

Amazon concentre à lui seul ce que représentaient autrefois le centre commercial, le supermarché et le magasin d’électronique du coin. Quand on travaille dans la vente, l’e-commerce ou les opérations, on sait que rien de ce qui se passe sur la marketplace n’y reste vraiment cloisonné : les prix qu’on y affiche, les niveaux de stock, le calendrier d’un lancement produit, tout finit par dépendre de ce qu’on observe là-bas. Le hic, c’est que ces fiches produits, ces tarifs, ces notes et ces avis sont enfermés derrière une interface conçue pour les acheteurs, surtout pas pour les équipes qui ont faim de données. Reste donc une question : comment récupérer tout cela sans y passer ses week-ends à copier-coller à la main ?
La réponse tient en deux mots : extraction web. Ce guide détaille deux façons de sortir des données produits d’Amazon. La première, artisanale, consiste à retrousser ses manches et à coder en Python. La seconde, plus récente, laisse l’IA s’occuper du gros du travail via un extracteur sans code comme Thunderbit. On part sur du vrai code Python — avec ses pièges et ses parades — avant de voir comment Thunderbit livre les mêmes données en quelques clics, sans écrire une seule ligne. Développeur, analyste métier ou simplement lassé de la saisie manuelle : il y a de quoi vous servir dans les deux cas.
Pourquoi extraire des données produits Amazon ? (amazon scraper python, web scraping with python)
Amazon n’est pas seulement le premier détaillant en ligne de la planète : c’est aussi le plus vaste terrain de veille concurrentielle qui soit. Avec plus de 600 millions de produits répertoriés et près de 2 millions de vendeurs actifs, la marketplace devient une mine d’or dès qu’on cherche à :

- Surveiller les prix (et ajuster les vôtres en temps réel)
- Analyser les concurrents (suivre leurs lancements, leurs notes et leurs avis)
- Générer des leads (repérer vendeurs, fournisseurs ou partenaires potentiels)
- Anticiper la demande (en lisant les niveaux de stock et les classements de ventes)
- Détecter les tendances du marché (en exploitant avis et résultats de recherche)
Ce ne sont pas de simples promesses : des entreprises bien réelles en tirent un retour mesurable. Un distributeur d’électronique grand public s’est ainsi appuyé sur des prix Amazon extraits pour gagner 15 % de marge bénéficiaire, pendant qu’une autre marque voyait ses ventes progresser de 4 % et le temps de ses analystes fondre de 30 % une fois le suivi des prix concurrents automatisé.
Voici, en un coup d’œil, les principaux cas d’usage et le type de bénéfice à en attendre :
| Cas d’usage | Qui l’utilise | ROI / bénéfice typique |
|---|---|---|
| Surveillance des prix | E-commerce, opérations | +15 % ou plus de marge, +4 % de ventes, 30 % de temps analyste en moins |
| Analyse concurrentielle | Vente, produit, opérations | Ajustements de prix plus rapides, compétitivité accrue |
| Étude de marché (avis) | Produit, marketing | Itérations produit plus rapides, meilleurs textes publicitaires, insights SEO |
| Génération de leads | Vente | Plus de 3 000 leads/mois, plus de 8 heures économisées par commercial et par semaine |
| Prévision des stocks et de la demande | Opérations, supply chain | 20 % de surstock en moins, moins de ruptures |
| Détection des tendances | Marketing, dirigeants | Détection précoce des produits et catégories en vogue |
Dernier chiffre qui résume bien l’enjeu : plus de 90 % des organisations affirment désormais tirer une valeur mesurable de l’analyse de données. Ne pas extraire les données Amazon, c’est laisser filer à la fois des insights et de l’argent.
Aperçu : Amazon Scraper Python vs. outils d’extraction web sans code
Pour faire passer les données Amazon du navigateur à vos feuilles de calcul ou à vos tableaux de bord, deux grandes voies s’offrent à vous :
-
Amazon Scraper Python (web scraping with python) :
Vous écrivez votre propre script avec des bibliothèques Python comme Requests et BeautifulSoup. Le contrôle est total, mais il faut coder, déjouer les protections anti-bot et maintenir le script à chaque évolution du site d’Amazon.
