
Si vous explorez des outils d’extraction web propulsés par l’IA, vous êtes sans doute déjà tombé sur Crawl4AI. C’est un projet open source très populaire, dont les développeurs parlent beaucoup pour sa vitesse et sa flexibilité. Mais que faire si vous n’êtes pas développeur — ou si vous voulez simplement obtenir des données rapidement, sans vous battre avec des scripts Python ? Que vous envisagiez Crawl4AI pour votre prochain projet ou que vous cherchiez une meilleure alternative plus simple à utiliser, surtout si vous travaillez dans la vente, le marketing, l’e-commerce ou l’immobilier, vous êtes au bon endroit. Dans cet article, je vais détailler ce que propose Crawl4AI, ses points forts et ses limites. Je vais aussi vous montrer comment Thunderbit se compare en tant que solution moderne, sans code, pour les professionnels qui veulent extraire le web en quelques clics seulement.
Qu’est-ce que Crawl4AI ?
Crawl4AI est une bibliothèque Python open source conçue pour le crawl web et l’extraction de données, avec un accent particulier sur les cas d’usage liés à l’IA et aux grands modèles de langage (LLM). Elle a gagné en popularité sur GitHub grâce à son crawl parallèle à haute vitesse et à sa capacité à produire des données dans des formats adaptés à l’IA, comme JSON et Markdown. En bref, c’est une boîte à outils pour les développeurs qui veulent extraire des sites web à grande échelle, puis envoyer ces données vers des modèles d’IA, des tableaux de bord analytiques ou des bases de données personnalisées.
![]()
Produits et fonctionnalités clés :
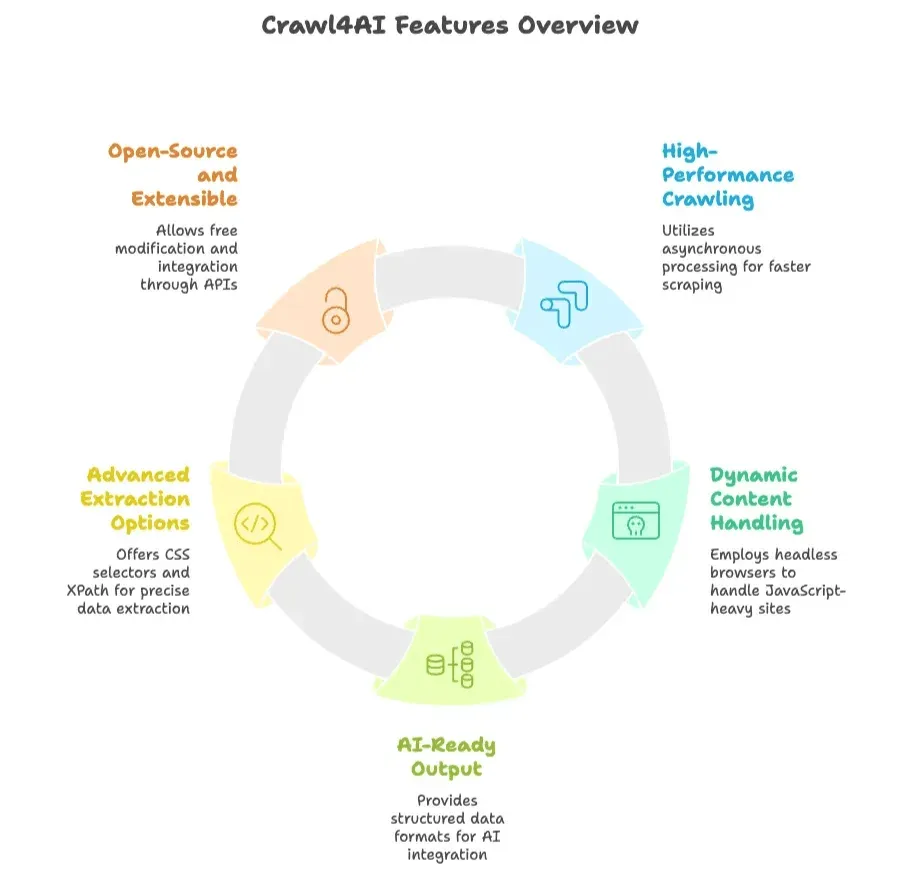
- Crawl haute performance : utilise un traitement asynchrone et parallèle pour explorer plusieurs pages en même temps, ce qui le rend bien plus rapide que de nombreux extracteurs traditionnels.
