérience client : Les clients détestent recevoir deux fois le même mail ou être traités comme deux personnes différentes. Plus de si la communication n’est pas personnalisée.
- Analyses fiables : Des données foireuses, ça donne des décisions à côté de la plaque. viennent des doublons ou des mauvais rapprochements.
- Moins de risques réglementaires : Des données incohérentes, c’est la galère pour respecter le RGPD ou l’HIPAA.
Petit aperçu des bénéfices concrets de la correspondance de données :
| Cas d’usage / Scénario | Comment la correspondance de données aide |
|---|---|
| Déduplication de leads (Ventes) | Fusionne les prospects en double pour éviter que les commerciaux ne contactent la même personne deux fois. |
| Unification des profils clients | Relie les fiches clients entre systèmes pour une vue à 360°, favorisant la personnalisation et le service. |
| Nettoyage des données produits | Regroupe les fiches produits en double pour garantir des stocks et des prix cohérents. |
| Rapprochement fournisseurs | Détecte les doublons de fournisseurs ou de factures, évitant les paiements en double et simplifiant l’analyse des achats. |
| Nettoyage des contacts (Marketing) | Standardise et fait matcher les contacts, réduisant les coûts d’emailing et améliorant la délivrabilité. |
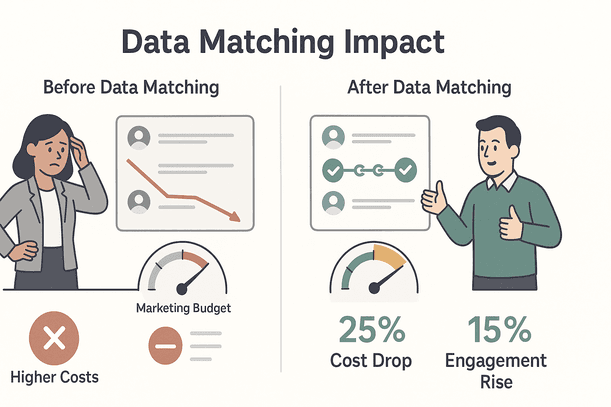
Les boîtes qui misent sur la correspondance de données voient jusqu’à 25 % d’économies sur le marketing et une hausse de 15 % de l’engagement client (). Ce n’est pas juste un truc de data—tout le monde y gagne.
Comment ça marche, la correspondance de données ? Les bases et les techniques
Voilà comment ça se passe concrètement :
- Préparation des données : On nettoie et on standardise (corriger les fautes, harmoniser les formats de dates ou de numéros, etc.) ().
- Définition des critères de matching : On choisit les champs à comparer (nom, email, téléphone…). Certains sont uniques, d’autres demandent une comparaison « floue ».
- Comparaison et scoring : On utilise des algos pour comparer les enregistrements et donner un score de ressemblance (ex : « Jonathan Smith » vs « Johnathan Smithe » = 0,92/1).
- Règles de décision : On fixe des seuils—au-dessus de 90 %, c’est un match ; en dessous de 50 %, c’est non ; entre les deux, on vérifie à la main.
- Regroupement et fusion : On relie ou fusionne les enregistrements trouvés pour avoir une fiche unique.
Matching flou et autres méthodes malines
Les données réelles sont rarement parfaites, d’où l’intérêt de techniques avancées :
- Matching flou : Repère les correspondances proches malgré les fautes ou variantes d’orthographe (« Jon Smyth » et « John Smith ») ().
- Matching phonétique : Associe les mots qui se prononcent pareil (« Katherine » et « Catherine »).
- Matching par motif/regex : Reconnaît les formats standards (ex : numéros de téléphone).
- Empreinte digitale des données : Crée une « signature » numérique pour chaque fiche, pour repérer les doublons (« 123 Main St. Apt 5 » et « 123 Main Street Apartment #5 »).
- Matching boosté par l’IA : L’IA apprend des exemples et s’améliore avec le temps, pour détecter des correspondances complexes que les règles classiques loupent ().
Les meilleurs outils mixent ces approches pour une précision au top.
Exemples concrets de correspondance de données en entreprise
La correspondance de données, ce n’est pas que pour l’IT : ça touche plein de métiers :
- Intégration des données clients : Fusionner les fiches du site, de l’appli et des magasins pour une vision unique. Un distributeur a réduit de 40 % ses doublons et augmenté de 15 % l’engagement email ().
- Déduplication des leads commerciaux : Nettoyer les prospects de plusieurs sources pour éviter que les commerciaux ne contactent deux fois la même personne. Les meilleurs gardent un taux de doublons sous 1 % ().
