

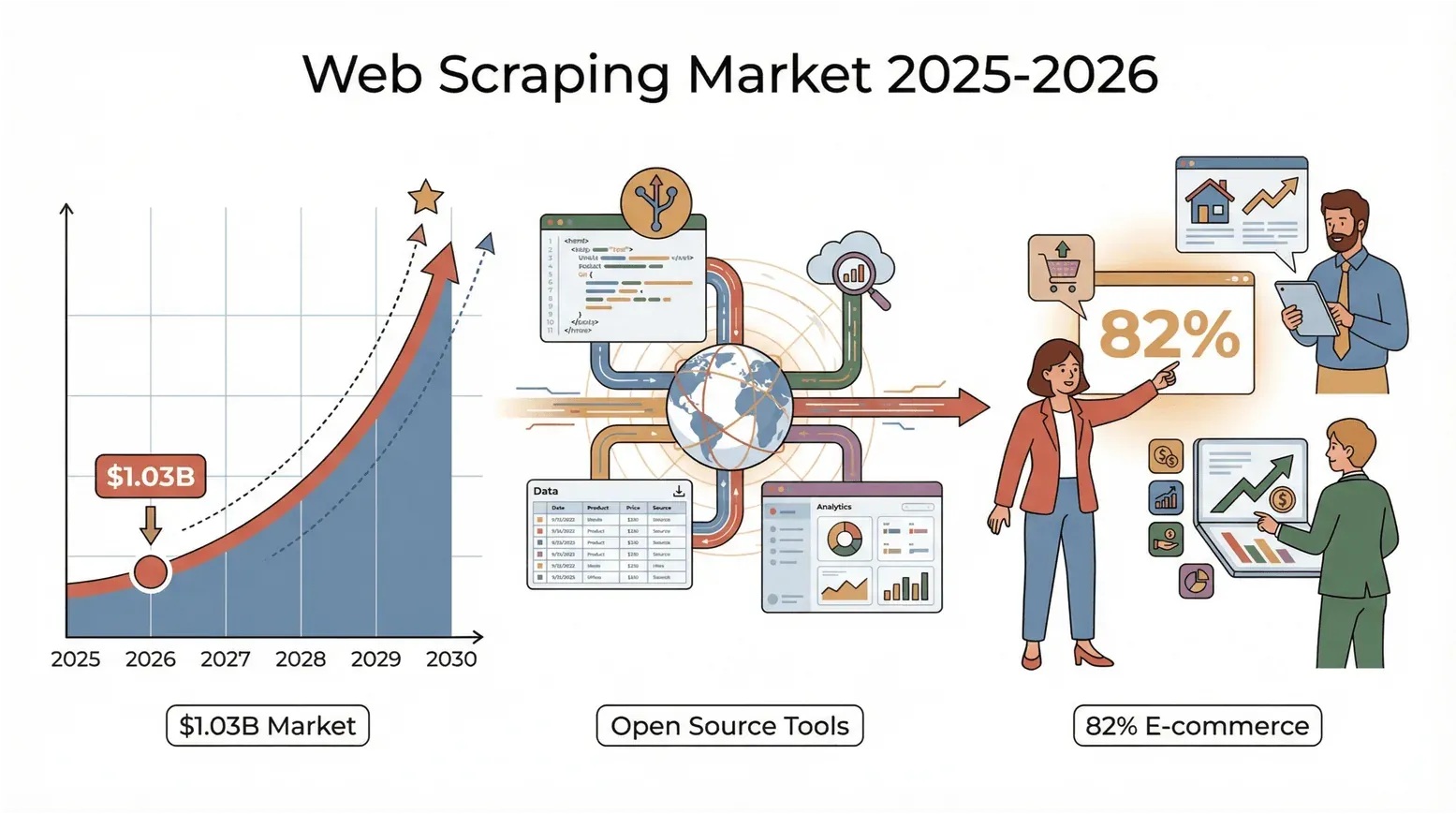
Le web déborde de données, et en 2026, transformer ce flux désordonné en informations exploitables n'a jamais été aussi disputé. Que vous travailliez dans la vente, le e-commerce, l'immobilier, ou que vous soyez simplement passionné de données comme moi, vous avez sans doute constaté que le bon vieux « copier-coller » ne suffit plus. Un chiffre pour mesurer l'ampleur du phénomène : le marché mondial du web scraping a atteint 1,03 milliard de dollars en 2025 selon Mordor Intelligence (cité dans le rapport 2026 sur l'état du web scraping de PromptCloud), et il devrait à peu près doubler d'ici 2030.
