

Quel langage de programmation choisir pour le web scraping ? Tout dépend de votre projet — et j’ai vu plus d’un développeur jeter l’éponge après avoir misé sur le mauvais.
Le marché des logiciels de web scraping pesait 1,01 milliard de dollars en 2024 et devrait plus que doubler d’ici 2032. Le bon langage vous fait gagner du temps et vous épargne de la maintenance. Le mauvais, lui, finit en scrapers cassés et en week-ends sacrifiés.
Je construis des outils d’automatisation depuis des années. Voici sept langages que j’ai utilisés pour le scraping — avec des extraits de code, des arbitrages sans langue de bois, et le moment précis où il vaut mieux ne pas coder du tout et passer par Thunderbit.
Comment nous avons choisi le meilleur langage pour le web scraping
En web scraping, tous les langages ne se valent pas. J’ai vu des projets décoller — ou se planter — selon quelques critères décisifs :
- Facilité d’utilisation : À quelle vitesse pouvez-vous démarrer ? La syntaxe est-elle agréable, ou faut-il un doctorat en informatique pour afficher un simple « Hello, World » ?
- Support des bibliothèques : Existe-t-il des bibliothèques solides pour les requêtes HTTP, l’analyse HTML et le contenu dynamique ? Ou faut-il réinventer la roue ?
- Performances : Peut-il avaler des millions de pages, ou s’essouffle-t-il après quelques centaines ?
- Gestion du contenu dynamique : Les sites modernes raffolent de JavaScript. Votre langage suit-il la cadence ?
- Communauté et support : Quand vous êtes bloqué — et ça arrivera — y a-t-il une communauté pour vous tendre la main ?
Sur la base de ces critères — et de beaucoup de tests nocturnes — voici les sept langages que je vais passer en revue :
- Python : la valeur sûre, des débutants aux experts.
- JavaScript et Node.js : le roi du contenu dynamique.
- Ruby : syntaxe propre, scripts rapides.
- PHP : la simplicité côté serveur.
- C++ : pour les cas où seule la vitesse brute compte.
- Java : prêt pour l’entreprise et scalable.
- Go (Golang) : rapide et concurrent.
Et si vous vous dites « Shuai, je ne veux pas coder du tout » — restez jusqu’à la fin pour découvrir Thunderbit.
Web scraping avec Python : la puissance à portée des débutants
Commençons par le chouchou du public : Python. Demandez à une salle pleine de spécialistes de la donnée quel est le meilleur langage pour le web scraping, et vous entendrez « Python » résonner comme un chœur à un concert de Taylor Swift.
Pourquoi Python ?
- Syntaxe accueillante pour les débutants : Vous pouvez lire du code Python à voix haute, et ça sonne presque comme de l’anglais.
- Support de bibliothèques sans égal : De BeautifulSoup pour analyser le HTML à Scrapy pour l’exploration à grande échelle, en passant par Requests pour HTTP et Selenium pour l’automatisation du navigateur — Python a tout sous la main.
- Communauté immense : Plus de 33 000 questions Stack Overflow rien que sur le web scraping.
Exemple de code Python : extraire le titre d’une page
import requests
from bs4 import BeautifulSoup
response = requests.get("<https://example.com>")
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.title.string
print(f"Titre de la page : {title}")
Atouts :
- Développement et prototypage rapides.
- Des tonnes de tutoriels et de réponses Q&R.
- Excellent pour l’analyse de données — extraire avec Python, analyser avec pandas, visualiser avec matplotlib.
- Les bibliothèques continuent d’évoluer : la version 2.14 de Scrapy (janvier 2026) a apporté
async/awaitnatif dans tout le framework, donc l’asynchrone ne se limite plus à Selenium ou Playwright.
Limites :
- Plus lent que les langages compilés sur les gros volumes.
- La gestion des sites très dynamiques peut devenir lourde (même si Selenium et Playwright aident).
- Pas idéal pour extraire des millions de pages à toute allure.
En résumé :
Si vous débutez en scraping, ou si vous voulez simplement avancer vite, Python est le meilleur langage pour le web scraping — point final. Pourquoi Python domine le web scraping.
