

Temu rassemble désormais plus de 416 millions d’utilisateurs actifs mensuels répartis sur plus de 50 marchés. Son catalogue ratisse large : gadgets de cuisine, accessoires pour animaux, bandes LED, et tout le reste. Toute personne active dans l’e-commerce, le dropshipping ou la veille concurrentielle a sans doute déjà rêvé de déverser les données Temu dans un tableur — avant de buter sur un constat : Temu refuse catégoriquement de vous laisser faire.
J’ai investi énormément de temps à explorer et tester des outils de scraping pour les sites e-commerce protégés. Temu se classe parmi les cibles les plus coriaces qui soient. Les guides en ligne, eux, oscillent entre deux extrêmes : un tutoriel Python qui rend l’âme en une semaine, ou des API d’entreprise dont le prix dépasse votre budget publicitaire mensuel.
Or, dans les faits, la majorité des utilisateurs métier — dropshippers, indépendants, équipes marketing — réclament une seule chose : un tableur propre rassemblant noms de produits, prix, images, notes et infos vendeur. Déboguer des scripts Playwright à 2 h du matin ne figure nulle part sur leur liste de souhaits.
Ce guide vient combler exactement ce vide : un comparatif concret, organisé par niveau, des meilleurs extracteurs Temu qui tiennent réellement la route en 2026, complété par les bonnes pratiques qui métamorphosent un simple scrape en veille concurrentielle continue. Débutant complet ou développeur en train d’assembler un pipeline de données, vous trouverez ici une section taillée pour vous.
Essayez Thunderbit pour extraire Temu
Pourquoi extraire Temu ? Les principaux cas d’usage pour les équipes métier
Les données Temu ne se contentent pas d’être curieuses : elles ont une valeur stratégique.
La plateforme s’est muée en force qui tire les prix vers le bas dans les catégories à faible et moyen ticket. Même sans vendre sur Temu, vous êtes concerné : vos clients confrontent vos prix à ceux qu’ils y repèrent. Voici comment différentes équipes exploitent ces données :
| Cas d’usage | Données nécessaires | Pourquoi c’est important |
|---|---|---|
| Recherche de produits pour dropshipping | Titre, prix, image, note, nombre d’avis, nombre d’unités vendues, variantes | Repère des produits à faible coût avec des signaux de demande, à comparer sur Amazon, Shopify, AliExpress, TikTok Shop |
| Tarification concurrentielle | Prix actuel, prix initial, pourcentage de remise, devise, expédition, horodatage | Établit une base pour la stratégie tarifaire et la planification promotionnelle |
| Approvisionnement produit | Caractéristiques, images, variantes, vendeur/boutique, ID produit, catégorie | Identifie les types de produits et les annonces de type fournisseur qui méritent une vérification approfondie |
| Analyse des tendances du marché | Mot-clé de recherche, catégorie, nombre d’unités vendues, nombre d’avis, note | Montre quels produits gagnent du terrain selon les catégories |
| Marketing et recherche créative | Titre, image, nombre d’avis, note, descriptions, libellés de catégorie | Révèle les messages, accroches visuelles, bundles et promesses utilisés par les annonces à fort volume |
| Suivi des stocks et des disponibilités | URL du produit, disponibilité, estimation d’expédition, prix, horodatage | Détecte les ruptures, les changements d’entrepôt local et les variations de prix dans le temps |
Le public qui traque les « meilleurs extracteurs Temu » se répartit en général en trois camps. Les utilisateurs non techniques veulent une extension Chrome qui exporte vers un tableur. Les opérateurs semi-techniques veulent un outil visuel avec modèles et planification. Les développeurs veulent une API, un script Playwright et une stratégie de proxy.
Cet article aborde les trois — mais il s’ouvre sur le plus large : ceux qui ont besoin de données, pas de code.
Ce qui distingue les meilleurs extracteurs Temu en 2026
Un extracteur qui assure sur Amazon ou Shopify ne survivra pas forcément à Temu. Les critères d’évaluation retenus dans cet article sont les suivants :
- Fiabilité sur Temu — renvoie-t-il vraiment des données propres, ou se fait-il bloquer, ramène-t-il des lignes vides, ou casse-t-il après un changement de mise en page ?
- Facilité d’utilisation — un utilisateur métier non technique peut-il démarrer sans écrire de code ?
- Complétude des données — prend-il en charge l’enrichissement des sous-pages (visite de chaque page de détail produit pour les caractéristiques, variantes, infos vendeur) ?
- Charge de maintenance — s’ajuste-t-il quand Temu remanie sa structure de page ?
- Planification et supervision — sait-il lancer des extractions récurrentes et exporter vers une destination de données vivante ?
- Destinations d’export — CSV, Excel, Google Sheets, Airtable, Notion, JSON ?
- Lisibilité des coûts — combien coûte vraiment, par mois, un flux de scraping Temu réaliste ?
Sur r/webscraping de Reddit, les retours de la communauté rangent régulièrement Temu parmi les sites e-commerce les plus rétifs à l’extraction. Un utilisateur confiait qu’il « n’arrive même pas à obtenir un prix en tant qu’acheteur », tandis qu’un autre soulignait que Temu et Shopee mobilisent des équipes qui musclent en continu leurs mécanismes anti-bot. Aucun benchmark public ne mesure le taux d’échec propre à Temu, mais le rapport Imperva Bad Bot 2025 a établi que le trafic automatisé avait dépassé le trafic humain, les bots pesant 51 % de tout le trafic Internet. Voilà l’environnement contre lequel Temu monte ses défenses.
Défenses anti-bot de Temu : pourquoi la plupart des extracteurs échouent
La plupart des articles sur le scraping de Temu se débarrassent du sujet anti-bot en une phrase : « Temu utilise de l’anti-bot ». Aucune utilité.
