Le web est devenu un véritable territoire sauvage, en mouvement constant — oubliez l’image de la « bibliothèque numérique » ; on est plutôt dans une jungle de données. En 2025, quand on veut extraire des données de sites modernes, on ne se heurte plus seulement à un mur de JavaScript : on fait face à une forteresse. J’ai pu constater de mes propres yeux à quel point les outils d’extraction traditionnels s’écroulent sous le poids du contenu dynamique, du défilement infini et des protections anti-bot. C’est pourquoi l’essor du navigateur headless Python n’est pas juste une tendance : c’est un vrai tournant pour toutes celles et ceux qui ont besoin d’une extraction de données web fiable et scalable.
Et les techniciens ne sont pas les seuls concernés. D’ici 2025, , et plus de . Que vous travailliez dans la vente, l’e-commerce ou les opérations, le bon navigateur headless Python fait toute la différence entre « la donnée au bout des doigts » et « la donnée hors de portée ». Alors, faisons le tri dans tout ce bruit : j’ai testé, comparé et utilisé ces outils au quotidien, et je vais vous présenter les 10 meilleurs navigateurs headless Python pour l’extraction moderne (avec un focus particulier sur la façon dont l’IA change la donne pour les non-développeurs).
Pourquoi un navigateur headless Python est-il indispensable pour l’extraction moderne ?
Démystifions un peu le jargon : un navigateur headless Python est tout simplement un navigateur web que vous pilotez avec du code Python, mais sans la fenêtre qui s’affiche à l’écran. Il charge les pages, exécute JavaScript, clique sur des boutons, remplit des formulaires — tout ça en arrière-plan, sans être visible. Voyez-le comme un navigateur fantôme, qui bosse sans relâche pendant que vous sirotez votre café.
Pourquoi c’est important ? Parce que les sites modernes sont conçus pour les utilisateurs, pas pour les robots. Ils cachent les données derrière JavaScript, demandent une connexion et attendent que vous interagissiez comme une vraie personne. Les extracteurs traditionnels, qui se contentent de récupérer le HTML, se retrouvent face à des coquilles vides. Les navigateurs headless, eux, imitent un vrai comportement utilisateur : ils attendent les appels AJAX, font défiler les fils infinis et récupèrent le contenu exactement tel que vous le voyez dans Chrome ou Firefox ().
Mais ce n’est pas tout :
- Vitesse et efficacité : les navigateurs headless se passent du rendu visuel ; ils sont donc plus rapides et consomment moins de mémoire — parfait pour une extraction à grande échelle ().
- Prise en charge du contenu dynamique : ils exécutent JavaScript, ce qui vous permet d’obtenir les vraies données rendues, pas seulement le HTML brut.
- Superpouvoirs d’automatisation : besoin de vous connecter, de paginer ou de gérer des pop-ups ? Les navigateurs headless Python peuvent tout automatiser.
- Scalabilité : lancez des centaines d’instances dans le cloud, extrayez des milliers de pages en parallèle et sans effort.
Pour les utilisateurs métier, cela veut dire enfin pouvoir collecter des leads, surveiller les concurrents ou suivre les prix — même si le site est construit comme Fort Knox. Et avec les derniers outils propulsés par l’IA, nul besoin d’être développeur pour se lancer.
Comment nous avons choisi les meilleurs navigateurs headless Python
Je n’ai pas juste lancé des fléchettes sur une liste de noms de navigateurs. Voici les critères que j’ai retenus :
- Performance et vitesse : peut-il gérer rapidement et de façon fiable les sites modernes, riches en JavaScript ?
- Prise en charge des navigateurs : fonctionne-t-il avec Chrome, Firefox, WebKit, ou même des moteurs plus anciens comme IE ?
- Facilité d’utilisation : est-il accessible aux non-développeurs, ou faut-il un doctorat en Python ?
- Fonctionnalités IA et no-code : les utilisateurs métier peuvent-ils tirer parti de l’IA pour automatiser l’extraction sans écrire de scripts ?
- Communauté et support : existe-t-il une communauté active, une bonne documentation et un développement suivi ?
