Le web avance à une vitesse folle, bien plus vite que je ne termine mon café du matin — et pourtant, je ne traîne pas ! En 2026, extraire des données en ligne n’est plus juste un petit plus pour les geeks : c’est devenu le carburant secret de la prospection commerciale, du suivi des prix e-commerce, des études de marché ou encore de l’analyse immobilière. Avec , choisir la bonne bibliothèque ou le bon outil, c’est la différence entre des heures de galère et un tableau d’insights prêt à l’emploi — livré avant même que tes concurrents aient fini leur pause café.
Ce qui est vraiment cool, c’est la variété des bibliothèques d’extraction web en 2026 : des extensions Chrome intelligentes sans code jusqu’aux frameworks de dev ultra-poussés. Que tu sois commercial qui veut des leads dans Excel, responsable des ops qui gère 500 références produits, ou pro du Python qui code son propre crawler, il y a forcément une solution qui colle à tes besoins. Après des années à bosser dans le SaaS et l’automatisation (et pas mal de nuits blanches), j’ai passé ces bibliothèques au crible. Voici donc mon top 10 des bibliothèques d’extraction web à connaître absolument cette année, et comment choisir celle qui va te simplifier la vie.
Qu’est-ce qui fait une bonne bibliothèque d’extraction web en 2026 ?
Avant de rentrer dans le vif du sujet, parlons des critères qui comptent vraiment pour choisir une bibliothèque d’extraction web. D’après mon expérience, les meilleurs outils en 2026 ont plusieurs points forts :
- Facilité d’utilisation : Est-ce qu’un non-développeur peut s’en sortir en quelques minutes ? Ou il faut sortir le doctorat Python ?
- Gestion du contenu dynamique : L’outil sait-il extraire des sites modernes bourrés de JavaScript ? Ou il se limite au HTML tout simple ?
- Compatibilité avec les langages et plateformes : Est-ce que ça marche dans ton langage préféré — Python, JavaScript, Java — ou même direct dans ton navigateur ?
- Scalabilité : Est-ce que ça tient la route sur des centaines ou des milliers de pages ?
- Intégration et export : Peut-on envoyer les données direct dans Excel, Google Sheets, Notion ou ton pipeline de données ?