Et il ne s'agit pas seulement des géants de la tech : 82 % des entreprises de e-commerce et plus d'un tiers des sociétés d'investissement extraient déjà des données du web pour générer des prospects, comparer les prix et mener des études de marché (Browsercat). En clair : sans outil de web scraping, vous laissez probablement de l'argent — et des informations précieuses — sur la table.
Bonne nouvelle, en revanche : les outils open source de web scraping n'ont jamais été aussi puissants, aussi accessibles et aussi portés par leur communauté. Que vous soyez adepte de Python, fan de JavaScript ou utilisateur métier qui veut simplement ses données sans se compliquer la vie, il existe un outil pour vous. J'ai passé des années dans le SaaS et l'automatisation, et j'ai vu cet écosystème mûrir. Voici donc les 5 meilleurs outils open source de web scraping à explorer en 2026 — ainsi que la manière de choisir celui qui répondra le mieux à vos besoins.
Pourquoi choisir des outils open source de web scraping ?
Qu’est-ce que le data scraping et comment le faire en 2026 Get Started Free
Les outils open source de web scraping sont les véritables tout-en-un de l'univers de la donnée. Ils sont économiques (aucun frais de licence), flexibles (vous pouvez tout personnaliser) et transparents (vous voyez exactement comment ils fonctionnent). Mais leur vraie force réside ailleurs : dans la communauté. Des milliers de développeurs et d'utilisateurs partagent plugins, tutoriels et correctifs, si bien que vous n'êtes jamais seul (Oreate AI).
Face aux outils commerciaux, les options open source vous laissent les commandes. Vous n'êtes pas tributaire de la feuille de route ou des tarifs d'un éditeur, et vous pouvez adapter vos extracteurs au gré de l'évolution des sites. Autre point : de nombreux services commerciaux de scraping reposent en réalité sur ces moteurs open source — alors pourquoi ne pas aller directement à la source ?
Comment nous avons sélectionné les meilleurs outils open source de web scraping
Avec autant d'options disponibles, je me suis concentré sur quelques critères clés :
- Facilité d'utilisation : les non-développeurs peuvent-ils démarrer rapidement ? Existe-t-il des options visuelles ou pilotées par l'IA ?
- Scalabilité : l'outil tient-il la charge sur de gros projets, ou se limite-t-il aux tâches ponctuelles ?
- Prise en charge des langages et des plateformes : Python, JavaScript, navigateur, bureau — il y en a pour chaque stack.
- Communauté et maintenance : l'outil est-il activement mis à jour ? Existe-t-il des forums, de la documentation et des plugins ?
- Fonctionnalités uniques : détection de champs par IA, scraping de sous-pages, planification, support cloud, et bien plus encore.
J'ai aussi tenu compte des retours du terrain et des cas d'usage métier — car le meilleur outil reste celui qui résout réellement votre problème.
