
Le web déborde de données, et soyons honnêtes : personne n’a le temps de copier-coller mille fiches produits ou pages de prix concurrents. Si vous utilisez Linux — comme moi pour la plupart de mes tâches d’automatisation et de dev — vous savez déjà que cette plateforme est une vraie machine pour les équipes pilotées par la donnée. En fait, , et . Mais voilà le hic : trouver le bon extracteur Web pour Linux, vraiment adapté à votre flux de travail — que vous soyez un utilisateur métier non technique ou un développeur chevronné — peut vite donner l’impression de chercher une aiguille dans une botte de foin.
C’est pourquoi j’ai rassemblé ce tour d’horizon des 18 meilleurs outils d’extraction Web pour Linux en 2026. Des solutions IA sans code comme (oui, celui que mon équipe et moi avons créé) aux frameworks développeur classiques comme Scrapy et Beautiful Soup, cette liste est votre raccourci pour choisir le meilleur extracteur Web Linux selon vos besoins — sans la galère des essais-erreurs.
Pourquoi les outils d’extraction Web Linux sont importants pour les utilisateurs métiers
Soyons concrets : la collecte manuelle de données plombe la productivité. Des études montrent que les équipes qui s’appuient sur le copier-coller perdent des heures chaque semaine et atteignent des taux d’erreur proches de 5 % — une recette idéale pour des erreurs coûteuses et des occasions manquées (). Linux, avec sa stabilité, sa sécurité et sa flexibilité, est la plateforme de choix pour exécuter des extracteurs devant tourner 24 h/24 et 7 j/7 — que vous soyez sur un poste de travail, un serveur ou dans le cloud.
Cas d’usage métier courants des outils d’extraction Web Linux :
- Génération de leads : les équipes commerciales extraient des annuaires, des réseaux sociaux ou des sites d’avis pour récupérer de nouveaux contacts sans le travail manuel fastidieux ().
- Surveillance des prix : les équipes e-commerce récupèrent automatiquement les prix et les stocks des concurrents, afin de garder leurs propres tarifs précis et à jour.
- Veille concurrentielle : les équipes marketing et opérationnelles suivent les lancements de produits, les avis et les mots-clés SEO — fini de naviguer à l’aveugle.
- Intelligence de marché : les analystes agrègent les actualités, les forums et les données sociales pour repérer les tendances en temps réel.
- Automatisation des flux de travail : certains outils — surtout ceux propulsés par l’IA — peuvent même automatiser des tâches web, comme remplir des formulaires ou naviguer dans des tableaux de bord, directement depuis votre machine Linux.
Le plus intéressant ? Le bon outil d’extraction Web Linux peut autonomiser les utilisateurs non techniques — pas seulement les développeurs — pour accéder aux données du web et les exploiter afin de prendre des décisions métier plus rapides et plus intelligentes.
Comment nous avons sélectionné le meilleur extracteur Web pour Linux
Tous les extracteurs ne se valent pas, surtout sur Linux. Voici les critères que j’ai retenus :
- Compatibilité Linux : chaque outil de cette liste fonctionne nativement sur Linux, via navigateur, ou avec une simple solution de contournement (comme Wine ou un accès cloud).
- Facilité d’utilisation : des prompts IA en langage naturel aux interfaces visuelles de type point-and-click, j’ai privilégié les outils qui permettent aux non-développeurs d’obtenir vite des résultats — sans oublier les utilisateurs avancés qui veulent un contrôle total.
- Puissance d’extraction des données : sait-il gérer le contenu dynamique, la pagination, les sous-pages et différents types de données ? Résiste-t-il aux techniques anti-scraping ?
- Passage à l’échelle et automatisation : planification, extraction cloud, crawling distribué — ce sont des indispensables pour les projets de données sérieux.
- Intégration et export : CSV, Excel, Google Sheets, API — si vous ne pouvez pas sortir vos données, à quoi bon ?
- Tarifs et licences : gratuit, open source ou payant — il existe des options pour tous les budgets, des fondateurs solo aux équipes enterprise.
- Communauté et support : des bases d’utilisateurs actives, une bonne documentation et un support réactif font toute la différence quand vous bloquez.
