

Un souvenir qui m’a marqué. Il y a quelques années, j’ai donné un coup de main à une équipe commerciale qui lançait une grosse campagne. Sur le papier, tout était nickel : les emails calés, les offres ciselées, le CRM rempli de milliers de prospects. Sauf qu’au lancement, 30 % des emails sont revenus en erreur. En creusant, on s’est rendu compte que la base débordait de coquilles, de champs vides et de doublons. L’équipe a passé des jours à tout remettre en ordre, et au passage, on a vu filer un paquet d’occasions. C’est ce jour-là que j’ai pigé un truc : même une minuscule erreur de saisie peut coûter une fortune à une boîte.
Des années après, je constate que beaucoup d’entreprises, des géants comme des TPE, se cassent encore les dents sur les mêmes galères. La bonne nouvelle ? Aujourd’hui, les outils IA savent débusquer (et même réparer) la plupart de ces erreurs avant qu’elles ne fassent des ravages. En tant que cofondateur de Thunderbit, j’ai vu de mes propres yeux à quel point la techno peut transformer la saisie de données : plus fiable, et nettement moins pénible. On va passer en revue ensemble les erreurs de saisie les plus fréquentes, leurs causes, et la façon dont l’IA rebat les cartes au quotidien.
Pourquoi la qualité de la saisie, c’est vital pour n’importe quelle boîte
Qu’est-ce que le data scraping et comment le faire en 2025 Get Started Free
La saisie de données, c’est le travail de l’ombre qui fait tourner toute la machine. Que tu sois dans la vente, le marketing, l’e-commerce ou l’immobilier, tes décisions ne valent jamais plus que tes données. Une coquille par-ci, un champ oublié par-là, et c’est toute ton analyse qui dérape, la relation client qui se grippe, parfois même des soucis de conformité qui pointent.
Et crois-moi, la note est salée. Selon Gartner, une mauvaise qualité des données coûte en moyenne 12,9 millions de dollars par an à une entreprise. À l’échelle d’un pays, IBM chiffre à 3 000 milliards de dollars par an le manque à gagner que les données pourries infligent à l’économie américaine. Et le plus dingue : à peine 3 % des données en entreprise atteignent les standards de qualité de base.