- Fonctionnalités uniques : propose-t-il quelque chose de spécial — comme des modèles instantanés, l’extraction cloud ou la navigation entre sous-pages ?
J’ai vu des équipes perdre des semaines à se battre avec la configuration, pour finir bloquées dès que la mise en page du site change. Les meilleurs outils ne se contentent pas de fonctionner : ils s’adaptent, montent en charge et vous simplifient la vie.
Les 10 meilleurs navigateurs headless Python pour l’extraction moderne
Voici ma liste définitive, avec un zoom sur ce qui fait briller chacun de ces outils — ou trébucher.
1. Thunderbit
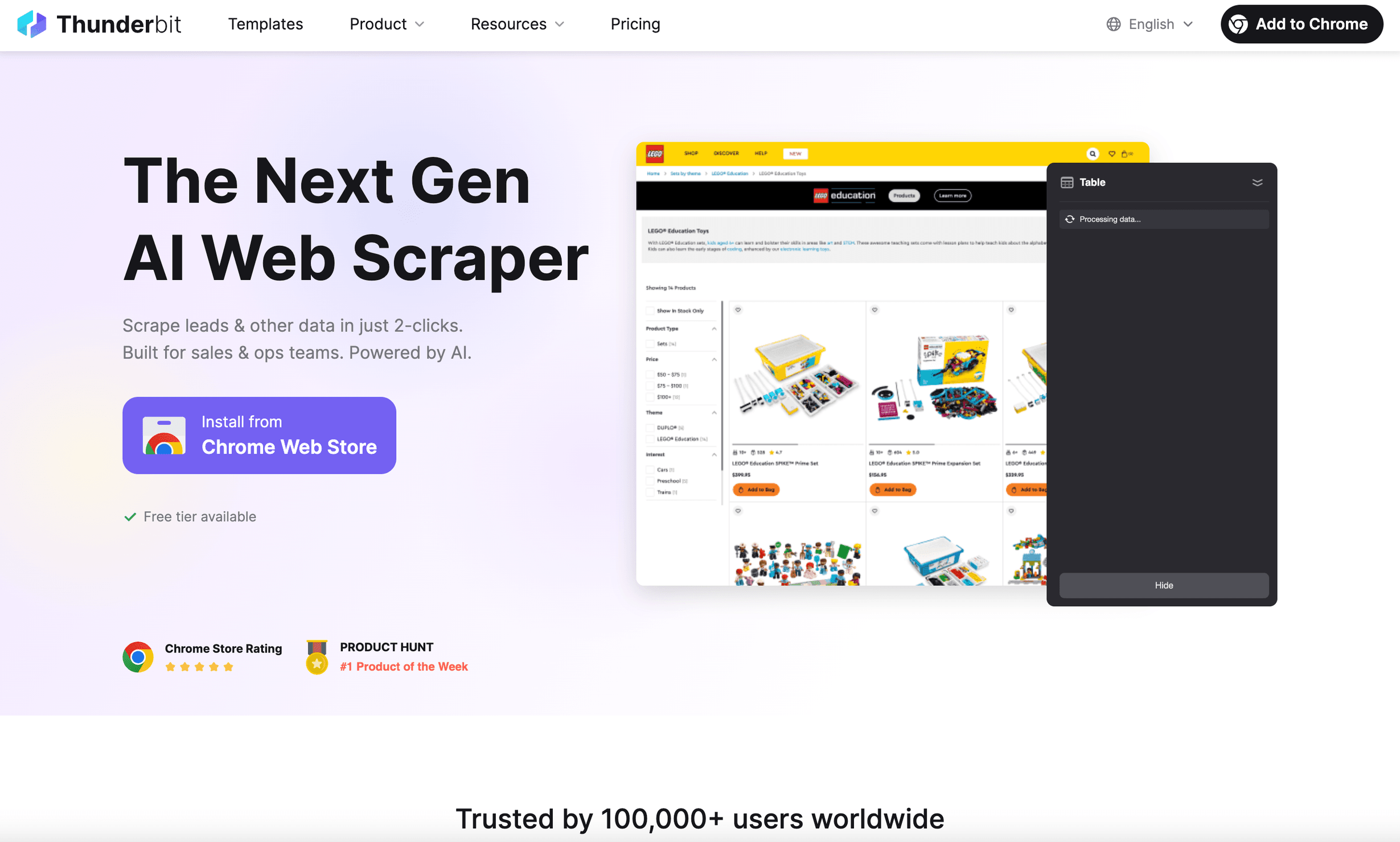 est le navigateur headless Python que j’aurais aimé avoir il y a des années. Ce n’est pas seulement un outil d’automatisation de navigateur : c’est une extension Chrome d’Extracteur Web IA pensée pour les utilisateurs métier qui veulent des résultats, pas des prises de tête.
