Le web est une véritable mine d’or de données, mais la plupart ne sont pas faites pour être téléchargées facilement. En 2025, l’extraction web est devenue un incontournable, que ce soit pour surveiller les prix, dénicher des offres d’emploi, suivre le marché immobilier ou garder un œil sur la concurrence. Le hic ? Github regorge de projets d’extraction web. Certains sont ultra aboutis, d’autres sont restés à l’état de brouillon, et beaucoup n’ont pas vu de mise à jour depuis belle lurette. Alors, comment s’y retrouver, surtout si on n’est pas un as du développement ?
Dans ce guide, je vous propose un tour d’horizon des 15 meilleurs projets d’extraction web sur Github pour 2025. Mais pas question de balancer une simple liste : je les passe au crible selon la facilité d’installation, la pertinence selon l’usage, la gestion du contenu dynamique, la fréquence des mises à jour, les options d’export de données, et le public visé. Et si vous en avez marre de bidouiller du code, je vous explique aussi pourquoi des outils sans code, boostés à l’IA comme , changent la donne pour les pros comme pour les non-techniciens.
Notre méthode pour sélectionner les 15 meilleurs projets d’extraction web sur Github
Soyons clairs : tous les projets Github ne se valent pas. Certains sont éprouvés par des milliers d’utilisateurs, d’autres sont restés des essais du week-end. Pour cette sélection, j’ai mis en avant les projets qui remplissent ces critères :
- Popularité & Communauté Github : Projets adoptés par une large communauté (de quelques milliers à plus de 90k étoiles) et avec des contributeurs actifs.
- Activité récente : Outils encore mis à jour en 2025, pas des fossiles numériques.
- Documentation & Prise en main : Documentation claire, exemples de code, et prise en main accessible.
- Utilisation réelle : Déjà utilisés dans des contextes pros ou de recherche, pas juste des démos « hello world ».
Et comme l’extraction web n’est pas universelle, j’ai comparé chaque projet selon :
- Complexité d’installation : Peut-on démarrer en quelques minutes ou faut-il se battre avec des dépendances et des drivers ?
- Adéquation à l’usage : Est-il taillé pour l’e-commerce, l’actualité, la recherche, ou autre ?
- Gestion des pages dynamiques : Peut-il extraire des sites modernes, bourrés de JavaScript ?
- Santé du projet : Est-il encore maintenu ou le dernier commit date-t-il de l’époque des dinosaures ?
- Options d’export de données : Permet-il d’obtenir des données prêtes à l’emploi ou juste du HTML brut ?
- Public cible : Débutants Python, ingénieurs data, équipes non techniques ?
Chaque projet est accompagné de tags pour ces critères, histoire que vous puissiez cibler direct ce qui vous correspond—que vous soyez un mordu du code ou que vous vouliez juste vos données dans Google Sheets.