Au moment de choisir un outil, vous devez savoir quelles défenses Temu déploie et quelles capacités de l’outil les neutralisent une à une. Voici la carte concrète :
| Défense Temu | Ce que cela fait | Capacité requise de l’outil | Exemples d’outils |
|---|---|---|---|
| Cloudflare WAF / contrôles du navigateur | Bloque les user-agents automatisés, identifie les bots par empreinte, renvoie des pages de vérification | Infrastructure cloud avec rotation d’IP résidentielles et empreintes de navigateur réelles | Thunderbit (scraping cloud), Bright Data, Oxylabs, ScraperAPI |
| Rendu JavaScript intensif | Les données produit se chargent via JS ; le HTML brut est vide | Navigateur headless ou rendu navigateur complet | Thunderbit (mode scraping navigateur), Playwright, Selenium, ParseHub, acteurs navigateur Apify |
| Sélecteurs CSS dynamiques | Les noms de classe changent entre déploiements, ce qui casse les extracteurs basés sur CSS | Détection de champs par IA (sans dépendre de sélecteurs fixes) | Thunderbit (l’IA lit la page à neuf à chaque fois), générateur d’extracteur IA Bright Data |
| Limitation de débit | Ralentit les requêtes séquentielles rapides | Requêtes cloud concurrentes avec limitation intelligente | Thunderbit (jusqu’à 50 pages à la fois via le cloud), ScraperAPI, Bright Data |
| Défis CAPTCHA | Interrompt les sessions après un comportement suspect | Résolution CAPTCHA intégrée ou stratégie à faible déclenchement | Bright Data, Oxylabs, ScraperAPI premium/ultra-premium |
| Défilement infini / chargement paresseux | Seuls les premiers produits apparaissent sans interaction | Défilement intelligent, détection de pagination, automatisation des interactions | Pagination Thunderbit, défilement intelligent Apify, constructeur de workflow Octoparse |
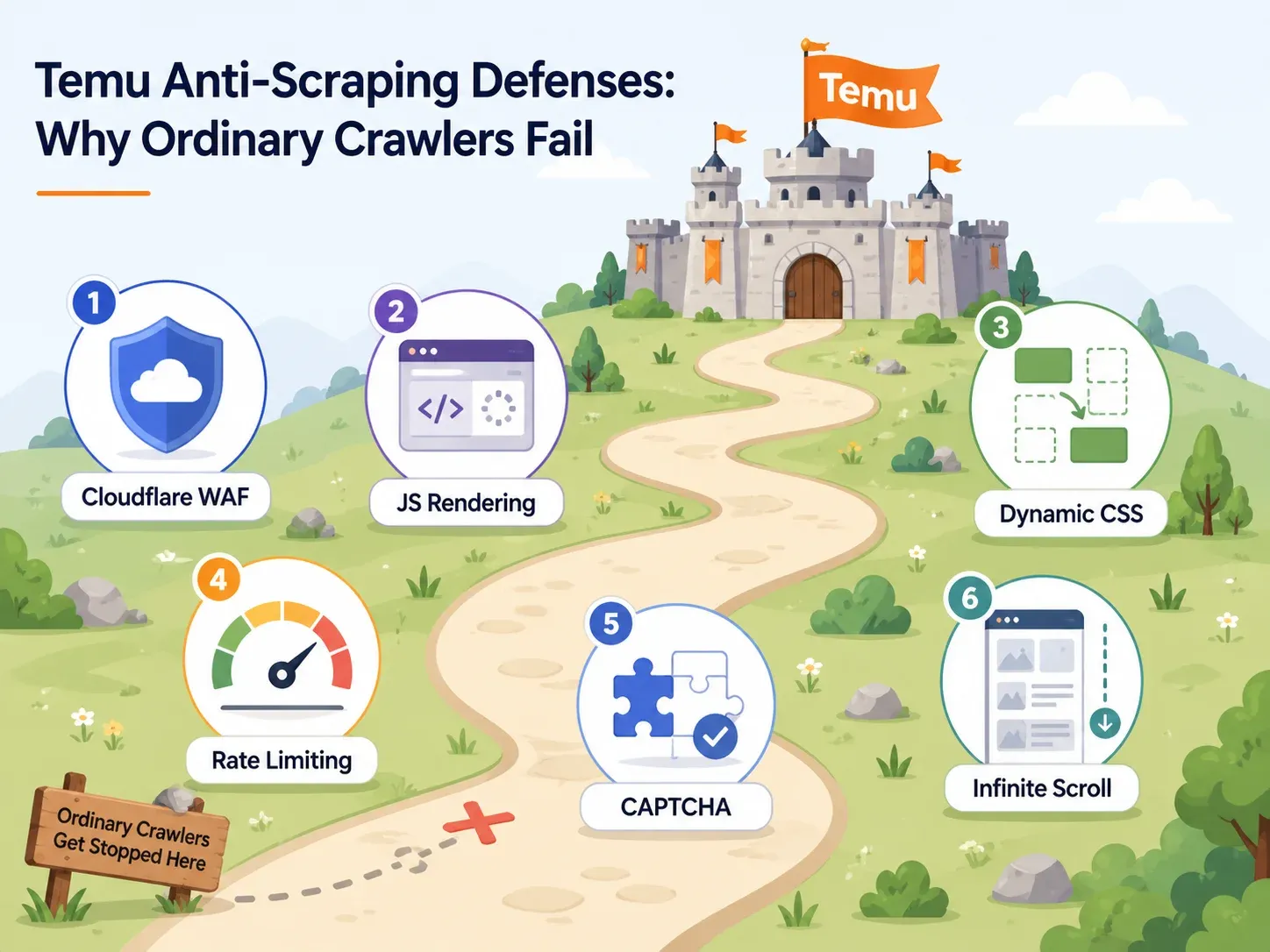
Cloudflare WAF et blocage d’IP
La porte d’entrée de Temu est verrouillée par des contrôles d’intégrité du navigateur de type Cloudflare. Les requêtes HTTP rudimentaires — un banal requests.get() Python, par exemple — se voient défiées, renvoyées en 403 ou servies à moitié.
Les outils qui s’en sortent ici réclament des IP résidentielles ou mobiles en rotation, ainsi que de vraies empreintes de navigateur. La revue 2025 de Cloudflare Radar a relevé que les bots non IA entamaient 2025 en représentant environ la moitié des requêtes de pages HTML. Telle est l’ampleur de l’automatisation contre laquelle des plateformes comme Temu se protègent.
Rendu JavaScript et sélecteurs dynamiques
C’est précisément là que la plupart des extracteurs débutants échouent en silence.
Inspectez le code source d’une page Temu : vous tomberez souvent sur une coquille vide — les vraies cartes produits, les prix et les images sont injectés par JavaScript une fois la page chargée. Un extracteur qui se borne à lire le HTML brut ne ramènera rien d’utile. Pire encore : les noms de classes CSS et les structures DOM de Temu changent d’un déploiement à l’autre. Un extracteur arrimé à un sélecteur CSS figé comme .product-card__price marchera aujourd’hui et renverra des colonnes vides demain.
Les extracteurs basés sur l’IA (comme Thunderbit) lisent la page de façon sémantique à chaque passage : ils ne dépendent donc pas du maintien de noms de classes spécifiques.
Limitation de débit et défis CAPTCHA
Allez trop vite ou trop souvent sur Temu depuis une même IP, et vous déclencherez des limites de débit ou des CAPTCHA. Certains outils encaissent cela grâce à une limitation intelligente et une résolution CAPTCHA intégrée. D’autres vous laissent vous dépatouiller seul — ce qui, pour un utilisateur non technique, ressemble fort à une impasse.
Pour le scraping cloud, la clé tient en quelques mots : des requêtes concurrentes réparties sur des IP propres, doublées d’une logique de réessai automatique.
