En 2026, le monde pro ressemble à un immense buffet de données où tout le monde veut sa part. Que tu bosses en vente, en opérations, en marketing ou sur le produit, la pression pour collecter, analyser et exploiter les données n’a jamais été aussi forte. Je le vois tous les jours : les équipes galèrent avec des copier-coller à la main, des fichiers Excel qui traînent partout et des liens de sondages qui circulent dans tous les sens. Mais le vrai souci, c’est que 80 % des données mondiales sont maintenant non structurées – et ce chiffre ne fait qu’augmenter (). Sans un bon logiciel de collecte de données, non seulement tu prends du retard, mais tu passes aussi à côté de décisions plus malines, de process plus rapides et, surtout, de beaucoup moins de stress.

Après des années dans le SaaS et l’automatisation, j’ai vu comment le bon outil peut transformer un vrai cauchemar de données en avantage concurrentiel. Mais avec toutes les options – extracteurs web IA, plateformes de sondage, formulaires interactifs – comment choisir le bon logiciel pour ton équipe ? Voici mon guide. Découvre les 6 meilleurs logiciels de collecte de données à adopter en 2026, chacun avec ses points forts, ses particularités et ses cas d’usage préférés. Que tu veuilles extraire des leads du web, mener des enquêtes poussées ou juste récolter des retours rapidement, cette sélection t’aidera à trouver chaussure à ton pied.
Pourquoi le choix du bon logiciel de collecte de données est crucial
Soyons clairs : la collecte de données, c’est la base de toute boîte moderne. Le bon logiciel, ce n’est pas juste un gadget – c’est la différence entre perdre des heures sur des tâches répétitives et avoir accès direct à des infos exploitables. Selon , 76 % des dirigeants ressentent une pression croissante pour baser leurs décisions sur des données, et les boîtes qui y arrivent sont 23 fois plus susceptibles de gagner de nouveaux clients et 19 fois plus rentables ().
Mais il y a un hic : plus de 60 % des pros de la data trouvent que la collecte est la partie la plus pénible de leur job (). Le bon outil automatise ces tâches, limite les erreurs et permet à ton équipe de se concentrer sur l’essentiel : analyser et agir.
En entreprise, on s’en sert pour :
- Générer des leads : extraire des contacts sur le web, faire des listes de prospects.
- Études de marché : lancer des sondages, analyser le ressenti client.
- Feedback client : récolter du NPS, CSAT ou des avis produits.
- Veille concurrentielle : suivre les prix, les stocks ou les tendances.
- Automatiser les workflows : alimenter automatiquement le CRM, les dashboards ou les outils d’analyse.
En bref : choisir le bon logiciel de collecte de données, c’est aligner tes besoins (structuré ou non, sondage ou extraction web, analyses simples ou avancées) avec l’outil le plus adapté.
Notre méthode de sélection des meilleurs logiciels de collecte de données
Je n’ai pas choisi ces outils au hasard. Mes critères :
- Facilité d’utilisation : Est-ce que même les non-tech peuvent s’y mettre vite ? Y a-t-il de l’IA ou du drag & drop ?
- Fonctionnalités : Est-ce que ça gère ton type de données (web, sondage, fichiers…) ? Est-ce que ça propose de la logique, de la planification, de l’automatisation ?
- Analytique : Rapports intégrés, dashboards, options d’export ?
- Intégrations : Peut-on envoyer les données vers Sheets, CRM ou d’autres applis ?
- Tarifs : Y a-t-il une version gratuite ? Est-ce adapté aux équipes ou aux grosses boîtes ?
- Points forts uniques : Qu’est-ce qui le rend spécial – IA, analyses poussées, expérience utilisateur ?
J’ai aussi regardé les avis utilisateurs, les retours d’experts et des cas concrets. Chaque outil a son domaine de prédilection, à toi de choisir celui qui colle à tes besoins.
