
La demande pour des données annotées de qualité n’a jamais été aussi intense dans le monde du machine learning. À chaque fois que je discute avec des équipes qui bossent sur de nouveaux modèles d’IA—que ce soit pour anticiper les ventes, recommander des produits ou analyser le ressenti des clients—on retombe toujours sur le même souci : l’annotation manuelle, c’est long, cher, et franchement, ça peut vite démotiver. J’ai vu des projets rester en stand-by pendant des semaines, voire des mois, juste parce qu’il n’y avait pas assez d’exemples annotés pour entraîner un modèle solide. Et si les annotations ne sont pas cohérentes ? Autant dire que vos prédictions risquent d’être aussi fiables qu’un parapluie troué sous la pluie.
Heureusement, l’annotation automatisée des données avec le machine learning vient tout changer. En laissant l’IA s’occuper de cette tâche, les entreprises gagnent un temps fou, mais aussi en précision et en régularité—deux ingrédients clés pour réussir un projet ML. Dans ce guide, je vais t’expliquer comment fonctionne l’annotation automatisée, pourquoi c’est indispensable pour construire des modèles costauds, et comment tu peux utiliser des outils comme pour mettre en place ton propre workflow d’annotation automatisée—sans avoir à écrire une seule ligne de code.
Qu’est-ce que l’annotation automatisée des données avec le machine learning ?
Pour faire simple, l’annotation automatisée des données avec le machine learning, c’est utiliser des algorithmes et des outils d’IA pour coller des étiquettes (genre « spam » ou « non spam », « chat » ou « chien », « positif » ou « négatif ») sur tes données brutes—sans que quelqu’un doive tout vérifier à la main. Imagine la différence entre taguer à la main des milliers de photos de vacances et utiliser la reconnaissance faciale pour tout trier automatiquement par personne, lieu ou même humeur.
L’annotation manuelle, comme son nom l’indique, c’est des gens qui passent sur chaque donnée pour lui donner la bonne étiquette. C’est parfois précis, mais c’est lent, cher, et impossible à faire à grande échelle. L’annotation automatisée, elle, s’appuie sur des modèles de machine learning—entraînés sur un petit échantillon annoté à la main—pour deviner les étiquettes du reste de tes données. Résultat : c’est plus rapide, plus homogène, et bien plus simple à déployer à grande échelle ().
Pour les entreprises, ça veut dire des modèles plus performants, développés plus vite, et avec beaucoup moins de boulot manuel. Dans un monde où tout tourne autour de la donnée, c’est un vrai avantage.
Pourquoi l’annotation automatisée est essentielle pour des modèles de machine learning performants
C’est simple : la qualité de tes annotations a un impact direct sur la performance de tes modèles de machine learning. Comme on dit, « des données pourries, des résultats pourris ». Si tes étiquettes sont bancales ou fausses, ton modèle va apprendre n’importe quoi—et tes prédictions ne vaudront pas grand-chose ().
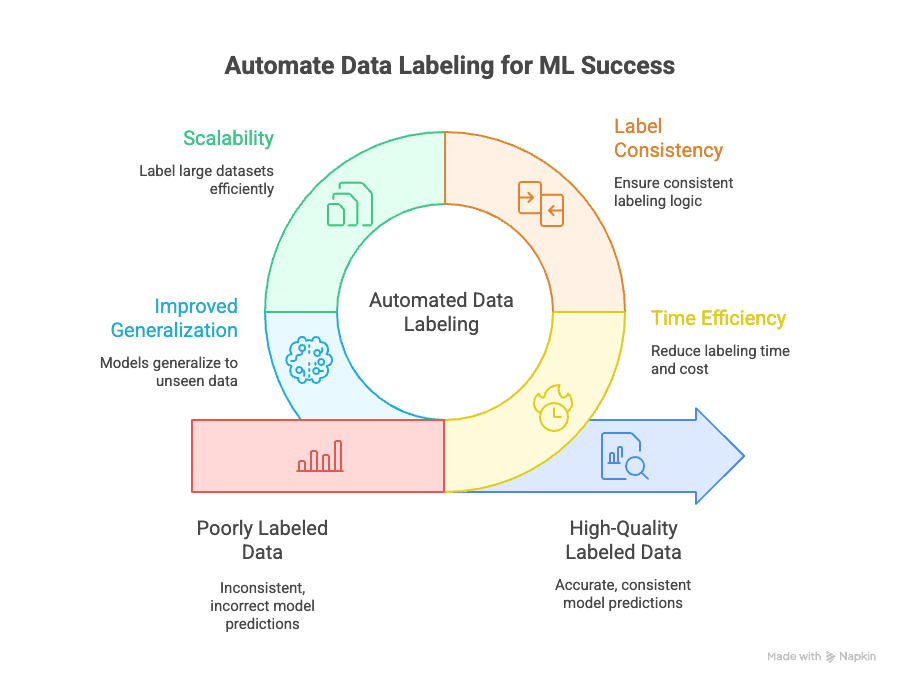
L’annotation automatisée des données permet de régler plusieurs gros problèmes :
- Gain de temps : L’annotation manuelle peut représenter d’un projet ML. L’automatisation fait gagner un temps fou, ce qui te permet d’itérer et de lancer tes modèles beaucoup plus vite.
