
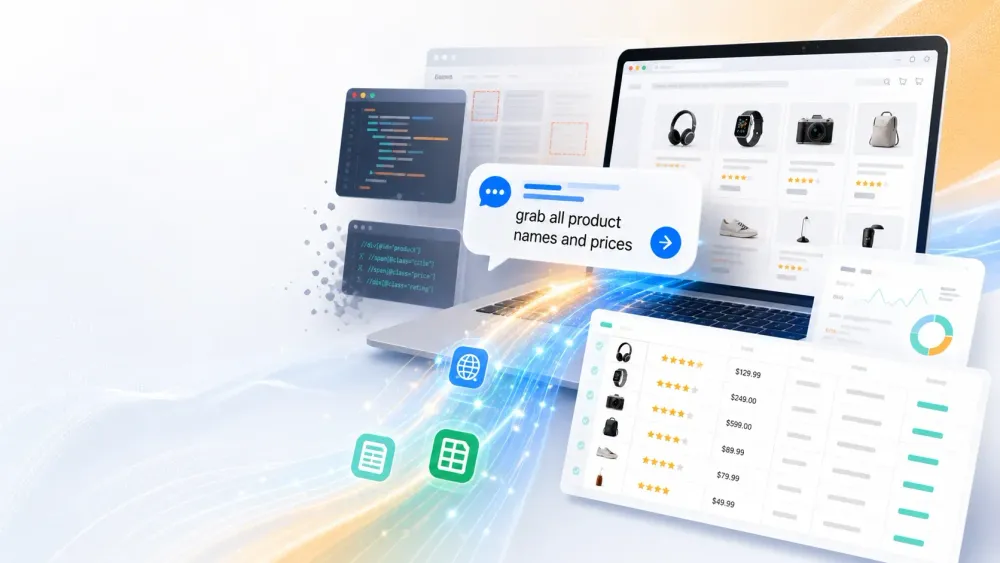
En 2015, scraper un site supposait de supplier un développeur de vous pondre un script Python, ou de sacrifier un week-end à l'apprentissage de XPath. En 2026, vous tapez « récupère tous les noms et prix des produits » et une IA s'occupe du reste.
La bascule a été fulgurante. Plus de 2 millions d'entreprises s'appuient désormais sur le scraping web. Le marché a franchi la barre du milliard de dollars en 2024 (environ 900 millions d'euros) et devrait doubler d'ici 2030.
Le moteur principal ? Les AI web crawlers. Ils s'adaptent aux changements de mise en page. Ils comprennent le contenu des pages, pas seulement les balises HTML. Et ils fonctionnent pour des personnes qui n'ont jamais écrit la moindre ligne de code.
J'en ai testé 15 pendant des mois. Voici ce que j'en ai retenu — y compris les raisons pour lesquelles Thunderbit (oui, l'entreprise que j'ai cofondée) décroche la première place.
Pourquoi l'IA transforme l'extraction de pages web : la nouvelle ère des outils d'Extracteur Web
Extraire des données de n'importe quel site web grâce à l'IA Get Started Free
Reconnaissons-le : le scraping web traditionnel n'a jamais été conçu pour l'utilisateur métier moyen. Tout reposait sur le code, les sélecteurs, et l'espoir que votre script tienne encore debout au prochain changement de mise en page. L'IA et les LLM ont complètement rebattu les cartes.
Voici pourquoi :
- Instructions en langage naturel : au lieu de vous battre avec du code, vous dites simplement à l'IA ce que vous voulez. Des outils comme Thunderbit interprètent vos consignes en anglais simple et configurent l'extraction pour vous (source).
- Apprentissage adaptatif : les extracteurs IA peuvent s'adapter aux changements de mise en page des sites web, ce qui réduit les problèmes de maintenance.
- Gestion du contenu dynamique : les sites modernes adorent JavaScript et le défilement infini. Les outils propulsés par l'IA interagissent avec ces éléments et capturent des données que les anciens extracteurs manqueraient.
