

« Gratuit » : voilà le mot qui revient dans presque toutes les recherches d’outils d’extraction. Le problème, c’est qu’il ne veut presque jamais dire ce que tu crois. Derrière la promesse se cachent le plus souvent des essais bridés, ou les fonctions vraiment utiles verrouillées derrière un paiement.
Aujourd’hui, copier-coller des données à la main n’est plus une option tenable pour une équipe commerciale, marketing ou opérationnelle. Tout le monde passe à l’extraction automatisée — et ceux qui restent sur le copier-coller manuel accumulent du retard sans même s’en rendre compte.
Du coup, j’ai mis 12 outils à l’épreuve pour distinguer les vrais gratuits des appâts. Mon protocole : extraire des fiches Google Maps, des pages dynamiques planquées derrière une connexion, et des PDF. Certains ont assuré. D’autres m’ont juste bouffé un après-midi.
Voici le bilan, sans langue de bois — en partant de ceux que je conseille vraiment.
Pourquoi les extracteurs gratuits sont plus importants que jamais
Disons-le franchement : en 2026, l’extraction web a quitté le terrain des hackers et des data scientists. C’est devenu un réflexe pour les entreprises modernes, et les chiffres parlent d’eux-mêmes. Le marché des logiciels d’extraction web a atteint 1,01 milliard de dollars en 2024 et devrait plus que doubler d’ici 2032. La raison ? Des équipes commerciales aux agents immobiliers, tout le monde exploite désormais les données web pour garder une longueur d’avance.
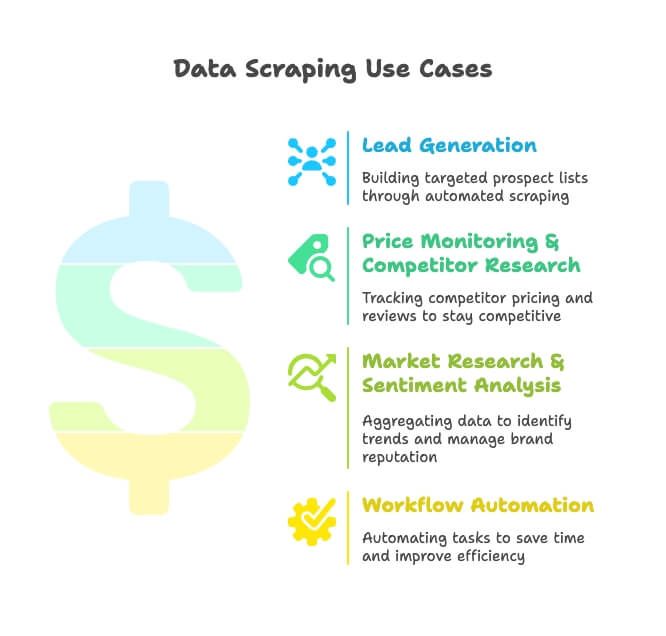
- Génération de leads : les commerciaux extraient annuaires, fiches Google Maps et réseaux sociaux pour bâtir des listes de prospects ciblés — adieu la prospection manuelle.
- Veille tarifaire et analyse concurrentielle : dans l’e-commerce et le retail, on suit références, prix et avis des concurrents pour rester dans la course (82 % des entreprises e-commerce utilisent l’extraction précisément pour ça).
- Études de marché et analyse des sentiments : côté marketing, on agrège avis, actualités et conversations sociales pour capter les tendances et surveiller son image.
- Automatisation des workflows : les équipes opérations automatisent tout, du suivi des stocks aux rapports programmés, et récupèrent des heures chaque semaine.
Un chiffre qui résume tout : les entreprises équipées d’extracteurs web dopés à l’IA gagnent 30 à 40 % de temps face aux méthodes manuelles. Ce n’est pas un petit gain marginal : c’est ce qui sépare une journée qui finit à 18 h d’une journée qui s’éternise jusqu’à 21 h.