J’ai aussi intégré les retours d’utilisateurs, les avis du secteur et ma propre expérience pratique avec ces outils. Entrons dans la liste.
1. Thunderbit
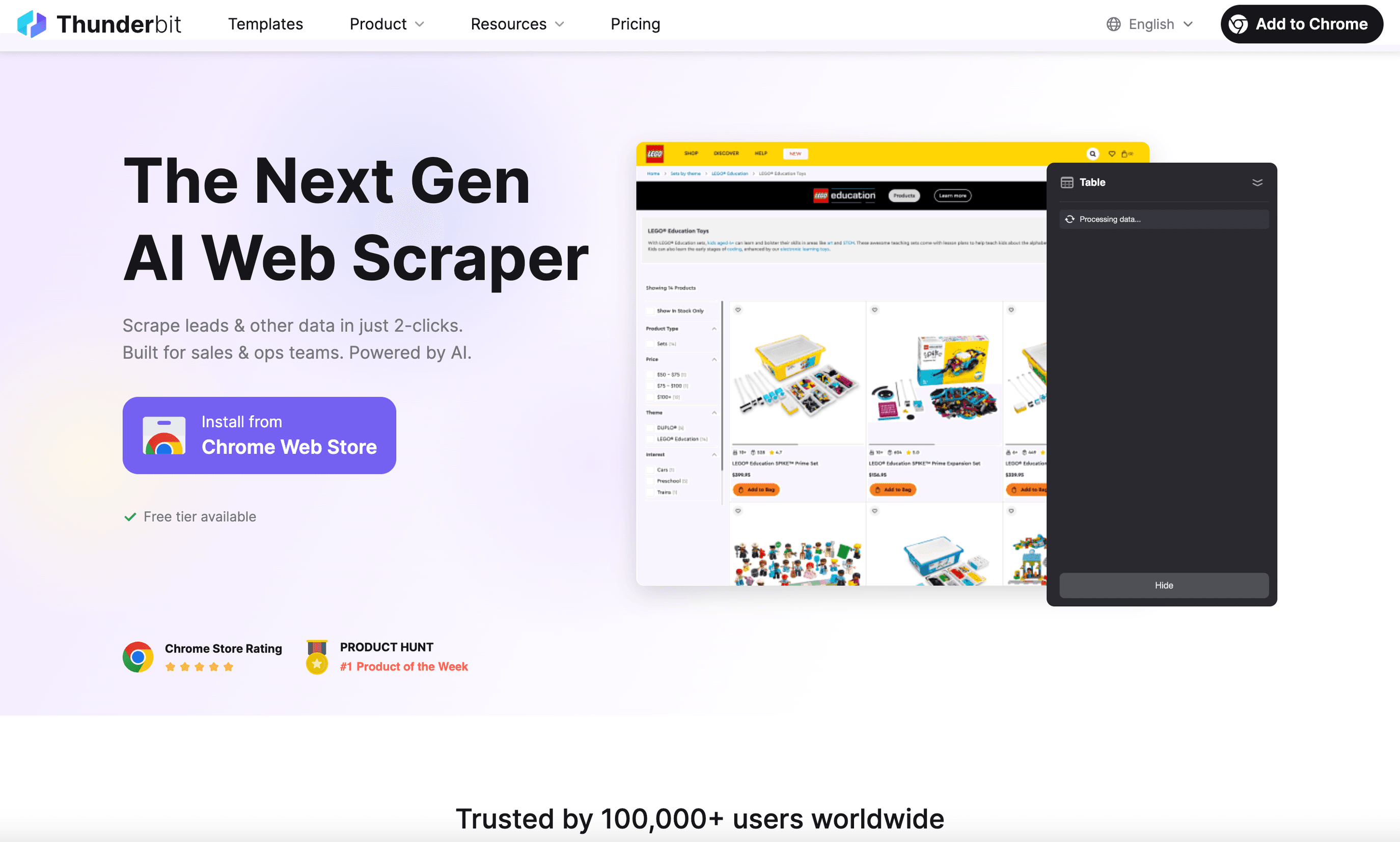 est mon premier choix pour les utilisateurs métier qui veulent un extracteur Web pour Linux vraiment simple à utiliser. En tant qu’, elle fonctionne parfaitement sur Linux (ouvrez simplement Chrome ou Chromium) et vous permet d’extraire des données depuis n’importe quel site en seulement deux clics.
est mon premier choix pour les utilisateurs métier qui veulent un extracteur Web pour Linux vraiment simple à utiliser. En tant qu’, elle fonctionne parfaitement sur Linux (ouvrez simplement Chrome ou Chromium) et vous permet d’extraire des données depuis n’importe quel site en seulement deux clics.
