Le web en 2025 est un drôle d’endroit — la moitié du trafic que vous voyez n’est même pas humain. C’est exact : les bots et les crawlers représentent désormais plus de 50 % de l’activité Internet (), et seule une petite partie correspond aux « bons » bots que vous souhaitez : moteurs de recherche, prévisualiseurs des réseaux sociaux et assistants d’analyse. Le reste ? Disons simplement qu’ils ne sont pas toujours là pour aider. Après des années à concevoir des outils d’automatisation et d’IA chez , j’ai pu voir de près à quel point un crawler — le bon comme le mauvais — peut faire ou défaire votre SEO, fausser vos analyses, consommer votre bande passante, voire déclencher un véritable incident de sécurité.
Si vous dirigez une entreprise, gérez un site web ou essayez simplement de garder votre environnement numérique en ordre, savoir qui frappe à la porte de votre serveur est plus important que jamais. C’est pourquoi j’ai préparé ce guide 2025 des crawlers les plus importants : ce qu’ils font, comment les repérer et comment garder votre site ouvert aux bons bots tout en tenant les mauvais à distance.
Qu’est-ce qui fait d’un crawler un « crawler connu » ? User-Agent, IP et vérification
Commençons par les bases : qu’est-ce qu’un « crawler connu » exactement ? Au sens le plus simple, c’est un bot qui s’identifie avec une chaîne user-agent cohérente (comme Googlebot/2.1 ou bingbot/2.0) et qui, idéalement, parcourt le web depuis des plages d’adresses IP ou des blocs ASN publiés que vous pouvez vérifier (). Les grands acteurs — Google, Microsoft, Baidu, Yandex, DuckDuckGo — publient une documentation sur leurs bots et, dans de nombreux cas, fournissent des outils ou des fichiers JSON listant leurs IP officielles (, , ).
Mais voici le piège : se fier uniquement au user-agent est risqué. L’usurpation est monnaie courante — des bots malveillants se font souvent passer pour Googlebot ou Bingbot afin de contourner vos défenses (). C’est pourquoi la référence absolue est la double vérification : contrôler à la fois le user-agent et l’adresse IP (ou l’ASN), à l’aide de recherches DNS inversées ou de listes publiées. Si vous utilisez un outil comme , vous pouvez automatiser ce processus — extraire les journaux, faire correspondre les user-agents et recouper les IP pour constituer une liste fiable et en temps réel de ce qui explore votre site.
Comment utiliser cette liste de crawlers
Alors, que faire concrètement avec une liste de crawlers connus ? Voici comment je vous recommande de l’exploiter :
- Liste d’autorisation : assurez-vous que les bots que vous souhaitez autoriser (moteurs de recherche, prévisualiseurs de réseaux sociaux) ne soient jamais bloqués par erreur par votre pare-feu, votre CDN ou votre WAF. Utilisez leurs IP et user-agents officiels pour une liste d’autorisation précise.
- Filtrage analytique : filtrez le trafic des bots dans vos analyses afin que vos chiffres reflètent de vrais visiteurs humains — et non pas seulement Googlebot et AhrefsBot en train de faire des tours sur votre site ().
- Gestion des bots : définissez des règles de crawl-delay ou de limitation pour les outils SEO agressifs, et bloquez ou challengez les bots inconnus ou malveillants.
- Analyse automatisée des journaux : utilisez des outils d’IA (comme Thunderbit) pour extraire, classer et étiqueter l’activité des crawlers dans vos journaux, afin de repérer les tendances, identifier les imposteurs et tenir vos règles à jour.
Garder votre liste de crawlers à jour n’est pas une tâche de type « on configure et on oublie ». De nouveaux bots apparaissent, d’anciens changent de comportement, et les attaquants deviennent plus rusés chaque année. Automatiser les mises à jour — en extrayant la documentation officielle ou des dépôts GitHub avec Thunderbit — peut vous faire gagner des heures et vous épargner bien des tracas.