Les 6 meilleurs logiciels de collecte de données
- pour l’extraction web automatisée par IA
- pour les enquêtes et analyses avancées en entreprise
- pour des formulaires en ligne flexibles et abordables
- pour une collecte rapide, gratuite et simple
- pour des sondages puissants avec reporting et intégrations
- pour des formulaires interactifs et engageants
1. Thunderbit
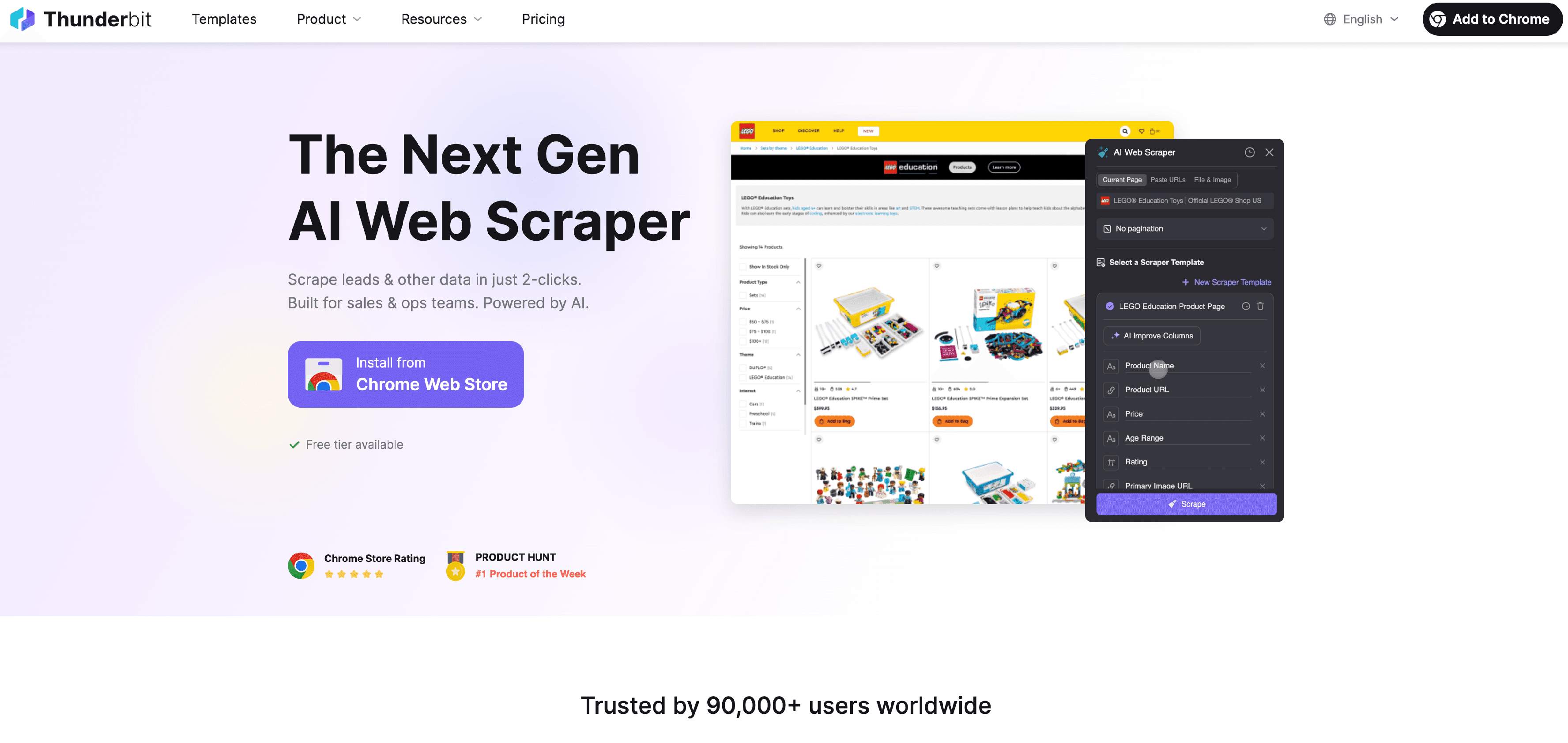
est mon chouchou pour la collecte de données web – et pas juste parce que j’ai bossé dessus. C’est le seul de cette liste à mixer extraction web par IA et interface no-code pensée pour les pros. Si tu as déjà perdu des heures à copier-coller des infos de sites, Thunderbit va vite devenir ton meilleur pote.