Ce qui distingue Thunderbit :
- Prompts en langage naturel : décrivez simplement ce que vous voulez (« Extraire tous les noms et prix des produits de cette page ») et l’IA de Thunderbit fait le reste.
- Suggestions de champs par IA : un clic suffit ; Thunderbit analyse la page et propose les colonnes ainsi que les types de données — sans sélection manuelle des champs.
- Extraction des sous-pages et pagination : besoin de plus de détails ? Thunderbit peut visiter chaque sous-page (comme les pages de détail produit) et enrichir automatiquement votre tableau.
- Extraction cloud ou locale : extrayez jusqu’à 50 pages en même temps dans le cloud, ou utilisez le mode navigateur pour les sites nécessitant une connexion.
- Export instantané : export en un clic vers Excel, Google Sheets, Airtable, Notion, CSV ou JSON — toujours gratuit.
- Outils bonus : extraction des e-mails, numéros de téléphone et images en un seul clic. Le remplissage automatique par IA peut même automatiser la saisie dans les formulaires.
Tarifs : formule gratuite (6 à 10 pages extraites), formules payantes à partir de 15 $/mois pour 500 lignes (). Les utilisateurs adorent le fait qu’il n’y ait « aucune courbe d’apprentissage » et que cela « transforme des heures de travail en minutes » (). Pour les gros volumes, il peut être nécessaire de fractionner en plusieurs exécutions, mais pour la plupart des cas d’usage métier, le gain de temps est énorme.
Compatibilité Linux : 100 %. Il suffit d’utiliser Chrome/Chromium sur votre ordinateur ou serveur Linux.
Idéal pour : les utilisateurs métier non techniques (vente, marketing, opérations) qui veulent la configuration la plus rapide et la plus simple.
2. Scrapy
 est la référence pour les développeurs Python qui veulent un extracteur Web Linux flexible et scalable. Open source, extrêmement rapide (crawling asynchrone) et capable de tout gérer, des extractions simples aux crawls massifs et distribués.
est la référence pour les développeurs Python qui veulent un extracteur Web Linux flexible et scalable. Open source, extrêmement rapide (crawling asynchrone) et capable de tout gérer, des extractions simples aux crawls massifs et distribués.
Fonctionnalités clés :
- Crawling asynchrone et haute vitesse — parfait pour extraire des milliers de pages.
- Très extensible : plugins pour les proxys, les CAPTCHA, et plus encore.
- Intégration avec la pile Python : export vers JSON, CSV, bases de données ou pandas.
- Gestion des cookies, des sessions et de l’auto-throttling.
Tarifs : 100 % gratuit et open source.
Compatibilité Linux : native (installation via pip). Fonctionne très bien sur serveurs et conteneurs.
Idéal pour : les développeurs qui créent des extracteurs personnalisés à grande échelle.
À savoir : la prise en main est plus technique pour les non-développeurs, mais si vous maîtrisez Python, Scrapy est difficile à battre.
3. Beautiful Soup
 est une bibliothèque Python légère pour analyser le HTML et le XML. C’est l’outil idéal pour une extraction rapide et pragmatique, ou pour nettoyer des pages web mal structurées.
est une bibliothèque Python légère pour analyser le HTML et le XML. C’est l’outil idéal pour une extraction rapide et pragmatique, ou pour nettoyer des pages web mal structurées.
Fonctionnalités clés :
- API simple et intuitive — parfaite pour les débutants.
- Se combine bien avec requests pour récupérer les pages.
- Gère proprement le HTML cassé.
Tarifs : gratuit et open source.
Compatibilité Linux : 100 % (Python pur).
