Mon tout premier projet de scraping reposait sur un script Python bricolé à la main, un proxy partagé et une prière. Il plantait tous les trois jours.
En 2026, les API de scraping prennent en charge les parties les plus pénibles — proxys, rendu, CAPTCHAs, nouvelles tentatives — pour que vous n’ayez pas à le faire. Elles sont la colonne vertébrale de tout, du suivi des prix aux pipelines de données d’entraînement pour l’IA.
Mais il y a un twist : des outils pilotés par l’IA comme rendent désormais de nombreux cas d’usage d’API inutiles pour les non-développeurs. J’y reviens plus bas.
Voici 10 API de scraping que j’ai utilisées ou évaluées — ce qu’elles font bien, là où elles montrent leurs limites, et quand vous n’avez peut-être pas besoin d’une API du tout.
Pourquoi envisager Thunderbit AI plutôt que les API de web scraping traditionnelles ?
Avant d’entrer dans la liste des API, parlons de l’éléphant dans la pièce : l’automatisation pilotée par l’IA. J’ai passé des années à aider des équipes à automatiser les tâches répétitives, et je peux vous dire qu’il y a une raison pour laquelle de plus en plus d’entreprises abandonnent les API lourdes en code pour passer directement à des agents IA comme Thunderbit.
Voici ce qui distingue Thunderbit des API de web scraping traditionnelles :
-
Appels d’API en cascade pour un taux de réussite de 99 %
L’IA de Thunderbit ne se contente pas d’appeler une seule API en espérant le meilleur. Elle utilise un modèle en cascade — en sélectionnant automatiquement la meilleure méthode d’extraction pour chaque tâche, en réessayant si nécessaire, et en garantissant un taux de réussite de 99 %. Vous obtenez les données, pas les maux de tête.
-
Configuration sans code en deux clics
Oubliez les scripts Python ou les prises de tête avec la documentation d’API. Avec Thunderbit, il suffit de cliquer sur « Suggestion IA des champs » puis sur « Extraire ». C’est tout. Même ma mère pourrait s’en servir (et elle pense encore que « le cloud », c’est juste du mauvais temps).
-
Extraction par lots : rapide et précise
Le modèle IA de Thunderbit peut traiter en parallèle des milliers de sites web différents, en s’adaptant à chaque mise en page à la volée. C’est comme avoir une armée de stagiaires — sauf qu’ils ne demandent pas de pause café.
-
Sans maintenance
Les sites changent tout le temps. Les API traditionnelles ? Elles cassent. Thunderbit ? L’IA relit la page à neuf à chaque fois, donc vous n’avez pas besoin de mettre à jour le code quand un site modifie sa mise en page ou ajoute un nouveau bouton.
-
Extraction et post-traitement de données personnalisés
Vous devez nettoyer, étiqueter, traduire ou résumer vos données ? Thunderbit peut le faire pendant l’extraction — voyez cela comme le fait de jeter 10 000 pages web dans ChatGPT et de récupérer un jeu de données parfaitement structuré.
-
Extraction de sous-pages et pagination
L’IA de Thunderbit peut suivre les liens, gérer la pagination et même enrichir votre tableau avec des données issues de sous-pages — le tout sans code personnalisé.
-
Export de données et intégrations gratuits
Exportez vers Excel, Google Sheets, Airtable, Notion, ou téléchargez en CSV/JSON — pas de paywall, pas d’absurdité.
Voici une comparaison rapide pour mieux visualiser :
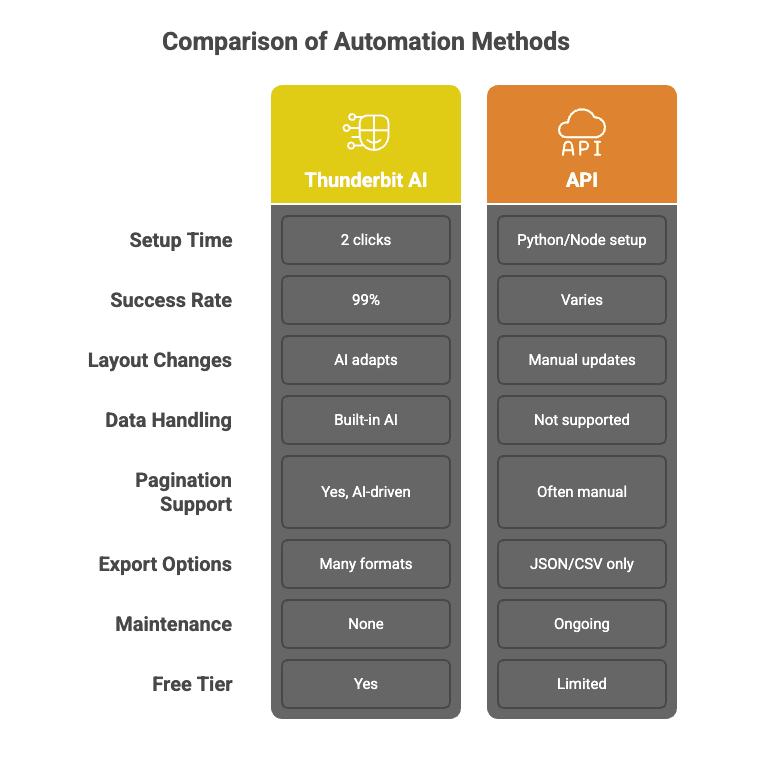
Vous voulez le voir en action ? Découvrez l’.