JavaScript et Node.js : extraire les sites dynamiques sans transpirer
Si Python est l’outil polyvalent qui fait tout, JavaScript (et Node.js) est la perceuse électrique — surtout pour extraire des sites modernes, gorgés de JavaScript.
Pourquoi JavaScript/Node.js ?
- Natif pour le contenu dynamique : Il s’exécute dans le navigateur, donc il voit ce que voient les utilisateurs — même quand la page est construite avec React, Angular ou Vue.
- Asynchrone par nature : Node.js encaisse des centaines de requêtes en parallèle.
- Familier aux développeurs web : Si vous avez déjà créé un site, vous connaissez déjà un peu JavaScript.
Bibliothèques clés :
- Playwright : multi-navigateurs (Chromium, Firefox, WebKit), attente automatique et proxys par contexte. Pour démarrer un nouveau scraper Node en 2026, c’est le choix par défaut.
- Puppeteer : Chrome en mode headless via le Chrome DevTools Protocol. Toujours très solide pour les tâches limitées à Chrome avec un besoin de dépendances plus légères.
- Cheerio : analyse HTML façon jQuery pour Node, quand un vrai navigateur n’est pas nécessaire.
Exemple de code Node.js : extraire le titre d’une page avec Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('<https://example.com>', { waitUntil: 'networkidle2' });
const title = await page.title();
console.log(`Titre de la page : ${title}`);
await browser.close();
})();
Atouts :
- Gère nativement le contenu rendu par JavaScript.
- Très efficace pour le scroll infini, les pop-ups et les sites interactifs.
- Performant pour du scraping simultané à grande échelle.
Limites :
- La programmation asynchrone peut piéger les débutants.
- Les navigateurs headless dévorent la mémoire si vous en lancez trop d’un coup.
- Moins d’outils d’analyse de données que Python.
Quand JavaScript/Node.js est-il le meilleur langage pour le web scraping ?
Quand votre site cible est dynamique, ou quand vous voulez automatiser les actions du navigateur. En savoir plus sur Node.js pour le scraping de contenu dynamique.
Ruby : une syntaxe propre pour des scripts de web scraping express
Ruby ne se réduit pas aux applications Rails ni à la poésie du code. C’est aussi un excellent choix pour le web scraping — surtout si vous aimez que votre code se lise comme un haïku.
Pourquoi Ruby ?
- Syntaxe lisible et expressive : Vous écrivez un scraper en Ruby presque aussi facilement que votre liste de courses.
- Idéal pour le prototypage : Rapide à écrire, facile à ajuster.
- Bibliothèques clés : Nokogiri pour l’analyse, Mechanize pour automatiser la navigation.
Exemple de code Ruby : extraire le titre d’une page
require 'open-uri'
require 'nokogiri'
html = URI.open("<https://example.com>")
doc = Nokogiri::HTML(html)
title = doc.at('title').text
puts "Titre de la page : #{title}"
Atouts :
- Ultra lisible et concis.
- Parfait pour les petits projets, les scripts ponctuels, ou si vous baignez déjà dans Ruby.
Limites :
- Plus lent que Python ou Node.js sur les gros volumes.
- Moins de bibliothèques dédiées au scraping et une communauté plus restreinte sur le sujet.
- Pas idéal pour les sites très riches en JavaScript (même si Watir ou Selenium dépannent).
Meilleur cas d’usage :
Si vous aimez Ruby ou si vous voulez torcher un script vite fait, Ruby est un vrai plaisir. Pour du scraping massif et dynamique, regardez ailleurs.
PHP : la simplicité côté serveur pour extraire des données web
PHP a beau sentir les débuts du web, il est toujours bien vivant — surtout si vous voulez extraire des données directement sur votre serveur.
Pourquoi PHP ?
- Fonctionne partout : La plupart des serveurs web embarquent déjà PHP.
- Facile à brancher sur des applications web : Extraire et afficher sur votre site en une seule étape.
- Bibliothèques clés : cURL pour HTTP, Guzzle pour les requêtes, Symfony Panther pour l’automatisation de navigateur en mode headless.
Exemple de code PHP : extraire le titre d’une page
<?php
$ch = curl_init("<https://example.com>");
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$html = curl_exec($ch);
curl_close($ch);
$dom = new DOMDocument();
@$dom->loadHTML($html);
$title = $dom->getElementsByTagName("title")->item(0)->nodeValue;
echo "Titre de la page : $title\n";
?>
Atouts :
- Facile à déployer sur des serveurs web.
