Il y a trois semaines, je me suis assis pour chercher des vendeurs de « portrait personnalisé pour animaux » sur Etsy. Quarante-sept onglets de navigateur, deux heures de copier-coller et un tableur très mal organisé plus tard, je n’avais toujours pas une vision claire des prix, des avis, ni de ceux qui diffusaient des publicités par rapport à ceux qui ressortaient naturellement. C’est cette expérience qui a lancé tout ce projet.
Etsy propose désormais , 5,6 millions de vendeurs actifs et 86,5 millions d’acheteurs actifs. C’est une place de marché immense et bruyante — et si vous êtes vendeur, marketeur ou chercheur e-commerce et que vous essayez de comprendre ce qui fonctionne dans votre niche, vous avez besoin de données structurées, pas d’un mur d’onglets ouverts. Le problème ? Les défenses anti-bot d’Etsy sont devenues redoutablement sophistiquées en 2026. Entre les structures de page dynamiques, le fingerprinting TLS, les CAPTCHAs et l’analyse comportementale, l’époque où l’on pouvait écrire un petit script Python et considérer l’affaire réglée est pratiquement révolue.
J’ai passé les dernières semaines à tester six extracteurs Etsy face à face — des outils IA sans code aux API pour développeurs — et je vais vous montrer précisément ce qui a marché, ce qui n’a pas marché, et quel outil convient à quel type d’utilisateur. Je vais aussi aborder les données que vous pouvez réellement extraire (et celles que vous ne pouvez pas), le débat API Etsy contre scraping, des cas d’usage concrets et la manière de vérifier vos résultats pour éviter de prendre des décisions sur la base de mauvaises données.
Pourquoi extraire Etsy est plus difficile qu’on ne le pense
Si vous avez déjà essayé d’extraire Etsy et vous êtes retrouvé bloqué, vous n’êtes pas seul. Etsy n’est pas un catalogue statique — c’est une place de marché dynamique et personnalisée. Les résultats de recherche, les annonces, les badges, les infos d’expédition et même les noms de classes CSS sur la page peuvent changer selon la session, l’appareil et le pays.
Voici, en résumé, ce qui rend Etsy délicat :
- Structure de page dynamique : le front-end d’Etsy change fréquemment. Des sélecteurs qui fonctionnaient hier peuvent renvoyer du vide aujourd’hui. C’est un peu comme si Etsy changeait les serrures de ses portes toutes les quelques heures — la page paraît toujours familière pour l’acheteur, mais les points d’accroche dont dépend un extracteur peuvent bouger sans prévenir.
- Systèmes de gestion des bots : des fournisseurs d’extracteurs comme indiquent publiquement qu’Etsy utilise une « protection anti-bot agressive » et que des sessions peuvent être bloquées. Certaines pages d’Actor mentionnent des schémas d’URL conçus pour contourner DataDome et l’imitation du fingerprint TLS de Chrome. Plus largement, a constaté que le trafic automatisé représentait 53 % de tout le trafic web en 2025, et que les bots constituaient 42,1 % du trafic web global — les sites e-commerce sont une cible de premier ordre.
- CAPTCHA et limitation de débit : un scraping à fort volume peut déclencher des CAPTCHA ou des blocages purs et simples. Le précise même que si un CAPTCHA apparaît, les utilisateurs peuvent mettre la tâche en pause et le résoudre manuellement.
- Résultats sponsorisés et personnalisation : les résultats de recherche Etsy mélangent des annonces organiques et payantes, et . Si vous ne suivez pas quels résultats sont des annonces, votre analyse concurrentielle peut être complètement faussée.
Rien de tout cela ne signifie qu’extraire Etsy est impossible. Cela signifie simplement que l’outil que vous choisissez compte beaucoup plus qu’avant.

Quelles données pouvez-vous réellement extraire d’Etsy ?
C’est la section que j’aimerais voir dans tous les articles concurrents — et que presque aucun n’inclut. Avant de choisir un outil, vous devez savoir ce qui est réellement possible.
Données accessibles depuis les résultats de recherche Etsy
Les pages de résultats vous offrent de la largeur. Voici ce que vous pouvez généralement extraire depuis la grille :
- Titre du produit
- Prix (actuel, promotion, prix d’origine quand il est visible)
- Devise
- URL de l’image principale
- URL de la fiche produit / ID de la fiche
- Nom de la boutique (quand visible — les annonces affichent parfois « Ad by Etsy Seller »)
- Note
- Nombre d’avis
- Badge de livraison gratuite
- Badges Bestseller / Etsy’s Pick / Star Seller
- Libellé sponsorisé / annonce
- Numéro de page et position
- Métadonnées de requête, filtre, tri et pays/session
L’, par exemple, expose des champs comme listingId, name, url, imageUrl, shop, shopId, price, originalPrice, currency, onSale, freeShipping, rating, availability, position, query, page et scrapedAt — une bonne validation de ce qui est réellement extrait de manière fiable.
Données qui nécessitent de visiter chaque fiche produit (scraping des sous-pages)
Les cartes de recherche sont volontairement compactes. Si vous faites une vraie analyse produit, vous avez besoin des champs cachés un clic plus loin :
- Description complète
- Galerie d’images complète et URL des vidéos
- Variantes et options de personnalisation
- Détails de l’article (matériaux, attributs, dimensions)
- Délai de traitement
- Détails d’expédition et estimations de livraison
- Détails du profil vendeur/boutique et politiques
- Extraits d’avis ou avis complets
- Articles associés
La confirme que les vendeurs saisissent le titre, la catégorie, les attributs, le prix, les variantes, la personnalisation, la description, le profil d’expédition, les détails de traitement/livraison et les dimensions/poids de l’article — ces champs existent donc, mais il faut visiter la page pour les récupérer.
C’est là que le scraping des sous-pages devient vraiment utile. Avec , par exemple, vous pouvez extraire une page de résultats Etsy pour récupérer les titres, prix et notes, puis cliquer sur « Scrape Subpages » pour que l’IA visite chaque fiche individuellement et enrichisse le tableau avec les tags, matériaux, détails d’expédition et infos vendeur — sans configuration supplémentaire. Le Field AI Prompt de Thunderbit vous permet aussi d’ajouter des instructions personnalisées par colonne (par exemple : « classer ce produit dans Bijoux / Déco / Vêtements »).
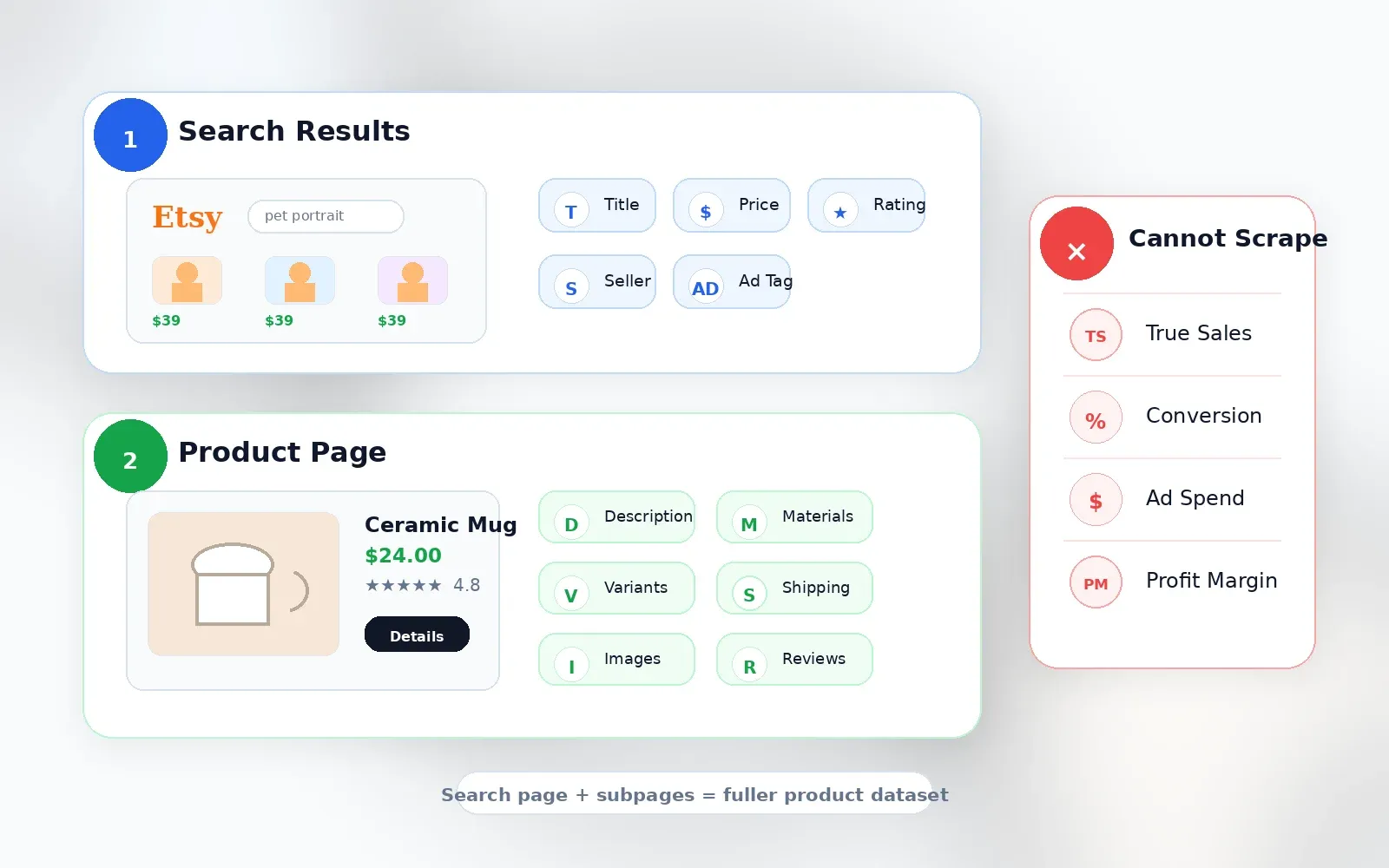
Ce que le scraping ne peut pas vous dire
Je préfère être transparent sur ce point, car c’est là que beaucoup d’outils perdent en crédibilité :
| Point de données | Disponible via le scraping ? | Remarques |
|---|---|---|
| Ventes réelles par fiche | Non | Etsy n’affiche pas publiquement les ventes exactes pour chaque fiche. Les ventes au niveau de la boutique peuvent être visibles, mais pas au niveau de la fiche. |
| Taux de conversion | Non | Réservé aux outils d’analyse du vendeur, pas public. |
| Vrai volume de recherche des mots-clés | Non | Etsy Marketplace Insights affiche des données sur 30 jours dans les outils vendeur, mais ce n’est pas un champ public à extraire. |
| Dépenses publicitaires / données d’enchère | Non | Non exposées comme données publiques des annonces. |
| Marge bénéficiaire | Non | Le prix et l’expédition sont visibles ; pas les coûts de production, les frais ni les retours. |
Tout outil affirmant connaître exactement les ventes Etsy des fiches concurrentes fait une estimation, pas l’extraction d’un fait public. Des outils comme , et décrivent ouvertement l’usage d’algorithmes d’estimation, et non un accès direct aux données.
