Quelque part entre 2 et 3 millions d’articles d’actualité sont publiés en ligne chaque jour. Essayer de collecter ces données de façon structurée — titres, dates, sources, texte intégral des articles — est à peu près aussi agréable que de monter un meuble sans notice.
Cela fait des années que je construis et teste des outils d’automatisation chez , et le paysage du news scraping en 2026 est un mélange étrange d’opportunités incroyables et de frustration bien réelle. Google a supprimé son API News officielle en 2011, les sites d’actualité déploient des mesures anti-bot toujours plus agressives (Cloudflare, CAPTCHA, barrières de rendu JavaScript), et les mises en page changent si souvent qu’un extracteur qui fonctionne le lundi peut casser le mercredi. Pendant ce temps, les équipes métier — des RP et des ventes aux chercheurs universitaires et aux ingénieurs IA — ont plus que jamais besoin de données d’actualité structurées.
J’ai donc entrepris de tester 15 outils de scraping d’actualité, couvrant les API, les plateformes no-code et les bibliothèques open source. L’objectif : vous offrir une comparaison normalisée du prix, de l’effort de maintenance, de la qualité de l’extraction du texte propre et de l’adéquation aux cas d’usage réels, qu’aucun autre guide ne propose.
Ce qui distingue les meilleurs extracteurs de news en 2026
La plupart des articles sur les « meilleurs extracteurs de news » passent complètement à côté des critères d’évaluation, alors voici ce que j’ai réellement testé. La plupart de ces articles se contentent de lister des fonctionnalités et passent à autre chose. Mais après des années à construire de l’infrastructure de scraping, j’ai appris que les critères qui comptent pour les utilisateurs métier sont précis — et souvent négligés.
Voici le cadre d’évaluation que j’ai utilisé :
| Critère | Ce que j’ai évalué |
|---|---|
| Approche | API, outil de navigateur no-code ou bibliothèque open source |
| Gestion anti-bot | Rotation de proxies, résolution de CAPTCHA, prise en charge d’un navigateur headless |
| Extraction de texte propre | Peut-il supprimer les pubs, barres latérales et la navigation pour ne renvoyer que le corps de l’article ? |
| Sortie des métadonnées | Auteur, date, images, URL source, catégorie |
| Formats d’export | CSV, JSON, Google Sheets, Airtable, Notion, etc. |
| Pagination / traitement en masse | Peut-il gérer les résultats multi-pages et les URL par lots ? |
| Charge de maintenance | Casse-t-il quand la mise en page change ? IA adaptative vs sélecteurs |
| Coût normalisé par 1 000 résultats | Prix comparables à périmètre égal (niveau gratuit inclus) |
| Cas d’usage idéal | Veille RP, génération de leads, recherche académique, pipeline LLM, etc. |
Deux critères méritent un peu plus de contexte. Le coût normalisé par 1 000 résultats est important parce que chaque fournisseur affiche ses prix différemment — par crédit, par requête, par recherche, par ligne. Sans normalisation, vous comparez des pommes avec des sous-marins. Et la charge de maintenance est de loin le plus gros point de douleur que j’entends chez les utilisateurs. De forum en forum, le même constat revient : « les sites d’actualité adorent casser mes crawlers tous les mardis ». J’ai noté chaque outil sur une échelle à trois niveaux :
- 🟢 Faible maintenance : IA adaptative ou API entièrement gérée — les changements de mise en page ne cassent pas votre workflow
- 🟡 Maintenance moyenne : gère l’anti-bot, mais votre logique d’extraction peut encore casser
- 🔴 Forte maintenance : basé sur des sélecteurs — quand le site change, vous corrigez manuellement
Quel extracteur de news correspond à votre rôle ? Une matrice de décision
Les recommandations d’extracteurs traitent presque toujours tous les lecteurs de la même manière, et c’est là tout le problème. Un responsable RP qui suit les mentions de marque n’a pas du tout les mêmes besoins qu’un développeur Python qui construit un pipeline RAG. Donc, avant la liste complète, voici un cadre rapide :
| Cas d’usage | Approche recommandée | Outils recommandés |
|---|---|---|
| Briefing quotidien de l’actualité (non technique) | Outil de navigateur no-code ou RSS | Thunderbit, Octoparse, ParseHub |
| Veille RP / média à grande échelle | News API avec alertes | Newscatcher, Webz.io, Newsdata.io |
| Extraction de leads commerciaux depuis l’actualité | Extracteur IA avec enrichissement des sous-pages | Thunderbit (scraping des sous-pages + extraction d’e-mails / numéros), Apify |
| Recherche académique / constitution de corpus | Bibliothèque open source | Newspaper4k |
| Pipeline LLM / ingestion RAG | API de distillation en Markdown | Thunderbit API, ScraperAPI |
| Veille concurrentielle / tarification | Scraping programmé | Thunderbit (Scheduled Scraper), Bright Data |
Vous savez déjà dans quelle case vous êtes ? Passez à la suite. Sinon, le détail ci-dessous vous aidera.
Les 15 meilleurs extracteurs de news en un coup d’œil
Voici la comparaison de référence — prix normalisé au coût pour 1 000 résultats au niveau payant le plus bas, maintenance évaluée sur l’échelle à trois niveaux.