Comment nous avons sélectionné les meilleurs outils gratuits d’extraction de données
Des listes de « meilleurs web scrapers » qui recyclent du discours marketing, j’en ai vu défiler des dizaines. Ici, on change de méthode. Mes critères de sélection :
- Utilité réelle de l’offre gratuite : l’outil permet-il d’abattre du vrai travail, ou sert-il juste d’appât ?
- Simplicité d’utilisation : un profil non technique obtient-il un résultat en quelques minutes, ou faut-il un doctorat en Regex ?
- Types de sites pris en charge : statiques, dynamiques, paginés, avec connexion, PDF, réseaux sociaux — l’outil tient-il face à des cas réels ?
- Options d’export : peut-on envoyer les données vers Excel, Google Sheets, Notion ou Airtable sans bricolage interminable ?
- Fonctions supplémentaires : extraction assistée par IA, planification, modèles, post-traitement, intégrations.
- Profil utilisateur visé : outil pour utilisateurs métier, analystes ou développeurs ?
J’ai aussi épluché la documentation de chaque outil, testé l’onboarding et comparé les limites des offres gratuites — parce que, encore une fois, « gratuit » est un mot à géométrie variable.
Vue d’ensemble : comparaison de 12 extracteurs de données gratuits
Voici un panorama côte à côte pour repérer en un coup d’œil l’outil le plus adapté à tes besoins.
| Outil | Plateforme | Limites de l’offre gratuite | Idéal pour | Formats d’export | Fonctions distinctives |
|---|---|---|---|---|---|
| Thunderbit | Extension Chrome | 6 pages/mois | Non-développeurs, entreprises | Excel, CSV | Prompts IA, extraction PDF/image, exploration de sous-pages |
| Browse AI | Cloud | 50 crédits/mois | Utilisateurs no-code | CSV, Sheets | Robots point-and-click, planification |
| Octoparse | Bureau | 10 tâches, 50 k lignes/mois | No-code, utilisateurs semi-techniques | CSV, Excel, JSON | Workflow visuel, prise en charge des sites dynamiques |
| ParseHub | Bureau | 5 projets, 200 pages/exécution | No-code, utilisateurs semi-techniques | CSV, Excel, JSON | Interface visuelle, support des sites dynamiques |
| Webscraper.io | Extension Chrome | Utilisation locale illimitée | No-code, tâches simples | CSV, XLSX | Basé sur des sitemaps, modèles communautaires |
| Apify | Cloud | 5 $ de crédits/mois | Équipes, utilisateurs semi-techniques, développeurs | CSV, JSON, Sheets | Marketplace d’actors, planification, API |
| Scrapy | Bibliothèque Python | Illimité (open source) | Développeurs | CSV, JSON, DB | Contrôle total du code, scalable |
| Puppeteer | Bibliothèque Node.js | Illimité (open source) | Développeurs | Personnalisé (code) | Navigateur headless, prise en charge du JavaScript dynamique |
| Selenium | Multi-langages | Illimité (open source) | Développeurs | Personnalisé (code) | Automatisation de navigateur, compatibilité multi-navigateurs |
| Zyte | Cloud | 1 spider, 1 h/tâche, rétention 7 jours | Développeurs, équipes ops | CSV, JSON | Scrapy hébergé, gestion des proxies |
| SerpAPI | API | 100 recherches/mois | Développeurs, analystes | JSON | API pour moteurs de recherche, anti-blocage |
| Diffbot | API | 10 000 crédits/mois | Développeurs, projets IA | JSON | Extraction IA, graphe de connaissance |
Thunderbit : le meilleur choix pour une extraction de données simple, puissante et dopée à l’IA
Extraire des données depuis n’importe quel site grâce à l’IA Get Started Free
Voyons pourquoi Thunderbit arrive en tête de ma sélection. Oui, je fais partie de l’équipe — mais c’est sincèrement ce qui se rapproche le plus, à mes yeux, d’un stagiaire IA qui écoute vraiment les consignes (et ne réclame pas une pause café toutes les heures).