Pourquoi Thunderbit sort du lot
Thunderbit est taillé pour le chaos des données non structurées du web. Les équipes commerciales l’utilisent pour extraire des leads depuis des annuaires, les e-commerçants pour surveiller les produits concurrents, les marketeurs pour collecter des infos produits ou des contacts – tout ça sans écrire une ligne de code. Il suffit d’ouvrir l’, de cliquer sur « AI Suggest Fields » et de laisser l’IA repérer les données de la page. Tu ajustes les colonnes, tu lances l’extraction, et hop : des données structurées, prêtes à être exportées vers Excel, Google Sheets, Airtable ou Notion.
Thunderbit ne s’arrête pas à une seule page. Il gère la pagination (genre, parcourir 20 pages de produits) et l’extraction sur sous-pages (cliquer sur chaque fiche pour choper plus d’infos). Des modèles tout prêts existent pour des sites comme Amazon ou Zillow, pour une collecte en un clic.
Le bonus : l’IA de Thunderbit peut étiqueter, classer et transformer les données en temps réel. Besoin d’extraire des emails, numéros de téléphone ou images ? C’est inclus. Tu veux planifier des extractions ou automatiser le remplissage de formulaires ? Thunderbit gère aussi.
Les atouts de Thunderbit pour les pros
- AI Suggest Fields : Tu décris ce que tu veux, l’IA crée l’extracteur pour toi.
- Extraction sur sous-pages & pagination : Parcours les listes et récupère les détails automatiquement.
- Exportation gratuite : Envoie les données vers Excel, Google Sheets, Airtable, Notion ou télécharge en CSV/JSON – sans frais cachés.
- Extracteurs en un clic : Récupère instantanément emails, numéros ou images sur n’importe quelle page.
- Extraction programmée : Automatise la collecte récurrente (ex : suivi quotidien des prix).
- Extraction cloud ou navigateur : Lance les tâches dans le cloud pour la rapidité, ou dans le navigateur pour les sites qui demandent une connexion.