1. Thunderbit : identification de crawlers et gestion des données propulsées par l’IA
n’est pas qu’un Extracteur Web IA : c’est un assistant de données pour les équipes qui veulent comprendre et gérer le trafic des crawlers. Voici ce qui distingue Thunderbit :

- Prétraitement sémantique : avant d’extraire des données, Thunderbit convertit les pages web et les journaux en contenu structuré de type Markdown. Ce prétraitement sémantique aide réellement l’IA à comprendre le contexte, les champs et la logique de ce qu’elle lit. C’est une vraie bouée de sauvetage pour les pages complexes, dynamiques ou très riches en JavaScript (pensez à Facebook Marketplace ou aux longs fils de commentaires), là où les extracteurs classiques basés sur le DOM échouent.
- Double vérification : Thunderbit peut collecter rapidement les documents officiels sur les IP des crawlers et les listes ASN, puis les comparer à vos journaux serveur. Le résultat ? Une « liste d’autorisation de crawlers de confiance » sur laquelle vous pouvez vraiment compter — fini les vérifications manuelles fastidieuses.
- Extraction automatisée des journaux : fournissez vos journaux bruts à Thunderbit, et il les transformera en tableaux structurés (Excel, Sheets, Airtable), en étiquetant les visiteurs à forte fréquence, les chemins suspects et les bots connus. À partir de là, vous pouvez envoyer les résultats vers votre WAF ou votre CDN pour un blocage, une limitation ou des défis CAPTCHA automatisés.
- Conformité et audit : l’extraction sémantique de Thunderbit conserve une trace d’audit claire — qui a accédé à quoi, quand, et comment cela a été traité. C’est un atout majeur pour le RGPD, le CCPA et d’autres exigences de conformité.
J’ai vu des équipes utiliser Thunderbit pour réduire de 80 % leur charge de travail liée à la gestion des crawlers — et enfin comprendre quels bots aident, lesquels nuisent, et lesquels se contentent d’imiter.