Idéal pour : les développeurs et data scientists qui réalisent des tâches d’extraction ou d’analyse de petite à moyenne taille.
Limites : ne gère pas JavaScript ni le contenu dynamique — combinez-le avec Selenium ou Puppeteer si nécessaire.
4. Selenium
 est le framework classique d’automatisation de navigateur. Il vous permet de contrôler Chrome, Firefox ou d’autres navigateurs pour extraire des sites dynamiques très chargés en JavaScript.
est le framework classique d’automatisation de navigateur. Il vous permet de contrôler Chrome, Firefox ou d’autres navigateurs pour extraire des sites dynamiques très chargés en JavaScript.
Fonctionnalités clés :
- Automatise de vrais navigateurs — peut se connecter, cliquer, faire défiler et interagir comme un humain.
- Prend en charge Python, Java, C# et plus encore.
- Mode headless pour l’exécution sur des serveurs Linux.
Tarifs : gratuit et open source.
Compatibilité Linux : prise en charge complète (il suffit d’installer le bon pilote de navigateur).
Idéal pour : les ingénieurs QA, les développeurs d’extraction et toute personne devant simuler le comportement d’un utilisateur.
À savoir : gourmand en ressources et plus lent que les extracteurs purement HTTP, mais parfois c’est la seule façon d’obtenir les données dont vous avez besoin.
5. Puppeteer
 est une bibliothèque Node.js de Google pour contrôler Chrome/Chromium en mode headless. C’est un peu comme Selenium, mais avec une API JavaScript moderne et une intégration étroite avec les fonctionnalités de Chrome.
est une bibliothèque Node.js de Google pour contrôler Chrome/Chromium en mode headless. C’est un peu comme Selenium, mais avec une API JavaScript moderne et une intégration étroite avec les fonctionnalités de Chrome.
Fonctionnalités clés :
- Exécute JavaScript, gère le contenu dynamique et capture des captures d’écran.
- Rapide, stable et simple à utiliser pour les développeurs Node.js.
- Intercepte les requêtes réseau et bloque les ressources indésirables.
Tarifs : gratuit et open source.
Compatibilité Linux : installe Chromium automatiquement ; fonctionne par défaut en mode headless.
Idéal pour : les développeurs qui extraient des applications web modernes ou des sites monopage.
6. Octoparse
 est un extracteur Web sans code avec interface glisser-déposer et de nombreux modèles prêts à l’emploi. Si l’application de bureau est réservée à Windows/Mac, les utilisateurs Linux peuvent accéder à la plateforme cloud d’Octoparse via navigateur ou exécuter l’application Windows avec Wine.
est un extracteur Web sans code avec interface glisser-déposer et de nombreux modèles prêts à l’emploi. Si l’application de bureau est réservée à Windows/Mac, les utilisateurs Linux peuvent accéder à la plateforme cloud d’Octoparse via navigateur ou exécuter l’application Windows avec Wine.
Fonctionnalités clés :
- Plus de 100 modèles d’extraction prêts à l’emploi pour des sites comme Amazon, eBay, Zillow, etc.
- Concepteur de workflow visuel — cliquez pour construire votre extracteur.
- Extraction cloud et planification — laissez les serveurs d’Octoparse faire le gros du travail.
- Export vers Excel, CSV, JSON et bases de données.
Tarifs : formule gratuite (fonctionnalités limitées), formules payantes à partir de 75 à 89 $/mois.
Compatibilité Linux : accès cloud/web ; application de bureau via Wine.
Idéal pour : les non-développeurs qui ont besoin rapidement de données e-commerce ou marketplace.
7. PhantomJS
 est un navigateur WebKit headless qui a longtemps été la référence pour l’automatisation légère de navigateur. Il est désormais obsolète, mais fonctionne encore sous Linux pour des tâches anciennes ou simples.
est un navigateur WebKit headless qui a longtemps été la référence pour l’automatisation légère de navigateur. Il est désormais obsolète, mais fonctionne encore sous Linux pour des tâches anciennes ou simples.
Fonctionnalités clés :
- Scriptable en JavaScript.
- Gère un JavaScript modéré et produit des captures d’écran/PDF.
- Aucune interface graphique nécessaire.