Quand la saisie déraille, les dégâts sont bien concrets : prospects envolés, budgets marketing partis en fumée, risques réglementaires, décisions à côté de la plaque. Mais avec la montée des outils IA, on peut enfin coincer ces erreurs avant qu’elles ne te coûtent un bras.
Les erreurs de saisie les plus courantes (et pourquoi elles surgissent)
Disons-le franchement : la saisie de données, ça n’éclate personne. C’est répétitif, pointilleux, souvent bâclé dans l’urgence. Le terrain rêvé pour les boulettes. Voici les types d’erreurs que j’ai le plus souvent croisés (et commis, soyons honnêtes !) :
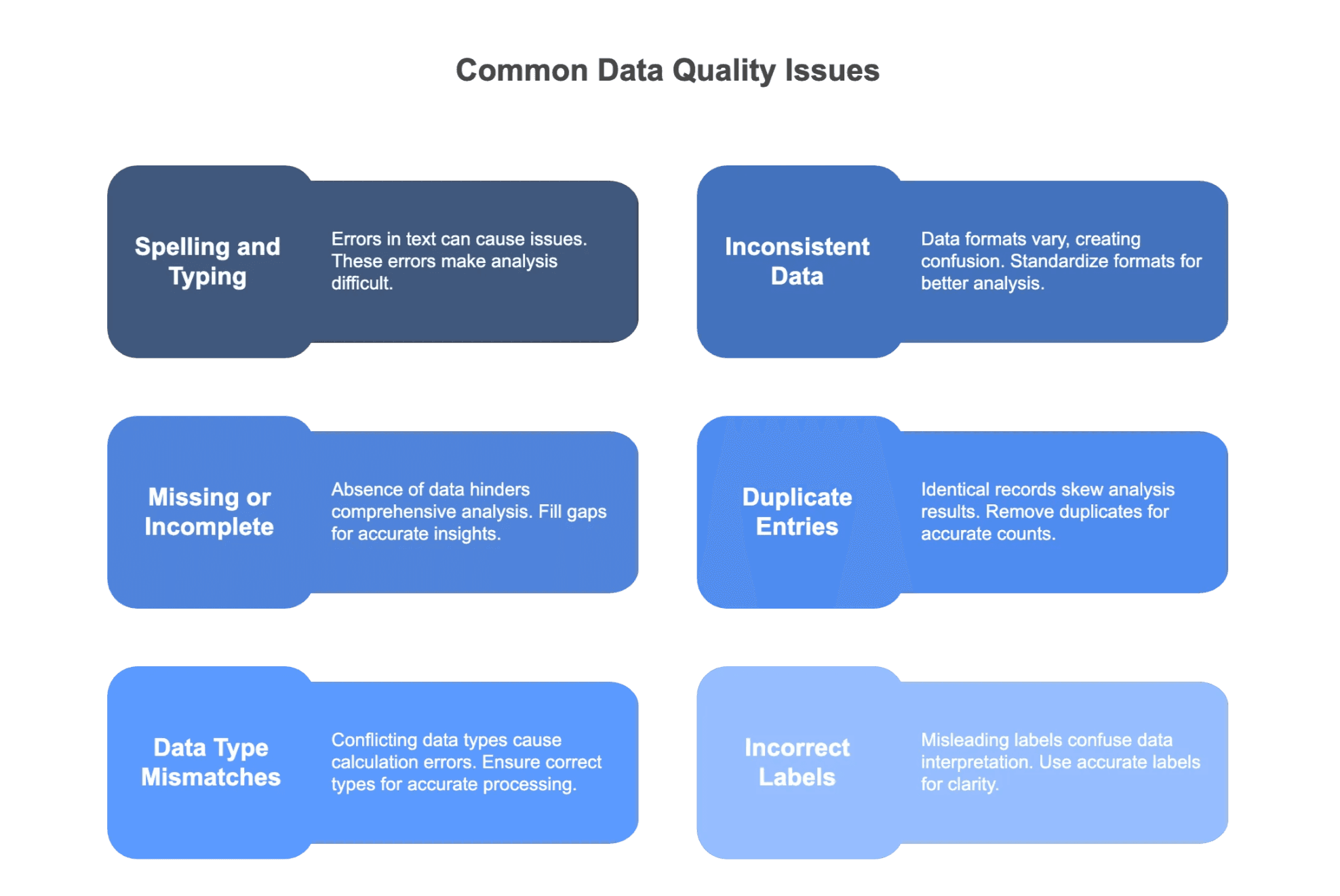
- Fautes de frappe et d’orthographe
- Formats de données pas uniformes
- Champs vides ou incomplets
- Doublons
- Incohérences dans les types de données
- Mauvais étiquetage ou mauvaise catégorie
D’où ça vient ? Le plus souvent, d’un cocktail : fatigue, baisse d’attention, manque de formation, et des process flous (formulaires mal conçus, aucune validation, fusion de sources hétéroclites). Même outillé en numérique, on n’y échappe pas, surtout quand les équipes nettoient et dédoublonnent encore à la main sous Excel (ce que 65 % des boîtes pratiquent toujours).
Regardons de plus près chaque famille d’erreurs et son origine.
Fautes de frappe et d’orthographe
Le grand classique ! Un prénom écorché (« Jonh » au lieu de « John ») ou une virgule baladeuse (« 10000 » au lieu de « 1000 »), et ces broutilles finissent par coûter cher. En vente, une faute dans une adresse mail, c’est un prospect qui s’évapore. En finance, une erreur de chiffre peut se chiffrer en millions (demande à Samsung Securities).
Formats de données pas uniformes
Tu as déjà tenté de trier une liste de dates où la moitié s’affiche en « JJ/MM/AAAA » et l’autre en « AAAA-MM-JJ » ? Ou des numéros de téléphone tantôt « (123) 456-7890 », tantôt « 1234567890 » ? Ces écarts enrayent les automatisations, biaisent les rapports et transforment l’intégration en casse-tête.