Installation & Complexité de mise en route : à quelle vitesse pouvez-vous extraire ?
Soyons honnêtes : le vrai frein pour beaucoup, c’est de réussir à lancer un extracteur. Voilà comment je classe la complexité d’installation :
- Plug & Play (zéro prise de tête) : On installe et c’est parti. Parfait pour les débutants.
- Modéré (ligne de commande, un peu de code) : Il faut taper quelques scripts ou commandes, mais ça reste accessible si vous avez déjà touché au code.
- Avancé (drivers, anti-bot, code poussé) : Nécessite de configurer l’environnement, des drivers de navigateur ou de solides bases en Python/JS.
Voici où se situent les principaux projets :
- Plug & Play : MechanicalSoup (Python), Nokogiri (Ruby), Maxun (pour les utilisateurs finaux, une fois déployé)
- Modéré : Scrapy, Crawlee, Node Crawler, Selenium, Playwright, Colly, Puppeteer, Katana, Scrapling, WebMagic
- Avancé : Heritrix, Apache Nutch (Java, fichiers de config, stack big data)
Si vous n’êtes pas développeur, privilégiez les options « Plug & Play » ou sans code. Pour les autres, « Modéré » veut dire qu’il faudra écrire un peu de code, mais rien d’insurmontable—sauf si les accolades vous donnent des sueurs froides.
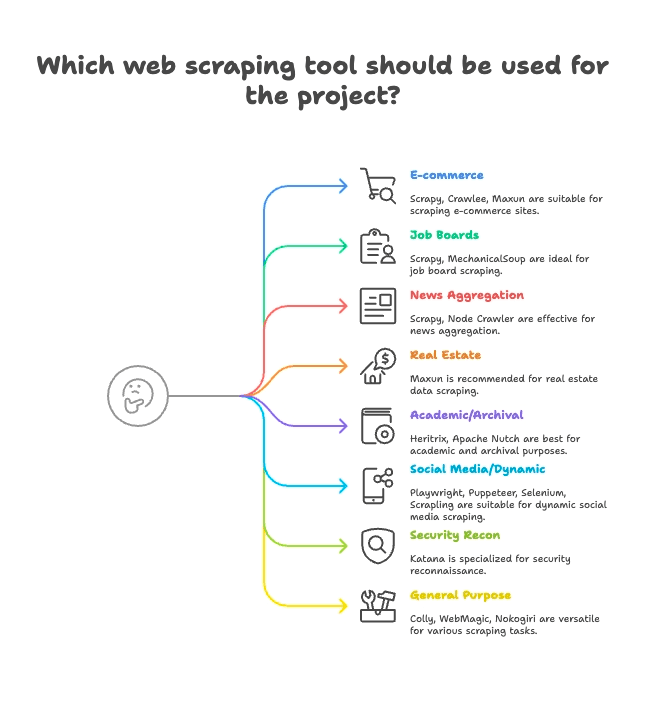
Classement par usage : trouvez l’extracteur adapté à votre secteur
Tous les extracteurs ne sont pas faits pour les mêmes besoins. Voici comment je regroupe les 15 meilleurs selon leur usage principal :
E-commerce & veille tarifaire
- Scrapy : Extraction à grande échelle de catalogues produits
- Crawlee : Polyvalent, adapté aux sites e-commerce statiques et dynamiques
- Maxun : Sans code, parfait pour extraire rapidement des listes de produits
Emploi & recrutement
- Scrapy : Gère la pagination et les listes structurées
- MechanicalSoup : Idéal pour les job boards nécessitant une connexion
Actualités & agrégation de contenu
- Scrapy : Conçu pour crawler des sites d’actualité à grande échelle
- Node Crawler : Rapide pour agréger des contenus statiques
Immobilier
- Thunderbit : Extraction IA des annonces et pages de détails
- Maxun : Sélection visuelle des données immobilières
Recherche académique & archivage web
- Heritrix : Archivage complet de sites (fichiers WARC)
- Apache Nutch : Crawl distribué pour jeux de données de recherche
Réseaux sociaux & contenu dynamique
- Playwright, Puppeteer, Selenium : Extraction de flux dynamiques, simulation de connexion
- Scrapling : Extraction furtive pour sites protégés contre les bots
Sécurité & reconnaissance
- Katana : Découverte rapide d’URLs, crawl de sécurité
Polyvalent / multi-usages
- Colly : Extraction performante en Go pour tout type de site
- WebMagic : Flexible, basé sur Java, adapté à de nombreux domaines
- Nokogiri : Parsing Ruby pour scripts personnalisés
Gestion des pages dynamiques : ces projets Github peuvent-ils extraire des sites modernes ?
Les sites web d’aujourd’hui raffolent du JavaScript. React, Vue, scroll infini, AJAX… Si vous avez déjà tenté d’extraire une page et obtenu un « rien du tout », vous voyez le problème.
Voici comment chaque projet gère le contenu dynamique :
- Support JS complet (navigateur sans tête) :
- Selenium : Contrôle des navigateurs réels, exécution de tout le JS
- Playwright : Multi-navigateurs, multi-langages, gestion JS avancée
- Puppeteer : Chrome/Firefox sans tête, rendu JS complet
- Crawlee : Bascule HTTP/navigateur (via Puppeteer/Playwright)
