Remontez avec moi à mes premiers pas dans le monde de l’extraction de données sur le web. Imaginez la scène : on est en 2015, je squatte un petit appart dans le New Jersey, déjà trois cafés dans le sang, et je galère sur un script Python qui plante dès que le site cible change un bouton ou une balise. Mes armes de l’époque ? Beautiful Soup et Selenium. Avance rapide, on est en 2025 : le débat « beautiful soup vs selenium » fait toujours rage, mais l’arrivée de l’IA a tout chamboulé, bien au-delà de ce que j’aurais pu imaginer. Aujourd’hui, les outils ne se contentent plus de lire du HTML : ils comprennent le contenu, naviguent comme un humain, extraient des données structurées à partir de simples instructions, et peuvent même nettoyer, résumer ou traduire les infos en un clin d’œil.

L’extraction de données web n’est plus réservée aux geeks en sweat à capuche. C’est devenu un atout incontournable pour les équipes commerciales, marketing, e-commerce ou opérations qui ont besoin de données fraîches et structurées, tout de suite. Avec un marché de l’extraction web qui pèse désormais plus d’ et l’arrivée de solutions boostées à l’IA comme , la vraie question n’est plus « Quel extracteur Python choisir ? » mais « Comment obtenir les données dont j’ai besoin, sans prise de tête ni maintenance interminable ? » Allez, plongeons dans le match beautiful soup vs selenium, et voyons comment l’IA redistribue les cartes.
Beautiful Soup vs Selenium : quelles différences ?
Si tu as déjà tapé « python web scraper » sur Google, tu es forcément tombé sur et . Mais qu’est-ce qui les différencie vraiment ?
Imagine Beautiful Soup comme un bibliothécaire super efficace. C’est une bibliothèque Python faite pour lire et extraire des données de fichiers HTML ou XML statiques. Si les infos que tu cherches sont déjà dans le code source de la page, Beautiful Soup les repère, les trie et te les sert sur un plateau. C’est rapide, léger, et il n’a pas besoin de « voir » la page comme un humain : il lit juste le HTML brut.
Selenium, à l’inverse, c’est comme un assistant robot qui utilise un vrai navigateur web. Il automatise les actions dans le navigateur : cliquer, remplir des formulaires, se connecter, scroller, attendre le chargement du JavaScript… Selenium est indispensable quand les données n’apparaissent qu’après une interaction ou sur des pages dynamiques générées par JavaScript.
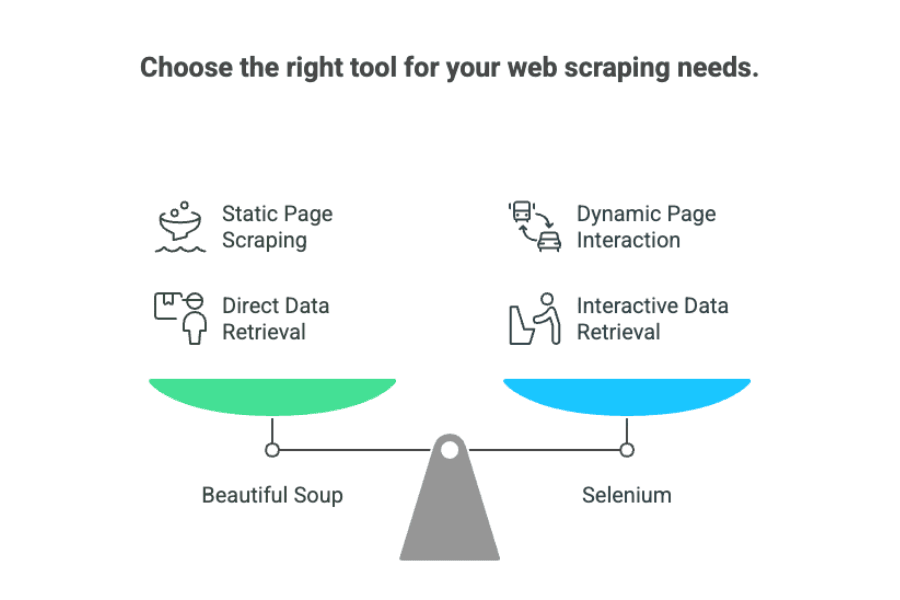
En résumé, dans le duel « beautiful soup vs selenium » :
- Beautiful Soup : Parfait pour les pages statiques où les données sont directement dans le HTML.
- Selenium : Idéal pour les sites dynamiques qui nécessitent des interactions ou un chargement différé.
Pour les équipes métiers, une image simple :
- Beautiful Soup c’est recopier des infos depuis un catalogue papier.
- Selenium c’est envoyer quelqu’un en magasin pour feuilleter le catalogue, appuyer sur quelques boutons et obtenir les prix à jour.
