
Chaque Extracteur Web IA a l’air brillant dans sa démo produit. Puis vous le confrontez à un vrai site protégé par Cloudflare, et il vous renvoie une page de challenge tout en vous assurant avec aplomb qu’il a trouvé 47 fiches produits.
J’ai passé les derniers mois à évaluer des outils de scraping pour notre équipe chez Thunderbit. L’écart entre les performances en démo et la fiabilité en production reste, de loin, la principale source de frustration que je constate dans les communautés. Un utilisateur Reddit l’a parfaitement résumé : Avec rien que dans la catégorie des logiciels de scraping web, plus des dizaines d’autres extensions Chrome, fournisseurs d’API et marketplaces d’actors, le paradoxe du choix est bien réel. J’en ai donc testé 12.
Cet article évalue 12 outils d’Extracteur Web IA selon des critères de production : gestion anti-bot, passage à l’échelle, qualité de la sortie structurée, efficacité coûts, prise en charge des sites dynamiques et flexibilité pour les développeurs. Pas de listes de fonctionnalités. Pas de captures marketing. Juste ce qui fonctionne vraiment une fois la démo terminée.
Pourquoi la plupart des Extracteurs Web IA échouent après la démo
Le scénario est toujours le même. Le site marketing d’un outil montre une extraction de colonnes propres à partir d’une simple page de listing produits. Vous l’installez, vous l’essayez sur un site e-commerce protégé, et vous obtenez l’un de ces résultats :
- Une réponse
200 OKcontenant une page de challenge Cloudflare au lieu des vraies données - Des résultats propres pour les 5 premières pages, puis des échecs silencieux ou des lignes hallucinées
- Une extraction parfaite aujourd’hui, puis des sélecteurs cassés la semaine suivante après une légère modification de mise en page
Ce ne sont pas des cas extrêmes. C’est la norme.
Comme l’a dit un praticien : « Le scraper renvoie un 200 avec une page de challenge Cloudflare, votre agent essaie de l’interpréter, hallucine, et vous ne savez même pas pourquoi. »
Le problème de fond est architectural. La plupart des démos mettent en avant la couche d’analyse sur des pages publiques propres, alors que le vrai travail échoue dans la couche de récupération. Les sites de production ajoutent des protections anti-bot, du rendu dynamique, des pages de détail imbriquées, du défilement infini, des états de connexion, des variantes locales et des mises en page changeantes.
Un outil peut sembler excellent lors d’une démonstration et s’effondrer dès le premier vrai flux de travail client.
C’est pourquoi cet article évalue chaque outil sous l’angle de la préparation à la production plutôt que selon une simple liste de fonctionnalités. Voici les six critères utilisés :
| Critère | Pourquoi c’est important |
|---|---|
| Gestion anti-bot/CAPTCHA | Les sites protégés échouent avant même que la qualité d’extraction n’entre en jeu |
| Passage à l’échelle au-delà de la démo | Les traitements par lots et les exécutions parallèles révèlent les limites opérationnelles |
| Qualité de la sortie structurée | Les utilisateurs ont besoin de JSON/CSV propres, pas de HTML brut à nettoyer manuellement |
| Efficacité jetons/coûts | L’extraction IA peut coûter plus cher que le scraping lui-même |
| Prise en charge des sites dynamiques/lourds en JS | Les pages modernes exigent du DOM rendu, pas du HTML statique |
| Flexibilité sans code vs API | Les équipes commerciales et les ingénieurs data n’ont pas les mêmes besoins |
Si vous voulez un aperçu rapide du marché sur la manière dont le web scraping a évolué au cours des deux dernières années, cette présentation de Browserless constitue une bonne mise en contexte avant de comparer les outils un par un.
Là où l’IA aide vraiment dans un pipeline de scraping — et là où elle n’aide pas
Un mythe persistant dans ce marché veut que « Extracteur Web IA » signifie que l’IA gère tout de bout en bout. Le consensus de la communauté est remarquablement clair : . Le constat d’un utilisateur est sans détour : « Vous utilisez l’IA pour lire une capture d’écran d’une page web. Vous ne l’utilisez pas pour coder le scraper lui-même. »
Le pipeline de scraping comporte trois couches distinctes, et la valeur de l’IA varie énormément selon chacune d’elles :
Crawling et récupération : la couche infrastructure
C’est là que les requêtes s’exécutent : proxys, navigateurs sans tête, gestion de session, résolution de CAPTCHA, tentatives répétées. L’IA n’y apporte presque rien d’utile. Vous avez toujours besoin de pools de proxys, d’empreintes navigateur et d’une infrastructure de déblocage. C’est là que la plupart des outils échouent d’abord en production.
Analyse et extraction : là où l’IA excelle
Une fois le contenu de la page propre, l’IA excelle pour transformer du HTML non structuré en champs structurés. L’extraction basée sur un schéma, la détection adaptative des champs et la gestion des variantes de mise en page sans sélecteurs XPath fragiles constituent le point fort de l’IA dans le scraping.
Post-traitement : étiquetage, traduction, catégorisation
Après l’extraction, l’IA apporte de la valeur en catégorisant les produits, en traduisant du texte, en normalisant des numéros de téléphone ou en résumant des descriptions. C’est un excellent usage, mais seulement si les données extraites sont déjà correctes.