API Etsy ou scraping : de quoi avez-vous vraiment besoin ?
C’est une question que je vois tout le temps sur les forums : « Puisque l’API Etsy ne fournit pas les données de mots-clés, j’imagine qu’ils font du scraping. » La confusion est réelle, alors voici un décryptage clair.
| Dimension | API officielle Etsy | Web Scraping |
|---|---|---|
| Meilleur cas d’usage | Gérer votre boutique, vos fiches, votre stock, vos commandes, vos paiements | Recherche concurrentielle, suivi des recherches, intelligence prix, enrichissement des sous-pages |
| Fiches | Recherche de fiches actives et points de détail | Toute page publique de recherche / fiche / boutique / avis |
| Ventes/commandes de votre boutique | Oui, avec autorisation/scopes | Inutile ; utilisez l’API / Shop Manager |
| Ventes exactes des concurrents | Non | Non (estimations uniquement) |
| Volume de recherche des mots-clés | Non exposé comme point de terminaison Open API public | Pas directement ; Marketplace Insights est dans l’interface vendeur |
| Limites de débit | QPS/QPD spécifiques à l’application ; gestion des 429 | Dépend de l’outil / de la plateforme |
| Position vis-à-vis des CGU | Voie officielle lorsqu’elle est utilisée dans les règles | Les conditions Etsy limitent le scraping sans autorisation |
| Sortie | Réponses JSON de l’API | CSV/Sheets/JSON/HTML selon l’outil |
En bref : si vous devez gérer votre propre boutique, utilisez l’API. Si vous devez comprendre vos concurrents, surveiller les prix ou étudier une niche, le scraping est la voie la plus pratique. Des outils comme eRank et Alura combinent probablement l’accès API, le scraping et l’estimation — vous savez maintenant pourquoi.
Sans code ou avec code : comment choisir le meilleur extracteur Etsy
La plupart des personnes qui cherchent les « meilleurs extracteurs Etsy » ne sont pas des développeurs en train de bâtir une infrastructure. Ce sont des vendeurs, des marketeurs, des assistants virtuels ou des chercheurs e-commerce qui veulent un tableau exploitable. Pourtant, la plupart des articles concurrents se concentrent sur des outils API ou des bibliothèques Python. Il y a un décalage.
Voici mon cadre de décision :
| Si vous êtes... | Choisissez... | Pourquoi |
|---|---|---|
| Vendeur ou marketeur non technique | Thunderbit | Suggestions de champs IA, extension Chrome, scraping des sous-pages, export direct, scraping programmé |
| Non technique mais adepte des workflows visuels | Octoparse | Constructeur de workflows visuel pour desktop, modèles, détection automatique, mode cloud |
| Freelance ou petite agence gérant des missions Etsy récurrentes | Apify | Actors cloud, planificateur, API, options au résultat |
| Développeur construisant un pipeline interne | ScrapingBee ou ZenRows | Transport par API, rendu JS, gestion des proxys/CAPTCHA ; vous contrôlez le parsing et le stockage |
| Équipe data en entreprise | Bright Data | API/dataset de scraping managés, options de livraison, disponibilité et posture de conformité |
Pour ce public, « sans code » signifie : pas de configuration de proxy, pas de sélecteurs CSS, pas de commandes terminal, pas de gestion de navigateur headless, pas de logique de réessai personnalisée, pas de base de données à configurer. Vous exportez directement vers un tableur ou une application de travail, et l’enrichissement des sous-pages ne vous oblige pas à construire des boucles de clics.
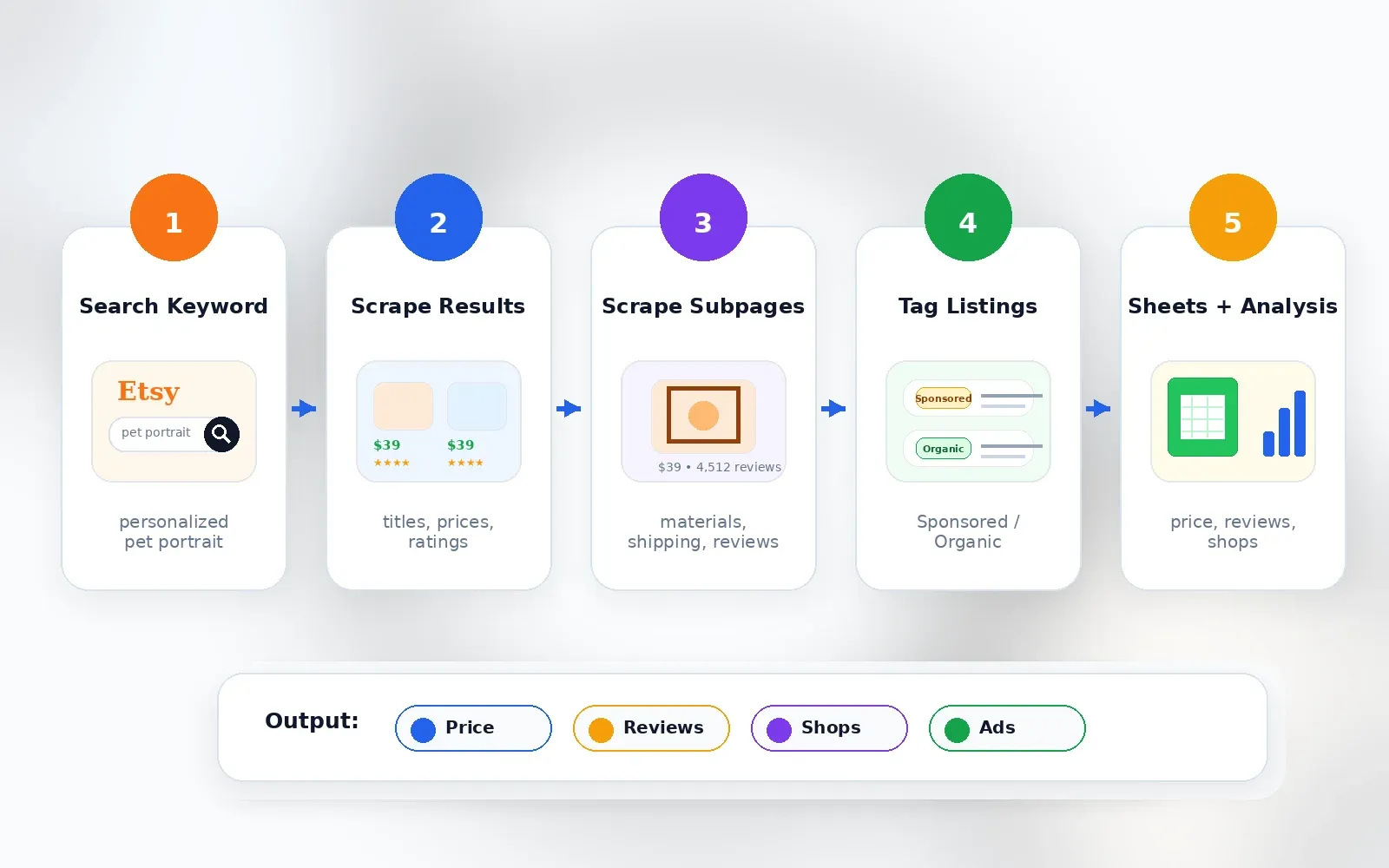
Comment j’ai évalué ces 6 extracteurs Etsy
J’ai testé chaque outil sur le même ensemble de tâches : une requête Etsy (« personalized pet portrait »), une requête produit très concurrentielle (« gold huggie earrings »), une URL de boutique avec de nombreuses fiches, dix pages de détail de fiche pour l’enrichissement des sous-pages, une tâche de suivi hebdomadaire de prix programmée, et un export vers Google Sheets ou CSV.