Qu’est-ce qu’une API de scraping de données ?
Revenons un instant aux bases. Une API de scraping de données est un outil qui vous permet d’extraire des données de sites web par programmation — sans avoir à construire vos propres scrapers de zéro. Voyez-la comme un robot que vous pouvez envoyer récupérer les derniers prix, avis ou annonces, et qui vous ramène les données dans un format propre et structuré (généralement JSON ou CSV).
Comment ça marche ? La plupart des API de scraping gèrent les aspects pénibles — rotation des proxys, résolution des CAPTCHAs, rendu du JavaScript — pour que vous puissiez vous concentrer sur ce dont vous avez vraiment besoin : les données. Vous envoyez une requête (généralement avec une URL et quelques paramètres), et l’API renvoie le contenu, prêt pour votre flux de travail métier.
Principaux avantages :
- Rapidité : les API peuvent scraper des milliers de pages par minute.
- Scalabilité : vous devez surveiller 10 000 produits ? Aucun problème.
- Intégration : branchez-les à votre CRM, outil de BI ou entrepôt de données avec un minimum de friction.
Mais comme nous allons le voir, toutes les API ne se valent pas — et toutes ne sont pas aussi « configurez puis oubliez » qu’elles le prétendent.
Comment j’ai évalué ces API
J’ai passé beaucoup de temps sur le terrain — à tester, casser, et parfois à faire involontairement un DDoS de mes propres serveurs (ne le dites pas à mon ancienne équipe IT). Pour cette liste, je me suis concentré sur :
- Fiabilité : est-ce que ça fonctionne vraiment, même sur des sites compliqués ?
- Vitesse : à quelle vitesse cela peut-il fournir des résultats à grande échelle ?
- Tarification : est-ce abordable pour des startups et scalable pour des entreprises ?
- Scalabilité : peut-il gérer des millions de requêtes, ou s’effondre-t-il à 100 ?
- Facilité pour les développeurs : la documentation est-elle claire ? Y a-t-il des SDK et des exemples de code ?
- Support : quand les choses tournent mal (et ce sera le cas), l’aide est-elle disponible ?
- Retours utilisateurs : de vrais avis terrain, pas juste du marketing creux.
Je me suis aussi appuyé fortement sur des tests pratiques, l’analyse des avis et les retours de la communauté Thunderbit (nous sommes un public exigeant).
Les 10 API à considérer en 2026
Prêt pour le plat de résistance ? Voici ma liste mise à jour des meilleures API et plateformes d’extraction web pour les utilisateurs métier et les développeurs en 2026.
1. Oxylabs
 Aperçu :
Aperçu :
Oxylabs est le champion poids lourd de l’extraction de données web pour l’entreprise. Avec un énorme pool de proxys et des API spécialisées pour tout, des SERP au e-commerce, c’est la solution de référence pour les entreprises du Fortune 500 et pour tous ceux qui ont besoin de fiabilité à grande échelle.
Fonctionnalités clés :
- Immense réseau de proxys (résidentiels, datacenter, mobiles, ISP) dans plus de 195 pays
- API de scraping avec anti-bot, résolution de CAPTCHA et rendu via navigateur headless
- Géociblage, persistance de session et haute précision des données (taux de réussite de 95 % et plus)
- OxyCopilot : assistant IA qui génère automatiquement du code d’analyse et des requêtes API
Tarification :
À partir d’environ 49 $/mois pour une seule API, 149 $/mois pour l’offre tout-en-un. Inclut un essai gratuit de 7 jours avec jusqu’à 5 000 requêtes.
Retours utilisateurs :
Évalué , apprécié pour sa fiabilité et son support. Principal défaut ? C’est cher, mais on en a pour son argent.