- Sortie structurée grâce à l'analyse IA : les extracteurs basés sur les LLM comprennent réellement le contenu des pages et produisent des données propres et structurées.
- Évitement automatique des anti-bots : les extracteurs IA peuvent contourner les protections anti-scraping et utiliser des proxys/navigateurs sans interface pour éviter les blocages IP.
- Flux de travail de données intégrés : les meilleurs outils ne se contentent pas de récupérer des données — ils les envoient là où vous en avez besoin, avec des exportations en un clic vers Google Sheets, Airtable, Notion, et plus encore (source).
Le résultat ? Le web scraping est devenu une expérience de type cliquer-et-obtenir, presque conversationnelle, qui permet aux équipes commerciales, marketing et opérations — et plus seulement aux développeurs — d'exploiter directement les données du web.
15 AI Web Crawlers qui méritent votre attention en 2026
Passons en revue les 15 meilleurs AI web crawlers, à commencer par Thunderbit. Pour chaque outil, je vous présente les fonctionnalités clés, le public cible, le prix et ce qui le distingue. Et oui, je serai honnête sur ses forces comme sur ses faiblesses.
1. Thunderbit : l'Extracteur Web IA pour tout le monde
Mon parti pris est évident ici, mais Thunderbit est l'Extracteur Web IA dont j'aurais rêvé il y a des années. Voici pourquoi il prend la tête de cette liste :
- Extraction en langage naturel : vous discutez avec Thunderbit. Décrivez simplement les données voulues — « extraire tous les noms et prix des produits de cette page » — et l'IA fait le reste (source). Aucun code, aucun sélecteur, aucun casse-tête.
- Crawling des sous-pages et multi-niveaux : Thunderbit peut suivre les liens et extraire les sous-pages. Par exemple, récupérez une liste de produits, puis ouvrez chaque fiche pour obtenir les détails, le tout en une seule fois.
- Sortie structurée instantanée : l'IA formate et nettoie les données à la volée, suggère des champs pertinents, normalise les formats et peut même résumer ou catégoriser le texte.
- Large compatibilité avec les sources : Thunderbit ne se limite pas au HTML — il extrait aussi des données à partir de PDF et d'images grâce à l'OCR intégré et à la vision IA (source).
- Intégrations métier : export en un clic vers Google Sheets, Airtable, Notion ou Excel (source). Planifiez des extractions et injectez les données directement dans le flux de travail de votre équipe.
- Modèles prêts à l'emploi : pour des sites comme Amazon, LinkedIn, Zillow, etc., Thunderbit propose des « recettes » d'extraction préconçues pour une extraction en un clic.
- Simple et accessible : l'interface fonctionne en point-and-click, avec un assistant intuitif. Les utilisateurs disent être opérationnels en quelques minutes.

Thunderbit est utilisé par plus de 30 000 utilisateurs dans le monde, notamment des équipes chez Accenture, Grammarly et Puma. Les équipes commerciales s'en servent pour constituer des listes de prospects, les agents immobiliers agrègent des annonces, et les marketeurs surveillent les concurrents — sans écrire une seule ligne de code.
Tarifs : il existe une offre gratuite (jusqu'à 100 étapes par mois), avec des formules payantes à partir de 14,99 $/mois (environ 14 €/mois). Même les offres pro restent abordables pour les particuliers et les petites équipes.
Thunderbit est ce qui se rapproche le plus de « transformer le web en base de données » — et c'est conçu pour tout le monde, pas seulement pour les ingénieurs.
Essayer l'extension Chrome Thunderbit
2. Crawl4AI
Pour qui : les développeurs et équipes techniques qui construisent des pipelines sur mesure.
Crawl4AI est un framework open source basé sur Python, optimisé pour la vitesse et le crawling à grande échelle, avec l'intégration des LLM en ligne de mire. Il est extrêmement rapide, prend en charge les navigateurs sans interface pour le contenu dynamique et peut structurer les données extraites pour les injecter facilement dans des workflows IA.
- Idéal pour : les développeurs qui ont besoin d'un moteur de crawling puissant et personnalisable.