Voici les critères que j’ai notés :
| Critère | Pourquoi c’est important |
|---|---|
| Facilité d’utilisation (sans code vs avec code) | Les vendeurs Etsy ne devraient pas devoir devenir ingénieurs en scraping |
| Gestion anti-bot/CAPTCHA | Un outil qui fonctionne sur 10 lignes mais échoue à la page 2 n’est pas utile |
| Champs de données extractibles | Les champs des résultats de recherche ne suffisent pas pour une vraie recherche produit |
| Options d’export (CSV, JSON, Sheets, Airtable) | Le vrai workflow se termine généralement dans Sheets, Airtable, Notion, CSV, JSON ou des outils BI |
| Transparence des prix (niveau gratuit + coût par 1K enregistrements) | Le coût par ligne exploitable compte plus que le prix mensuel affiché |
| Enrichissement des sous-pages | Tags, descriptions, expédition, matériaux, variantes et avis se trouvent un clic plus loin |
1. Thunderbit
est l’outil que nous avons créé chez Thunderbit, spécialement pour les utilisateurs non techniques qui ont besoin rapidement de données web structurées. C’est une propulsée par l’IA — vous ouvrez une page Etsy, cliquez sur « AI Suggest Fields », et l’IA lit la structure de la page et propose des colonnes comme titre, prix, avis, vendeur, URL, image, badge et expédition. Ensuite, vous cliquez sur « Scrape » et obtenez un tableau. C’est tout.
Ce qui rend Thunderbit particulièrement utile pour la recherche Etsy, c’est la fonction de scraping des sous-pages. Après avoir extrait une page de résultats, vous pouvez cliquer sur « Scrape Subpages » et l’IA de Thunderbit visite chaque fiche individuelle pour enrichir votre tableau avec les descriptions complètes, détails d’expédition, matériaux, tags et infos vendeur — sans configuration supplémentaire. J’ai utilisé ce flux pour passer d’une requête de recherche à un tableur d’analyse concurrentielle complet en moins de dix minutes.
Fonctionnalités clés
- AI Suggest Fields : l’IA lit la page Etsy et recommande des colonnes. Pas de sélecteurs, pas de devinettes.
- Scraping en 2 clics : idéal pour la recherche produit ponctuelle.
- Scraping des sous-pages : enrichissez les résultats de recherche avec les détails complets des fiches en un clic.
- Scraping programmé : mettez en place un suivi hebdomadaire des prix concurrents en décrivant simplement l’intervalle.
- Field AI Prompt : ajoutez des instructions personnalisées par colonne (par exemple : « classer dans Bijoux / Déco / Vêtements » ou « indiquer si cette fiche semble personnalisée »).
- Exports : Excel, Google Sheets, Airtable, Notion, CSV, JSON — .
- Mode cloud et mode navigateur : mode cloud pour des tâches publiques plus rapides ; mode navigateur pour les pages où votre session/rendu actuel compte (plus précis pour les champs dynamiques comme les favoris).
- API ouverte : le accepte une URL + un schéma JSON et prend en charge jusqu’à 100 URL par requête.
Comment Thunderbit extrait Etsy en 2 clics
- Accédez à une page de résultats Etsy (par exemple, recherchez « personalized pet portrait »).
- Cliquez sur AI Suggest Fields — l’IA propose des colonnes comme titre, prix, avis, vendeur, URL, image, badges.
- Cliquez sur Scrape — les données s’affichent dans un tableau.
- En option, cliquez sur Scrape Subpages dans la colonne URL de la fiche pour enrichir les lignes avec la description complète, les détails d’expédition, les matériaux ou les avis.
- Exportez vers Google Sheets, Airtable, Notion, Excel, CSV ou JSON.
Vous pouvez aussi consulter notre pour des tutoriels vidéo.
Tarifs
Thunderbit fonctionne avec un système de crédits. Il existe un niveau d’essai / gratuit, et le plan Starter coûte environ 15 $/mois pour 500 crédits (ou 108 $/an pour 5 000 crédits annuels). Le scraping des sous-pages peut consommer davantage de crédits, car chaque ligne/page enrichie compte séparément. Voir pour les informations à jour.
Avantages et inconvénients
| Avantages | Inconvénients |
|---|---|
| Aucun code, aucune configuration de sélecteur | Système à crédits ; les très gros volumes nécessitent un plan payant |
| La détection IA des champs réduit la maintenance liée aux changements de page | L’extension Chrome nécessite une installation dans le navigateur |
| L’enrichissement des sous-pages est intégré | N’est pas positionné comme fournisseur de datasets à l’échelle entreprise |
| Le scraping programmé et l’auto-export soutiennent les workflows de surveillance | La précision doit toujours être vérifiée ponctuellement (vrai pour tous les outils) |
| Fonctionne au-delà d’Etsy — utile pour la recherche e-commerce générale | Certains champs restent indisponibles car Etsy ne les expose pas |
Idéal pour : les vendeurs Etsy qui font de la recherche produit, les marketeurs qui construisent des rapports concurrents, les équipes ops qui surveillent les prix.
2. Apify Etsy Scraper
est une plateforme d’automatisation cloud avec une place de marché d’« Actors » — des extracteurs prêts à l’emploi que vous pouvez exécuter sans gérer votre propre infrastructure. Pour Etsy, plusieurs Actors sont disponibles, notamment le et le .
L’Actor Automation Lab prend en charge la recherche par mot-clé, le filtrage par catégorie, la pagination (jusqu’à 5 000 produits par exécution) et une sortie structurée avec des champs comme l’ID de fiche, le titre, l’URL, l’URL de l’image, la boutique, le prix, le prix d’origine, la devise, le statut promo, la livraison gratuite, la note, la disponibilité, la position, la requête, la page et l’horodatage d’extraction. C’est un ensemble solide pour des données au niveau des résultats de recherche.
Fonctionnalités clés
- Hébergé dans le cloud (aucune ressource locale nécessaire)
- Recherche par mot-clé, catégorie et scraping d’URL de boutique
- Gestion de la pagination
- Export JSON, CSV, Excel
- Intégration de proxy (proxies résidentiels disponibles en supplément)
- Planificateur pour tâches récurrentes
- Accès API pour l’intégration de pipelines
Tarifs
L’ facture à l’exécution plus à l’utilisation par produit : environ 0,80 $ à 3,45 $ par 1K produits selon votre plan Apify. Les plans de la plateforme commencent à environ 9 $/mois (Starter) plus l’usage des actors. Le plan gratuit inclut 5 $/mois d’utilisation plateforme.
Avantages et inconvénients
| Avantages | Inconvénients |
|---|---|
| Actors Etsy prêts à l’emploi | La qualité varie selon le mainteneur |
| Exécution cloud, planificateur, API, webhooks | Les Actors communautaires peuvent prendre du retard quand Etsy change la mise en page |
| Tarification transparente au résultat sur certains Actors | Les coûts des proxys augmentent à grande échelle |
| Export JSON/CSV/Excel via le dataset Apify | L’enrichissement personnalisé des sous-pages peut nécessiter de la configuration |
| Adapté aux pipelines de données récurrents | Low-code, moins simple qu’une extension de navigateur pour les vendeurs |
Idéal pour : les freelances, petites agences et utilisateurs semi-techniques qui veulent un pipeline de données Etsy prêt à l’emploi.
3. Bright Data
est l’option entreprise. Si vous êtes une grande société e-commerce ou une équipe data qui extrait des milliers de fiches Etsy chaque jour, cet outil est conçu pour vous. Bright Data propose une et un avec plus de 18 millions d’enregistrements et 59 champs.
Leur infrastructure est massive — plus de 100 millions d’IP résidentielles, gestion anti-bot complète (proxies résidentiels, résolution de CAPTCHA, fingerprinting de navigateur), sortie JSON structurée et approche orientée conformité. Ils proposent aussi une option Data Collector sans code pour les utilisateurs qui ne veulent pas toucher au code.
Fonctionnalités clés
- Collecteur de données Etsy préconstruit (option tableau de bord sans code)
- Gestion anti-bot complète
- Sortie JSON structurée avec plus de 59 champs
- Livraison gérée, webhooks et intégrations de stockage cloud
- SLA entreprise, outils de conformité, garanties de disponibilité
- Dataset Etsy prêt à l’emploi pour l’analyse en masse
Tarifs
L’API Etsy Scraper de Bright Data démarre à environ en pay-as-you-go. Le dataset Etsy a un minimum de 50 $. Pas de niveau gratuit, mais la page de l’API Scraper annonce 1K requêtes d’essai. Le plan Scale est à 499 $/mois. C’est un tarif premium — ce n’est pas pour quelqu’un qui extrait 50 fiches un samedi après-midi.