Tarifs : gratuit et open source.
Compatibilité Linux : binaire natif.
Idéal pour : les projets hérités ou les environnements où l’installation de Chrome est impossible.
Réserve : le projet n’est plus maintenu — les sites modernes peuvent ne pas fonctionner correctement.
8. ParseHub
 est un extracteur Web visuel, multiplateforme, avec une application native pour Linux. C’est une excellente solution pour les non-développeurs qui veulent extraire des sites complexes et dynamiques.
est un extracteur Web visuel, multiplateforme, avec une application native pour Linux. C’est une excellente solution pour les non-développeurs qui veulent extraire des sites complexes et dynamiques.
Fonctionnalités clés :
- Interface point-and-click — sélectionnez des éléments et construisez vos workflows visuellement.
- Gère le contenu dynamique, les cartes, le défilement infini, et plus encore.
- Exécution cloud et planification.
- Export vers CSV, JSON ou via API.
Tarifs : formule gratuite (5 projets), formules payantes à partir de 189 $/mois.
Compatibilité Linux : application native pour Linux, Windows et Mac.
Idéal pour : les analystes et utilisateurs semi-techniques qui veulent du contrôle sans coder.
9. Kimurai
 est un framework d’extraction Web Ruby qui prend en charge Linux nativement. C’est un peu comme Scrapy, mais pour les développeurs Ruby.
est un framework d’extraction Web Ruby qui prend en charge Linux nativement. C’est un peu comme Scrapy, mais pour les développeurs Ruby.
Fonctionnalités clés :
- Prise en charge de plusieurs navigateurs : Headless Chrome, Firefox, PhantomJS ou HTTP simple.
- Traitement asynchrone pour une forte concurrence.
- DSL Ruby propre pour écrire des spiders.
Tarifs : gratuit et open source.
Compatibilité Linux : 100 % (Ruby).
Idéal pour : les développeurs Ruby ou les équipes Rails qui ont besoin d’une extraction personnalisée à forte concurrence.
10. Apify
 est une plateforme d’extraction Web basée sur le cloud avec des SDK open source et une place de marché d’« actors » prêts à l’emploi. Vous pouvez exécuter des extracteurs sur votre machine Linux ou dans le cloud.
est une plateforme d’extraction Web basée sur le cloud avec des SDK open source et une place de marché d’« actors » prêts à l’emploi. Vous pouvez exécuter des extracteurs sur votre machine Linux ou dans le cloud.
Fonctionnalités clés :
- SDK pour Node.js, Python, et plus encore.
- Place de marché d’extracteurs préconstruits.
- Exécution cloud, planification et intégration API.
Tarifs : formule gratuite, paiement à l’usage pour l’utilisation du cloud.
Compatibilité Linux : le CLI/SDK fonctionne sur Linux ; la plateforme cloud est accessible via navigateur.
Idéal pour : les développeurs qui veulent un mélange de code personnalisé et d’infrastructure cloud prête à l’emploi.
11. Colly
 est un framework d’extraction Web basé sur Go, conçu pour la vitesse et l’efficacité. Si vous êtes développeur Go, c’est votre outil.
est un framework d’extraction Web basé sur Go, conçu pour la vitesse et l’efficacité. Si vous êtes développeur Go, c’est votre outil.
Fonctionnalités clés :
- Extraction ultra-rapide et concurrente — plus de 1 000 requêtes/s sur un seul cœur.
- Crawling respectueux (respecte robots.txt), gestion des sessions et des cookies.
- Faible empreinte mémoire.
Tarifs : gratuit et open source.
Compatibilité Linux : binaires Go natifs.
Idéal pour : les développeurs Go qui ont besoin d’une extraction haute performance.
12. PySpider
 est un système de crawling Web Python avec interface web. Vous pouvez gérer, planifier et surveiller les crawls depuis votre navigateur.
est un système de crawling Web Python avec interface web. Vous pouvez gérer, planifier et surveiller les crawls depuis votre navigateur.
Fonctionnalités clés :
- Interface web pour le scripting et le suivi.
- Crawling distribué, planification et relances automatiques.
- Intégration avec des bases de données et des files de messages.
Tarifs : gratuit et open source.