Avec Thunderbit, on oublie la vieille logique « apprends d’abord l’outil, extrait ensuite ». L’approche tient plutôt du briefing donné à un assistant futé : tu décris ce que tu veux (« Récupère tous les noms de produits, prix et liens de cette page »), et l’IA de Thunderbit fait le reste. Aucun XPath, aucun sélecteur CSS, aucune bagarre avec les Regex. Besoin d’aller plus loin, dans les sous-pages — fiches produit ou pages de contact, par exemple ? Thunderbit clique tout seul et enrichit ton tableau, là encore en un clic.
Mais la vraie différence se joue après l’extraction. Résumer, traduire, classer ou nettoyer tes données ? Le post-traitement IA intégré s’en occupe. Tu ne repars pas avec des données brutes : tu obtiens une information structurée et directement exploitable, prête à filer dans ton CRM, ton tableur ou ton prochain gros projet.
Offre gratuite : l’essai gratuit de Thunderbit te laisse extraire jusqu’à 6 pages (ou 10 avec le boost d’essai), PDF, images et modèles pour réseaux sociaux compris. L’export vers Excel ou CSV est gratuit, et tu peux tester des fonctions comme l’extraction d’e-mails, de numéros de téléphone et d’images. Pour des besoins plus costauds, les offres payantes débloquent davantage de pages, l’export direct vers Google Sheets/Notion/Airtable, l’extraction programmée et des modèles instantanés pour des sites populaires comme Amazon, Google Maps et Instagram.
Pour voir Thunderbit à l’œuvre, jette un œil à l’extension Chrome Thunderbit ou fais un tour sur notre chaîne YouTube, où tu trouveras des tutoriels de prise en main rapide.
Essayer Thunderbit gratuitement
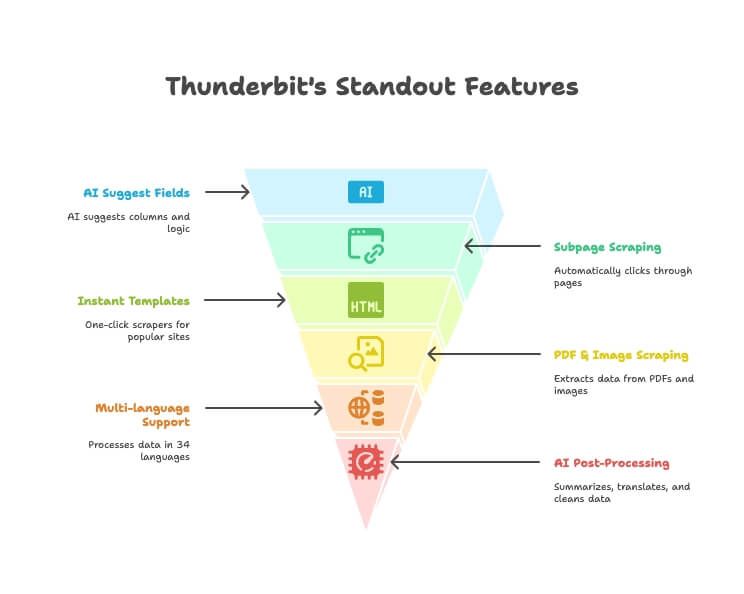
Les points forts de Thunderbit
- Suggestions de champs par IA : décris les données que tu veux, et l’IA de Thunderbit propose les colonnes et la logique d’extraction adaptées.
- Extraction de sous-pages : clic automatique sur les pages de détail ou les liens pour enrichir ton tableau principal — sans réglage manuel.
- Modèles instantanés : extracteurs en un clic pour Amazon, Google Maps, Instagram et bien d’autres.
- Extraction PDF et image : récupère tableaux et données depuis des PDF et des images grâce à l’IA — aucun outil supplémentaire requis.
- Prise en charge multilingue : extrais et traite des données dans 34 langues.
- Export direct : envoie tes données vers Excel, Google Sheets, Notion ou Airtable (offres payantes).
- Post-traitement IA : résume, traduis, catégorise et nettoie les données pendant l’extraction.
- Extraction gratuite d’e-mails, de téléphones et d’images : récupère coordonnées ou visuels d’un site en un clic.
Thunderbit comble le fossé entre « extraire des données » et « obtenir des données vraiment utiles ». C’est l’outil le plus proche d’un véritable assistant de données IA pour les profils métier.