- Gestion du contenu dynamique : contrôle un navigateur sans interface graphique (comme Chromium via Playwright) pour exécuter JavaScript et extraire les sites modernes et dynamiques.
- Sortie prête pour l’IA : exporte les données sous forme de texte structuré (JSON, Markdown ou HTML nettoyé), prêt pour l’IA ou l’analyse de données.
- Options d’extraction avancées : permet de définir des règles d’extraction via des sélecteurs CSS ou XPath, et même d’intégrer des LLM pour résumer ou extraire du contenu.
- Open source et extensible : gratuit à utiliser, modifier et étendre. Propose une API Python, une interface en ligne de commande et une API REST pour une intégration flexible.
La philosophie de Crawl4AI est de « démocratiser la donnée » en offrant aux développeurs un extracteur rapide, piloté par le code, sans les paywalls ni les limitations des outils commerciaux. Si vous êtes à l’aise avec Python, c’est un moyen puissant de collecter rapidement de grandes quantités de données web.
Pour qui Crawl4AI est-il conçu ?
Crawl4AI est conçu principalement pour des utilisateurs techniques — pensez aux développeurs, data scientists, chercheurs en IA et à toute personne à l’aise avec l’écriture de scripts Python. Voici quelques cas d’usage typiques :
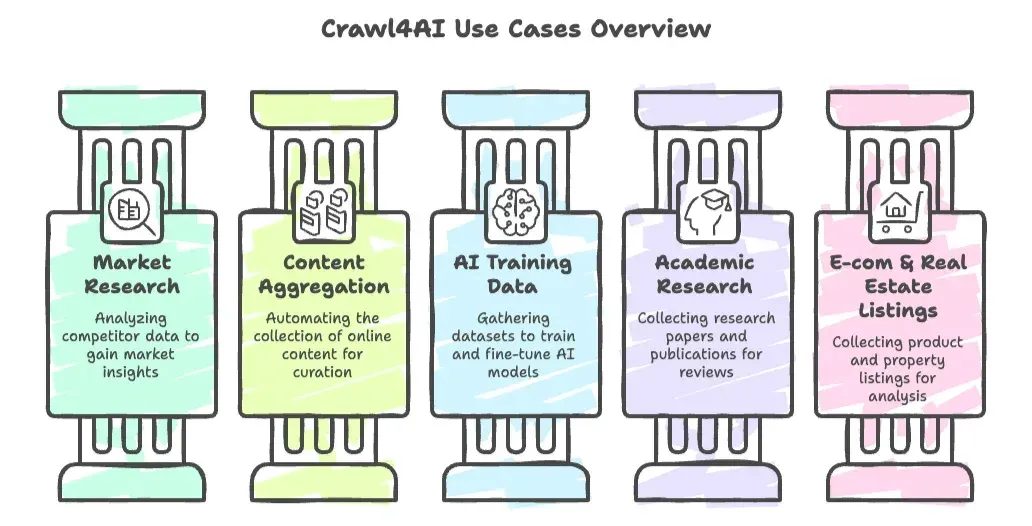
- Études de marché et analyse concurrentielle : extraire des sites concurrents, des articles de presse ou des réseaux sociaux pour en tirer des insights.
- Agrégation de contenu : automatiser la collecte d’articles, de blogs ou de publications de forums pour la curation ou le suivi des tendances.
- Collecte de données d’entraînement pour l’IA : réunir de grands ensembles de données (documentation, FAQ, articles, etc.) pour entraîner ou affiner des modèles de langage.
- Recherche académique : collecter automatiquement des articles de recherche, des décisions de justice ou des publications en ligne pour les revues de littérature.
- Annonces e-commerce et immobilières : les développeurs peuvent créer des crawlers personnalisés pour collecter des fiches produits ou des annonces immobilières à des fins d’analyse.