Meilleurs extracteurs Temu par niveau de compétence : analyse complète
Repérez votre ligne et filez droit vers la section qui vous correspond :
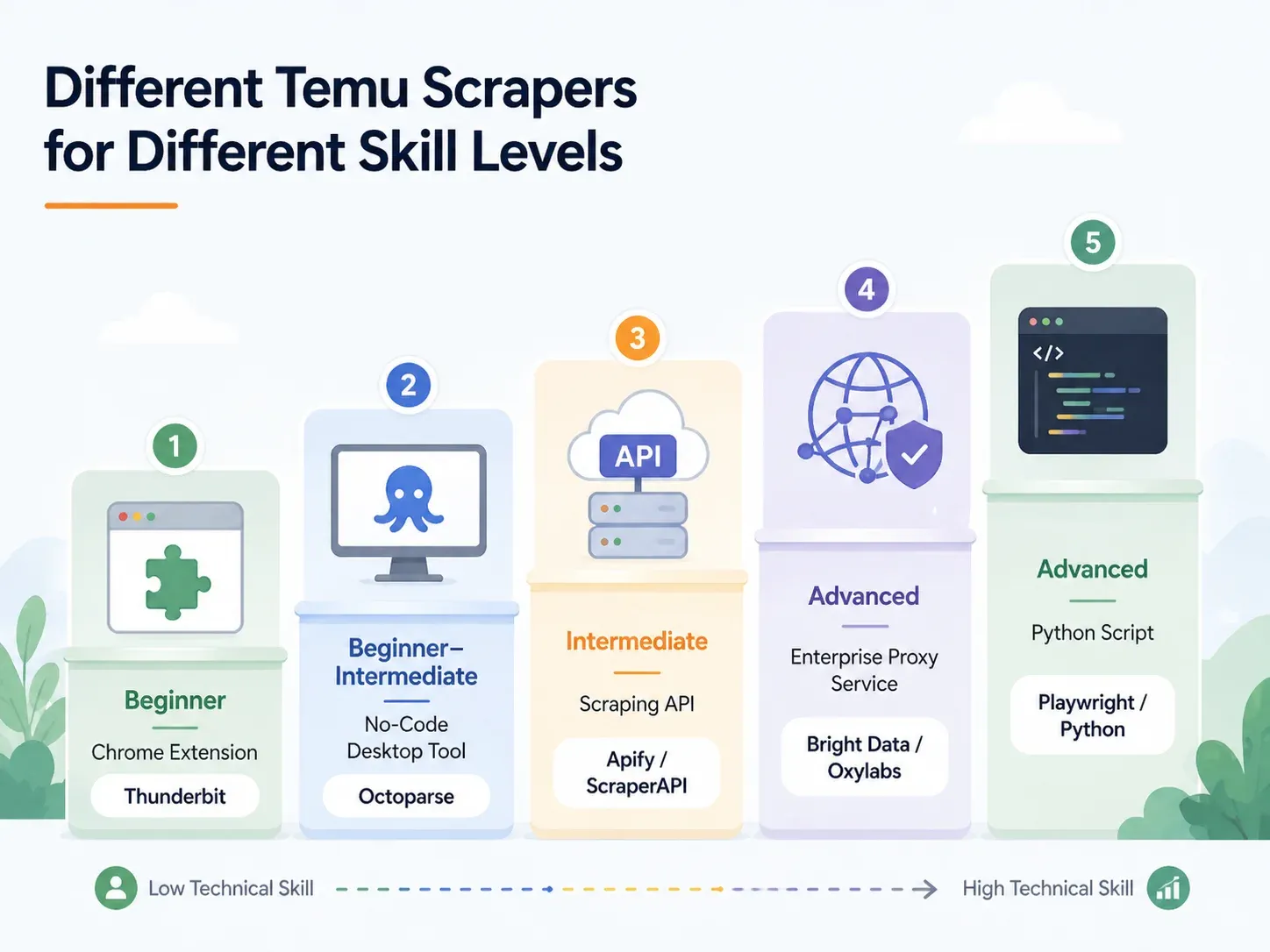
| Approche | Niveau | Temps de configuration | Gestion anti-bot | Idéal pour |
|---|---|---|---|---|
| Extension Chrome IA (ex. Thunderbit) | Débutant | < 2 min | Pris en charge (cloud ou navigateur) | Dropshippers, marketeurs, équipes e-commerce |
| Outil de bureau no-code (ex. Octoparse, ParseHub) | Débutant–Intermédiaire | 10–60 min | Partielle (configuration de proxy nécessaire) | Extraction régulière avec modèles |
| API/service de scraping (ex. ScraperAPI, Apify) | Intermédiaire | 15–45 min | Intégrée | Développeurs intégrant des pipelines |
| Proxy géré/entreprise (ex. Bright Data, Oxylabs) | Avancé/Entreprise | Heures–jours | Infrastructure complète | Gros volumes, livraison vers entrepôt de données |
| Script Python personnalisé (Playwright/Selenium) | Avancé | 1–4 h+ | Manuelle (proxy + CAPTCHA à configurer) | Contrôle total, personnalisation de cas particuliers |
Thunderbit : le meilleur extracteur Temu pour les utilisateurs non techniques
Thunderbit est une extension Chrome propulsée par l’IA, conçue pour les utilisateurs métier — équipes commerciales, opérateurs e-commerce, dropshippers, marketeurs — qui réclament des données structurées issues de sites web sans écrire de code. Je travaille chez Thunderbit, donc je connais le produit sur le bout des doigts. Je serai franc sur ce qu’il fait et sur la place qu’il occupe dans l’écosystème.
Le flux principal tient en deux clics : ouvrez une page Temu, cliquez sur AI Suggest Fields, vérifiez les colonnes suggérées (nom du produit, prix, image, note, etc.), puis cliquez sur Scrape.
L’IA de Thunderbit lit la structure de la page et propose automatiquement les noms de colonnes ainsi que les types de données. Elle ne s’appuie pas sur des sélecteurs CSS figés : ainsi, lorsque Temu rebaptise ses noms de classes ou redispose ses cartes, l’extracteur suit le mouvement.
Fonctionnalités clés pour Temu :
- Mode de scraping cloud : plus rapide pour les pages publiques, traite jusqu’à 50 pages à la fois. Parfait pour les pages de catégorie, les résultats de recherche et les listes de produits sans connexion requise.
- Mode de scraping navigateur : s’appuie sur votre session Chrome actuelle, cookies, locale et état de connexion compris. Idéal quand la région, les popups ou le contenu connecté pèsent sur l’affichage de la page.
- Scrape Subpages : une fois la page de listing extraite, cliquez sur « Scrape Subpages » pour parcourir chaque page de détail produit et ajouter des colonnes comme la description complète, les variantes, les informations vendeur, l’estimation d’expédition et les caractéristiques — sans configuration additionnelle.