- Tarifs : gratuit (licence MIT). Vous devrez l'héberger et l'exécuter vous-même.
3. ScrapeGraphAI
Pour qui : les développeurs et analystes qui construisent des agents IA ou des pipelines de données complexes.
ScrapeGraphAI est une bibliothèque Python open source pilotée par des prompts, qui transforme les sites web en « graphes » de données structurées grâce aux LLM. Vous pouvez écrire des requêtes comme « extraire tous les noms de produits, prix et évaluations des 5 premières pages », et l'outil construit pour vous le workflow d'extraction (source).
- Idéal pour : les utilisateurs techniques qui veulent un scraping flexible basé sur des prompts.
- Tarifs : gratuit pour la bibliothèque open source ; l'API cloud démarre à 20 $/mois.
4. Firecrawl
Pour qui : les développeurs qui construisent des agents IA ou des pipelines de données à grande échelle.
Firecrawl est une plateforme de crawling et une API centrées sur l'IA qui transforment des sites entiers en données « prêtes pour les LLM » (source). Elle produit du Markdown ou du JSON, gère le contenu dynamique et s'intègre à des frameworks comme LangChain et LlamaIndex.
- Idéal pour : les développeurs qui doivent alimenter des modèles d'IA avec des données web en temps réel.
- Tarifs : le cœur open source est gratuit ; les formules cloud démarrent à 19 $/mois.
5. Browse AI
Pour qui : les utilisateurs métier, les growth hackers et les analystes.
Browse AI est une plateforme no-code avec une interface point-and-click. Vous « entraînez » un robot en cliquant sur les données souhaitées, puis l'IA généralise le schéma pour les extractions futures. Elle gère les connexions, le défilement infini, et peut surveiller les changements sur les sites.
- Idéal pour : les utilisateurs non techniques qui veulent automatiser la collecte et la surveillance de données.
- Tarifs : formule gratuite (50 crédits/mois) ; offres payantes à partir de 19 $/mois.
6. LLM Scraper
Pour qui : les développeurs qui veulent laisser l'IA s'occuper du parsing.
LLM Scraper est une bibliothèque JavaScript/TypeScript open source qui vous permet de définir un schéma de données et de demander à un LLM d'extraire ces données depuis n'importe quelle page web. Elle repose sur Playwright, prend en charge plusieurs fournisseurs de LLM et peut même générer du code réutilisable.
- Idéal pour : les développeurs qui veulent transformer n'importe quelle page web en données structurées à l'aide des LLM.
- Tarifs : gratuit (licence MIT).
7. Reader (Jina Reader)
Pour qui : les développeurs qui construisent des applications LLM, des chatbots ou des résumeurs.
Jina Reader est une API qui extrait du texte propre et des données structurées à partir de pages web (et même de PDF/images), en renvoyant du Markdown ou du JSON prêts pour les LLM. Elle est propulsée par un modèle d'IA personnalisé et peut même légender les images.
- Idéal pour : récupérer un contenu propre et lisible pour des LLM ou des systèmes de questions-réponses.
- Tarifs : API gratuite (aucune clé requise pour une utilisation de base).
8. Bright Data
Pour qui : les entreprises et utilisateurs professionnels qui ont besoin d'échelle, de conformité et de fiabilité.
Bright Data est un poids lourd de l'industrie des données web, avec un vaste réseau de proxys et des outils de scraping pilotés par l'IA. La société propose des extracteurs prêts à l'emploi, une API Web Scraper générale et des flux de données « prêts pour les LLM ».
- Idéal pour : les organisations qui ont besoin de données web fiables à grande échelle.
- Tarifs : facturation à l'usage, premium. Essais gratuits disponibles.
9. Octoparse
Pour qui : les utilisateurs non techniques à semi-techniques.
Octoparse est un outil no-code bien établi avec un concepteur visuel de workflows et une détection automatique propulsée par l'IA. Il gère les connexions, le défilement infini et peut exporter les données dans différents formats.
- Idéal pour : les analystes, les petits entrepreneurs ou les chercheurs.
- Tarifs : offre gratuite disponible ; formules payantes à partir de 119 $/mois.