-
Outils d’extraction web sans code (comme Thunderbit) :
Vous passez par un outil qui repère, sélectionne et extrait les données — sans aucune programmation. Les plus aboutis, comme Thunderbit, mobilisent même l’IA pour deviner quoi récupérer, parcourir sous-pages et pagination, puis exporter d’un trait vers Excel ou Google Sheets.
Voici comment les deux se positionnent :
| Critère | Scraper Python | Sans code (Thunderbit) |
|---|---|---|
| Temps de configuration | Élevé (installation, code, débogage) | Faible (installer l’extension) |
| Compétence requise | Codage requis | Aucune (pointer et cliquer) |
| Flexibilité | Illimitée | Élevée pour les cas d’usage courants |
| Maintenance | Vous corrigez le code | L’outil se met à jour tout seul |
| Gestion anti-bot | Vous gérez proxies et en-têtes | Intégré, géré pour vous |
| Scalabilité | Manuelle (threads, proxies) | Extraction cloud, parallélisée |
| Export des données | Personnalisé (CSV, Excel, base de données) | Vers Excel, Sheets en un clic |
| Coût | Gratuit (votre temps + proxies) | Freemium, payant à grande échelle |
Les sections suivantes déroulent les deux approches : d’abord la construction d’un extracteur Amazon en Python, code à l’appui ; ensuite la même opération confiée à l’extracteur web IA de Thunderbit.
Bien démarrer avec Amazon Scraper Python : prérequis et configuration
Avant d’écrire la moindre ligne, préparons votre environnement.
Il vous faudra :
- Python 3.x (à récupérer sur python.org)
- Un éditeur de code (VS Code a ma préférence, mais le vôtre fera très bien l’affaire)
- Les bibliothèques suivantes :
requests(pour les requêtes HTTP)beautifulsoup4(pour l’analyse HTML)lxml(analyseur HTML rapide)pandas(pour les tableaux de données et l’export)re(expressions régulières, intégré)
Installez les bibliothèques :
pip install requests beautifulsoup4 lxml pandas
Configuration du projet :
- Créez un nouveau dossier pour votre projet.
- Ouvrez votre éditeur, créez un nouveau fichier Python (par exemple
amazon_scraper.py). - Et voilà, vous pouvez attaquer.
Étape par étape : extraction web avec Python pour des données produits Amazon
Commençons par une seule page produit Amazon. (L’extraction de plusieurs produits sur plusieurs pages viendra juste après, rassurez-vous.)
1. Envoyer des requêtes et récupérer le HTML
Première chose : récupérer le HTML d’une fiche produit. (Remplacez l’URL par le produit Amazon de votre choix.)
import requests
url = "<https://www.amazon.com/dp/B0ExampleASIN>"
response = requests.get(url)
html_content = response.text
print(response.status_code)
Attention : telle quelle, cette requête a toutes les chances d’être bloquée par Amazon. À la place de la fiche produit, vous risquez une erreur 503 ou un CAPTCHA. La raison ? Amazon a tout de suite compris que vous n’êtes pas un vrai navigateur.
Gérer les protections anti-bot d’Amazon
Amazon a horreur des robots. Pour passer entre les mailles du filet, plusieurs réflexes s’imposent :
- Définir un en-tête User-Agent (faire passer la requête pour Chrome ou Firefox)
- Faire tourner les User-Agents (ne pas réutiliser le même à chaque fois)
- Espacer les requêtes (avec des délais aléatoires)
- Recourir à des proxies (pour l’extraction à grande échelle)
Voici comment renseigner les en-têtes :
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)... Safari/537.36",
"Accept-Language": "en-US,en;q=0.9",
}
response = requests.get(url, headers=headers)
Envie d’aller plus loin ? Constituez une liste de User-Agents et changez-en à chaque requête. Pour les gros volumes, un service de proxy devient indispensable (il en existe une foule), mais à petite échelle, en-têtes et délais font généralement l’affaire.