Avantages et inconvénients
| Avantages | Inconvénients |
|---|---|
| Plateforme la plus fiable et la plus stable | Surdimensionné pour une recherche ponctuelle de vendeur |
| Contournement anti-bot parmi les meilleurs du secteur | Prix premium (barrière pour les petites entreprises) |
| Option Data Collector sans code | Trop de fonctionnalités pour des tâches simples |
| Outils de conformité stricts | Aucun niveau gratuit |
| Échelle massive | La personnalisation des sous-pages peut nécessiter du travail API/configuration |
Idéal pour : les grandes entreprises e-commerce, les équipes data et les organisations ayant besoin de disponibilité garantie, de conformité juridique et d’échelle.
4. Octoparse
est une application de bureau avec une interface visuelle point-and-click pour créer des workflows de scraping. Si vous aimez voir exactement ce que fait votre extracteur — cliquer, faire défiler, paginer — c’est l’outil qu’il vous faut.
Octoparse propose un capable d’extraire, à partir d’un mot-clé, le nom du produit, le vendeur, la note, le nombre d’avis, le prix, l’URL et l’URL de l’image. Leur explique comment extraire les informations produit Etsy, y compris la détection automatique des données de la page et la création de workflows avec pagination et défilement.
Fonctionnalités clés
- Constructeur de workflows visuel (glisser-déposer)
- Rotation d’IP intégrée
- Gestion des CAPTCHA via intégrations tierces (option de résolution manuelle indiquée dans le modèle Etsy)
- Support du défilement infini et de la pagination
- Option d’exécution cloud
- Exports : CSV, Excel, JSON, connexions base de données, Google Sheets (sur les plans payants)
Tarifs
Plan gratuit avec extraction locale et limites de lignes. Le plan Standard est d’environ en annuel. Les offres payantes ajoutent les fonctionnalités cloud, davantage d’options d’export et des limites de lignes plus élevées.
Avantages et inconvénients
| Avantages | Inconvénients |
|---|---|
| Vraie interface visuelle sans code | L’application de bureau est gourmande en ressources |
| Un modèle Etsy et un tutoriel existent | Le scraping complexe des sous-pages nécessite une configuration manuelle du workflow |
| Gère la pagination et le défilement infini | Le CAPTCHA peut exiger une résolution manuelle dans certains cas |
| Exports CSV, Excel, JSON, bases de données | Plus lent que les solutions basées sur API à grande échelle |
| Bon parcours d’apprentissage pour le scraping sans code | Plus de friction de configuration que les outils de suggestion de champs IA |
Idéal pour : les chercheurs marché et analystes business non techniques qui préfèrent une interface visuelle et veulent personnaliser leurs workflows d’extraction sans code.
5. ScrapingBee
est une API pensée pour les développeurs. Vous lui envoyez une URL, elle renvoie le HTML rendu (ou du JSON extrait si vous configurez des règles d’extraction). Il n’existe pas de parseur Etsy prêt à l’emploi qui vous donne directement un tableur — vous écrivez votre propre logique d’extraction en Python, JavaScript ou dans le langage de votre choix.
La indique que les champs extractibles peuvent inclure le nom du produit, les catégories, le prix, le statut de stock, les informations d’expédition et la taille à l’aide de règles d’extraction au format JSON. Elle souligne aussi que le scraping Etsy doit tenir compte des proxys premium, de la gestion du rythme des requêtes et des risques liés aux conditions d’utilisation.
Fonctionnalités clés
- Rendu JavaScript
- Rotation automatique des proxys
- Gestion des CAPTCHA
- API REST simple
- Compatible Python/Node.js/quel que soit le langage
- Retourne du HTML brut ou du JSON ; l’utilisateur effectue le parsing et l’export
Tarifs
1 000 crédits API gratuits pour commencer. Le inclut 250K crédits et 10 requêtes simultanées. Startup à 99 $/mois pour 1M de crédits. Business à 249 $/mois pour 3M de crédits.
Avantages et inconvénients
| Avantages | Inconvénients |
|---|---|
| Intégration API simple | Code requis (Python/JS) |
| Rendu JavaScript et options de proxy | Renvoie du HTML brut (pas de parsing automatique de tous les champs) |
| Fonctionne avec n’importe quel langage | Pas d’interface visuelle |
| Bon pour les pipelines de données personnalisés | L’enrichissement des sous-pages nécessite un script personnalisé |
| Plus flexible que les outils visuels | L’export, le stockage et la planification sont de votre responsabilité |
Idéal pour : les développeurs Python/JS qui construisent des outils internes propriétaires et qui ont besoin d’une « couche de transport » fiable pour récupérer le HTML d’Etsy sans blocage.
6. ZenRows
est une autre API pour développeurs, similaire à ScrapingBee mais avec une emphase plus forte sur le contournement anti-bot à grande échelle. Elle gère automatiquement les CAPTCHA, le fingerprinting et les proxys résidentiels.
La liste des champs comme la remise, l’URL, le nom du vendeur, la description, la note, le nom du produit, le prix, la disponibilité, la catégorie, l’image, les avis et la devise. Elle revendique un taux de réussite de 99,93 % et des fonctionnalités comme l’anti-CAPTCHA, les proxys premium, le mode furtif, l’extraction intelligente et le rendu JavaScript.
Fonctionnalités clés
- Contournement anti-bot (proxys premium, navigateurs headless)
- En-têtes à rotation automatique
- Rendu JavaScript
- Appels API simples
- Support de forte concurrence
Tarifs
Essai gratuit de 14 jours avec 1 000 résultats de base et 40 résultats protégés. Le inclut 250K résultats de base / 10K résultats protégés. Les requêtes protégées (pour les sites avec anti-bot) coûtent plus cher par requête.
Avantages et inconvénients
| Avantages | Inconvénients |
|---|---|
| Contournement anti-bot puissant à grande échelle | Code requis |
| Taux de réussite élevé revendiqué pour l’e-commerce | Pas de parsing — renvoie seulement HTML/JSON |
| Rendu JS, proxys premium, gestion des CAPTCHA | Pas d’interface visuelle |
| Bonne documentation et modèle API-first | L’enrichissement des sous-pages est entièrement manuel |
| Passe mieux à l’échelle que les outils desktop | Pas idéal pour une recherche vendeur ponctuelle |
Idéal pour : les équipes de développement qui construisent des pipelines de données Etsy à grande échelle et qui ont besoin d’une anti-détection robuste à forte concurrence.
Comparatif des meilleurs extracteurs Etsy : tableau côte à côte
This paragraph contains content that cannot be parsed and has been skipped.
Etsy affiche désormais , 5,6 millions de vendeurs actifs et 86,5 millions d’acheteurs actifs. C’est une place de marché immense et bruyante — et si vous êtes vendeur, marketeur ou chercheur e-commerce et que vous essayez de comprendre ce qui fonctionne dans votre niche, il vous faut des données structurées, pas un mur d’onglets ouverts. Le problème ? Les défenses anti-bot d’Etsy sont devenues redoutablement sophistiquées en 2026. Entre les structures de page dynamiques, le fingerprinting TLS, les CAPTCHA et l’analyse comportementale, l’époque où l’on pouvait écrire un petit script Python et considérer l’affaire réglée est pratiquement révolue.
J’ai passé les dernières semaines à tester six extracteurs Etsy face à face — des outils IA sans code aux API pour développeurs — et je vais vous montrer précisément ce qui a marché, ce qui n’a pas marché, et quel outil convient à quel type d’utilisateur. Je vais aussi aborder les données que vous pouvez réellement extraire (et celles que vous ne pouvez pas), le débat API Etsy contre scraping, des cas d’usage concrets et la manière de vérifier vos résultats pour éviter de prendre des décisions sur la base de mauvaises données.
Pourquoi extraire Etsy est plus difficile qu’on ne le pense
Si vous avez déjà essayé d’extraire Etsy et que vous vous êtes retrouvé bloqué, vous n’êtes pas seul. Etsy n’est pas un catalogue statique — c’est une place de marché dynamique et personnalisée. Les résultats de recherche, les annonces, les badges, les infos d’expédition et même les noms de classes CSS sur la page peuvent changer selon la session, l’appareil et le pays.
Voici, en résumé, ce qui rend Etsy délicat :
- Structure de page dynamique : le front-end d’Etsy change souvent. Des sélecteurs qui fonctionnaient hier peuvent renvoyer du vide aujourd’hui. C’est un peu comme si Etsy changeait les serrures de ses portes toutes les quelques heures — la page paraît toujours familière pour l’acheteur, mais les points d’accroche dont dépend un extracteur peuvent bouger sans prévenir.
- Systèmes de gestion des bots : des fournisseurs d’extracteurs comme indiquent publiquement qu’Etsy utilise une « protection anti-bot agressive » et que des sessions peuvent être bloquées. Certaines pages d’Actor mentionnent des schémas d’URL conçus pour contourner DataDome et l’imitation du fingerprint TLS de Chrome. Plus largement, a constaté que le trafic automatisé représentait 53 % de tout le trafic web en 2025, et que les bots constituaient 42,1 % du trafic web global — les sites e-commerce sont une cible de premier ordre.