Voici comment les 12 outils se répartissent sur ces couches :
| Outil | Crawling/Récupération | Analyse/Extraction | Post-traitement | Meilleure description |
|---|---|---|---|---|
| Thunderbit | Fort | Fort | Fort | Extracteur IA no-code full stack |
| Octoparse | Fort | Moyen | Faible | Extracteur visuel fondé sur des règles avec infrastructure cloud |
| Browse AI | Moyen | Moyen | Moyen | Plateforme cloud de surveillance d’abord |
| Firecrawl | Moyen | Fort | Faible-Moyen | API d’extraction pour développeurs |
| Apify | Fort | Moyen-Fort | Moyen | Marketplace d’actors et orchestration |
| Gumloop | Moyen | Moyen | Fort | Automatisation de workflows avec nœuds de scraping |
| Bright Data | Très fort | Moyen | Faible-Moyen | Pile d’infrastructure entreprise |
| Bardeen | Moyen | Moyen | Fort | Automatisation navigateur pour les workflows GTM |
| Diffbot | Faible-Moyen | Très fort | Moyen | Extraction pré-entraînée avec knowledge graph |
| ScrapingBee | Fort | Faible-Moyen | Faible | API de récupération et de déblocage |
| Instant Data Scraper | Faible | Moyen (pages simples) | Faible | Scraper rapide heuristique côté navigateur |
| ParseHub | Moyen | Moyen | Faible | Scraper visuel de bureau pour interactions complexes |
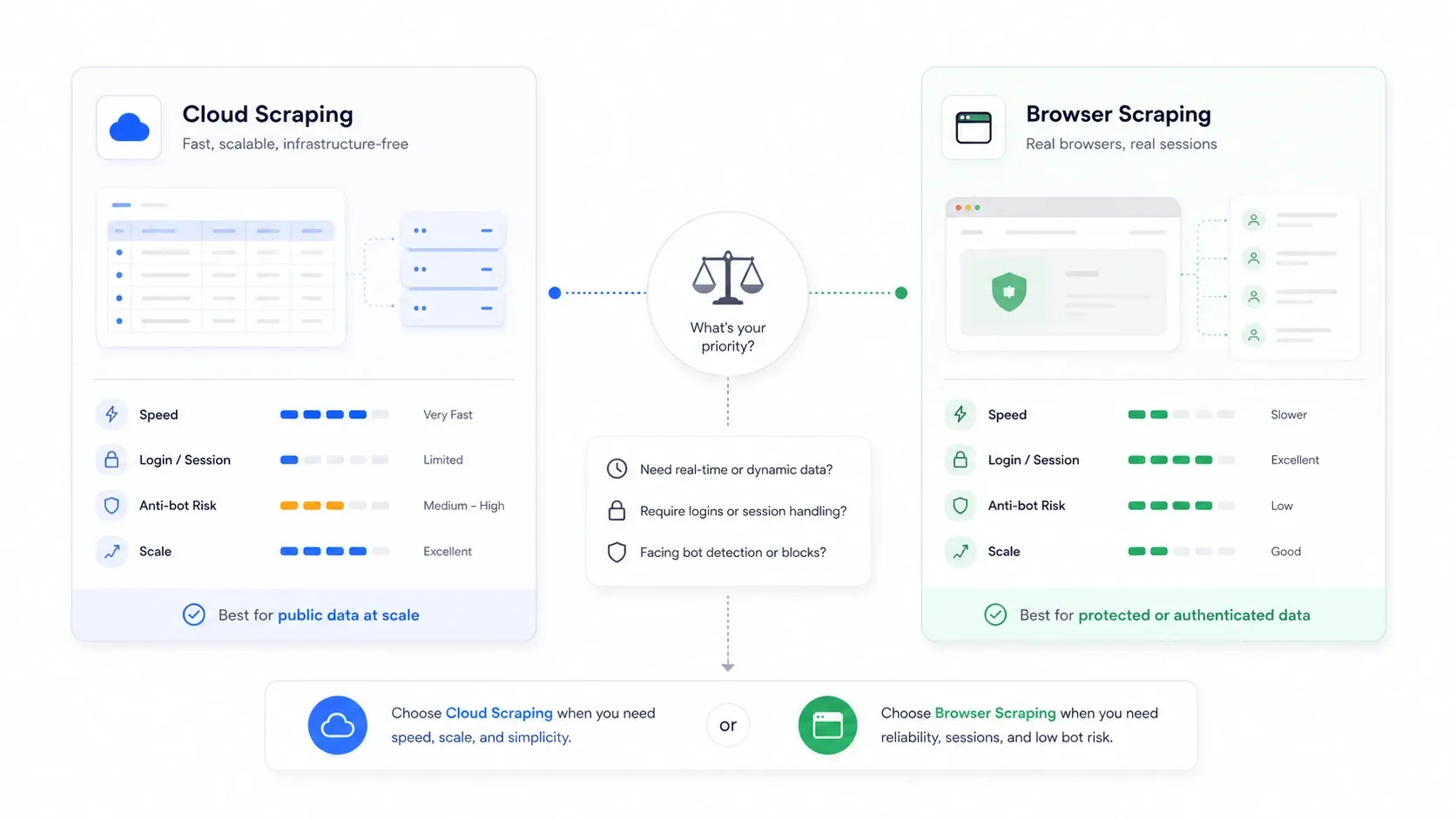
Scraping cloud vs scraping navigateur : le choix que personne n’explique
C’est la décision architecturale que la plupart des articles comparatifs ignorent complètement, et elle est souvent plus importante que le choix de l’outil.