- Tarifs accessibles : Version gratuite (6 pages), puis 15 $/mois pour 500 crédits (lignes). L’export reste toujours gratuit.
Avis utilisateurs : Un commercial nous a dit que Thunderbit lui a permis de « monter une base de contacts influenceurs en quelques minutes au lieu de payer pour l’avoir » (). Un autre a transformé des heures de recherche manuelle en « opération en deux clics ».
Si tu veux transformer le web en base de données privée – sans code ni prise de tête IT – Thunderbit est un must.
2. Qualtrics
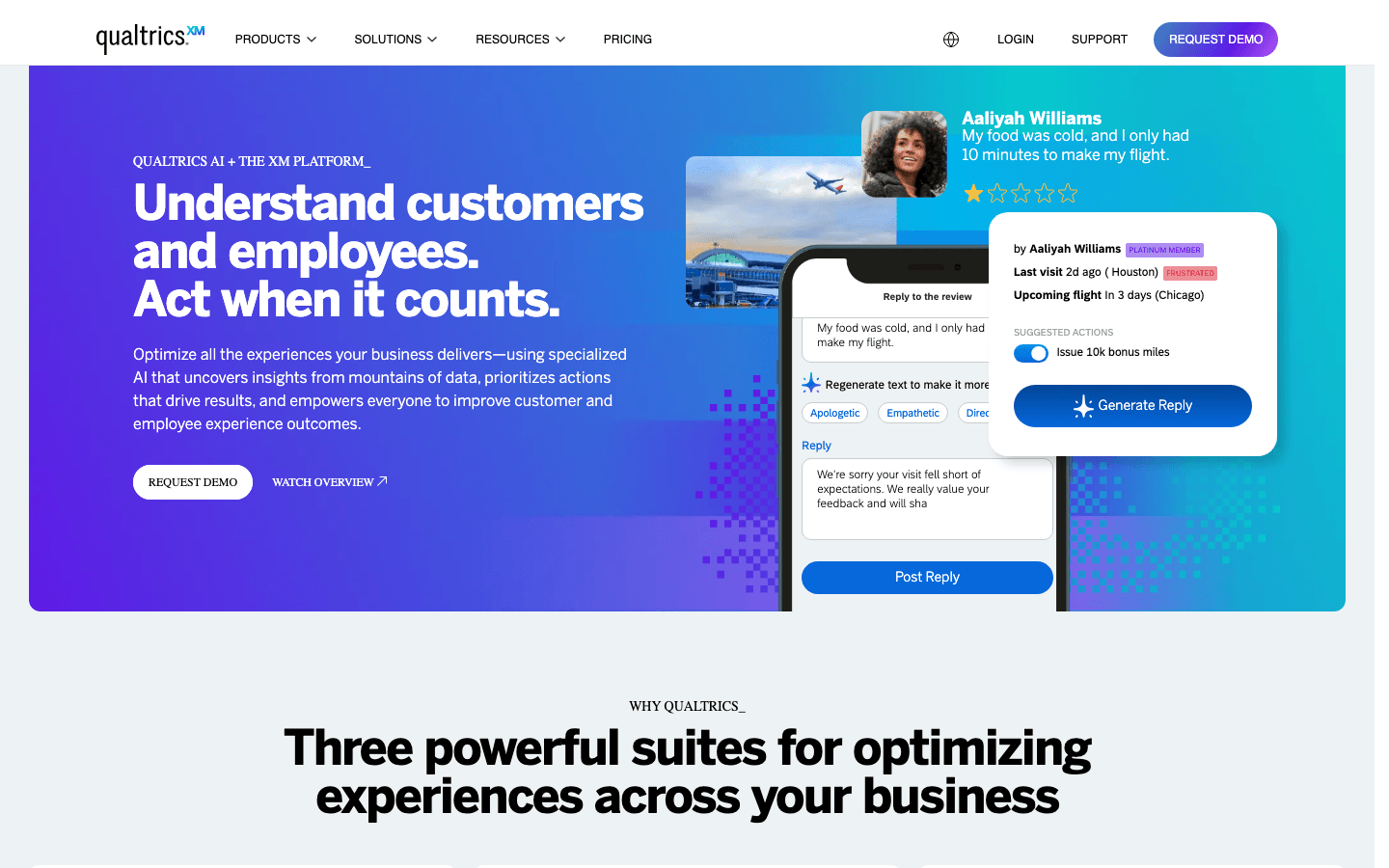
est la référence des plateformes d’enquêtes et d’analyses pour les grandes boîtes. Si ton organisation a besoin d’enquêtes poussées, de rapports avancés et d’analyses de haut niveau, Qualtrics est fait pour toi (à condition d’avoir le budget).
Qualtrics pour l’analyse approfondie des enquêtes
Qualtrics brille par sa logique d’enquête complexe, sa diffusion multicanale et ses analyses puissantes. Tu crées des questionnaires avec branchements avancés, randomisation, validation. Tu les diffuses par email, web, mobile ou SMS. Les résultats arrivent en temps réel, avec dashboards, segmentation, analyses statistiques et même analyse de texte par IA.
C’est l’outil parfait pour :
- Programmes d’engagement des employés
- Satisfaction client (NPS, CSAT)
- Études de marché
- Recherche académique
Qualtrics s’intègre à Salesforce, Tableau et d’autres outils d’entreprise. Sécurité et conformité sont au top. Attention : la prise en main demande du temps, et les tarifs commencent à 420 $/mois pour les petites structures, avec des contrats entreprise qui peuvent grimper très haut ().
Si tu dois analyser et visualiser des données à grande échelle – et que tu as le budget – Qualtrics est la référence.