2. ScrapingBee
 Aperçu :
Aperçu :
ScrapingBee est le meilleur allié du développeur — simple, abordable et ciblé. Vous envoyez une URL, il gère Chrome headless, les proxys et les CAPTCHAs, puis renvoie la page rendue ou simplement les données dont vous avez besoin.
Fonctionnalités clés :
- Rendu via navigateur headless (prise en charge du JavaScript)
- Rotation automatique des IP et résolution de CAPTCHA
- Pool de proxys furtifs pour les sites difficiles
- Configuration minimale — un simple appel API
Tarification :
Offre gratuite avec environ 1 000 appels/mois. Les offres payantes commencent à environ 29 $/mois pour 5 000 requêtes.
Retours utilisateurs :
Constamment . Les développeurs adorent la simplicité ; les non-codeurs peuvent la trouver un peu trop minimaliste.
3. Apify
 Aperçu :
Aperçu :
Apify est le couteau suisse du scraping web. Vous pouvez créer des scrapers personnalisés (« Actors ») en JavaScript ou en Python, ou utiliser leur vaste bibliothèque d’actors préconstruits pour les sites populaires. C’est aussi flexible que nécessaire.
Fonctionnalités clés :
- Scrapers personnalisés et préconstruits (Actors) pour presque n’importe quel site
- Infrastructure cloud, planification et gestion des proxys incluses
- Export des données vers JSON, CSV, Excel, Google Sheets, et plus encore
- Communauté active et support sur Discord
Tarification :
Plan gratuit à vie avec 5 $/mois de crédits. Les offres payantes commencent à 39 $/mois.
Retours utilisateurs :
. Les développeurs aiment la flexibilité ; les débutants doivent passer par une phase d’apprentissage.
4. Decodo (anciennement Smartproxy)
 Aperçu :
Aperçu :
Decodo (rebaptisé à partir de Smartproxy) mise avant tout sur le rapport qualité-prix et la simplicité. Il combine une infrastructure de proxys robuste avec des API de scraping pour le web général, les SERP, l’e-commerce et les réseaux sociaux — le tout sous un seul abonnement.
Fonctionnalités clés :
- API de scraping unifiée pour tous les endpoints (plus besoin d’options séparées)
- Scrapers spécialisés pour Google, Amazon, TikTok et plus encore
- Tableau de bord convivial avec playground et générateurs de code
- Support par chat en direct 24/7
Tarification :
À partir d’environ 50 $/mois pour 25 000 requêtes. Essai gratuit de 7 jours avec 1 000 requêtes.
Retours utilisateurs :
Apprécié pour son excellent rapport qualité-prix et son support réactif. .
5. Octoparse
 Aperçu :
Aperçu :
Octoparse est le champion du no-code. Si vous détestez coder mais aimez les données, cette application de bureau en mode clic-clic (avec fonctionnalités cloud) vous permet de créer visuellement des scrapers et de les exécuter localement ou dans le cloud.
Fonctionnalités clés :
- Constructeur visuel de workflows — cliquez simplement pour sélectionner les champs de données
- Extraction cloud, planification et rotation automatique des IP
- Modèles pour les sites populaires et marketplace pour scrapers personnalisés
- Octoparse AI : intègre RPA et ChatGPT pour le nettoyage des données et l’automatisation des workflows
Tarification :
Plan gratuit jusqu’à 10 tâches locales. Les offres payantes commencent à 119 $/mois (fonctionnalités cloud, tâches illimitées). Essai gratuit de 14 jours pour les fonctionnalités premium.
Retours utilisateurs :
. Très apprécié des non-codeurs, mais les utilisateurs avancés peuvent atteindre ses limites.
6. Bright Data
 Aperçu :
Aperçu :
Bright Data est le grand patron — si vous avez besoin d’échelle, de vitesse et de toutes les fonctionnalités imaginables, c’est votre plateforme. Avec le plus grand réseau de proxys au monde et un puissant IDE de scraping, elle est pensée pour l’entreprise.
Fonctionnalités clés :
- Plus de 150 millions d’IP (résidentielles, mobiles, ISP, datacenter)
- Web Scraper IDE, collecteurs de données préconstruits et jeux de données prêts à acheter
- Anti-bot avancé, résolution de CAPTCHA et prise en charge des navigateurs headless
- Accent fort sur la conformité et le juridique (initiative Ethical Web Data)
Tarification :
Paiement à l’usage : environ 1,05 $ pour 1 000 requêtes, proxys à partir de 3 à 15 $/Go. Essais gratuits pour la plupart des produits.