10. Apify
Pour qui : les développeurs et équipes techniques qui ont besoin de scraping/automatisation sur mesure.
Apify est une plateforme cloud pour exécuter des scripts de scraping (« actors ») et propose une bibliothèque d'actors préconstruits. Elle est scalable, s'intègre à l'IA et prend en charge la gestion des proxys.
- Idéal pour : les développeurs qui veulent exécuter des scripts personnalisés dans le cloud.
- Tarifs : offre gratuite ; les formules payantes à l'usage démarrent à 49 $/mois.
11. Zyte (Scrapy Cloud)
Pour qui : les développeurs et entreprises qui ont besoin d'un scraping de niveau entreprise.
Zyte est la société derrière Scrapy et propose une plateforme cloud ainsi qu'une extraction automatique propulsée par l'IA. Elle gère la planification, les proxys et les projets à grande échelle.
- Idéal pour : les équipes de développement qui mènent des projets de scraping de longue durée.
- Tarifs : essais gratuits et offres entreprise sur mesure.
12. Webscraper.io
Pour qui : les débutants, journalistes et chercheurs.
Webscraper.io est une extension Chrome très populaire pour l'extraction de données en point-and-click. C'est simple, gratuit pour une utilisation locale, et une offre cloud existe pour les travaux plus importants.
- Idéal pour : les tâches de scraping rapides et ponctuelles.
- Tarifs : extension gratuite ; offres cloud à partir d'environ 50 $/mois.
13. ParseHub
Pour qui : les utilisateurs non techniques qui ont besoin de plus de puissance que les outils de base.
ParseHub est une application de bureau avec un workflow visuel pour extraire du contenu dynamique, y compris des cartes et des formulaires. Elle peut exécuter des projets dans le cloud et propose une API.
- Idéal pour : les spécialistes du marketing digital, les analystes et les journalistes.
- Tarifs : offre gratuite (200 pages/exécution) ; formules payantes à partir de 189 $/mois.
14. Diffbot
Pour qui : les entreprises et sociétés d'IA qui ont besoin de données web structurées à grande échelle.
Diffbot utilise la vision par ordinateur et le NLP pour extraire automatiquement des données de n'importe quelle page web, avec des API pour les articles, les produits et un immense knowledge graph.
- Idéal pour : la veille marché, la finance et les données d'entraînement pour l'IA.
- Tarifs : premium, à partir d'environ 299 $/mois.
15. DataMiner
Pour qui : les utilisateurs non techniques, surtout dans la vente, le marketing et le journalisme.
DataMiner est une extension Chrome pour extraire rapidement des données web en point-and-click. Elle propose une bibliothèque de « recettes » préconstruites et peut exporter directement vers Google Sheets.
- Idéal pour : les tâches rapides comme l'export de tableaux ou de listes vers des tableurs.
- Tarifs : offre gratuite (500 pages/jour) ; Pro à partir d'environ 19 $/mois.
Comparaison des meilleurs outils d'Extracteur Web IA : lequel vous convient ?