| Outil | Type | Niveau gratuit | Coût par 1 000 résultats (est.) | Anti-bot | Texte propre | Maintenance | Cas d’usage idéal |
|---|---|---|---|---|---|---|---|
| Thunderbit | IA no-code (extension Chrome + cloud) | 6 pages/mois gratuites | ~3 $–15 $ | Fort (mode navigateur + cloud) | Oui (IA + sous-pages) | 🟢 Faible | Équipes métier, génération de leads, veille quotidienne |
| SerpApi | API | 250 recherches/mois | ~15 $ | Fort (spécifique SERP) | Non (extraits seulement) | 🟢 Faible | Tableaux de bord Google News SERP |
| ScraperAPI | API | 1 000 crédits/mois | ~1 $–5 $ | Fort (proxy + rendu JS) | Non (HTML brut) | 🟡 Moyenne | Développeurs voulant une infra anti-bot |
| Newsdata.io | News API | 200 requêtes/jour | ~5 $–15 $ | N/A (API gérée) | Partiel (premium) | 🟢 Faible | Métadonnées d’actualité structurées |
| Apify | Plateforme cloud | 5 $ de crédits gratuits | ~1 $–6 $ | Fort | Variable selon l’actor | 🟡 Moyenne | Workflows cloud personnalisés |
| Oxylabs | API entreprise | Essai de 2 000 résultats | ~0,50 $–2 $ | Très fort | Partiel | 🟢 Faible | SERP et web à l’échelle entreprise |
| ScrapingBee | API | Crédits d’essai | ~2 $–5 $ | Fort (Chrome headless) | Partiel (basique) | 🟡 Moyenne | Sites d’actualité très JavaScript |
| Scrapingdog | API SERP | 1 000 crédits | ~0,10 $–0,50 $ | Fort | Non (données SERP) | 🟢 Faible | Veille SERP à petit budget |
| Bright Data | Plateforme entreprise | Essai de 1 000 requêtes | ~0,30 $–0,50 $ | Très fort | Oui (News Scraper) | 🟢 Faible | Données d’actualité d’entreprise à grande échelle |
| Octoparse | No-code bureau + cloud | Forfait gratuit limité | ~5 $–10 $ (amorti) | Fort | Oui (avec modèles) | 🟡 Moyenne | Scraping visuel no-code |
| ParseHub | No-code bureau | 5 projets, 200 pages/exécution | ~5 $–12 $ (amorti) | Modéré | Oui (avec configuration) | 🔴 Forte | Débutants, petits projets |
| Newscatcher | News API | Pas de niveau gratuit public | Sur mesure (entreprise) | N/A (API gérée) | Oui (enrichi par NLP) | 🟢 Faible | Veille RP / média |
| Webz.io | Plateforme de données d’actualité | Pas de niveau gratuit en libre-service | Sur mesure (entreprise) | N/A (flux géré) | Oui (texte intégral + métadonnées) | 🟢 Faible | Archives historiques, entraînement LLM |
| Newspaper4k | Python open source | Gratuit | 0 $ (+ coûts serveur) | Aucun | Oui (conçu pour cela) | 🔴 Forte | Développeurs, constitution de corpus |
| HasData | API SERP | Crédits gratuits | ~0,25 $–0,60 $ | Fort | Non (données SERP) | 🟢 Faible | Endpoint SERP d’actualité à petit budget |
En bref : Scrapingdog et HasData sont les options API les moins chères par requête. Thunderbit et Newspaper4k arrivent en tête pour le texte propre des articles, mais de façons très différentes. Bright Data et Oxylabs dominent le segment entreprise. Des soucis de maintenance ? Restez sur les outils 🟢.
1. Thunderbit — Le meilleur extracteur de news IA no-code pour les équipes métier
 est l’outil que mon équipe et moi avons conçu précisément pour résoudre ce problème : « j’ai besoin de données sur ce site, et je ne veux ni coder ni maintenir des sélecteurs ». Pour le scraping d’actualité, le flux est aussi simple que possible : ouvrez une page d’actualité, cliquez sur AI Suggest Fields, vérifiez les colonnes proposées par Thunderbit (titre, date, source, URL, résumé — il lit la structure de la page et comprend ce qu’elle contient), puis cliquez sur Scrape.
est l’outil que mon équipe et moi avons conçu précisément pour résoudre ce problème : « j’ai besoin de données sur ce site, et je ne veux ni coder ni maintenir des sélecteurs ». Pour le scraping d’actualité, le flux est aussi simple que possible : ouvrez une page d’actualité, cliquez sur AI Suggest Fields, vérifiez les colonnes proposées par Thunderbit (titre, date, source, URL, résumé — il lit la structure de la page et comprend ce qu’elle contient), puis cliquez sur Scrape.
Plusieurs fonctionnalités combinées rendent Thunderbit particulièrement performant pour l’actualité :
- Extraction IA adaptative : pas de sélecteurs CSS à écrire ou à maintenir. L’IA relit la mise en page actuelle à chaque fois, ce qui signifie que lorsqu’un site d’actualité refond son design (et ils le font tous), votre extracteur ne casse pas.
- Scraping des sous-pages : après avoir extrait une liste de liens d’articles, vous pouvez cliquer sur Scrape Subpages pour visiter chaque article et extraire le texte intégral, l’auteur, la date de publication et les images. C’est comme cela que vous obtenez un contenu d’article propre, et pas seulement des titres.
- Field AI Prompt : vous pouvez donner une consigne à l’IA pour chaque colonne — par exemple : « extraire uniquement le corps principal de l’article, exclure la navigation et les publicités » ou « classer le sentiment de cet article comme positif, neutre ou négatif ». C’est unique parmi les outils no-code et extrêmement utile pour l’analyse de news.
- Scraping navigateur vs scraping cloud : le mode navigateur utilise votre propre session (utile pour les sites qui bloquent les IP cloud), tandis que le mode cloud peut traiter jusqu’à 50 pages à la fois pour aller plus vite.
- Scheduled Scraper : mettez en place des exécutions quotidiennes ou hebdomadaires avec des intervalles en langage naturel — parfait pour la veille d’actualité continue.
- Export partout : Excel, CSV, Google Sheets, Airtable, Notion — tout est pris en charge.
Tarifs et limites
Thunderbit propose un niveau gratuit (6 pages/mois) et un essai de 10 pages. Les formules payantes commencent autour de pour 500 crédits (1 crédit = 1 ligne). L’extension Chrome est requise pour le mode navigateur. Les fonctionnalités IA consomment des crédits, donc une utilisation intensive sur des milliers d’articles nécessitera un forfait payant — mais pour la plupart des équipes métier qui assurent une veille quotidienne ou des recherches hebdomadaires, le coût reste modeste.
Maintenance : 🟢 Faible. L’IA relit la page à chaque exécution.
Idéal pour : les équipes commerciales, RP et opérations non techniques qui veulent des données d’actualité quotidiennes sans construire ni maintenir des extracteurs.
Pour aller plus loin sur la façon dont Thunderbit gère le , consultez notre guide.
