

Un lien qui ne mène nulle part. Une page que plus aucun menu ne relie au reste du site. Une vieille page « test » de 2019 que Google a fini par indexer sans prévenir. Qui gère un site web connaît forcément ce genre de galère.
C’est exactement le travail d’un bon crawler : repérer tout ça et dresser la carte complète de ton site pour que tu puisses corriger le tir. Reste un malentendu tenace : beaucoup confondent encore « web crawler » et « web scraper ». Or ce ne sont pas les mêmes outils.
J’ai mis 10 crawlers gratuits à l’épreuve sur de vrais sites. Certains excellent en audit SEO. D’autres penchent plutôt vers l’extraction de données. Voici ce qui a marché — et ce qui a déçu.
Qu’est-ce qu’un crawler de site web ? Les bases à connaître
Clarifions ce point d’entrée : un crawler de site web n’est pas un web scraper. Je sais, on mélange souvent les deux termes, mais ils renvoient à des fonctions bien distinctes. Vois le crawler comme le cartographe de ton site : il en explore chaque recoin, suit tous les liens et trace la carte de toutes tes pages. Sa mission, c’est la découverte : trouver des URLs, comprendre la structure du site et indexer le contenu. C’est précisément ce que font les robots des moteurs de recherche comme Google, et ce sur quoi s’appuient les outils SEO pour auditer la santé d’un site (Thunderbit Blog: What Is a Web Crawler?).
Le web scraper, lui, est un extracteur de données. Il ne cherche pas à dresser la carte d’ensemble : il fonce droit sur les infos utiles — prix produits, noms d’entreprise, avis, adresses e-mail, etc. Les scrapers extraient des champs précis à partir des pages que les crawlers ont découvertes (Thunderbit Blog: How to Web Crawl a Site?).
Une petite analogie :
- Crawler : la personne qui fait le tour de tous les rayons d’un supermarché pour dresser l’inventaire de tous les produits.
- Scraper : la personne qui file direct au rayon café et relève le prix de chaque mélange bio.
Pourquoi ça change tout ? Parce que pour retrouver simplement toutes les pages de ton site (un audit SEO, par exemple), il te faut un crawler. Pour extraire tous les prix des produits d’un concurrent, il te faut un scraper — ou, mieux encore, un outil qui fait les deux.
Pourquoi utiliser un crawler web en ligne ? Les avantages business à retenir
Alors, pourquoi se mettre au crawl web ? Parce que le web ne cesse de grossir. Concrètement, plus de 54 % des grandes marques utilisent des plateformes de crawl dédiées pour optimiser leurs sites, et certains outils SEO explorent jusqu’à 7 milliards de pages par jour.
Concrètement, voici ce qu’un crawler t’apporte :
- Audits SEO : détecter liens cassés, titres manquants, contenus dupliqués, pages orphelines, et bien plus encore (SEO.ai).
- Contrôle des liens et QA : repérer les erreurs 404 et les boucles de redirection avant tes utilisateurs (Screaming Frog).
- Génération de sitemap : créer automatiquement des sitemaps XML pour les moteurs de recherche et la planification (PowerMapper).
- Inventaire de contenu : dresser la liste de toutes tes pages, de leur hiérarchie et de leurs métadonnées.
- Conformité et accessibilité : vérifier chaque page au regard des normes WCAG, du SEO et des obligations légales (SiteOne Crawler).
- Performance et sécurité : repérer les pages lentes, les images trop lourdes ou les failles de sécurité (SiteOne Crawler).
- Données pour l’IA et l’analyse : alimenter des outils d’analyse ou d’IA avec les données récupérées (Thunderbit Blog: Crawl4AI Review).