Extraire les champs clés du produit
Le HTML en poche, place à l’analyse avec BeautifulSoup.
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_content, "lxml")
Passons aux informations qui comptent vraiment :
Titre du produit
title_elem = soup.find(id="productTitle")
product_title = title_elem.get_text(strip=True) if title_elem else None
Prix
Le prix peut nicher à plusieurs endroits chez Amazon. Tentez ceci :
price = None
price_elem = soup.find(id="priceblock_ourprice") or soup.find(id="priceblock_dealprice")
if price_elem:
price = price_elem.get_text(strip=True)
else:
price_whole = soup.find("span", {"class": "a-price-whole"})
price_frac = soup.find("span", {"class": "a-price-fraction"})
if price_whole and price_frac:
price = price_whole.text + price_frac.text
Note et nombre d’avis
rating_elem = soup.find("span", {"class": "a-icon-alt"})
rating = rating_elem.get_text(strip=True) if rating_elem else None
review_count_elem = soup.find(id="acrCustomerReviewText")
reviews_text = review_count_elem.get_text(strip=True) if review_count_elem else ""
reviews_count = reviews_text.split()[0] # ex. : "1,554 ratings"
URL de l’image principale
Amazon dissimule parfois ses images haute résolution dans du JSON glissé au cœur du HTML. Une expression régulière permet de les débusquer rapidement :
import re
match = re.search(r'"hiRes":"(https://.*?.jpg)"', html_content)
main_image_url = match.group(1) if match else None
Vous pouvez aussi viser directement la balise de l’image principale :
img_tag = soup.find("img", {"id": "landingImage"})
img_url = img_tag['src'] if img_tag else None
Détails du produit
Les caractéristiques — marque, poids, dimensions — figurent le plus souvent dans un tableau :
details = {}
rows = soup.select("#productDetails_techSpec_section_1 tr")
for row in rows:
header = row.find("th").get_text(strip=True)
value = row.find("td").get_text(strip=True)
details[header] = value
Et si Amazon opte pour le format « detailBullets » :
bullets = soup.select("#detailBullets_feature_div li")
for li in bullets:
txt = li.get_text(" ", strip=True)
if ":" in txt:
key, val = txt.split(":", 1)
details[key.strip()] = val.strip()
Affichez le résultat :
print("Titre :", product_title)
print("Prix :", price)
print("Note :", rating, "sur", reviews_count, "avis")
print("URL de l’image principale :", main_image_url)
print("Détails :", details)
Extraire plusieurs produits et gérer la pagination
Un produit isolé, c’est un bon début, mais vous visez sans doute une liste complète. Voyons comment récolter les résultats de recherche et enchaîner les pages.
Récupérer les liens produits depuis une page de recherche
search_url = "<https://www.amazon.com/s?k=bluetooth+headphones>"
res = requests.get(search_url, headers=headers)
soup = BeautifulSoup(res.text, "lxml")
product_links = []
for a in soup.select("h2 a.a-link-normal"):
href = a['href']
full_url = "<https://www.amazon.com>" + href
product_links.append(full_url)
Gérer la pagination
Les URL de recherche Amazon s’appuient sur &page=2, &page=3, etc.
for page in range(1, 6): # extraire les 5 premières pages
search_url = f"<https://www.amazon.com/s?k=bluetooth+headphones&page={page}>"
res = requests.get(search_url, headers=headers)
if res.status_code != 200:
break
soup = BeautifulSoup(res.text, "lxml")