Les 5 meilleurs outils open source de web scraping à explorer
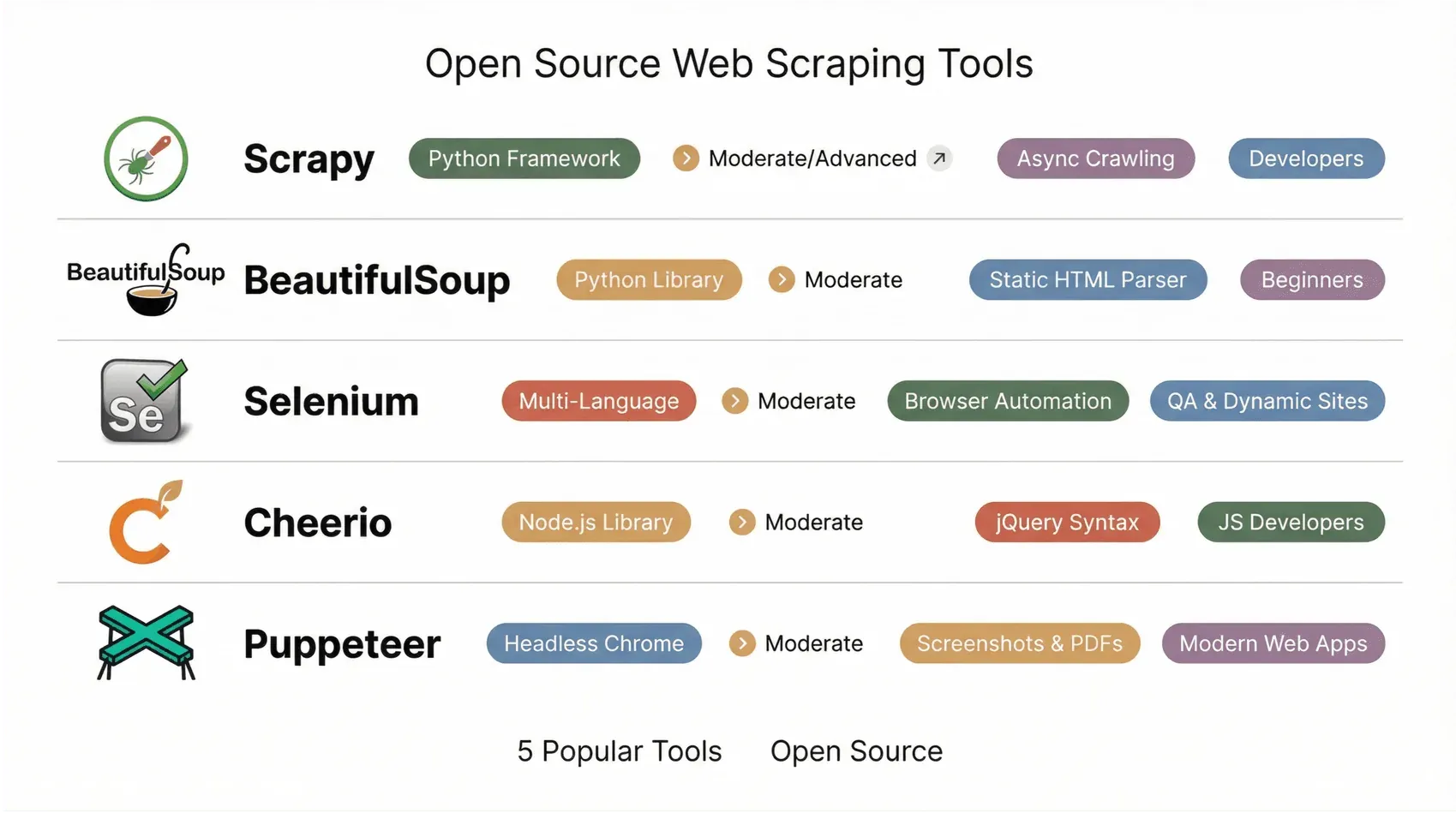
Entrons dans le vif du sujet. Voici ma sélection personnelle, de la simplicité dopée à l'IA aux frameworks les plus puissants pour développeurs.
1. Scrapy
Scrapy est un régal pour les développeurs Python. C'est un framework éprouvé pour créer des robots d'exploration et des pipelines de données à la fois scalables et personnalisables. Vous définissez des « spiders » en Python, et Scrapy gère la mise en file d'attente, la limitation de débit et l'export vers JSON, CSV ou XML. Depuis la version 2.14 (octobre 2025) et le correctif 2.14.1 (janvier 2026), une grande partie des internals Twisted-Deferred de Scrapy a été réécrite en coroutines asyncio natives, avec un nouveau point d'entrée AsyncCrawlerProcess qui s'intègre bien dans l'écosystème Python async moderne ; le reactor asyncio est désormais le comportement par défaut pour les projets nouvellement générés. À noter : Scrapy 2.14+ exige Python 3.10 ou une version plus récente.
L'écosystème de plugins est immense, avec des middlewares pour les proxies, les cookies et même l'intégration de navigateurs headless pour les sites dynamiques. Scrapy est le framework vers lequel se tournent la plupart des équipes lorsqu'il faut parcourir des catalogues e-commerce entiers ou agréger des actualités à grande échelle. La courbe d'apprentissage est raide pour les non-développeurs, mais si vous recherchez puissance et flexibilité, Scrapy tient ses promesses (Octoparse).