Voici un tableau express qui relie chaque cas d’usage à sa fonction métier :
| Cas d’usage | Idéal pour | Bénéfice / résultat |
|---|---|---|
| SEO et audit de site | Marketing, SEO, dirigeants de petites entreprises | Identifier les problèmes techniques, optimiser la structure, améliorer le classement |
| Inventaire de contenu et QA | Responsables contenu, webmasters | Auditer ou migrer du contenu, repérer les liens/images cassés |
| Génération de leads (scraping) | Vente, développement commercial | Automatiser la prospection, enrichir le CRM avec de nouveaux leads |
| Veille concurrentielle | E-commerce, chefs de produit | Suivre les prix concurrents, les nouveaux produits et les variations de stock |
| Clonage de sitemap et de structure | Développeurs, DevOps, consultants | Reproduire la structure d’un site pour une refonte ou une sauvegarde |
| Agrégation de contenu | Chercheurs, médias, analystes | Collecter des données provenant de plusieurs sites pour l’analyse ou le suivi des tendances |
| Étude de marché | Analystes, équipes d’entraînement IA | Réunir de grands ensembles de données pour l’analyse ou l’entraînement de modèles IA |
(Thunderbit Blog: How to Web Crawl a Site?)
Comment nous avons choisi les meilleurs outils gratuits de crawl de sites web
Ces tests m’ont coûté pas mal de soirées tardives — et plus de cafés que je ne veux l’avouer — à manipuler des outils, éplucher la doc et lancer des essais. Voici les critères que j’ai retenus :
- Capacités techniques : l’outil gère-t-il les sites modernes (JavaScript, connexions, contenu dynamique) ?
- Facilité d’utilisation : est-il accessible aux non-techniciens, ou faut-il passer par la ligne de commande ?
- Limites du plan gratuit : est-ce vraiment gratuit, ou juste une démo déguisée ?
- Accessibilité en ligne : outil cloud, application desktop ou bibliothèque de code ?
- Fonctionnalités distinctives : propose-t-il un vrai plus — extraction par IA, sitemaps visuels, crawl piloté par événements, etc. ?
J’ai testé chaque outil, parcouru les retours d’utilisateurs et comparé les fonctionnalités côte à côte. Un outil qui m’a donné envie de balancer mon ordinateur par la fenêtre n’a pas survécu à la sélection.
Tableau comparatif rapide : 10 meilleurs crawlers de sites web gratuits en un coup d’œil
| Outil et type | Fonctionnalités principales | Meilleur cas d’usage | Compétences techniques requises | Détails du plan gratuit |
|---|---|---|---|---|
| BrightData (Cloud/API) | Crawl d’entreprise, proxies, rendu JavaScript, résolution de CAPTCHA | Collecte de données à grande échelle | Quelques compétences techniques utiles | Essai gratuit : 3 scrapers, 100 enregistrements chacun (environ 300 au total) |
| Crawlbase (Cloud/API) | Crawl via API, anti-bot, proxies, rendu JS | Développeurs ayant besoin d’une infrastructure de crawl backend | Intégration API | Gratuit : environ 5 000 appels API pendant 7 jours, puis 1 000/mois |
| ScraperAPI (Cloud/API) | Rotation de proxies, rendu JS, crawl asynchrone, endpoints prêts à l’emploi | Développeurs, suivi des prix, données SEO | Installation minimale | Gratuit : 5 000 appels API pendant 7 jours, puis 1 000/mois |
| Diffbot Crawlbot (Cloud) | Crawl + extraction par IA, knowledge graph, rendu JS | Données structurées à grande échelle, IA/ML | Intégration API | Gratuit : 10 000 crédits/mois (environ 10 000 pages) |
| Screaming Frog (Desktop) | Audit SEO, analyse des liens et des métadonnées, sitemap, extraction personnalisée | Audits SEO, gestion de sites | Application desktop, interface graphique | Gratuit : 500 URLs par crawl, fonctionnalités de base uniquement |
| SiteOne Crawler (Desktop) | SEO, performance, accessibilité, sécurité, export hors ligne, Markdown | Développeurs, QA, migration, documentation | Desktop/CLI, interface graphique | Gratuit et open source, 1 000 URLs dans le rapport GUI (configurable) |