2. SerpApi — Le meilleur pour les données Google News SERP structurées
 est une API dédiée aux SERP qui renvoie du JSON structuré à partir des résultats Google News. Si votre besoin est : « donnez-moi les meilleurs résultats Google News pour un mot-clé, structurés et prêts pour un tableau de bord », SerpApi est un excellent choix. Il renvoie les titres, la source, la date, l’extrait et la miniature — mais pas le texte complet de l’article. Il faudrait une étape supplémentaire (ou un autre outil) pour récupérer le corps réel de l’article.
est une API dédiée aux SERP qui renvoie du JSON structuré à partir des résultats Google News. Si votre besoin est : « donnez-moi les meilleurs résultats Google News pour un mot-clé, structurés et prêts pour un tableau de bord », SerpApi est un excellent choix. Il renvoie les titres, la source, la date, l’extrait et la miniature — mais pas le texte complet de l’article. Il faudrait une étape supplémentaire (ou un autre outil) pour récupérer le corps réel de l’article.
Fonctionnalités clés :
- Sortie JSON structurée à partir des SERP Google News
- Anti-détection géré de leur côté (spécifique SERP)
- Prise en charge de nombreux locaux et langues Google News
Tarifs : niveau gratuit à 250 recherches/mois. Les forfaits payants commencent à 75 $/mois pour 5 000 recherches — soit environ 15 $ par 1 000 résultats.
Limite : ne renvoie que des extraits. Si vous avez besoin du texte complet de l’article, SerpApi n’est que la première étape, pas tout le pipeline.
Maintenance : 🟢 Faible (API gérée, ils gèrent les changements de Google).
Idéal pour : les développeurs qui construisent des tableaux de bord de veille d’actualité ou alimentent des outils d’analyse avec des données SERP.
3. ScraperAPI — La meilleure API de scraping économique avec rotation de proxies
 est une API de scraping généraliste, pas spécifique à l’actualité, mais efficace pour récupérer des pages de news. Sa valeur centrale réside dans la rotation de proxies, le rendu JavaScript et la gestion des CAPTCHA — l’infrastructure anti-bot que vous devriez autrement construire vous-même.
est une API de scraping généraliste, pas spécifique à l’actualité, mais efficace pour récupérer des pages de news. Sa valeur centrale réside dans la rotation de proxies, le rendu JavaScript et la gestion des CAPTCHA — l’infrastructure anti-bot que vous devriez autrement construire vous-même.
Fonctionnalités clés :
- Rotation de proxies avec IP résidentielles et datacenter
- Rendu JavaScript pour les sites d’actualité dynamiques
- Gestion des CAPTCHA
- Renvoie du HTML brut — vous parsez vous-même le contenu de l’article
Tarifs : niveau gratuit à 1 000 crédits/mois (plus des crédits d’essai). Le rendu JS coûte davantage de crédits par requête. Les forfaits payants commencent à 49 $/mois. Le coût normalisé est d’environ 1 $–5 $ par 1 000 requêtes selon l’usage du JS.
Limite : pas d’analyse d’article intégrée. Vous obtenez du HTML, pas du texte propre. Combinez-le avec Newspaper4k ou votre propre parser pour extraire les articles.
Maintenance : 🟡 Moyenne (gère l’anti-bot, mais la logique d’extraction vous appartient).
Idéal pour : les développeurs qui veulent une infrastructure anti-bot sans construire leur propre réseau de proxies.
4. Newsdata.io — La meilleure News API dédiée pour les métadonnées structurées
 est une API d’actualité conçue pour cela, couvrant . Elle renvoie des données structurées — titre, description, source, date, catégories, sentiment — ainsi que le contenu complet des articles sur les offres premium.
est une API d’actualité conçue pour cela, couvrant . Elle renvoie des données structurées — titre, description, source, date, catégories, sentiment — ainsi que le contenu complet des articles sur les offres premium.
Fonctionnalités clés :
- Recherche par mot-clé, catégorie, langue, pays
- Analyse de sentiment incluse
- Archive d’actualité historique (forfaits payants)
- Aucune infrastructure de scraping à gérer
Tarifs : niveau gratuit à 200 requêtes/jour avec champs limités. Les offres payantes débloquent le contenu complet et les données historiques. Le coût par 1 000 résultats dépend du niveau du forfait, mais se situe dans la fourchette 5 $–15 $.
Limite : couvre ses propres sources indexées — vous ne pouvez pas lui dire « scrape cette URL arbitraire ». Si une publication de niche n’est pas dans leur index, vous ne la trouverez pas ici.
Maintenance : 🟢 Faible (API d’actualité entièrement gérée).
Idéal pour : les équipes qui ont besoin de métadonnées d’actualité structurées et ne veulent gérer aucune infrastructure de scraping.
5. Apify — La meilleure plateforme cloud pour des workflows de scraping d’actualité personnalisés
 est une plateforme cloud basée sur des actors, avec des extracteurs préconstruits pour Google News, des publications spécifiques et l’extraction générale d’articles. Elle se situe à mi-chemin entre le no-code et le développement entièrement personnalisé.
est une plateforme cloud basée sur des actors, avec des extracteurs préconstruits pour Google News, des publications spécifiques et l’extraction générale d’articles. Elle se situe à mi-chemin entre le no-code et le développement entièrement personnalisé.
Fonctionnalités clés :
- Actors préconstruits pour Google News, l’extraction d’articles, et plus encore
- Prise en charge du rendu JavaScript et de l’exécution dans un navigateur headless
- Exécution cloud avec planification
- Export vers JSON, CSV, Excel, XML, et plus encore
Tarifs : forfait gratuit avec . Niveaux payants à 49 $, 499 $ et 999 $/mois. Le coût par 1 000 résultats varie selon l’actor — environ 1 $–6 $ pour les actors de scraping d’actualité.
Limite : les actors préconstruits sont maintenus par la communauté et peuvent casser quand les sites d’actualité changent. Cela demande plus de configuration que les outils purement no-code.
Maintenance : 🟡 Moyenne (les actors peuvent nécessiter des mises à jour quand les sites changent).
Idéal pour : les équipes qui veulent une exécution cloud et sont à l’aise avec le choix et la configuration d’actors du marketplace.
6. Oxylabs — La meilleure infrastructure de scraping de niveau entreprise
 est un service de scraping entreprise avec un pool de plus de 100 millions de proxies, la résolution de CAPTCHA et le rendu navigateur. Leur SERP Scraper API gère les résultats Google News avec ciblage géographique, et leur Web Scraper API fonctionne pour n’importe quelle page d’actualité.
est un service de scraping entreprise avec un pool de plus de 100 millions de proxies, la résolution de CAPTCHA et le rendu navigateur. Leur SERP Scraper API gère les résultats Google News avec ciblage géographique, et leur Web Scraper API fonctionne pour n’importe quelle page d’actualité.