Voici une comparaison générale pour vous aider à trouver l'outil adapté :
| Outil | Utilisation IA/LLM | Facilité d'utilisation | Sortie / intégration | Idéal pour | Tarifs |
|---|---|---|---|---|---|
| Thunderbit | Interface en langage naturel ; l'IA suggère les champs | Le plus simple (chat no-code) | Export vers Sheets, Airtable, Notion | Équipes non techniques | Offre gratuite ; Pro ~30 $/mois |
| Crawl4AI | Crawling prêt pour l'IA ; intégration des LLM | Difficile (code Python) | Bibliothèque/CLI ; intégration via code | Développeurs ayant besoin de pipelines IA rapides | Gratuit |
| ScrapeGraphAI | Pipelines de prompts LLM pour le scraping | Moyen (un peu de code ou API) | API/SDK ; sortie JSON | Développeurs/analystes qui construisent des agents IA | Open source gratuit ; API 20 $+/mois |
| Firecrawl | Crawling vers Markdown/JSON prêts pour les LLM | Moyen (utilisation API/SDK) | SDK (Py, Node, etc.) ; intégration LangChain | Développeurs qui intègrent des données web en direct à l'IA | Gratuit + cloud payant |
| Browse AI | Point-and-click assisté par l'IA | Facile (no-code) | Plus de 7000 intégrations d'apps (Zapier) | Utilisateurs non techniques automatisant la veille web | 50 exécutions gratuites ; payant 19 $+/mois |
| LLM Scraper | Utilise les LLM pour parser une page selon un schéma | Difficile (code TS/JS) | Bibliothèque de code ; sortie JSON | Développeurs qui veulent que l'IA gère le parsing | Gratuit (avec votre propre API LLM) |
| Reader (Jina) | Un modèle IA extrait le texte/JSON | Facile (appel API simple) | L'API REST renvoie du Markdown/JSON | Développeurs qui ajoutent recherche/contenu web aux LLM | API gratuite |
| Bright Data | API de scraping enrichies par l'IA ; vaste réseau de proxys | Difficile (API, technique) | API/SDK ; flux de données ou jeux de données | Échelle entreprise | Facturation à l'usage |
| Octoparse | Détection automatique IA des listes | Modéré (application no-code) | CSV/Excel, API pour les résultats | Utilisateurs semi-techniques | Gratuit limité ; 59–166 $/mois |
| Apify | Quelques fonctions IA (Actors, tutoriels IA) | Difficile (scripts de code) | API complète ; intégration avec LangChain | Développeurs ayant besoin de scraping personnalisé dans le cloud | Offre gratuite ; paiement à l'usage |
| Zyte (Scrapy) | Extraction automatique basée sur le machine learning ; framework Scrapy | Difficile (code Python) | API, interface Scrapy Cloud ; JSON/CSV | Équipes de développement, projets longue durée | Tarification personnalisée |
| Webscraper.io | Pas d'IA (modèles manuels) | Facile (extension navigateur) | Téléchargement CSV, API cloud | Débutants, extractions rapides ponctuelles | Extension gratuite ; cloud ~50 $/mois |
| ParseHub | Pas de LLM explicite ; constructeur visuel | Modéré (application no-code) | JSON/CSV ; API pour exécutions cloud | Non-développeurs qui extraient des sites complexes | Gratuit 200 pages ; payant 189 $+/mois |
| Diffbot | Vision IA/NLP pour n'importe quelle page ; knowledge graph | Facile (de simples appels API) | API (Article/Prod/...) + requête sur le knowledge graph | Entreprise, données web structurées | À partir d'environ 299 $/mois |
| DataMiner | Pas de LLM ; recettes communautaires | Le plus simple (interface navigateur) | Export Excel/CSV ; Google Sheets | Utilisateurs non techniques qui extraient vers des tableurs | Gratuit limité ; Pro ~19 $/mois |
Catégories d'outils : des mastodontes pour développeurs aux extracteurs Web pensés pour les entreprises
Pour mieux s'y retrouver dans cette liste, regroupons ces outils en quelques catégories :
1. Mastodontes pour développeurs et open source
- Exemples : Crawl4AI, LLM Scraper, Apify, Zyte/Scrapy, Firecrawl
- Atouts : grande flexibilité, scalabilité et personnalisation. Parfait pour construire des pipelines sur mesure ou les intégrer à des modèles IA.
- Compromis : nécessitent des compétences en code et davantage de configuration.
- Cas d'usage : créer un pipeline de données personnalisé, extraire des sites complexes ou s'intégrer à des systèmes internes.
2. Agents d'extraction intégrés à l'IA
- Exemples : Thunderbit, ScrapeGraphAI, Firecrawl, Reader (Jina), LLM Scraper
- Atouts : réduisent l'écart entre extraction et compréhension des données. Les interfaces en langage naturel les rendent accessibles.
- Compromis : certains sont encore en évolution ; le contrôle granulaire peut manquer.
- Cas d'usage : obtenir rapidement des réponses ou des jeux de données, construire des agents autonomes ou alimenter des LLM avec des données en temps réel.