- Pratique pour le scraping intégré à un workflow web.
- Rapide pour des tâches simples de scraping côté serveur.
Limites :
- Support de bibliothèques limité pour le scraping avancé.
- Pas taillé pour la forte concurrence ni pour le scraping à grande échelle.
- La gestion des sites très riches en JavaScript reste délicate (même si Panther aide).
Meilleur cas d’usage :
Si votre stack est déjà en PHP, ou si vous voulez extraire et afficher des données sur votre site, PHP est un choix pragmatique. En savoir plus sur PHP vs Python pour le scraping.
C++ : du web scraping haute performance pour les projets à grande échelle
C++, c’est la voiture musclée des langages de programmation. Si vous cherchez la vitesse brute et le contrôle, et que le travail manuel ne vous effraie pas, C++ peut vous mener loin.
Pourquoi C++ ?
- Ultra rapide : Surpasse la plupart des langages sur les tâches gourmandes en CPU.
- Contrôle au millimètre : Vous gérez la mémoire, les threads et les optimisations de performance.
- Bibliothèques clés : libcurl pour HTTP, htmlcxx pour l’analyse.
Exemple de code C++ : extraire le titre d’une page
#include <curl/curl.h>
#include <iostream>
#include <string>
size_t WriteCallback(void* contents, size_t size, size_t nmemb, void* userp) {
std::string* html = static_cast<std::string*>(userp);
size_t totalSize = size * nmemb;
html->append(static_cast<char*>(contents), totalSize);
return totalSize;
}
int main() {
CURL* curl = curl_easy_init();
std::string html;
if(curl) {
curl_easy_setopt(curl, CURLOPT_URL, "<https://example.com>");
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, &html);
CURLcode res = curl_easy_perform(curl);
curl_easy_cleanup(curl);
}
std::size_t startPos = html.find("<title>");
std::size_t endPos = html.find("</title>");
if(startPos != std::string::npos && endPos != std::string::npos) {
startPos += 7;
std::string title = html.substr(startPos, endPos - startPos);
std::cout << "Titre de la page : " << title << std::endl;
} else {
std::cout << "Balise title introuvable" << std::endl;
}
return 0;
}
Atouts :
- Vitesse inégalée pour les gros travaux de scraping.
- Excellent pour intégrer le scraping dans des systèmes haute performance.
Limites :
- Courbe d’apprentissage abrupte (préparez le café).
- Gestion manuelle de la mémoire.
- Peu de bibliothèques de haut niveau ; pas idéal pour le contenu dynamique.
Meilleur cas d’usage :
Quand vous devez extraire des millions de pages, ou quand la performance ne souffre aucun compromis. Sinon, vous risquez de passer plus de temps à déboguer qu’à extraire.
Java : des solutions de web scraping prêtes pour l’entreprise
Java, c’est le cheval de trait du monde de l’entreprise. Si vous bâtissez quelque chose qui doit tourner sans fin, brasser d’énormes volumes de données et survivre à une apocalypse zombie, Java est votre allié.
Pourquoi Java ?
- Robuste et scalable : Excellent pour les gros projets de scraping au long cours.
- Typage fort et gestion des erreurs : Moins de mauvaises surprises en production.
- Bibliothèques clés : Jsoup pour l’analyse, Selenium WebDriver pour l’automatisation du navigateur, Apache HttpClient pour HTTP.
Exemple de code Java : extraire le titre d’une page
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class ScrapeTitle {
public static void main(String[] args) throws Exception {
Document doc = Jsoup.connect("<https://example.com>").get();
String title = doc.title();
System.out.println("Titre de la page : " + title);
}
}
Atouts :
- Hautes performances et forte concurrence.
- Excellent pour les bases de code volumineuses et maintenables.
- Bon support du contenu dynamique (via Selenium ou HtmlUnit).
Limites :
- Syntaxe verbeuse ; plus de configuration que les langages de script.
- Démesuré pour de petits scripts ponctuels.