Les galères classiques : limites de Beautiful Soup et Selenium
Soyons francs sur les difficultés. Après avoir passé des heures à déboguer des scripts d’extraction, voici les principaux obstacles avec Beautiful Soup et Selenium :
1. Fragilité face aux changements de site
Les deux outils sont ultra sensibles au moindre changement de structure du site. Si le propriétaire modifie un nom de classe ou déplace une balise, ton script peut planter du jour au lendemain. Comme : « Les coûts de maintenance peuvent dépasser dix fois ceux du développement. » Ça pique.
2. Vitesse (ou lenteur)
- Beautiful Soup est rapide pour l’analyse, mais si tu dois extraire des milliers de pages, ça prend du temps.
- Selenium est bien plus lent : chaque page nécessite d’ouvrir un navigateur, d’attendre le chargement, d’interagir… Pour passer à l’échelle, il faut lancer plein de navigateurs, ce qui bouffe pas mal de ressources.
3. Peu de réutilisabilité du code
Chaque site est unique. Il faut donc écrire une logique d’extraction spécifique à chaque nouveau site, et tout recommencer dès qu’il change. Pas de script universel.
4. Complexité technique
Les deux outils demandent de bonnes bases en Python, de savoir manier les sélecteurs HTML/CSS, et (pour Selenium) de gérer les drivers de navigateur. Pour les non-développeurs, c’est vite décourageant.
5. Maintenance chronophage
Faire tourner des extracteurs, c’est un boulot sans fin. Les sites évoluent, les protections anti-bot se renforcent, il faut surveiller et mettre à jour les scripts en permanence. Pour les équipes métiers, ça veut dire dépendre des développeurs ou externaliser l’extraction.
Au-delà des outils Python classiques : l’essor des solutions boostées à l’IA
C’est là que ça devient vraiment intéressant. Depuis quelques années, on voit débarquer des extracteurs web dopés à l’IA : des outils qui s’appuient sur des modèles de langage (genre GPT) pour « lire » et extraire les données, sans écrire une seule ligne de code.
Thunderbit : l’Extracteur Web IA pensé pour les métiers
est une extension Chrome qui permet d’extraire les données de n’importe quel site en deux clics. Pas de Python, pas de code, pas de drivers à configurer. Tu pointes, tu cliques, et l’IA fait le reste.
Pourquoi les extracteurs IA comme Thunderbit changent la donne
- Zéro code, zéro prise de tête : Thunderbit va encore plus loin que le « no code » : c’est « sans effort ». Installe juste l’, va sur la page cible, et laisse l’IA te suggérer les champs à extraire.
- Gère le contenu dynamique : Puisqu’il fonctionne dans le navigateur, Thunderbit voit tout ce que tu vois, y compris les données chargées par JavaScript, après des clics ou derrière une connexion.
- Rapide et précis : L’IA de Thunderbit peut extraire en lot plusieurs pages, avec une rapidité et une précision idéales pour la génération de leads, l’e-commerce ou l’immobilier.
- Aucune maintenance : Thunderbit, c’est comme un assistant IA qui ne dort jamais. Si le site change, l’IA s’adapte. Fini les scripts à réécrire à chaque modif.
- Nettoyage et enrichissement des données : Thunderbit ne se contente pas d’extraire les données brutes : il peut les étiqueter, les formater, les traduire ou les résumer à la volée. C’est comme confier 10 000 pages web à ChatGPT pour obtenir un tableau structuré et propre.
Résultat : les équipes métiers peuvent enfin accéder aux données dont elles ont besoin, sans attendre l’IT ni se plonger dans Python.
Thunderbit vs Beautiful Soup vs Selenium : le comparatif express
Voici un aperçu comparatif pour les équipes métiers :
| Critère | Beautiful Soup | Selenium | Thunderbit (Extracteur Web IA) |
|---|---|---|---|
| Installation | Simple installation Python | Complexe (drivers navigateur) | Extension Chrome, aucune configuration |
| Facilité d’utilisation | Facile pour les codeurs | Plus complexe, nécessite du code | Sans code, adapté aux métiers |
| Vitesse | Rapide sur pages statiques | Lent (surcharge navigateur) | Rapide pour petits/moyens volumes, pas pour des millions |
| Contenu dynamique | Ne gère pas le JS | Gère tout le contenu dynamique | Gère tout le contenu dynamique |
| Maintenance | Élevée (casse au moindre changement) | Élevée (casse, mises à jour drivers) | Faible (l’IA s’adapte aux changements) |
| Scalabilité | Bien pour statique, nécessite de l’infra | Difficile à scaler, gourmand en ressources | Idéal pour petits/moyens volumes, pas pour le scraping massif |
| Nettoyage des données | Manuel, post-traitement | Manuel, post-traitement | Intégré : étiquetage, formatage, traduction, résumé |
| Intégrations | Code personnalisé | Code personnalisé | Export 1-clic vers Excel, Sheets, Airtable, Notion |
| Compétences techniques | Python requis | Python + connaissances navigateur | Aucune compétence requise |
Fonctionnalités avancées : comment Thunderbit révolutionne l’extraction web pour les métiers
Voyons ce qui fait de Thunderbit un vrai game changer pour les non-développeurs :
1. Extraction de données pilotée par l’IA
Thunderbit utilise l’IA pour « lire » les pages web et suggérer les champs à extraire. Clique sur « Suggérer les champs IA », vérifie les colonnes, puis lance l’extraction. Plus besoin de se prendre la tête avec des sélecteurs ou du HTML.