3. Zoho Forms
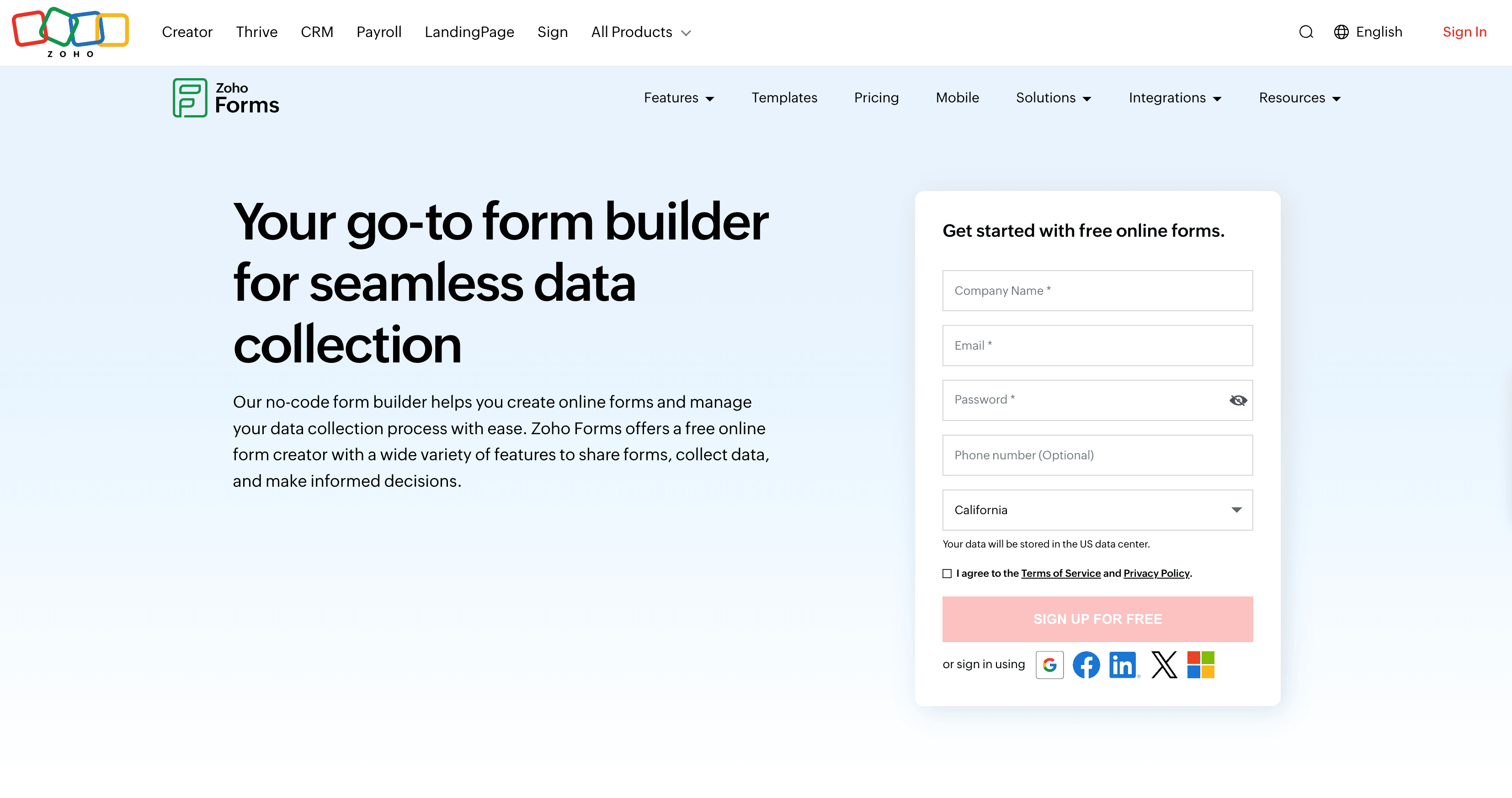
est le couteau suisse des petites équipes et des boîtes qui font attention à leur budget. Un générateur de formulaires en ligne simple à prendre en main, mais super complet.
Zoho Forms en pratique
Zoho Forms est top pour :
- Capture de leads (intégration directe avec Zoho CRM)
- Inscriptions à des événements
- Collecte de feedback client
- Demandes et validations internes
Plus de 30 types de champs (fichiers, signatures…), logique conditionnelle, thèmes personnalisables, support mobile et hors-ligne. Si tu utilises déjà les applis Zoho, l’intégration est fluide. Sinon, Zoho Forms se connecte aussi à Google Sheets, Slack, etc. via Zapier.
Côté tarifs : version gratuite (1 utilisateur, 5 formulaires), puis à partir de 12 $/mois pour 1 utilisateur et 10 000 soumissions. Les forfaits supérieurs ajoutent des utilisateurs et des fonctionnalités, mais même l’offre à 25 $/mois couvre la plupart des besoins des petites équipes ().
Petit bémol : l’analytique reste basique, et l’outil est surtout intéressant si tu es déjà dans l’écosystème Zoho. Mais pour les PME qui veulent mieux que Google Forms sans la complexité de Qualtrics, Zoho Forms est un super choix.