2. Googlebot : la référence des moteurs de recherche
est la référence absolue des crawlers web. Il est responsable de l’indexation de votre site pour Google Search — le bloquer revient presque à afficher un panneau « Fermé » sur votre vitrine numérique.
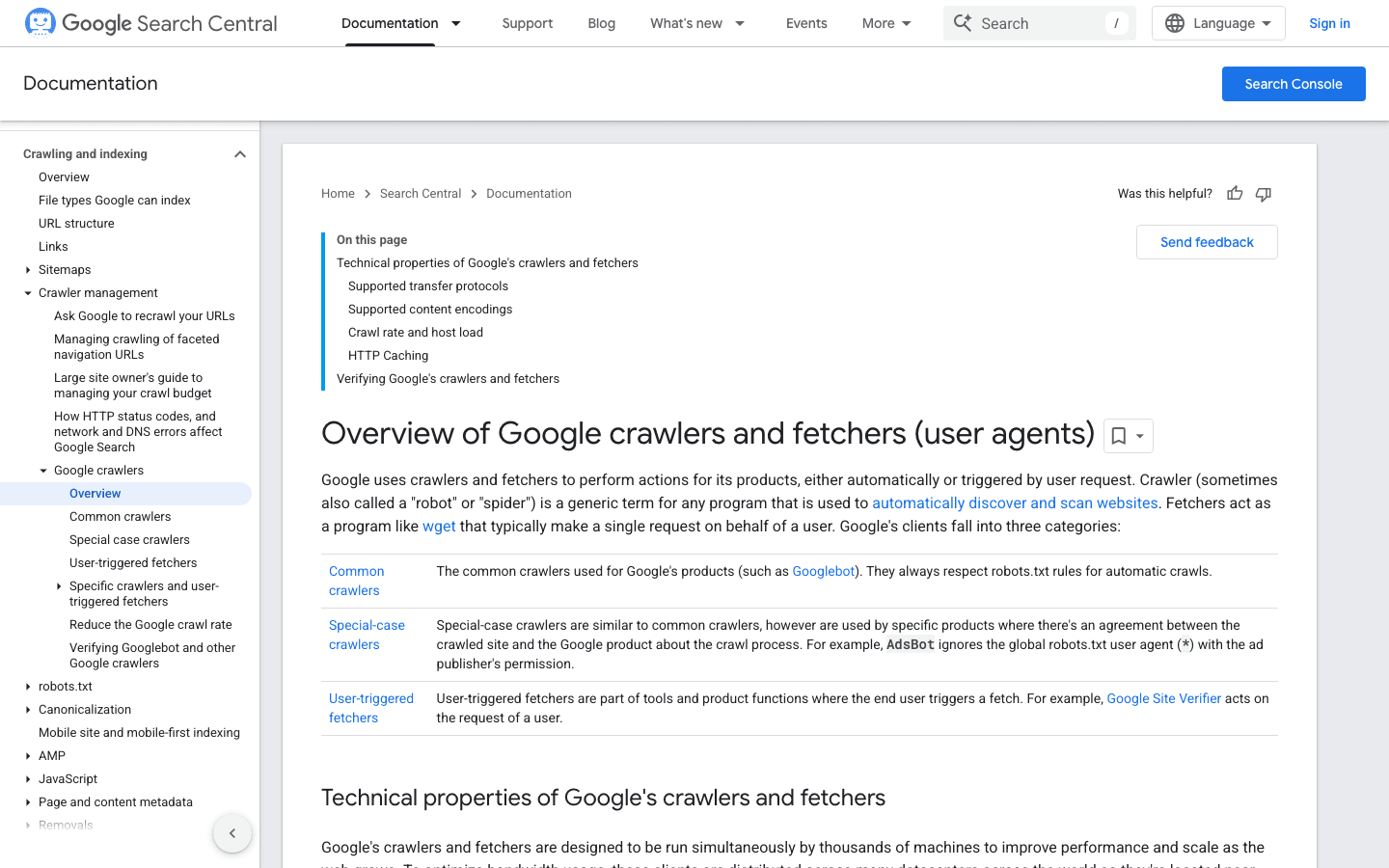
- User-Agent :
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) - Vérification : utilisez la ou la .
- Conseils de gestion : autorisez toujours Googlebot. Utilisez robots.txt pour guider son exploration (sans le bloquer), et ajustez le taux d’exploration dans Google Search Console si nécessaire.
3. Bingbot : l’explorateur web de Microsoft
alimente les résultats de recherche de Bing et Yahoo. C’est le deuxième crawler le plus important pour la plupart des sites.
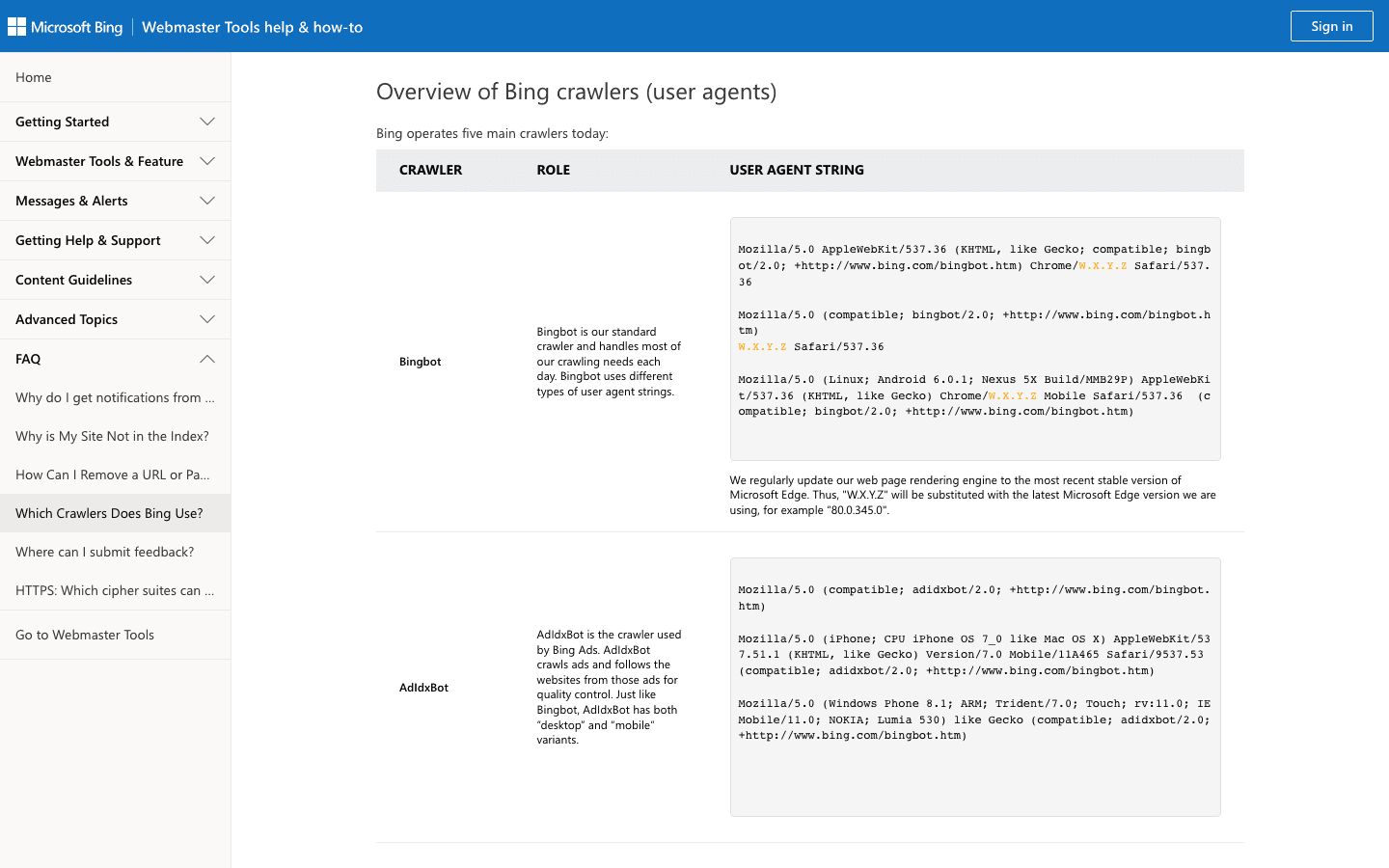
- User-Agent :
Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) - Vérification : utilisez l’ et la .