- Katana : Mode sans tête optionnel pour le JS
- Scrapling : Intègre Playwright pour extraction furtive JS
- Maxun : Utilise un navigateur en arrière-plan pour le contenu dynamique
- Pas de support JS natif (HTML statique uniquement) :
- Scrapy : Nécessite un plugin Selenium/Playwright pour le JS
- MechanicalSoup, Node Crawler, Colly, WebMagic, Nokogiri, Heritrix, Apache Nutch : Récupèrent uniquement le HTML, pas de gestion JS par défaut
L’IA de Thunderbit fait toute la différence ici : elle repère et extrait automatiquement le contenu dynamique—aucune configuration manuelle, pas de plugin, pas de prise de tête avec les sélecteurs. Cliquez sur « Suggestion IA » et laissez l’outil bosser, même sur des sites React bien costauds. Pour en savoir plus, jetez un œil au .
Santé & fiabilité des projets : cet extracteur fonctionnera-t-il encore l’an prochain ?
Rien de pire que de bâtir son workflow sur un outil, puis de le voir tomber à l’abandon. Voici l’état des principaux projets :
- Actifs (mises à jour fréquentes) :
- Scrapy :
- Crawlee :
- Playwright :
- Puppeteer :
- Katana :
- Colly :
- Maxun :
- Scrapling :
- Stables mais mises à jour plus lentes :
- MechanicalSoup :
- Node Crawler :
- WebMagic :
- Nokogiri :
- Mode maintenance (spécialisé, lent) :
- Heritrix :
- Apache Nutch :
Thunderbit est un service géré : vous n’avez jamais à craindre l’abandon du code. L’équipe s’occupe des mises à jour de l’IA, des modèles et des intégrations—et vous profitez d’un accompagnement, de tutos et d’un support si besoin.
Gestion & export des données : du HTML brut à la donnée exploitable
Récupérer les données, c’est bien, mais il faut aussi pouvoir les utiliser—CSV, Excel, Google Sheets, Airtable, Notion, ou même une API en direct.
- Export structuré intégré :
- Scrapy : Export CSV, JSON, XML
- Crawlee : Jeux de données et stockages flexibles
- Maxun : CSV, Excel, Google Sheets, API JSON
- Thunderbit :
- Gestion manuelle (à coder soi-même) :
- MechanicalSoup, Node Crawler, Selenium, Playwright, Puppeteer, Colly, WebMagic, Nokogiri, Scrapling : À vous d’écrire le code d’export
- Export spécialisé :
- Heritrix : Fichiers WARC (archives web)
- Apache Nutch : Contenu brut vers stockage/index
L’export structuré et les intégrations de Thunderbit font gagner un temps fou aux pros. Fini les CSV à bidouiller ou le code à bricoler—un clic et vos données sont prêtes à l’emploi.
Public cible : à qui s’adresse chaque projet d’extraction web sur Github ?
On ne va pas se mentir : chaque outil n’est pas fait pour tout le monde. Voici mes conseils :
- Débutants Python : MechanicalSoup, Scrapling (pour les plus curieux)
- Ingénieurs data : Scrapy, Crawlee, Colly, WebMagic, Node Crawler
- QA & automatisation : Selenium, Playwright, Puppeteer
- Recherche sécurité : Katana
- Développeurs Ruby : Nokogiri
- Développeurs Java : WebMagic, Heritrix, Apache Nutch
- Utilisateurs non techniques / équipes métier : Maxun, Thunderbit
- Growth hackers, analystes : Maxun, Thunderbit
Si le code, ce n’est pas votre truc, ou si vous voulez des résultats rapides, Thunderbit et Maxun sont vos meilleurs alliés. Pour les autres, choisissez l’outil adapté à votre langage et à votre usage.
Les 15 meilleurs projets d’extraction web sur Github : comparatif détaillé
On rentre dans le vif du sujet : chaque projet, classé par usage, avec tags et points forts.
E-commerce, veille tarifaire et crawl généraliste
— 57,1k étoiles, mise à jour juin 2025

