Votre CRM n’est aussi fiable que les données que tu y fais entrer. Et soyons clairs : les meilleures infos sont souvent planquées sur des sites publics — pas dans des bases tierces hors de prix qui te vendent du “déjà vu”.
Les extracteurs web transforment ce bazar en tableaux propres, carrés, directement exploitables. Et les meilleurs font ça en quelques minutes, sans que tu aies à écrire la moindre ligne de code.
J’ai utilisé ces outils sur des projets bien réels — création de listes de prospects, suivi des prix des concurrents, extraction de catalogues produits. Voici 12 solutions qui ont vraiment assuré, classées selon leur efficacité sur des tâches business concrètes.
Pourquoi les extracteurs web sont devenus indispensables en entreprise
Soyons honnêtes : le web, c’est la plus grande base de données au monde… et aussi la plus chaotique. En 2026, les boîtes capables de transformer ce chaos en insights prennent une vraie longueur d’avance. D’après des , les organisations pilotées par la donnée sont 5 % plus productives et 6 % plus rentables que leurs pairs. Ce n’est pas un “petit plus” : c’est un avantage compétitif net.
Les outils d’extraction web (aussi appelés extracteurs de pages web ou solutions d’extraction web) sont le moteur de cette bascule. Ils permettent aux équipes commerciales de collecter des données depuis des annuaires publics, les réseaux sociaux et les sites d’entreprises pour créer des listes de prospects ciblées — terminé l’achat de fichiers de leads périmés ou les marathons de copier-coller en espérant que le stagiaire ne fasse pas un burn-out à mi-parcours (). Les équipes marketing et e-commerce s’en servent pour suivre les prix des concurrents, surveiller les stocks et comparer les produits en temps réel — John Lewis, par exemple, attribue au web scraping une hausse de 4 % des ventes grâce à une tarification plus intelligente ().
Mais ce n’est pas qu’une histoire de KPI. Les extracteurs web font gagner un temps énorme (un utilisateur parle de « centaines d’heures » économisées grâce à l’automatisation de la collecte) et limitent les erreurs humaines (). Les équipes ops mettent maintenant en place des scrapers qui collectent en continu des données qui auraient pris des semaines à des stagiaires — en récupérant des heures autrefois englouties dans du copier-coller répétitif (). Et avec les extracteurs pilotés par l’IA, même les profils non techniques peuvent convertir des sites web en données structurées prêtes à être analysées ().
En clair : si tu n’utilises pas d’extracteur web en 2026, tu laisses probablement des insights (et de l’argent) sur la table.
Comment nous avons sélectionné les 12 meilleurs extracteurs web
Avec la tonne d’outils d’extraction web disponibles, comment choisir le bon ? J’ai passé au crible des dizaines de solutions, mais seules 12 ont fait la sélection. Voici les critères principaux :
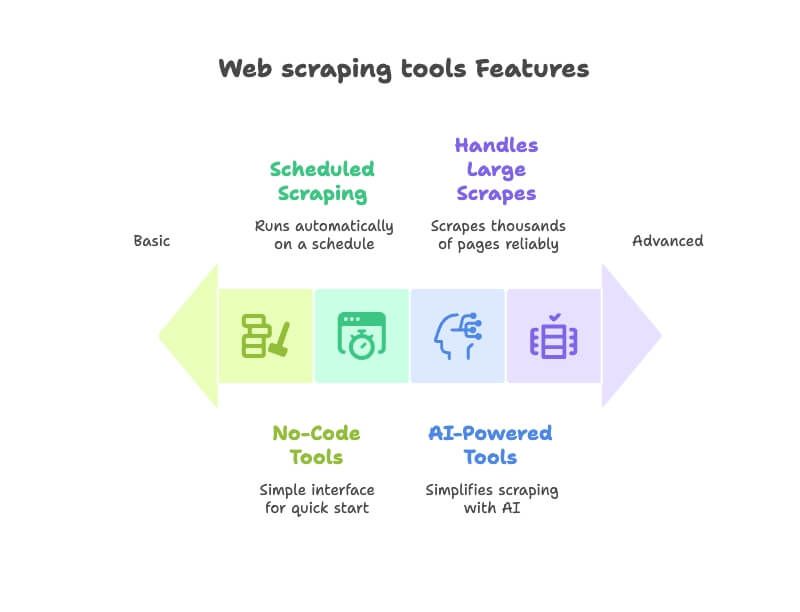
- Facilité d’utilisation : est-ce qu’un utilisateur non technique peut démarrer vite, sans coder ? J’ai favorisé les outils no-code/low-code avec une interface intuitive ().