4. Google Forms
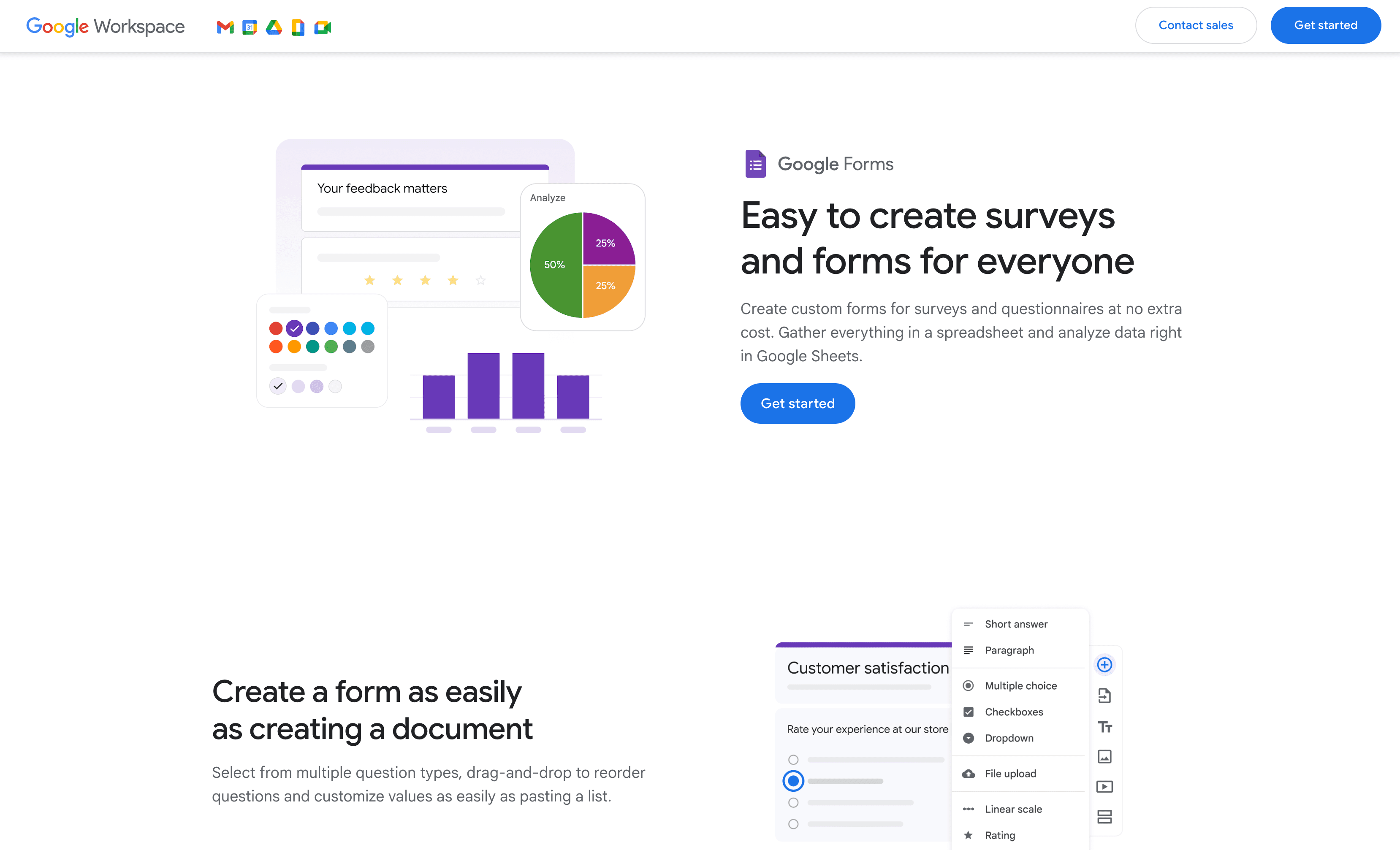
est l’outil incontournable pour collecter des données vite fait, bien fait et gratuitement. Besoin d’un sondage, d’un formulaire d’inscription ou de feedback en cinq minutes – sans rien dépenser ? Google Forms est la solution.