3. Extracteurs no-code/low-code pensés pour les entreprises
- Exemples : Thunderbit, Browse AI, Octoparse, ParseHub, Webscraper.io, DataMiner
- Atouts : faciles à utiliser, peu ou pas de code requis, adaptés aux tâches métier régulières.
- Compromis : peuvent peiner sur les sites très complexes ou à très grande échelle.
- Cas d'usage : génération de leads, surveillance des concurrents, projets de recherche et extractions ponctuelles.
4. Plateformes et services de données d'entreprise
- Exemples : Bright Data, Diffbot, Zyte
- Atouts : solutions complètes, services managés, conformité et fiabilité à grande échelle.
- Compromis : coût plus élevé, onboarding plus important.
- Cas d'usage : pipelines de données toujours actifs à grande échelle, veille marché et données d'entraînement pour l'IA.
Comment choisir le bon AI Web Crawler pour vos besoins d'extraction de pages web
Qu'est-ce que le data scraping et comment le faire Get Started Free
Le choix peut vite donner le vertige, alors voici mon guide étape par étape :
- Définissez vos objectifs et vos besoins en données : quels sites et quelles données vous faut-il ? À quelle fréquence ? En quelle quantité ? Qu'en ferez-vous ?
- Évaluez votre niveau technique : pas de code ? Essayez Thunderbit, Browse AI ou Octoparse. Un peu de scripting ? LLM Scraper ou DataMiner. Solides compétences dev ? Crawl4AI, Apify ou Zyte.
- Prenez en compte la fréquence et l'échelle : usage ponctuel ? Utilisez des outils gratuits. Besoin récurrent ? Cherchez des fonctions de planification. Grande échelle ? Outils entreprise ou open source à l'échelle.
- Budget et modèle tarifaire : les offres gratuites sont idéales pour tester. Abonnement ou facturation à l'usage : cela dépend de vos besoins.
- Essai et preuve de concept : testez quelques outils sur vos vraies données. La plupart proposent des offres gratuites.
- Maintenance et support : qui corrige les problèmes si le site change ? Les outils no-code avec IA peuvent corriger automatiquement les petits changements ; l'open source dépend de vous ou de la communauté.
- Associez les outils aux scénarios : une équipe commerciale qui récupère des leads ? Thunderbit ou Browse AI. Un chercheur qui collecte des tweets ? DataMiner ou Webscraper.io. Un modèle IA qui a besoin d'articles de presse ? Jina Reader ou Zyte. Vous construisez un site comparatif ? Apify ou Zyte.
- Prévoyez un plan B : parfois, un outil ne fonctionne pas sur un site précis. Ayez une solution de repli.
Le « bon » outil est celui qui vous donne les données dont vous avez besoin avec le moins de friction possible et dans votre budget. Parfois, c'est une combinaison d'outils.
Thunderbit vs. les outils traditionnels d'Extracteur Web : ce qui le distingue
Venons-en directement à ce qui rend Thunderbit différent :
- Interface en langage naturel : pas de code, pas de gymnastique point-and-click. Décrivez simplement ce que vous voulez (source).
- Aucune configuration et suggestions de modèles : Thunderbit détecte automatiquement la pagination, les sous-pages et propose même des modèles pour les sites courants (source).
- Nettoyage et enrichissement des données par l'IA : résumez, catégorisez, traduisez et enrichissez les données pendant l'extraction (source).
- Moins de soucis de maintenance : l'IA de Thunderbit résiste aux petits changements de site, ce qui réduit les ruptures.
- Intégration aux outils métier : export direct vers Google Sheets, Airtable, Notion — fini les prises de tête avec les CSV (source).
- Rapidité de mise en valeur : passez de l'idée aux données en quelques minutes, pas en quelques jours.
- Courbe d'apprentissage : si vous savez naviguer sur le web et expliquer ce qu'il vous faut, vous savez utiliser Thunderbit.
- Polyvalence : extraire des sites web, des PDF, des images et plus encore — avec le même outil.