# ... extraire les liens produits comme ci-dessus ...
Parcourir les pages produits et exporter en CSV
Regroupez vos données dans une liste de dictionnaires, puis confiez le reste à pandas :
import pandas as pd
df = pd.DataFrame(product_data_list) # liste de dictionnaires
df.to_csv("amazon_products.csv", index=False)
Ou en direction d’Excel :
df.to_excel("amazon_products.xlsx", index=False)
Bonnes pratiques pour les projets Amazon Scraper Python
Soyons lucides : Amazon retouche son site en permanence et traque les extracteurs. Voici comment garder votre projet sur les rails :
- Faites tourner en-têtes et User-Agents (avec une bibliothèque comme
fake-useragent) - Recourez aux proxies pour l’extraction à grande échelle
- Espacez les requêtes (via des
time.sleep()aléatoires) - Gérez les erreurs avec soin (relancez en cas de 503, ralentissez si vous êtes bloqué)
- Écrivez une logique d’analyse souple (prévoyez plusieurs sélecteurs par champ)
- Surveillez les changements de HTML (si votre script ne renvoie soudain que des
None, inspectez la page) - Respectez robots.txt (Amazon interdit l’extraction de nombreuses sections — agissez de façon responsable)
- Nettoyez vos données à la volée (symboles monétaires, virgules, espaces parasites)
- Gardez le lien avec la communauté (forums, Stack Overflow, le subreddit r/webscraping)
Checklist pour entretenir votre extracteur :
- Faire tourner les User-Agents et les en-têtes
- Utiliser des proxies si vous extrayez à grande échelle
- Ajouter des délais aléatoires
- Modulariser le code pour faciliter les mises à jour
- Surveiller les bannissements ou les CAPTCHA
- Exporter les données régulièrement
- Documenter vos sélecteurs et votre logique
Pour creuser le sujet, jetez un œil à mon guide d’extraction de données web avec Python.
L’alternative sans code : extraire Amazon avec l’extracteur web IA Thunderbit
Extraire les données produit Amazon avec l’IA Get Started Free
Vous avez vu la méthode Python dans le détail. Mais si l’idée de coder ne vous emballe pas — ou si vous voulez juste les données en deux clics pour passer à autre chose ? C’est précisément le rôle de Thunderbit.
Thunderbit est une extension Chrome d’extraction web propulsée par l’IA, capable de récupérer des données produits Amazon (et celles de quasiment n’importe quel site) sans la moindre ligne de code. Ce qui me plaît dans cet outil :
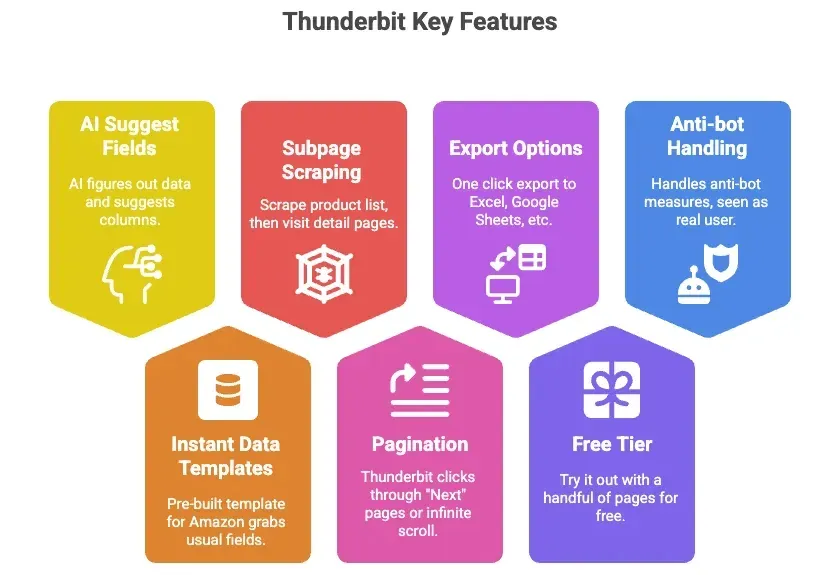
- Suggestion de champs par IA : un clic suffit, et l’IA de Thunderbit identifie les données présentes sur la page pour proposer les colonnes pertinentes (Titre, Prix, Note, etc.).
- Modèles de données prêts à l’emploi : pour Amazon, un modèle clé en main capte d’emblée tous les champs habituels — zéro configuration.
- Extraction de sous-pages : récupérez une liste de produits, et laissez Thunderbit visiter chaque fiche détaillée pour compléter automatiquement les informations.