Le scraping cloud signifie que des serveurs distants récupèrent les pages pour vous. Le scraping navigateur signifie que l’extraction s’effectue dans votre propre session de navigateur, avec vos cookies, votre IP et votre état d’authentification.
| Scénario | Meilleur mode | Pourquoi |
|---|---|---|
| Sites e-commerce publics et annuaires à volume élevé | Cloud | Parallélisme plus rapide et pas de goulot d’étranglement sur la machine locale |
| Sites nécessitant une connexion ou une authentification | Navigateur | Réutilise vos vrais cookies de session |
| Sites qui pénalisent les IP des datacenters | Navigateur | Se présente comme un trafic utilisateur normal |
| Gros travaux récurrents de surveillance | Cloud | Planification et continuité plus faciles |
| Travaux ponctuels, fragiles et sensibles à l’anti-bot | Navigateur | Plus simple pour voir ce que le site a réellement rendu |
L’enjeu est aussi économique. Le rapport 2026 de l’État du Web Scraping d’Apify a révélé que d’une année sur l’autre, et que ont déclaré des dépenses d’infrastructure plus élevées. L’anti-bot n’est pas seulement un problème technique. C’est aussi un problème de budget.
La plupart des outils ne proposent qu’un seul mode. Voici le détail :
| Outil | Cloud | Navigateur | Les deux |
|---|---|---|---|
| Thunderbit | ✅ | ✅ | ✅ |
| Octoparse | ✅ | ✅ (local) | ✅ |
| Browse AI | ✅ | Configuration uniquement | — |
| Firecrawl | ✅ | API pour l’interactif | — |
| Apify | ✅ | ✅ (via des actors) | ✅ |
| Gumloop | ✅ | ✅ (Web Agent) | ✅ |
| Bright Data | ✅ | ✅ | ✅ |
| Bardeen | Limité (pages publiques) | ✅ | Partiel |
| Diffbot | ✅ | — | — |
| ScrapingBee | ✅ | — | — |
| Instant Data Scraper | — | ✅ | — |
| ParseHub | ✅ (payant) | ✅ (bureau) | ✅ |
Les 12 Extracteurs Web IA en un coup d’œil
Voici la comparaison générale des 12 outils :
| Outil | Idéal pour | Offre gratuite | Cloud/Navigateur | Accès API | Scraping programmé | Gestion anti-bot |
|---|---|---|---|---|---|---|
| Thunderbit | Équipes non techniques | ✅ (6 pages) | Les deux | ✅ | ✅ | Forte |
| Octoparse | Scraping à base de modèles | ✅ (limité) | Les deux | ✅ | ✅ | Modérée-forte |
| Browse AI | Surveillance des changements | ✅ (limité) | Principalement cloud | ✅ | ✅ | Modérée |
| Firecrawl | Pipelines d’extraction pour développeurs | ✅ (1 000 crédits/mois) | Cloud plus API navigateur | ✅ | Non | Modérée |
| Apify | Équipes dev + marketplace | ✅ (5 $ d’usage gratuit) | Les deux | ✅ | ✅ | Forte avec modules additionnels |
| Gumloop | Automatisation de workflows | ✅ (5 000 crédits/mois) | Les deux | ✅ | ✅ | Moyenne |
| Bright Data | Accès aux données entreprise | Essai / crédits | Les deux | ✅ | Externe | Très forte |
| Bardeen | Automatisation navigateur pour les équipes sales et ops | ✅ (100 crédits) | Navigateur d’abord | Limité | ✅ | Moyenne-faible |
| Diffbot | API d’extraction structurée | ✅ (10 000 crédits) | Cloud | ✅ | Non | Faible pour la récupération / forte pour l’extraction |
| ScrapingBee | Récupération et déblocage pour développeurs | ✅ (1 000 crédits) | Cloud | ✅ | Non | Forte |
| Instant Data Scraper | Scrapes ponctuels gratuits | ✅ (entièrement gratuit) | Navigateur uniquement | Non | Non | Faible |
| ParseHub | Workflows visuels complexes | ✅ (5 projets) | Bureau plus cloud | ✅ | ✅ (payant) | Moyenne |
1. Thunderbit
est l’Extracteur Web IA que nous avons conçu spécifiquement pour les équipes non techniques qui ont besoin de données de qualité production sans écrire de code ni gérer d’infrastructure. Le flux de travail principal tient vraiment en deux clics : AI Suggest Fields lit la page et propose des colonnes, puis Scrape lance l’extraction en mode cloud ou navigateur.
Ce qui le distingue des autres scrapers no-code, c’est son architecture. Thunderbit sépare les préoccupations de crawling, comme l’infrastructure cloud, la rotation des proxys, la gestion anti-bot et le rendu JavaScript, de l’extraction IA qui lit le HTML et produit des colonnes structurées. Cela correspond au modèle recommandé par les experts — « scraper d’abord, LLM ensuite » — mais emballé dans une extension Chrome que les commerciaux et les responsables opérations peuvent réellement utiliser.