Champs vides ou incomplets
Le champ vide, c’est le poison silencieux des process métier. Un code postal qui manque, c’est un colis qui n’arrive jamais. Un contact à trous, c’est une relance ratée. Parfois l’info n’existait pas au moment de la saisie, parfois le système ne l’exigeait pas. Dans les deux cas, tout le monde ralentit.
Doublons
Qui n’a jamais vu « Acme Inc. » et « Acme Incorporated » se balader comme deux clients distincts dans un CRM ? Les doublons gonflent tes chiffres, sèment la pagaille dans les équipes et bouffent du temps. Il arrive même que 10 à 20 % des enregistrements soient des doublons.
Incohérences dans les types de données
Tu as déjà repéré un « ABC » dans un champ censé contenir un numéro de téléphone ? Ou un « 999 » sur une échelle de 1 à 5 ? Ces incohérences déclenchent des bugs, faussent les analyses, et peuvent même virer au problème de conformité (imagine saisir 100 000 € au lieu de 10 000 € dans une demande de prêt).
Mauvais étiquetage ou mauvaise catégorie
Les erreurs de classement sont sournoises. Un client rangé en « Grossiste » au lieu de « Détail », une dépense imputée au mauvais service, et c’est toute l’analyse qui part de travers — sans compter les risques réglementaires.
Comment l’IA rebat les cartes de la saisie de données
C’est là que ça devient vraiment palpitant. L’IA, ce n’est pas réservé aux voitures autonomes ou aux chatbots : elle bouleverse aussi la saisie de données. Au lieu de tout relire à la main, les outils IA savent désormais :
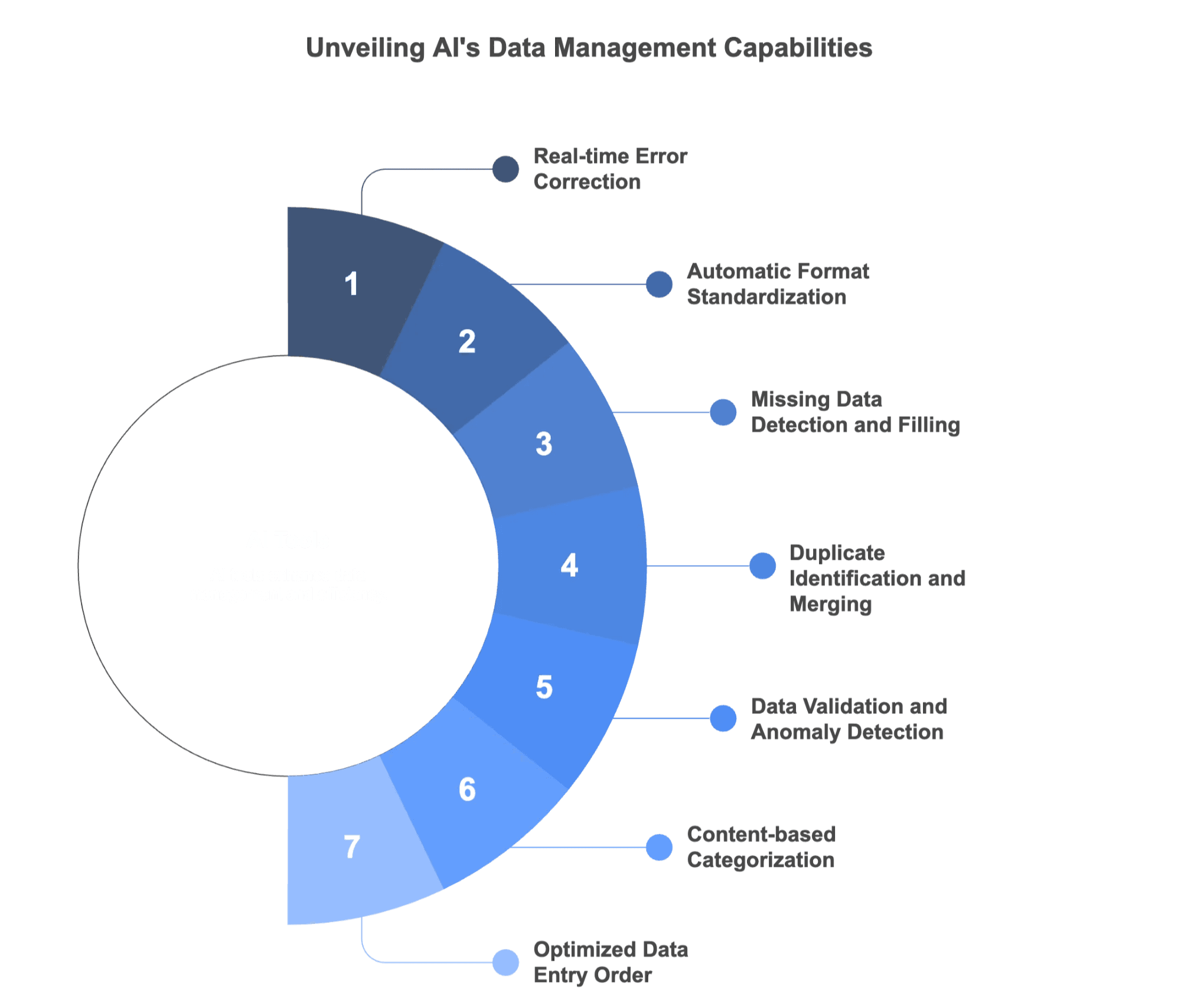
- Repérer les fautes de frappe et proposer des corrections à la volée
- Uniformiser les formats tout seuls
- Détecter les champs manquants et les compléter
- Identifier et fusionner les doublons
- Valider les types de données et lever une alerte sur les anomalies
- Catégoriser les entrées automatiquement, d’après leur contenu
- Réorganiser l’ordre de saisie pour limiter les oublis