2. Beautiful Soup
Beautiful Soup est la bibliothèque Python classique pour analyser du HTML rapidement et sans complication. Débutants comme experts l'apprécient pour sa courbe d'apprentissage douce et son analyseur indulgent (il s'accommode même du HTML le plus désordonné). Vous récupérez une page (généralement avec requests), vous la chargez dans Beautiful Soup, puis vous utilisez des méthodes simples pour trouver et extraire les éléments.
C'est parfait pour les petits projets, les prototypes et l'apprentissage. Le revers de la médaille ? Beautiful Soup ne peut pas exécuter le JavaScript, et ne fonctionne donc que sur du HTML statique. Pour les sites dynamiques, il faut l'associer à Selenium ou à requests_html (ProsperaSoft).
3. Selenium
Selenium est le grand classique de l'automatisation de navigateur. Conçu à l'origine pour les tests, il est devenu un favori pour extraire des données sur des sites dynamiques très dépendants de JavaScript. Selenium lance un vrai navigateur (Chrome, Firefox, etc.) et simule des actions utilisateur — clics, défilement, connexions, tout y passe. Si un humain peut le voir, Selenium peut l'extraire.
Il prend en charge plusieurs langages (Python, Java, JS, C#) et excelle pour le scraping derrière une authentification ou dans des parcours interactifs. Selenium 4 intègre aussi progressivement WebDriver BiDi, un protocole bidirectionnel qui permet à votre script de s'abonner aux événements du navigateur (requêtes réseau, logs de console, mutations du DOM) et d'intercepter les appels réseau — des fonctionnalités qui rendaient jusqu'ici Puppeteer ou Playwright plus pratiques pour le scraping. Les versions 4.40 (janvier 2026) et 4.41 (février 2026) ont étendu la prise en charge de BiDi aux bindings Python, Java, .NET et Ruby. Les inconvénients restent inchangés : Selenium est plus lent et plus lourd que les extracteurs purement HTTP, et la gestion des drivers de navigateur demeure fastidieuse. Mais pour les sites difficiles — et pour les équipes déjà standardisées sur Selenium pour l'automatisation des tests — il reste une option de scraping crédible en 2026 (ScrapeHero).
4. Cheerio
Cheerio est le jQuery de l'univers Node.js. Il permet d'analyser du HTML côté serveur avec une syntaxe familière, proche de jQuery. C'est extrêmement rapide et parfait pour les pages statiques : récupérez simplement le HTML (avec Axios ou Fetch), chargez-le dans Cheerio, puis utilisez des sélecteurs pour extraire ce qu'il vous faut.
Cheerio n'exécute pas le JavaScript : il est donc surtout adapté au contenu statique. Mais il s'intègre à merveille avec les autres outils Node.js, et c'est un favori des développeurs qui veulent tout garder en JavaScript (Cheerio Docs).
5. Puppeteer
Puppeteer est une bibliothèque Node.js qui permet de piloter Chrome ou Chromium en mode headless. C'est un choix populaire pour extraire des données d'applications web modernes et d'applications monopage qui nécessitent un vrai rendu navigateur : captures d'écran, génération de PDF, interception réseau, le tout derrière une API claire en async/await. L'équipe Chrome de Google maintient toujours Puppeteer et l'aligne sur chaque nouvelle version de Chrome et chaque mise à jour du DevTools Protocol.
Un point de contexte utile pour 2026 : le rythme des versions de Puppeteer porte désormais surtout sur la compatibilité Chrome et les mises à jour de dépendances, plutôt que sur de nouvelles fonctionnalités. L'équipe à l'origine des ambitions les plus avancées de Puppeteer a ensuite créé Playwright chez Microsoft. Si vous utilisez déjà Puppeteer et n'avez besoin que d'automatiser Chrome, il reste un choix stable. Si vous partez de zéro et souhaitez une prise en charge multi-navigateurs, un test runner intégré, des locators avec attente automatique et une visionneuse de traces, la plupart des équipes se tournent en 2026 d'abord vers Playwright (Firecrawl — Playwright vs Puppeteer, Autonoma — Playwright vs Puppeteer 2026).
