Le web, c’est une vraie mine d’or d’infos, mais pour transformer tout ce bazar en données vraiment utiles pour ton business ? C’est là que ça se corse… et que ça devient super intéressant. Après avoir passé des années à bosser sur des solutions SaaS et des outils d’automatisation, j’ai vu le monde passer du feeling à la prise de décision basée sur la data. Aujourd’hui, ce n’est plus réservé aux géants de la tech : même les petites équipes veulent extraire des données de sites web pour booster leurs ventes, leur marketing, leur pricing ou leurs produits. Mais plus le web devient complexe et changeant, plus c’est galère d’obtenir des données propres, conformes et vraiment exploitables.
Soyons clairs : je vais t’expliquer pourquoi l’extraction de données web est devenue incontournable pour les boîtes modernes, les galères principales à gérer, et les meilleures astuces (avec quelques retours d’expérience de chez Thunderbit) pour faire ça bien—légalement, efficacement et à grande échelle. Que tu sois face à des contenus non structurés, que le RGPD te fasse flipper, ou que tu en aies marre de faire du copier-coller dans Excel, ce guide est fait pour toi.
Pourquoi l’Extraction de Données Web Est Incontournable pour les Entreprises d’Aujourd’hui
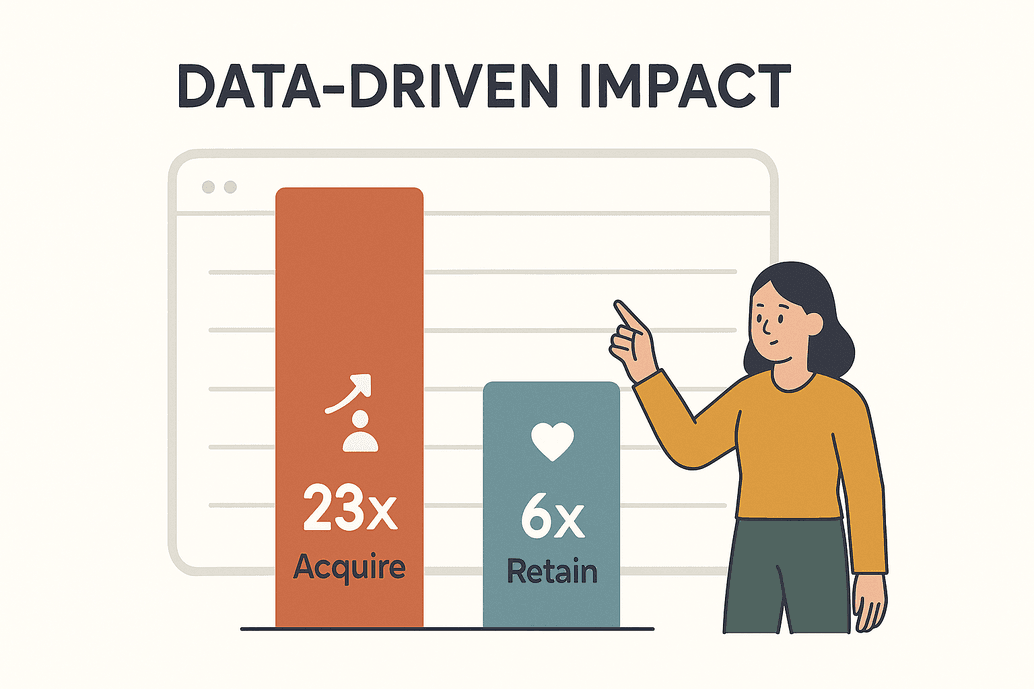 La data, ce n’est pas juste un buzzword : c’est le carburant de la compétitivité aujourd’hui. D’après une , les boîtes pilotées par la donnée ont 23 fois plus de chances de choper de nouveaux clients et 6 fois plus de les garder. Ce n’est pas juste stylé, c’est vital. D’ici 2025, les entreprises vont extraire chaque jour des milliards de pages web pour nourrir leurs analyses, leurs modèles d’IA et leurs décisions en temps réel ().