Retours utilisateurs :
Apprécié pour ses performances et ses fonctionnalités, mais le prix et la complexité peuvent constituer un frein pour les petites équipes.
7. WebAutomation
 Aperçu :
Aperçu :
WebAutomation est une plateforme cloud conçue pour les non-développeurs. Avec une marketplace de extracteurs préconstruits et un constructeur no-code, c’est parfait pour les utilisateurs métier qui veulent des données, pas du code.
Fonctionnalités clés :
- Extracteurs préconstruits pour les sites populaires (Amazon, Zillow, etc.)
- Constructeur d’extracteur no-code avec interface point-and-click
- Planification cloud, livraison des données et maintenance incluses
- Tarification par ligne (payez ce que vous extrayez)
Tarification :
Formule projet à 74 $/mois (environ 400 000 lignes/an), paiement à l’usage à 1 $ pour 1 000 lignes. Essai gratuit de 14 jours avec 10 millions de crédits.
Retours utilisateurs :
Les utilisateurs apprécient sa simplicité d’utilisation et sa tarification transparente. Le support est utile, et la maintenance est prise en charge par l’équipe.
8. ScrapeHero
 Aperçu :
Aperçu :
ScrapeHero a commencé comme cabinet de conseil en scraping sur mesure et propose désormais une plateforme cloud en libre-service. Vous pouvez utiliser des scrapers préconstruits pour les sites populaires ou demander des projets entièrement gérés.
Fonctionnalités clés :
- ScrapeHero Cloud : scrapers préconstruits pour Amazon, Google Maps, LinkedIn et plus encore
- Fonctionnement no-code, planification et livraison cloud
- Solutions sur mesure pour des besoins spécifiques
- Accès API pour une intégration programmatique
Tarification :
Les offres cloud commencent à seulement 5 $/mois. Projets personnalisés à partir de 550 $ par site (paiement unique).
Retours utilisateurs :
Apprécié pour sa fiabilité, la qualité des données et son support. Très bien pour passer du DIY à des solutions gérées.
9. Sequentum
 Aperçu :
Aperçu :
Sequentum est le couteau suisse de l’entreprise — conçu pour la conformité, la traçabilité et les volumes massifs. Si vous avez besoin d’une certification SOC-2, de pistes d’audit et de collaboration en équipe, c’est votre outil.
Fonctionnalités clés :
- Concepteur d’agents low-code (point-and-click + script)
- Déploiement SaaS cloud ou sur site
- Gestion intégrée des proxys, résolution de CAPTCHA et navigateurs headless
- Pistes d’audit, accès par rôle et conformité SOC-2
Tarification :
Paiement à l’usage (6 $/heure d’exécution, 0,25 $/Go exporté), formule Starter à 199 $/mois. 5 $ de crédit offerts à l’inscription.
Retours utilisateurs :
Les entreprises apprécient les fonctions de conformité et la scalabilité. Il y a une courbe d’apprentissage, mais le support et la formation sont excellents.
10. Grepsr
 Aperçu :
Aperçu :
Grepsr est un service d’extraction de données géré — dites-leur simplement ce dont vous avez besoin, et ils construisent, exécutent et maintiennent les scrapers pour vous. Parfait pour les entreprises qui veulent des données sans la charge technique.
Fonctionnalités clés :
- Extraction gérée (« Grepsr Concierge ») — ils configurent et entretiennent tout
- Tableau de bord cloud pour planifier, surveiller et télécharger les données
- Multiples formats de sortie et intégrations (Dropbox, S3, Google Drive)
- Paiement par enregistrement de données (et non par requête)
Tarification :
Pack Starter à 350 $ (extraction ponctuelle), abonnements récurrents sur devis.
Retours utilisateurs :
Les clients adorent l’expérience sans effort et le support réactif. Idéal pour les équipes non techniques et celles qui accordent plus de valeur au temps qu’au bidouillage.