Compatibilité Linux : conçu pour un déploiement sur Linux.
Idéal pour : les équipes qui gèrent plusieurs projets d’extraction via une interface web.
13. WebHarvy
 est un extracteur visuel point-and-click pour Windows, mais les utilisateurs Linux peuvent le faire fonctionner via Wine. Il est connu pour sa détection de motifs et son modèle d’achat unique.
est un extracteur visuel point-and-click pour Windows, mais les utilisateurs Linux peuvent le faire fonctionner via Wine. Il est connu pour sa détection de motifs et son modèle d’achat unique.
Fonctionnalités clés :
- Naviguez et cliquez pour sélectionner les données — sans coder.
- Détection automatique des motifs pour les listes.
- Export vers CSV, JSON, XML, SQL.
Tarifs : licence unique d’environ 139 $.
Compatibilité Linux : fonctionne sous Wine ou dans une VM.
Idéal pour : les débutants ou les professionnels indépendants qui veulent un extracteur visuel rapide.
14. OutWit Hub
 est une application GUI native pour Linux dédiée à l’extraction Web. Elle reconnaît automatiquement les motifs de données et propose de puissantes fonctionnalités d’extraction et d’automatisation.
est une application GUI native pour Linux dédiée à l’extraction Web. Elle reconnaît automatiquement les motifs de données et propose de puissantes fonctionnalités d’extraction et d’automatisation.
Fonctionnalités clés :
- Détecte automatiquement les liens, images, tableaux, e-mails, et plus encore.
- Éditeur de scripts pour des extractions personnalisées.
- Automatisation par macros et planification.
Tarifs : version gratuite (limitée), licence Pro d’environ 50 à 100 $.
Compatibilité Linux : application native pour Linux, Windows et Mac.
Idéal pour : les non-développeurs avec une certaine sensibilité technique qui veulent un extracteur avec interface de bureau.
15. Portia
 est un extracteur Web visuel open source signé Scrapinghub. Il fonctionne dans votre navigateur et vous permet d’annoter des pages pour entraîner des extracteurs.
est un extracteur Web visuel open source signé Scrapinghub. Il fonctionne dans votre navigateur et vous permet d’annoter des pages pour entraîner des extracteurs.
Fonctionnalités clés :
- Interface web pour l’extraction visuelle.
- Intégration avec Scrapy pour les projets personnalisés.
- Open source et extensible.
Tarifs : gratuit et open source.
Compatibilité Linux : basé sur le navigateur ; fonctionne sur n’importe quel OS.
Idéal pour : les utilisateurs qui veulent une extraction visuelle open source avec intégration Scrapy.
16. Content Grabber
 est un extracteur visuel de niveau enterprise pour Windows, mais peut être exécuté sur Linux via Wine ou virtualisation.
est un extracteur visuel de niveau enterprise pour Windows, mais peut être exécuté sur Linux via Wine ou virtualisation.
Fonctionnalités clés :
- Éditeur visuel + scripting C# pour une logique avancée.
- Gestion multi-agents et planification.
- Intégration avec des bases de données, des API, et plus encore.
Tarifs : licences à plusieurs milliers de dollars ; édition serveur à partir de 69 $/mois.
Compatibilité Linux : via Wine ou VM.
Idéal pour : les agences et grandes équipes qui gèrent de nombreux projets d’extraction.
17. Helium
 est une bibliothèque Python qui simplifie l’automatisation avec Selenium. Elle a été conçue pour rendre le scripting de navigateur plus naturel et plus humain.
est une bibliothèque Python qui simplifie l’automatisation avec Selenium. Elle a été conçue pour rendre le scripting de navigateur plus naturel et plus humain.
Fonctionnalités clés :
- Commandes intuitives comme
click("Login")ouwrite("email"). - Automatise Chrome et Firefox.
- Très utile pour les tâches de scripting rapide et d’automatisation.
Tarifs : gratuit et open source.
Compatibilité Linux : fonctionne sur Linux (basé sur Selenium).
Idéal pour : les utilisateurs Python qui trouvent Selenium trop lourd.