La data, ce n’est pas juste un buzzword : c’est le carburant de la compétitivité aujourd’hui. D’après une , les boîtes pilotées par la donnée ont 23 fois plus de chances de choper de nouveaux clients et 6 fois plus de les garder. Ce n’est pas juste stylé, c’est vital. D’ici 2025, les entreprises vont extraire chaque jour des milliards de pages web pour nourrir leurs analyses, leurs modèles d’IA et leurs décisions en temps réel ().
Concrètement, ça donne quoi ? Voilà quelques exemples que je croise toutes les semaines :
| Application métier | Description & Bénéfices | Exemple/Stat |
|---|---|---|
| Veille tarifaire | Suivre en temps réel les prix, stocks et promos des concurrents ; ajuster sa stratégie pour rester devant. | Plus de 80% des gros e-commerçants checkent les prix concurrents tous les jours (kanhasoft.com). |
| Génération de leads | Extraire des contacts depuis des annuaires, réseaux sociaux ou sites d’avis. | L’automatisation remplit les CRM bien plus vite que la recherche à la main. |
| Analyse des tendances | Rassembler avis, forums et news pour repérer vite les tendances ou changements d’opinion. | 26% des extractions concernent les réseaux sociaux pour l’analyse de tendances (blog.apify.com). |
| Agrégation de contenu | Centraliser news, fiches produits ou événements de plusieurs sites. | Les médias créent des flux personnalisés pour leur public. |
| Données produit & recherche | Récupérer caractéristiques, avis ou données de recherche pour l’analyse et le développement. | 67% des conseillers en investissement utilisent des données web alternatives (scrap.io). |
| Données pour l’IA | Extraire de gros volumes de textes, images ou sons pour entraîner des modèles IA. | Environ 70% des gros modèles IA tournent avec des données web extraites (kanhasoft.com). |
Si tu n’extrais pas de données du web, tu n’es pas juste à la traîne : tu es carrément invisible sur ton marché. J’ai vu des équipes e-commerce tripler leur ROI en six mois juste en automatisant la veille tarifaire (). Bref : la donnée web, c’est un vrai levier stratégique, et bien l’extraire, c’est devenu indispensable.
Les Galères Majeures de l’Extraction de Données sur le Web
Évidemment, ce n’est pas tout rose. Le web, c’est un vrai far west, et extraire des données, ça pose pas mal de soucis :
- Données non structurées : Environ 80% des données en ligne sont en vrac—planquées dans du HTML fouillis, éparpillées sur plein de pages ou cachées derrière des éléments interactifs. Les transformer en tableau clean, c’est pas gagné ().
- Sites qui changent tout le temps : Les sites modifient souvent leur structure. J’ai vu des extracteurs tomber en rade 15 fois dans le même mois à cause d’un simple changement de design ().
- Volume et échelle : Les boîtes doivent extraire des centaines, voire des milliers de pages—et souvent, ça doit tourner en boucle. Le copier-coller à la main, c’est mort.
- Barrières anti-scraping : CAPTCHAs, limites de fréquence, murs de connexion… Les sites sont de plus en plus malins pour bloquer les robots. Plus d’un tiers du trafic web, c’est des bots (), et les protections évoluent vite.
- Erreurs humaines : Le copier-coller manuel, c’est lent et plein d’erreurs. Un mauvais sélecteur, et tu récupères n’importe quoi—ou rien du tout.
Les vieilles méthodes ne tiennent plus la route. C’est pour ça que de plus en plus d’équipes passent à des solutions automatisées et intelligentes (et pourquoi je crois à fond aux outils boostés à l’IA).
Légalité, Conformité et Sécurité : Les Bons Réflexes pour l’Extraction de Données Web
On va être cash : ce n’est pas parce que tu peux extraire des données d’un site que tu dois le faire—surtout sans réfléchir à la légalité et à l’éthique. Voilà ce qu’il faut garder en tête :
- Données publiques vs privées : Extraire des infos publiques, c’est généralement ok dans pas mal de pays. Mais tout ce qui est derrière une connexion ? Interdit. Faut pas jouer avec le feu ().
- Conditions d’utilisation : Lis toujours les CGU d’un site. Si c’est interdit, tu risques d’être bloqué ou pire. En cas de doute, demande l’autorisation ou passe par les API officielles.