Essayez gratuitement le Web Scraper IA de Thunderbit
Tableau comparatif rapide : meilleurs outils open source de web scraping
| Outil | Facilité d’utilisation | Plateforme/Langage | Contenu dynamique | Idéal pour | Points forts uniques |
|---|---|---|---|---|---|
| Scrapy | Moyen/Avancé (code) | Framework Python | Partiel | Développeurs, data scientists | Scraping asynchrone, plugins, grande communauté |
| BeautifulSoup | Moyen (code simple) | Bibliothèque Python | Non | Débutants, analyse rapide | Analyseur indulgent, excellent pour le HTML statique |
| Selenium | Moyen (script) | Multi-langage | Oui | QA, scraping de sites dynamiques | Automatisation réelle du navigateur, gère les connexions et les événements utilisateur |
| Cheerio | Moyen (code JS) | Bibliothèque Node.js | Non | Développeurs JS, pages statiques | Syntaxe jQuery, analyse HTML rapide |
| Puppeteer | Moyen (code JS) | Node.js (Chrome headless) | Oui | Développeurs, applications web modernes | Captures d’écran, PDF, scraping de SPA, API async/await |
Comment choisir le bon outil open source de web scraping selon vos besoins
Comment extraire n’importe quel site web avec l’IA Get Started Free
Voici mon aide-mémoire pour faire le bon choix :
- Niveau technique : pas développeur ? Commencez avec Thunderbit, Octoparse, ParseHub ou WebHarvy. Développeur ? Scrapy, Cheerio, Puppeteer ou Apify.
- Taille du projet : tâche ponctuelle ou petit volume ? Beautiful Soup, Cheerio, WebHarvy. Projet à grande échelle ou récurrent ? Scrapy, Apify, Thunderbit (avec planification).
- Type de données : HTML statique ? Optez pour Cheerio, Beautiful Soup ou WebHarvy. Dynamique ou très axé JS ? Puppeteer, Selenium, Thunderbit, Octoparse.
- Intégration : vous devez exporter vers Sheets, Notion ou des bases de données ? Thunderbit et Octoparse facilitent la tâche. Vous avez besoin d'API ou de pipelines personnalisés ? Scrapy et Apify sont vos alliés.
- Communauté et support : recherchez des forums actifs, des mises à jour récentes et de nombreux tutoriels. Scrapy, Cheerio et Selenium ont d'immenses communautés ; Thunderbit et Octoparse ont des bases d'utilisateurs en croissance et beaucoup de guides.
Testez quelques outils sur un petit projet — vous verrez vite lequel s'accorde à votre flux de travail et à votre niveau de confort. Et n'hésitez pas à combiner plusieurs approches : la solution la plus rapide consiste parfois à faire un scraping express avec un outil visuel, puis un crawl plus poussé avec un framework basé sur le code.
La valeur de la communauté et du support continu dans le scraping open source
L'un des plus grands atouts de l'open source ? La communauté. Forums actifs, dépôts GitHub et tags Stack Overflow : vous n'êtes jamais seul. Si vous bloquez, il y a de fortes chances que quelqu'un ait déjà résolu le problème — ou puisse vous aider. Les outils portés par la communauté bénéficient de mises à jour fréquentes et de nouvelles fonctionnalités, et vous trouverez une foule de tutoriels, de plugins et de bonnes pratiques (Oreate AI).
Pour les outils visuels comme Thunderbit et Octoparse, les forums utilisateurs et le partage de modèles constituent une vraie mine d'or. Pour les outils destinés aux développeurs, ce sont les issues GitHub et les groupes Discord/Slack qui font la différence. En choisissant un outil open source, vous rejoignez un réseau mondial de personnes qui résolvent des problèmes — et c'est une valeur inestimable.
Thunderbit : une solution de web scraping sans code, plus simple, à la portée de tous
L'open source a de quoi séduire — mais parfois, vous n'avez tout simplement pas envie de construire, régler et surveiller un extracteur juste pour obtenir des données exploitables. Et tous les problèmes de scraping ne se résolvent pas avec du code open source : c'est précisément là que Thunderbit trouve sa place. Si vous avez lu jusqu'ici en vous disant « Ces outils sont puissants, mais je veux juste les données, sans avoir à construire ni maintenir des extracteurs », Thunderbit est l'étape suivante la plus naturelle.
Thunderbit est une extension Chrome dopée à l'IA, conçue pour les utilisateurs métier qui se soucient davantage des résultats que de l'infrastructure. Au lieu d'écrire des sélecteurs ou des scripts, vous commencez par cliquer sur AI Suggest Fields. L'IA comprend la structure de la page, propose des colonnes, et vous lancez l'extraction d'un second clic. La pagination, les sous-pages et les parcours liste-vers-détail sont pris en charge à votre place.