- Field AI Prompts : catégorisez, traduisez ou reformatez les données en cours d’extraction. Par exemple : « Classez ce produit dans Ustensiles de cuisine, Petit électroménager, Rangement ou Autre. »
- Scraping programmé : définissez un planning en langage naturel (« tous les lundis à 9 h »), saisissez les URL et Thunderbit lance l’extraction dans le cloud avant d’exporter vers Google Sheets, Airtable ou une autre destination.
- Exports gratuits : Excel, CSV, Google Sheets, Airtable, Notion, JSON — aucun paywall sur l’export. Les images partent comme de vraies pièces jointes dans Airtable et Notion.
Tarification : offre gratuite jusqu’à 6 pages (ou 10 avec un boost d’essai) ; les formules payantes débutent autour de 15 $/mois (mensuel) ou 9 $/mois (annuel) pour 500 crédits, avec 1 crédit = 1 ligne de sortie.
Extrayez les données Temu avec l’IA Get Started Free
Comparaison directe : Thunderbit vs script Python sur la même page Temu
Le contraste est saisissant :
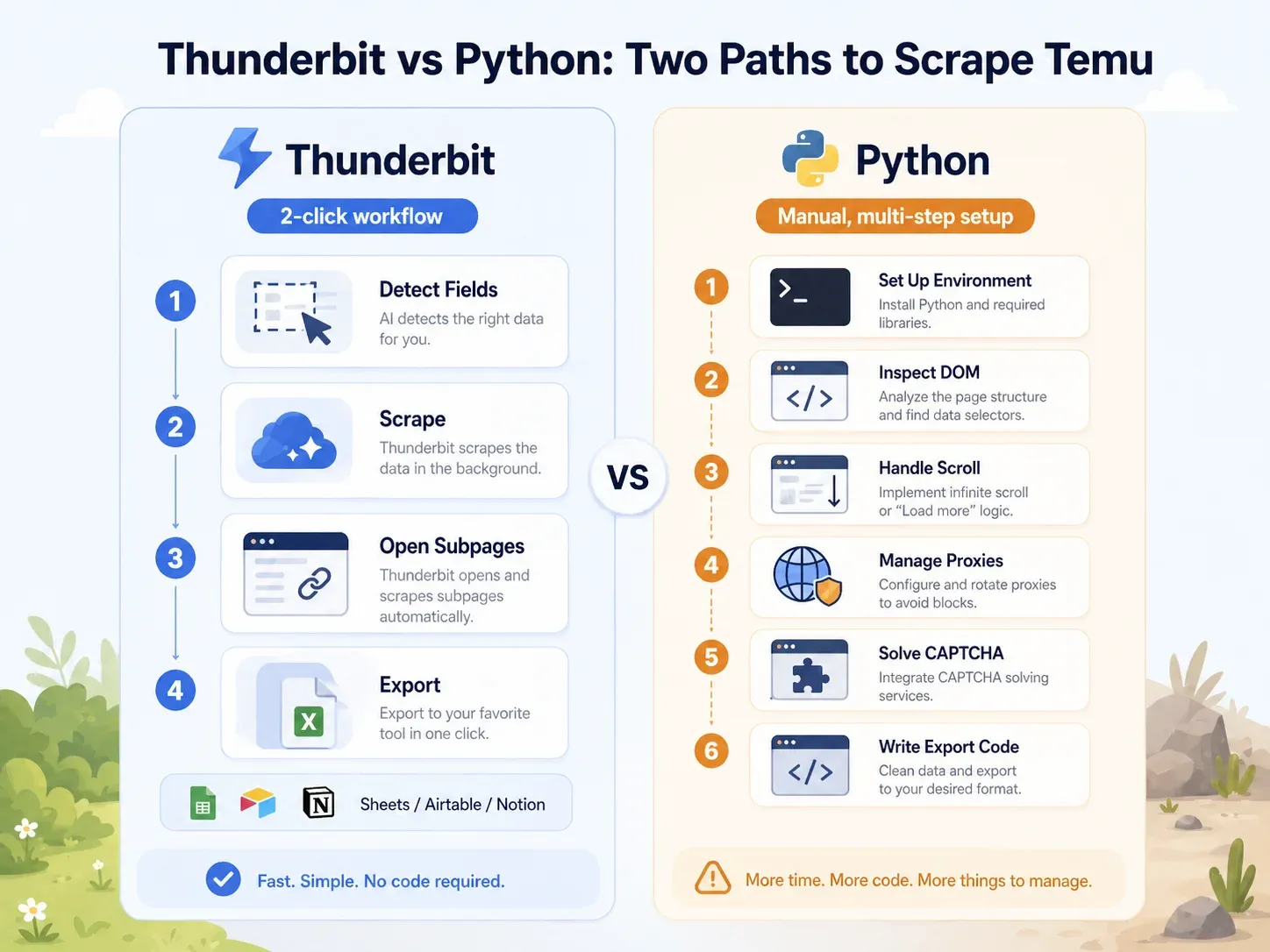
| Tâche | Thunderbit | Python (Playwright) |
|---|---|---|
| Ouvrir une page catégorie Temu | Ouvrir la page dans Chrome | Configurer l’environnement Python, installer Playwright, installer les navigateurs |
| Identifier les champs | Cliquer sur « AI Suggest Fields » | Inspecter le DOM, les appels réseau, les payloads JSON |
| Gérer le chargement dynamique | Mode navigateur/cloud + pagination | Écrire la logique de scroll/attente, intercepter les requêtes |
| Gérer les blocages | Essayer le mode cloud ou navigateur | Ajouter des proxies, des en-têtes, du fingerprinting, des réessais, le CAPTCHA |
| Extraire les champs de listing | Cliquer sur « Scrape » | Écrire des sélecteurs ou une logique d’analyse d’API |
| Enrichir les pages produit | Cliquer sur « Scrape Subpages » | Construire un crawler PDP séparé |
| Exporter | Cliquer sur Sheets/Airtable/Notion/Excel | Écrire du code d’intégration CSV/JSON/Sheets |
| Configuration typique pour un utilisateur métier | Moins de 2 minutes | 1–4 heures minimum ; maintenance continue |
Un prototype Playwright minimal pour Temu ressemblerait à ceci (pseudocode — pas prêt pour la production) :
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto("https://www.temu.com/search_result.html?search_key=kitchen+organizer")
page.wait_for_load_state("networkidle")
for _ in range(8):
page.mouse.wheel(0, 2000)
page.wait_for_timeout(1200)
cards = page.locator("[data-product-id], a[href*='goods.html']")
# Le code de production nécessite encore des sélecteurs, des proxies, des réessais,
# la gestion du CAPTCHA, le crawling des PDP et la logique d’export.
print(cards.count())
Cela représente déjà plus de 10 lignes avant même d’avoir extrait le moindre champ, et vous n’avez pas encore touché aux proxies, au CAPTCHA, à l’enrichissement PDP ni à l’export. Pour un utilisateur non technique, Thunderbit comprime tout ce flux en quelques clics. Pour un développeur, la voie Python ouvre davantage de contrôle — mais à un coût de maintenance bien plus lourd.