Points forts
- Scraping cloud et navigateur dans une seule interface. Passez d’un mode à l’autre selon que le site cible est public ou qu’il nécessite votre session authentifiée. Le mode cloud gère jusqu’à 50 pages en parallèle.
- L’IA relit la structure de la page à chaque fois. Aucun XPath à maintenir. Lorsqu’un site modifie sa mise en page, Thunderbit s’adapte automatiquement au lancement suivant.
- Scraping de sous-pages. L’IA visite les pages de détail liées et enrichit le tableau principal sans configuration manuelle.
- Field AI Prompts. Étiquetage, traduction et catégorisation personnalisés pendant l’extraction, au lieu d’une étape de post-traitement séparée.
- Exports gratuits vers Google Sheets, Excel, Airtable et Notion.
- Modèles de scraper instantanés pour des sites populaires comme Amazon, Zillow et LinkedIn.
- Planification en langage naturel. Dites-lui « extraire tous les lundis à 9 h » et il convertit cela en tâche récurrente.
- API ouverte avec les endpoints Distill et Extract, traitement par lots jusqu’à 100 URL, et concurrence publiée de 2 en gratuit à 50 en Pro 1.
Ce qui pourrait être amélioré
- L’offre gratuite est volontairement limitée.
- L’expérience no-code repose surtout sur l’extension Chrome. Les développeurs qui veulent des flux de travail exclusivement API doivent utiliser l’Open API séparément.
- Ce n’est pas l’outil idéal si votre besoin principal est une simple infrastructure de proxys sans extraction.
Tarifs
Offre gratuite disponible. Les formules no-code démarrent à 9 $/mois facturés à l’année ou 15 $/mois pour Starter. La tarification API est distincte : 600 unités en gratuit unique, puis 16 $/mois facturés à l’année pour Starter API et 40 $/mois facturés à l’année pour Pro 1 API. Voir et .
Idéal pour : Les équipes commerciales, e-commerce et opérations qui ont besoin de données web structurées sans soutien d’ingénierie.
2. Octoparse
est un constructeur visuel de workflows pour le scraping web avec une grande bibliothèque de modèles préconstruits. L’outil existe depuis assez longtemps pour disposer d’une infrastructure cloud mature, et il gère bien la pagination sur les sites structurés et prévisibles.
Points forts
- Nombreux modèles de scraping préconstruits pour des sites populaires
- Extraction cloud avec exécutions planifiées
- Rotation d’IP et résolution de CAPTCHA en modules payants
- Accès API sur les offres supérieures
Ce qui pourrait être amélioré
- Les capacités IA sont moins avancées que celles des outils nativement fondés sur des LLM. La suggestion de champs repose encore davantage sur des modèles que sur une lecture adaptative.
- Les mises en page complexes ou inhabituelles exigent beaucoup de réglages manuels dans l’éditeur visuel.
- La courbe d’apprentissage se creuse dès que vous avez besoin de logique conditionnelle ou de contournements anti-blocage.
Tarifs
Offre gratuite à vie disponible. La page d’aide officielle renvoie actuellement à Standard à partir de 75 $/mois facturés à l’année et Professional à partir de 208 $/mois facturés à l’année, tandis que certaines pages localisées et certains parcours de mise à niveau affichent des équivalents mensuels plus élevés. L’essentiel à retenir est qu’Octoparse combine désormais des abonnements avec des modules payants tels que les proxys résidentiels et la résolution de CAPTCHA.
Idéal pour : Les analystes et équipes ops qui extraient des données sur des sites structurés et compatibles avec les modèles, à une échelle modérée.
3. Browse AI
est une plateforme no-code basée sur le cloud, conçue principalement pour la surveillance des changements de site dans le temps, comme les prix des concurrents, la disponibilité des stocks et les mises à jour de contenu. Le scraping fait partie du produit, mais le vrai différenciateur est le système récurrent de surveillance et d’alertes.
Points forts
- Détection de changements et alertes intégrées
- Enregistreur de robots no-code avec configuration en point-and-click
- Robots préconstruits pour des sites populaires
- Support de proxys premium sur les offres supérieures
Ce qui pourrait être amélioré
- La tarification à base de crédits devient vite coûteuse lorsqu’on surveille des pages de détail à grande échelle
- Moins convaincant pour l’extraction ponctuelle à grande échelle que les outils API-first
- Gestion anti-bot modérée ; certains sites exigent encore des proxys premium ou des contournements
Tarifs
Compte gratuit disponible. Les formules payantes démarrent autour de 19 $/mois facturés à l’année pour Starter, avec des niveaux plus élevés de crédits et de surveillance au-dessus.
Idéal pour : Les équipes qui ont besoin d’une surveillance continue des prix concurrents, des changements de contenu ou des niveaux de stock, plutôt que d’une extraction massive ponctuelle.
4. Firecrawl
est une API pensée pour les développeurs qui convertit des pages web en Markdown propre ou en JSON structuré. Elle se situe principalement dans la couche d’extraction et convient parfaitement aux équipes qui construisent des pipelines RAG ou alimentent des LLM avec du contenu web.