- Cohérence des étiquettes : Les machines ne se fatiguent pas et ne perdent pas le fil. L’annotation automatisée garantit que chaque donnée est traitée de la même façon, ce qui limite les erreurs humaines et les biais ().
- Scalabilité : Tu dois annoter 10 000, 100 000, voire un million de données ? L’automatisation le fait—pas besoin de recruter une armée d’annotateurs ().
- Meilleure généralisation : Des étiquettes cohérentes et de qualité aident tes modèles à mieux s’adapter à de nouvelles données, ce qui est le but ultime du machine learning ().
Et l’impact business est bien réel : des données mal annotées peuvent faire chuter la précision d’un modèle de , alors qu’une annotation automatisée et de qualité accélère le développement et le déploiement de tes modèles.
Comparatif : annotation manuelle vs annotation automatisée
Petit tableau pour y voir plus clair :
| Critère | Annotation manuelle | Annotation automatisée avec ML |
|---|---|---|
| Vitesse | Lente (semaines/mois pour de gros volumes) | Rapide (quelques minutes/heures pour de gros volumes) |
| Précision | Élevée, mais sujette aux erreurs/incohérences humaines | Élevée, logique constante et moins d’erreurs |
| Scalabilité | Limitée par les ressources humaines | Passe à l’échelle sur des millions de données |
| Coût | Élevé (main d’œuvre importante) | Coût réduit sur le long terme (Keylabs) |
| Idéal pour | Petits jeux de données, cas complexes ou ambigus | Jeux de données volumineux, répétitifs ou bien définis |
L’annotation manuelle reste utile—surtout pour les cas tordus ou les données ambiguës—mais pour la plupart des besoins en entreprise, l’automatisation s’impose.
Les étapes clés de l’annotation automatisée des données avec le machine learning
Comment ça marche concrètement ? Voici le workflow que je recommande (et que j’utilise au quotidien) :
- Collecte et préparation des données
- Extraction et préparation des caractéristiques
- Annotation automatisée via le machine learning
- Contrôle qualité et validation humaine
On détaille chaque étape.
Étape 1 : Collecte et préparation des données
Avant d’annoter quoi que ce soit, il faut rassembler et nettoyer tes données. Ça peut passer par le scraping de fiches produits, l’export de commentaires clients ou la collecte d’images depuis tes bases internes. L’essentiel, c’est la qualité : des données brutes de mauvaise qualité donneront des annotations médiocres, et donc des modèles peu fiables ().
Astuces :
- Supprime les doublons et les entrées inutiles
- Uniformise les formats (dates, devises, etc.)
- Gère les données manquantes ou incomplètes
Étape 2 : Extraction et préparation des caractéristiques
Ensuite, repère les attributs importants pour ta tâche d’annotation. Par exemple, pour annoter des fiches produits, tu peux extraire le prix, la marque, la catégorie et la description. En vente ou marketing, ça peut être le nom de l’entreprise, les coordonnées ou le ressenti extrait d’un email.
Exemple concret : Avec , tu peux extraire des données structurées de pages web—comme des specs produits, des avis ou des coordonnées—sans coder.