- Législation sur la vie privée (RGPD, CCPA) : Si tu récupères des données perso, il te faut une base légale (intérêt légitime, par exemple), limiter la collecte et être prêt à supprimer sur demande. Sinon, l’addition peut être salée ().
- Respect du robots.txt : Ce n’est pas une loi, mais c’est une question de respect. Suis les règles de crawl-delay et ne spamme pas les serveurs.
- Sécurité des données : Considère les données extraites comme sensibles. Stocke-les de façon sécurisée, limite les accès et nettoie-les avant de t’en servir.
Checklist conformité :
| Point de vigilance | Bonne pratique |
|---|---|
| Accès légal | Extraire uniquement des données publiques ; jamais de contournement de connexion (xbyte.io). |
| Conditions d’utilisation | Lire et respecter les CGU ; utiliser les API si l’extraction est interdite. |
| Données personnelles | Éviter si possible ; sinon, limiter la collecte et respecter RGPD/CCPA. |
| robots.txt & délais de crawl | Respecter les règles du site ; limiter la fréquence des requêtes. |
| Sécurité des données | Chiffrer, restreindre l’accès et supprimer quand ce n’est plus nécessaire. |
Gagner du Temps : Comment l’IA Change la Donne pour l’Extraction de Données Web
C’est là que ça devient vraiment cool. L’IA a complètement changé la façon d’extraire des données du web. Fini les scripts fragiles ou la galère des sélecteurs : les outils intelligents “lisent” la page et repèrent ce qu’il faut extraire—souvent en quelques clics.
En pratique, ça donne quoi ?
- Configuration ultra simple : Des extracteurs IA comme détectent les champs tout seuls. Clique sur “Suggérer les champs IA” et l’outil te propose direct les bonnes colonnes—pas besoin de coder ou de bidouiller.
- Adaptabilité : Les extracteurs IA pigent les schémas, pas juste les structures fixes. Si un site change, l’IA s’adapte souvent toute seule. Moins de maintenance, moins de prise de tête.
- Précision : L’IA fait le tri, enlève les doublons et nettoie les données en temps réel. Certaines équipes atteignent jusqu’à 99,5% de précision avec des extracteurs IA ().
- Contenus dynamiques : Les extracteurs IA gèrent les sites complexes (JavaScript, scroll infini) et peuvent même extraire du texte d’images ou de PDF.
- Traitement instantané : Besoin de traduire, catégoriser ou résumer les données à la volée ? L’IA s’en occupe en un clin d’œil.
 J’ai vu des équipes gagner 30 à 40% de temps sur l’extraction de données rien qu’en passant à des outils IA (). Ce n’est pas juste un gain de productivité : c’est un vrai avantage sur la concurrence.
J’ai vu des équipes gagner 30 à 40% de temps sur l’extraction de données rien qu’en passant à des outils IA (). Ce n’est pas juste un gain de productivité : c’est un vrai avantage sur la concurrence.
Thunderbit a été pensé pour rendre l’extraction simple, précise et accessible—même pour ceux qui n’ont jamais touché une ligne de code. (Et oui, ma mère s’en sert. Par contre, elle galère toujours avec Netflix.)
Thunderbit AI Web Scraper : Les Forces Qui Font la Différence
Je vais me permettre de faire un peu de pub pour ce qu’on a construit chez Thunderbit (franchement, c’est mérité !). Thunderbit vise les pros—ventes, ops, marketing, immobilier—qui veulent des résultats, pas des migraines. Voilà ce qui change tout :
- Suggérer les champs IA : Un clic, et l’IA de Thunderbit scanne la page, propose les colonnes et configure l’extracteur. Fini les sélecteurs à la main.
- Extraction en 2 clics : Une fois les champs choisis, clique sur “Extraire” et récupère un tableau clean—sans code, sans prise de tête.
- Extraction de sous-pages : Besoin de détails ? Thunderbit va automatiquement sur chaque sous-page (fiche produit, profil…) et enrichit ton tableau.
- Modèles prêts à l’emploi : Pour les sites connus (Amazon, Zillow, Instagram, Shopify…), choisis un modèle et c’est parti—aucun réglage à faire.
- Exportation partout : Export gratuit vers Excel, Google Sheets, Airtable, Notion ou CSV. Pas de frais cachés.