| Crawljax (Java, OpenSrc) | Crawl piloté par événements pour sites riches en JavaScript, export statique | Développeurs, QA pour applications web dynamiques | Java, CLI/configuration | Gratuit et open source, sans limite |
| Apache Nutch (Java, OpenSrc) | Distribué, basé sur des plugins, intégration Hadoop, recherche personnalisée | Moteurs de recherche sur mesure, crawl massif | Java, ligne de commande | Gratuit et open source, seuls les coûts d’infrastructure restent à prévoir |
| YaCy (Java, OpenSrc) | Crawl et recherche pair-à-pair, confidentialité, indexation web/intranet | Recherche privée, décentralisation | Java, interface navigateur | Gratuit et open source, sans limite |
| PowerMapper (Desktop/SaaS) | Sitemaps visuels, accessibilité, QA, compatibilité navigateur | Agences, QA, cartographie visuelle | Interface graphique, simple à prendre en main | Essai gratuit : 30 jours, 100 pages (desktop) ou 10 pages (en ligne) par scan |
BrightData : un crawler cloud haut de gamme pour les entreprises

BrightData, c’est le poids lourd du crawl web. Sa plateforme cloud aligne un vaste réseau de proxies, le rendu JavaScript, la résolution de CAPTCHA et un IDE pour bâtir des crawls personnalisés. Pour une collecte de données à grande échelle — surveiller, par exemple, les prix de centaines de sites e-commerce — son infrastructure est difficile à prendre en défaut (aimultiple.com).
Points forts :
- Encaisse les sites coriaces protégés par des mécanismes anti-bot
- Très scalable pour les besoins d’entreprise
- Modèles prêts à l’emploi pour les sites courants
Limites :
- Pas de niveau gratuit permanent (uniquement un essai : 3 scrapers, 100 enregistrements chacun)
- Peut s’avérer surdimensionné pour de simples audits
- Courbe d’apprentissage à prévoir pour les profils non techniques
Pour crawler le web à grande échelle, BrightData revient à louer une Formule 1. En revanche, inutile d’espérer la garder gratuitement après l’essai (BrightData Pricing).
Crawlbase : un crawler web gratuit piloté par API pour les développeurs

Crawlbase (anciennement ProxyCrawl) mise tout sur le crawl programmatique. Tu envoies une URL à son API, et elle te renvoie le HTML — en gérant proxies, géolocalisation et CAPTCHA en arrière-plan (Capterra).
Points forts :
- Taux de réussite très élevés (99 % et plus)
- Gère les sites riches en JavaScript
- Très pratique à brancher sur tes propres applications ou workflows
Limites :
- Nécessite une intégration API ou SDK
- Plan gratuit : environ 5 000 appels API pendant 7 jours, puis 1 000 par mois
Si tu es développeur et que tu veux crawler — voire scraper — à grande échelle sans gérer toi-même les proxies, Crawlbase tient très bien la route (Crawlbase Pricing).
ScraperAPI : simplifier le crawl web dynamique

ScraperAPI, c’est l’API du « récupère-le-moi ». Tu lui passes une URL ; elle se charge des proxies, des navigateurs headless et des protections anti-bot, puis te renvoie le HTML — parfois des données structurées, selon les sites. Elle se montre redoutable sur les pages dynamiques et offre un plan gratuit généreux (ScraperAPI Pricing).
Points forts :
- Très simple pour les développeurs (un seul appel API)
- Gère CAPTCHA, blocages IP et JavaScript
- Gratuit : 5 000 appels API pendant 7 jours, puis 1 000/mois
Limites :
- Pas de rapports visuels de crawl
- À toi d’écrire la logique de crawl si tu veux suivre les liens
Pour brancher le crawl web sur ton code en quelques minutes, ScraperAPI s’impose comme une évidence.
Diffbot Crawlbot : découverte automatisée de la structure d’un site

Diffbot Crawlbot passe à la vitesse supérieure. Il ne se contente pas de crawler : il mobilise l’IA pour classer les pages et extraire des données structurées (articles, produits, événements, etc.) au format JSON. Comme un stagiaire robot qui comprend réellement ce qu’il lit (Diffbot Free Plan).