2. Extraction sur sous-pages
Besoin de récupérer des infos sur une liste de produits, puis d’aller sur chaque fiche pour plus de détails ? Thunderbit visite automatiquement chaque sous-page et enrichit ton tableau, sans configuration supplémentaire.
3. Nettoyage, étiquetage et traduction des données
L’IA de Thunderbit peut :
- Étiqueter les données : Ajouter des catégories ou tags à la volée.
- Formater : Standardiser numéros de téléphone, dates, prix…
- Traduire : Traduire instantanément le contenu extrait dans la langue de ton choix.
- Résumer : Générer des synthèses ou points clés à partir de textes longs.
C’est comme avoir un data analyst intégré à ton extracteur.
4. Intégrations fluides
Exporte tes données directement vers Excel, Google Sheets, Airtable ou Notion en un clic. Fini les galères de CSV.
5. Sans code, sans maintenance
Thunderbit est pensé pour les métiers, pas pour les développeurs. Pas besoin de Python, ni de se soucier de la maintenance. L’IA s’adapte aux changements, tes workflows restent fluides.
Pour découvrir toutes les fonctionnalités de Thunderbit, jette un œil à .
Choisir le bon outil : conseils pratiques pour les métiers
Alors, comment choisir entre Beautiful Soup, Selenium et Thunderbit ? Voici mes conseils, après des années à extraire (et casser) des sites :
1. Quel volume de données ?
- Petits à moyens volumes (quelques centaines ou milliers de pages) : Thunderbit est top : installation rapide, sans code, nettoyage intégré.
- Extraction massive (dizaines ou centaines de milliers de pages) : Beautiful Soup (avec des frameworks comme Scrapy) ou des solutions d’entreprise. Thunderbit n’est pas encore fait pour le scraping massif.
2. Avez-vous des ressources de développement ?
- Des développeurs sous la main : Beautiful Soup et Selenium offrent un contrôle total.
- Pas de développeurs, ou besoin d’aller vite : Thunderbit ou un autre outil IA.
3. Le site change-t-il souvent ?
- Changements fréquents : L’IA de Thunderbit s’adapte automatiquement, tu évites la maintenance.
- Changements rares : Beautiful Soup ou Selenium peuvent suffire, mais prévois de mettre à jour tes scripts.
4. Besoin de nettoyage ou d’enrichissement des données ?
- Oui : Thunderbit peut étiqueter, formater, traduire et résumer à l’extraction.
- Non, juste les données brutes : Beautiful Soup ou Selenium.
Tableau de décision
| Question | Meilleur outil |
|---|---|
| Pas de développeur, besoin de données rapidement | Thunderbit |
| Besoin de nettoyage/traduction à l’extraction | Thunderbit |
| Extraction massive, pipeline sur-mesure | Beautiful Soup/Scrapy |
| Changements fréquents, maintenance minimale | Thunderbit |
Conclusion : l’avenir des outils Python d’extraction web
L’extraction de données web a bien changé depuis mes débuts à galérer sur des scripts Python fragiles. En 2025, le débat « beautiful soup vs selenium » reste d’actualité, mais l’essor des outils IA comme Thunderbit change la donne pour les métiers.
Beautiful Soup reste la référence pour extraire rapidement des pages HTML statiques : rapide, léger, parfait pour les tâches simples. Selenium reste l’outil de choix pour automatiser les navigateurs et extraire des sites dynamiques, mais il demande plus de configuration et d’entretien.
Mais si tu veux éviter le code, la maintenance et obtenir des données propres et structurées sans effort, les extracteurs web IA comme Thunderbit ouvrent une nouvelle ère. Ce n’est plus juste « sans code » : c’est « sans effort ». Et pour les équipes commerciales, e-commerce ou opérations qui ont besoin de données tout de suite (et pas après une semaine de débogage), c’est un vrai changement de paradigme.
Mon conseil ? Fais le point sur tes process d’extraction actuels. Si tu en as marre des scripts qui cassent, de la maintenance ou d’attendre les développeurs, teste Thunderbit. L’avenir de l’extraction web sera plus intelligent, plus rapide et plus accessible que jamais – et j’ai hâte de voir la suite.
Envie de voir Thunderbit en action ? ou découvre d’autres guides sur le . Et si tu veux extraire des sites spécifiques (Amazon, Twitter, PDF, etc.), on a ce qu’il te faut :
Bonne extraction – que tes données soient toujours fraîches, bien rangées et sans prise de tête.