- Nettoyage des listes marketing : Supprimer les doublons dans les listes d’emails pour éviter les envois en double et booster les campagnes.
- Gestion des catalogues e-commerce : Unifier les fiches produits pour éviter les erreurs de stock et garantir des rapports fiables.
- Rapprochement financier : Associer fournisseurs et factures pour éviter les paiements en double—les PME risquent plus de 12 000 $ de surcoûts à cause des doublons ().
- Matching des dossiers patients (santé) : Sécuriser les soins en associant les dossiers entre établissements—les hôpitaux constatent environ 10 % de doublons dans les dossiers patients ().
Peu importe ton secteur, si tu as plusieurs sources de données, la correspondance de données est incontournable.
Comment la correspondance de données booste la prise de décision
Tu connais sûrement le fameux « garbage in, garbage out ». Si tes rapports sont basés sur des données bancales et pleines de doublons, tes décisions seront à côté de la plaque. La correspondance de données change la donne :
- Analyses fiables : Sans doublons, tes rapports sont justes. Fini de croire que tu as 100 000 clients alors qu’il n’y en a que 80 000.
- Meilleure stratégie : Des données consolidées révèlent les vraies tendances, pour investir là où ça compte.
- Décisions plus rapides : Des données propres permettent de réagir vite—repérer un produit qui cartonne ou un client à risque.
- Vision client complète : Tu comprends chaque client dans sa globalité, pour mieux segmenter et vendre.
- Suivi précis des KPIs : Les équipes sont évaluées sur des chiffres réels, pas gonflés par les doublons.
Les boîtes qui misent sur la correspondance de données voient jusqu’à 15 % d’augmentation du ROI des campagnes et des décisions plus sûres ().
Les limites des outils classiques de correspondance de données
Si la correspondance de données est si utile, pourquoi tout le monde ne le fait pas nickel ? Les outils classiques ont pas mal de défauts :
- Beaucoup de manuel : Les méthodes à l’ancienne (Excel, scripts maison) sont lentes et galèrent à passer à l’échelle. Les équipes data passent à nettoyer et rapprocher les données.
- Règles compliquées à régler : Les vieux outils demandent plein de réglages techniques et d’entretien.
- Rigides et sources d’erreurs : Ils plantent dès que les formats changent ou qu’une nouvelle source arrive.
- Pas faits pour les gros volumes ou les données non structurées : Excel sature vite, et les vieux outils rament avec des données complexes.
- Traitement par lots uniquement : Les doublons s’accumulent entre deux nettoyages—pas de matching en temps réel.
- Pas user-friendly : La plupart sont pensés pour l’IT, pas pour les équipes métiers.
Pas étonnant que galèrent avec les doublons.
L’IA révolutionne la correspondance de données : plus malin, plus rapide, plus fiable
L’IA change la donne. Les outils modernes de correspondance de données s’appuient sur le machine learning et le traitement du langage naturel pour automatiser les tâches reloues :
- Automatisation des tâches répétitives : L’IA peut réduire les doublons de 30 à 40 % en quelques mois ().
- Gestion des données complexes : L’IA repère les motifs et le contexte, détectant des correspondances que les règles classiques loupent.
- Scalabilité : L’IA traite des millions d’enregistrements en quelques minutes.
- Amélioration continue : Les modèles s’affinent au fil des données et des retours utilisateurs.
- Traitement en temps réel : Beaucoup d’outils IA font le matching à la volée, pas juste en lots.
Par exemple, montre que l’IA peut rapprocher « John Smith » et « Jonathan S. Smith » en quelques minutes, là où il fallait des jours avant.
Thunderbit : la correspondance de données pour tous
Chez Thunderbit, notre mission c’est de rendre la correspondance de données simple pour tout le monde, pas juste pour les ingénieurs data. Voilà comment t’aide à avoir des données propres et associées en quelques clics :
- Suggestion de champs par IA : Ouvre une page web, clique sur « Suggestion IA » et Thunderbit repère les colonnes clés à extraire (Nom, Société, Email, etc.), pour des données homogènes ().
- Extraction de sous-pages et pagination : Thunderbit visite automatiquement les sous-pages (profils détaillés, etc.) et fusionne les infos dans ton tableau principal—fini les oublis ou les jointures à la main ().
- Reconnaissance et standardisation IA : Thunderbit détecte les types de données (dates, numéros…) et les standardise direct, même en multilingue ().
- Interface en langage naturel : Décris juste ce que tu veux, Thunderbit s’occupe du reste ().