Basculer d’une saisie manuelle à une saisie épaulée par l’IA, ça libère les équipes pour des tâches à plus forte valeur, et ça fait reculer le fléau des « données sales ».
Des solutions IA pour chaque type d’erreur de saisie
Dans le concret, voilà comment l’IA s’attaque à chaque souci récurrent :
Correction orthographique intelligente
Les IA modernes mobilisent le traitement du langage naturel (NLP) pour traquer les fautes, y compris quand le mot est « correct » mais mal placé dans son contexte (genre « john Smyth » au lieu de « John Smith »). Ces systèmes dépassent largement le correcteur d’antan : ils apprennent les variantes de noms et le jargon métier.
Standardisation des formats avec l’IA
L’IA détecte les schémas dans tes données et bascule le tout vers un format unique. Une colonne de dates dans tous les formats imaginables ? L’IA harmonise en « AAAA-MM-JJ ». Idem pour les numéros de téléphone, les adresses, etc. Certains outils te proposent carrément : « On convertit ces entrées au format standard ? »
Détection et complétion des champs manquants
Les modèles d’apprentissage automatique signalent les fiches à trous et suggèrent les valeurs les plus plausibles. Si un code postal manque, par exemple, l’IA peut le déduire à partir de la ville et du pays. Parfois, elle va même puiser dans des bases externes pour boucher les trous (avec ton feu vert, évidemment).
Détection des doublons par l’IA
La déduplication à l’ancienne ne capte que les correspondances exactes. L’IA, elle, dégaine des algos de rapprochement flou pour dénicher les enregistrements proches mais pas identiques (« IBM Corp. » contre « International Business Machines »). À la clé : une base propre et beaucoup moins de confusion.
Validation des types de données
L’IA apprend ce qui est « normal » et signale tout ce qui détonne. Un « 999 » pour une note sur 5, une lettre glissée dans un champ numérique, et le système réclame une correction. Elle sait aussi croiser les champs (si le pays est « France », elle attend un code postal à 5 chiffres).