18. Dexi.io
 est une plateforme d’extraction de données et d’automatisation basée sur le cloud. Accessible via navigateur, elle ne nécessite aucune installation pour les utilisateurs Linux.
est une plateforme d’extraction de données et d’automatisation basée sur le cloud. Accessible via navigateur, elle ne nécessite aucune installation pour les utilisateurs Linux.
Fonctionnalités clés :
- Concepteur de workflows visuel pour l’extraction et l’automatisation.
- Planification, transformation des données et intégration API.
- Scalabilité et support de niveau enterprise.
Tarifs : à partir de 119 $/mois (Standard) ; des niveaux supérieurs pour les besoins plus importants.
Compatibilité Linux : application web — fonctionne sur n’importe quel OS.
Idéal pour : les professionnels et entreprises qui ont besoin d’une extraction de données Web intégrée et scalable.
Tableau comparatif rapide : les outils d’extraction Web Linux en un coup d’œil
| Outil | Type / Fonctionnalités clés | Idéal pour | Tarifs | Compatibilité Linux |
|---|---|---|---|---|
| Thunderbit | Extension Chrome IA, 2 clics, sous-pages, cloud/local | Utilisateurs métier non techniques | Gratuit, à partir de 15 $/mois | ✔ Chrome sur Linux |
| Scrapy | Framework Python, async, CLI, très extensible | Développeurs, extracteurs custom à grande échelle | Gratuit | ✔ Natif |
| Beautiful Soup | Bibliothèque Python, analyse simple HTML/XML | Devs, data scientists, petites tâches | Gratuit | ✔ Natif |
| Selenium | Automatisation de navigateur, sites riches en JS | QA, devs, contenu dynamique | Gratuit | ✔ Natif |
| Puppeteer | Node.js, Chrome headless, rendu JS | Devs Node, applications web modernes | Gratuit | ✔ Natif |
| Octoparse | Sans code, glisser-déposer, modèles cloud | Non-développeurs, e-commerce | Gratuit, à partir de 75 $/mois | ◐ Cloud/Wine |
| PhantomJS | WebKit headless, JS scriptable | Héritage, léger, sans Chrome | Gratuit | ✔ Natif |
| ParseHub | Visuel, multiplateforme, point-and-click | Analystes, utilisateurs semi-techniques | Gratuit, à partir de 189 $/mois | ✔ Natif |
| Kimurai | Framework Ruby, multi-navigateurs, async | Devs Ruby, forte concurrence | Gratuit | ✔ Natif |
| Apify | Plateforme cloud, SDK, marketplace | Devs, hybride personnalisé/cloud | Formule gratuite, usage payant | ✔ Natif/Cloud |
| Colly | Framework Go, rapide, concurrent | Devs Go, haute performance | Gratuit | ✔ Natif |
| PySpider | Python, interface web, planification, distribué | Équipes, projets multiples | Gratuit | ✔ Natif |
| WebHarvy | Visuel, détection de motifs, licence unique | Débutants, pros solo | ~139 $ unique | ◐ Wine/VM |
| OutWit Hub | GUI native, détection auto des données, scripting | Non-développeurs, GUI de bureau | Gratuit, Pro 50 à 100 $ | ✔ Natif |
| Portia | Open source, visuel, basé sur navigateur | Open source, intégration Scrapy | Gratuit | ✔ Navigateur |
| Content Grabber | Enterprise, visuel, scripting, multi-agent | Agences, grandes équipes | $$$, à partir de 69 $/mois | ◐ Wine/VM |
| Helium | Python, Selenium simplifié, API intuitive | Utilisateurs Python, automatisation rapide | Gratuit | ✔ Natif |
| Dexi.io | Cloud, workflow visuel, planification, API | Enterprise, automatisation scalable | À partir de 119 $/mois | ✔ Navigateur |
Comment choisir le bon extracteur Web pour Linux : critères clés
Choisir le bon outil, c’est avant tout aligner vos besoins et vos compétences :
- Niveau technique : les non-développeurs devraient se tourner vers Thunderbit, ParseHub, Octoparse ou OutWit Hub. Les développeurs peuvent aller plus loin avec Scrapy, Puppeteer, Colly ou Kimurai.