Points forts
- Excellente qualité de sortie Markdown pour les workflows LLM en aval
- API propre avec scrape, crawl, map, search, extract et actions navigateur
- Prise en charge du traitement par lots
- Concurrence de 2 en gratuit à 100 en Growth
Ce qui pourrait être amélioré
- Aucune interface no-code et des compétences de développeur sont nécessaires
- Une aide intégrée via proxys et anti-bot existe, mais Firecrawl n’est pas positionné comme un fournisseur spécialisé de déblocage
- Pas de planificateur natif pour les tâches récurrentes
- Peu rentable pour les non-développeurs qui veulent simplement un tableau de données
Tarifs
L’offre gratuite inclut 1 000 crédits par mois. Les formules payantes commencent à 16 $/mois à l’année pour Hobby et montent avec davantage de crédits, de concurrence et d’usage du navigateur. Les sessions navigateur sont facturées séparément en crédits.
Idéal pour : Les développeurs qui construisent des pipelines LLM, des systèmes RAG ou des workflows d’extraction sur mesure et qui ont besoin de Markdown ou de JSON propres depuis des pages web.
5. Apify
est une plateforme avec une marketplace d’actors de scraping préconstruits, ainsi que des outils pour en créer des personnalisés. Voyez-la comme une couche d’orchestration où vous choisissez ou construisez des scrapers spécialisés pour des sites précis, puis vous les planifiez et les gérez via une API unifiée.
Points forts
- Immense marketplace d’actors avec des scrapers construits par la communauté pour des centaines de sites
- API et SDK solides pour les développeurs
- Gestion des proxys et planification intégrées
- S’intègre à de nombreux outils en aval
Ce qui pourrait être amélioré
- Le « no-code » n’est que partiellement vrai dès que vous quittez la marketplace et avez besoin de logique personnalisée
- La fiabilité des actors dépend de la maintenance communautaire
- Les coûts peuvent grimper rapidement, car le calcul, les actors et les proxys s’additionnent
Tarifs
L’offre gratuite inclut 5 $ de crédits plateforme par mois. Les formules payantes commencent à 39 $/mois pour Starter, avec des paliers orientés montée en charge au-dessus.
Idéal pour : Les équipes de développement qui veulent des workflows de scraping réutilisables et planifiables, avec un vaste écosystème de solutions prêtes à l’emploi.
6. Gumloop
est une plateforme d’automatisation de workflows no-code qui inclut un nœud de scraping web. La vraie valeur ne réside pas dans le scraping seul, mais dans le fait de connecter l’extraction aux LLM, à Google Sheets, aux CRM et à d’autres outils dans une seule toile visuelle.
Points forts
- Constructeur visuel de workflows par glisser-déposer
- Intègre le scraping aux LLM et aux outils métiers en aval dans un seul flux
- L’offre gratuite est actuellement annoncée à 5 000 crédits/mois
- Planification horaire pour les workflows récurrents
- Le scraping basique et le mode Web Agent interactif couvrent à la fois des flux simples et plus riches
Ce qui pourrait être amélioré
- Le moteur de scraping est moins robuste que celui des outils dédiés à l’Extracteur Web IA
- Gestion anti-bot et profondeur de proxys plus limitées que chez les fournisseurs spécialisés
- Les limites de concurrence et de déclencheurs sont plus serrées sur les offres gratuites
- Peu adapté au scraping massif à très fort volume comme cas d’usage principal
Tarifs
Offre gratuite disponible. Gumloop a fusionné son ancienne structure Solo et Team dans une offre Pro fin 2025, et la communication publique depuis met davantage l’accent sur des crédits gratuits plus généreux et des paliers payants consolidés que sur une tarification centrée sur le scraping.
Idéal pour : Les équipes qui veulent intégrer le scraping comme une étape d’un workflow automatisé plus large : extraire, analyser et pousser dans les outils métiers.
Si vous voulez voir à quoi ressemble concrètement un workflow d’extraction natif IA avant de lire la suite de la liste, ce guide Thunderbit est la démonstration produit la plus pertinente pour les équipes non techniques.
7. Bright Data
est la pile d’infrastructure de niveau entreprise de cette liste. Si votre problème est « je n’arrive pas à franchir la protection anti-bot de ce site, quoi que j’essaie », Bright Data est probablement la réponse, mais cela s’accompagne d’une complexité et d’une tarification d’entreprise.
Points forts
- Réseau de proxys leader du secteur, couvrant les IP résidentielles, datacenter et mobiles
- Web Unlocker pour contourner l’anti-bot et les CAPTCHA
- Scraping Browser avec déblocage intégré
- Jeux de données précollectés disponibles à l’achat
- Contrôle programmatique complet via API et SDK
Ce qui pourrait être amélioré
- Pas conçu pour les utilisateurs non techniques
- La tarification reflète son positionnement entreprise
- L’extraction IA n’est pas la raison principale d’acheter la plateforme
Tarifs
L’API navigateur démarre à 8 $/Go en paiement à l’usage, avec des tarifs par Go plus bas sur les engagements mensuels plus importants. D’autres produits Bright Data, comme Unlocker, les Scraper APIs, les datasets et les pools de proxys, utilisent d’autres unités tarifaires.
Idéal pour : Les équipes data entreprise qui doivent extraire à grande échelle des sites fortement protégés et disposent du personnel technique pour gérer l’infrastructure.