- Résumé : Framework Python asynchrone pour le crawl et l’extraction à grande échelle.
- Installation : Modérée (code Python, async)
- Usage : E-commerce, actualités, recherche, spiders multi-pages
- Support JS : Non (plugin Selenium/Playwright nécessaire)
- Santé du projet : Actif
- Export : CSV, JSON, XML intégrés
- Public : Développeurs, ingénieurs data
- Points forts : Évolutif, robuste, riche en plugins. Courbe d’apprentissage raide pour les débutants.
— 17,9k étoiles, 2025

- Résumé : Librairie Node.js complète pour extraction statique et dynamique.
- Installation : Modérée (code Node/TS)
- Usage : E-commerce, réseaux sociaux, automatisation
- Support JS : Oui (intégration Puppeteer/Playwright)
- Santé du projet : Très actif
- Export : Flexible (datasets, stockages)
- Public : Équipes JS/TS
- Points forts : Anti-blocage, bascule HTTP/navigateur facile.
— 13k étoiles, juin 2025

- Résumé : Plateforme open source d’extraction web sans code, interface visuelle.
- Installation : Modérée (déploiement serveur), Facile (pour l’utilisateur final)
- Usage : Polyvalent, e-commerce, extraction métier
- Support JS : Oui (navigateur intégré)
- Santé du projet : Actif et en croissance
- Export : CSV, Excel, Google Sheets, API JSON
- Public : Utilisateurs non techniques, analystes, équipes
- Points forts : Extraction par clic, navigation multi-niveaux, auto-hébergeable.
Emploi, recrutement et interactions simples
— 4,8k étoiles, 2024

- Résumé : Librairie Python pour automatiser les formulaires et la navigation simple.
- Installation : Plug & Play (Python, peu de code)
- Usage : Job boards avec connexion, sites statiques
- Support JS : Non
- Santé du projet : Mature, peu de mises à jour
- Export : Aucun (manuel)
- Public : Débutants Python, scripts rapides
- Points forts : Simule des sessions navigateur en quelques lignes. Pas adapté aux sites dynamiques.
Agrégation d’actualités & contenu statique
— 6,8k étoiles, 2024

- Résumé : Crawler serveur rapide et concurrent, parsing Cheerio.
- Installation : Modérée (callbacks/async Node)
- Usage : Actualités, extraction statique rapide
- Support JS : Non (HTML uniquement)
- Santé du projet : Activité modérée (v2 beta)
- Export : Aucun (à coder)
- Public : Développeurs Node.js, besoins haute-concurrence
- Points forts : Crawl asynchrone, limitation de débit, API façon jQuery.
Immobilier, annonces et extraction de sous-pages

- Résumé : Extracteur web sans code, boosté par l’IA, pour les professionnels.
- Installation : Plug & Play (extension Chrome, installation en 2 clics)
- Usage : Immobilier, e-commerce, ventes, marketing, tout site web
- Support JS : Oui (détection automatique du contenu dynamique par l’IA)
- Santé du projet : Mise à jour continue, service géré
- Export : Un clic vers Sheets, Airtable, Notion, CSV, JSON
- Public : Utilisateurs non techniques, équipes métier, ventes, marketing
- Points forts : Suggestion IA, extraction de sous-pages, export instantané, onboarding, modèles, .
Recherche académique & archivage web
— 3k étoiles, 2023

- Résumé : Crawler d’archivage web à grande échelle de l’Internet Archive.
- Installation : Avancée (application Java, fichiers de config)
- Usage : Archivage web, crawl de domaines entiers
- Support JS : Non (récupération brute)
- Santé du projet : Maintenu (lent mais stable)
- Export : Fichiers WARC (archives web)
- Public : Archives, bibliothèques, institutions
- Points forts : Évolutif, robuste, conforme aux standards. Pas pour l’extraction ciblée.
— 3k étoiles, 2024

- Résumé : Crawler open source pour le big data et les moteurs de recherche.
- Installation : Avancée (Java+Hadoop pour l’échelle)
- Usage : Crawl moteur de recherche, big data
- Support JS : Non (HTTP uniquement)
- Santé du projet : Actif (Apache)
- Export : Contenu brut vers stockage/index
- Public : Entreprises, big data, recherche académique
- Points forts : Architecture à plugins, crawl distribué.
Réseaux sociaux, contenu dynamique et automatisation
— ~30k étoiles, 2025

- Résumé : Automatisation de navigateur pour extraction et tests, tous navigateurs majeurs.
- Installation : Modérée (drivers, multi-langages)
- Usage : Sites riches en JS, tests, réseaux sociaux
- Support JS : Oui (automatisation complète)
- Santé du projet : Actif, mature
- Export : Aucun (manuel)
- Public : Ingénieurs QA, développeurs
- Points forts : Multi-langages, simulation du comportement utilisateur.
— 73,5k étoiles, 2025

- Résumé : Automatisation moderne de navigateur pour extraction et tests E2E.
- Installation : Modérée (scripts multi-langages)
- Usage : Web apps modernes, réseaux sociaux, automatisation
- Support JS : Oui (navigateur sans tête ou réel)
- Santé du projet : Très actif
- Export : Aucun (à gérer soi-même)
- Public : Développeurs ayant besoin d’un contrôle avancé du navigateur
- Points forts : Multi-navigateurs, auto-attente, interception réseau.
— 90,9k étoiles, 2025