Étape 3 : Annotation automatisée via le machine learning
C’est là que la magie opère. Tu utilises des modèles de machine learning (entraînés sur un petit jeu de données annotées à la main) pour prédire les étiquettes du reste de tes données. Les techniques courantes incluent :
- Modèles supervisés : Tu entraînes un classificateur sur des exemples annotés, puis tu l’appliques à de nouvelles données.
- Annotation par règles : Tu utilises des règles simples (ex : « si prix > 1000€, étiquette ‘premium’ ») pour les cas évidents.
- Apprentissage actif : Le modèle demande l’avis humain sur les cas douteux, ce qui l’améliore au fil du temps ().
- Transfert de connaissances : Tu utilises des modèles pré-entraînés pour accélérer l’annotation dans de nouveaux domaines ().
Résultat : des annotations homogènes et de qualité, à grande échelle.
Étape 4 : Contrôle qualité et validation humaine
Même les meilleurs modèles ont besoin d’un check. Un contrôle humain régulier permet de repérer les cas limites, les données ambiguës ou la dérive du modèle. Quelques bonnes pratiques QA :
- Prendre un échantillon au hasard pour vérification manuelle
- Comparer les annotations automatiques à un jeu de référence (« gold standard »)
- Utiliser des métriques d’accord entre annotateurs pour mesurer la cohérence ()
Comment utiliser Thunderbit pour automatiser l’annotation des données avec le machine learning
Passons à la pratique. est un extracteur web IA et un outil d’annotation pensé pour les pros—pas besoin d’être un as du code. Voici comment automatiser ton workflow d’annotation avec Thunderbit :
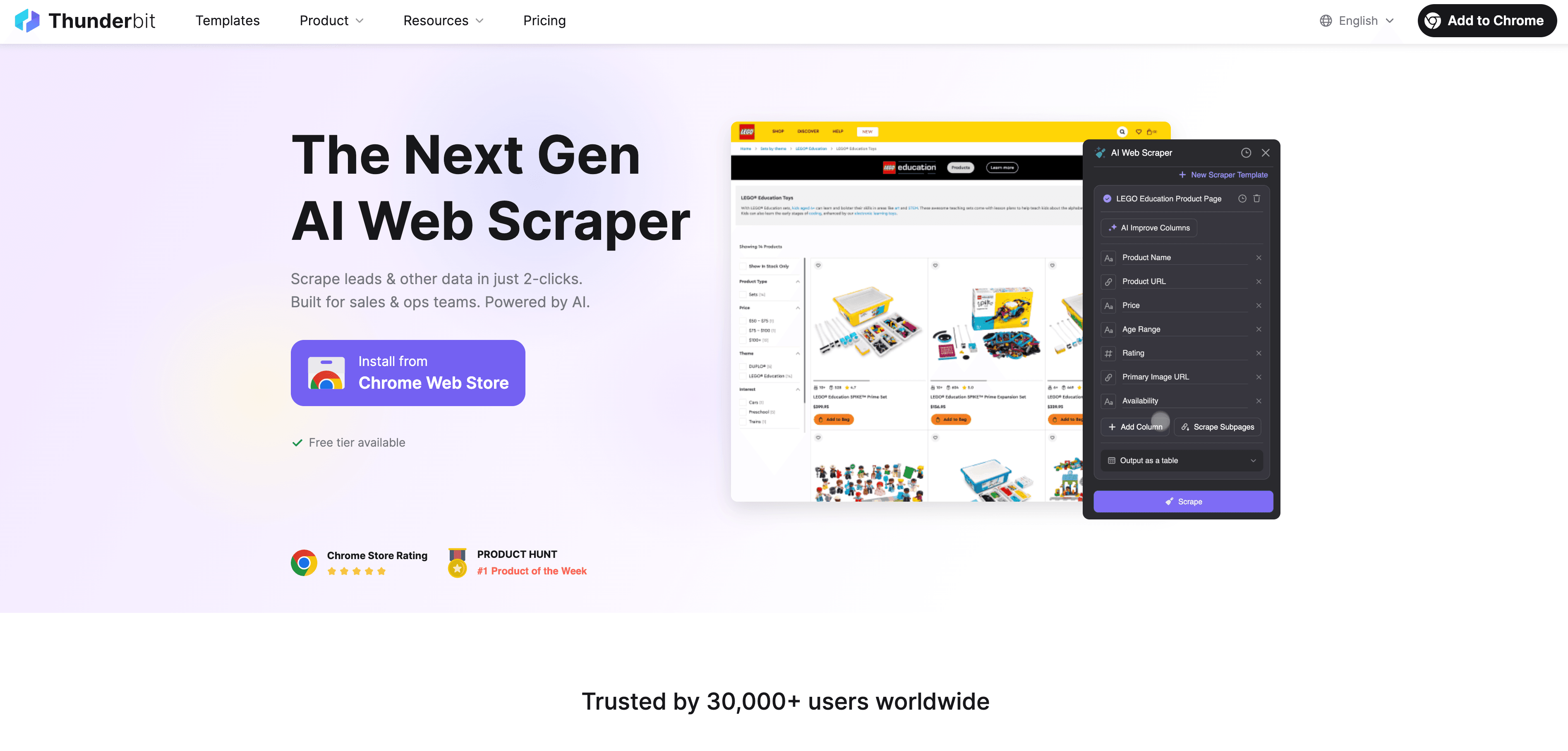
Guide étape par étape
- Scraper les données du web : Utilise l’ pour collecter des données structurées sur n’importe quel site. Ouvre l’extension, choisis ta source, et laisse l’IA de Thunderbit te suggérer les champs à extraire.