- Conseils de gestion : autorisez Bingbot, gérez le taux d’exploration dans Bing Webmaster Tools et utilisez robots.txt pour affiner le comportement.
4. Baiduspider : le principal crawler de recherche en Chine
est la porte d’entrée vers le trafic de recherche chinois.
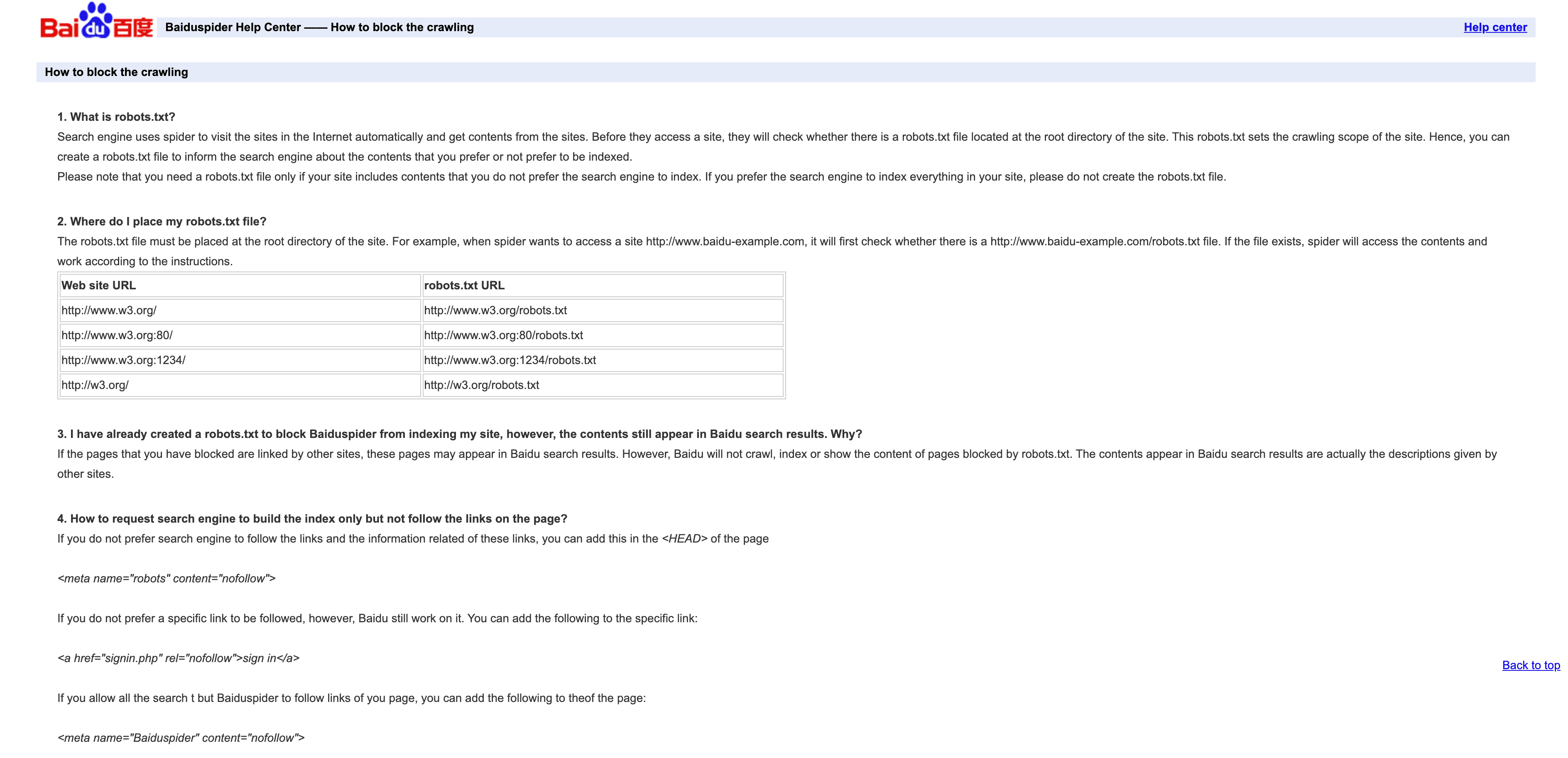
- User-Agent :
Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html) - Vérification : aucune liste d’IP officielle ; vérifiez la présence de
.baidu.comdans le DNS inversé, mais gardez à l’esprit ses limites. - Conseils de gestion : autorisez-le si vous souhaitez du trafic chinois. Utilisez robots.txt pour définir des règles, mais notez que Baiduspider les ignore parfois. Si vous n’avez pas besoin de SEO en Chine, envisagez de limiter ou de bloquer pour économiser de la bande passante.
5. YandexBot : le crawler du moteur de recherche russe
est essentiel pour les marchés russes et de la CEI.