L'une des plus grandes forces de Thunderbit, c'est sa capacité à relier l'intention humaine aux données structurées. Vous décrivez ce que vous voulez en langage naturel (par exemple : « collecte les noms des produits, les prix et les notes »), et Thunderbit le transforme en un tableau propre. Le scraping de sous-pages facilite l'extraction de données plus riches en visitant automatiquement les pages de détail. Les exports vers Excel, Google Sheets, Notion et Airtable sont intégrés, ce qui rend vos données immédiatement exploitables.
Thunderbit a particulièrement la faveur des équipes commerciales, marketing, e-commerce et immobilières qui ont besoin de données fiables sans vouloir maintenir des pipelines open source. Il prend en charge des dizaines de langues, se débrouille bien sur les sites dynamiques et propose une formule gratuite généreuse pour démarrer. Bien qu'il ne soit pas open source, il complète parfaitement les outils open source — voyez-le comme le moyen le plus rapide de valider des idées ou de gérer des extractions métier récurrentes sans surcharge d'ingénierie.
Conclusion : exploiter les données du web avec les meilleurs outils open source
Le web scraping n'est plus l'apanage des développeurs ou des grandes entreprises. Avec les outils open source d'aujourd'hui, chacun peut transformer le web en données structurées et exploitables — que vous construisiez une liste de prospects, surveilliez des prix ou alimentiez votre prochain projet d'IA. L'essentiel est d'adapter l'outil à votre besoin : outils visuels et pilotés par l'IA pour aller vite et rester simple, frameworks de code pour gagner en puissance et en échelle.
Et maintenant ? Choisissez un outil dans cette liste, mettez-le à l'épreuve sur une tâche réelle et mesurez le temps et l'énergie économisés. Et si vous cherchez une victoire rapide, téléchargez Thunderbit et découvrez à quel point le web scraping peut être simple. Le web est à portée de main — à vous d'aller y puiser vos données.
Pour aller plus loin avec des analyses et des tutoriels, consultez le blog Thunderbit. Bonne extraction !
Essayez gratuitement le Web Scraper IA de Thunderbit Get Started Free
FAQ
1. Quel est le principal avantage des outils open source de web scraping par rapport aux outils commerciaux ?
Les outils open source sont économiques, flexibles et soutenus par des communautés actives. Vous pouvez les personnaliser, éviter l'enfermement propriétaire et profiter de connaissances partagées ainsi que de mises à jour fréquentes.
2. Quel outil open source convient le mieux aux utilisateurs métier non techniques ?
Thunderbit, Octoparse, ParseHub et WebHarvy sont tous excellents pour les non-développeurs. Thunderbit se distingue par son workflow piloté par l'IA en deux clics et ses options d'export direct.
3. Les outils open source peuvent-ils gérer des sites dynamiques très chargés en JavaScript ?
Oui. Des outils comme Thunderbit, Selenium, Puppeteer, Octoparse et ParseHub peuvent tous extraire du contenu dynamique en rendant les pages dans un navigateur réel ou headless.
4. Comment savoir si un outil est activement maintenu et pris en charge ?
Vérifiez sur GitHub les commits récents, les issues ouvertes et l'activité des contributeurs. Recherchez des forums actifs, des articles de blog récents et de nombreux plugins ou modèles fournis par les utilisateurs.
5. Quelle est la meilleure façon de débuter dans le web scraping ?
Commencez avec un outil visuel ou piloté par l'IA comme Thunderbit ou Octoparse. Essayez d'extraire un petit jeu de données, exportez-le vers Excel ou Sheets, puis expérimentez. Une fois à l'aise, vous pourrez explorer des outils basés sur le code pour des projets plus avancés.
Vous voulez voir Thunderbit à l'œuvre ? Téléchargez l'extension Chrome et rejoignez plus de 30 000 utilisateurs qui transforment le web en données — sans écrire une seule ligne de code.
En savoir plus
- 7 outils de web scraping les plus populaires à utiliser en 2026
- Top 5 des meilleurs logiciels de scraping de données web en 2026
- Top 6 des outils essentiels de web scraper pour réussir en 2025
- Les meilleurs outils et logiciels de web scraping en 2025
- Top 17 des outils de scraping de sites web en 2025