Catégorisation et étiquetage automatiques
Les modèles NLP rangent les entrées d’eux-mêmes, selon leur contenu. Un ticket support qui évoque « compte bloqué, échec de connexion » sera étiqueté « Problème de connexion ». En saisie de données, ça allège le travail manuel et garantit des catégories cohérentes.
Optimisation de l’ordre de saisie avec l’IA
L’IA sait suggérer le meilleur enchaînement de saisie, en remodelant les formulaires au fil des réponses. Tu coches « International » ? Le formulaire réclame un numéro de passeport plutôt qu’un numéro de sécu. De quoi limiter les oublis et s’assurer que tout est bien renseigné.
Des outils IA concrets pour une saisie de données plus futée
L’écosystème des outils IA dédiés à la saisie ne cesse de s’étoffer. Voici quelques solutions que j’ai testées ou décortiquées :
Thunderbit : extracteur web IA et assistant de saisie
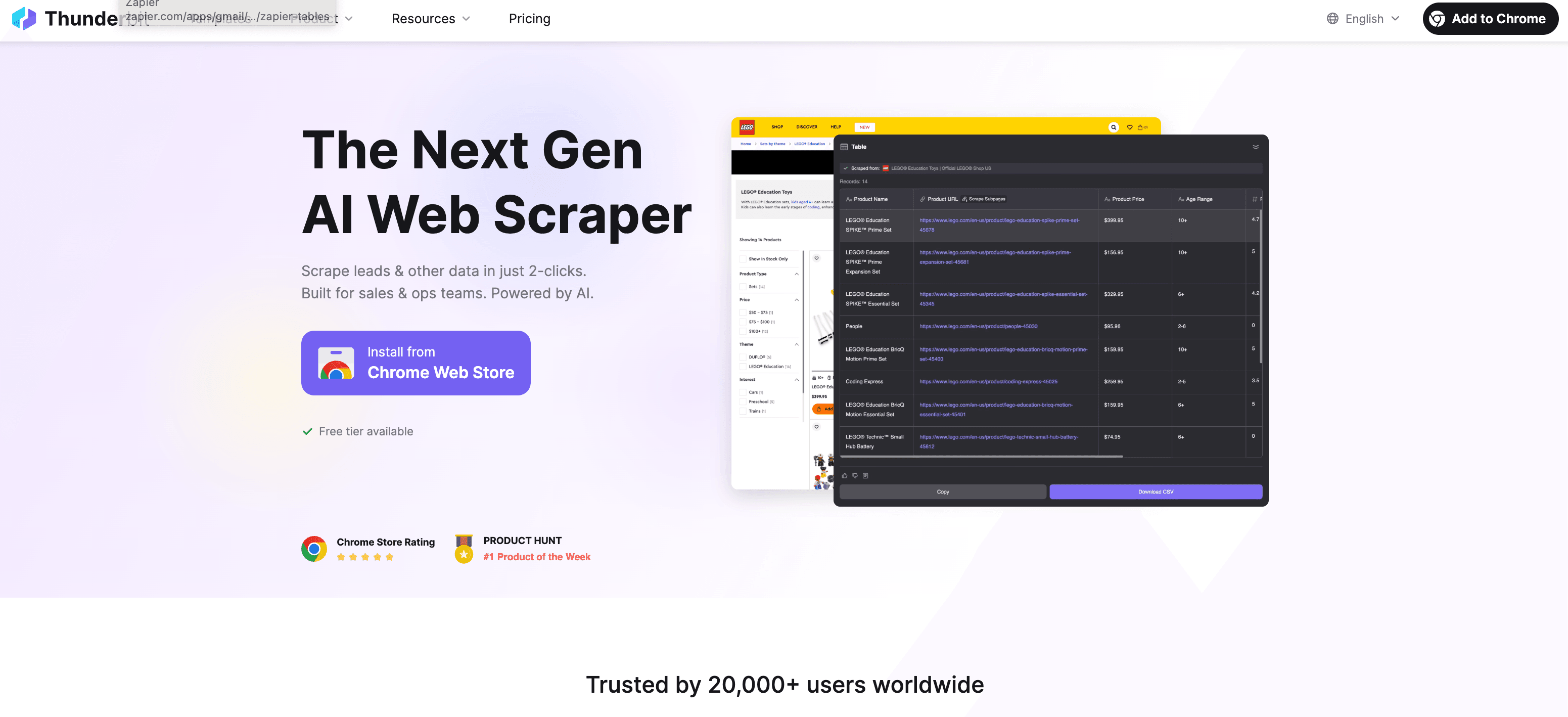
Thunderbit est une extension Chrome dopée à l’IA qui extrait des données structurées de n’importe quel site web en quelques clics. La fonction « Suggestion de champs IA » lit la page, te recommande les champs à récupérer et structure les données à ta place. Elle gère aussi les sous-pages et la pagination, ce qui en fait un sacré atout pour les équipes commerciales, l’e-commerce ou les chercheurs de données marché. Et oui, c’est nettement plus rapide (et plus fiable) que le copier-coller manuel. Tu peux l’essayer depuis la page de téléchargement de l’extension Thunderbit.