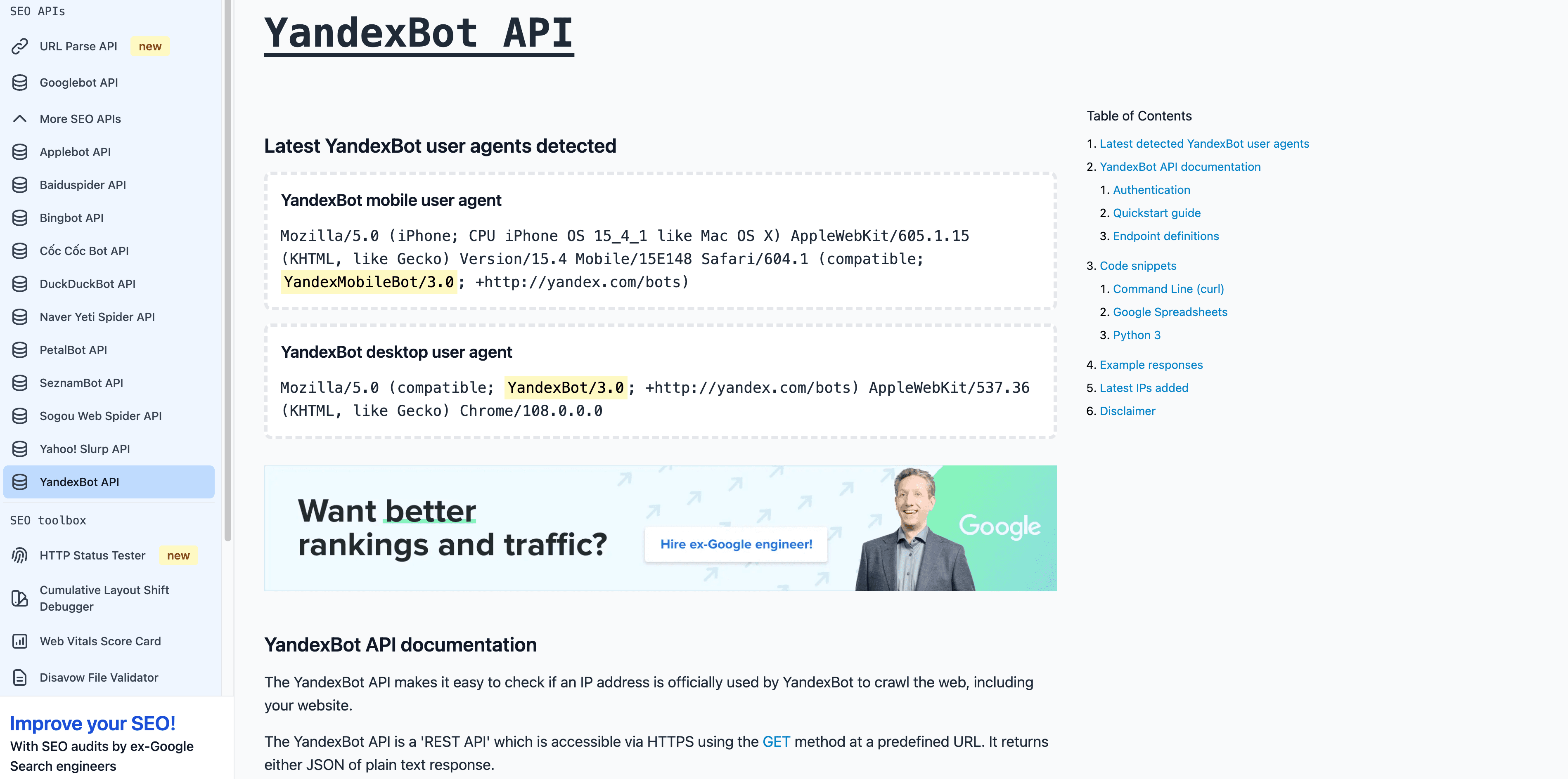
- User-Agent :
Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots) - Vérification : le DNS inversé doit se terminer par
.yandex.ru,.yandex.netou.yandex.com. - Conseils de gestion : autorisez-le si vous ciblez des utilisateurs russophones. Utilisez Yandex Webmaster pour contrôler l’exploration.
6. DuckDuckBot : le crawler de recherche axé sur la confidentialité
alimente la recherche axée sur la confidentialité de DuckDuckGo.
- User-Agent :
DuckDuckBot/1.1; (+http://duckduckgo.com/duckduckbot.html) - Vérification : .
- Conseils de gestion : autorisez-le, sauf si vous n’avez aucun intérêt pour les utilisateurs sensibles à la confidentialité. Charge de crawl faible, facile à gérer.