Points forts :
- Extraction dopée à l’IA, et pas seulement crawl
- Gère JavaScript et le contenu dynamique
- Gratuit : 10 000 crédits/mois (environ 10 000 pages)
Limites :
- Orienté développeurs (intégration API)
- Pas un outil SEO visuel — plutôt taillé pour les projets data
Si tu vises des données structurées à grande échelle, notamment pour l’IA ou l’analytique, Diffbot est une vraie machine de guerre.
Screaming Frog : le crawler SEO desktop gratuit

Screaming Frog reste LA référence des crawlers desktop pour les audits SEO. La version gratuite explore jusqu’à 500 URLs par scan et livre l’essentiel : liens cassés, balises meta, contenu dupliqué, sitemaps, et plus encore (Screaming Frog User Guide).
Points forts :
- Rapide, complet et reconnu dans tout l’univers SEO
- Zéro code : tu saisis une URL et tu lances l’analyse
- Gratuit jusqu’à 500 URLs par crawl
Limites :
- Uniquement en local (pas de version cloud)
- Les fonctions avancées (rendu JS, planification) passent par une licence payante
Si le SEO compte vraiment pour toi, Screaming Frog est incontournable — mais ne compte pas crawler gratuitement un site de 10 000 pages.
SiteOne Crawler : export de sites statiques et documentation

SiteOne Crawler est l’outil polyvalent des audits techniques. Open source et multiplateforme, il crawle, audite et exporte même ton site en Markdown, pour la documentation ou un usage hors ligne (SiteOne Crawler).
Points forts :
- Couvre SEO, performance, accessibilité et sécurité
- Exporte les sites pour l’archivage ou la migration
- Gratuit et open source, sans limite d’utilisation
Limites :
- Plus technique que certains outils à interface graphique
- Le rapport dans l’interface plafonne par défaut à 1 000 URLs (configurable)
Si tu es développeur, QA ou consultant et que l’open source te parle, SiteOne est une belle trouvaille.
Crawljax : un crawler web Java open source pour pages dynamiques
Crawljax est un outil de niche : il explore les applications web modernes bourrées de JavaScript en simulant les gestes d’un utilisateur réel (clics, remplissage de formulaires, etc.). Piloté par événements, il peut même générer une version statique d’un site dynamique (Wikipedia: Crawljax).
Points forts :
- Excellent pour les SPAs et les sites très dépendants d’AJAX
- Open source et extensible
- Aucune limite d’utilisation
Limites :
- Exige Java et un minimum de configuration/développement
- Pas adapté aux profils non techniques
Pour crawler une app React ou Angular comme un vrai utilisateur, Crawljax est un allié de poids.
Apache Nutch : un crawler web distribué et scalable

Apache Nutch est le doyen des crawlers open source. Il est taillé pour les crawls massifs et distribués — par exemple, monter ton propre moteur de recherche ou indexer des millions de pages (Martechvibe).
Points forts :
- S’étend jusqu’à des milliards de pages avec Hadoop
- Très configurable et extensible
- Gratuit et open source
Limites :
- Courbe d’apprentissage costaude (Java, ligne de commande, configuration)
- Pas idéal pour les petits sites ou les usages occasionnels
Si tu veux crawler le web à grande échelle et que la ligne de commande ne te fait pas peur, Nutch est fait pour toi.
YaCy : crawler web pair-à-pair et moteur de recherche
YaCy est un crawler et moteur de recherche décentralisé assez singulier. Chaque instance explore et indexe des sites, et tu peux rejoindre un réseau pair-à-pair pour partager les index avec d’autres (TechRadar: YaCy).
Points forts :
- Axé confidentialité, sans serveur central
- Idéal pour bâtir une recherche privée ou interne
- Gratuit et open source
Limites :
- Les résultats dépendent de la couverture du réseau
- Exige un peu de configuration (Java, interface navigateur)
Si la décentralisation te parle ou si tu rêves de ton propre moteur de recherche, YaCy mérite vraiment le détour.