Essayez Thunderbit pour la saisie de données assistée par IA
OpenRefine : nettoyage de données open source
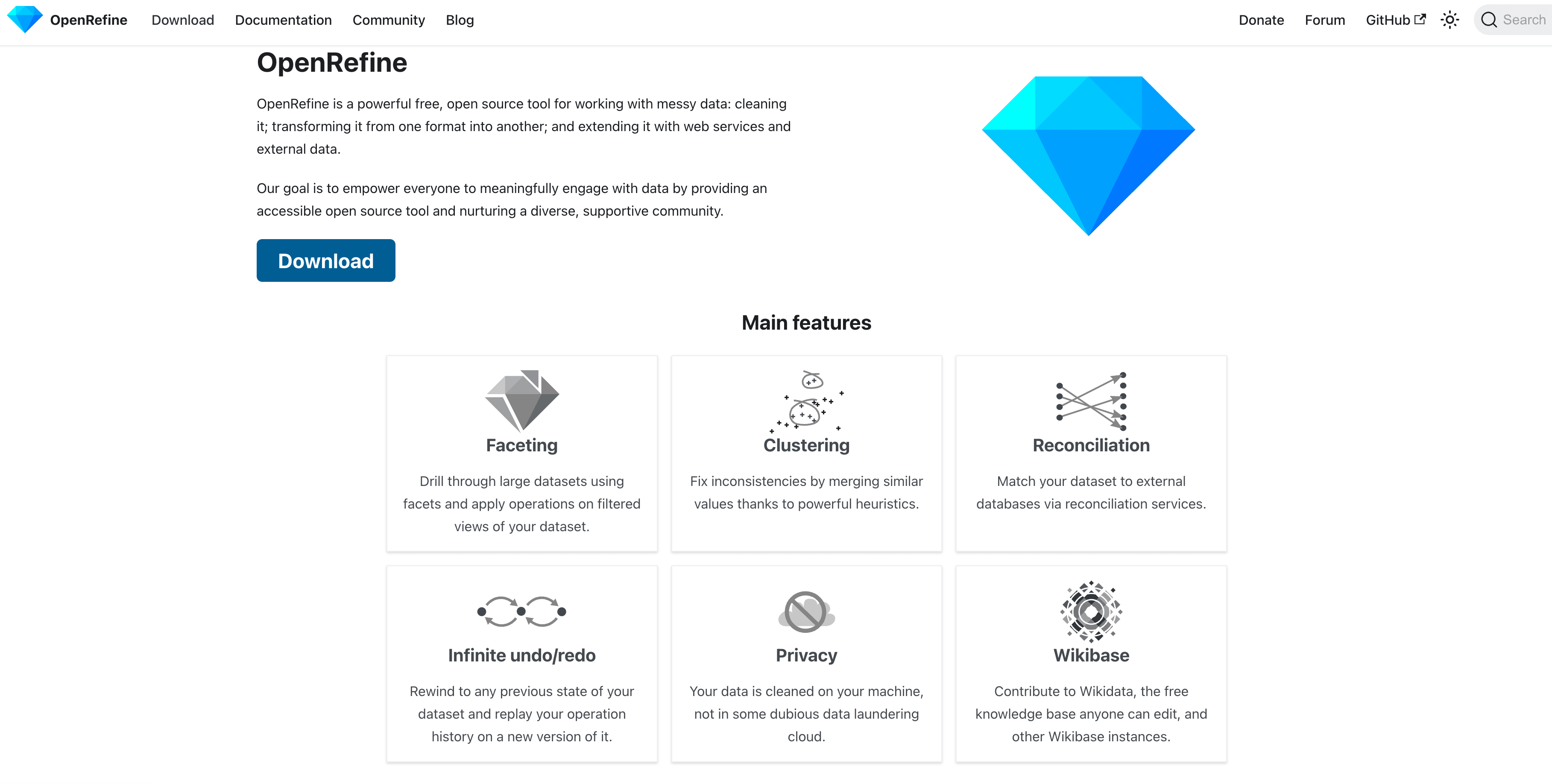
OpenRefine est le chouchou des analystes pour dégrossir les jeux de données « en vrac ». Il s’appuie sur des algos de regroupement pour repérer les entrées voisines (« Acme Inc. » et « ACME, Inc. »), ce qui simplifie la fusion des doublons et l’harmonisation des formats. Idéal pour les nettoyages ponctuels, et gratuit de bout en bout.
Trifacta (devenu Alteryx) : préparation de données guidée par l’IA

Trifacta Pricing mise sur le machine learning pour proposer des étapes de nettoyage (standardisation des dates, extraction de domaines, etc.). Pensé pour le big data, il offre des profils visuels et des fonctions collaboratives aux équipes qui jonglent avec des millions de lignes.
OCR et traitement intelligent des documents
Des outils comme ABBYY FlexiCapture Pricing, Microsoft Form Recognizer Pricing et Google Document AI Pricing exploitent l’OCR boosté à l’IA pour tirer des données structurées de documents scannés, de factures ou de tickets. Ces plateformes captent les champs clés, les valident et font fondre jusqu’à 80 % les erreurs de saisie manuelle.
Solutions NLP pour structurer les données
Des plateformes comme IBM Watson NLU Pricing et Amazon Comprehend Pricing recourent au NLP pour décortiquer et structurer des données textuelles. Elles savent extraire des dates, des actions, auto-étiqueter des tickets support ou normaliser des adresses.