- Définir les instructions d’annotation : Rédige tes consignes en français courant pour indiquer à l’IA comment annoter tes données. Par exemple : « Étiqueter tous les produits à plus de 500€ comme ‘premium’ » ou « Taguer les avis positifs ».
- Appliquer l’annotation automatisée : La fonction Field AI Prompt de Thunderbit te permet d’affiner et de personnaliser l’annotation—parfait pour les tâches multi-champs ou complexes.
- Exporter les données annotées : Une fois l’annotation terminée, exporte tes données directement vers Excel, Google Sheets, Airtable ou Notion—prêtes à être utilisées pour entraîner tes modèles ou pour l’analyse.
Le top ? Thunderbit est pensé pour les utilisateurs non techniques en vente, marketing, opérations, etc. Pas besoin de coder ni de se prendre la tête avec des modèles compliqués.
Prompts en langage naturel et fonctionnalités Field AI de Thunderbit
L’un des gros atouts, c’est la possibilité de définir la logique d’annotation en français simple. Tu veux classer des prospects par région, taguer des produits par catégorie ou repérer les emails urgents ? Décris juste ce que tu veux, et l’IA de Thunderbit s’occupe du reste.
Exemples de prompts :
- « Étiqueter tous les contacts avec une adresse email ‘.edu’ comme segment ‘Éducation’. »
- « Si l’avis mentionne ‘livraison rapide’, taguer comme ‘Expérience de livraison positive’. »
- « Regrouper les produits par marque et tranche de prix. »
Le Field AI Prompt de Thunderbit va encore plus loin—tu peux personnaliser la logique d’annotation pour chaque colonne, combiner des règles, ou même traduire les étiquettes dans plusieurs langues.
Scraping de sous-pages et annotation multi-champs
Des structures de données complexes ? Aucun souci. La fonction de scraping de sous-pages de Thunderbit permet d’extraire et d’annoter des données issues de pages imbriquées (comme les fiches produits ou les bios d’auteurs) et de tout rassembler dans un tableau structuré. Tu peux annoter plusieurs champs en une seule fois—un vrai gain de temps.
Cas concret : Extraire des fiches produits d’un site e-commerce, puis suivre chaque lien pour récupérer et annoter les specs, avis et infos vendeur—le tout dans un seul workflow.
Combiner plusieurs outils d’annotation pour plus de précision et d’efficacité
Si Thunderbit couvre déjà pas mal de besoins, il arrive que certaines tâches demandent des outils spécialisés—comme l’annotation d’images ou de vidéos. C’est là que des plateformes comme ou entrent en jeu.
Astuce de pro : Utilise Thunderbit pour extraire les données web et faire une première annotation, puis exporte tes données vers Label Studio ou Supervisely pour des annotations avancées (par exemple, délimiter des objets sur des images ou taguer image par image sur des vidéos). Cette approche multi-outils te permet de profiter des points forts de chaque plateforme, pour plus de précision et d’efficacité ().