- Extraction programmée : Automatise les extractions récurrentes—tu dis juste la fréquence (“tous les lundis à 8h”) et Thunderbit gère tout.
- Cloud ou navigateur : Utilise les serveurs cloud de Thunderbit pour la rapidité, ou ton navigateur pour les sites qui demandent une connexion.
- Multi-langues : Extraction possible dans 34 langues, dont l’anglais, l’espagnol, le chinois, etc.
Automatiser et Passer à la Vitesse Supérieure : Programmer et Intégrer l’Extraction de Données
L’extraction à la main, c’est dépassé. Le vrai game, c’est d’automatiser et d’intégrer l’extraction dans tes process :
- Extraction programmée : Planifie Thunderbit pour lancer des extractions chaque jour, chaque semaine, ou comme tu veux. Parfait pour la veille tarifaire, la génération de leads ou l’agrégation de news.
- Intégration directe : Envoie les données extraites direct dans Google Sheets, Excel, Airtable ou Notion. Fini les imports manuels.
- Connexion CRM & Analytics : Balance les données dans ton CRM ou tes outils BI pour des dashboards en temps réel, des alertes ou des campagnes auto.
Exemple : Workflow de veille tarifaire automatisée
- Configure Thunderbit sur la page produit d’un concurrent.
- Utilise “Suggérer les champs IA” pour choper nom, prix et URL du produit.
- Programme l’extraction chaque matin à 7h.
- Exporte les résultats vers Google Sheets, relié à un dashboard.
- Le responsable pricing ajuste la stratégie avant même que la concurrence ne bouge.
Avec l’automatisation, tu es non seulement plus rapide, mais toujours à jour.
Astuces pour Gérer les Données Non Structurées lors de l’Extraction Web
Soyons honnêtes : la plupart des données web sont en vrac, incohérentes, parfois même n’importe quoi. Voilà comment les remettre d’équerre :
- Définir la structure avant : Utilise les suggestions IA ou les modèles pour structurer tes données—décide des colonnes et types avant d’extraire.
- Prompts IA par champ : Thunderbit permet d’ajouter des instructions personnalisées pour chaque champ. Besoin de catégoriser, formater un numéro ou traduire une description ? Demande à l’IA.
- Exploiter le NLP : Pour les avis, commentaires ou articles, utilise les fonctions NLP intégrées pour résumer, analyser le sentiment ou extraire des mots-clés.
- Normaliser les données : Nettoie les formats (dates, prix, téléphones) dès l’extraction. La cohérence, c’est la base.
- Dédupliquer et valider : Vire les doublons et vérifie la qualité. Si un résultat te paraît bizarre, ajuste tes prompts ou paramètres.
Prompts IA par Champ : Personnalise l’Extraction pour des Résultats au Top
C’est une de mes options préférées. Avec les prompts IA par champ, tu peux :
- Étiqueter et classer : « Classe ce produit en Électronique, Mobilier ou Vêtements selon sa description. »
- Imposer un format : « Affiche la date au format AAAA-MM-JJ. » « Extrais juste le prix numérique. »
- Traduire à la volée : « Traduis la description du produit en français. »
- Nettoyer le bruit : « Extrais la bio utilisateur, sans les liens ‘Lire la suite’ ou les pubs. »
- Fusionner des champs : « Regroupe les lignes d’adresse en un seul champ. »
C’est comme avoir un assistant data intégré à ton extracteur—qui ne prend jamais de pause café.
Assurer la Qualité et la Cohérence des Données Extraites
Une bonne extraction, ça ne s’arrête pas à l’export. Voilà comment garder des données fiables :
- Contrôles de validation : Mets en place des vérifs de plage, champs obligatoires et clés uniques pour repérer les erreurs.
- Audit par échantillon : Vérifie à la main un échantillon de données extraites par rapport au site source—surtout après une nouvelle config ou un changement de site.
- Gestion des erreurs : Note les échecs d’extraction et mets des alertes en cas d’anomalie (genre une chute du nombre de lignes).
- Nettoyage continu : Utilise des outils tableur ou scripts pour enlever les espaces, corriger l’encodage et normaliser le texte.