Les bons réflexes pour une saisie de données sans erreur à l’ère de l’IA
L’IA, c’est costaud, mais ce n’est pas de la magie. Les meilleurs résultats viennent du duo gagnant : outils malins + process adaptés.
Quelques conseils tirés de mon vécu :
- L’humain dans la boucle : laisse l’IA débusquer les erreurs, mais fais trancher les cas litigieux par un humain, surtout sur les données sensibles.
- Automatise les contrôles qualité : traite tes données comme du code — déclenche des vérifs automatiques à chaque import ou modif.
- Surveillance continue : monte des tableaux de bord pour suivre taux d’erreur, complétude et doublons. Branche des alertes IA pour repérer les soucis au plus tôt.
- Intègre l’IA dans les workflows : glisse la validation et les suggestions IA directement dans tes interfaces de saisie.
- Boucles de retour : laisse les utilisateurs donner leur avis sur les suggestions IA pour l’aider à s’affûter.
- Mélange IA et contrôle classique : double saisie ou audit pour les champs critiques, IA pour le reste.
- Cultive le réflexe qualité : fais de la fiabilité des données l’affaire de tous, pas seulement de l’IT.
Faire vivre une vraie culture de la qualité des données : le rôle des équipes
La techno ne règle qu’une partie de l’équation. Les boîtes qui s’en sortent le mieux sont celles où la qualité des données concerne tout le monde. Voilà comment y parvenir :
- Engagement de la direction : les patrons doivent fixer des objectifs nets et relier la qualité des données aux résultats business.
