

Aujourd'hui, près de la moitié du trafic internet est généré par des bots, et une grande partie sert à récupérer des liens, des données et des URL à grande échelle. Continuer à le faire à la main, c'est prendre le risque de se laisser distancer.
J'ai mis 12 outils d'extraction de liens à l'épreuve — des extensions Chrome dopées à l'IA jusqu'aux bibliothèques Python — pour voir lesquels tiennent vraiment la route quand il faut récupérer des milliers d'URL en un temps record.
Voici ce que j'en ai retiré.
Pourquoi les extracteurs de liens sont devenus essentiels
Soyons clairs : le web déborde de données, et les entreprises cherchent à transformer ce désordre en informations utiles. Les extracteurs de liens et les extracteurs d'URL sont aujourd'hui incontournables pour les équipes qui veulent :
- Générer des leads : les équipes commerciales récupèrent en quelques minutes des liens de profils d'entreprise depuis des annuaires ou LinkedIn, puis les transmettent à des outils chargés d'en extraire les coordonnées. Fini les clics à n'en plus finir.
- Centraliser du contenu et renforcer le SEO : les marketeurs peuvent rassembler tous les liens d'articles d'un blog, surveiller les backlinks des concurrents ou auditer l'architecture d'un site pour repérer les liens cassés.
- Surveiller la concurrence et faire de la veille marché : les équipes opérationnelles regroupent automatiquement les liens vers les nouveaux produits, les pages tarifaires ou les communiqués de presse — sans effort.
- Automatiser les workflows et gagner du temps : les extracteurs de liens modernes traitent les URL en masse, explorent les sous-pages et exportent les données dans des formats structurés (CSV, Excel, Google Sheets, Notion, et bien d'autres). Résultat : adieu les sessions de copier-coller et les fichiers texte en vrac à nettoyer.
Sachant que des dizaines de milliards de pages web sont explorées chaque jour, le travail manuel n'est tout simplement plus tenable. Un bon extracteur de liens, c'est un assistant infatigable : il n'oublie jamais un lien et ne réclame jamais de pause café.
Comment nous avons sélectionné les meilleurs extracteurs de liens
Avec autant d'outils sur le marché, choisir le bon extracteur de liens peut vite tourner au casse-tête : tous promettent d'être « le bon », mais seuls quelques-uns tiennent réellement parole. Voici comment j'ai ramené la sélection aux 12 meilleurs :
- Simplicité d'utilisation : un non-développeur peut-il s'en servir sans maîtriser les expressions régulières ? Les solutions no-code et low-code ont gagné des points.
- Extraction en masse et multi-niveau : l'outil gère-t-il des centaines d'URL d'un coup ? Explore-t-il automatiquement les sous-pages et suit-il les liens ?
- Export et intégrations : exporte-t-il vers CSV, Excel, Google Sheets, Notion, Airtable ou via API ? Moins le travail manuel est lourd, mieux c'est.
- Profil utilisateur et flexibilité : est-il pensé pour les utilisateurs métier, les analystes ou les développeurs ? Certains outils sont polyvalents, d'autres plus spécialisés.
- Fonctionnalités avancées : reconnaissance pilotée par l'IA, planification, montée en charge cloud, nettoyage des données et modèles pour les sites les plus courants.
- Tarification et évolutivité : version gratuite, paiement à l'usage ou offre entreprise ? J'ai regardé ce que vous obtenez vraiment pour votre argent.
J'ai inclus aussi bien des extensions de navigateur que des plateformes pour entreprises, afin que vous trouviez une solution adaptée, que vous soyez fondateur en solo ou membre d'une équipe data d'un grand groupe.
Thunderbit : l'extracteur de liens le plus malin pour les utilisateurs métier
Commençons par mon premier choix. Thunderbit est ma recommandation numéro un pour l'extraction de liens — et pas seulement parce que j'ai participé à sa conception. Thunderbit est une extension Chrome de web scraping propulsée par l'IA, pensée pour les utilisateurs métier qui veulent des résultats, et vite.
Qu'est-ce qui le distingue ? Sa capacité à vraiment comprendre votre demande. Vous décrivez ce que vous voulez en langage courant (« récupère tous les liens produits et les prix de cette page »), et l'IA de Thunderbit se charge du reste. Pas besoin de bricoler des sélecteurs ni d'écrire des scripts.
Et ce n'est pas tout :
- Prise en charge des URL en masse : collez une seule URL ou une liste de plusieurs centaines — Thunderbit les traite toutes d'un coup.