PowerMapper : générateur de sitemap visuel pour l’UX et la QA

PowerMapper mise tout sur la visualisation de la structure de ton site. Il l’explore, génère des sitemaps interactifs et vérifie au passage l’accessibilité, la compatibilité navigateur et les bases du SEO (Slickplan Review).
Points forts :
- Les sitemaps visuels rendent service aux agences et aux designers
- Vérifie l’accessibilité et la conformité
- Interface simple, aucune compétence technique requise
Limites :
- Essai gratuit uniquement (30 jours, 100 pages desktop / 10 pages en ligne par scan)
- La version complète est payante
Pour présenter un plan de site à un client ou vérifier la conformité d’un projet, PowerMapper rend de fiers services.
Choisir le bon crawler web gratuit selon vos besoins
Face à autant d’options, comment trancher ? Voici mon aide-mémoire express :
- Pour les audits SEO : Screaming Frog (petits sites), PowerMapper (visuel), SiteOne (audits approfondis)
- Pour les applications web dynamiques : Crawljax
- Pour les crawls à grande échelle ou la recherche personnalisée : Apache Nutch, YaCy
- Pour les développeurs qui ont besoin d’une API : Crawlbase, ScraperAPI, Diffbot
- Pour la documentation ou l’archivage : SiteOne Crawler
- Pour une approche entreprise avec essai : BrightData, Diffbot
Critères clés à garder en tête :
- Scalabilité : quelle taille fait ton site ou ta mission de crawl ?
- Facilité d’utilisation : à l’aise avec le code, ou tu préfères cliquer sans programmer ?
- Export des données : besoin de CSV, JSON ou d’une intégration avec d’autres outils ?
- Support : existe-t-il une communauté ou une documentation utile en cas de blocage ?
Quand le web crawling rencontre le web scraping : pourquoi Thunderbit est le choix le plus malin
Extrayez des données de n’importe quel site web grâce à l’IA Get Started Free
Soyons honnêtes : presque personne ne crawle un site pour le plaisir de jolies cartes. L’objectif final, le plus souvent, c’est d’obtenir des données structurées — fiches produits, coordonnées ou inventaires de contenu. C’est exactement là que Thunderbit entre en scène.
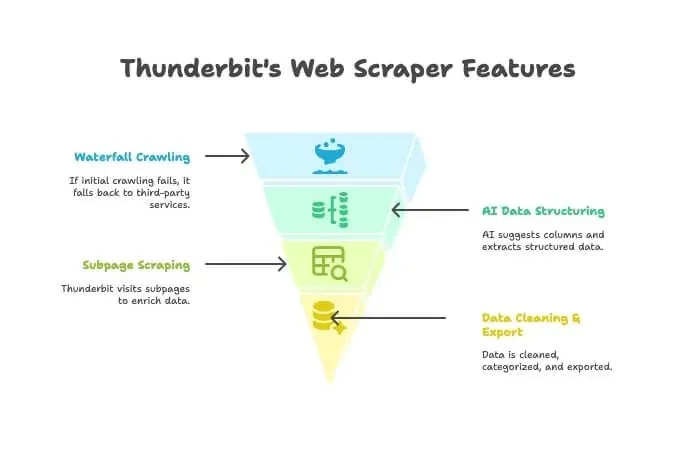
Thunderbit n’est pas qu’un crawler ou qu’un scraper : c’est une extension Chrome dopée à l’IA qui réunit les deux. Le mécanisme :
- Crawler IA : Thunderbit explore le site à la manière d’un crawler.
- Crawl en cascade : si son moteur n’arrive pas à charger une page (une protection anti-bot coriace, par exemple), il bascule tout seul vers des services de crawl tiers — sans configuration manuelle.
- Structuration IA des données : une fois le HTML en main, l’IA de Thunderbit propose les bonnes colonnes et extrait des données structurées (noms, prix, e-mails, etc.) sans que tu écrives un seul sélecteur.
- Scraping des sous-pages : besoin du détail de chaque fiche produit ? Thunderbit visite chaque sous-page automatiquement et enrichit ton tableau.
- Nettoyage et export des données : il résume, classe, traduit et exporte tes données vers Excel, Google Sheets, Airtable ou Notion en un clic.