Fonctionnalités clés :
- Infrastructure de proxies massive avec ciblage géographique
- SERP Scraper API pour Google News
- Web Scraper API pour des URL arbitraires
- Sortie JSON/CSV, requêtes concurrentes à grande échelle
Tarifs : à partir de 49 $/mois pour les données SERP. Tarification entreprise sur mesure pour les gros volumes. Essai gratuit jusqu’à 2 000 résultats.
Limite : coûteux pour les petites équipes. Conçu principalement pour les opérations à grande échelle.
Maintenance : 🟢 Faible (API entreprise entièrement gérée).
Idéal pour : les entreprises qui ont besoin de données d’actualité volumineuses, géociblées et fiables.
7. ScrapingBee — Le meilleur pour les sites d’actualité très riches en JavaScript
 est une API de scraping centrée sur le rendu JavaScript avec exécution réelle dans un navigateur. Si le site d’actualité que vous ciblez charge son contenu via du JS côté client (et c’est le cas de beaucoup de sites modernes), ScrapingBee s’en sort très bien.
est une API de scraping centrée sur le rendu JavaScript avec exécution réelle dans un navigateur. Si le site d’actualité que vous ciblez charge son contenu via du JS côté client (et c’est le cas de beaucoup de sites modernes), ScrapingBee s’en sort très bien.
Fonctionnalités clés :
- Chrome headless avec rotation de proxies
- Gestion des CAPTCHA
- Fonctionnalité basique « Article Extraction » pour certaines pages
- Renvoie du HTML brut, du JSON ou une sortie de type Markdown
Tarifs : forfaits à partir de . Modèle à crédits, avec un coût plus élevé pour le rendu JS. Crédits d’essai disponibles.
Limite : la fonctionnalité d’extraction d’article reste basique comparée aux alternatives basées sur l’IA. Elle renvoie principalement du HTML — vous aurez encore besoin d’un parsing pour la plupart des workflows.
Maintenance : 🟡 Moyenne (gère l’anti-bot, mais l’extraction nécessite une configuration utilisateur).
Idéal pour : les développeurs qui scrappent des sites d’actualité riches en JS et veulent du HTML rendu sans gérer eux-mêmes des navigateurs headless.
8. Scrapingdog — La meilleure API SERP économique pour l’actualité
 est une API SERP à petit budget avec un endpoint Google News dédié. Les temps de réponse sont rapides (environ 2 secondes par requête lors des tests), et la tarification est la plus compétitive de cette liste parmi les options API.
est une API SERP à petit budget avec un endpoint Google News dédié. Les temps de réponse sont rapides (environ 2 secondes par requête lors des tests), et la tarification est la plus compétitive de cette liste parmi les options API.
Fonctionnalités clés :
- Endpoint Google News dédié
- Sortie JSON structurée (titres, source, date, extraits)
- Temps de réponse rapides
Tarifs : à partir de 40 $/mois pour 400 000 requêtes — soit environ 0,10 $ par 1 000 résultats, ce qui est remarquablement peu cher. Niveau gratuit à 1 000 crédits.
Limite : ne renvoie que les données SERP (titres, extraits), pas le contenu complet des articles. Même compromis que SerpApi, mais pour une fraction du prix.
Maintenance : 🟢 Faible (API SERP gérée).
Idéal pour : les développeurs soucieux du budget qui ont besoin de données Google News SERP à grande échelle.
9. Bright Data — Le meilleur pour les données d’actualité d’entreprise à grande échelle
 est le poids lourd du segment entreprise. Sa plateforme inclut un produit News Scraper dédié, une infrastructure massive de proxies, la résolution de CAPTCHA, le rendu navigateur et la livraison des données vers S3, Snowflake, et plus encore.
est le poids lourd du segment entreprise. Sa plateforme inclut un produit News Scraper dédié, une infrastructure massive de proxies, la résolution de CAPTCHA, le rendu navigateur et la livraison des données vers S3, Snowflake, et plus encore.
Fonctionnalités clés :
- Produit News Scraper dédié
- Jeux de données préconstruits et collecte en temps réel
- Gestion automatisée des proxies et résolution de CAPTCHA
- Collecte programmée et alertes
- Exports vers JSON, CSV, NDJSON, S3, Snowflake, GCS, Azure, SFTP
Tarifs : à partir d’environ en pay-as-you-go. Forfaits entreprise sur mesure disponibles. Essai gratuit de 1 000 requêtes.
Limite : structure tarifaire complexe avec engagements minimums. Conçu avant tout pour des budgets d’entreprise.
Maintenance : 🟢 Faible (géré par l’entreprise, fiabilité élevée).
Idéal pour : les grandes organisations qui ont besoin de pipelines de données d’actualité fiables et à haut volume.
10. Octoparse — Le meilleur extracteur visuel no-code pour les pages d’actualité
 Octoparse est une application de bureau dotée d’un constructeur de workflows visuel en point et clic. Elle propose des modèles préconstruits pour les sites d’actualité courants, gère la pagination et le défilement infini, et offre une exécution cloud pour les tâches planifiées.
Octoparse est une application de bureau dotée d’un constructeur de workflows visuel en point et clic. Elle propose des modèles préconstruits pour les sites d’actualité courants, gère la pagination et le défilement infini, et offre une exécution cloud pour les tâches planifiées.
Fonctionnalités clés :
- Constructeur de workflows visuel en point et clic
- Modèles préconstruits pour les sites d’actualité
- Exécution cloud avec planification
- Rotation d’IP et résolution automatique des CAPTCHA
- Exports vers Excel, CSV, JSON, bases de données, Google Sheets
Tarifs : forfait gratuit avec 10 tâches et 50 000 exports/mois. Formules payantes à partir d’environ 89 $/mois.
Limite : l’extraction basée sur des sélecteurs signifie que les extracteurs cassent quand les sites d’actualité mettent à jour leur mise en page. Cela nécessite des corrections manuelles — et les sites d’actualité changent souvent de mise en page.
Maintenance : 🟡 Moyenne (les modèles aident, mais les sélecteurs peuvent encore casser).
Idéal pour : les utilisateurs qui veulent un constructeur visuel no-code et ne craignent pas une maintenance occasionnelle des modèles.