Thunderbit n'est pas seulement un extracteur — c'est un assistant de données qui s'intègre à votre flux de travail, que vous soyez dans la vente, le marketing, l'e-commerce ou l'immobilier.
Essayer l'Extracteur Web IA Thunderbit
Bonnes pratiques d'extraction de pages web avec les outils d'Extracteur Web IA
Pour tirer le meilleur parti des extracteurs web IA, voici mes conseils principaux :
- Définissez clairement vos besoins en données : sachez quels champs vous voulez, combien de pages, et dans quel format.
- Exploitez les suggestions de l'IA : utilisez la détection de champs et les suggestions IA pour repérer des données importantes que vous pourriez manquer (source).
- Commencez petit et validez : testez sur un petit échantillon, vérifiez la sortie et ajustez si nécessaire.
- Gérez le contenu dynamique : assurez-vous que votre outil prend en charge le contenu dynamique et les interactions (pagination, défilement infini, etc.).
- Respectez les politiques des sites : vérifiez robots.txt, évitez d'extraire des données sensibles et respectez les limites de fréquence.
- Intégrez pour automatiser : utilisez les fonctions d'export et les webhooks pour injecter directement les données extraites dans votre workflow.
- Maintenez la qualité des données : effectuez des contrôles de cohérence, post-traitez les données et surveillez les erreurs.
- Soyez concis dans les prompts : avec les outils pilotés par l'IA, des consignes claires et précises donnent de meilleurs résultats.
- Apprenez de la communauté : rejoignez des forums et communautés pour obtenir des conseils et du dépannage.
- Restez à jour : les outils IA évoluent vite — gardez un œil sur les nouvelles fonctionnalités et améliorations.
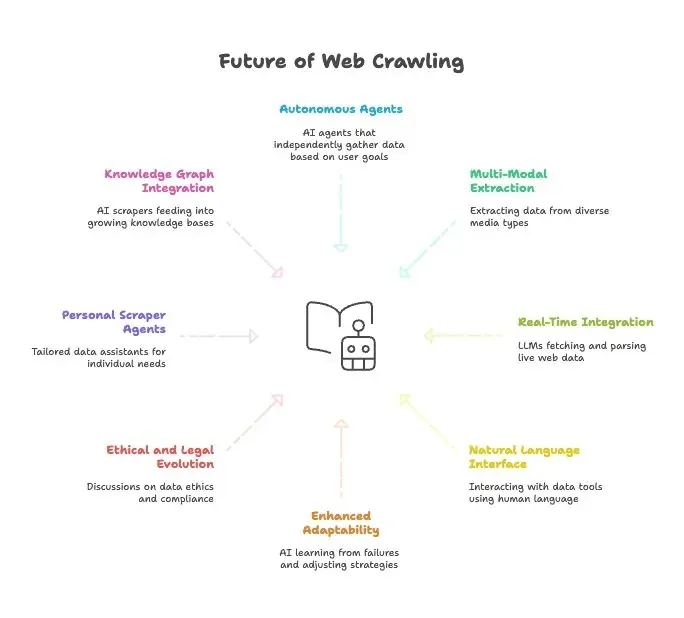
L'avenir du scraping web : IA, LLM et montée des agents d'Extracteur Web en langage naturel
À l'horizon, la convergence entre l'IA et le scraping web ne fait que s'accélérer :
- Agents de scraping entièrement autonomes : bientôt, vous donnerez simplement à un agent IA votre objectif final, et il trouvera comment obtenir les données.
- Extraction de données multimodales : les extracteurs récupéreront des données à partir de texte, d'images, de PDF et même de vidéos.
- Intégration en temps réel avec les modèles IA : les LLM auront des modules intégrés pour récupérer et analyser les données web en direct.
- Le langage naturel partout : nous parlerons à nos outils de données comme à des humains, rendant la collecte et la transformation de données accessibles à tous.
- Adaptabilité renforcée : les extracteurs IA apprendront des échecs et adapteront automatiquement leurs stratégies.