- Fonctionnalités IA : les outils nouvelle génération qui simplifient l’extraction grâce à l’IA — détection automatique des champs, navigation sur le site, ou possibilité d’exprimer le besoin en langage naturel ().
- Automatisation & planification : les meilleurs extracteurs tournent en mode autopilote. J’ai retenu ceux qui permettent de planifier des extractions récurrentes ou de surveiller des sites ().
- Export & intégrations : export facile vers Excel, Google Sheets, Airtable ou Notion ? Bonus pour les intégrations de workflow ().
- Scalabilité et fiabilité : que ce soit une page ou des milliers, l’outil doit tenir la charge. J’ai aussi regardé les retours utilisateurs sur la stabilité.
- Cas d’usage orientés business : priorité aux outils adoptés par les équipes sales, marketing, e-commerce et opérations — pas uniquement par les devs.
Certaines solutions sont des nouveaux acteurs boostés à l’IA, d’autres des classiques du secteur. Toutes ont le même objectif : faire du web ta base de données métier, sans prise de tête.
Comparatif rapide : les extracteurs web en un coup d’œil
Voici un aperçu des 12 outils présentés, pour capter rapidement leurs différences :
| Outil | Automatisation IA | Facilité d’utilisation | Meilleur cas d’usage |
|---|---|---|---|
| Thunderbit | Oui – l’IA suggère les champs et gère automatiquement les pages | Très facile (extension Chrome, sans code) | Extraction rapide de leads, prix, etc. pour des utilisateurs non techniques qui veulent des résultats en quelques minutes. |
| Octoparse | Limité (basé sur des modèles, pas d’IA) | Facile pour la plupart (interface visuelle en glisser-déposer) | Workflows d’extraction personnalisés (connexions, pagination) pour des analystes qui veulent du contrôle sans coder. |
| Browse AI | Partiel – “robots” en point-and-click | Facile (no-code, cloud) | Suivi automatisé de données (prix, annonces, etc.) sur un planning, avec alertes et intégrations. |
| WebScraper.io | Non (configuration manuelle) | Intermédiaire (extension navigateur avec configuration de sitemap) | Extraction visuelle de sites multi-niveaux pour les utilisateurs prêts à configurer les étapes. |
| ScraperAPI | N/A (service API, gère les proxies via API) | Nécessite du code (intégration API) | Extraction à gros volume pour équipes techniques — proxies & CAPTCHAs gérés pour des scrapes à grande échelle. |
| Data Miner | Non | Très facile (extension navigateur avec modèles en un clic) | Extraction ponctuelle rapide (surtout tableaux ou listes) directement vers CSV/Excel. |
| Simplescraper | Non (quelques fonctions assistées par IA) | Facile (créateur de “recettes” en point-and-click) | Extraction no-code avec intégrations — idéal pour envoyer des données vers Google Sheets, Airtable ou une API. |
| Instant Data Scraper | Oui – détecte automatiquement les tableaux | Très facile (un clic, aucune configuration) | Extraction instantanée et gratuite de tableaux/listes HTML pour tous (parfait pour des besoins rapides). |
| ScrapeStorm | Oui – l’IA identifie les éléments de page | Facile (interface visuelle ; application multiplateforme) | Projets d’extraction complexes ou à grande échelle sans code, y compris des crawls planifiés. |
| Apify | Partiel – “actors” préconstruits disponibles | Intermédiaire (interface web ; code optionnel) | Extraction cloud scalable et automatisation via scripts prêts à l’emploi ou personnalisés. |
| ParseHub | Non (sans scripts mais configuration manuelle) | Facile pour démarrer (éditeur visuel ; application desktop) | Extraction de sites dynamiques/complexes (contenu AJAX) via une interface no-code. |
| OutWit Hub | Non | Facile (application desktop avec interface graphique) | Extraction simple hors ligne et archivage de contenu pour de petits projets. |
La plupart des outils proposent une offre gratuite ou un essai, ainsi que des abonnements par paliers. Ici, l’accent est mis sur les capacités et les cas d’usage plutôt que sur le prix.