11. ParseHub — La meilleure option no-code gratuite pour débutants
 ParseHub est un extracteur visuel en point et clic avec un niveau gratuit généreux. Il gère le contenu rendu en JavaScript et fonctionne bien pour des projets de recherche ponctuels ou des extractions d’actualité à petite échelle.
ParseHub est un extracteur visuel en point et clic avec un niveau gratuit généreux. Il gère le contenu rendu en JavaScript et fonctionne bien pour des projets de recherche ponctuels ou des extractions d’actualité à petite échelle.
Fonctionnalités clés :
- Sélection visuelle des éléments (sans code)
- Gère les pages rendues en JavaScript
- Exporte vers CSV/JSON
- Niveau gratuit : 5 projets, 200 pages par exécution
Tarifs : forfait gratuit avec 5 projets et 200 pages/exécution. Les forfaits payants commencent à 189 $/mois.
Limite : basé sur les sélecteurs CSS, donc les extracteurs cassent fréquemment lorsque les mises en page changent. Scalabilité limitée et plus lent que les outils API. Les utilisateurs sur Reddit et les forums signalent régulièrement la courbe d’apprentissage et la fragilité.
Maintenance : 🔴 Forte (les sélecteurs cassent souvent, pas d’adaptation IA).
Idéal pour : les débutants qui réalisent de petits projets de recherche d’actualité ponctuels et veulent un point de départ gratuit.
12. Newscatcher — La meilleure News API pour la RP et la veille média
 est une API d’agrégation d’actualité dédiée couvrant . Elle est conçue pour la veille média, le suivi RP et l’analyse des tendances, avec des champs enrichis par le NLP comme le sentiment, le résumé et l’extraction d’entités.
est une API d’agrégation d’actualité dédiée couvrant . Elle est conçue pour la veille média, le suivi RP et l’analyse des tendances, avec des champs enrichis par le NLP comme le sentiment, le résumé et l’extraction d’entités.
Fonctionnalités clés :
- Couverture de plus de 70 000 sources
- Enrichissements NLP : sentiment, résumé, extraction d’entités, déduplication, clustering
- Recherche par mot-clé, sujet, source, langue, pays
- Accès aux archives historiques
Tarifs : prix entreprise (devis sur mesure). Pas de niveau gratuit public pour tester, même s’ils peuvent proposer des essais sur demande.
Limite : une tarification centrée sur l’entreprise peut être hors de portée des petites équipes. Pas de niveau gratuit en libre-service.
Maintenance : 🟢 Faible (API entièrement gérée).
Idéal pour : les équipes RP et veille média dans les entreprises de taille moyenne à grande.
13. Webz.io — Le meilleur pour les archives historiques d’actualité et les données d’entraînement LLM
 est une plateforme de données d’actualité dotée d’une archive historique massive — des milliards d’articles remontant à plusieurs années. Elle fournit à la fois des flux en temps réel et un accès aux données historiques, avec une sortie JSON structurée comprenant le texte intégral, les métadonnées et des enrichissements.
est une plateforme de données d’actualité dotée d’une archive historique massive — des milliards d’articles remontant à plusieurs années. Elle fournit à la fois des flux en temps réel et un accès aux données historiques, avec une sortie JSON structurée comprenant le texte intégral, les métadonnées et des enrichissements.
Fonctionnalités clés :
- Des milliards d’articles dans l’archive historique
- Flux en temps réel et accès aux données historiques
- Texte intégral des articles avec métadonnées structurées
- Très apprécié des équipes IA/ML pour les jeux de données d’entraînement et les pipelines RAG
Tarifs : tarification entreprise / sur mesure (selon le volume de données). Pas de niveau gratuit en libre-service pour l’actualité.
Limite : pas conçu pour les utilisateurs occasionnels. Tarification entreprise uniquement.
Maintenance : 🟢 Faible (flux de données entièrement géré).
Idéal pour : les équipes IA/ML qui construisent des jeux de données d’entraînement, et les équipes entreprise qui ont besoin d’archives historiques très approfondies.
14. Newspaper4k — La meilleure bibliothèque open source pour l’extraction d’articles
 est une bibliothèque Python (successeur de Newspaper3k) conçue spécialement pour extraire un contenu d’article propre. Elle supprime les publicités, les barres latérales et la navigation, et ne renvoie que l’article : titre, corps du texte, auteurs, date de publication, images, mots-clés et résumé.
est une bibliothèque Python (successeur de Newspaper3k) conçue spécialement pour extraire un contenu d’article propre. Elle supprime les publicités, les barres latérales et la navigation, et ne renvoie que l’article : titre, corps du texte, auteurs, date de publication, images, mots-clés et résumé.
Fonctionnalités clés :
- Extrait un corps d’article propre en supprimant le bruit
- Renvoie le titre, les auteurs, la date de publication, les images, les mots-clés et le résumé
- Entièrement gratuit et open source
- Léger et rapide pour les pages HTML statiques
Tarifs : gratuit. Mais vous aurez besoin de votre propre serveur, de votre infrastructure de proxies et de temps développeur.
Limite : pas de gestion anti-bot intégrée. Casse sur les sites d’actualité très dynamiques / rendus en JS. Nécessite des connaissances Python et un pipeline personnalisé pour aller au-delà de l’extraction de base. Quand la structure HTML d’un site change, c’est à vous de corriger.
Maintenance : 🔴 Forte (casse quand le HTML du site change, corrections manuelles nécessaires).
Idéal pour : les développeurs Python qui construisent des pipelines d’extraction d’actualité sur mesure et veulent un contrôle maximal sur le parsing des articles.