- IA et automatisation : En 2026, les outils boostés à l’IA qui comprennent le langage naturel, c’est un vrai plus — surtout pour les équipes business qui veulent éviter de coder.
La réalité, c’est que les équipes veulent de la rapidité, de la précision et zéro prise de tête. Moins tu passes de temps à réparer des extracteurs ou à déboguer du code, plus tu peux exploiter tes données. Et avec l’essor de l’IA et de l’automatisation dans le navigateur, même les non-techs peuvent maintenant extraire des données qui demandaient avant l’aide d’un développeur ().
Allez, on passe au concret.
Top 10 des bibliothèques d’extraction web à utiliser en 2026
- pour l’extraction web sans code et boostée à l’IA, direct dans ton navigateur
- pour parser du HTML et nettoyer des données en Python
- pour crawler à grande échelle et gérer des pipelines costauds
- pour automatiser le navigateur et extraire sur des sites dynamiques bourrés de JavaScript
- pour parser du XML/HTML ultra-rapide en Python
- pour sélectionner du HTML façon jQuery en Python
- pour gérer le HTTP, parser du HTML et rendre du JS tout-en-un en Python
- pour automatiser les formulaires et tâches simples dans le navigateur en Python
- pour automatiser Chrome en mode headless avec Node.js
- pour parser du HTML solide en Java
1. Thunderbit
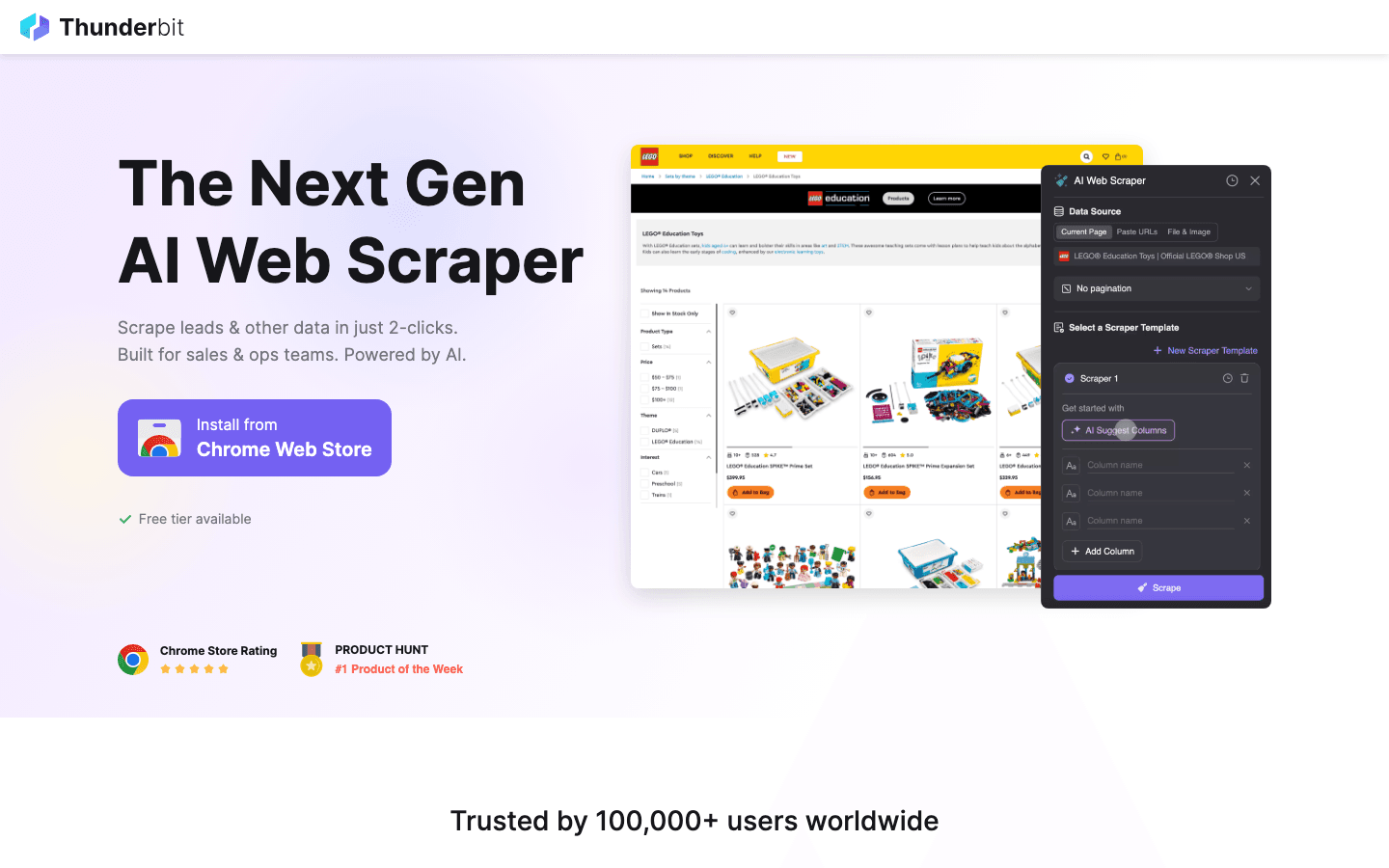
est mon chouchou pour tous ceux qui veulent extraire des données web sans écrire une ligne de code. Cette te permet de décrire ce que tu veux (« Récupère tous les noms de produits, prix et images de cette page »), et l’IA fait le reste. Pas de modèles, pas de config — clique sur « Suggérer les champs IA », ajuste si besoin, et lance l’extraction.
Pourquoi Thunderbit cartonne en 2026 :
- Interface sans code, langage naturel : Accessible à tous — commerciaux, ops, marketing, immobilier. Pas besoin de Python.
- Suggérer les champs IA : L’IA analyse la page et propose les colonnes à extraire.
- Extraction de sous-pages : Besoin de détails en plus ? Thunderbit peut visiter chaque sous-page (fiche produit, profil, etc.) et enrichir ton tableau automatiquement ().
- Modèles instantanés pour les sites connus : Amazon, Zillow, Shopify, et plein d’autres — extraction en un clic.