- Résumé : API haut niveau pour automatiser Chrome/Firefox.
- Installation : Modérée (scripts Node)
- Usage : Extraction Chrome sans tête, contenu dynamique
- Support JS : Oui (Chrome/Firefox)
- Santé du projet : Actif (équipe Chrome)
- Export : Aucun (à coder)
- Public : Développeurs Node.js, front-end
- Points forts : Contrôle navigateur avancé, captures, PDF, interception réseau.
— 5,4k étoiles, juin 2025

- Résumé : Extraction furtive et performante avec anti-bot intégré.
- Installation : Modérée (code Python)
- Usage : Extraction furtive, anti-bot, sites dynamiques
- Support JS : Oui (intégration Playwright)
- Santé du projet : Actif, à la pointe
- Export : Aucun (manuel)
- Public : Développeurs Python, hackers, ingénieurs data
- Points forts : Furtivité, proxy, anti-blocage, async.
Reconnaissance sécurité
— 13,8k étoiles, 2025

- Résumé : Crawler web rapide pour la sécurité, l’automatisation et la découverte de liens.
- Installation : Modérée (outil CLI ou librairie Go)
- Usage : Crawl sécurité, découverte d’endpoints
- Support JS : Oui (mode sans tête optionnel)
- Santé du projet : Actif (ProjectDiscovery)
- Export : Sortie texte (listes d’URLs)
- Public : Chercheurs sécurité, devs Go
- Points forts : Rapidité, concurrence, parsing JS sans tête.
Extraction polyvalente / multi-usages
— 24,3k étoiles, 2025

- Résumé : Framework d’extraction rapide et élégant pour Go.
- Installation : Modérée (code Go)
- Usage : Extraction performante, généraliste
- Support JS : Non (HTML uniquement)
- Santé du projet : Actif, commits récents
- Export : Aucun (à coder)
- Public : Développeurs Go, recherche de performance
- Points forts : Async, limitation de débit, extraction distribuée.
— 11,6k étoiles, 2023

- Résumé : Framework Java flexible, style Scrapy.
- Installation : Modérée (Java, API simple)
- Usage : Extraction web généraliste en Java
- Support JS : Non (extensible avec Selenium)
- Santé du projet : Communauté active
- Export : Pipelines modulables
- Public : Développeurs Java
- Points forts : Pool de threads, planificateurs, anti-blocage.
— 6,2k étoiles, 2025