- Simplicité sans code : si tu sais te servir d’un navigateur, tu sais te servir de Thunderbit. Pas de code, pas de proxies, pas de prise de tête.
Quand préférer Thunderbit à un crawler traditionnel ?
- Quand ton objectif final est un tableau propre et exploitable, pas une simple liste d’URLs.
- Quand tu veux tout automatiser au même endroit — crawl, extraction, nettoyage, export.
- Quand ton temps et ta tranquillité d’esprit comptent.
Tu peux télécharger l’extension Chrome de Thunderbit ici et constater par toi-même pourquoi tant d’utilisateurs pros l’adoptent.
Essayer Thunderbit gratuitement – AI Web Scraper
Conclusion : tirer le meilleur parti des crawlers de sites web gratuits
Qu’est-ce que le data scraping et comment le faire Get Started Free
Les crawlers de sites web ont fait du chemin. Marketeur, développeur ou simplement soucieux de la santé de ton site : il existe un outil gratuit — ou au moins testable gratuitement — pour ton profil. Des plateformes d’entreprise comme BrightData et Diffbot aux pépites open source comme SiteOne et Crawljax, en passant par les cartographes visuels comme PowerMapper, l’offre n’a jamais été aussi fournie.
Mais si tu cherches une façon plus maligne et mieux intégrée de passer de « il me faut ces données » à « voici mon tableau », essaie Thunderbit. L’outil est pensé pour les utilisateurs business en quête de résultats, pas de simples rapports.
Envie de te lancer dans le crawl ? Télécharge un outil, lance une analyse et découvre ce que tu ratais jusqu’ici. Et pour passer du crawl à des données exploitables en deux clics, découvre Thunderbit.
Pour d’autres analyses approfondies et guides pratiques, fais un tour sur le Thunderbit Blog.
Extraire des données de site web avec l’IA en 2 clics
Essayer l’AI Web Scraper Get Started Free
FAQ
Quelle est la différence entre un crawler de site web et un web scraper ?
Un crawler découvre et cartographie toutes les pages d’un site (un peu comme s’il en dressait la table des matières). Un scraper, lui, extrait des champs de données précis (prix, e-mails, avis) depuis ces pages. Les crawlers trouvent, les scrapers extraient (Thunderbit Blog: What Is a Web Crawler?).
Quel crawler web gratuit est le plus adapté aux non-techniciens ?
Pour les petits sites et les audits SEO, Screaming Frog se prend en main facilement. Pour la cartographie visuelle, PowerMapper fait très bien le travail pendant l’essai. Et si ton but est d’obtenir des données structurées avec une expérience sans code, directement dans le navigateur, Thunderbit reste le plus simple.
Existe-t-il des sites qui bloquent les crawlers web ?
Oui — certains sites recourent à des fichiers robots.txt ou à des mécanismes anti-bot (CAPTCHA, blocage d’IP) pour empêcher le crawl. Des outils comme ScraperAPI, Crawlbase et Thunderbit (avec le crawl en cascade) parviennent souvent à franchir ces obstacles, mais il faut toujours crawler de façon responsable et respecter les règles du site (BrightData Pricing).
Les crawlers de sites web gratuits ont-ils des limites de pages ou de fonctionnalités ?
La plupart, oui. La version gratuite de Screaming Frog plafonne à 500 URLs par crawl ; l’essai de PowerMapper se limite à 100 pages. Les outils basés sur API imposent souvent des plafonds mensuels de crédits. Les outils open source comme SiteOne ou Crawljax n’ont en général pas de limite stricte, mais tu es alors borné par ton matériel.
L’utilisation d’un crawler web est-elle légale et conforme aux règles de confidentialité ?
En règle générale, crawler des pages web publiques est légal, mais vérifie toujours les conditions d’utilisation du site et son fichier robots.txt. Ne crawle jamais de données privées ou protégées par mot de passe sans autorisation, et reste vigilant sur les lois de protection des données dès que tu extrais des informations personnelles (Crawlbase Guide).