- Navigation entre sous-pages : vous devez extraire les liens d'une page de liste, puis visiter chaque page détail pour récupérer d'autres URL ? La logique d'extraction multi-couche de Thunderbit s'en occupe.
- Export structuré : une fois les liens extraits, vous pouvez renommer les champs, les classer et les exporter directement vers Google Sheets, Notion, Airtable, Excel ou CSV. Plus de post-traitement laborieux.
Extraire des liens de n’importe quel site grâce à l’IA Get Started Free
Thunderbit est utilisé par plus de 30 000 personnes dans le monde, des équipes commerciales aux agents immobiliers, en passant par des boutiques e-commerce indépendantes. Et oui, il existe une version gratuite (jusqu'à 6 pages, ou 10 avec un bonus d'essai), pour le tester sans engagement.
Essayer gratuitement l’extracteur de liens Thunderbit
Les fonctionnalités qui distinguent Thunderbit
Voyons ce qui rend Thunderbit vraiment différent :
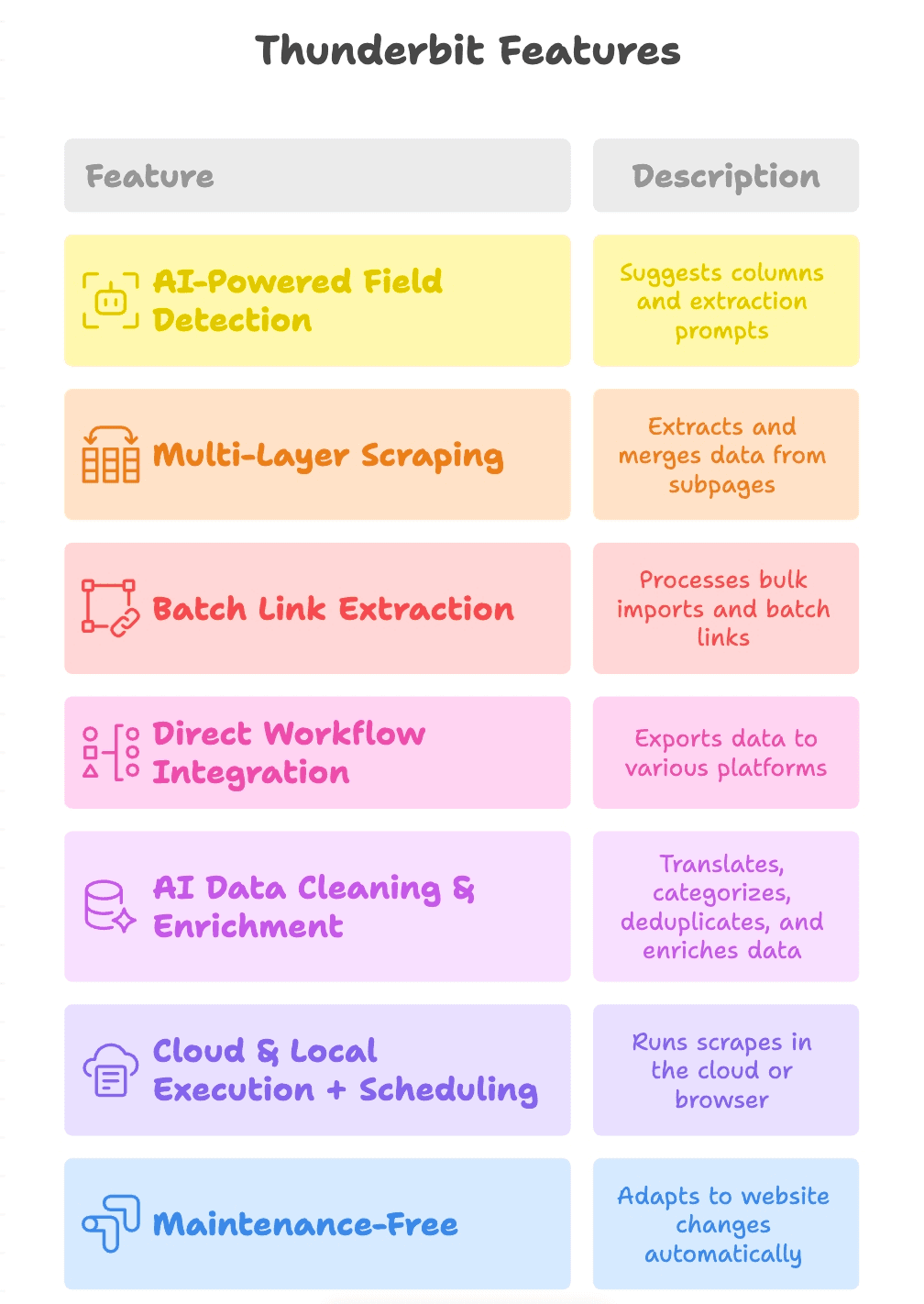
- Détection de champs alimentée par l'IA : cliquez simplement sur « AI Suggest Fields », et Thunderbit lit la page, propose des colonnes (comme « Lien produit », « URL PDF », « Email de contact ») et génère même les invites d'extraction pour chaque champ.