- Résumé : Parseur HTML/XML natif et rapide pour Ruby.
- Installation : Plug & Play (gem Ruby)
- Usage : Parsing HTML/XML dans les apps Ruby
- Support JS : Non (parsing uniquement)
- Santé du projet : Actif, suit l’évolution de Ruby
- Export : Aucun (formatage via Ruby)
- Public : Développeurs Ruby, Rails
- Points forts : Rapidité, conformité, sécurité par défaut.
En un coup d’œil : tableau comparatif des fonctionnalités
Voici un tableau récapitulatif—avec Thunderbit pour la comparaison :
| Projet | Complexité d’installation | Usage | Support JS | Maintenance | Export de données | Public | Étoiles Github |
|---|---|---|---|---|---|---|---|
| Scrapy | Modérée | E-commerce, actualités | Non | Actif | CSV, JSON, XML | Devs, data engineers | 57,1k |
| Crawlee | Modérée | Polyvalent, automatisation | Oui | Très actif | Jeux de données flexibles | Équipes JS/TS | 17,9k |
| MechanicalSoup | Plug & Play | Statique, formulaires | Non | Mature | Aucun (manuel) | Débutants Python | 4,8k |
| Node Crawler | Modérée | Actualités, statique | Non | Modéré | Aucun (manuel) | Devs Node.js | 6,8k |
| Selenium | Modérée | JS, tests | Oui | Actif | Aucun (manuel) | QA, devs | ~30k |
| Heritrix | Avancée | Archivage, recherche | Non | Maintenu | WARC | Archives, institutions | 3k |
| Apache Nutch | Avancée | Big data, recherche | Non | Actif | Contenu brut | Entreprises, recherche | 3k |
| WebMagic | Modérée | Java, généraliste | Non | Communauté active | Pipelines modulables | Devs Java | 11,6k |
| Nokogiri | Plug & Play | Parsing Ruby | Non | Actif | Aucun (manuel) | Rubyists | 6,2k |
| Playwright | Modérée | Dynamique, automatisation | Oui | Très actif | Aucun (manuel) | Devs, QA | 73,5k |
| Katana | Modérée | Sécurité, découverte | Oui | Actif | Sortie texte | Sécurité, devs Go | 13,8k |
| Colly | Modérée | Haute perf, généraliste | Non | Actif | Aucun (manuel) | Devs Go | 24,3k |
| Puppeteer | Modérée | Dynamique, automatisation | Oui | Actif | Aucun (manuel) | Devs Node.js | 90,9k |
| Maxun | Facile (utilisateur) | Sans code, métier | Oui | Actif | CSV, Excel, Sheets, API | Non-tech, analystes | 13k |
| Scrapling | Modérée | Furtif, anti-bot | Oui | Actif | Aucun (manuel) | Devs Python, hackers | 5,4k |
| Thunderbit | Plug & Play | Sans code, métier | Oui | Géré, à jour | Sheets, Airtable, Notion | Non-tech, pros métier | N/A |
Pourquoi Thunderbit est le choix idéal pour les non-techniciens et les professionnels
Soyons francs : la plupart des projets open source sur Github sont pensés par et pour les développeurs. Ça veut dire installation, maintenance et dépannage. Si vous êtes pro, marketeur, commercial, ou que vous voulez juste des résultats—sans vous prendre la tête avec les regex—Thunderbit est fait pour vous.
Voici ce qui fait la différence avec Thunderbit :
- Simplicité sans code, boostée par l’IA : Installez l’, cliquez sur « Suggestion IA » et lancez l’extraction. Pas de Python, pas de sélecteurs, pas de « pip install » à gérer.
- Gestion des pages dynamiques : L’IA de Thunderbit lit et extrait les données des sites modernes (React, Vue, AJAX) sans configuration manuelle.
- Extraction de sous-pages : Besoin de récupérer les détails de chaque produit ou annonce ? L’IA de Thunderbit peut cliquer sur chaque sous-page et fusionner les données dans un seul tableau—sans code personnalisé.
- Exports prêts à l’emploi : Export en un clic vers Google Sheets, Airtable, Notion, CSV ou JSON. Idéal pour la prospection, la veille tarifaire ou l’agrégation de contenu.
- Mises à jour continues & support : Thunderbit est un service géré—aucun risque d’abandon. Vous profitez d’un onboarding, de tutos et d’une bibliothèque de modèles pour les sites courants.
- Public cible : Thunderbit s’adresse aux non-techniciens, équipes métier, et à tous ceux qui veulent aller vite et éviter la galère du code.
Ne vous fiez pas qu’à mon avis—Thunderbit est déjà adopté par plus de 30 000 utilisateurs dans le monde, dont des équipes chez Accenture, Grammarly et Puma. Et oui, on a même été élu Produit de la Semaine sur Product Hunt.
Envie de voir à quel point l’extraction peut être simple ? .
Conclusion : comment choisir la bonne solution d’extraction web en 2025
En résumé : Github regorge d’outils puissants pour l’extraction, mais la plupart sont pensés pour les développeurs. Si vous aimez coder, des frameworks comme Scrapy, Crawlee, Playwright ou Colly vous offrent un contrôle total. Pour la recherche ou la sécurité, Heritrix, Nutch et Katana sont incontournables.
Mais si vous êtes pro, analyste, ou que vous voulez simplement des données—rapidement, structurées et prêtes à l’emploi—Thunderbit est la solution idéale. Pas d’installation, pas de maintenance, pas de code. Juste des résultats.
Alors, quelle est la suite ? Testez un projet Github adapté à votre niveau et à vos besoins. Ou, pour aller droit au but et obtenir des résultats en quelques minutes, et commencez à extraire dès aujourd’hui.
Pour aller plus loin sur l’extraction web, découvrez d’autres guides sur le , comme ou .
Bonne extraction—et que vos données soient toujours propres, structurées et prêtes à l’emploi. Si vous bloquez, rappelez-vous : il y a sûrement un repo Github pour ça… ou alors laissez l’IA de Thunderbit s’en charger pour vous.