Mais voilà le problème : Crawl4AI n’est pas conçu pour les utilisateurs non techniques. Si vous êtes responsable commercial, marketeur ou agent immobilier sans expérience en codage, vous trouverez probablement la prise en main et l’utilisation intimidantes. L’outil suppose que vous maîtrisez Python et que vous êtes à l’aise avec la configuration des règles d’extraction et le dépannage.
Tarifs de Crawl4AI
L’un des plus gros arguments de Crawl4AI, c’est son prix : il est totalement gratuit. En tant que projet open source, il n’y a ni frais de licence, ni abonnement, ni paywall. Vous pouvez l’installer via pip et commencer à l’utiliser immédiatement.
Cependant, le « gratuit » s’accompagne de quelques réserves :
- Configuration et maintenance : vous devrez investir du temps pour mettre en place votre environnement, écrire des scripts et maintenir vos workflows d’extraction.
- Coûts indirects : si vous lancez des crawls volumineux, vous devrez peut-être payer des proxies, des serveurs ou des ressources cloud.
- Assistance : il n’existe pas de support client officiel — seulement les forums communautaires et les issues GitHub.
Pour les entreprises disposant de ressources techniques en interne, cela peut être une solution rentable. Mais pour les équipes non techniques, le temps et l’effort nécessaires pour démarrer peuvent vite dépasser l’avantage du prix zéro.
Retours d’utilisateurs sur Crawl4AI
Pour comprendre concrètement les performances de Crawl4AI, j’ai passé en revue des avis d’utilisateurs sur des blogs tech, des annuaires d’outils IA et des forums communautaires. Voici ce que j’ai trouvé :
Ce que les utilisateurs apprécient
- Rapidité et rentabilité : les développeurs vantent la vitesse à laquelle Crawl4AI peut extraire de grands sites, dépassant souvent des outils payants. Le fait qu’il soit gratuit est un énorme plus.
- Flexibilité open source : les utilisateurs apprécient de garder un contrôle total sur le code, sans verrouillage éditeur ni restrictions de fonctionnalités.
- Sortie prête pour l’IA : les données structurées et propres (surtout en JSON ou Markdown) font gagner du temps à ceux qui alimentent des modèles d’IA ou des outils d’analyse.
Là où les utilisateurs bloquent
Mais ces éloges s’accompagnent de gros bémols — surtout pour les débutants ou les non-programmeurs.
1. Courbe d’apprentissage abrupte
Un thème revient souvent : Crawl4AI n’est pas adapté aux débutants. Si vous débutez en extraction web ou si vous n’êtes pas à l’aise avec Python, la courbe d’apprentissage sera raide. Il n’y a pas d’interface visuelle en mode clic, tout passe par des scripts et des fichiers de configuration. La mise en place de l’environnement, l’écriture des règles d’extraction et la gestion du crawl asynchrone exigent toutes une vraie expertise technique. Un testeur l’a résumé sans détour : « Si vous n’êtes pas codeur, vous allez être perdu. »
2. Peu accueillant pour les nouveaux débutants
Même pour ceux qui ont un bagage technique, Crawl4AI peut s’avérer difficile. La documentation s’améliore, mais la communauté reste réduite, donc trouver de l’aide peut prendre du temps. Des utilisateurs signalent des bugs ou des plantages sur des sites complexes, et le dépannage implique souvent de fouiller les issues GitHub ou Stack Overflow. Il manque aussi des fonctionnalités intégrées pour des besoins métiers courants — comme la connexion à des sites, la résolution des CAPTCHA ou la planification de crawls récurrents. Si vous voulez extraire des données selon un calendrier ou gérer l’authentification, vous devrez développer ces fonctions vous-même.
Exemple concret :
- Un responsable marketing d’une entreprise e-commerce de taille moyenne a essayé d’utiliser Crawl4AI pour surveiller les prix des concurrents. Après plusieurs jours à se battre avec des scripts Python et des pilotes de navigateur, il a abandonné et a basculé vers un outil sans code. Les obstacles techniques et l’absence de support rendaient la solution impraticable pour son équipe.
- Un agent immobilier voulait extraire des annonces depuis plusieurs sites. Il a trouvé la configuration de Crawl4AI trop lourde et n’a pas réussi à dépasser la configuration initiale. Sans développeur disponible, le projet est resté bloqué.