7. AhrefsBot : analyse SEO et backlinks
est un crawler majeur des outils SEO — très utile pour l’analyse des backlinks, mais il peut être gourmand en bande passante.
- User-Agent :
Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/) - Vérification : aucune liste d’IP publique ; vérifiez via le UA et le DNS inversé.
- Conseils de gestion : autorisez-le si vous utilisez Ahrefs. Utilisez robots.txt pour définir un crawl-delay ou le bloquer. Vous pouvez .
8. SemrushBot : analyses SEO concurrentielles
est un autre crawler SEO majeur.
- User-Agent :
Mozilla/5.0 (compatible; SemrushBot/1.0; +http://www.semrush.com/bot.html)(avec des variantes commeSemrushBot-BA,SemrushBot-SI, etc.) - Vérification : via le user-agent ; aucune liste d’IP publique.
- Conseils de gestion : autorisez-le si vous utilisez Semrush, sinon limitez-le ou bloquez-le avec robots.txt ou des règles serveur.
9. FacebookExternalHit : le bot de prévisualisation des réseaux sociaux
récupère les données Open Graph pour les aperçus de liens sur Facebook et Instagram.
- User-Agent :
facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php) - Vérification : via le user-agent ; les IP appartiennent à l’ASN de Facebook.
- Conseils de gestion : autorisez-le pour de riches aperçus sociaux. Le bloquer signifie l’absence de vignettes ou de résumés sur Facebook/Instagram.
10. Twitterbot : le crawler d’aperçu de liens de X (Twitter)
récupère les données Twitter Card pour X (Twitter).
- User-Agent :
Twitterbot/1.0 - Vérification : via le user-agent ; ASN Twitter (AS13414).
- Conseils de gestion : autorisez-le pour les aperçus Twitter. Utilisez les balises méta Twitter Card pour obtenir les meilleurs résultats.
Tableau comparatif : liste des crawlers en un coup d’œil
| Crawler | Objectif | Exemple de User-Agent | Méthode de vérification | Impact business | Conseils de gestion |
|---|---|---|---|---|---|
| Thunderbit | Analyse IA des journaux/crawlers | N/A (outil, pas un bot) | N/A | Gestion des données, classification des bots | Utiliser pour l’extraction des journaux, la création de listes d’autorisation |
| Googlebot | Indexation pour Google Search | Googlebot/2.1 | DNS et liste d’IP | Essentiel pour le SEO | Toujours autoriser, gérer via Search Console |
| Bingbot | Recherche Bing/Yahoo | bingbot/2.0 | DNS et liste d’IP | Important pour le SEO Bing/Yahoo | Autoriser, gérer via Bing Webmaster Tools |
| Baiduspider | Recherche Baidu (Chine) | Baiduspider/2.0 | DNS inversé, chaîne UA | Clé pour le SEO en Chine | Autoriser si vous ciblez la Chine, surveiller la bande passante |
| YandexBot | Recherche Yandex (Russie) | YandexBot/3.0 | DNS inversé vers .yandex.ru | Clé pour la Russie et l’Europe de l’Est | Autoriser si vous ciblez la Russie/la CEI, utiliser les outils Yandex |
| DuckDuckBot | Recherche DuckDuckGo | DuckDuckBot/1.1 | Liste officielle des IP | Audience soucieuse de la confidentialité | Autoriser, faible impact |
| AhrefsBot | Analyse SEO/backlinks | AhrefsBot/7.0 | Chaîne UA, DNS inversé | Outil SEO, peut consommer beaucoup de bande passante | Autoriser/limiter/bloquer via robots.txt |
| SemrushBot | Analyse SEO/concurrentielle | SemrushBot/1.0 (plus variantes) | Chaîne UA | Outil SEO, peut être agressif | Autoriser/limiter/bloquer via robots.txt |
| FacebookExternalHit | Aperçus des liens sociaux | facebookexternalhit/1.1 | Chaîne UA, ASN Facebook | Engagement sur les réseaux sociaux | Autoriser pour les aperçus, utiliser les balises OG |
| Twitterbot | Aperçus de liens Twitter | Twitterbot/1.0 | Chaîne UA, ASN Twitter | Engagement sur Twitter | Autoriser pour les aperçus, utiliser les balises Twitter Card |
Gérer votre liste de crawlers : bonnes pratiques pour 2025
- Mettez à jour régulièrement : le paysage des crawlers évolue vite. Programmez des revues trimestrielles et utilisez des outils comme Thunderbit pour extraire et comparer les listes officielles ().