- Extraction multi-niveau : Thunderbit peut suivre les liens d'une page principale vers des sous-pages (fiches produits, PDF), en extraire d'autres et tout regrouper dans un seul tableau.
- Extraction de liens par lots : que vous analysiez une page ou un millier, Thunderbit gère l'import en masse et l'extraction groupée sans difficulté.
- Intégration directe au workflow : exportez les résultats vers Google Sheets, Notion, Airtable, ou téléchargez-les en CSV/Excel. Vos données arrivent exactement là où votre équipe en a besoin.
- Nettoyage et enrichissement des données par IA : Thunderbit peut traduire, catégoriser, dédupliquer et même enrichir vos données pendant l'extraction — pour un résultat directement exploitable, et non un simple export brut.
- Exécution cloud et locale + planification : lancez les extractions dans le cloud pour gagner en vitesse, ou dans votre navigateur pour les sites qui exigent une connexion. Programmez des tâches récurrentes pour garder vos données à jour.
- Sans maintenance : l'IA de Thunderbit s'adapte aux changements de site, ce qui vous évite de réparer sans cesse des extracteurs cassés.
Octoparse : un extracteur de liens no-code pour tout le monde
Octoparse est une valeur sûre de l'univers du scraping sans code. C'est une application de bureau (Windows/Mac) dotée d'une interface visuelle en mode clic-clic. Vous chargez une page web, vous cliquez sur les liens qui vous intéressent, et Octoparse fait le reste.
- Idéal pour les débutants : aucun code requis. Cliquez, extrayez, c'est parti.
- Gestion de la pagination et du contenu dynamique : Octoparse peut cliquer sur les boutons « Suivant », faire défiler la page et même se connecter à des sites.
- Scraping cloud et planification : les offres payantes permettent d'exécuter les tâches dans le cloud et de programmer des tâches récurrentes.
- Options d'export : téléchargement en CSV, Excel, JSON ou envoi vers des bases de données.
Le plan gratuit est généreux pour les petits besoins (jusqu'à 10 tâches et 50 000 lignes/mois), mais les usages plus intensifs nécessiteront une offre payante (à partir d'environ 75 $/mois, soit autour de 70 €/mois).
Apify : un extracteur d'URL flexible pour les workflows sur mesure
Apify est l'outil polyvalent par excellence du web scraping. La plateforme propose une place de marché d'« actors » prêts à l'emploi (des outils de scraping), et vous laisse aussi écrire vos propres scripts en JavaScript ou Python.
- Prêt à l'emploi et personnalisable : utilisez les actors de la communauté pour les tâches courantes, ou créez les vôtres pour des workflows spécifiques.
- Scraping en masse et planifié : mettez des URL en file d'attente, lancez plusieurs tâches en parallèle et planifiez des extractions récurrentes.
- Orienté API : exportez en JSON, CSV, Excel ou Google Sheets, et connectez-vous à votre pipeline de données.
- Paiement à l'usage : crédits gratuits chaque mois, puis facturation selon l'utilisation.
Apify convient parfaitement aux équipes semi-techniques et aux développeurs en quête de flexibilité et de montée en charge.
Bright Data URL Scraper : l'extraction de liens au niveau entreprise
Bright Data est conçu pour les entreprises qui doivent scraper à grande échelle. Son Data Collector propose un URL Scraper préconfiguré pour les gros volumes.
- Gère des volumes massifs : extrayez des milliers, voire des millions de pages, avec une infrastructure proxy robuste pour éviter les blocages.
- Modèles préconfigurés : des extracteurs prêts à l'emploi pour l'e-commerce, les réseaux sociaux, l'immobilier et bien d'autres secteurs.
- Fonctionnalités entreprise : outils de conformité, support expert et protection avancée contre les blocages.