Le reste du top 12 : analyse des outils gratuits d’extraction de données
Place au reste du classement, rangé selon les profils auxquels chaque outil convient le mieux.
Pour les utilisateurs no-code et les équipes métier
Thunderbit
Déjà présenté plus haut. La porte d’entrée la plus simple pour les non-développeurs, avec ses fonctions IA et ses modèles instantanés.
Webscraper.io
- Plateforme : extension Chrome
- Idéal pour : sites simples et statiques ; non-développeurs qui acceptent un peu d’essais-erreurs.
- Fonctions clés : extraction basée sur des sitemaps, prise en charge de la pagination, export CSV/XLSX.
- Offre gratuite : utilisation locale illimitée, mais pas d’exécutions cloud ni de planification. Usage manuel uniquement.
- Limites : pas de gestion native des connexions, PDF ou contenus dynamiques complexes. Support communautaire uniquement.
ParseHub
- Plateforme : application de bureau (Windows, Mac, Linux)
- Idéal pour : non-développeurs et profils semi-techniques prêts à investir un peu de temps d’apprentissage.
- Fonctions clés : création de workflows visuels, prise en charge des sites dynamiques, AJAX, connexions et pagination.
- Offre gratuite : 5 projets publics, 200 pages par exécution, exécution manuelle uniquement.
- Limites : sur l’offre gratuite, les projets sont publics (gare aux données sensibles), pas de planification, vitesse d’extraction plus lente.
Octoparse
- Plateforme : application de bureau (Windows/Mac), cloud (payant)
- Idéal pour : non-développeurs et analystes en quête de puissance et de souplesse.
- Fonctions clés : interface visuelle point-and-click, support des contenus dynamiques, modèles pour les sites populaires.
- Offre gratuite : 10 tâches, jusqu’à 50 000 lignes/mois, uniquement sur desktop (pas de cloud/planification).
- Limites : pas d’API, pas de rotation d’IP ni de planification dans l’offre gratuite. La prise en main peut être rude sur les sites complexes.
Browse AI
- Plateforme : cloud
- Idéal pour : utilisateurs no-code qui veulent automatiser l’extraction simple et la surveillance.
- Fonctions clés : enregistrement de robots par point-and-click, planification, intégrations (Sheets, Zapier).
- Offre gratuite : 50 crédits/mois, 1 site web, jusqu’à 5 robots.
- Limites : volume limité, apprentissage initial parfois nécessaire pour les sites complexes.
Pour les développeurs et profils techniques
Scrapy
- Plateforme : bibliothèque Python (open source)
- Idéal pour : développeurs en quête de contrôle total et de scalabilité.
- Fonctions clés : hautement personnalisable, compatible avec les gros crawls, middlewares et pipelines.
- Offre gratuite : illimitée (open source).
- Limites : pas d’interface graphique, code Python obligatoire. Pas adapté aux non-développeurs.
Puppeteer
- Plateforme : bibliothèque Node.js (open source)
- Idéal pour : développeurs qui extraient des sites dynamiques et fortement dépendants du JavaScript.
- Fonctions clés : automatisation de navigateur headless, contrôle total de la navigation et de l’extraction.
- Offre gratuite : illimitée (open source).
- Limites : code JavaScript requis, pas d’interface graphique.
Selenium
- Plateforme : multi-langages (Python, Java, etc.), open source
- Idéal pour : développeurs qui automatisent des navigateurs pour l’extraction ou les tests.
- Fonctions clés : compatibilité multi-navigateurs, automatisation des clics, du scroll et des connexions.
- Offre gratuite : illimitée (open source).
- Limites : plus lent que les bibliothèques headless, scripting requis.
Zyte (Scrapy Cloud)
- Plateforme : cloud
- Idéal pour : développeurs et équipes ops qui déploient des spiders Scrapy à grande échelle.
- Fonctions clés : Scrapy hébergé, gestion des proxies, planification des tâches.
- Offre gratuite : 1 spider simultané, 1 heure par tâche, rétention des données 7 jours.