- Vérifiez, ne faites pas confiance : contrôlez toujours à la fois le user-agent et l’IP/ASN. Ne laissez pas les imposteurs s’infiltrer et fausser vos analyses ou aspirer vos données ().
- Autorisez les bons bots : assurez-vous que les crawlers de recherche et des réseaux sociaux ne soient jamais bloqués par des règles anti-bot ou des pare-feu.
- Limitez ou bloquez les bots agressifs : utilisez robots.txt, crawl-delay ou des règles serveur pour les outils SEO trop insistants.
- Automatisez l’analyse des journaux : utilisez des outils propulsés par l’IA (comme Thunderbit) pour extraire, classer et étiqueter l’activité des crawlers — vous gagnerez du temps et repérerez des tendances qui pourraient vous échapper.
- Trouvez l’équilibre entre SEO, analytique et sécurité : ne bloquez pas les bots qui font avancer votre entreprise, mais ne laissez pas les mauvais agir librement.
Conclusion : garder votre liste de crawlers à jour et exploitable
En 2025, gérer votre liste de crawlers n’est pas qu’une tâche informatique : c’est une mission critique pour l’entreprise, qui touche au SEO, à l’analytique, à la sécurité et à la conformité. Avec des bots qui représentent désormais la majorité du trafic web, vous devez savoir qui visite votre site, pourquoi, et quoi faire à ce sujet. Gardez votre liste à jour, automatisez autant que possible et utilisez des outils comme pour garder une longueur d’avance. Le web devient toujours plus actif — et une stratégie de crawlers intelligente et exploitable est votre meilleure défense (et votre meilleur atout offensif) dans ce monde piloté par les bots.
FAQ
1. Pourquoi est-il important de maintenir une liste de crawlers à jour ?
Parce que les bots représentent désormais plus de la moitié du trafic web, et seule une petite partie est réellement utile. Garder votre liste à jour vous permet d’autoriser les bons bots (pour le SEO et les aperçus sociaux) et de bloquer ou limiter les mauvais, protégeant ainsi vos analyses, votre bande passante et la sécurité de vos données.
2. Comment savoir si un crawler est légitime ou faux ?
Ne vous fiez jamais uniquement au user-agent — vérifiez toujours l’adresse IP ou l’ASN à l’aide de listes officielles ou de recherches DNS inversées. Des outils comme Thunderbit peuvent automatiser ce processus en comparant vos journaux avec les IP et user-agents publiés des bots.
3. Que dois-je faire si un bot inconnu explore mon site ?
Examinez le user-agent et l’IP. S’il ne figure pas dans votre liste d’autorisation et ne correspond à aucun bot connu, envisagez de le limiter, de le challenger ou de le bloquer. Utilisez des outils d’IA pour classer et surveiller les nouveaux crawlers au fur et à mesure de leur apparition.
4. Comment Thunderbit aide-t-il à gérer les crawlers ?
Thunderbit utilise l’IA pour extraire, structurer et classer l’activité des crawlers à partir des journaux, ce qui facilite la création de listes d’autorisation, l’identification des imposteurs et l’automatisation de l’application des règles. Son prétraitement sémantique est particulièrement robuste pour les sites complexes ou dynamiques.
5. Quel est le risque de bloquer un grand crawler comme Googlebot ou Bingbot ?
Bloquer les crawlers des moteurs de recherche peut faire disparaître votre site des résultats de recherche et anéantir votre trafic organique. Vérifiez toujours votre pare-feu, robots.txt et vos règles anti-bot pour éviter de fermer accidentellement la porte aux bots les plus importants.
En savoir plus :