Google Forms pour une collecte rapide et simple
Ses points forts :
- Formulaires et réponses illimités, gratuitement ()
- Collaboration en temps réel (plusieurs personnes peuvent créer un formulaire ensemble)
- Export automatique vers Google Sheets pour l’analyse instantanée
- Logique de saut basique et quelques types de questions
Idéal pour les sondages internes, inscriptions à des événements, quiz éducatifs ou retours clients simples. L’interface est ultra-intuitive et s’intègre parfaitement à Google Workspace.
Limites : personnalisation minimale, analytique basique, et pour les intégrations hors Google, il faut passer par Zapier ou des modules complémentaires. Mais pour un déploiement immédiat et sans frais, difficile de faire mieux.
5. SurveyMonkey
est la référence pour les sondages en ligne, et ce n’est pas pour rien. Il offre un super compromis entre puissance et simplicité, parfait pour les équipes qui veulent des fonctionnalités avancées sans la complexité des outils d’entreprise.
Les atouts de SurveyMonkey en reporting et intégration
SurveyMonkey se démarque par :
- Plus de 15 types de questions (NPS, classement, matrice, etc.)
- Logique de saut, branchements, piping
- Analytique en temps réel et rapports personnalisés
- Plus de 200 intégrations (Salesforce, HubSpot, Slack, Tableau…)
Envoie tes sondages par email, suis les répondants, automatise les relances. Le dashboard est intuitif, tu peux filtrer, segmenter et partager les résultats en quelques clics. SurveyMonkey gère aussi la collaboration en équipe et la sécurité niveau entreprise.
Tarifs : plan gratuit (10 questions, 25 réponses par sondage), puis 25–39 $/mois pour des limites supérieures (). Pour la plupart des besoins pros, SurveyMonkey est le choix « juste ce qu’il faut ».
6. Typeform
est la star des formulaires interactifs – si l’expérience utilisateur compte pour toi et que tu veux des formulaires qui ressemblent plus à une conversation qu’à un interrogatoire, Typeform est fait pour toi.
Typeform pour des enquêtes engageantes
La force de Typeform, c’est son interface question par question, qui fait penser à un chat et permet d’atteindre 30 à 40 % de taux de complétion en plus (). Ajoute images, GIFs, vidéos, branding personnalisé. Les logiques conditionnelles personnalisent le parcours, et les intégrations (Google Sheets, HubSpot, Slack…) facilitent l’automatisation.
Idéal pour :
- Quiz de génération de leads
- Feedback client
- Sondages marketing
- Inscriptions à des événements
Le plan gratuit est très limité (10 réponses/mois), mais les offres payantes démarrent à 25 $/mois pour 100 réponses. Si tu veux que la collecte de données soit aussi un atout pour ton image de marque, Typeform vaut largement l’investissement.
Tableau comparatif des logiciels de collecte de données
Voici un aperçu pour comparer rapidement :
| Outil | Idéal pour | Fonctionnalités clés | Prix de départ | Facilité d’utilisation | Analytique/Reporting | Intégrations | Points forts uniques |
|---|---|---|---|---|---|---|---|
| Thunderbit | Extraction web, ventes, ops, e-commerce | Extraction web IA, sous-pages/pagination, export instantané | Gratuit (6 pages), 15 $/mois | Très facile, sans code | Pas d’analytique intégré, export uniquement | Sheets, Excel, Notion, API | IA, gère les données web non structurées |
| Qualtrics | Enquêtes entreprise, analyses poussées | Logique complexe, dashboards, segmentation, multicanal | 420 $/mois+ | Courbe d’apprentissage | Avancé, temps réel | Salesforce, Tableau, API | Analytique puissante, niveau entreprise |
| Zoho Forms | PME, équipes à budget limité, utilisateurs Zoho | Builder drag-drop, logique, validations, mobile/hors-ligne | Gratuit, 12 $/mois+ | Facile, apprentissage léger | Basique, export Zoho | Suite Zoho, Sheets, Zapier | Abordable, automatisation des workflows |
| Google Forms | Formulaires/sondages simples et gratuits | Formulaires illimités, export Sheets, logique basique | Gratuit | Ultra simple | Basique, export Sheets | Google Workspace, add-ons | Gratuit & illimité, déploiement instantané |
| SurveyMonkey | Sondages pros, reporting | Modèles, logique, analytique temps réel, 200+ intégrations | Gratuit, 25–39 $/mois+ | Intuitif, complet | Solide, rapports personnalisés | Salesforce, Slack, Tableau | Puissant & simple, marque reconnue |
| Typeform | Formulaires/sondages interactifs | UX conversationnelle, logiques, médias riches, branding | Gratuit (10 rép.), 25 $/mois | Moderne, soigné | Statistiques complétion/abandon | Sheets, HubSpot, Slack, API | UX inégalée, booste le taux de réponse |
Comment choisir le bon logiciel de collecte de données ?