Octoparse et ParseHub : extracteurs Temu no-code de bureau
Si vous voulez plus de marge de manœuvre qu’une extension Chrome sans pour autant écrire de code, Octoparse et ParseHub sont vos deux candidats de tête.
Octoparse met à disposition un modèle public Temu Details Scraper. Son exemple de sortie comprend les IDs produits, titres, prix, données vendeur/boutique, URL d’images, remises, URL de boutique et spécifications détaillées. Voilà un vrai atout : vous partez d’un modèle plutôt que de bâtir un workflow de A à Z. Octoparse prend aussi en charge l’extraction cloud, la planification et la création visuelle de workflows.
Les réserves pour Temu :
- Les modules anti-bot additionnels (proxies résidentiels à 3 $/Go, résolution CAPTCHA à 1–1,50 $ par mille) peuvent vite gonfler l’addition.
- Les modèles peuvent céder quand Temu change sa mise en page. Vous devrez peut-être retoucher les sélecteurs ou patienter le temps qu’Octoparse maintienne le modèle.
- La configuration s’étale de 10 à 60 minutes selon la complexité de la page.
Tarification Octoparse : plan gratuit avec 10 tâches et 50 000 exportations mensuelles de données ; Standard autour de 75 $/mois en annuel ; Professional autour de 108 $/mois en annuel. Les add-ons pour proxies, CAPTCHA et services gérés s’ajoutent à la facture.
ParseHub est un extracteur visuel de bureau/web qui dompte bien les pages dynamiques (il exécute un navigateur Chromium complet). En revanche, les formules payantes démarrent à 189 $/mois, un seuil élevé pour un indépendant. Mes recherches n’ont pas révélé de modèle Temu public particulièrement robuste. ParseHub conviendra surtout aux équipes déjà rodées à la création de projets de scraping visuels.
| Outil | Atouts pour Temu | Faiblesses sur Temu | Tarification |
|---|---|---|---|
| Octoparse | Modèle Temu public, workflow visuel, extraction cloud, planification | Maintenance des modèles, add-ons anti-bot qui augmentent le coût | Gratuit ; ~75 $/mois Standard annuel ; ~108 $/mois Pro annuel ; add-ons en plus |
| ParseHub | Gestion des pages dynamiques, constructeur de workflows projet, rotation d’IP sur les formules payantes | Prix d’entrée plus élevé, aucun modèle Temu public trouvé | Formules payantes à partir de 189 $/mois |
APIs de scraping : ScraperAPI, Apify et Bright Data pour Temu
Les services de scraping basés sur API prennent en charge proxies, rendu et logique anti-bot, libérant les développeurs pour qu’ils se concentrent sur l’analyse et le stockage des données. Ils brillent quand vous montez un pipeline, pas pour un export ponctuel vers un tableur.
ScraperAPI est une API développeur dédiée à la rotation de proxy et au rendu. Sa page tarifaire affiche un essai de 7 jours avec 5 000 crédits, Hobby à 49 $/mois pour 100 000 crédits, puis des paliers supérieurs. Le point sensible pour Temu : le rendu JavaScript et les pools de proxy premium engloutissent de 10 à 75 crédits par requête selon le palier. Cette multiplication des crédits fait que votre coût réel par ligne peut s’envoler bien au-delà du prix affiché.
Apify est une plateforme dotée d’une place de marché d’« actors » (extracteurs) prêts à l’emploi. Plusieurs actors Temu existent. Un Temu Scraper maintenu par la communauté affiche une tarification au paiement par événement d’environ 5 $ pour 1 000 produits sur le niveau gratuit. Un autre Temu Products Scraper indique 4 $ pour 1 000 résultats. Le hic : la qualité des actors fluctue, la maintenance dépend de la communauté et certains actors peuvent être obsolètes ou casser à chaque mise à jour de Temu. Vérifiez toujours la date de dernière modification et les notes des utilisateurs avant de vous engager.
Bright Data est l’option entreprise. Sa page dédiée au scraper Temu précise que les tâches tournent sur l’infrastructure Bright Data avec rotation de proxy, géociblage, logique CAPTCHA/déblocage et autoscaling. Les formats de sortie embrassent JSON, CSV, Parquet, plus une livraison directe vers S3, GCS, Azure Blob, BigQuery et Snowflake. Les comparatifs sectoriels chiffrent la tarification Web Scraper API en paiement à l’usage autour de 2,5 $ pour 1 000 enregistrements, avec des plans engagés à partir d’environ 499 $/mois. Puissant, mais calibré pour des équipes aux vrais budgets.
Oxylabs dispose elle aussi d’une page dédiée Temu Scraper API. Les plans s’amorcent à 49 $/mois, avec un essai gratuit allant jusqu’à 2 000 résultats. C’est une solide alternative à Bright Data pour les équipes de développement en quête de données Temu structurées via API.
| API/Plateforme | Preuve spécifique à Temu | Point fort | Point faible | Idéal pour |
|---|---|---|---|---|
| ScraperAPI | Aucune page spécifique Temu trouvée, mais des fonctions anti-bot e-commerce sont documentées | Point d’entrée simple, rendu JS, proxies premium | Multiplication des crédits pour les fonctions premium ; les développeurs doivent analyser les données | Pipelines développeur |
| Apify | Plusieurs actors Temu dans la marketplace | Le chemin le plus rapide pour les développeurs si l’actor correspond et est maintenu | Qualité des actors variable ; certains obsolètes | Développeurs voulant une marketplace d’actors + planification |
| Bright Data | Page dédiée au scraper Temu | Infrastructure entreprise, déblocage, livraison vers entrepôt de données | Cher ; des notions de web scraping restent nécessaires | Équipes data à l’échelle entreprise |
| Oxylabs | Page dédiée Temu Scraper API | Tarification claire par résultat, gestion JS, promesses d’IP/CAPTCHA | Workflow d’API développeur | Équipes de développement ayant besoin d’un accès API Temu |
Scripts Python personnalisés (Playwright/Selenium) : contrôle total, effort élevé
Les extracteurs Python sur mesure offrent une flexibilité maximale — voilà leur force. Playwright fait généralement un meilleur point de départ que Selenium pour Temu, grâce à son modèle d’attente automatique et à sa meilleure prise en charge des pages gorgées de JavaScript.
Mais l’arbitrage est sévère.
Un prototype réclame 1 à 4 heures. Un extracteur de production exige rotation de proxy, empreintes navigateur réalistes, stratégie CAPTCHA, réessais, validation de schéma, stockage des sorties, supervision, alertes et examen juridique.