- Limites : pas de planification avancée dans l’offre gratuite, connaissance de Scrapy requise.
Pour les équipes et les usages entreprise
Apify
- Plateforme : cloud
- Idéal pour : équipes, profils semi-techniques et développeurs en quête d’extracteurs prêts à l’emploi ou sur mesure.
- Fonctions clés : marketplace d’actors (bots préconstruits), planification, API, intégrations.
- Offre gratuite : 5 $ de crédits/mois (de quoi mener de petites tâches), rétention des données 7 jours.
- Limites : une courbe d’apprentissage à prévoir, usage plafonné par les crédits.
SerpAPI
- Plateforme : API
- Idéal pour : développeurs et analystes qui ont besoin de données issues des moteurs de recherche (Google, Bing, YouTube).
- Fonctions clés : API de recherche, anti-blocage, sortie JSON structurée.
- Offre gratuite : 100 recherches/mois.
- Limites : ne convient pas aux sites arbitraires, usage via API uniquement.
Diffbot
- Plateforme : API
- Idéal pour : développeurs, équipes IA/ML et grandes entreprises qui ont besoin de données web structurées à grande échelle.
- Fonctions clés : extraction IA, graphe de connaissance, API pour articles/produits.
- Offre gratuite : 10 000 crédits/mois.
- Limites : API uniquement, compétences techniques requises, débit limité par des quotas.
Limites des offres gratuites : ce que « gratuit » veut vraiment dire pour chaque extracteur
Soyons honnêtes : « gratuit » peut tout aussi bien signifier « illimité pour les amateurs » que « juste de quoi t’accrocher ». Voici ce que tu obtiens réellement :
| Outil | Pages/lignes par mois | Formats d’export | Planification | Accès API | Limites gratuites notables |
|---|---|---|---|---|---|
| Thunderbit | 6 pages | Excel, CSV | Non | Non | Champs suggérés par IA limités, pas d’export direct vers Sheets/Notion sur l’offre gratuite |
| Browse AI | 50 crédits | CSV, Sheets | Oui | Oui | 1 site web, 5 robots, rétention 15 jours |
| Octoparse | 50 000 lignes | CSV, Excel, JSON | Non | Non | Desktop uniquement, pas de cloud/planification |
| ParseHub | 200 pages/exécution | CSV, Excel, JSON | Non | Non | 5 projets publics, vitesse lente |
| Webscraper.io | Local illimité | CSV, XLSX | Non | Non | Exécutions manuelles, pas de cloud |
| Apify | 5 $ de crédits (~petit volume) | CSV, JSON, Sheets | Oui | Oui | Rétention 7 jours, plafond de crédits |
| Scrapy | Illimité | CSV, JSON, DB | Non | N/A | Code obligatoire |
| Puppeteer | Illimité | Personnalisé (code) | Non | N/A | Code obligatoire |
| Selenium | Illimité | Personnalisé (code) | Non | N/A | Code obligatoire |
| Zyte | 1 spider, 1 h/tâche | CSV, JSON | Limité | Oui | Rétention 7 jours, 1 tâche simultanée |
| SerpAPI | 100 recherches | JSON | Non | Oui | API de recherche uniquement |
| Diffbot | 10 000 crédits | JSON | Non | Oui | API uniquement, débit limité |
En résumé : pour de vrais projets, Thunderbit, Browse AI et Apify offrent les essais gratuits les plus utiles aux profils métier. Pour une extraction continue ou à grande échelle, tu atteindras vite les limites — il faudra alors basculer sur une formule payante ou adopter des solutions open source / code.