Thunderbit : l’Extracteur Web IA accessible à tous

On commence par Thunderbit — oui, c’est mon bébé, mais laisse-moi poser le contexte. Le secteur est en train de passer de « configure ton scraper » à « dis juste à l’IA ce que tu veux ». Thunderbit est le premier outil que j’ai vu (et auquel j’ai contribué) qui ressemble vraiment à un assistant data IA, pas juste à un “crawler”.
Avec , pas besoin de te battre avec XPath, sélecteurs CSS ou regex. Tu décris ce que tu veux en langage naturel — par exemple « récupère le titre, l’auteur et la date sur cette page » — et l’IA gère le reste (). Tu cliques sur « AI Suggest Fields » : Thunderbit analyse la page, propose des colonnes, et gère même automatiquement les sous-pages et la pagination ().
Et ce n’est pas juste “collecter”. Thunderbit peut nettoyer, transformer, catégoriser et même traduire les champs pendant l’extraction. Besoin d’uniformiser des numéros de téléphone, de résumer des descriptions ou de traduire des noms de produits ? Tu ajoutes une instruction, et l’IA s’en charge. Ensuite, export direct vers Excel, Google Sheets, Airtable ou Notion ().
Ce qui distingue vraiment Thunderbit, c’est le zéro config, zéro courbe d’apprentissage. C’est une extension Chrome : tu es opérationnel en quelques secondes. Pas de plugins, pas de paramétrage, pas de jargon technique. C’est pour ça que l’outil est devenu un favori des équipes commerciales, marketing et opérations qui veulent des résultats — vite (). L’offre gratuite permet de tester tout le workflow, et les plans payants restent abordables (souvent « moins que votre budget café mensuel »).
Pour voir concrètement ce que l’extraction web avec IA change, et teste. Tes journées de copier-coller pourraient bien prendre fin.
Octoparse : un Extracteur Web visuel pour des workflows sur mesure
Octoparse, c’est un grand classique du scraping visuel. C’est une app desktop avec une interface en point-and-click : tu interagis avec la page, tu sélectionnes les données, et Octoparse construit le workflow en coulisses (). Connexions, pagination, soumission de formulaires… tu peux tout faire sans coder.
Son gros point fort : une bibliothèque de plus de 500 modèles pour des sites populaires (Amazon, Twitter, LinkedIn, etc.), ce qui permet souvent de démarrer direct (). Pour les sites plus tordus, tu passes en mode manuel et tu configures visuellement chaque étape. Octoparse gère les contenus chargés après clic ou scroll, peut utiliser des proxies et résoudre des CAPTCHAs quand ça se complique. Il existe aussi une option cloud pour planifier et exécuter des extractions à grande échelle.
Le revers : une courbe d’apprentissage, surtout dès que tu vas sur des scénarios avancés. Mais pour les non-développeurs et analystes data qui veulent un workflow d’extraction personnalisé sans code, Octoparse reste une valeur sûre ().
Browse AI : extraction automatisée avec des robots prêts à l’emploi
Browse AI a une approche assez fun : tu “entraînes” un robot en pointant et cliquant sur les données à récupérer, et il apprend à les extraire sur des pages similaires (). Tout est no-code et dans le cloud : pas de scripts, pas de serveurs à gérer.
Là où ça devient vraiment intéressant, c’est l’automatisation et la surveillance. Tu planifies l’exécution des robots et tu reçois des alertes quand les données bougent (baisse de prix d’un concurrent, nouvelle offre d’emploi, etc.). Il y a aussi une bibliothèque de robots préconfigurés pour des tâches courantes, que tu peux ajuster selon ton besoin ().
Browse AI s’intègre à des milliers d’apps via Zapier et Make, et exporte vers Google Sheets ou via API/webhooks (). Idéal pour la surveillance continue et la collecte récurrente, avec alertes et intégrations en mode mains libres.
WebScraper.io : un extracteur de pages web dans le navigateur

WebScraper.io (souvent appelé simplement « Web Scraper ») est une extension de navigateur qui te permet de créer des “sitemaps” — des plans visuels qui expliquent comment naviguer sur un site et quoi extraire (). Tu définis des sélecteurs pour les données et les liens à suivre (par exemple « cliquer sur suivant » pour paginer, ou « visiter chaque fiche produit » pour récupérer les détails).