Et il casse. Les communautés de scraping sur Reddit dépeignent régulièrement le scraping e-commerce moderne comme instable dès que les sites mobilisent Cloudflare, le rendu JavaScript et des empreintes anti-bot.
| Mode d’échec | Cause typique | Atténuation | |---|---|---|---| | HTML vide / produits manquants | Le JS charge les cartes produits après le HTML initial | Utiliser Playwright, attendre le réseau et le DOM | | Seuls les premiers produits apparaissent | Défilement infini / chargement paresseux | Boucle de scroll, attentes réseau inactif, seuils de nombre de cartes | | Prix manquants ou incohérents | État région/session/devise ou réponse anti-bot | Définir la locale, les cookies, un proxy géociblé | | 403 / défi / CAPTCHA | Réputation IP, empreinte headless, rythme des requêtes | Proxies résidentiels, navigateur furtif, rythme réduit | | Rupture des sélecteurs | Changements DOM/classe, tests A/B | Extraction sémantique ou analyse d’API si disponible |
Les scripts personnalisés ne forment pas l’option « gratuite ». Ils déplacent simplement les coûts des abonnements vers le temps développeur, les factures de proxy, les dépenses CAPTCHA et le risque de maintenance. Si vous comptez un ingénieur scraping en interne et qu’une logique atypique s’impose, c’est la bonne voie. Pour tous les autres, c’est en pratique l’option la plus onéreuse.
Bonne pratique : scraping des sous-pages pour des données produit Temu complètes
C’est la bonne pratique la plus déterminante de cet article — et presque aucun autre guide n’en souffle mot.
Une page de catégorie ou de recherche Temu vous livre l’essentiel : titre, miniature, prix, note approximative. Mais les champs qui rendent vraiment une ligne exploitable — descriptions détaillées, liste des variantes, nombre complet d’avis, estimations d’expédition, noms des vendeurs, tableaux de spécifications — se nichent sur la page de détail produit (PDP).
Vous bornez-vous à scraper la page de listing ? Vous travaillez alors avec un jeu de données amputé.
Le flux en deux étapes :
- Étape 1 — Extraire la page de listing (PLP) : récupérer le nom du produit, le prix, la miniature et la note depuis une page de recherche ou de catégorie Temu.
- Étape 2 — Enrichir via le scraping des sous-pages : parcourir chaque PDP produit et ajouter des colonnes comme la description complète, le nombre d’avis, les options de variantes, le délai d’expédition et les informations vendeur.
Voici les données avant et après :
| Champ | Depuis la PLP (Étape 1) | Ajouté depuis la PDP (Étape 2) |
|---|---|---|
| Titre du produit | ✅ | — |
| Prix | ✅ | ✅ (vérifié / % de remise) |
| Miniature | ✅ | — |
| Note étoiles | ✅ | ✅ (avec nombre d’avis) |
| Description complète | ❌ | ✅ |
| Variantes (tailles, couleurs) | ❌ | ✅ |
| Nom du vendeur | ❌ | ✅ |
| Estimation d’expédition | ❌ | ✅ |
| Caractéristiques détaillées | ❌ | ✅ |
Dans Thunderbit, tout cela tient en un clic : après votre première extraction, cliquez sur « Scrape Subpages ». L’IA parcourt chaque URL produit et ajoute les colonnes supplémentaires — sans configuration additionnelle, sans spider séparé, sans maintenance de sélecteurs. Le modèle Temu Details d’Octoparse et l’actor Temu d’Apify gèrent aussi les champs au niveau PDP, mais au prix d’une configuration et d’une maintenance plus lourdes. En Python, il faudrait bâtir un crawler PDP séparé, entretenir ses sélecteurs et gérer la pagination à l’intérieur des pages de détail — un investissement supplémentaire conséquent.
Bonne pratique : scraping Temu programmé pour le suivi continu des prix et des stocks
Les extractions ponctuelles ont leur utilité pour la découverte produit. La veille concurrentielle, elle, exige une observation répétée.
Les prix bougent, les produits tombent en rupture, de nouveaux articles surgissent chaque jour et la profondeur des remises ondule au gré des promotions. Une extraction hebdomadaire ou quotidienne tisse un tableau d’historique sur lequel votre équipe peut réellement s’appuyer pour agir.
Trois cas d’usage qui valent l’automatisation :
- Suivi des prix : pistez chaque semaine les 50 principaux SKU Temu d’un concurrent. Recevez les prix actualisés automatiquement dans Google Sheets pour les confronter d’un coup d’œil à vos propres tarifs.
- Suivi des stocks et des disponibilités : repérez quand un produit tendance passe en rupture, qu’une nouvelle variante apparaît ou que les délais d’expédition se décalent.
- Détection de nouveaux produits/tendances : programmez une extraction quotidienne de la section « Nouveautés » de Temu ou d’une page de catégorie prioritaire. Triez par nombre d’unités vendues ou d’avis pour flairer tôt les produits en hausse.
Dans Thunderbit, vous mettez tout cela en place en décrivant l’intervalle en langage naturel (« tous les lundis à 9 h »), en saisissant vos URL cibles et en cliquant sur « Schedule ». L’extraction tourne dans le cloud et exporte vers la destination choisie. Comme l’IA relit la page à chaque passage, les extractions programmées épousent automatiquement les changements de mise en page de Temu — inutile de retoucher les sélecteurs quand Temu redessine une carte produit.
L’alternative : installer une tâche cron, entretenir un script Python, configurer la rotation de proxy, bâtir un pipeline de sortie et rafistoler les sélecteurs à chaque remaniement de mise en page de Temu. Pour une équipe non technique, c’est rédhibitoire. Pour un développeur, c’est une charge permanente. Apify et Bright Data gèrent eux aussi les exécutions planifiées, mais avec une configuration plus technique et un coût plancher plus élevé.
Bonne pratique : flux Temu de bout en bout (extraire → nettoyer → exporter → agir)
La plupart des guides de scraping s’arrêtent au « téléchargement du CSV ».