8. Bardeen
est un outil d’automatisation navigateur centré sur les clics, le remplissage de formulaires et le scraping, avec une extraction de données alimentée par l’IA par-dessus. Il faut surtout le voir comme un outil de workflows GTM qui scrape, et non comme un outil de scraping qui fait aussi du GTM.
Points forts
- Automatisation intuitive en mode playbook, avec le scraping comme une étape
- Scrapers officiels maintenus par l’équipe Bardeen pour des sites populaires
- Intégrations solides avec CRM, Google Sheets, Slack et d’autres outils métiers
- Bien adapté au scraping de prospects, à l’enrichissement et aux workflows d’export vers le CRM
Ce qui pourrait être amélioré
- L’architecture centrée navigateur limite le scraping massif sans surveillance
- Le scraping cloud ne fonctionne que sur des pages publiques, pas sur des pages verrouillées
- La gestion anti-bot se limite en grande partie à ce que votre session navigateur fournit déjà
- L’extraction IA peut avoir du mal avec des mises en page complexes ou non standard
Tarifs
L’offre gratuite inclut 100 crédits mensuels. La documentation publique d’assistance fait référence à un ancien tarif Pro à 15 $/mois pour les utilisateurs existants, tandis que l’offre commerciale actuelle de Bardeen est davantage orientée entreprise et automatisation de workflows que tarification classique de scraper d’entrée de gamme.
Idéal pour : Les équipes sales et ops qui ont besoin du scraping comme partie d’un workflow plus large d’automatisation navigateur.
9. Diffbot
utilise la vision par ordinateur et le NLP pour lire les pages web comme un humain, puis produire des données structurées pour les articles, produits, discussions et organisations. C’est l’une des API d’extraction de la plus haute qualité si vos pages correspondent à ses modèles pré-entraînés.
Points forts
- Modèles d’extraction pré-entraînés pour les articles, produits, discussions et plus encore
- Knowledge Graph avec des milliards d’entités pour enrichir les données
- Excellente qualité de sortie structurée sur les types de pages pris en charge
- API développeur claire avec des limites de débit publiées
Ce qui pourrait être amélioré
- Aucune interface no-code
- Pas de crawling intégré, de gestion des proxys ni de gestion anti-bot
- Coûteux pour les petites équipes
- Moins flexible sur les types de pages non standards que les extracteurs basés sur des schémas et prompts
Tarifs
L’offre gratuite inclut 10 000 crédits. Startup est à 299 $/mois pour 250 000 crédits, et Plus est à 899 $/mois pour 1 000 000 de crédits.
Idéal pour : Les équipes de développement qui ont besoin d’une extraction structurée très précise à partir de types de pages standard et sont prêtes à gérer la récupération séparément.
10. ScrapingBee
est une API de scraping web centrée sur la couche de récupération et de déblocage. Vous lui envoyez une URL, elle gère les proxys, le rendu via navigateur sans tête et les défenses anti-bot, puis elle renvoie du HTML ou, en option, des données extraites.
Points forts
- Rotation de proxys et gestion anti-bot intégrées
- Prise en charge du rendu JavaScript
- API REST simple
- Point de terminaison pour scraper Google Search
- Concurrence publiée selon l’offre
Ce qui pourrait être amélioré
- Les fonctions d’extraction IA sont limitées
- Pas d’interface no-code
- Pas de planification ni de surveillance intégrées
- Une réponse
200avec une page bloquée peut tout de même compter comme une requête réussie
Tarifs
L’offre gratuite inclut 1 000 crédits API. Les formules payantes commencent à 49 $/mois et montent avec une concurrence et un volume de requêtes plus élevés.
Idéal pour : Les développeurs qui ont principalement besoin d’une récupération fiable des pages malgré les défenses anti-bot et qui gèreront l’extraction avec leur propre code ou un outil séparé.
11. Instant Data Scraper
est une extension Chrome gratuite avec plus de 1 000 000 d’utilisateurs qui détecte automatiquement les motifs de données sur une page et permet l’export en CSV ou Excel. Il n’y a pas de suggestion de champs IA au sens LLM. Elle utilise une détection heuristique des motifs.
Points forts
- Entièrement gratuit, sans compte requis
- Détection de données en un clic sur de nombreuses pages de listing et de tableaux
- Gère la pagination sur certains sites
- Barrière d’entrée extrêmement faible
- Toujours maintenu, avec des mises à jour sur le Chrome Web Store en 2026
Ce qui pourrait être amélioré
- Pas de suggestion de champs ni d’étiquetage des données pilotés par l’IA
- Pas de scraping cloud, pas de planification, pas d’API
- Difficultés avec les mises en page complexes, le contenu dynamique et les sites lourds en JS
- Pas de gestion anti-bot au-delà de ce que votre navigateur peut déjà charger
- Export limité à CSV et Excel
Tarifs
Gratuit. À vie.
Idéal pour : Toute personne qui a besoin d’un scraping rapide et ponctuel d’une page de listing simple et qui ne veut ni créer de compte ni payer quoi que ce soit.
12. ParseHub
est une application de bureau avec une interface visuelle en point-and-click pour créer des projets de scraping. Elle peut gérer des données imbriquées complexes, du contenu chargé en AJAX, le défilement infini et les interactions avec menus déroulants que des extensions plus simples ratent souvent.