- Tarification : à partir d'environ 350 $ pour 100 000 chargements de pages (soit autour de 320 €) — clairement destiné aux grandes organisations.
Pour une startup, ce sera sans doute surdimensionné. Mais pour des besoins d'extraction stratégiques et à très gros volume, Bright Data fait figure de référence.
WebHarvy : un extracteur de liens visuel, d'une simplicité enfantine
WebHarvy est une application de bureau (Windows) qui permet d'extraire des liens en cliquant simplement dessus dans son navigateur intégré.
- Ultra simple : cliquez sur un lien, et WebHarvy met en surbrillance tous les éléments similaires à extraire.
- Prise en charge des expressions régulières : modèles intégrés pour les tâches courantes, sans coder.
- Export vers Excel, CSV, JSON, XML, SQL : parfait pour les utilisateurs métier qui veulent leurs données dans des formats familiers.
- Licence à vie : paiement unique, utilisation illimitée.
Idéal pour les petites entreprises, les chercheurs ou toute personne qui veut récupérer des liens rapidement, sans complication ni code.
Web Scraper (extension Chrome) : extraction rapide directement dans le navigateur
L'extension Chrome Web Scraper est un outil gratuit et open source qui transforme votre navigateur en extracteur.
- Définition de sitemaps : indiquez-lui comment naviguer et quoi extraire.
- Gestion de la pagination et du crawling multi-niveau : explorez catégories, sous-catégories et pages détail.
- Export en CSV/XLSX : téléchargez les données directement depuis votre navigateur.
- Modèles communautaires : de nombreux sitemaps partagés pour les sites populaires.
Un excellent choix pour les besoins rapides et ponctuels, ou pour les étudiants et petites équipes au budget serré.
ScraperAPI : un extracteur de liens scalable pour les développeurs
ScraperAPI s'adresse aux développeurs qui veulent récupérer des pages web à grande échelle sans se soucier des proxies, des blocages ou des CAPTCHA.
- Basé sur une API : envoyez une URL et récupérez du HTML ou des données déjà extraites.
- Gère l'échelle et les protections anti-bot : rotation de proxy, rendu JavaScript et résolution de CAPTCHA intégrés.
- S'intègre à votre code : utilisable avec Python, Node.js ou n'importe quel langage.
- Tarification : version gratuite (~1 000 appels API), puis paiement à la requête.
Très utile pour créer des crawlers personnalisés ou quand vous avez besoin de fiabilité et de rapidité à grande échelle.
ParseHub : un extracteur de liens visuel avec une sélection avancée
ParseHub est une application de bureau (Windows, Mac, Linux) qui permet de construire visuellement des projets de scraping.
- Sélection et navigation avancées : cliquez, bouclez et extrayez des liens de manière conditionnelle — même à partir d'éléments dynamiques ou cachés.
- Gestion des pages imbriquées : explorez les catégories, puis les pages détail, puis extrayez d'autres liens.
- Export vers CSV, Excel, JSON : exécutions cloud et accès API sur les offres payantes.
- Plan gratuit : 5 projets, jusqu'à 200 pages par exécution.
ParseHub a la faveur des marketeurs et des chercheurs qui veulent de la puissance sans écrire de code.
Scrapy : l'extracteur de liens Python pour les développeurs
Scrapy est la référence pour les développeurs Python qui veulent un contrôle total.
- Code d'abord : construisez des spiders personnalisés pour explorer et extraire des liens à n'importe quelle échelle.
- Gestion du crawling distribué : efficace, asynchrone et hautement personnalisable.
- Export vers CSV, JSON, XML ou base de données : vous maîtrisez le format de sortie.
- Open source et gratuit : à vous, en revanche, de gérer votre propre environnement.
Si vous êtes à l'aise avec Python, Scrapy offre un niveau de puissance difficile à égaler.
Diffbot : un extracteur de liens propulsé par l'IA pour les données structurées
Diffbot est le cerveau IA du web scraping. Il analyse les pages et renvoie des données structurées — liens compris — sans configuration manuelle.
- Reconnaissance automatique du contenu : vous fournissez une URL, vous récupérez des données structurées (articles, produits, liens, etc.).
- Crawlbot et Knowledge Graph : explorez des sites entiers ou interrogez leur immense index web.
- Basé sur API : intégration avec vos outils BI ou votre pipeline de données.
- Tarification entreprise : à partir d'environ 299 $/mois (soit autour de 275 €/mois), mais la qualité se paie.