Il y a une petite courbe d’apprentissage, mais toujours sans code : tu sélectionnes des éléments et tu définis des actions. Web Scraper gère la navigation multi-niveaux, la pagination et même l’infinite scroll (à condition de bien configurer les étapes). Et comme tout se passe dans le navigateur, tu peux extraire des sites derrière un login en te connectant toi-même.
WebScraper.io est top pour des analystes “citoyens” à l’aise avec la structure des pages web, qui veulent un outil gratuit et flexible.
ScraperAPI : un Extracteur Web orienté API pour développeurs et équipes techniques
Toutes les équipes ne veulent pas d’une interface point-and-click : parfois, il faut une solution backend pour pousser les données web directement dans tes apps ou tes bases. ScraperAPI est un extracteur web “API-first” : tu lui donnes une URL, il te renvoie le HTML brut ou les données, en gérant pour toi les proxies, la rotation d’IP géolocalisées, les navigateurs headless et les CAPTCHAs ().
ScraperAPI s’appuie sur plus de 40 millions de proxies dans plus de 50 pays et traite 36 milliards de requêtes par mois (). C’est un excellent choix pour l’extraction automatisée à grande échelle, quand la fiabilité et l’anti-blocage sont non négociables. Il faut savoir coder, mais pour construire des pipelines data ou intégrer le scraping à un produit, ScraperAPI est une référence.
Data Miner : extension Chrome pour extraire rapidement des données

Data Miner est une extension Chrome pensée pour les équipes business et les chercheurs qui doivent récupérer des données rapidement. Elle propose une expérience point-and-click et une bibliothèque de “recettes” prêtes à l’emploi pour des formats courants (tableaux, listes, ou sites spécifiques) ().
Tu installes l’extension, tu ouvres la page cible, puis tu cliques sur l’icône Data Miner. Tu choisis une recette ou tu crées la tienne en sélectionnant des éléments. Parfait pour des besoins ponctuels : un commercial qui extrait une liste de leads depuis un annuaire, ou un responsable e-commerce qui relève les prix concurrents.
Simple, dans le navigateur, idéal pour une extraction interactive et à la demande.
Simplescraper : un Extracteur Web no-code pour des résultats immédiats

Simplescraper porte bien son nom. C’est une extension Chrome no-code (et une web app) qui te permet de sélectionner visuellement des données pour créer une “recette” d’extraction (). Tu peux suivre des liens pour extraire des sous-pages, gérer la pagination, et même transformer ton extraction en endpoint API en un clic.
Là où Simplescraper est vraiment fort, c’est sur les intégrations : envoi direct vers Google Sheets, Airtable ou des outils comme Zapier (). Il existe aussi une exécution cloud, la planification de tâches récurrentes, et une fonction “AI Enhance” pour nettoyer/analyser les données avec GPT.
Si tu veux des résultats rapides et des intégrations simples, Simplescraper fait très bien le job, façon couteau suisse du scraping léger.
Instant Data Scraper : extraction express pour tableaux et listes
Parfois, tu veux les données maintenant, sans config. C’est exactement le délire d’Instant Data Scraper (IDS). Cette extension Chrome gratuite est connue pour l’extraction en un clic des données tabulaires (). Tu actives l’extension : IDS détecte automatiquement les tableaux ou listes. Il peut même gérer la pagination et l’infinite scroll en parcourant les pages automatiquement.
IDS est 100 % gratuit, sans inscription, sans code, sans attente. Parfait pour des besoins urgents ou occasionnels : un commercial qui récupère une liste de prospects, ou un étudiant qui extrait des tableaux Wikipédia. Si l’outil détecte tes données, tu les as en quelques secondes.
ScrapeStorm : Extracteur Web cloud avec assistance IA
ScrapeStorm est un outil de web scraping piloté par l’IA qui mélange interface visuelle et algorithmes avancés (). Tu saisis une URL, et l’IA identifie automatiquement les champs : listes, tableaux, boutons “page suivante”, etc.
ScrapeStorm tourne sur Windows, Mac et Linux et propose une exécution desktop ou cloud. Tu peux planifier des tâches, lancer plusieurs jobs en parallèle, et exporter en Excel, CSV, JSON, ou vers une base de données (). Il est particulièrement apprécié en e-commerce et études de marché, et peut même extraire des données depuis des images ou des PDF grâce à l’IA.