- Export vers Excel, Google Sheets, Notion, Airtable : Tes données arrivent direct là où ton équipe en a besoin.
- Support de 34 langues : Parfait pour les équipes internationales.
- Extraction cloud ou navigateur : À toi de choisir — le cloud est super rapide pour les sites publics, le mode navigateur gère les connexions.
Thunderbit, c’est déjà plus de 30 000 utilisateurs dans le monde, et la version gratuite te permet d’extraire jusqu’à 6 pages (ou 10 avec l’essai boosté). Pour découvrir ce que l’extraction web moderne peut faire, c’est le point de départ parfait.
2. Beautiful Soup

est une bibliothèque Python incontournable, adorée des data scientists et analystes pour sa simplicité et son efficacité à gérer du HTML « sale ». Si tu as déjà galéré à extraire des données d’une page au balisage chaotique, Beautiful Soup va devenir ton meilleur pote.
Les points forts de Beautiful Soup :
- Gère le HTML irrégulier : Parfait pour nettoyer et extraire des données de pages web « compliquées » ().
- Facile à prendre en main : Même les débutants en Python s’y retrouvent vite.
- Flexible : Fonctionne avec Requests, et peut être couplé à lxml pour plus de rapidité.
- Cas d’usage typiques : Extraction rapide, nettoyage de données web, petits scripts.
Pour les pages statiques ou le traitement de balisages complexes, Beautiful Soup reste une valeur sûre.
3. Scrapy

est le mastodonte de l’extraction web en Python. C’est un framework complet pour créer des crawlers costauds et des pipelines de données. Si tu dois extraire des milliers de pages, suivre des liens et traiter des données à grande échelle, Scrapy est fait pour toi.
Pourquoi Scrapy est un must :
- Super modulaire : Crée des spiders, pipelines et middlewares complexes ().
- Gère les gros projets : Idéal pour la veille concurrentielle, l’analyse de marché ou tout projet qui doit crawler plein de sites.
- Asynchrone et rapide : Pensé pour la perf.
- Communauté active : Plein de plugins, tutos et ressources.
Scrapy demande un peu d’apprentissage, mais pour les gros volumes, c’est la référence.
4. Selenium

est l’outil de base pour automatiser les navigateurs. Il sert autant à tester des applis web qu’à extraire des données sur des sites qui demandent une connexion, des clics ou la gestion de pop-ups. Pour interagir avec des sites dynamiques bourrés de JavaScript, Selenium simule un vrai utilisateur ().
Les atouts de Selenium :
- Automatise de vrais navigateurs : Chrome, Firefox, Safari, Edge, etc.
- Gère les connexions, pop-ups et actions utilisateur : Parfait pour l’extraction après login ou les workflows complexes.
- Multi-langage : Python, Java, C#, et plus.
- Idéal pour : Les sites qui bloquent les extracteurs classiques, ou quand il faut simuler un humain.
C’est plus lourd que les bibliothèques HTTP, mais parfois, il n’y a pas d’autre choix.
5. lxml
est un parseur XML et HTML ultra-performant pour Python. Si tu veux de la vitesse (genre traiter des milliers de gros fichiers), lxml est imbattable ().
Pourquoi lxml est top :
- Ultra-rapide : Plus rapide que la plupart des parseurs Python, surtout sur les gros fichiers.
- Robuste : Gère XML et HTML, et s’intègre facilement à d’autres outils.
- Idéal pour : Le traitement de gros volumes de données, en complément de Beautiful Soup ou Scrapy.
Pour l’extraction à grande échelle ou le traitement de fichiers massifs, lxml est un must.
6. PyQuery
apporte la puissance des sélecteurs jQuery à Python. Si tu aimes sélectionner des éléments avec $('.class') en jQuery, PyQuery te permet de faire pareil dans tes scripts d’extraction ().
Les points forts de PyQuery :
- Sélecteurs façon jQuery : Super intuitif pour les devs front-end.
- Code concis et lisible : Simplifie les sélections complexes.
- S’appuie sur lxml : Rapide et efficace sous le capot.
- Idéal pour : Les projets où tu veux manipuler le HTML à la sauce jQuery en Python.
C’est le pont parfait entre le dev web et l’extraction de données.