Le meilleur choix pour les entreprises qui veulent des données propres et structurées sans gérer elles-mêmes les extracteurs.
Cheerio : un extracteur de liens léger pour Node.js
Cheerio est un parseur HTML rapide, à la manière de jQuery, pour Node.js.
- Extrêmement rapide : analyse le HTML en quelques millisecondes.
- Syntaxe familière : si vous connaissez jQuery, Cheerio vous semblera immédiatement naturel.
- Parfait pour les pages statiques : il ne rend pas le JavaScript, mais excelle sur le contenu rendu côté serveur.
- Open source et gratuit : à combiner avec axios ou fetch pour les requêtes.
Idéal pour les développeurs qui créent des scripts personnalisés et veulent aller vite sans complexité superflue.
Puppeteer : l'automatisation du navigateur pour les extractions avancées
Puppeteer est une bibliothèque Node.js pour piloter Chrome en mode headless.
- Automatisation complète du navigateur : chargez des pages, cliquez, faites défiler et interagissez comme un vrai utilisateur.
- Gère le contenu dynamique et les connexions : parfait pour les sites riches en JavaScript ou les workflows complexes.
- Contrôle fin : attente d'éléments, captures d'écran, interception des requêtes réseau.
- Open source et gratuit : en contrepartie, gourmand en ressources et plus lent que les outils légers.
Tournez-vous vers Puppeteer lorsque vous devez extraire des liens sur des sites qui résistent aux extracteurs classiques.
Comparatif rapide : quel extracteur de liens correspond à vos besoins ?
Voici un résumé rapide des 12 outils :
| Outil | Idéal pour | Prise en charge du volume et des sous-pages | Options d’export | Tarification |
|---|---|---|---|---|
| Thunderbit | Non-développeurs, équipes métier | Oui (IA, multi-niveau) | Excel, CSV, Sheets, Notion, Airtable | Essai gratuit, à partir d’environ 9 $/mois |
| Octoparse | Utilisateurs no-code, analystes | Oui | CSV, Excel, JSON, stockage cloud | Version gratuite, ~75 $/mois |
| Apify | Semi-tech, développeurs | Oui | CSV, JSON, Sheets via API | Crédits gratuits, facturation à l’usage |
| Bright Data | Entreprise | Oui (très gros volumes) | CSV, JSON, NDJSON via API | ~350 $ / 100k pages |
| WebHarvy | Non-développeurs, desktop | Oui | Excel, CSV, JSON, XML, SQL | Licence payante |
| Web Scraper Extension | Tout le monde, besoin rapide/gratuit | Oui | CSV, XLSX | Gratuit, open source |
| ScraperAPI | Développeurs, utilisateurs d’API | Oui | JSON (HTML via API) | 1k requêtes gratuites, offres payantes |
| ParseHub | Non-développeurs, avancé | Oui | CSV, Excel, JSON, API | 5 projets gratuits, offre payante |
| Scrapy | Développeurs Python | Oui | CSV, JSON, XML, base de données | Gratuit, open source |
| Diffbot | Entreprise, IA | Oui (crawl IA) | JSON (données structurées via API) | ~299 $/mois et + |
| Cheerio | Développeurs Node.js | Oui (code personnalisé) | Sur mesure (JSON, etc.) | Gratuit, open source |
| Puppeteer | Développeurs, sites complexes | Oui (automatisation complète) | Sur mesure (sortie scriptée) | Gratuit, open source |
Comment choisir le bon extracteur de liens pour votre entreprise
Alors, comment trancher ? Voici mon aide-mémoire :
- Pas de compétences en code ? Commencez avec Thunderbit, Octoparse, ParseHub, WebHarvy ou l'extension Web Scraper.
- Besoin de workflows sur mesure ? Apify, ScraperAPI ou Cheerio sont d'excellentes options pour les développeurs.
- À l'échelle entreprise ? Bright Data ou Diffbot sont faits pour vous.
- Vous développez en Python ou en Node.js ? Scrapy (Python) ou Cheerio/Puppeteer (Node.js) vous offrent un contrôle total.
- Vous voulez exporter directement vers Sheets/Notion ? Thunderbit est votre meilleur choix.
Choisissez l'outil en fonction de votre aisance technique, du volume de données et de vos besoins d'intégration. La plupart proposent un essai gratuit, alors n'hésitez pas à les mettre à l'épreuve.