- Complexité des données : pour les pages statiques, Beautiful Soup ou Colly sont rapides et simples. Pour les sites dynamiques riches en JavaScript, il vaut mieux utiliser Selenium, Puppeteer ou un outil visuel compatible JS.
- Échelle et fréquence : pour des besoins ponctuels, les outils sans code ou les extracteurs cloud conviennent très bien. Pour des crawls planifiés à grande échelle, privilégiez Scrapy, PySpider ou Apify.
- Besoins d’intégration : besoin d’exporter vers Excel, Sheets ou une base de données ? Vérifiez que l’outil s’intègre bien à votre flux de travail.
- Budget : les options gratuites et open source ne manquent pas pour les codeurs. Pour les utilisateurs métier, Thunderbit et ParseHub offrent des points d’entrée abordables, tandis que les équipes enterprise peuvent investir dans Dexi.io ou Content Grabber.
- Support et communauté : les outils open source disposent de grandes communautés ; les outils commerciaux offrent un support dédié.
Conseil de pro : n’hésitez pas à combiner les outils. Utilisez Thunderbit pour prototyper et repérer les structures de données, puis passez à Scrapy pour des crawls à l’échelle de la production. Ou utilisez Selenium pour vous connecter et récupérer les cookies de session, puis confiez l’extraction haute vitesse à Colly ou Scrapy.
Conclusion : trouvez votre meilleur outil d’extraction Web Linux pour 2026
Les utilisateurs Linux ont l’embarras du choix en 2026. Que vous vouliez un outil sans code propulsé par l’IA qui vous donne des résultats en quelques minutes (Thunderbit), un framework développeur robuste (Scrapy, Colly) ou une plateforme de niveau enterprise (Dexi.io), il existe un extracteur Web pour Linux adapté à vos besoins et à votre flux de travail.
À retenir :
- Linux est la colonne vertébrale de l’infrastructure de données moderne — la plupart des meilleurs extracteurs fonctionnent nativement ou via navigateur.
- Les outils IA et sans code démocratisent l’extraction Web pour les utilisateurs métier.
- Les frameworks développeur restent incontournables pour la flexibilité, la vitesse et le passage à l’échelle.
- Essayez avant d’acheter : la plupart des outils proposent des formules gratuites ou des essais.
Prêt à vous lancer ? ou consultez le pour d’autres guides sur l’extraction Web, l’automatisation et la croissance pilotée par la donnée.
FAQ
1. Quel est l’extracteur Web Linux le plus simple si je ne sais pas coder ?
est le meilleur choix pour les utilisateurs non techniques. Il fonctionne comme une extension Chrome sur Linux, utilise l’IA pour tout automatiser et vous permet d’extraire des données en seulement deux clics.
2. Quel extracteur Web Linux est le meilleur pour les projets personnalisés à grande échelle ?
est la référence pour les développeurs. Rapide, scalable et hautement personnalisable, il est parfait pour les gros crawls récurrents.
3. Puis-je extraire sur Linux des sites riches en JavaScript ou dynamiques ?
Oui ! Utilisez ou pour contrôler de vrais navigateurs et extraire du contenu dynamique. Les outils visuels comme ParseHub et Thunderbit prennent aussi en charge les sites dynamiques.
4. Existe-t-il des outils d’extraction Web Linux gratuits pour un usage métier ?
Absolument. Scrapy, Beautiful Soup, Selenium, Colly, PySpider et Kimurai sont tous gratuits et open source. Thunderbit et ParseHub proposent aussi des formules gratuites pour les petits volumes.
5. Comment choisir entre un extracteur Linux sans code et un outil basé sur du code ?
Si vous voulez aller vite et rester simple, optez pour le sans code (Thunderbit, ParseHub, Octoparse). Si vous avez besoin de flexibilité, d’automatisation ou d’intégration avec d’autres systèmes, les outils basés sur du code (Scrapy, Puppeteer, Colly) sont votre meilleur choix.
Bon scraping — et que vos projets de données sous Linux tournent plus fluidement qu’une installation toute neuve d’Ubuntu. Si vous voulez voir davantage d’astuces sur l’extraction Web, consultez le ou abonnez-vous à notre pour des tutoriels pratiques.
En savoir plus