7. Requests-HTML
est une bibliothèque Python qui combine la simplicité de Requests (pour le HTTP) avec le parsing HTML intégré et même le rendu JavaScript.
Ce qui rend Requests-HTML unique :
- Tout-en-un : Récupère des pages, parse le HTML et rend du JavaScript dans un seul package.
- Idéal pour les débutants : Parfait pour les petits à moyens projets d’extraction.
- Idéal pour : Scripts rapides, sites avec un peu de contenu dynamique, utilisateurs qui veulent de la simplicité.
Pour débuter ou pour des besoins flexibles sur de petits volumes, Requests-HTML est un super choix.
8. MechanicalSoup

est une bibliothèque Python qui automatise les formulaires web et les interactions simples dans le navigateur. Basée sur Beautiful Soup et Requests, elle facilite la connexion, le remplissage de formulaires et la navigation dans des workflows basiques ().
Pourquoi MechanicalSoup est pratique :
- Automatise les formulaires et connexions : Parfait pour extraire des données derrière une authentification.
- API simple : Facile à prendre en main pour les débutants.
- Idéal pour : Tâches répétitives dans le navigateur, workflows simples, sites où Selenium serait trop lourd.
Moins puissant que Selenium pour les sites complexes, mais bien plus léger pour les besoins basiques.
9. Puppeteer
est une bibliothèque Node.js pour contrôler Chrome ou Chromium en mode headless. C’est l’outil préféré pour extraire des sites interactifs et bourrés de JavaScript ().
Les super-pouvoirs de Puppeteer :
- Automatisation complète du navigateur : Clique, scrolle, remplis des formulaires, interagis comme un vrai utilisateur.
- Gère le contenu dynamique : Parfait pour les sites qui chargent les données via JavaScript.
- Idéal pour : E-commerce, réseaux sociaux, ou tout site où les extracteurs classiques plantent.
Pour les devs JavaScript ou l’extraction du « web moderne », Puppeteer est incontournable.
10. Jsoup
est la référence pour parser du HTML en Java. C’est l’équivalent de Beautiful Soup, mais pour les devs Java ().
Pourquoi les équipes Java adorent Jsoup :
- API simple et puissante : Extraire et manipuler les données en quelques lignes de code.
- Gère le HTML « sale » : Nettoie et parse même les pages mal formatées.
- Idéal pour : Intégrer l’extraction dans des applis ou workflows backend Java.
Si tu bosses en Java, Jsoup est le choix évident.
Tableau comparatif des bibliothèques d’extraction web
Voici un aperçu comparatif des 10 bibliothèques :
| Bibliothèque | Langage | Facilité d’utilisation | Contenu dynamique | IA/Sans code | Cas d’usage typiques | Idéal pour |
|---|---|---|---|---|---|---|
| Thunderbit | Extension Chrome | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Oui | Vente, opérations, recherche, immobilier | Non-développeurs, équipes métiers |
| Beautiful Soup | Python | ⭐⭐⭐⭐ | ⭐ | Non | Parsing HTML, nettoyage de données | Débutants Python, analystes |
| Scrapy | Python | ⭐⭐⭐ | ⭐⭐ | Non | Crawling à grande échelle, pipelines | Développeurs, projets big data |
| Selenium | Multi | ⭐⭐ | ⭐⭐⭐⭐⭐ | Non | Automatisation navigateur, connexions | QA, extraction sites dynamiques |
| lxml | Python | ⭐⭐⭐ | ⭐ | Non | Parsing rapide, gros fichiers | Power users, gros volumes |
| PyQuery | Python | ⭐⭐⭐⭐ | ⭐ | Non | Sélection façon jQuery | Dév web, scripts concis |
| Requests-HTML | Python | ⭐⭐⭐⭐ | ⭐⭐ | Non | Scripts rapides, rendu JS | Débutants, petits projets |
| MechanicalSoup | Python | ⭐⭐⭐⭐ | ⭐⭐ | Non | Automatisation formulaires, connexions | Tâches simples dans le navigateur |
| Puppeteer | Node.js | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Non | Sites JS, automatisation | Dév JS, extraction web dynamique |
| Jsoup | Java | ⭐⭐⭐⭐ | ⭐ | Non | Parsing HTML en Java | Équipes Java, workflows backend |
Comment choisir la bonne bibliothèque d’extraction web pour ton entreprise
Alors, tu choisis quoi ? Voici mes conseils, après pas mal de tests (et quelques nuits blanches à déboguer) :
- Non-développeurs ou équipes métiers : Fonce sur Thunderbit. L’approche IA/sans code donne des résultats en quelques minutes. Si ton équipe veut juste des données dans Excel ou Sheets, pas besoin de se compliquer la vie.