Quel outil d’extraction de données correspond le mieux à vos besoins ? (Guide par type d’utilisateur)
Voici une fiche mémo pour choisir l’outil adapté à ton rôle et à ton niveau technique :
| Type d’utilisateur | Meilleurs outils (gratuits) | Pourquoi |
|---|---|---|
| Non-développeur (vente/marketing) | Thunderbit, Browse AI, Webscraper.io | Prise en main rapide, point-and-click, aide IA |
| Semi-technique (ops/analyste) | Octoparse, ParseHub, Apify, Zyte | Plus de puissance, gère les sites complexes, un peu de scripting possible |
| Développeur/ingénieur | Scrapy, Puppeteer, Selenium, Diffbot, SerpAPI | Contrôle total, illimité, orienté API |
| Équipe/entreprise | Apify, Zyte | Collaboration, planification, intégrations |
Scénarios réels d’extraction web : comparaison de l’adaptabilité des outils
Regardons comment ces outils se débrouillent dans cinq scénarios d’extraction courants :
| Scénario | Thunderbit | Browse AI | Octoparse | ParseHub | Webscraper.io | Apify | Scrapy | Puppeteer | Selenium | Zyte | SerpAPI | Diffbot |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Listes paginées | Facile | Facile | Moyen | Moyen | Moyen | Facile | Facile | Facile | Facile | Facile | N/A | Moyen |
| Fiches Google Maps | Facile* | Difficile | Moyen | Moyen | Difficile | Facile | Difficile | Difficile | Difficile | Difficile | Facile | N/A |
| Pages nécessitant une connexion | Facile | Moyen | Moyen | Moyen | Manuel | Moyen | Facile | Facile | Facile | Facile | N/A | N/A |
| Extraction de données PDF | Facile | Non | Non | Non | Non | Moyen | Difficile | Difficile | Difficile | Difficile | Non | Limité |
| Contenu des réseaux sociaux | Facile* | Partiel | Difficile | Difficile | Difficile | Facile | Difficile | Difficile | Difficile | Difficile | YouTube | Limité |
- Thunderbit et Apify proposent des modèles/actors prêts à l’emploi pour Google Maps et l’extraction des réseaux sociaux, ce qui simplifie énormément ces cas d’usage pour les profils non techniques.
Extension, logiciel desktop ou cloud : quelle est la meilleure expérience d’extracteur web ?
- Extensions Chrome (Thunderbit, Webscraper.io) :
- Avantages : démarrage rapide, fonctionne dans le navigateur, configuration minimale.
- Inconvénients : usage manuel, sensible aux changements de site, automatisation limitée.
- L’avantage Thunderbit : l’IA encaisse les changements de structure, la navigation entre sous-pages et même l’extraction de PDF/images — bien plus robuste qu’une extension classique.
- Applications desktop (Octoparse, ParseHub) :
- Avantages : puissantes, workflows visuels, gestion des sites dynamiques et des connexions.
- Inconvénients : prise en main plus longue, pas d’automatisation cloud sur les offres gratuites, dépend de l’OS.
- Plateformes cloud (Browse AI, Apify, Zyte) :
- Avantages : planification, travail en équipe, évolutives, intégrations.
- Inconvénients : offres gratuites souvent plafonnées par les crédits, configuration parfois nécessaire, connaissances API parfois requises.
- Bibliothèques open source (Scrapy, Puppeteer, Selenium) :
- Avantages : illimitées, personnalisables, idéales pour les développeurs.
- Inconvénients : code requis, pas adaptées aux profils métier.