Quand utiliser des outils spécialisés en complément de Thunderbit
- Annotation d’images : Pour la détection ou la segmentation d’objets, privilégie Supervisely ou Label Studio.
- Annotation vidéo : Les outils spécialisés gèrent l’annotation image par image et le suivi d’objets.
- Tâches multi-label complexes : Combine l’extraction structurée de Thunderbit avec des outils d’annotation avancés pour un résultat optimal.
Bonnes pratiques : Commence avec Thunderbit pour annoter rapidement et à grande échelle tes données structurées ou semi-structurées, puis passe à des outils spécialisés pour les annotations plus poussées.
Bonnes pratiques pour l’annotation automatisée des données avec le machine learning
Tu veux vraiment optimiser ton workflow d’annotation automatisée ? Voici mes conseils :
- Sois clair dans tes consignes : Des étiquettes floues donnent des données incohérentes—sois précis sur la signification de chaque label.
- Commence avec un jeu de données de qualité : Annote à la main un petit échantillon représentatif pour entraîner ton premier modèle.
- Itère et améliore : Utilise l’apprentissage actif pour affiner ton modèle, en concentrant la validation humaine sur les cas difficiles.
- Valide régulièrement : Contrôle de temps en temps un échantillon au hasard pour repérer les erreurs ou la dérive.
- Intègre et automatise : Utilise des outils comme Thunderbit pour relier collecte, annotation et export dans un seul workflow.
Défis courants et solutions
L’annotation automatisée n’est pas sans embûches. Voici comment les contourner :
- Données ambiguës : Rédige des définitions d’étiquettes précises et donne des exemples pour les cas limites.
- Dérive du modèle : Réentraîne régulièrement ton modèle d’annotation avec de nouvelles données validées à la main.
- Cas particuliers : Prévoyez une validation humaine pour les données incertaines ou inédites.
- Problèmes d’intégration : Choisis des outils (comme Thunderbit) qui facilitent l’export vers tes plateformes préférées.
Conclusion & points clés à retenir
L’annotation automatisée des données avec le machine learning, c’est le secret des modèles d’IA les plus performants aujourd’hui. Tu gagnes du temps, tu réduis les coûts et—surtout—tu obtiens des étiquettes homogènes et de qualité, indispensables pour réussir tes modèles. En combinant des outils comme avec des plateformes d’annotation spécialisées, tu peux construire un workflow rapide, précis et évolutif—peu importe ton niveau technique.
Prêt à voir la différence ? , teste l’annotation automatisée sur ton prochain projet, et regarde tes modèles progresser à toute vitesse. Pour plus d’astuces et de tutos, va faire un tour sur le .
FAQ
1. Qu’est-ce que l’annotation automatisée des données avec le machine learning ?
C’est le fait d’utiliser l’IA et des modèles ML pour attribuer automatiquement des étiquettes aux données, au lieu de le faire à la main. Cette méthode accélère l’annotation, améliore la cohérence et permet de traiter de gros volumes de données.
2. Pourquoi la qualité de l’annotation est-elle cruciale pour le machine learning ?
Des étiquettes fiables et homogènes sont indispensables pour entraîner des modèles précis. Une annotation de mauvaise qualité peut faire chuter la performance d’un modèle de 80% et donner des prédictions peu fiables.
3. Comment Thunderbit facilite-t-il l’annotation automatisée ?
Thunderbit permet de collecter et d’annoter des données web grâce à l’IA, avec des prompts en langage naturel et une logique personnalisable—sans coder. C’est l’outil parfait pour les équipes commerciales, marketing ou opérationnelles.
4. Puis-je combiner Thunderbit avec d’autres outils d’annotation ?
Bien sûr. Utilise Thunderbit pour l’extraction et l’annotation initiale de données structurées, puis exporte-les vers des outils comme Label Studio ou Supervisely pour des annotations avancées sur images ou vidéos.
5. Quelles sont les bonnes pratiques pour l’annotation automatisée ?
Sois clair dans tes consignes, commence avec un jeu de données de qualité, itère avec l’apprentissage actif, valide régulièrement et utilise des outils intégrés pour fluidifier ton workflow.
Prêt à automatiser l’annotation de tes données et à booster tes projets de machine learning ? Essaie Thunderbit et découvre combien de temps (et d’énergie) tu peux économiser.
Pour aller plus loin :