Points forts
- Interface de sélection visuelle pour définir les règles d’extraction
- Gère les données imbriquées, les menus déroulants, le défilement infini et le contenu AJAX
- Offre gratuite avec jusqu’à 5 projets
- Export vers JSON, CSV et Excel
- Planification cloud et rotation d’IP sur les offres payantes
Ce qui pourrait être amélioré
- Flux de travail uniquement sur bureau, sans la commodité d’une extension navigateur
- Exécution plus lente que les outils natifs cloud
- Les projets se cassent lorsque les mises en page changent, car il n’y a pas de couche IA de relecture
- Capacités IA limitées et sensation plus ancienne d’outil visuel de scraping
Tarifs
Offre gratuite disponible avec 5 projets et 200 pages par exécution. Les formules payantes commencent à 189 $/mois avec planification, rotation d’IP et limites plus élevées.
Idéal pour : Les utilisateurs non techniques qui doivent extraire des sites interactifs complexes et sont prêts à investir du temps dans la configuration visuelle du workflow.
Comment démarrer avec un Extracteur Web IA en 5 étapes
Chaque outil de cette liste possède un parcours d’intégration différent. Je vais utiliser Thunderbit comme exemple concret, car il correspond le mieux à l’intention de recherche « j’ai juste besoin que ça fonctionne sur une vraie page ».
Étape 1 : Installer et naviguer
Installez l’ et rendez-vous sur la page que vous souhaitez extraire : une liste de produits, un annuaire ou un portail immobilier.
Étape 2 : Laissez l’IA suggérer vos champs de données
Cliquez sur AI Suggest Fields. L’IA lit la page actuelle et propose des noms de colonnes ainsi que des types de données. Sur une page produit, elle peut suggérer Nom du produit, Prix, Note, URL de l’image et Description.
Étape 3 : Personnaliser les champs avec des invites IA
Ajustez les colonnes si les valeurs par défaut ne conviennent pas tout à fait. Ajoutez des Field AI Prompts pour des transformations personnalisées telles que « traduire la description en espagnol », « classer en Électronique, Maison ou Mode » ou « extraire uniquement le prix numérique ».
Étape 4 : Choisir le mode cloud ou navigateur et lancer l’extraction
Sélectionnez le scraping cloud pour les sites publics ou le scraping navigateur pour les cibles authentifiées ou fortement protégées. Puis cliquez sur Scrape.
Étape 5 : Exporter vos données partout
Exportez les résultats vers Google Sheets, Excel, Airtable ou Notion. Les exports sont gratuits.
Et si la mise en page du site change ?
C’est là l’avantage production clé des extracteurs natifs IA par rapport aux outils fondés sur des règles. Les scrapers traditionnels comme ParseHub et les anciens workflows Octoparse reposent sur des sélecteurs XPath ou des chemins CSS. Lorsqu’un site modifie sa structure HTML, ces sélecteurs cassent et vous devez tout reconfigurer manuellement.
Les extracteurs alimentés par l’IA comme Thunderbit relisent la structure de la page à chaque exécution. Cela signifie aucun XPath à maintenir et aucun sélecteur fragile. L’IA s’adapte automatiquement aux changements de mise en page lors de l’exécution suivante.
Scraping programmé et accès API : les fonctions avancées que personne ne teste
Les scrapes ponctuels suffisent pour la recherche. Les cas d’usage en production, comme la surveillance des prix, l’actualisation de listes de prospects et le suivi des stocks, exigent une extraction récurrente et un accès programmatique. Ces fonctions séparent les gadgets des vrais outils.
Prise en charge de la planification
| Outil | Planification native | Remarques |
|---|---|---|
| Thunderbit | ✅ | Configuration en langage naturel |
| Octoparse | ✅ | Exécutions cloud planifiées |
| Browse AI | ✅ | Fonction principale du produit |
| Firecrawl | ❌ | Utiliser un cron externe |
| Apify | ✅ | Expressions cron complètes |
| Gumloop | ✅ | Déclencheurs de workflow basés sur le temps |
| Bright Data | Externe | Généralement orchestré via les systèmes du client |
| Bardeen | ✅ | Planification des playbooks |
| Diffbot | ❌ | API d’abord, orchestration externe |
| ScrapingBee | ❌ | API uniquement |
| Instant Data Scraper | ❌ | Outil manuel côté navigateur |
| ParseHub | ✅ (payant) | Fonction premium |
Comparaison des API pour développeurs
| Outil | Signal de concurrence ou de débit | Modèle tarifaire |
|---|---|---|
| Thunderbit | 2 → 50 requêtes concurrentes | Basé sur des crédits |
| Firecrawl | 2 → 100 requêtes concurrentes | Basé sur des crédits |
| Apify | Dépend de l’offre | Unités de calcul |
| Gumloop | Concurrence de workflow limitée par l’offre | Basé sur des crédits |
| Diffbot | 5 appels/min → 25 appels/sec | Basé sur des crédits |
| ScrapingBee | 10 → 200 requêtes concurrentes | Crédits API |
| Bright Data | L’API navigateur annonce des requêtes concurrentes illimitées | Basé sur les Go |
Si votre cas d’usage est plus technique et que vous cherchez à décider combien d’infrastructure vous souhaitez réellement posséder, ce guide Firecrawl constitue un complément orienté exécution utile aux comparatifs ci-dessus.