En résumé, même si Crawl4AI est une machine de guerre pour les développeurs, c’est un choix difficile à défendre pour les utilisateurs métier qui veulent simplement obtenir des données sans prise de tête.
Points clés à retenir de l’avis sur Crawl4AI
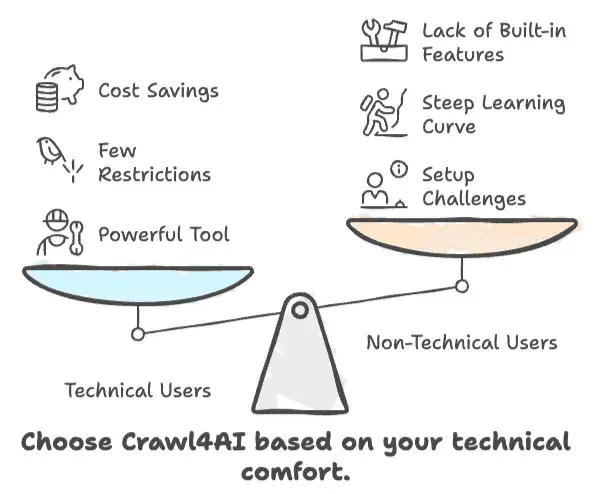
- Crawl4AI est rapide, flexible et gratuit — mais seulement si vous êtes à l’aise avec le code.
- Les utilisateurs non techniques auront du mal avec la configuration, la courbe d’apprentissage et l’absence de fonctionnalités métiers intégrées.
- Si vous avez besoin d’une solution sans code, en mode clic, Crawl4AI n’est probablement pas pour vous.
- Pour les développeurs et les praticiens de l’IA, c’est un outil puissant avec peu de restrictions.
- Pour les utilisateurs métier, le temps et l’effort nécessaires peuvent dépasser les économies réalisées.
Présentation de Thunderbit : l’Extracteur Web IA sans code pour les utilisateurs métier
Après avoir vu les limites de Crawl4AI pour les utilisateurs non techniques, parlons d’une meilleure alternative : Thunderbit.
Thunderbit est une extension Chrome d’extraction web propulsée par l’IA conçue spécifiquement pour les utilisateurs métier — commerciaux, marketeurs, e-commerçants et professionnels de l’immobilier qui veulent extraire des données de n’importe quel site, rapidement, sans écrire une seule ligne de code. J’ai testé beaucoup d’outils d’extraction, et Thunderbit se démarque par sa simplicité et sa puissance.
Qu’est-ce qui rend Thunderbit différent ?
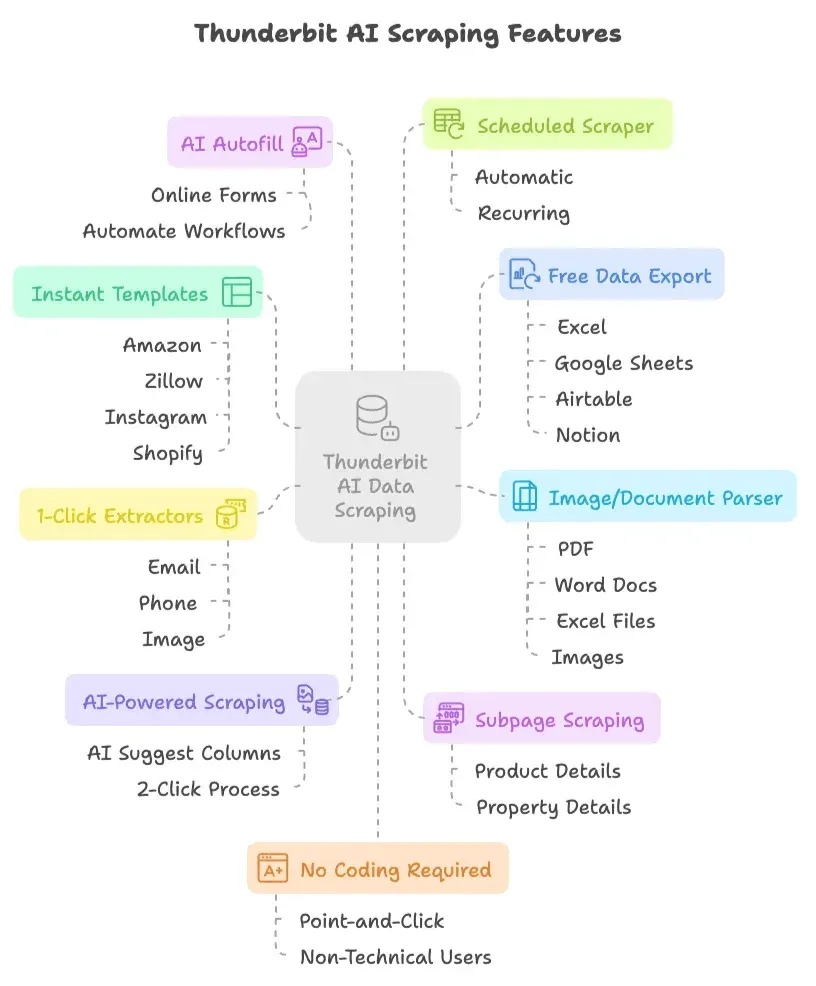
- Extraction en 2 clics grâce à l’IA : cliquez simplement sur « Suggérer des colonnes avec l’IA », laissez l’IA recommander quoi extraire, puis appuyez sur « Extraire ». C’est tout. Pas de scripts, pas de sélecteurs, pas de casse-tête.
- Extraction des sous-pages : l’IA de Thunderbit peut visiter automatiquement les sous-pages (comme les détails d’un produit ou d’un bien) et enrichir votre tableau de données — sans configuration manuelle.
- Modèles d’extraction instantanés : pour des sites populaires comme Amazon, Zillow, Instagram et Shopify, vous pouvez exporter les données en un clic grâce à des modèles préconstruits.