est le navigateur headless Python que j’aurais aimé avoir il y a des années. Ce n’est pas seulement un outil d’automatisation de navigateur : c’est une extension Chrome d’Extracteur Web IA pensée pour les utilisateurs métier qui veulent des résultats, pas des prises de tête.
Pourquoi Thunderbit se démarque :
- Champs suggérés par l’IA : cliquez simplement sur « Champs suggérés par l’IA », et l’IA de Thunderbit lit la page, recommande les données à extraire et configure l’extracteur pour vous ().
- Modèles de données instantanés : pour les sites les plus populaires (Amazon, Zillow, LinkedIn, etc.), vous obtenez des modèles en un clic — aucune configuration nécessaire.
- Extraction de sous-pages et pagination : Thunderbit peut cliquer à travers les sous-pages, gérer le défilement infini et regrouper toutes les données dans un seul tableau.
- Instructions en langage naturel : décrivez ce que vous voulez en anglais simple ; l’IA de Thunderbit s’occupe du reste.
- Extraction cloud ou dans le navigateur : lancez des extractions en local ou dans le cloud (jusqu’à 50 pages à la fois pour aller plus vite).
- Aucune compétence en code requise : sérieusement — si vous savez utiliser un navigateur, vous savez utiliser Thunderbit.
- Export gratuit des données : exportez vers Excel, Google Sheets, Notion ou Airtable en un clic.
J’ai vu Thunderbit faire gagner des heures aux équipes commerciales et opérationnelles — extraction de leads, surveillance des prix ou agrégation de données produits sans jamais écrire une ligne de code. L’outil est adopté par dans le monde entier, et le retour est toujours le même : « Je n’arrive pas à croire à quel point c’est simple. »
Idéal pour : les non-techniciens, les équipes métier, et toute personne qui veut laisser l’IA faire le gros du travail.
2. Selenium
 est le grand classique de l’automatisation de navigateur. Si vous avez déjà tapé « python headless browser » sur Google, vous êtes probablement tombé sur Selenium WebDriver.
est le grand classique de l’automatisation de navigateur. Si vous avez déjà tapé « python headless browser » sur Google, vous êtes probablement tombé sur Selenium WebDriver.
Avantages :
- Prend en charge tous les navigateurs majeurs : Chrome, Firefox, Safari, Edge, et même Internet Explorer (pour les plus téméraires).
- Communauté immense : une quantité énorme de tutoriels, de plugins et de réponses sur Stack Overflow.
- Très flexible : automatisez tout ce qu’un utilisateur peut faire — clics, formulaires, navigation.
Inconvénients :
- La configuration peut être pénible : il faut gérer les pilotes de navigateur et maintenir les versions synchronisées.
- Plus lent que les outils modernes : le protocole WebDriver ajoute une surcharge, et faire tourner des centaines de navigateurs est peu pratique.
- API verbeuse : vous écrirez plus de code qu’avec Playwright ou Puppeteer.
Idéal pour : les équipes qui maîtrisent déjà Selenium, les tests multi-navigateurs ou les workflows d’automatisation legacy.
3. Puppeteer
 est la bibliothèque d’automatisation haut niveau de Google pour Chrome/Chromium. Même si elle est native à Node.js, les utilisateurs Python peuvent aussi en profiter via Pyppeteer.
est la bibliothèque d’automatisation haut niveau de Google pour Chrome/Chromium. Même si elle est native à Node.js, les utilisateurs Python peuvent aussi en profiter via Pyppeteer.
Avantages :
- Optimisé pour Chrome : rapide, efficace et étroitement intégré à Chrome DevTools.