- CAPTCHA et limitation de débit : un scraping à fort volume peut déclencher des CAPTCHA ou des blocages purs et simples. Le précise même que si un CAPTCHA apparaît, les utilisateurs peuvent mettre la tâche en pause et le résoudre manuellement.
- Résultats sponsorisés et personnalisation : les résultats de recherche Etsy mélangent des annonces organiques et payantes, et . Si vous ne suivez pas quels résultats sont des annonces, votre analyse concurrentielle peut être complètement faussée.
Rien de tout cela ne signifie qu’extraire Etsy est impossible. Cela signifie simplement que l’outil que vous choisissez compte beaucoup plus qu’avant.
Quelles données pouvez-vous réellement extraire d’Etsy ?
C’est la section que j’aimerais voir dans tous les articles concurrents — et que presque aucun n’inclut. Avant de choisir un outil, vous devez savoir ce qui est réellement possible.
Données accessibles depuis les résultats de recherche Etsy
Les pages de résultats vous offrent de la largeur. Voici ce que vous pouvez généralement extraire depuis la grille :
- Titre du produit
- Prix (actuel, promotion, prix d’origine quand il est visible)
- Devise
- URL de l’image principale
- URL de la fiche produit / ID de la fiche
- Nom de la boutique (quand visible — les annonces affichent parfois « Ad by Etsy Seller »)
- Note
- Nombre d’avis
- Badge de livraison gratuite
- Badges Bestseller / Etsy’s Pick / Star Seller
- Libellé sponsorisé / annonce
- Numéro de page et position
- Métadonnées de requête, filtre, tri et pays/session
L’, par exemple, expose des champs comme listingId, name, url, imageUrl, shop, shopId, price, originalPrice, currency, onSale, freeShipping, rating, availability, position, query, page et scrapedAt — une bonne validation de ce qui est réellement extrait de manière fiable.
Données qui nécessitent de visiter chaque fiche produit (scraping des sous-pages)
Les cartes de recherche sont volontairement compactes. Si vous faites une vraie analyse produit, vous avez besoin des champs cachés un clic plus loin :
- Description complète
- Galerie d’images complète et URL des vidéos
- Variantes et options de personnalisation
- Détails de l’article (matériaux, attributs, dimensions)
- Délai de traitement
- Détails d’expédition et estimations de livraison
- Détails du profil vendeur/boutique et politiques
- Extraits d’avis ou avis complets
- Articles associés
La confirme que les vendeurs saisissent le titre, la catégorie, les attributs, le prix, les variantes, la personnalisation, la description, le profil d’expédition, les détails de traitement/livraison et les dimensions/poids de l’article — ces champs existent donc, mais il faut visiter la page pour les récupérer.
C’est là que le scraping des sous-pages devient vraiment utile. Avec , par exemple, vous pouvez extraire une page de résultats Etsy pour récupérer les titres, prix et notes, puis cliquer sur « Scrape Subpages » pour que l’IA visite chaque fiche individuellement et enrichisse le tableau avec les tags, matériaux, détails d’expédition et infos vendeur — sans configuration supplémentaire. Le Field AI Prompt de Thunderbit vous permet aussi d’ajouter des instructions personnalisées par colonne (par exemple : « classer ce produit dans Bijoux / Déco / Vêtements »).
Ce que le scraping ne peut pas vous dire
Je préfère être transparent sur ce point, car c’est là que beaucoup d’outils perdent en crédibilité :
| Point de données | Disponible via le scraping ? | Remarques |
|---|---|---|
| Ventes réelles par fiche | Non | Etsy n’affiche pas publiquement les ventes exactes pour chaque fiche. Les ventes au niveau de la boutique peuvent être visibles, mais pas au niveau de la fiche. |
| Taux de conversion | Non | Réservé aux outils d’analyse du vendeur, pas public. |
| Vrai volume de recherche des mots-clés | Non | Etsy Marketplace Insights affiche des données sur 30 jours dans les outils vendeur, mais ce n’est pas un champ public à extraire. |
| Dépenses publicitaires / données d’enchère | Non | Non exposées comme données publiques des annonces. |
| Marge bénéficiaire | Non | Le prix et l’expédition sont visibles ; pas les coûts de production, les frais ni les retours. |
Tout outil affirmant connaître exactement les ventes Etsy des fiches concurrentes fait une estimation, pas l’extraction d’un fait public. Des outils comme , et décrivent ouvertement l’usage d’algorithmes d’estimation, et non un accès direct aux données.
API Etsy ou scraping : de quoi avez-vous vraiment besoin ?
C’est une question que je vois tout le temps sur les forums : « Puisque l’API Etsy ne fournit pas les données de mots-clés, j’imagine qu’ils font du scraping. » La confusion est réelle, alors voici un décryptage clair.
| Dimension | API officielle Etsy | Web Scraping |
|---|---|---|
| Meilleur cas d’usage | Gérer votre boutique, vos fiches, votre stock, vos commandes, vos paiements | Recherche concurrentielle, suivi des recherches, intelligence prix, enrichissement des sous-pages |
| Fiches | Recherche de fiches actives et points de détail | Toute page publique de recherche / fiche / boutique / avis |
| Ventes/commandes de votre boutique | Oui, avec autorisation/scopes | Inutile ; utilisez l’API / Shop Manager |
| Ventes exactes des concurrents | Non | Non (estimations uniquement) |
| Volume de recherche des mots-clés | Non exposé comme point de terminaison Open API public | Pas directement ; Marketplace Insights est dans l’interface vendeur |
| Limites de débit | QPS/QPD spécifiques à l’application ; gestion des 429 | Dépend de l’outil / de la plateforme |
| Position vis-à-vis des CGU | Voie officielle lorsqu’elle est utilisée dans les règles | Les conditions Etsy limitent le scraping sans autorisation |
| Sortie | Réponses JSON de l’API | CSV/Sheets/JSON/HTML selon l’outil |
En bref : si vous devez gérer votre propre boutique, utilisez l’API. Si vous devez comprendre vos concurrents, surveiller les prix ou étudier une niche, le scraping est la voie la plus pratique. Des outils comme eRank et Alura combinent probablement l’accès API, le scraping et l’estimation — vous savez maintenant pourquoi.
Sans code ou avec code : comment choisir le meilleur extracteur Etsy
La plupart des personnes qui cherchent les « meilleurs extracteurs Etsy » ne sont pas des développeurs en train de bâtir une infrastructure. Ce sont des vendeurs, des marketeurs, des assistants virtuels ou des chercheurs e-commerce qui veulent un tableau exploitable. Pourtant, la plupart des articles concurrents se concentrent sur des outils API ou des bibliothèques Python. Il y a un décalage.
Voici mon cadre de décision :
| Si vous êtes... | Choisissez... | Pourquoi |
|---|---|---|
| Vendeur ou marketeur non technique | Thunderbit | Suggestions de champs IA, extension Chrome, scraping des sous-pages, export direct, scraping programmé |
| Non technique mais adepte des workflows visuels | Octoparse | Constructeur de workflows visuel pour desktop, modèles, détection automatique, mode cloud |
| Freelance ou petite agence gérant des missions Etsy récurrentes | Apify | Actors cloud, planificateur, API, options au résultat |
| Développeur construisant un pipeline interne | ScrapingBee ou ZenRows | Transport par API, rendu JS, gestion des proxys/CAPTCHA ; vous contrôlez le parsing et le stockage |
| Équipe data en entreprise | Bright Data | API/dataset de scraping managés, options de livraison, disponibilité et posture de conformité |
Pour ce public, « sans code » signifie : pas de configuration de proxy, pas de sélecteurs CSS, pas de commandes terminal, pas de gestion de navigateur headless, pas de logique de réessai personnalisée, pas de base de données à configurer. Vous exportez directement vers un tableur ou une application de travail, et l’enrichissement des sous-pages ne vous oblige pas à construire des boucles de clics.
Comment j’ai évalué ces 6 extracteurs Etsy
J’ai testé chaque outil sur le même ensemble de tâches : une requête Etsy (« personalized pet portrait »), une requête produit très concurrentielle (« gold huggie earrings »), une URL de boutique avec de nombreuses fiches, dix pages de détail de fiche pour l’enrichissement des sous-pages, une tâche de suivi hebdomadaire de prix programmée, et un export vers Google Sheets ou CSV.
Voici les critères que j’ai notés :
| Critère | Pourquoi c’est important |
|---|---|
| Facilité d’utilisation (sans code vs avec code) | Les vendeurs Etsy ne devraient pas devoir devenir ingénieurs en scraping |
| Gestion anti-bot/CAPTCHA | Un outil qui fonctionne sur 10 lignes mais échoue à la page 2 n’est pas utile |
| Champs de données extractibles | Les champs des résultats de recherche ne suffisent pas pour une vraie recherche produit |
| Options d’export (CSV, JSON, Sheets, Airtable) | Le vrai workflow se termine généralement dans Sheets, Airtable, Notion, CSV, JSON ou des outils BI |
| Transparence des prix (niveau gratuit + coût par 1K enregistrements) | Le coût par ligne exploitable compte plus que le prix mensuel affiché |
| Enrichissement des sous-pages | Tags, descriptions, expédition, matériaux, variantes et avis se trouvent un clic plus loin |
1. Thunderbit
est l’outil que nous avons créé chez Thunderbit, spécialement pour les utilisateurs non techniques qui ont besoin rapidement de données web structurées. C’est une propulsée par l’IA — vous ouvrez une page Etsy, cliquez sur « AI Suggest Fields », et l’IA lit la structure de la page et propose des colonnes comme titre, prix, avis, vendeur, URL, image, badge et expédition. Ensuite, vous cliquez sur « Scrape » et obtenez un tableau. C’est tout.