Pour des projets complexes ou à grande échelle avec un assistant “intelligent”, ScrapeStorm vaut clairement le détour.
Apify : marketplace d’extracteurs et plateforme d’automatisation

Apify n’est pas juste un scraper : c’est une plateforme de web scraping et d’automatisation. Tu exécutes des “actors”, des scripts d’extraction ou d’automatisation navigateur. Le vrai plus : la marketplace d’actors prêts à l’emploi pour des besoins courants (). Besoin d’extraire tous les avis d’un site e-commerce ? Il y a de grandes chances qu’un actor existe déjà.
Pour les développeurs, Apify permet d’écrire ses propres scrapers en Node.js ou Python et de les déployer dans le cloud. C’est scalable, automatisable et intégrable via API. Apify colle bien aux power users et aux organisations qui voient la donnée web comme un actif stratégique — extraction continue, gros volumes, intégration dans des pipelines data.
ParseHub : extracteur visuel pour sites complexes

ParseHub est une application desktop (avec options cloud) connue pour gérer des sites dynamiques et complexes. Tu navigues dans une interface type navigateur, tu cliques sur les données, et ParseHub construit le scraper (). Il prend en charge la logique conditionnelle, l’extraction imbriquée, le contenu AJAX, etc.
ParseHub est souvent l’option “plan B” quand d’autres outils se cassent les dents. Utilisé par chercheurs, analystes et petites entreprises sur des sites difficiles. Il y a une courbe d’apprentissage, mais si tu dois extraire un site très complexe sans coder, ParseHub est un excellent choix.
OutWit Hub : extracteur desktop pour l’archivage de contenu

OutWit Hub est un peu “old school”, mais c’est une application desktop super pratique pour collecter et organiser plein de types de contenus (liens, images, adresses email, etc.) (). L’outil ressemble à un navigateur mixé avec un tableur : tu ouvres une page, et OutWit Hub peut extraire tableaux, listes, images, etc.
Très utile pour l’archivage ou la recherche — par exemple extraire tous les posts d’un forum ou télécharger une collection de fichiers. Comme c’est un outil desktop, tu l’exécutes en local et tu gardes tes données sous contrôle. Idéal pour des projets petits à moyens avec une interface simple.
Quel extracteur web choisir selon vos besoins ?
Douze outils, mille scénarios. Voilà mon mémo rapide :
-
Pour les débutants complets ou les besoins ponctuels ultra rapides :
Teste Instant Data Scraper pour des tableaux/listes simples (gratuit et immédiat). Data Miner est aussi très accessible, avec plus de modèles si tu extrais souvent des pages similaires.
-
Pour les utilisateurs non techniques qui veulent du récurrent ou des intégrations :
Thunderbit propose le workflow le plus simple grâce à l’IA — parfait pour sortir des résultats vite et de façon régulière. Browse AI est excellent pour la surveillance continue et les alertes. Simplescraper est idéal si tu veux envoyer les données vers Google Sheets ou une app interne via API.
-
Pour des sites complexes ou des workflows sur mesure sans coder :
Va sur un outil visuel comme Octoparse ou ParseHub. Octoparse est convivial et blindé de modèles. ParseHub gère des sites dynamiques très complexes et offre un contrôle fin. WebScraper.io est aussi une bonne option si tu acceptes de configurer tes sitemaps.
-
Pour les développeurs / data engineers qui ont besoin d’échelle :
ScraperAPI est fait pour intégrer le scraping dans un logiciel ou industrialiser des projets volumineux. Apify est parfait si tu veux une plateforme scalable avec marketplace de scripts prêts à l’emploi ou personnalisés.
-
Pour l’extraction orientée contenu ou l’usage hors ligne :
OutWit Hub est un bon choix pour collecter et archiver du contenu de façon systématique, surtout si tu préfères un outil desktop pour la confidentialité ou le contrôle.
Dans la vraie vie, beaucoup d’équipes utilisent plusieurs outils selon le besoin. Tu peux démarrer avec Instant Data Scraper pour un cas simple, passer à Thunderbit ou Octoparse pour un projet plus ambitieux, puis utiliser ScraperAPI ou Apify quand il faut industrialiser. Bonne nouvelle : la plupart proposent une offre gratuite ou un essai, donc tu peux tester et choisir ce qui colle à ton contexte.