- API asynchrone : idéal pour les sites modernes riches en JavaScript.
- Fonctionnalités riches : captures d’écran, export PDF, interception réseau.
Inconvénients :
- Uniquement Chromium : pas de support pour Firefox ou Safari.
- Natif Node.js : les utilisateurs Python doivent passer par Pyppeteer (qui n’est plus maintenu — voir ci-dessous).
Idéal pour : les développeurs qui veulent une automatisation Chrome rapide et fiable, sans avoir besoin du multi-navigateur.
4. Playwright
 est le petit nouveau, développé par Microsoft — et il est rapidement devenu mon outil de référence pour l’extraction avancée.
est le petit nouveau, développé par Microsoft — et il est rapidement devenu mon outil de référence pour l’extraction avancée.
Avantages :
- Prise en charge de plusieurs navigateurs : automatisez Chromium, Firefox et WebKit avec une seule API.
- Attente automatique : fini les devinettes pour savoir quand une page est prête — Playwright attend pour vous.
- Concurrence : lancez plusieurs contextes de navigateur en parallèle pour une vitesse fulgurante.
- Pensé d’abord pour Python : bindings Python natifs, en async comme en sync.
Inconvénients :
- Installation plus lourde : plusieurs navigateurs sont intégrés, donc la configuration est un peu plus conséquente.
- Nécessite toujours du code : moins accessible aux profils non techniques que Thunderbit.
Idéal pour : les développeurs qui ont besoin d’une automatisation robuste et moderne — surtout pour des applications web complexes et dynamiques.
5. Headless Chrome
 est le moteur qui alimente de nombreux outils cités plus haut. Vous pouvez le piloter directement via le Chrome DevTools Protocol (CDP) pour une flexibilité maximale.
est le moteur qui alimente de nombreux outils cités plus haut. Vous pouvez le piloter directement via le Chrome DevTools Protocol (CDP) pour une flexibilité maximale.
Avantages :
- Prise en charge web de pointe : si cela fonctionne dans Chrome, cela fonctionne dans Headless Chrome.
- Contrôle très fin : accès à chaque recoin du navigateur.
Inconvénients :
- Courbe d’apprentissage abrupte : il faut parler CDP ou utiliser une bibliothèque intermédiaire.
- Uniquement Chrome : pas de prise en charge multi-navigateurs.
Idéal pour : les experts qui construisent des pipelines d’automatisation sur mesure ou qui intègrent Chrome à bas niveau.
6. Pyppeteer
 est le port Python non officiel de Puppeteer. Il a apporté l’automatisation asynchrone de Chrome à Python, mais… il y a un hic.
est le port Python non officiel de Puppeteer. Il a apporté l’automatisation asynchrone de Chrome à Python, mais… il y a un hic.
Avantages :
- API de style Puppeteer : si vous connaissez Puppeteer, vous vous y sentirez immédiatement à l’aise.
- Automatisation Chrome rapide : très bon pour les sites dynamiques.
Inconvénients :
- Non maintenu : le projet d’origine n’est plus mis à jour (les développeurs recommandent de passer à Playwright).
- Uniquement Chromium : pas de Firefox ni Safari.
Idéal pour : les projets legacy qui utilisent déjà Pyppeteer. Pour les nouveaux projets, utilisez Playwright.
7. Splash
 est un navigateur headless léger et scriptable avec une API HTTP, développé par l’équipe de Scrapinghub (aujourd’hui Zyte).
est un navigateur headless léger et scriptable avec une API HTTP, développé par l’équipe de Scrapinghub (aujourd’hui Zyte).
Avantages :
- Léger : il utilise QtWebKit, donc il consomme moins de ressources que Chrome.
- API HTTP : contrôlez-le depuis n’importe quel langage, pas seulement Python.
- Très bon avec Scrapy : intégration fluide avec les spiders Scrapy pour le rendu JavaScript.
Inconvénients :
- Moteur WebKit plus ancien : peut avoir du mal avec le JavaScript le plus récent.
- Nécessite du scripting Lua : pour les interactions avancées, il faut apprendre un peu de Lua.