Ce qui rend Thunderbit particulièrement utile pour la recherche Etsy, c’est la fonction de scraping des sous-pages. Après avoir extrait une page de résultats, vous pouvez cliquer sur « Scrape Subpages » et l’IA de Thunderbit visite chaque fiche individuelle pour enrichir votre tableau avec les descriptions complètes, détails d’expédition, matériaux, tags et infos vendeur — sans configuration supplémentaire. J’ai utilisé ce flux pour passer d’une requête de recherche à un tableur d’analyse concurrentielle complet en moins de dix minutes.
Fonctionnalités clés
- AI Suggest Fields : l’IA lit la page Etsy et recommande des colonnes. Pas de sélecteurs, pas de devinettes.
- Scraping en 2 clics : idéal pour la recherche produit ponctuelle.
- Scraping des sous-pages : enrichissez les résultats de recherche avec les détails complets des fiches en un clic.
- Scraping programmé : mettez en place un suivi hebdomadaire des prix concurrents en décrivant simplement l’intervalle.
- Field AI Prompt : ajoutez des instructions personnalisées par colonne (par exemple : « classer dans Bijoux / Déco / Vêtements » ou « indiquer si cette fiche semble personnalisée »).
- Exports : Excel, Google Sheets, Airtable, Notion, CSV, JSON — .
- Mode cloud et mode navigateur : mode cloud pour des tâches publiques plus rapides ; mode navigateur pour les pages où votre session/rendu actuel compte (plus précis pour les champs dynamiques comme les favoris).
- API ouverte : le accepte une URL + un schéma JSON et prend en charge jusqu’à 100 URL par requête.
Comment Thunderbit extrait Etsy en 2 clics
- Accédez à une page de résultats Etsy (par exemple, recherchez « personalized pet portrait »).
- Cliquez sur AI Suggest Fields — l’IA propose des colonnes comme titre, prix, avis, vendeur, URL, image, badges.
- Cliquez sur Scrape — les données s’affichent dans un tableau.
- En option, cliquez sur Scrape Subpages dans la colonne URL de la fiche pour enrichir les lignes avec la description complète, les détails d’expédition, les matériaux ou les avis.
- Exportez vers Google Sheets, Airtable, Notion, Excel, CSV ou JSON.
Vous pouvez aussi consulter notre pour des tutoriels vidéo.
Tarifs
Thunderbit fonctionne avec un système de crédits. Il existe un niveau d’essai / gratuit, et le plan Starter coûte environ 15 $/mois pour 500 crédits (ou 108 $/an pour 5 000 crédits annuels). Le scraping des sous-pages peut consommer davantage de crédits, car chaque ligne/page enrichie compte séparément. Voir pour les informations à jour.
Avantages et inconvénients
| Avantages | Inconvénients |
|---|---|
| Aucun code, aucune configuration de sélecteur | Système à crédits ; les très gros volumes nécessitent un plan payant |
| La détection IA des champs réduit la maintenance liée aux changements de page | L’extension Chrome nécessite une installation dans le navigateur |
| L’enrichissement des sous-pages est intégré | N’est pas positionné comme fournisseur de datasets à l’échelle entreprise |
| Le scraping programmé et l’auto-export soutiennent les workflows de surveillance | La précision doit toujours être vérifiée ponctuellement (vrai pour tous les outils) |
| Fonctionne au-delà d’Etsy — utile pour la recherche e-commerce générale | Certains champs restent indisponibles car Etsy ne les expose pas |
Idéal pour : les vendeurs Etsy qui font de la recherche produit, les marketeurs qui construisent des rapports concurrents, les équipes ops qui surveillent les prix.
2. Apify Etsy Scraper
est une plateforme d’automatisation cloud avec une place de marché d’« Actors » — des extracteurs prêts à l’emploi que vous pouvez exécuter sans gérer votre propre infrastructure. Pour Etsy, plusieurs Actors sont disponibles, notamment le et le .
L’Actor Automation Lab prend en charge la recherche par mot-clé, le filtrage par catégorie, la pagination (jusqu’à 5 000 produits par exécution) et une sortie structurée avec des champs comme l’ID de fiche, le titre, l’URL, l’URL de l’image, la boutique, le prix, le prix d’origine, la devise, le statut promo, la livraison gratuite, la note, la disponibilité, la position, la requête, la page et l’horodatage d’extraction. C’est un ensemble solide pour des données au niveau des résultats de recherche.
Fonctionnalités clés
- Hébergé dans le cloud (aucune ressource locale nécessaire)
- Recherche par mot-clé, catégorie et scraping d’URL de boutique
- Gestion de la pagination
- Export JSON, CSV, Excel
- Intégration de proxy (proxies résidentiels disponibles en supplément)
- Planificateur pour tâches récurrentes
- Accès API pour l’intégration de pipelines
Tarifs
L’ facture à l’exécution plus à l’utilisation par produit : environ 0,80 $ à 3,45 $ par 1K produits selon votre plan Apify. Les plans de la plateforme commencent à environ 9 $/mois (Starter) plus l’usage des actors. Le plan gratuit inclut 5 $/mois d’utilisation plateforme.
Avantages et inconvénients
| Avantages | Inconvénients |
|---|---|
| Actors Etsy prêts à l’emploi | La qualité varie selon le mainteneur |
| Exécution cloud, planificateur, API, webhooks | Les Actors communautaires peuvent prendre du retard quand Etsy change la mise en page |
| Tarification transparente au résultat sur certains Actors | Les coûts des proxys augmentent à grande échelle |
| Export JSON/CSV/Excel via le dataset Apify | L’enrichissement personnalisé des sous-pages peut nécessiter de la configuration |
| Adapté aux pipelines de données récurrents | Low-code, moins simple qu’une extension de navigateur pour les vendeurs |
Idéal pour : les freelances, petites agences et utilisateurs semi-techniques qui veulent un pipeline de données Etsy prêt à l’emploi.
3. Bright Data
est l’option entreprise. Si vous êtes une grande société e-commerce ou une équipe data qui extrait des milliers de fiches Etsy chaque jour, cet outil est conçu pour vous. Bright Data propose une et un avec plus de 18 millions d’enregistrements et 59 champs.
Leur infrastructure est massive — plus de 100 millions d’IP résidentielles, gestion anti-bot complète (proxies résidentiels, résolution de CAPTCHA, fingerprinting de navigateur), sortie JSON structurée et approche orientée conformité. Ils proposent aussi une option Data Collector sans code pour les utilisateurs qui ne veulent pas toucher au code.
Fonctionnalités clés
- Collecteur de données Etsy préconstruit (option tableau de bord sans code)
- Gestion anti-bot complète
- Sortie JSON structurée avec plus de 59 champs
- Livraison gérée, webhooks et intégrations de stockage cloud
- SLA entreprise, outils de conformité, garanties de disponibilité
- Dataset Etsy prêt à l’emploi pour l’analyse en masse
Tarifs
L’API Etsy Scraper de Bright Data démarre à environ en pay-as-you-go. Le dataset Etsy a un minimum de 50 $. Pas de niveau gratuit, mais la page de l’API Scraper annonce 1K requêtes d’essai. Le plan Scale est à 499 $/mois. C’est un tarif premium — ce n’est pas pour quelqu’un qui extrait 50 fiches un samedi après-midi.
Avantages et inconvénients
| Avantages | Inconvénients |
|---|---|
| Plateforme la plus fiable et la plus stable | Surdimensionné pour une recherche ponctuelle de vendeur |
| Contournement anti-bot parmi les meilleurs du secteur | Prix premium (barrière pour les petites entreprises) |
| Option Data Collector sans code | Trop de fonctionnalités pour des tâches simples |
| Outils de conformité stricts | Aucun niveau gratuit |
| Échelle massive | La personnalisation des sous-pages peut nécessiter du travail API/configuration |
Idéal pour : les grandes entreprises e-commerce, les équipes data et les organisations ayant besoin de disponibilité garantie, de conformité juridique et d’échelle.
4. Octoparse
est une application de bureau avec une interface visuelle point-and-click pour créer des workflows de scraping. Si vous aimez voir exactement ce que fait votre extracteur — cliquer, faire défiler, paginer — c’est l’outil qu’il vous faut.
Octoparse propose un capable d’extraire, à partir d’un mot-clé, le nom du produit, le vendeur, la note, le nombre d’avis, le prix, l’URL et l’URL de l’image. Leur explique comment extraire les informations produit Etsy, y compris la détection automatique des données de la page et la création de workflows avec pagination et défilement.
Fonctionnalités clés
- Constructeur de workflows visuel (glisser-déposer)
- Rotation d’IP intégrée
- Gestion des CAPTCHA via intégrations tierces (option de résolution manuelle indiquée dans le modèle Etsy)
- Support du défilement infini et de la pagination
- Option d’exécution cloud
- Exports : CSV, Excel, JSON, connexions base de données, Google Sheets (sur les plans payants)
Tarifs
Plan gratuit avec extraction locale et limites de lignes. Le plan Standard est d’environ en annuel. Les offres payantes ajoutent les fonctionnalités cloud, davantage d’options d’export et des limites de lignes plus élevées.