Comment choisir le bon Extracteur Web IA
Après avoir testé les 12 outils, voici comment je déciderais :
- Équipe non technique qui a besoin de données rapidement : Commencez avec Thunderbit. Le workflow en deux clics, les exports gratuits et le basculement navigateur/cloud couvrent la plupart des besoins métiers sans support d’ingénierie.
- Besoin de surveillance continue et d’alertes : Browse AI est conçu pour cela. Ce n’est pas l’extracteur ponctuel le plus puissant, mais la détection de changements est une fonctionnalité de premier plan.
- Développeur qui construit un pipeline LLM : Firecrawl pour une extraction Markdown ou JSON, ou Diffbot pour une extraction structurée pré-entraînée. Associez l’un ou l’autre à ScrapingBee ou Bright Data si vous avez besoin d’une vraie gestion anti-bot dans la couche de récupération.
- Besoin d’une marketplace de scrapers préconstruits : Apify possède le plus grand écosystème d’actors. Préparez-vous simplement à la maintenance lorsque les actors cassent.
- Cibles protégées à l’échelle entreprise : Bright Data. Rien d’autre n’égale son infrastructure proxy, mais prévoyez le budget et les ressources techniques en conséquence.
- Vous voulez intégrer le scraping dans une automatisation plus large : Gumloop ou Bardeen, selon que vous automatisez des workflows ou des tâches GTM basées navigateur.
- Vous avez juste besoin d’un scrape gratuit et rapide : Instant Data Scraper. Aucune configuration, aucun coût, aucune complexité, mais aussi aucun planning, aucune IA et aucun cloud.
- Sites interactifs complexes avec menus déroulants et AJAX : ParseHub gère encore cela mieux que la plupart des extensions, même si la charge de maintenance est bien réelle.
Conclusion
Le marché des Extracteurs Web IA en 2026 est saturé d’outils impressionnants en démo, mais décevants en production. L’écart entre « fonctionne sur une capture marketing » et « fonctionne sur un site e-commerce protégé à 3 h du matin selon un planning » est l’endroit où la plupart des acheteurs perdent du temps et de l’argent.
L’enseignement principal de l’évaluation des 12 outils est simple : la couche de récupération reste la partie la plus difficile. L’IA excelle dans l’extraction et le post-traitement, mais elle ne remplace pas l’infrastructure de proxys, la gestion anti-bot ou la gestion de session. Les meilleurs outils couvrent les deux couches, comme Thunderbit et Bright Data, ou indiquent clairement celle qu’ils prennent en charge, comme Firecrawl pour l’extraction et ScrapingBee pour la récupération.
Si vous voulez voir à quoi ressemble un Extracteur Web IA prêt pour la production sans écrire de code, . L’offre gratuite suffit pour tester le flux complet sur de vraies pages. Si vos besoins sont plus orientés développeur, associez une API d’extraction à un service de récupération dédié et épargnez-vous la frustration d’attendre d’un seul outil qu’il fasse tout.
FAQ
Pourquoi la plupart des Extracteurs Web IA échouent-ils sur de vrais sites alors qu’ils fonctionnent bien en démo ?
Les démos montrent généralement l’extraction sur des pages propres et non protégées. Les vrais sites ajoutent la protection Cloudflare, le rendu JavaScript dynamique, la pagination, des exigences de connexion et des mises en page qui changent souvent. La plupart des outils gèrent bien la couche d’analyse et d’extraction, mais manquent d’une infrastructure robuste pour la couche de récupération.
Quelle est la différence entre le scraping cloud et le scraping navigateur, et quand utiliser l’un ou l’autre ?
Le scraping cloud utilise des serveurs distants pour récupérer les pages, ce qui est plus rapide, parallèle et scalable. Le scraping navigateur s’exécute dans votre propre session et convient mieux aux sites authentifiés ou à forte détection de bots. Thunderbit fait partie des rares outils à proposer les deux modes dans la même interface.
Puis-je utiliser un Extracteur Web IA pour des tâches récurrentes comme la surveillance des prix ?
Oui, mais seulement si l’outil prend en charge le scraping programmé. Thunderbit, Octoparse, Browse AI, Apify, Gumloop, Bardeen et ParseHub sur les offres payantes proposent tous la planification.
Quel Extracteur Web IA est le meilleur si je n’ai aucune compétence en code ?
Thunderbit offre la voie la plus rapide vers des données exploitables pour les utilisateurs non techniques. Instant Data Scraper est entièrement gratuit mais limité aux pages simples. Browse AI et Octoparse proposent des interfaces visuelles avec davantage de configuration. ParseHub est puissant pour les sites interactifs complexes, mais sa prise en main est plus exigeante.
Combien coûte réellement le scraping web IA de niveau production ?
La fourchette est large. Instant Data Scraper est gratuit. Thunderbit, Firecrawl et Browse AI proposent des points d’entrée gratuits avec des offres payantes abordables. Des outils de milieu de gamme comme Octoparse, ParseHub et ScrapingBee peuvent coûter d’environ 49 à 189 $ par mois. Les solutions entreprise comme Bright Data et Diffbot commencent beaucoup plus haut.