Idéal pour : les utilisateurs de Scrapy qui ont besoin d’un rendu JavaScript ponctuel, ou pour des tâches légères de rendu côté serveur.
8. PhantomJS
 est le premier navigateur headless scriptable, basé sur WebKit. Il a été pionnier — mais il est aujourd’hui largement obsolète.
est le premier navigateur headless scriptable, basé sur WebKit. Il a été pionnier — mais il est aujourd’hui largement obsolète.
Avantages :
- Scripting simple : facile à automatiser avec JavaScript.
- Prise en charge legacy : fonctionne encore pour les anciens sites statiques.
Inconvénients :
- Non maintenu : plus aucune mise à jour depuis 2016.
- Moteur dépassé : incapable de gérer les sites modernes riches en JavaScript.
- Risques de sécurité : aucun correctif récent.
Idéal pour : maintenir des scripts legacy. Pour les nouveaux projets, migrez vers Playwright ou Puppeteer.
9. HtmlUnit
 est un navigateur headless basé sur Java qui simule le comportement d’un navigateur. Il est rapide et léger, mais ce n’est pas un vrai moteur de navigateur.
est un navigateur headless basé sur Java qui simule le comportement d’un navigateur. Il est rapide et léger, mais ce n’est pas un vrai moteur de navigateur.
Avantages :
- 100 % Java : excellent pour les environnements très orientés Java.
- Rapide sur les pages statiques : pas besoin de lancer un navigateur complet.
Inconvénients :
- Prise en charge limitée de JavaScript : difficulté avec les sites modernes et dynamiques.
- Pas natif Python : nécessite des couches d’intégration (par exemple, HtmlUnitDriver de Selenium).
Idéal pour : les workflows basés sur Java, les tests d’applications legacy ou l’extraction de pages simples rendues côté serveur.
10. TrifleJS
 est un navigateur headless pour Internet Explorer (IE), conçu pour automatiser des applications web legacy sous Windows.
est un navigateur headless pour Internet Explorer (IE), conçu pour automatiser des applications web legacy sous Windows.
Avantages :
- Automatisation d’IE : gère les anciennes applications intranet ou les systèmes qui ne fonctionnent que sous IE.
- API proche de PhantomJS : peu de modifications nécessaires pour les scripts PhantomJS.
Inconvénients :
- Windows uniquement : pas de prise en charge multiplateforme.
- Obsolète : IE est à la retraite ; TrifleJS reste de niche et rarement maintenu.
Idéal pour : les workflows legacy spécialisés où l’automatisation d’IE reste nécessaire.
Tableau comparatif des fonctionnalités : aperçu des navigateurs headless Python
| Outil | Prise en charge des navigateurs | Performance et échelle | Facilité d’utilisation | Fonctionnalités IA / no-code | Communauté et support | Idéal pour |
|---|---|---|---|---|---|---|
| Thunderbit | Chrome (extension/cloud) | Élevée (parallélisme cloud) | La plus simple — sans code | Oui (IA, modèles) | En croissance, active | Non-développeurs, vente/ops, extraction rapide de données |
| Selenium | Tous les navigateurs majeurs | Moyenne | Moyenne (configuration) | Non | Très grande, mature | Multi-navigateurs, legacy, automatisation de tests |
| Puppeteer | Chromium/Chrome | Très élevée | Élevée (développeurs) | Non | Grande (Node.js) | Chrome uniquement, développeurs, automatisation rapide |
| Playwright | Chromium, Firefox, WebKit | Très élevée (multi-contextes) | Élevée (développeurs) | Non | En forte croissance | Avancé, multi-navigateurs, extraction moderne |
| Headless Chrome | Chrome/Edge | Très élevée | Faible (CDP manuel) | Non | N/A (fondation) | Sur mesure, experts, contrôle bas niveau |
| Pyppeteer | Chromium/Chrome | Élevée | Moyenne (async) | Non | Petite, non maintenue | Scripts Pyppeteer legacy |
| Splash | QtWebKit | Moyenne | Moyenne (API/Lua) | Non | De niche (Scrapy/Zyte) | Utilisateurs Scrapy, rendu JavaScript léger |
| PhantomJS | WebKit (ancien) | Faible (désormais obsolète) | Moyenne (JS) | Non | Discontinué | Legacy uniquement |
| HtmlUnit | Simulé (Java) | Moyenne/Élevée (statique) | Faible (Java) | Non | Petite, centrée Java | Workflows Java, pages simples/statique |
| TrifleJS | Internet Explorer (Trident) | Faible/Moyenne | Moyenne (JS, Win) | Non | Très petite, legacy | Automatisation legacy IE uniquement |
Comment choisir le bon navigateur headless Python pour votre entreprise
Voici ma fiche mémo pour choisir le bon outil :
- Vous avez besoin d’une extraction rapide, sans code, avec l’aide de l’IA ? Optez pour . C’est la façon la plus simple pour les non-développeurs d’obtenir des données fiables — surtout pour les équipes vente, e-commerce ou recherche.