- Évolution éthique et juridique : attendez-vous à davantage de discussions sur l'éthique des données, la conformité et l'usage équitable.
- Agents personnels d'extraction : imaginez un assistant de données personnel qui collecte des actualités, des offres d'emploi et bien plus encore, selon vos besoins.
- Intégration aux knowledge graphs : les extracteurs IA alimenteront en continu des bases de connaissances toujours plus vastes, renforçant des IA plus intelligentes.
En clair ? L'avenir du web scraping est intimement lié à celui de l'IA. Les outils deviennent plus intelligents, plus autonomes et plus accessibles chaque jour.
Conclusion : créer de la valeur business avec le bon AI Web Crawler
Le scraping web est passé d'une compétence technique de niche à une capacité métier essentielle — grâce à l'IA. Les 15 outils présentés ici représentent le meilleur de ce qui est possible en 2026, des géants pour développeurs aux assistants pensés pour les entreprises.
Le vrai secret ? Choisir le bon outil peut augmenter de façon spectaculaire la valeur que vous tirez des données web. Pour les équipes non techniques, Thunderbit est la manière la plus simple de transformer le web en une base de données structurée et prête à l'analyse — sans code, sans friction, avec des résultats.
Alors, que vous collectiez des leads, surveilliez des concurrents ou alimentiez votre prochain modèle IA, prenez le temps d'évaluer vos besoins, d'essayer quelques outils et de voir ce qui vous convient. Et si vous voulez découvrir dès aujourd'hui l'avenir du scraping web, essayez Thunderbit. Les informations qu'il vous faut sont à un prompt de distance.
Envie d'en savoir plus ? Consultez le blog Thunderbit pour des analyses approfondies, des tutoriels et les dernières nouveautés de l'extraction de données propulsée par l'IA.
Lectures complémentaires :
- Qu'est-ce que le data scraping et comment le faire en 2026
- Comment extraire des données de site web vers Excel avec l'IA
- Les meilleurs outils et logiciels de scraping web en 2026
Essayer l'Extracteur Web IA Get Started Free
FAQ
1. Qu'est-ce qu'un AI web crawler et en quoi est-il différent des extracteurs web traditionnels ?
Un AI web crawler utilise le traitement du langage naturel et le machine learning pour comprendre, extraire et structurer les données web. Contrairement aux extracteurs traditionnels qui nécessitent du codage manuel et des sélecteurs XPath, les outils IA peuvent gérer le contenu dynamique, s'adapter aux changements de mise en page et interpréter les consignes en anglais simple.
2. Qui devrait utiliser des outils d'extraction web IA comme Thunderbit ?
Thunderbit est conçu à la fois pour les utilisateurs non techniques et techniques. Il est idéal pour les professionnels de la vente, du marketing, des opérations, de la recherche et de l'e-commerce qui souhaitent extraire des données structurées depuis des sites web, des PDF ou des images — sans écrire de code.
3. Quelles fonctionnalités distinguent Thunderbit des autres AI web crawlers ?
Thunderbit propose une interface en langage naturel, le crawling multi-niveaux, la structuration automatique des données, la prise en charge de l'OCR et des exports fluides vers des plateformes comme Google Sheets et Airtable. Il inclut aussi des suggestions de champs basées sur l'IA et des modèles prêts à l'emploi pour les sites populaires.
4. Existe-t-il des options gratuites pour l'extraction web IA en 2026 ?
Oui. De nombreux outils comme Thunderbit, Browse AI et DataMiner proposent des offres gratuites avec usage limité. Pour les développeurs, des options open source comme Crawl4AI et ScrapeGraphAI offrent toutes leurs fonctionnalités sans frais, même si elles demandent une mise en place technique.
5. Comment choisir le bon AI web crawler pour mes besoins ?
Commencez par identifier vos objectifs de données, votre niveau technique, votre budget et vos besoins en échelle. Si vous voulez une solution no-code, simple à utiliser, Thunderbit ou Browse AI sont d'excellents choix. Pour des besoins à grande échelle ou sur mesure, des outils comme Apify ou Bright Data sont mieux adaptés.