Or les utilisateurs métier ont besoin des données dans les outils qu’ils manipulent vraiment — Google Sheets pour la collaboration, Airtable pour les bases produit, Notion pour les tableaux de bord d’équipe. La vraie bonne pratique, c’est un flux de bout en bout :
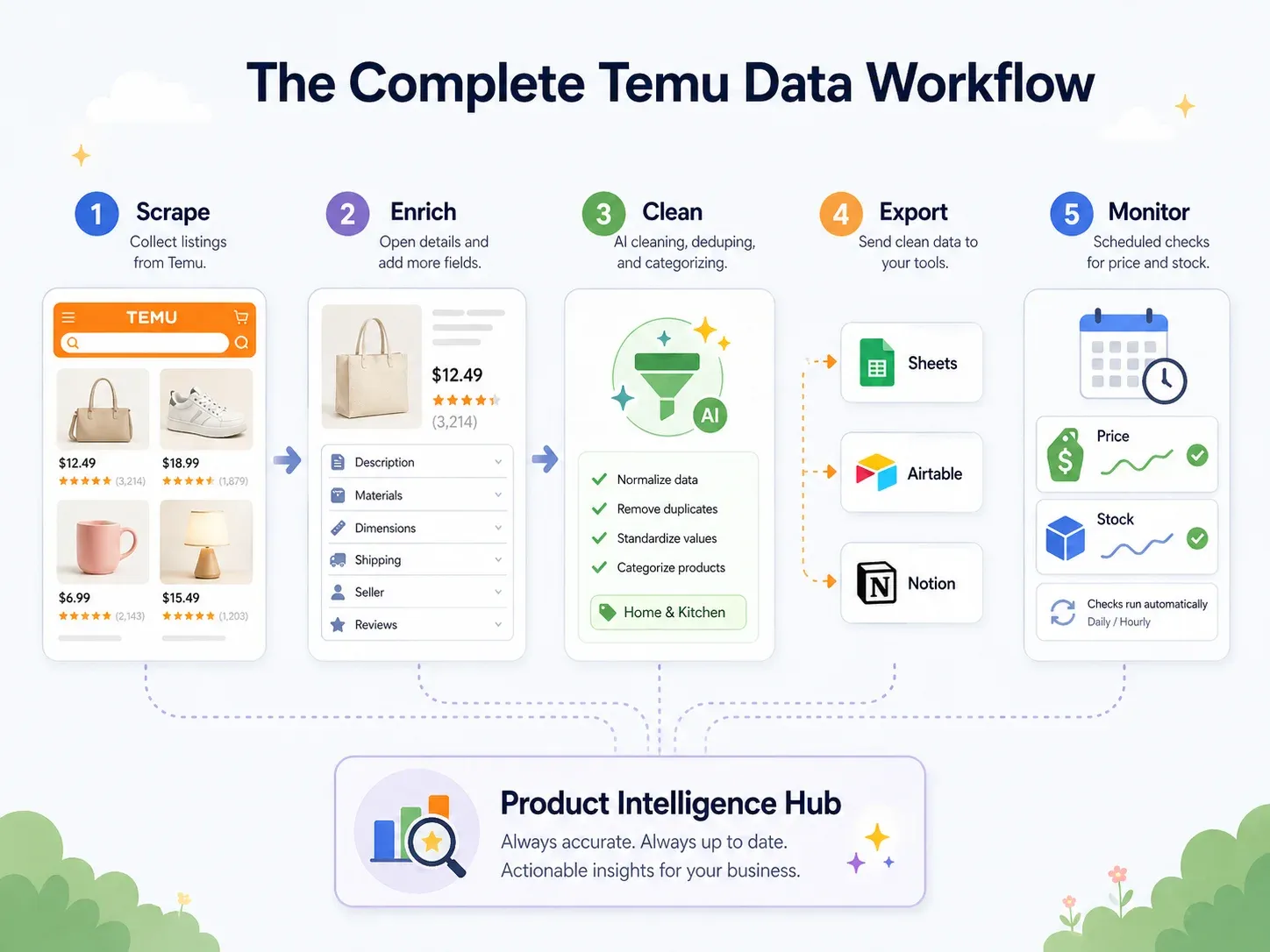
| Étape du workflow | Ce qui se passe | Capacité Thunderbit |
|---|---|---|
| Extraire | Récupérer les données des pages Temu | AI Suggest Fields → Scrape (2 clics) |
| Enrichir | Visiter la page de détail de chaque produit | Scrape Subpages (1 clic) |
| Nettoyer et étiqueter | Catégoriser les produits, normaliser les prix, traduire les titres | Field AI Prompt — étiqueter, formater, traduire pendant l’extraction |
| Exporter | Envoyer les données vers les outils métier | Export gratuit vers Excel, Google Sheets, Airtable, Notion ; téléchargement CSV/JSON |
| Surveiller | Suivre les changements dans le temps | Scheduled Scraper avec intervalles en langage naturel |
Prenons un exemple concret : vous extrayez 200 produits de cuisine Temu. En cours d’extraction, un Field AI Prompt classe automatiquement chaque produit dans « Ustensiles / Petit électroménager / Rangement / Nettoyage / Décoration ». Les prix sont normalisés en valeurs numériques USD. Les titres de produits chinois sont traduits en anglais. Les données filent droit vers une base Airtable avec les images produit intactes (pas de simples URL — de vraies pièces jointes d’image, comme l’explique le guide de scraping d’images de Thunderbit). Une extraction programmée rafraîchit ensuite les données chaque semaine.
Voici quelques instructions Field AI Prompt utiles pour les données Temu :
- « Classez ce produit dans l’une de ces catégories : Ustensiles de cuisine, Petit électroménager, Rangement, Nettoyage, Décoration, Autre. Retournez uniquement la catégorie. »
- « Traduisez le titre du produit en anglais concis tout en conservant les noms de marque, quantités, tailles et numéros de modèle. »
- « Normalisez le prix en un nombre sans symbole monétaire. »
- « Évaluez la demande comme Forte, Moyenne ou Faible en fonction de la note, du nombre d’avis et du nombre d’unités vendues. Si une donnée manque, renvoyez Inconnu. »
Ce workflow transforme un simple scrape en une base vivante d’intelligence produit — sans qu’un développeur ait à monter un pipeline ETL séparé.