- Export de données gratuit : exportez vos données extraites vers Excel, Google Sheets, Airtable ou Notion — sans frais supplémentaires.
- AI Autofill (totalement gratuit) : utilisez l’IA pour remplir des formulaires en ligne et automatiser des workflows. Sélectionnez simplement le contexte et laissez Thunderbit faire le reste.
- Extracteur programmé : configurez des extractions automatiques et récurrentes avec une simple planification — sans cron ni configuration serveur.
- Extracteurs d’e-mail, de téléphone et d’images en 1 clic : récupérez instantanément des e-mails, numéros de téléphone ou images depuis n’importe quel site.
- Analyseur d’images et de documents : extrayez des tableaux depuis des PDF, des documents Word, des fichiers Excel ou des images. Importez votre fichier, laissez l’IA structurer les données, puis cliquez sur « Extraire ».
- Aucun codage requis : tout se fait en mode clic, pensé pour les utilisateurs non techniques.
Extraire des données depuis n’importe quel site avec l’IA Get Started Free
Thunderbit a pour mission de rendre les données web accessibles à tout le monde — pas seulement aux développeurs. Si vous voulez voir comment cela fonctionne, consultez la page de téléchargement de l’extension Chrome Thunderbit ou parcourez le blog Thunderbit pour découvrir des cas d’usage concrets.
Essayez gratuitement l’Extracteur Web IA Thunderbit
Tarifs de Thunderbit
Thunderbit utilise un système simple de crédits : 1 crédit = 1 ligne de sortie. Voici le détail des offres :
| Offre | Prix mensuel | Prix annuel (par mois) | Crédits (mensuels) |
|---|---|---|---|
| Gratuit | Gratuit | Gratuit | 6 pages |
| Starter | 15 $ | 9 $ | 500 |
| Pro 1 | 38 $ | 16,5 $ | 3 000 |
| Pro 2 | 75 $ | 33,8 $ | 6 000 |
| Pro 3 | 125 $ | 68,4 $ | 10 000 |
| Pro 4 | 249 $ | 137,5 $ | 20 000 |
Vous pouvez commencer gratuitement et extraire jusqu’à 6 pages (ou 10 avec un essai gratuit). Les formules payantes débloquent davantage de crédits et de fonctionnalités avancées, mais même l’offre gratuite reste généreuse pour un usage léger. Pour plus de détails, consultez la page Tarifs Thunderbit.