Meilleur cas d’usage :
Le scraping à l’échelle de l’entreprise, ou quand vous avez besoin d’une fiabilité et d’une scalabilité à toute épreuve.
Go (Golang) : un web scraping rapide et concurrent
Go est le petit dernier, mais il fait déjà beaucoup parler de lui — surtout pour le scraping rapide et concurrent.
Pourquoi Go ?
- Vitesse du compilé : Presque aussi rapide que C++.
- Concurrence native : Les goroutines rendent le scraping parallèle d’une simplicité enfantine.
- Bibliothèques clés : Colly pour le scraping, Goquery pour l’analyse.
Exemple de code Go : extraire le titre d’une page
package main
import (
"fmt"
"github.com/gocolly/colly"
)
func main() {
c := colly.NewCollector()
c.OnHTML("title", func(e *colly.HTMLElement) {
fmt.Println("Titre de la page :", e.Text)
})
err := c.Visit("<https://example.com>")
if err != nil {
fmt.Println("Erreur :", err)
}
}
Atouts :
- Ultra rapide et efficace pour le scraping à grande échelle.
- Facile à déployer (un seul binaire).
- Excellent pour le crawling concurrent.
Limites :
- Communauté plus petite que Python ou Node.js.
- Moins de bibliothèques de scraping de haut niveau.
- La gestion des sites très riches en JavaScript demande une config en plus (Chromedp ou Selenium).
Meilleur cas d’usage :
Quand vous devez extraire à grande échelle, ou quand Python n’est tout bonnement pas assez rapide. Go vs Python pour le scraping : comparaison des performances.
Comparer les meilleurs langages de programmation pour le web scraping
Rassemblons tout ça. Voici une comparaison côte à côte pour vous aider à choisir le meilleur langage pour le web scraping en 2026 :
| Langage/Outil | Facilité d’utilisation | Performances | Support des bibliothèques | Gestion du contenu dynamique | Meilleur cas d’usage |
|---|---|---|---|---|---|
| Python | Très élevée | Modérée | Excellente | Bonne (Selenium/Playwright) | Usage général, débutants, analyse de données |
| JavaScript/Node.js | Moyenne | Élevée | Solide | Excellente (native) | Sites dynamiques, scraping asynchrone, développeurs web |
| Ruby | Élevée | Modérée | Correcte | Limitée (Watir) | Scripts rapides, prototypage |
| PHP | Moyenne | Modérée | Moyenne | Limitée (Panther) | Côté serveur, intégration à des applications web |
| C++ | Faible | Très élevée | Limitée | Très limitée | Performances critiques, très grande échelle |
| Java | Moyenne | Élevée | Bonne | Bonne (Selenium/HtmlUnit) | Entreprise, services longue durée |
| Go (Golang) | Moyenne | Très élevée | En croissance | Modérée (Chromedp) | Scraping rapide et concurrent |
Quand ne pas coder : Thunderbit comme solution de web scraping sans code
Essayez Thunderbit AI Web Scraper Web scraping sans code, propulsé par l’IA, pour les équipes commerciales, marketing et opérationnelles. Get Started Free
Soyons honnêtes : parfois, vous voulez juste les données — sans le code, sans le débogage, sans la crise existentielle du « mais pourquoi ce sélecteur ne marche-t-il pas ? ». C’est là que Thunderbit entre en scène.