Conclusion : l’avenir de l’extraction web pour les équipes business
Les outils d’extraction web ont énormément évolué. En 2026, ils sont devenus grand public. La tendance majeure ? Le web scraping devient plus simple, plus automatisé et mieux intégré aux workflows du quotidien (). Les scrapers boostés à l’IA permettent de dompter des sites complexes et dynamiques sans compétences spécialisées. Comme l’expliquait un data engineer : « Depuis l’arrivée des outils de web scraping IA, je termine les tâches beaucoup plus vite et à plus grande échelle… avec l’IA, le [nettoyage des données] est automatiquement intégré à mon workflow. »
Autre évolution : la frontière devient floue entre extraction, monitoring et automatisation. Des outils comme Browse AI et Thunderbit ne font pas qu’extraire : ils gardent les données à jour et peuvent même déclencher des actions (remplir des formulaires, envoyer des alertes). L’adoption explose : une grande plateforme a vu ses utilisateurs actifs mensuels augmenter de plus de 140 % en un an (). Les entreprises comprennent que l’accès aux données publiques du web (de manière éthique et légale) est indispensable pour rester compétitives.
Pour les équipes business, le message est limpide : autonomie. Plus besoin d’attendre des semaines un développeur ni de décider “au feeling”. Les outils de cette liste mettent la donnée web à portée de main, avec des interfaces et fonctionnalités pensées pour des cas d’usage réels en sales, marketing, opérations, et au-delà. Et vu la vitesse à laquelle ça bouge, on peut s’attendre à des interfaces encore plus simples, une IA plus fine et des intégrations plus profondes avec les plateformes BI et analytics.
Garde quand même un point en tête : respecte les conditions d’utilisation des sites et les règles robots.txt, et assure-toi d’être conforme aux lois sur la protection des données. Un scraping éthique, c’est la base si tu veux que ça dure.
Que tu commences avec une extension gratuite ou que tu déploies une flotte d’extraction “enterprise”, il n’y a jamais eu de meilleur moment pour transformer l’info du web en décisions actionnables. La révolution des extracteurs web est là — choisis un outil, teste-le, et révèle la valeur cachée sous tes yeux. Ton futur piloté par la donnée n’est qu’à un clic.
FAQs
1. Qu’est-ce qu’un extracteur web et pourquoi est-ce important pour les entreprises ?
Un extracteur web est un outil qui collecte automatiquement des données structurées depuis des sites web. Il est essentiel car il permet de transformer des informations en ligne désordonnées en insights actionnables — en améliorant la productivité, la rentabilité et en supprimant la collecte manuelle.
2. Qui peut utiliser des extracteurs web — faut-il des compétences techniques ?
Non, de nombreux extracteurs web modernes ne demandent aucune compétence technique. Des outils comme Thunderbit, Browse AI et Instant Data Scraper sont conçus pour des utilisateurs non techniques, avec des interfaces intuitives, de l’automatisation par IA et des workflows no-code.
3. Comment les équipes sales, marketing et opérations peuvent-elles en bénéficier ?
Les équipes commerciales peuvent créer des listes de prospects depuis des annuaires en ligne, le marketing peut surveiller les prix des concurrents, et les opérations peuvent automatiser des processus de collecte. Ces outils font gagner du temps, réduisent les erreurs et fournissent des insights fiables pour des décisions stratégiques.
4. Quels critères regarder pour choisir un outil d’extraction web ?
Les points clés : facilité d’utilisation, capacités IA, automatisation/planification, intégrations (Google Sheets, Airtable, etc.), scalabilité, et adéquation avec votre cas d’usage (leads, suivi des prix, archivage de contenu…).
5. Existe-t-il des extracteurs web gratuits ou peu coûteux ?
Oui. Beaucoup proposent une offre gratuite ou des plans abordables. Instant Data Scraper est entièrement gratuit pour les besoins basiques, tandis que Thunderbit, Simplescraper et Data Miner offrent des plans gratuits généreux avec des options de montée en gamme.
Envie d’aller plus loin sur l’extraction web, le scraping IA, ou la façon de transformer des sites en avantage compétitif pour ton équipe ? Consulte le pour d’autres guides, conseils et retours terrain sur l’automatisation des données.