- Export en un clic : Exporte tes données propres et associées vers Excel, Google Sheets, Airtable ou Notion—sans frais cachés ().
- Modèles pour les sites populaires : Thunderbit propose des modèles prêts à l’emploi pour Amazon, Zillow, Shopify, etc., pour des données toujours prêtes à matcher.
- Extraction programmée : Planifie des extractions régulières pour garder tes données à jour et synchronisées ().
Mini-guide : Associer tes données avec Thunderbit
- Ouvre l’.
- Va sur la page web cible.
- Clique sur « Suggestion IA » pour que Thunderbit propose les colonnes à extraire.
- Clique sur « Extraire »—Thunderbit collecte, standardise et associe les données (même sur les sous-pages).
- Exporte tes données propres et dédupliquées vers l’outil de ton choix.
C’est vraiment aussi simple que ça. Pour voir Thunderbit en action, check notre .
Comment choisir le bon outil de correspondance de données ?
Voici les critères à regarder pour choisir ton outil :
| Critère | Ce qu’il faut regarder |
|---|---|
| Facilité d’utilisation | Interface intuitive, commandes en langage naturel, pas de code compliqué. |
| Intégration | Import/export vers Excel, Google Sheets, CRM et autres outils déjà utilisés. |
| Scalabilité | Capacité à gérer aussi bien de petites listes que des millions d’enregistrements. |
| Fonctions IA | Matching flou, suggestions IA, apprentissage par retour utilisateur. |
| Nettoyage des données | Standardisation, validation et enrichissement intégrés. |
| Personnalisation | Possibilité d’ajuster les règles et seuils de matching. |
| Auditabilité & conformité | Historique, annulation/restauration, respect de la vie privée. |
| Support & communauté | Documentation claire, onboarding, support réactif. |
Thunderbit coche toutes les cases—parfait pour les non-techs qui veulent aller vite.
Même avec les meilleurs outils, la correspondance de données a ses défis. Voilà comment les gérer :
- Formats de données incohérents : Standardise les champs (dates, numéros…) avant le matching. Thunderbit le fait direct.
- Données manquantes : Utilise le matching multi-champs et enrichis les infos quand tu peux.
- Faux positifs/négatifs : Ajuste les seuils de matching et valide à la main les cas limites.
- Multiples systèmes sources : Prends un outil qui sait matcher entre systèmes ou adopte une gestion de données de référence.
- Respect de la vie privée : Anonymise les données lors du matching, garde des traces et respecte les règles de confidentialité.
- Maintenir la qualité dans le temps : Programme des matchings réguliers et encourage les bonnes pratiques data dans tes équipes.
À retenir : pourquoi la correspondance de données est incontournable aujourd’hui
- La correspondance de données crée une source unique de vérité—fini les doublons et les fiches éparpillées.
- Des données propres, c’est la clé de la perf : meilleur ROI, clients contents, décisions plus sûres.
- Les méthodes manuelles ne suffisent plus avec le volume et la complexité—les outils IA comme Thunderbit sont l’avenir.
- Thunderbit rend la correspondance de données accessible à tous, avec suggestions IA, matching sur sous-pages et exports simplifiés.
- Investir dans la correspondance de données, c’est prendre l’avantage—transforme tes données en vrai atout.
Envie de voir l’impact de données propres et associées sur ton business ? ou découvre d’autres guides sur le .
FAQ
1. C’est quoi la correspondance de données, en deux mots ?
C’est le fait d’identifier et de relier des enregistrements qui parlent de la même entité (client, produit…) dans différentes bases, même si les infos ne sont pas identiques.
2. Pourquoi la correspondance de données est-elle importante pour les entreprises ?
Elle permet d’éliminer les doublons, d’unifier les profils clients, d’améliorer les analyses et de réduire les efforts inutiles—pour de meilleures décisions et des clients plus satisfaits.
3. Comment l’IA facilite la correspondance de données ?
L’IA automatise les tâches reloues, gère les données complexes et améliore la précision en apprenant des exemples—pour un matching plus rapide et plus fiable.
4. Qu’est-ce qui différencie Thunderbit des autres outils de correspondance de données ?
Thunderbit utilise l’IA pour suggérer les champs, standardiser les données et faire le matching, même sur les sous-pages. Il est pensé pour les non-techs et s’intègre aux outils métiers classiques.
5. Comment lancer la correspondance de données dans mon équipe ?
Commence par repérer tes sources de données clés, utilise un outil comme Thunderbit pour extraire et standardiser tes données, puis programme des matchings réguliers pour garder des bases propres et unifiées. Plus d’astuces sur le .