15. HasData — La meilleure API SERP économique avec endpoint d’actualité
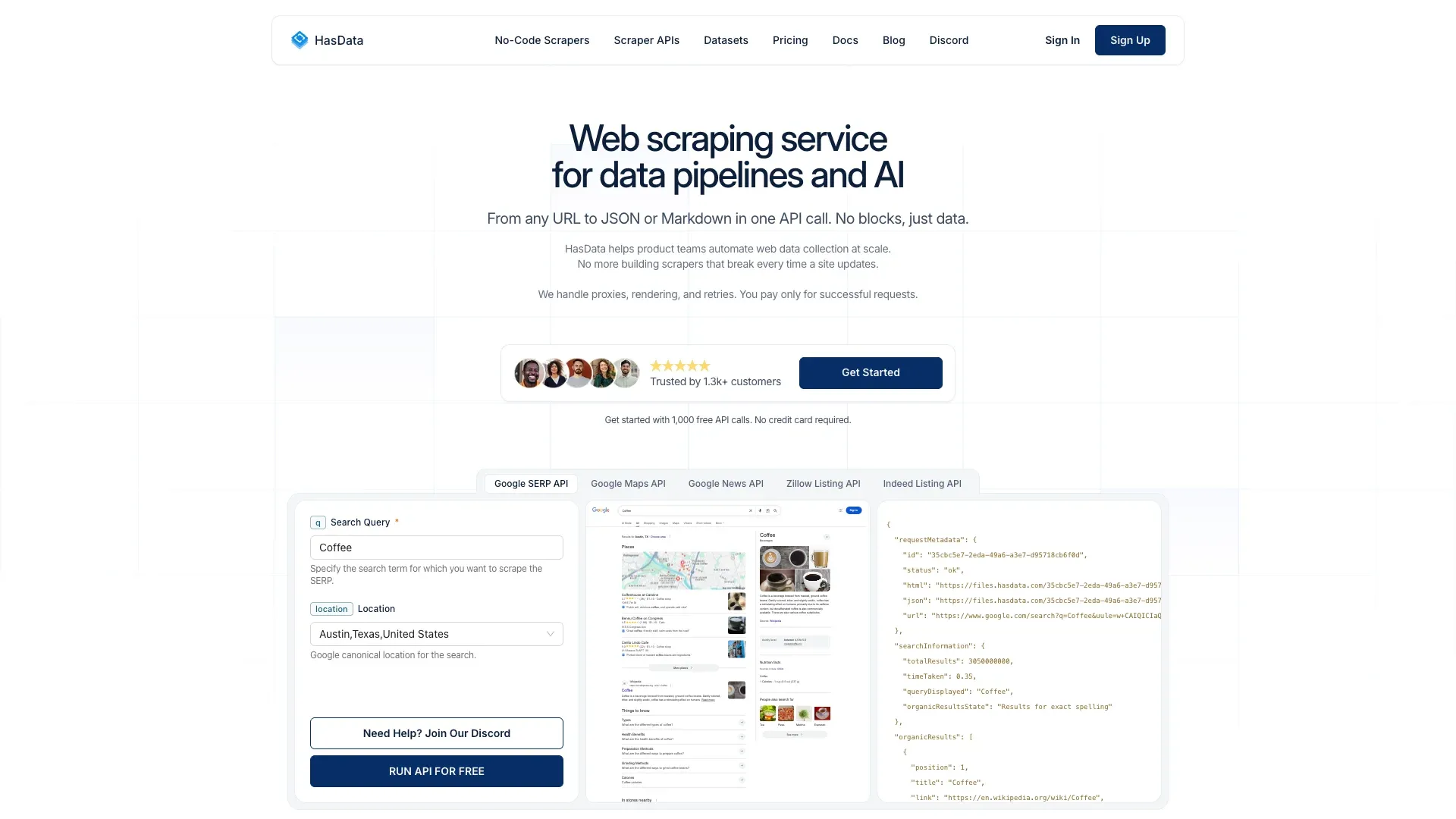 est une API SERP avec un endpoint Google News dédié. Elle renvoie du JSON structuré avec des résultats d’actualité à un prix compétitif.
est une API SERP avec un endpoint Google News dédié. Elle renvoie du JSON structuré avec des résultats d’actualité à un prix compétitif.
Fonctionnalités clés :
- Endpoint Google News dédié
- Sortie JSON structurée
- Temps de réponse d’environ 3 à 4 secondes par requête
- Crédits gratuits pour tester
Tarifs : à partir de (5 crédits par requête d’actualité = 40 000 requêtes). Soit environ 0,25 $–0,60 $ par 1 000 résultats.
Limite : renvoie des données SERP (titres, extraits), pas le contenu complet des articles.
Maintenance : 🟢 Faible (API SERP gérée).
Idéal pour : les équipes soucieuses du budget qui ont besoin de données Google News SERP sans le prix de SerpApi.
Tendances à retenir
Après avoir parcouru les 15 outils, quelques tendances ressortent.
Les API SERP (SerpApi, Scrapingdog, HasData) sont excellentes pour des données de titres structurées, mais vous laissent sur votre faim quand vous avez besoin du texte complet des articles. Les News API dédiées (Newsdata.io, Newscatcher, Webz.io) règlent magnifiquement le problème des métadonnées, mais ne peuvent pas scraper des URL arbitraires. Les outils no-code (Thunderbit, Octoparse, ParseHub) vous donnent la flexibilité de scraper n’importe quelle page — même si leur profil de maintenance varie énormément. Et Newspaper4k offre l’extraction d’article la plus propre, si vous êtes prêt à construire et maintenir vous-même le pipeline.
API vs no-code vs open source : le vrai coût par 1 000 articles
Personne d’autre ne normalise cette comparaison entre toutes les catégories. Voici le calcul :
| Méthode | Temps de configuration | Coût par 1 000 articles | Maintenance | Idéal pour |
|---|---|---|---|---|
| Open source (Newspaper4k) | Quelques heures à quelques jours | 0 $ (mais serveur + temps dev) | 🔴 Forte | Développeurs avec besoins personnalisés |
| News API (Newsdata.io, Newscatcher, Webz.io) | Quelques minutes | 5 $–50 $+ | 🟢 Faible | Données structurées, archives historiques |
| API de scraping (ScraperAPI, ScrapingBee, Oxylabs) | 30 min | 1 $–5 $ | 🟡 Moyenne | Développeurs voulant une gestion anti-bot |
| IA no-code (Thunderbit, Octoparse, ParseHub) | 2 minutes | 3 $–15 $ | 🟢–🟡 | Utilisateurs métier, équipes non techniques |
Le coût caché des outils open source « gratuits », c’est le temps développeur. Un développeur senior qui passe 4 heures par mois à réparer un pipeline Newspaper4k cassé ? Ce n’est pas gratuit — c’est cher.
À l’autre extrême, les API entreprise comme Webz.io et Newscatcher demandent peu de maintenance, mais affichent des prix qui ne se justifient qu’à grande échelle.
Pour la plupart des équipes métier avec lesquelles je parle, le juste milieu est soit un outil IA no-code (comme Thunderbit) pour un scraping flexible et ponctuel, soit une News API dédiée pour une veille structurée et continue.
Le problème de maintenance : pourquoi la plupart des extracteurs de news cassent-ils ? Et lesquels ne cassent pas ?