Avantages et inconvénients
| Avantages | Inconvénients |
|---|---|
| Vraie interface visuelle sans code | L’application de bureau est gourmande en ressources |
| Un modèle Etsy et un tutoriel existent | Le scraping complexe des sous-pages nécessite une configuration manuelle du workflow |
| Gère la pagination et le défilement infini | Le CAPTCHA peut exiger une résolution manuelle dans certains cas |
| Exports CSV, Excel, JSON, bases de données | Plus lent que les solutions basées sur API à grande échelle |
| Bon parcours d’apprentissage pour le scraping sans code | Plus de friction de configuration que les outils de suggestion de champs IA |
Idéal pour : les chercheurs marché et analystes business non techniques qui préfèrent une interface visuelle et veulent personnaliser leurs workflows d’extraction sans code.
5. ScrapingBee
est une API pensée pour les développeurs. Vous lui envoyez une URL, elle renvoie le HTML rendu (ou du JSON extrait si vous configurez des règles d’extraction). Il n’existe pas de parseur Etsy prêt à l’emploi qui vous donne directement un tableur — vous écrivez votre propre logique d’extraction en Python, JavaScript ou dans le langage de votre choix.
La indique que les champs extractibles peuvent inclure le nom du produit, les catégories, le prix, le statut de stock, les informations d’expédition et la taille à l’aide de règles d’extraction au format JSON. Elle souligne aussi que le scraping Etsy doit tenir compte des proxys premium, de la gestion du rythme des requêtes et des risques liés aux conditions d’utilisation.
Fonctionnalités clés
- Rendu JavaScript
- Rotation automatique des proxys
- Gestion des CAPTCHA
- API REST simple
- Compatible Python/Node.js/quel que soit le langage
- Retourne du HTML brut ou du JSON ; l’utilisateur effectue le parsing et l’export
Tarifs
1 000 crédits API gratuits pour commencer. Le inclut 250K crédits et 10 requêtes simultanées. Startup à 99 $/mois pour 1M de crédits. Business à 249 $/mois pour 3M de crédits.
Avantages et inconvénients
| Avantages | Inconvénients |
|---|---|
| Intégration API simple | Code requis (Python/JS) |
| Rendu JavaScript et options de proxy | Renvoie du HTML brut (pas de parsing automatique de tous les champs) |
| Fonctionne avec n’importe quel langage | Pas d’interface visuelle |
| Bon pour les pipelines de données personnalisés | L’enrichissement des sous-pages nécessite un script personnalisé |
| Plus flexible que les outils visuels | L’export, le stockage et la planification sont de votre responsabilité |
Idéal pour : les développeurs Python/JS qui construisent des outils internes propriétaires et qui ont besoin d’une « couche de transport » fiable pour récupérer le HTML d’Etsy sans blocage.
6. ZenRows
est une autre API pour développeurs, similaire à ScrapingBee mais avec une emphase plus forte sur le contournement anti-bot à grande échelle. Elle gère automatiquement les CAPTCHA, le fingerprinting et les proxys résidentiels.
La liste des champs comme la remise, l’URL, le nom du vendeur, la description, la note, le nom du produit, le prix, la disponibilité, la catégorie, l’image, les avis et la devise. Elle revendique un taux de réussite de 99,93 % et des fonctionnalités comme l’anti-CAPTCHA, les proxys premium, le mode furtif, l’extraction intelligente et le rendu JavaScript.
Fonctionnalités clés
- Contournement anti-bot (proxys premium, navigateurs headless)
- En-têtes à rotation automatique
- Rendu JavaScript
- Appels API simples
- Support de forte concurrence
Tarifs
Essai gratuit de 14 jours avec 1 000 résultats de base et 40 résultats protégés. Le inclut 250K résultats de base / 10K résultats protégés. Les requêtes protégées (pour les sites avec anti-bot) coûtent plus cher par requête.
Avantages et inconvénients
| Avantages | Inconvénients | |---|---|---| | Contournement anti-bot puissant à grande échelle | Code requis | | Taux de réussite élevé revendiqué pour l’e-commerce | Pas de parsing — renvoie seulement HTML/JSON | | Rendu JS, proxys premium, gestion des CAPTCHA | Pas d’interface visuelle | | Bonne documentation et modèle API-first | L’enrichissement des sous-pages est entièrement manuel | | Passe mieux à l’échelle que les outils desktop | Pas idéal pour une recherche vendeur ponctuelle |
Idéal pour : les équipes de développement qui construisent des pipelines de données Etsy à grande échelle et qui ont besoin d’une anti-détection robuste à forte concurrence.
Comparatif des meilleurs extracteurs Etsy : tableau côte à côte
| Outil | Sans code ? | Gestion anti-bot | Niveau gratuit / essai | Formats d’export | Scraping des sous-pages | Coût approx. par 1K | Idéal pour |
|---|---|---|---|---|---|---|---|
| Thunderbit | ✅ Oui (ext. Chrome) | Modes cloud + navigateur ; l’IA adapte les champs | ✅ Niveau gratuit / essai | Excel, Sheets, Airtable, Notion, CSV, JSON | ✅ Intégré | ~9,60 $–30 $/1K lignes (selon le plan) | Vendeurs et marketeurs non techniques |
| Apify Etsy Scraper | ⚠️ Low-code | Dépend de l’Actor ; retries proxy/session | ✅ 5 $/mois de plateforme gratuits | JSON, CSV, Excel, API/webhooks | ⚠️ Nécessite une config | ~0,80 $–3,45 $/1K produits | Pipelines de données Etsy dédiés |
| Bright Data | ⚠️ Tableau de bord + API | ✅ Complet (proxies résidentiels, CAPTCHA) | ❌ Non (1K requêtes d’essai) | JSON, NDJSON, CSV, livraison cloud | ⚠️ Nécessite une configuration | ~2,50 $/1K enregistrements PAYG | Extraction à l’échelle entreprise |
| Octoparse | ✅ Oui (application desktop) | Rotation intégrée ; option CAPTCHA manuelle | ✅ Plan gratuit (limité) | CSV, Excel, JSON, BD, Sheets (payant) | ⚠️ Basé sur workflow | SaaS forfaitaire (à partir d’environ 69 $/mois) | Constructeurs de workflows visuels |
| ScrapingBee | ❌ Code (API) | ✅ Proxy + rendu JS | ✅ 1K crédits | JSON, HTML brut | ❌ Manuel | ~4,90 $/1K (estimation Freelance) | Développeurs Python/JS |
| ZenRows | ❌ Code (API) | ✅ Contournement anti-bot, proxys premium | ✅ Essai de 14 jours | JSON, HTML | ❌ Manuel | ~7 $/1K protégés | Équipes dev qui ont besoin d’échelle |
Aucun outil ne gagne partout. Le meilleur extracteur Etsy dépend de votre niveau technique, de votre budget et de vos besoins en volume. Pour les vendeurs, 500 lignes exactes dans Google Sheets avec le titre, le prix, les avis, le vendeur, le drapeau annonce et l’expédition sont plus utiles que 5 000 pages HTML brutes bon marché.
Comment vérifier la précision de votre extracteur Etsy (ne sautez pas cette étape)
Je veux aborder quelque chose qui revient sans cesse dans les forums de vendeurs Etsy : le scepticisme vis-à-vis de la précision des données. Un utilisateur Reddit a indiqué qu’EverBee affichait 0 vente pour un autocollant qui s’était en réalité vendu à environ 40 exemplaires en deux mois. Un autre a dit que les chiffres d’EverBee, Alura et eRank étaient « totalement erronés » pour sa propre boutique connectée. Ce n’est pas propre à ces outils — n’importe quel extracteur peut renvoyer des données obsolètes ou inexactes si vous ne vérifiez pas.
Voici la méthode de vérification ponctuelle que j’utilise :
- Extrayez d’abord un petit échantillon — 20 à 50 lignes.
- Ouvrez manuellement 3 à 5 fiches de l’échantillon.
- Vérifiez le titre, le prix, la devise, le nombre d’avis, la note, la livraison gratuite, le nom du vendeur et l’URL de la fiche par rapport à la page Etsy en direct.
- Vérifiez si les lignes sponsorisées / annonces sont correctement étiquetées ou séparées.
- Relancez la même extraction après 24 heures et comparez les changements de prix / d’avis.
- Ajoutez des colonnes de métadonnées à votre export : scraped_at, source_url, query, page, position, country, tool, run_id.
La fraîcheur compte. Les outils qui extraient en temps réel (comme le mode de scraping navigateur de Thunderbit, qui accède à la page dans votre navigateur déjà connecté) renvoient généralement des résultats plus actuels que les jobs batch dont l’ancienneté du cache est inconnue. Les exigent d’ailleurs que les utilisateurs de l’API ne présentent pas de contenu de fiche datant de plus de 6 heures par rapport aux informations correspondantes du site Etsy — un bon repère sur la rapidité avec laquelle les données Etsy peuvent devenir obsolètes.