Petit pense-bête :
-
Tu dois extraire des données web (leads, infos produits, veille concurrentielle) ?
Prends . Seul extracteur web IA de la liste, il est parfait pour les données non structurées et l’automatisation des recherches répétitives. -
Tu lances des enquêtes complexes à grande échelle avec analyses avancées ?
est la référence – si tu as le budget et besoin d’analyses de niveau entreprise. -
Budget serré ou déjà utilisateur Zoho ?
propose des formulaires puissants, de la logique et de l’automatisation à prix mini. -
Besoin d’un formulaire simple et gratuit ?
est imbattable en rapidité et simplicité. -
Tu veux des sondages robustes avec reporting et intégrations ?
allie puissance et simplicité, avec modèles et analyses pour la plupart des besoins pros. -
L’expérience utilisateur et l’engagement sont tes priorités ?
propose des formulaires interactifs qui boostent le taux de réponse et valorisent ta marque.
Astuce : Profite des essais gratuits, teste avec tes vrais cas d’usage et demande l’avis de ton équipe. Parfois, le meilleur outil, c’est juste celui que tout le monde adopte !
Conclusion : trouve le logiciel de collecte de données fait pour toi
La donnée, c’est le carburant de la croissance en 2026, à condition de bien la collecter et de l’exploiter. Que tu extraies des leads du web, mènes des enquêtes d’envergure ou aies juste besoin d’un formulaire de feedback, il existe un outil adapté à tes besoins – et à ton budget.
Thunderbit démocratise la collecte web par IA, Qualtrics brille en analytique, Zoho Forms est le champion des PME, Google Forms reste la référence gratuite, SurveyMonkey est le couteau suisse, et Typeform le roi de l’engagement.
Fais le point sur tes besoins, teste plusieurs solutions, et rappelle-toi : le bon logiciel ne fait pas que collecter des données – il révèle des insights, fait gagner du temps et donne un vrai avantage à ton équipe.
FAQ
1. Quelle est la principale différence entre Thunderbit et les outils de sondage classiques ?
Thunderbit est pensé pour extraire et structurer les données non structurées du web (listings produits, contacts, veille concurrentielle) grâce à l’IA, alors que les outils de sondage comme Qualtrics ou SurveyMonkey servent à collecter des réponses via des formulaires et enquêtes.
2. Google Forms est-il vraiment gratuit et illimité ?
Oui ! Google Forms permet de créer autant de formulaires que tu veux et de collecter un nombre illimité de réponses, sans frais. Parfait pour la collecte de données basique et les sondages rapides.
3. Quand choisir Qualtrics plutôt que SurveyMonkey ?
Choisis Qualtrics si tu as besoin d’analyses avancées, de logique complexe et d’intégrations d’entreprise – surtout pour des programmes RH ou expérience client à grande échelle. SurveyMonkey est mieux pour la plupart des PME ou équipes qui veulent des fonctionnalités puissantes sans la complexité (ni le prix) de l’entreprise.
4. Peut-on utiliser plusieurs outils de collecte de données en même temps ?
Bien sûr. Beaucoup d’équipes combinent Thunderbit pour l’extraction web, Typeform pour la génération de leads et Google Forms pour les sondages internes. L’important, c’est d’avoir un plan pour centraliser et analyser tes données.
5. Comment savoir quel logiciel de collecte de données est fait pour mon équipe ?
Commence par définir ton usage principal (extraction web, sondages, formulaires), les fonctionnalités requises (analytique, intégrations, branding) et ton budget. Teste plusieurs outils avec de vraies données, demande l’avis de ton équipe et choisis celui qui s’intègre le mieux à ta façon de bosser.
Envie de voir Thunderbit en action ? et teste gratuitement l’extraction de ton premier site. Pour plus d’astuces et d’analyses sur l’automatisation des données, va faire un tour sur le . Bonne collecte !
Pour aller plus loin