Tableau comparatif rapide : les meilleures API de web scraping
Voici la fiche récapitulative des 10 plateformes :
| Plateforme | Types de données pris en charge | Prix de départ | Essai gratuit | Facilité d’utilisation | Support | Fonctionnalités notables |
|---|---|---|---|---|---|---|
| Oxylabs | Web, SERP, e-commerce, immobilier | 49 $/mois | 7 jours/5k requêtes | Orienté développeurs | 24/7, entreprise | OxyCopilot AI, énorme pool de proxys, géociblage |
| ScrapingBee | Web général, JS, CAPTCHA | 29 $/mois | 1k appels/mois | API simple | E-mail, forums | Chrome headless, proxys furtifs |
| Apify | Tout le web, préconstruit/personnalisé | Gratuit/39 $/mois | Gratuit à vie | Flexible, complexe | Communauté, Discord | Marketplace d’actors, infrastructure cloud, intégrations |
| Decodo | Web, SERP, e-commerce, social | 50 $/mois | 7 jours/1k requêtes | Convivial | Chat en direct 24/7 | API unifiée, playground de code, excellent rapport qualité-prix |
| Octoparse | Tout le web, no-code | Gratuit/119 $/mois | 14 jours | Visuel, no-code | E-mail, forum | Interface point-and-click, cloud, Octoparse AI |
| Bright Data | Tout le web, jeux de données | 1,05 $/1k requêtes | Oui | Puissant, complexe | 24/7, entreprise | Plus grand réseau de proxys, IDE, jeux de données prêts à l’emploi |
| WebAutomation | Structuré, e-commerce, immobilier | 74 $/mois | 14 jours/10 M lignes | No-code, modèles | E-mail, chat | Extracteurs préconstruits, tarification par ligne |
| ScrapeHero | E-commerce, cartes, emploi, sur mesure | 5 $/mois | Oui | No-code, géré | E-mail, tickets | Scrapers cloud, projets sur mesure, livraison Dropbox |
| Sequentum | Tout le web, entreprise | 0 $/199 $/mois | Crédit de 5 $ | Low-code, visuel | Accompagnement poussé | Pistes d’audit, SOC-2, sur site/cloud |
| Grepsr | Tout ce qui est structuré, géré | 350 $ ponctuel | Exécution d’exemple | Entièrement géré | Interlocuteur dédié | Configuration concierge, paiement par donnée, intégrations |
Choisir le bon outil de web scraping pour votre entreprise
Alors, quel outil devriez-vous choisir ? Voici comment je le présente aux équipes que je conseille :
-
Si vous voulez zéro code, des résultats instantanés et un nettoyage des données piloté par l’IA :
Optez pour . C’est le chemin le plus rapide de « j’ai besoin de données » à « j’ai les données » — sans avoir à surveiller des scripts ou des API.
-
Si vous êtes développeur et que vous aimez le contrôle et la flexibilité :
Essayez Apify, ScrapingBee ou Oxylabs. Ils offrent le plus de puissance, mais vous devrez gérer un peu de configuration et de maintenance.
-
Si vous êtes un utilisateur métier qui veut un outil visuel :
WebAutomation est excellent pour le scraping en mode point-and-click, surtout pour l’e-commerce et la génération de leads.
-
Si vous avez besoin de conformité, de traçabilité ou de fonctionnalités entreprise :
Sequentum est conçu pour vous. C’est plus cher, mais cela en vaut la peine dans les secteurs réglementés.
-
Si vous voulez simplement que quelqu’un d’autre gère tout :
Les services gérés de Grepsr ou ScrapeHero sont la bonne option. Vous payez un peu plus, mais votre tension artérielle vous remerciera.
Et si vous hésitez encore, la plupart de ces plateformes proposent des essais gratuits — alors testez-les !
Points clés à retenir
- Les API de web scraping sont désormais indispensables pour les entreprises pilotées par la donnée — le marché devrait atteindre .
- Le scraping manuel est dépassé — entre les technologies anti-bot, les proxys et les changements de sites, les API et les outils IA sont la seule façon de passer à l’échelle.
- Chaque API/plateforme a ses points forts :
- Oxylabs et Bright Data pour l’échelle et la fiabilité
- Apify pour la flexibilité
- Decodo pour le rapport qualité-prix
- WebAutomation pour le no-code
- Sequentum pour la conformité
- Grepsr pour des données gérées sans effort
- L’automatisation pilotée par l’IA (comme Thunderbit) change la donne — avec des taux de réussite plus élevés, zéro maintenance et un traitement de données intégré que les API traditionnelles ne peuvent pas égaler.
- Le meilleur outil est celui qui correspond à votre flux de travail, votre budget et vos compétences techniques. N’hésitez pas à expérimenter !
Si vous êtes prêt à laisser derrière vous les scripts cassés et le débogage sans fin, essayez — ou consultez d’autres guides sur le pour des analyses approfondies sur le scraping d’Amazon, Google, des PDF et plus encore.
Et souvenez-vous : dans le monde des données web, la seule chose qui change plus vite que les sites eux-mêmes, c’est la technologie que nous utilisons pour les scraper. Restez curieux, restez automatisés, et que vos proxys ne soient jamais bloqués.