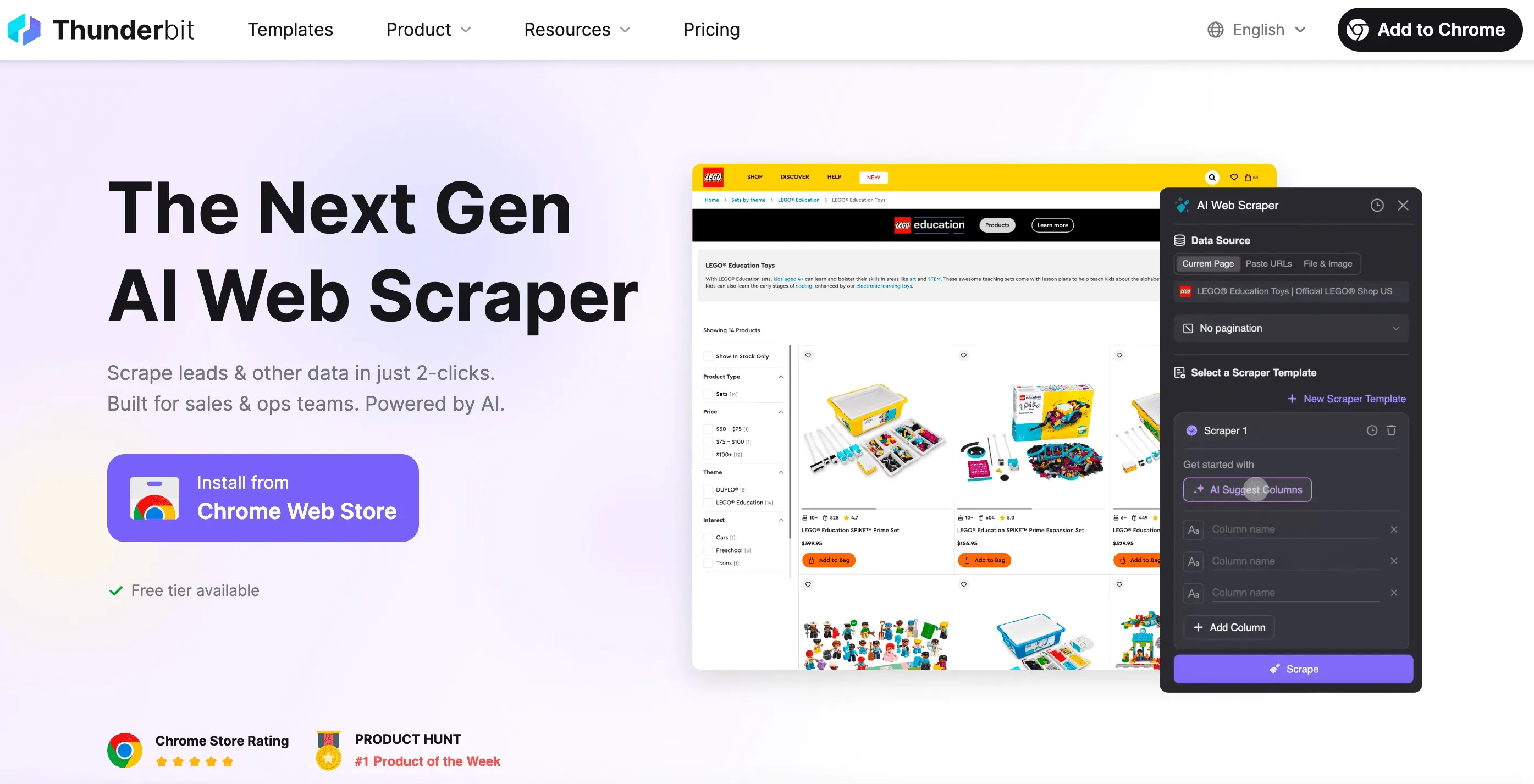
En tant que cofondateur de Thunderbit, je voulais un outil qui rende le web scraping aussi simple que commander un plat à emporter. Voici ce qui distingue Thunderbit :
- Configuration en 2 clics : Cliquez sur « AI Suggest Fields », puis sur « Scrape ». Pas de requêtes HTTP, pas de proxys, pas de techniques anti-bot à manier.
- Modèles intelligents : Un seul modèle de scraper s’adapte à plusieurs mises en page. Inutile de réécrire votre scraper à chaque changement de site.
- Scraping dans le navigateur et dans le cloud : Choisissez l’extraction dans votre navigateur (idéal pour les sites connectés) ou dans le cloud (ultra rapide pour les données publiques).
- Gestion du contenu dynamique : L’IA de Thunderbit pilote un vrai navigateur — elle gère donc le scroll infini, les pop-ups, les connexions, et le reste.
- Export partout : Téléchargez vers Excel, Google Sheets, Airtable, Notion, ou copiez simplement dans le presse-papiers.
- Aucune maintenance : Si un site change, relancez simplement la suggestion IA. Fini les sessions de débogage à pas d’heure.
- Planification et automatisation : Programmez vos scrapers pour qu’ils tournent selon un calendrier — pas de cron jobs, pas de serveur à configurer.