- Développeurs Python : Beautiful Soup et Requests-HTML sont parfaits pour les petits besoins. Scrapy est ton allié pour les gros projets. Combine avec lxml ou PyQuery pour plus de puissance.
- Gestion de connexions ou de contenu dynamique ? Selenium (multi-langage) ou Puppeteer (Node.js) sont tes meilleurs amis.
- Équipes Java : Jsoup s’impose pour intégrer l’extraction dans tes applis Java.
- Automatisation de formulaires ou workflows simples ? MechanicalSoup est léger et facile à utiliser.
Points clés à garder en tête :
- Niveau technique : Les outils sans code comme Thunderbit sont parfaits pour les équipes non techniques. Les devs préféreront la flexibilité des bibliothèques programmables.
- Complexité des données : Pour des pages simples et statiques, Beautiful Soup ou Jsoup suffisent. Pour des sites dynamiques bourrés de JavaScript, vise Selenium ou Puppeteer.
- Échelle : Scrapy et lxml sont top pour les gros volumes et la rapidité.
- Intégration : L’export direct de Thunderbit vers Sheets, Notion ou Airtable fait gagner un temps fou aux équipes métiers.
Pour aller plus loin dans le choix de l’outil, checke le .
Conclusion : Libère la puissance des données web avec les bons outils
L’extraction web en 2026, ce n’est plus réservé aux codeurs ou aux data scientists. Grâce à la montée des outils sans code et boostés à l’IA, toutes les équipes — de la vente à la recherche — peuvent profiter de la mine d’or des données du web. La bonne bibliothèque peut te faire gagner des centaines d’heures par an (), améliorer la précision de tes analyses et donner un vrai avantage à ton entreprise.
Mon conseil ? Pars de tes besoins — rapidité, volume, aisance technique — et teste plusieurs options. est parfaite pour commencer, et les bibliothèques open source comme Beautiful Soup ou Scrapy sont toujours là si tu veux aller plus loin techniquement.
Envie d’en savoir plus ? Va faire un tour sur le pour plus de guides, ou abonne-toi à notre pour des tutos pratiques.
Bonne extraction — et que tes données soient toujours propres, bien rangées et prêtes à l’emploi !
FAQ
1. Quelle est la bibliothèque d’extraction web la plus simple pour les non-développeurs en 2026 ?
est le choix numéro un pour les non-codeurs. Son extension Chrome boostée à l’IA permet d’extraire des données avec des instructions en langage naturel — sans coder.
2. Quelle bibliothèque est la plus adaptée pour extraire des sites dynamiques ou riches en JavaScript ?
(Node.js) et (multi-langage) sont idéaux pour extraire des sites dynamiques générés par JavaScript. Ils automatisent de vrais navigateurs et gèrent les interactions complexes.
3. Quelle est la différence entre Beautiful Soup et Scrapy ?
est parfait pour extraire et parser des données sur des pages individuelles ou de petits projets, surtout avec du HTML « sale ». est un framework complet pour créer des crawlers évolutifs et traiter de gros volumes de données.
4. Puis-je exporter directement les données extraites vers Google Sheets ou Notion ?
Oui — propose l’export direct vers Google Sheets, Notion, Airtable et Excel. La plupart des bibliothèques programmables demandent de coder l’export soi-même.
5. Comment choisir la bonne bibliothèque d’extraction web pour mon entreprise ?
Prends en compte ton niveau technique, la complexité des sites à extraire, le volume de données et tes besoins d’intégration. Les outils sans code comme Thunderbit sont idéaux pour les équipes métiers, tandis que les devs préféreront Scrapy, Beautiful Soup ou Puppeteer pour plus de contrôle.
Pour aller plus loin