- Pagination : Thunderbit clique pour vous sur « Suivant » ou déroule les listes à défilement infini.
- Export vers Excel, Google Sheets, Airtable, Notion : un clic, et vos données sont exploitables.
- Offre gratuite : essayez-le sans frais sur quelques pages.
- Anti-bot pris en charge à votre place : comme il s’exécute dans votre navigateur (ou dans le cloud), Amazon le perçoit comme un internaute ordinaire.
Étape par étape : utiliser Thunderbit pour extraire des données produits Amazon
Rien de plus simple :
-
Installez Thunderbit :
Téléchargez l’extension Chrome Thunderbit et connectez-vous.
-
Ouvrez Amazon :
Rendez-vous sur la page Amazon à extraire (résultats de recherche, fiche produit, peu importe).
-
Cliquez sur « Suggestion de champs par IA » ou choisissez un modèle :
Thunderbit vous propose des colonnes à extraire (ou laissez-le sur le modèle Amazon Product).
-
Vérifiez les colonnes :
Ajustez à votre guise (ajout/suppression de champs, renommage, etc.).
-
Cliquez sur « Extraire » :
Thunderbit récupère les données de la page et les range dans un tableau.
-
Gérez sous-pages et pagination :
Si vous avez extrait une liste, cliquez sur « Extraire les sous-pages » pour parcourir chaque fiche et récolter davantage d’informations. Thunderbit peut aussi enchaîner seul les pages « Suivant ».
-
Exportez vos données :
Cliquez sur « Exporter vers Excel » ou « Exporter vers Google Sheets ». C’est plié.
-
(Optionnel) Planifiez l’extraction :
Vous avez besoin de ces données chaque jour ? Le planificateur de Thunderbit s’en charge automatiquement.
Voilà, c’est tout. Pas de code, pas de débogage, pas de proxies, pas de migraine. Pour une démonstration en images, jetez un œil à la chaîne YouTube Thunderbit ou à la page du modèle Amazon Product Scraper.
Essayer le modèle Amazon Product Scraper
Amazon Scraper Python vs. extracteur web sans code : comparaison côte à côte
Faisons le point :
| Critère | Scraper Python | Thunderbit (sans code) |
|---|---|---|
| Temps de configuration | Élevé (installation, code, débogage) | Faible (installer l’extension) |
| Compétence requise | Codage requis | Aucune (pointer et cliquer) |
| Flexibilité | Illimitée | Élevée pour les cas d’usage courants |
| Maintenance | Vous corrigez le code | L’outil se met à jour tout seul |
| Gestion anti-bot | Vous gérez proxies et en-têtes | Intégré, géré pour vous |
| Scalabilité | Manuelle (threads, proxies) | Extraction cloud, parallélisée |
| Export des données | Personnalisé (CSV, Excel, base de données) | Vers Excel, Sheets en un clic |
| Coût | Gratuit (votre temps + proxies) | Freemium, payant à grande échelle |
| Idéal pour | Développeurs, besoins sur mesure | Utilisateurs métier, résultats rapides |
Si vous êtes développeur, que vous aimez mettre les mains dans le cambouis et qu’il vous faut du sur-mesure, Python reste votre meilleur allié. Si vous privilégiez la rapidité, la simplicité et le zéro code, Thunderbit l’emporte sans hésiter.
Quand choisir Python, le sans code ou un extracteur web IA pour les données Amazon
Optez pour Python si :
- Vous avez besoin d’une logique sur mesure ou voulez intégrer l’extraction à vos systèmes backend
- Vous extrayez à très grande échelle (des dizaines de milliers de produits)
- Vous voulez comprendre les rouages de l’extraction
Optez pour Thunderbit (sans code, extracteur web IA) si :
- Vous voulez des données vite, sans coder
- Vous êtes utilisateur métier, analyste ou marketeur
- Vous devez permettre à votre équipe de récupérer les données elle-même
- Vous voulez vous épargner la complexité des proxies, de l’anti-bot et de la maintenance
Combinez les deux si :
- Vous prototypez à toute vitesse avec Thunderbit avant de bâtir une solution Python sur mesure pour la production
- Vous confiez la collecte à Thunderbit et le nettoyage/l’analyse à Python
Pour la plupart des utilisateurs métier, Thunderbit couvre 90 % des besoins d’extraction Amazon en une fraction du temps. Pour les 10 % restants — l’ultra-personnalisé, le très grand volume, l’intégration profonde —, Python garde la couronne.