- Vous voulez un contrôle maximal et une prise en charge multi-navigateurs ? est votre meilleur choix. Il est robuste, moderne et pensé pour la montée en charge.
- Vous avez déjà investi dans Selenium ? Restez sur — il reste le roi des workflows legacy et multi-navigateurs.
- Vous construisez une automatisation Chrome uniquement en tant que développeur ? (ou Playwright) est rapide et puissant.
- Vous extrayez des pages simples et statiques dans un environnement Java ? est léger et facile à intégrer.
- Vous maintenez des scripts legacy ou des applis qui ne fonctionnent que sur IE ? et sont vos amis de dernier recours.
Et n’oubliez pas : le meilleur outil est celui qui correspond à votre workflow, aux compétences de votre équipe et aux besoins de votre entreprise. Parfois, cela signifie combiner plusieurs outils — utiliser Thunderbit pour les tâches rapides, Playwright pour les gros chantiers et Selenium pour les systèmes legacy.
FAQ
1. Qu’est-ce qu’un navigateur headless Python, et pourquoi en ai-je besoin pour l’extraction ?
Un navigateur headless Python est un navigateur web que vous contrôlez avec du code Python, mais qui fonctionne invisiblement (sans interface graphique). Il est indispensable pour extraire des sites modernes riches en JavaScript, car il peut exécuter des scripts, gérer les interactions utilisateur et récupérer du contenu entièrement rendu — ce que les extracteurs HTML traditionnels ne peuvent pas faire.
2. Quel navigateur headless Python est le meilleur pour les utilisateurs non techniques ?
est le meilleur choix pour les non-développeurs. Il utilise l’IA pour automatiser la configuration, propose des modèles instantanés et vous permet d’extraire des données en quelques clics seulement — sans programmation.
3. Quelle est la différence entre Playwright et Puppeteer pour les utilisateurs Python ?
Playwright prend en charge plusieurs navigateurs (Chromium, Firefox, WebKit) et dispose de bindings Python robustes, ce qui en fait un outil idéal pour l’automatisation avancée. Puppeteer est limité à Chrome et natif à Node.js, mais les utilisateurs Python peuvent utiliser Pyppeteer (bien qu’il ne soit désormais plus maintenu). Pour de nouveaux projets Python, Playwright est le meilleur choix.
4. Selenium est-il toujours pertinent pour l’extraction web moderne ?
Oui — Selenium reste largement utilisé, en particulier pour les tests multi-navigateurs et l’automatisation legacy. Cependant, sa configuration est plus lente et plus complexe que celle d’outils plus récents comme Playwright ou Thunderbit, et il est moins efficace pour extraire des données à grande échelle.
5. Quand dois-je utiliser des outils legacy comme PhantomJS, HtmlUnit ou TrifleJS ?
Uniquement pour maintenir ou migrer d’anciens workflows. PhantomJS et TrifleJS sont obsolètes, et HtmlUnit convient surtout aux environnements Java avec des pages simples. Pour les nouveaux projets, privilégiez des outils modernes et activement maintenus.
Si vous êtes prêt à voir à quoi ressemble une extraction moderne propulsée par l’IA, . Et pour aller plus loin sur l’automatisation web, consultez le . Bon scraping — que vos données soient toujours fraîches et vos navigateurs éternellement headless.
En savoir plus