Tendances 2026 de l’extraction web : ce qui distingue les outils modernes
En 2026, l’extraction web gravite autour de l’IA, de l’automatisation et des intégrations. Les nouveautés à connaître :
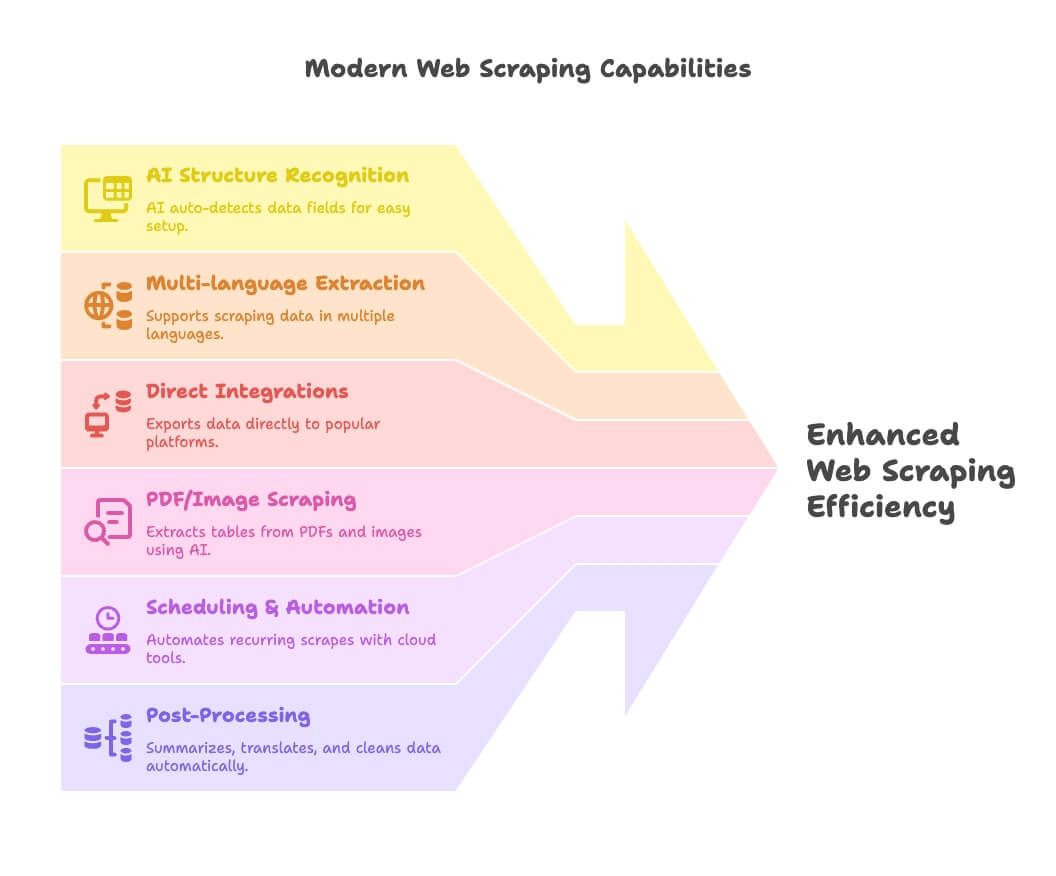
- Reconnaissance de structure par IA : des outils comme Thunderbit s’appuient sur l’IA pour détecter automatiquement les champs de données, ce qui allège énormément la configuration pour les non-développeurs.
- Extraction multilingue : Thunderbit, entre autres, permet d’extraire et de traiter des données dans des dizaines de langues.
- Intégrations directes : exporte les données extraites directement vers Google Sheets, Notion ou Airtable — terminées les manipulations de CSV.
- Extraction PDF/image : Thunderbit brille ici, en permettant d’extraire des tableaux depuis des PDF et des images grâce à l’IA.
- Planification et automatisation : les outils cloud (Apify, Browse AI) permettent de programmer des extractions récurrentes et de ne plus y penser.
- Post-traitement : résume, traduit, catégorise et nettoie les données pendant l’extraction — finis les tableaux en vrac.
Thunderbit, Apify et SerpAPI sont à la pointe de ces tendances ; mais c’est surtout Thunderbit qui se démarque, en rendant l’extraction dopée à l’IA accessible à tout le monde, pas seulement aux développeurs.
Au-delà de l’extraction : traitement des données et fonctions à forte valeur ajoutée
Récupérer des données ne suffit pas — encore faut-il les rendre exploitables. Voici comment les meilleurs outils se comparent en post-traitement :
| Outil | Nettoyage | Traduction | Catégorisation | Résumé | Remarques |
|---|---|---|---|---|---|
| Thunderbit | Oui | Oui | Oui | Oui | Post-traitement IA intégré |
| Apify | Partiel | Partiel | Partiel | Partiel | Dépend de l’actor utilisé |
| Browse AI | Non | Non | Non | Non | Données brutes uniquement |
| Octoparse | Partiel | Non | Partiel | Non | Quelques traitements de champs |
| ParseHub | Partiel | Non | Partiel | Non | Quelques traitements de champs |
| Webscraper.io | Non | Non | Non | Non | Données brutes uniquement |
| Scrapy | Oui* | Oui* | Oui* | Oui* | Si le développeur l’a codé |
| Puppeteer | Oui* | Oui* | Oui* | Oui* | Si le développeur l’a codé |
| Selenium | Oui* | Oui* | Oui* | Oui* | Si le développeur l’a codé |
| Zyte | Partiel | Non | Partiel | Non | Quelques fonctions d’extraction automatique |
| SerpAPI | Non | Non | Non | Non | Données de recherche structurées uniquement |
| Diffbot | Oui | Oui | Oui | Oui | Propulsé par l’IA, mais API uniquement |
- Le développeur doit coder lui-même la logique de traitement.