Découvrez d’autres guides sur le web scraping Get Started Free
La valeur unique de Thunderbit pour l'extraction de liens en 2026
Revenons sur ce qui distingue vraiment Thunderbit :
- Simplicité grâce à l'IA : décrivez votre besoin en langage courant — l'IA de Thunderbit prend le relais.
- Extraction multi-couche : récupérez des liens depuis les pages principales, suivez les sous-pages et collectez encore plus d'URL — le tout dans un seul flux.
- Import en masse et traitement par lots : collez des centaines d'URL, extrayez les liens en masse et exportez immédiatement des données structurées.
- Intégration aux workflows : export direct vers Google Sheets, Notion, Airtable, ou téléchargement en CSV/Excel.
- Zéro maintenance : l'IA de Thunderbit s'adapte aux changements de site, vous évitant de perdre du temps à réparer des extracteurs cassés.
Thunderbit fait le lien entre « extraire des données » et « obtenir des données vraiment exploitables ». C'est le genre d'outil qui m'aurait fait gagner un temps précieux il y a quelques années, quand je croulais sous les tâches de données manuelles.
Lancer gratuitement l’extraction de liens avec Thunderbit
Conclusion : extraire les liens plus intelligemment et gagner en productivité
Les données web nourrissent la croissance des entreprises — et le bon extracteur de liens, c'est votre moteur. Que vous construisiez des listes de prospects, surveilliez la concurrence ou automatisiez vos recherches, vous trouverez ici un outil adapté à vos besoins et à votre niveau.
Si vous voulez voir à quoi ressemble l'extraction moderne de liens, essayez la version gratuite de Thunderbit. Vous serez sans doute surpris de tout ce que vous pouvez accomplir en quelques clics. Et si Thunderbit ne vous convient pas parfaitement, testez-en quelques autres de cette liste : automatiser les tâches répétitives pour se concentrer sur l'essentiel n'a jamais été aussi simple.
Que vos liens restent toujours propres, structurés et prêts à l'emploi. Et si vous souhaitez aller plus loin dans le web scraping, consultez le Thunderbit Blog pour d'autres guides et conseils.
Essayez gratuitement l’extracteur de liens Thunderbit Get Started Free
FAQ
1. Pourquoi les extracteurs de liens sont-ils indispensables ?
Avec près de la moitié du trafic internet généré par des bots et des entreprises qui extraient des données à grande échelle, les extracteurs de liens sont essentiels pour transformer le désordre du web en informations utiles. Ils automatisent des tâches comme la génération de leads, l'agrégation de contenu, les audits SEO et la veille concurrentielle, ce qui fait gagner énormément de temps et d'énergie.
2. Qu'est-ce qui distingue Thunderbit des autres extracteurs de liens ?
Thunderbit s'appuie sur l'IA pour simplifier l'extraction : décrivez simplement votre objectif en langage naturel, et il se charge du reste. Il prend en charge l'import massif d'URL, l'extraction multi-niveau, la détection intelligente des champs et l'export fluide vers des plateformes comme Google Sheets et Notion. C'est l'outil idéal pour les non-développeurs et les utilisateurs métier qui veulent des résultats puissants sans complexité technique.
3. Existe-t-il des extracteurs de liens adaptés aux développeurs et aux workflows personnalisés ?
Oui. Des outils comme Apify, ScraperAPI, Cheerio, Puppeteer et Scrapy s'adressent aux développeurs. Ils offrent le scripting, l'intégration API et la flexibilité nécessaires pour gérer des tâches complexes, des opérations à grande échelle et des automatisations avancées.
4. Quels sont les meilleurs outils pour les utilisateurs sans expérience en code ?
Thunderbit, Octoparse, ParseHub, WebHarvy et l'extension Chrome Web Scraper figurent parmi les meilleurs choix pour les utilisateurs non techniques. Ces outils proposent des interfaces visuelles, des modèles prêts à l'emploi et des fonctions pilotées par l'IA qui rendent l'extraction de liens accessible à tous.
5. Comment choisir le bon extracteur de liens selon mes besoins ?
Prenez en compte vos compétences techniques, le volume de données et vos besoins en export. Les non-développeurs devraient se tourner vers Thunderbit ou Octoparse, tandis que les développeurs préféreront peut-être Scrapy ou Puppeteer. Les grandes entreprises peuvent envisager Bright Data ou Diffbot pour les opérations à grande échelle. Commencez toujours par un essai gratuit pour voir ce qui vous convient le mieux.