Ce point mérite sa propre section.
C’est la plainte numéro un que je vois dans les forums, les tickets support et les conversations avec les utilisateurs. Les sites d’actualité changent constamment de mise en page — parfois chaque semaine. Un extracteur basé sur des sélecteurs CSS ou XPath peut fonctionner parfaitement aujourd’hui et renvoyer des déchets demain.
Voici comment les 15 outils se répartissent sur le spectre de la maintenance :
| Niveau de maintenance | Outils | Que se passe-t-il quand un site change ? |
|---|---|---|
| 🟢 Faible (IA adaptative ou API gérée) | Thunderbit, SerpApi, Newsdata.io, Newscatcher, Webz.io, Scrapingdog, HasData, Oxylabs, Bright Data | L’IA relit la page, ou le fournisseur d’API gère le changement. Vous ne touchez à rien. |
| 🟡 Moyenne (modèle + proxy) | ScraperAPI, ScrapingBee, Apify, Octoparse | L’anti-bot est géré, mais votre logique d’extraction ou votre actor/modèle peut nécessiter une mise à jour. |
| 🔴 Forte (basé sur des sélecteurs) | ParseHub, Newspaper4k | Quand le site change, votre extracteur casse. Vous corrigez manuellement les sélecteurs ou les règles de parsing. |
L’approche de Thunderbit mérite d’être soulignée : comme l’IA relit la structure actuelle de la page à chaque exécution du scraping, il n’y a aucun sélecteur codé en dur à maintenir. J’ai vu nos utilisateurs scraper les mêmes sources d’actualité pendant des mois sans avoir à mettre à jour leur configuration, même après des changements de mise en page sur ces sites. C’est le genre de fiabilité qui compte quand on publie un briefing quotidien d’actualité ou un rapport concurrentiel hebdomadaire.
Texte propre des articles : quels extracteurs de news suppriment vraiment le bruit ?
« J’ai les données, mais elles sont remplies de pubs, de menus de navigation et d’éléments inutiles en barre latérale. » C’est à peu près trois questions de support sur cinq que je vois au sujet du scraping d’actualité.
Voici le bilan honnête :
| Capacité à produire du texte propre | Outils |
|---|---|
| Renvoie du texte propre d’article prêt à l’emploi | Newspaper4k, Thunderbit (avec scraping des sous-pages + Field AI Prompt), Newsdata.io (premium), Webz.io, Bright Data (News Scraper), Newscatcher |
| Renvoie seulement des titres / extraits (pas le texte complet) | SerpApi, Scrapingdog, HasData, Oxylabs (mode SERP) |
| Renvoie du HTML brut (à parser soi-même) | ScraperAPI, ScrapingBee |
| Varie selon la configuration | Apify, Octoparse, ParseHub |
Newspaper4k est la référence absolue pour supprimer le bruit des pages d’actualité standard — il a littéralement été conçu pour cela. Mais il nécessite Python et casse sur les sites très riches en JS.
Le Field AI Prompt de Thunderbit est l’équivalent no-code : vous pouvez donner une consigne à l’IA pour chaque colonne, par exemple « extraire uniquement le corps principal de l’article, exclure la navigation et les publicités », et elle peut aussi étiqueter, catégoriser ou résumer le texte pendant l’extraction. Pour les équipes qui ont besoin de texte d’article propre sans coder, c’est l’option la plus pratique que j’aie trouvée.
Si vous voulez voir comment l’extraction pilotée par l’IA se compare aux méthodes traditionnelles, notre article sur le va plus loin.
Scraper l’actualité de façon responsable : bases juridiques et éthiques
Je n’ai trouvé aucun article concurrent qui aborde cela — un manque qui mérite d’être comblé, surtout pour les lecteurs entreprise.
robots.txt : vérifiez toujours. De nombreux grands sites d’actualité interdisent explicitement le scraping de certains chemins. Les outils responsables (Thunderbit compris) permettent un scraping côté navigateur qui respecte le contexte de session, mais vous devriez quand même consulter le robots.txt du site avant de lancer des tâches à grande échelle.
Conditions d’utilisation : il y a une vraie différence entre extraire des métadonnées (titres, dates, URL) pour une recherche interne et republier des articles complets protégés par le droit d’auteur. Le premier cas est généralement moins risqué ; le second peut créer une réelle exposition juridique. Des affaires récentes comme et montrent que le paysage juridique évolue encore.
Bonnes pratiques : utilisez les API officielles quand elles existent (Google News RSS, Newsdata.io, Newscatcher). Mettez en cache de manière responsable. Limitez le débit de vos requêtes. Ne contournez jamais les paywalls. Plusieurs outils de cette liste — dont Thunderbit, ScraperAPI et Bright Data — proposent des fonctionnalités intégrées de limitation de débit ou de scraping éthique pour vous aider à rester dans les clous.
Cet article est informatif et ne constitue pas un avis juridique. Si vous scrapez à l’échelle de l’entreprise, consultez votre équipe juridique.
Comment Thunderbit s’intègre dans votre workflow de scraping d’actualité
Comme mon équipe a construit Thunderbit, je connais mieux que quiconque ses forces et ses limites pour le scraping d’actualité. Voici à quoi ressemble réellement le workflow.
Le flux typique pour un utilisateur métier ressemble à ceci :
- Ouvrez une page d’actualité (résultats Google News, page d’accueil d’une publication, page de recherche thématique) dans Chrome.
- Cliquez sur l’extension Thunderbit puis sur AI Suggest Fields. Thunderbit lit la page et propose des colonnes — titre, date, source, URL, extrait, image, etc.
- Ajustez les colonnes si besoin. Vous voulez une classification du sentiment ? Ajoutez une colonne avec un Field AI Prompt du type « classer le sentiment comme positif, neutre ou négatif ». Vous voulez uniquement les articles d’une catégorie précise ? Ajoutez une consigne de filtrage.
- Cliquez sur Scrape. Choisissez le mode Browser (utilise votre session, pratique pour les sites qui bloquent les IP cloud) ou le mode Cloud (plus rapide, traite jusqu’à 50 pages à la fois).
- Scrape Subpages pour visiter chaque URL d’article et extraire le texte complet, l’auteur, la date de publication et les images.
- Exportez vers Excel, CSV, , Airtable ou Notion.