Et une fois encore pour celles et ceux au fond de la salle : tout outil prétendant connaître exactement les ventes par fiche fait une estimation, pas l’extraction d’un fait public. Méfiez-vous des promesses de précision.
Cas d’usage concrets : choisir le meilleur extracteur Etsy pour votre besoin
« Qu’est-ce qui se vend dans ma niche ? » — Recherche concurrentielle produit
Un vendeur veut voir les meilleures fiches pour « personalized pet portrait » — fourchette de prix, nombre d’avis, badges bestseller, livraison gratuite, noms de boutiques et URLs de fiches.
Meilleur choix : Thunderbit (scraping en 2 clics des résultats de recherche, l’IA suggère toutes les colonnes pertinentes, export vers Google Sheets pour l’analyse) ou Apify (configurer un Actor récurrent pour la même requête chaque semaine).
Astuce : incluez le drapeau annonce / sponsorisé et la position. , donc les données de la première page ne sont pas purement organiques.
« Suivre les prix des concurrents chaque semaine » — Suivi des prix
Un propriétaire de boutique suit 50 fiches concurrentes pour observer les variations de prix dans le temps.
Meilleur choix : le Scheduled Scraper de Thunderbit (décrivez l’intervalle en langage courant, entrez les URL, c’est fait) ou Bright Data (pour un suivi à l’échelle entreprise sur des milliers de SKU). Apify fonctionne aussi très bien pour des jobs cloud récurrents à moindre coût.
Astuce : suivez toujours scraped_at, la devise, le pays et le fait que la fiche soit en promotion. Un prix sans horodatage ni localisation reste une preuve faible.
« Construire un catalogue produit pour ma boutique » — Extraction de données en masse
Extraire plus de 500 fiches avec images, titres, prix, descriptions et matériaux.
Meilleur choix : Thunderbit (le scraping des sous-pages enrichit chaque fiche, l’extraction d’images exporte vers Airtable/Notion) ou Octoparse (workflow visuel pour l’extraction en masse). Apify convient si la sortie JSON et l’exécution cloud comptent plus que le workflow visuel.
Astuce : ne réutilisez pas des descriptions ou images protégées sans autorisation. Utilisez le contenu créatif extrait pour l’analyse, pas pour le copier.
« Je construis un pipeline de données Etsy » — Cas d’usage développeur
Un développeur a besoin de JSON structuré brut à grande échelle avec gestion anti-bot, schéma personnalisé, journaux de réessai et pipeline vers un entrepôt de données.
Meilleur choix : ScrapingBee ou ZenRows comme couches d’accès / rendu API. Apify si l’écosystème d’Actors et les datasets managés sont préférés. L’ de Thunderbit si l’extraction via JSON Schema et jusqu’à 100 URL par lot s’intègre au pipeline.
Astuce : séparez le crawl, le parsing, la validation, le stockage et le reporting. L’outil qui récupère le HTML n’est qu’une partie du pipeline.
Une note sur les fiches sponsorisées
Les utilisateurs des forums se plaignent régulièrement qu’une énorme part des meilleurs résultats Etsy ne sont que des annonces sponsorisées. Un utilisateur Reddit discutant de filtres uBlock expliquait voir à répétition des résultats « Ad by Etsy Seller ». Un autre vendeur disait voir le même article à la fois comme annonce et comme résultat organique.
Conseils de scraping pratiques :
- Capturer is_sponsored quand c’est visible
- Séparer les positions payantes des positions organiques
- Extraire au-delà de la page 1
- Dédupliquer par ID de fiche / URL canonique, pas par titre (les annonces et les résultats organiques peuvent se chevaucher)
- Lancer une recherche propre déconnectée et une recherche connectée / en session navigateur si votre question de recherche dépend de la personnalisation
Considérations juridiques et éthiques pour extraire Etsy
Je vais faire court. Les indiquent que les utilisateurs ne peuvent pas crawler, scraper ou spider les pages sans autorisation expresse. Les interdisent également l’usage de systèmes automatisés pour accéder, analyser ou scraper le site / l’API / les données Etsy, sauf autorisation explicite.
La jurisprudence américaine est nuancée. Des affaires comme sont favorables à certaines théories de scraping de données publiques, mais elles n’effacent pas les risques liés au contrat, au droit d’auteur, à la vie privée ou à l’application des règles de plateforme. Bright Data a été impliqué dans sur ces sujets.
Mon conseil : utilisez l’API officielle d’Etsy lorsque votre cas d’usage est couvert, ne collectez que des données publiques et nécessaires, évitez les données personnelles / privées, respectez les limites de débit et les contrôles d’accès, et ne republiez pas de photos ou descriptions protégées par le droit d’auteur sans autorisation. Ceci n’est pas un avis juridique — consultez un professionnel pour des situations spécifiques.
Conclusion : quel extracteur Etsy vous convient le mieux ?
Après avoir testé les six, mon avis honnête est que le « meilleur » extracteur Etsy dépend entièrement de qui vous êtes et de ce dont vous avez besoin :
- Vendeurs et marketeurs non techniques : Thunderbit. Deux clics, alimenté par l’IA, enrichissement des sous-pages, exports directs vers Sheets/Airtable/Notion. Commencez par le et voyez jusqu’où il vous mène.
- Pipelines de données Etsy dédiés : Apify. Actors cloud, planificateur, API, tarification transparente au résultat.
- Échelle entreprise : Bright Data. Infrastructure managée, conformité, SLA, vaste pool de proxys.
- Préférence pour les workflows visuels : Octoparse. Constructeur desktop point-and-click avec modèles.
- Développeurs : ScrapingBee ou ZenRows. Transport API, rendu JS, anti-bot — vous construisez le reste.
Mon dernier conseil : commencez avec un niveau gratuit ou un essai, faites une vérification ponctuelle de la précision, puis montez en puissance seulement après avoir validé la qualité des données. Ne souscrivez pas à un plan payant avant d’avoir confirmé que l’outil renvoie bien les champs dont vous avez besoin, dans le format souhaité, avec la fraîcheur attendue.
Et que vos données Etsy restent toujours propres, structurées et sans fiches sponsorisées surprise.
FAQ
Quel est le meilleur extracteur Etsy pour les utilisateurs non techniques ?
Thunderbit est le meilleur choix pour les vendeurs et marketeurs non techniques. C’est une extension Chrome où vous cliquez sur « AI Suggest Fields » sur n’importe quelle page Etsy, vous vérifiez les colonnes suggérées, vous cliquez sur « Scrape », puis vous exportez vers Google Sheets, Airtable, Notion ou Excel. Le scraping des sous-pages et le scraping programmé sont intégrés. Octoparse est aussi une bonne option si vous préférez un constructeur de workflows visuel sur desktop.
Est-il légal d’extraire des données produit Etsy ?
L’extraction de données web publiquement disponibles bénéficie d’une jurisprudence américaine favorable dans certains contextes (par exemple hiQ v. LinkedIn), mais les conditions d’utilisation et les conditions API d’Etsy limitent le crawling, le scraping et l’accès automatisé sans autorisation. Pour un usage commercial, il est prudent de consulter un professionnel du droit, d’utiliser l’API officielle lorsque c’est possible et d’éviter de copier du contenu protégé comme les photos ou descriptions de produits.
Quelles données peut-on extraire d’Etsy avec un extracteur ?
Depuis les résultats de recherche : titres, prix, images, URLs des fiches, noms des vendeurs/boutiques, notes, nombre d’avis, badges (bestseller, livraison gratuite, Star Seller) et libellés sponsorisés / annonces. Depuis les pages de fiche individuelles (via le scraping des sous-pages) : descriptions complètes, matériaux, attributs, détails d’expédition, variantes, politiques du vendeur et avis. Les ventes réelles par fiche, les taux de conversion et le vrai volume de recherche des mots-clés ne sont pas directement disponibles via le scraping — tout outil qui les affiche fait une estimation.
Puis-je extraire Etsy sans être bloqué ?
Oui, avec le bon outil. Etsy utilise des contrôles anti-bot, notamment des structures de page dynamiques, le fingerprinting TLS, les CAPTCHA et la limitation de débit. Des outils comme Thunderbit (modes de scraping cloud et navigateur), Bright Data (infrastructure de proxy d’entreprise), ScrapingBee (rendu JS et proxys premium) et ZenRows (API anti-bot) gèrent automatiquement ces mécanismes. Pour des recherches à petite échelle, le mode navigateur de Thunderbit — qui utilise votre propre session connectée — est généralement fiable et renvoie des données à jour.
Combien coûte un extracteur Etsy ?
Des niveaux gratuits ou des essais sont disponibles chez Thunderbit, Apify, Octoparse, ScrapingBee et ZenRows. Bright Data propose des requêtes d’essai mais pas de niveau gratuit permanent. Les plans payants commencent généralement entre 49 $ et 69 $/mois pour les outils pour développeurs / sans code. Les API Etsy spécifiques au résultat vont d’environ 0,80 $ à 3,45 $ par 1K enregistrements (Apify) à 2,50 $/1K (Bright Data PAYG). Le modèle à crédits de Thunderbit commence à environ 15 $/mois. Le coût réel dépend du nombre de lignes dont vous avez besoin, de l’usage ou non de l’enrichissement des sous-pages et de la fréquence d’extraction.
En savoir plus