- Extracteurs spécialisés : Besoin d’e-mails, de numéros de téléphone ou d’images ? Thunderbit propose aussi des extracteurs en un clic pour ça.
Le meilleur dans tout ça ? Vous n’avez pas besoin d’une seule ligne de code. Thunderbit s’adresse aux utilisateurs métier, aux marketeurs, aux équipes commerciales, aux professionnels de l’immobilier — à toute personne qui a besoin de données, et vite.
Envie de voir Thunderbit à l’œuvre ? Téléchargez l’extension Chrome ou allez voir notre chaîne YouTube pour des démonstrations.
Essayez gratuitement Thunderbit AI Web Scraper
Conclusion : choisir le meilleur langage pour le web scraping en 2026
Qu’est-ce que le data scraping et comment le faire Get Started Free
Le web scraping en 2026 est plus accessible — et plus puissant — que jamais. Voici ce que des années dans les tranchées de l’automatisation m’ont appris :
- Python reste le meilleur langage pour le web scraping si vous voulez démarrer vite et disposer de ressources à foison.
- JavaScript/Node.js est imbattable pour les sites dynamiques gorgés de JavaScript.
- Ruby et PHP brillent pour les scripts rapides et l’intégration web, surtout si vous les pratiquez déjà.
- C++ et Go sont vos alliés quand il faut de la vitesse et de l’échelle.
- Java est le choix naturel pour les projets d’entreprise au long cours.
- Et si vous voulez zapper le code complètement ? Thunderbit est votre arme secrète.
Avant de vous lancer, posez-vous ces questions :
- Quelle est la taille de mon projet ?
- Dois-je gérer du contenu dynamique ?
- Quel est mon niveau de confort technique ?
- Est-ce que je veux construire quelque chose, ou simplement récupérer les données ?
Testez l’un des extraits de code ci-dessus, ou essayez Thunderbit pour votre prochain projet. Et pour aller plus loin, parcourez notre blog Thunderbit : encore plus de guides, de conseils et d’histoires de scraping vécues.
Bon scraping — et que vos données soient toujours propres, structurées et à un clic de vous.
P.-S. Si vous vous retrouvez un jour coincé dans un terrier de web scraping à 2 heures du matin, gardez juste ça en tête : Thunderbit est toujours là. Ou le café. Ou les deux.
Essayez Thunderbit AI Web Scraper maintenant Get Started Free
FAQ
1. Quel est le meilleur langage de programmation pour le web scraping en 2026 ?
Python reste le premier choix grâce à sa syntaxe lisible, ses bibliothèques puissantes (comme BeautifulSoup, Scrapy et Selenium) et sa grande communauté. Idéal pour les débutants comme pour les experts, surtout quand le scraping s’accompagne d’analyse de données.
2. Quel langage est le meilleur pour extraire des sites très riches en JavaScript ?
JavaScript (Node.js) est le meilleur choix pour les sites dynamiques. Des outils comme Puppeteer et Playwright vous donnent un contrôle total du navigateur, de quoi interagir avec du contenu chargé via React, Vue ou Angular.
3. Existe-t-il une option sans code pour le web scraping ?
Oui — Thunderbit est un extracteur Web IA sans code qui gère tout, du contenu dynamique à la planification. Cliquez sur « AI Suggest Fields » et lancez l’extraction. Parfait pour les équipes commerciales, marketing ou opérations qui ont vite besoin de données structurées.
4. Dois-je encore choisir un langage si un agent de codage IA peut écrire le scraper à ma place ?
Question légitime en 2026. Des outils comme Claude Code, Cursor et OpenAI Codex peuvent générer sans peine un spider Scrapy, un script Playwright ou un crawler Go + Colly à partir d’un prompt de quelques lignes — la friction du « quel langage apprendre en premier » est donc bien plus faible qu’il y a deux ans. Mais l’agent produit malgré tout du code dans un langage, et vous — ou la personne qui héritera du projet — devrez ensuite le lire, le déboguer et le déployer. Le choix compte donc toujours ; il compte simplement davantage pour la maintenance que pour les 30 premières lignes. Et si vous ne voulez toucher à aucun code, c’est là qu’intervient Thunderbit : il évacue complètement la question du langage.
En savoir plus :