Thunderbit vs Crawl4AI : comparaison côte à côte
Mettons Thunderbit et Crawl4AI face à face pour voir où chaque outil excelle — et où Thunderbit simplifie la vie des utilisateurs métier.
| Fonctionnalité / Critère | Thunderbit | Crawl4AI |
|---|---|---|
| Interface sans code, en mode clic | ✅ | ❌ |
| Suggérer des colonnes avec l’IA (détection automatique) | ✅ | ❌ |
| Extraction des sous-pages (automatique) | ✅ | ❌ |
| Modèles instantanés (Amazon, etc.) | ✅ | ❌ |
| Export de données gratuit (Excel, Sheets) | ✅ | ❌ |
| AI Autofill (remplissage de formulaires) | ✅ | ❌ |
| Extraction planifiée (sans code) | ✅ | ❌ |
| Extraction e-mail/téléphone/images en 1 clic | ✅ | ❌ |
| Extraction de tableaux depuis images/documents | ✅ | ❌ |
| Gère le contenu dynamique | ✅ | ✅ |
| Open source | ❌ | ✅ |
| Nécessite du code | ❌ | ✅ |
| Offre gratuite disponible | ✅ | ✅ |
| Support communautaire | ✅ | ⚠️ (limité) |
| Conçu pour les utilisateurs métier | ✅ | ❌ |
| Conçu pour les développeurs | ⚠️ | ✅ |
| Tarification | $ (offres gratuites et payantes) | Gratuit |
| Support client | ✅ | ❌ |
Légende :
✅ = Oui
❌ = Non
⚠️ = Limité / partiel
$ = offres payantes disponibles
Conclusion
Si vous êtes développeur, que vous aimez bidouiller du code et que vous voulez un contrôle total, Crawl4AI est un outil gratuit et puissant pour l’extraction web à grande échelle. Mais si vous êtes un utilisateur métier — surtout dans la vente, le marketing, l’e-commerce ou l’immobilier — et que vous voulez simplement obtenir des données sans les tracas, Thunderbit est le grand gagnant. Il est conçu pour les utilisateurs non techniques, avec une automatisation propulsée par l’IA, des modèles instantanés et une interface intuitive qui vous fait passer du site web au tableur en quelques secondes.
Extraire n’importe quel site avec Thunderbit
FAQ
1. Comment Thunderbit se compare-t-il à d’autres extracteurs web IA comme Crawl4AI ?
Thunderbit est conçu pour les utilisateurs non techniques, avec une interface sans code, en mode clic, tandis que Crawl4AI est une bibliothèque Python open source pensée pour les développeurs. Thunderbit automatise les tâches complexes grâce à l’IA, rendant l’extraction web accessible à tout le monde.
2. Quelles fonctionnalités uniques Thunderbit offre-t-il aux utilisateurs métier ?
Thunderbit propose des suggestions de colonnes propulsées par l’IA, l’extraction des sous-pages, des modèles instantanés pour les sites populaires et l’export gratuit vers Excel ou Google Sheets — le tout sans coder. Il inclut aussi l’extraction planifiée et des extracteurs en 1 clic pour les e-mails, numéros de téléphone et images.
3. Thunderbit peut-il gérer des extractions complexes comme les PDF ou les images ?
Absolument ! L’IA de Thunderbit peut extraire des tableaux depuis des PDF, des documents Word, des fichiers Excel et des images. Importez simplement votre fichier, laissez l’IA structurer les données, puis cliquez sur « Extraire » pour obtenir un résultat instantané. En savoir plus sur le blog Thunderbit.
En savoir plus
- Qu’est-ce que l’extraction de données et comment la faire en 2025 – Blog Thunderbit
- Les meilleurs outils et logiciels d’extraction web en 2025 – Blog Thunderbit
- Les meilleurs outils de collecte de données IA pour des jeux de données prêts pour les modèles – Medium
- Comment les extracteurs web IA peuvent aider à l’extraction et à l’analyse des données - Forbes
Essayez l’Extracteur Web IA Get Started Free