- Formation continue : sensibilise régulièrement les équipes à l’impact des données pourries et au maniement des nouveaux outils.
- Règles limpides : documente les standards de saisie et désigne des référents qualité.
- Communication ouverte : mets la qualité des données à l’ordre du jour des réunions, partage les réussites comme les ratés, sollicite les retours.
- Reconnaissance et récompenses : valorise les équipes ou les personnes qui font avancer la qualité des données.
- Outils accessibles : donne à chacun l’accès aux bons outils IA et aux bonnes ressources.
- Amélioration continue : vois chaque erreur comme une leçon et ajuste les process en conséquence.
Un exemple qui m’est resté : une boîte industrielle a élargi son programme Six Sigma à la qualité des données. Les salariés ont été formés aux principes de la data quality, les taux d’erreur suivis sur des tableaux de bord visuels, et les opérateurs équipés d’outils de validation IA. Résultat : des données plus propres, des changements de production accélérés et une confiance retrouvée dans l’analyse, à tous les étages.
À retenir : la saisie de données devient (enfin) intelligente grâce à l’IA
- Les erreurs de saisie coûtent cher et sont partout : fautes de frappe, doublons, champs vides, mauvais étiquetage…
- Les outils IA rebattent les cartes de la saisie, en traquant les erreurs en temps réel, en harmonisant les formats et en comblant les infos manquantes.
- Le combo gagnant, c’est le trio IA + process malins + culture de la qualité : du patron au stagiaire, chacun doit se sentir concerné par la propreté des données.
Si tu en as ras-le-bol de rattraper les erreurs de saisie (ou de redouter ce qui se cache dans ton CRM), il est temps de voir ce que l’IA peut faire pour toi. Des outils comme Thunderbit, OpenRefine ou les plateformes OCR nouvelle génération rendent la fiabilité et la disponibilité des données plus accessibles que jamais.
Et ne l’oublie pas : dans le business, des données propres, ce n’est pas du confort, c’est un vrai avantage concurrentiel. Alors, en chasse aux « données sales » — un outil malin (et une bonne habitude) à la fois.
Envie de creuser les workflows data dopés à l’IA ? Fais un saut sur le blog Thunderbit : conseils, guides et retours d’expérience sur l’IA au service de ta productivité t’y attendent.
Découvrez les outils IA de Thunderbit pour la data
FAQ
1. Quelles sont les erreurs de saisie de données les plus fréquentes ?
Fautes de frappe, formats incohérents, champs vides, doublons et mauvaises catégories arrivent en tête. Ces soucis perturbent l’activité, l’analyse et la prise de décision.
2. Comment l’IA améliore-t-elle la qualité des données ?
Les outils IA traquent les fautes, proposent des corrections, harmonisent les formats, repèrent les doublons et complètent les champs vides — autant d’erreurs humaines en moins.
3. L’IA peut-elle remplacer totalement la saisie manuelle ?
Pas complètement. L’IA réduit les erreurs et accélère le traitement, mais la supervision humaine reste incontournable pour les cas particuliers et la validation.
4. Quels types d’entreprises tirent le plus parti des outils IA pour la saisie de données ?
Les équipes commerciales, marketing, e-commerce, immobilières et opérationnelles, surtout celles qui jonglent avec des CRM, des listes de prospects ou de gros volumes de données web.
Pour aller plus loin
1. Des millions perdus à cause de mauvaises données : leçons de Samsung & Uber
Des exemples concrets d’erreurs coûteuses et les leçons tirées par les entreprises.
2. Mauvaises données : un problème à 3 000 milliards par an (VentureBeat)
Analyse sectorielle de l’impact des données erronées sur l’économie et des solutions IA.
3. La crise de la qualité des données (Eckerson Group)
Un rapport 2024 éclairant sur la persistance du nettoyage manuel des données en entreprise.
4. Blog Thunderbit : outils IA pour la vente, l’ops & la data web
Guides, astuces produits et cas d’usage pour en finir avec la saisie manuelle grâce à l’IA.
Essayez l’Extracteur Web IA Get Started Free