Thunderbit est le seul outil qui permet à des profils non techniques de passer de données web brutes à des insights structurés et exploitables, le tout dans un seul workflow.
Communauté, support et ressources d’apprentissage : comment monter en compétence
La documentation et l’onboarding pèsent lourd. Voici comment les outils se comparent :
| Outil | Docs et tutoriels | Communauté | Modèles | Courbe d’apprentissage |
|---|---|---|---|---|
| Thunderbit | Excellentes | En croissance | Oui | Très faible |
| Browse AI | Bonnes | Bonne | Oui | Faible |
| Octoparse | Excellentes | Grande | Oui | Moyenne |
| ParseHub | Excellentes | Grande | Oui | Moyenne |
| Webscraper.io | Bonnes | Forum | Oui | Moyenne |
| Apify | Excellentes | Grande | Oui | Moyenne à élevée |
| Scrapy | Excellentes | Immense | N/A | Élevée |
| Puppeteer | Bonnes | Grande | N/A | Élevée |
| Selenium | Bonnes | Immense | N/A | Élevée |
| Zyte | Bonnes | Grande | Oui | Moyenne à élevée |
| SerpAPI | Bonnes | Moyenne | N/A | Élevée |
| Diffbot | Bonnes | Moyenne | N/A | Élevée |
Thunderbit et Browse AI sont les plus faciles pour démarrer. Octoparse et ParseHub offrent d’excellentes ressources, mais demandent plus de patience. Apify et les outils pour développeurs affichent une courbe d’apprentissage plus raide, tout en étant très bien documentés.
Conclusion : choisir le bon extracteur de données gratuit en 2026
Découvrez les meilleurs outils d’extraction web en 2026 Get Started Free
En résumé : tous les outils d’extraction de données « gratuits » ne se valent pas, et ton choix doit suivre ton rôle, ton niveau technique et tes besoins réels en extraction.
- Si tu es un utilisateur métier ou un non-développeur qui veut des données rapidement — surtout depuis des sites complexes, des PDF ou des images — Thunderbit est le meilleur point de départ. Son approche pilotée par l’IA, ses prompts en langage naturel et ses fonctions de post-traitement en font l’outil le plus proche d’un véritable assistant de données IA. Teste gratuitement l’extension Chrome Thunderbit et mesure la vitesse à laquelle tu passes de « il me faut cette donnée » à « voici mon tableau ».
- Si tu es développeur ou s’il te faut une extraction illimitée et personnalisable, les outils open source comme Scrapy, Puppeteer et Selenium sont tes meilleurs alliés.
- Pour les équipes et les profils semi-techniques, Apify et Zyte proposent des solutions évolutives et collaboratives, avec des offres gratuites généreuses pour les petites tâches.
Quel que soit ton workflow, commence par l’outil qui colle à tes compétences et à tes besoins. Et garde ça en tête : en 2026, nul besoin d’être développeur pour exploiter la puissance des données web — il suffit du bon assistant (et peut-être d’un peu d’humour quand les robots te grillent la politesse).
Envie d’aller plus loin ? Découvre d’autres guides et comparatifs sur le blog Thunderbit, notamment :
- Qu’est-ce que l’extraction de données et comment la faire en 2026
- Comment extraire des données de sites web vers Excel avec l’IA
- Les meilleurs outils et logiciels d’extraction web en 2026
Commencer l’extraction avec Thunderbit
Essayer l’AI Web Scraper Get Started Free