- Cohérence du schéma : Garde des noms de champs et formats stables dans le temps. Note les changements pour éviter les mauvaises surprises.
La confiance dans tes données, c’est la clé. Un peu de rigueur au début, et tu t’épargnes bien des galères après.
Comparatif des Outils : Comment Choisir le Bon Extracteur
Tous les extracteurs web ne se valent pas. Voilà ce qu’il faut regarder :
| Outil | Points forts | Points à surveiller |
|---|---|---|
| Thunderbit | Ultra simple pour les non-techs ; détection IA des champs ; extraction de sous-pages ; modèles prêts à l’emploi ; export gratuit ; prix abordables (Thunderbit Blog). | Pas fait pour les très gros projets techniques ; système de crédits. |
| Browse AI | No-code, top pour la veille de changements ; intégration Google Sheets ; extraction en masse. | Abonnement de base plus cher ; config parfois longue. |
| Octoparse | Puissant, gère les sites dynamiques ; options avancées pour les techniciens. | Prise en main pas évidente ; prix élevé. |
| Web Scraper (webscraper.io) | Gratuit pour petits projets ; config visuelle ; communauté active. | Paramétrage manuel parfois galère ; peu d’aide IA. |
| Diffbot | IA avancée, analyse les pages non structurées via API ; parfait pour les devs. | Cher, basé sur API, pas pour les non-techs. |
Mon conseil : Si tu es un utilisateur métier qui veut des résultats rapides et fiables, est un super choix. Pour les devs ou les gros besoins, Octoparse ou Diffbot peuvent valoir le coup d’œil. Teste toujours la version gratuite avant de t’engager.
Conclusion : Passe à l’Action avec les Bons Réflexes d’Extraction Web
Extraire des données du web, ce n’est plus un “plus”—c’est devenu indispensable pour rester dans la course. À retenir :
- Valeur : Les données web te permettent de décider plus vite et plus juste. Ne les laisse pas de côté.
- Surmonte les galères : Utilise des outils IA pour gérer le non structuré, le volume et les changements de sites.
- Reste dans les clous : Respecte la loi, les règles des sites et la sécurité des données.
- Automatise : Programme et intègre l’extraction dans ta routine.
- Priorité à la qualité : Valide, nettoie et surveille tes données pour qu’elles restent fiables.
Envie de voir à quel point c’est simple ? et teste-la sur ton prochain projet data. Pour aller plus loin, checke le pour d’autres guides, astuces et retours d’expérience.
Bonne extraction—et que tes données soient toujours clean, conformes et prêtes à l’emploi !
FAQ
1. Est-ce légal d’extraire des données de n’importe quel site ?
En général, extraire des données publiques, c’est autorisé dans pas mal de pays, mais il ne faut jamais contourner une connexion ou des protections. Lis toujours les conditions d’utilisation du site et respecte les lois sur la vie privée comme le RGPD ou le CCPA ().
2. Comment l’IA booste l’extraction de données web ?
Des outils comme détectent les champs tout seuls, s’adaptent aux changements de structure, nettoient et formatent les données, et gèrent même les contenus dynamiques ou les traductions—tout ça avec une config minimale et une super précision ().
3. Quelles sont les bonnes pratiques pour gérer les données non structurées ?
Définis la structure avant, utilise des prompts IA par champ pour guider l’extraction, normalise les formats dès le départ et valide tes résultats. Thunderbit facilite la catégorisation, le formatage et l’étiquetage des données à la volée.
4. Comment automatiser et passer à l’échelle l’extraction de données web ?
Utilise la programmation pour lancer des extractions régulières, et envoie les résultats direct dans Google Sheets, Airtable ou ton CRM. L’automatisation, c’est la garantie d’avoir des données toujours fraîches et moins de boulot manuel.
5. Comment assurer la qualité et la cohérence des données extraites ?
Mets en place des contrôles de validation, audite régulièrement des échantillons, gère les erreurs et garde un schéma stable dans le temps. L’amélioration continue et la surveillance, c’est la base pour des données fiables.
Tu veux voir ces bonnes pratiques en vrai ? et découvre à quel point l’extraction web peut être simple, légale et scalable.
Pour aller plus loin