Comparatif des meilleurs extracteurs Temu : tableau côte à côte
| Outil | Niveau | Temps de configuration | Gestion anti-bot | Scraping des sous-pages | Planification | Options d’export | Tarif | Idéal pour |
|---|---|---|---|---|---|---|---|---|
| Thunderbit | Débutant | Minutes | Mode navigateur, mode cloud, détection de champs par IA | Oui (Scrape Subpages) | Oui (plannings en langage naturel) | Excel, CSV, Google Sheets, Airtable, Notion, JSON | 6 pages gratuites ; payant dès ~9–15 $/mois pour 500 crédits | Équipes e-commerce non techniques, dropshippers |
| Octoparse | Débutant–Intermédiaire | 10–60 min | Extraction cloud, add-ons proxy/CAPTCHA | Oui (workflows modèle) | Oui (formules payantes/cloud) | Excel, CSV, JSON, HTML, XML, base de données, Google Sheets | Gratuit ; ~75 $/mois Standard annuel ; add-ons en plus | Opérateurs voulant des workflows visuels + un modèle Temu |
| ParseHub | Débutant–Intermédiaire | 30–60 min | Rendu dynamique, rotation d’IP payante | Oui (flux de projet) | Formules payantes | CSV/JSON, Dropbox/S3 sur les formules payantes | Payant à partir de 189 $/mois | Équipes construisant des projets visuels pour des sites dynamiques |
| ScraperAPI | Développeur | Heures | Rotation de proxy, rendu JS, pools premium | Code personnalisé | DataPipeline/planificateur | HTML/JSON/CSV | Essai 5K crédits ; Hobby 49 $/mois ; paliers supérieurs disponibles | Développeurs construisant des pipelines Temu personnalisés |
| Apify | Intermédiaire | 10–30 min si l’actor convient | Logique navigateur/proxy spécifique à l’actor | Dépend de l’actor | Oui | JSON, CSV, Excel, API/ensembles de données | Plateforme gratuite ; actors Temu ~4–5 $/1K produits | Développeurs/opérateurs capables d’évaluer la qualité des actors |
| Bright Data | Avancé/Entreprise | Heures–jours | Proxies complets, CAPTCHA, déblocage, autoscaling | Via scraper/API personnalisé | Oui | JSON, CSV, Parquet, S3, GCS, Azure, BigQuery, Snowflake | ~2,5 $/1K enregistrements PAYG ; engagé à partir d’environ 499 $/mois | Équipes data entreprise, extraction à gros volume |
| Oxylabs | Avancé | Heures | Gestion JS, promesses d’IP/CAPTCHA | Via API personnalisé | Oui | JSON/sortie API | À partir de 49 $/mois ; essai jusqu’à 2K résultats | Équipes de développement ayant besoin d’un accès API Temu |
| Python personnalisé (Playwright) | Avancé | 1–4 h+ ; maintenance continue | Proxies manuels, CAPTCHA, empreintes | Entièrement personnalisé | Cron/file d’attente/manuel | Personnalisé | Temps dev + coûts proxy/CAPTCHA/hébergement | Cas particuliers, équipes avec ingénieurs scraping |
Quel extracteur Temu choisir ? Recommandations rapides
- Dropshipper en quête d’une recherche produit rapide ? Commencez par la version gratuite de Thunderbit. C’est le trajet le plus court entre « je veux des données Temu » et « j’ai un tableur ». Si cela marche sur vos pages cibles (et ce devrait être le cas pour la plupart des pages publiques de catégorie et de produit), l’affaire est réglée.
- Opérateur en quête d’un contrôle visuel et de modèles réutilisables ? Octoparse propose un modèle public Temu Details et un constructeur de workflow visuel. Comptez 10 à 30 minutes de configuration et un brin de paramétrage proxy/CAPTCHA.
- Développeur qui monte un pipeline de données ou un outil interne ? ScraperAPI ou Apify vous fournissent des workflows API/actor intégrables au code et aux tâches planifiées. Auscultez soigneusement les actors Apify — examinez leur état de maintenance et les notes des utilisateurs.
- Équipe entreprise réclamant de gros volumes de données Temu et une livraison vers entrepôt ? Bright Data est l’option infrastructure. Cher, mais il encaisse l’échelle, le déblocage et la livraison vers S3/BigQuery/Snowflake.
- Ingénieur scraping en quête d’une logique atypique ? Playwright/Selenium personnalisé vous accorde un contrôle total. Anticipez simplement la maintenance continue, les coûts de proxy et la gestion du CAPTCHA.
Pour la majorité des utilisateurs métier non techniques, je recommande de tester d’abord la version gratuite de Thunderbit. La question immédiate reste toujours la même : « puis-je obtenir les lignes dont j’ai besoin à partir de cette page Temu précise ? » — et vous y répondez en moins de deux minutes, sans débourser un centime. Pour les développeurs, établissez un benchmark du coût par ligne réussie entre Apify, ScraperAPI et un petit prototype Playwright avant d’engager le moindre budget.
Essayez Thunderbit gratuitement pour extraire Temu
FAQ sur l’extraction de Temu
Est-il légal d’extraire Temu ?
Tout dépend de la juridiction, des données que vous collectez, de votre méthode d’accès et de l’usage que vous en faites. Les Conditions d’utilisation de Temu interdisent explicitement l’accès automatisé, y compris le crawling, le scraping ou le spidering de pages ou de données. Les tribunaux américains ont esquissé certains précédents favorables à l’accès aux données librement accessibles (la décision hiQ v. LinkedIn de la Ninth Circuit), mais des décisions ultérieures ont aussi confirmé des actions pour rupture de contrat et intrusion. En résumé : extraire des données produit librement accessibles à des fins de recherche peut se défendre dans certains contextes, mais les conditions d’utilisation, le droit à la vie privée, le droit d’auteur et l’usage des données pèsent tous dans la balance. Ceci n’est pas un avis juridique — consultez un conseil pour un usage commercial.
À quelle fréquence Temu modifie-t-il la mise en page de son site ?
Aucun rythme public n’a été documenté. Les retours de la communauté et l’écosystème d’outils traitent Temu comme une cible dynamique, fréquemment remaniée. Partez du principe que les sélecteurs CSS peuvent céder à tout moment, et privilégiez l’extraction IA/sémantique ou des modèles activement maintenus plutôt que des sélecteurs codés en dur.
Puis-je extraire Temu sans me faire bloquer ?
Pour des pages publiques limitées et à un rythme raisonnable, oui — surtout avec des outils dotés d’un vrai rendu navigateur, du support de session et d’un mécanisme de limitation. Aucun outil ne doit toutefois passer pour une garantie universelle. Le scraping cloud avec IP rotatives convient bien aux pages de catalogue publiques ; le scraping navigateur avec votre session actuelle fait mieux dès que la région, la connexion ou des popups pèsent sur les données.
Quelles données puis-je extraire des pages produit Temu ?
Les champs publics courants couvrent le titre du produit, l’URL, le prix actuel, le prix initial, le pourcentage de remise, les URL d’image, la note étoiles, le nombre d’avis, le nombre d’unités vendues, le nom du vendeur/boutique, les informations d’expédition, la catégorie, les spécifications produit, les variantes (couleurs, tailles) et l’horodatage du scrape. Les champs exacts disponibles dépendent du type de page (listing vs détail) et de la région.
Ai-je besoin de proxys pour extraire Temu ?
Pour une petite extraction manuelle en mode navigateur (quelques pages à la fois), pas forcément. Pour une collecte cloud, planifiée ou à fort volume, des proxys ou une infrastructure gérée anti-blocage s’imposent généralement. Des outils comme Thunderbit, Bright Data et ScraperAPI intègrent la gestion des proxies à leur plateforme, ce qui vous épargne de la configurer à part.
Pour approfondir des sujets connexes, parcourez nos guides sur le web scraping pour la comparaison de prix, les meilleurs extracteurs web e-commerce, extraire des données d’un site web vers Excel et comment extraire vers Google Sheets. Vous pouvez aussi regarder des tutoriels sur la chaîne YouTube Thunderbit.
Essayez Thunderbit pour extraire Temu Get Started Free
En savoir plus