Conclusion et points clés à retenir
Comment extraire des produits et avis Amazon en 2025 avec l’IA Get Started Free
Savoir extraire les données produits Amazon, c’est un atout précieux pour toute équipe commerciale, e-commerce ou opérations. Suivre des prix, analyser ses concurrents ou simplement épargner à son équipe des heures de copier-coller : il existe forcément une approche adaptée.
- L’extraction en Python offre un contrôle total, au prix d’une courbe d’apprentissage et d’une maintenance continue.
- Les extracteurs sans code comme Thunderbit rendent les données Amazon accessibles à tous — sans code, sans casse-tête, juste des résultats.
- La meilleure approche ? Celle qui colle à vos compétences, à votre emploi du temps et à vos objectifs business.
Curieux de tester ? Thunderbit démarre gratuitement, et la vitesse à laquelle vous obtenez vos données risque de vous surprendre. Et si vous êtes développeur, rien ne vous empêche de mêler les deux : parfois, le plus efficace reste de laisser l’IA abattre les tâches répétitives.
Obtenir l’extension Chrome Thunderbit
FAQ
1. Pourquoi une entreprise voudrait-elle extraire des données produits Amazon ?
Extraire les données Amazon permet de surveiller les prix, d’analyser les concurrents, de collecter des avis pour la recherche produit, d’anticiper la demande et de générer des leads commerciaux. Avec plus de 600 millions de produits et près de 2 millions de vendeurs, la marketplace constitue une source de veille concurrentielle particulièrement riche.
2. Quelles sont les principales différences entre Python et les outils sans code comme Thunderbit pour extraire Amazon ?
Les extracteurs Python offrent une flexibilité maximale, mais exigent des compétences en codage, du temps de configuration et une maintenance continue. Thunderbit, extracteur web IA sans code, récupère instantanément les données Amazon via une extension Chrome — sans coder, avec gestion anti-bot intégrée et export vers Excel ou Sheets.
3. Est-il légal d’extraire des données depuis Amazon ?
Les conditions d’utilisation d’Amazon interdisent généralement l’extraction, et l’entreprise déploie activement des protections anti-bot. Cela dit, de nombreuses entreprises extraient malgré tout des données publiques en restant responsables, par exemple en respectant les limites de débit et en évitant les requêtes excessives.
4. Quels types de données puis-je extraire d’Amazon avec des outils d’extraction web ?
Les champs courants couvrent les titres produits, les prix, les notes, le nombre d’avis, les images, les caractéristiques techniques, la disponibilité et même les informations vendeur. Thunderbit prend aussi en charge l’extraction de sous-pages et la pagination pour capturer des données sur plusieurs fiches et plusieurs pages.
5. Quand privilégier Python plutôt qu’un outil comme Thunderbit, et inversement ?
Choisissez Python s’il vous faut un contrôle total, une logique sur mesure ou une intégration de l’extraction dans des systèmes backend. Choisissez Thunderbit si vous voulez des résultats rapides sans coder, monter en charge sans effort ou si vous êtes un utilisateur métier en quête d’une solution facile à maintenir.
Envie d’aller plus loin ? Voici quelques ressources :
- Blog Thunderbit
- Qu’est-ce que l’extraction de données et comment la faire en 2025
- Comment extraire des produits et avis Amazon en 2025 avec l’IA
- Guide de l’extraction web avec Python
Bonne extraction — et que vos feuilles de calcul restent toujours à jour.
Essayer l’extracteur web IA Thunderbit pour Amazon Get Started Free