Pour la veille continue, le Scheduled Scraper vous permet de configurer des exécutions quotidiennes ou hebdomadaires avec des intervalles en langage naturel (par exemple « tous les jours ouvrés à 8 h »). Et comme Thunderbit prend en charge , la veille d’actualité internationale devient simple.
Là où Thunderbit est moins idéal : le scraping de millions d’articles par mois au coût unitaire le plus bas possible — une API entreprise comme Bright Data ou Webz.io sera plus rentable dans ce cas. Et si vous avez besoin d’un enrichissement NLP avancé (extraction d’entités, clustering, déduplication) intégré à la réponse de l’API, Newscatcher est conçu précisément pour cela.
Vous pouvez essayer Thunderbit gratuitement via l’ — aucune carte bancaire requise.
Comment choisir le bon extracteur de news
Ma fiche mémo, synthétisée à partir des 15 outils testés :
- Utilisateur métier non technique qui veut des données d’actualité quotidiennes ? Commencez avec Thunderbit. Deux clics, pas de code, l’IA gère les changements de mise en page.
- Développeur qui construit un pipeline de veille ? SerpApi ou Scrapingdog pour les données SERP. ScraperAPI ou ScrapingBee pour du HTML brut avec anti-bot.
- Équipe entreprise qui a besoin d’échelle et de fiabilité ? Bright Data ou Oxylabs.
- Équipe RP qui suit les mentions de marque à travers des milliers de sources ? Newscatcher ou Newsdata.io.
- Chercheur qui construit un corpus texte ? Newspaper4k (si vous êtes à l’aise avec Python) ou le scraping des sous-pages de Thunderbit (sinon).
- Ingénieur IA qui alimente un pipeline RAG ? Thunderbit API ou Webz.io pour du texte d’article propre et structuré.
- Budget serré ? Scrapingdog pour l’API, le niveau gratuit de Thunderbit pour le no-code, Newspaper4k pour l’open source.
Le bon outil dépend de votre tolérance à la maintenance, de votre budget et de votre niveau technique. Vous hésitez ? Commencez par un niveau gratuit — la plupart de ces outils en proposent un — et voyez quel workflow correspond à votre réalité.
Pour plus d’options et de comparaisons, notre sélection des couvre un panorama plus large. Et si vous voulez comprendre avant d’adopter un outil, ce guide est un bon point de départ.
Conclusion
Le scraping d’actualité en 2026 est un problème résolu — choisissez le bon outil pour votre situation et les données suivront. Les recommandations universelles appartiennent au passé. Les API SERP sont excellentes pour les titres, mais ne vous donneront pas le texte des articles. Les News API dédiées sont formidables pour les métadonnées structurées, mais ne peuvent pas scraper des URL arbitraires. Les outils IA no-code comme Thunderbit offrent flexibilité et faible maintenance, tandis que les bibliothèques open source vous donnent le contrôle au prix de vos week-ends.
Ma recommandation honnête : décidez si vous avez besoin de titres, du texte intégral des articles ou de métadonnées enrichies — puis associez cela au niveau de maintenance et au budget que vous pouvez assumer. Et si vous voulez voir à quoi ressemble un scraping d’actualité moderne, adaptatif grâce à l’IA, sans écrire une ligne de code, . Je pense que vous serez surpris de tout ce que vous pouvez accomplir en quelques clics.
Bon scraping — et que votre texte d’article soit toujours propre, que vos sélecteurs ne cassent jamais et que vos exports arrivent dans la bonne feuille de calcul.
FAQ
1. Quel est le meilleur extracteur de news pour les utilisateurs non techniques ?
Thunderbit est la meilleure option pour les utilisateurs non techniques. Son workflow piloté par l’IA en 2 clics ne nécessite ni code ni sélecteurs CSS. L’IA lit automatiquement la structure de la page, propose les champs d’extraction et s’adapte quand les mises en page changent — vous n’avez donc rien à maintenir. Il exporte aussi directement vers Google Sheets, Airtable et Notion.
2. Puis-je obtenir le texte complet des articles avec les extracteurs de news, ou seulement les titres ?
Cela dépend de l’outil. Les API SERP comme SerpApi, Scrapingdog et HasData renvoient seulement les titres et les extraits. Les News API dédiées comme Newsdata.io et Webz.io renvoient le texte complet sur les forfaits premium. Les outils no-code comme Thunderbit peuvent extraire le texte complet des articles via le scraping des sous-pages, et Newspaper4k est conçu pour l’extraction propre d’articles en Python. Vérifiez toujours si un outil renvoie du HTML brut, des extraits ou le corps propre de l’article avant de vous engager.
3. Les extracteurs de news cassent-ils quand les sites changent de mise en page ?
Les outils basés sur des sélecteurs (ParseHub, Octoparse, Newspaper4k, pipelines Scrapy personnalisés) cassent fréquemment quand les sites d’actualité mettent à jour leur mise en page — et cela arrive souvent. Les outils IA adaptatifs comme Thunderbit relisent la structure de la page à chaque fois, donc les changements de mise en page ne cassent pas le workflow. Les API gérées (SerpApi, Newsdata.io, Newscatcher) gèrent les changements de leur côté. Si la maintenance vous inquiète, privilégiez les outils notés 🟢 Faible dans le tableau comparatif.
4. Quelle est la solution la moins chère pour scraper l’actualité à grande échelle ?
Pour un scraping basé sur API, Scrapingdog propose le coût par requête le plus bas (à partir d’environ 0,10 $ par 1 000 résultats). Pour le no-code, le niveau gratuit de Thunderbit couvre les petits projets, et les forfaits payants commencent à environ 9 $/mois. Pour l’open source, Newspaper4k est gratuit — mais il faut intégrer le temps développeur et les coûts serveur, qui peuvent grimper vite.
5. Est-il légal de scraper des sites d’actualité ?
Le scraping de données publiquement accessibles pour une recherche interne est généralement moins risqué, mais republier des articles complets protégés par le droit d’auteur peut créer une exposition juridique. Vérifiez toujours le robots.txt et les Conditions d’utilisation du site avant de scraper. Utilisez les API officielles quand elles existent, respectez les limites de débit et ne contournez jamais les paywalls. Des affaires récentes comme hiQ v. LinkedIn et Meta v. Bright Data montrent que le cadre juridique évolue encore. Pour un scraping à l’échelle entreprise, consultez votre équipe juridique.
En savoir plus