Résumé exécutif
Nous avons récupéré le fichier robots.txt de chaque domaine figurant dans la liste Tranco top 10,000 des sites web les plus visités au monde. Nous les avons ensuite analysés avec un parseur conforme à la RFC 9309, classé chaque fichier selon la politique éventuellement adoptée à l’égard des bots IA, et compté combien des sites les plus visités au monde tentent réellement de bloquer ChatGPT, Claude, Perplexity, Gemini, Common Crawl, Bytespider, Apple Intelligence et les autres crawlers qui entraînent et alimentent les grands modèles de langage en 2026.
Les chiffres clés, sur un échantillon de 7 248 sites dont nous avons pu lire robots.txt sans ambiguïté :
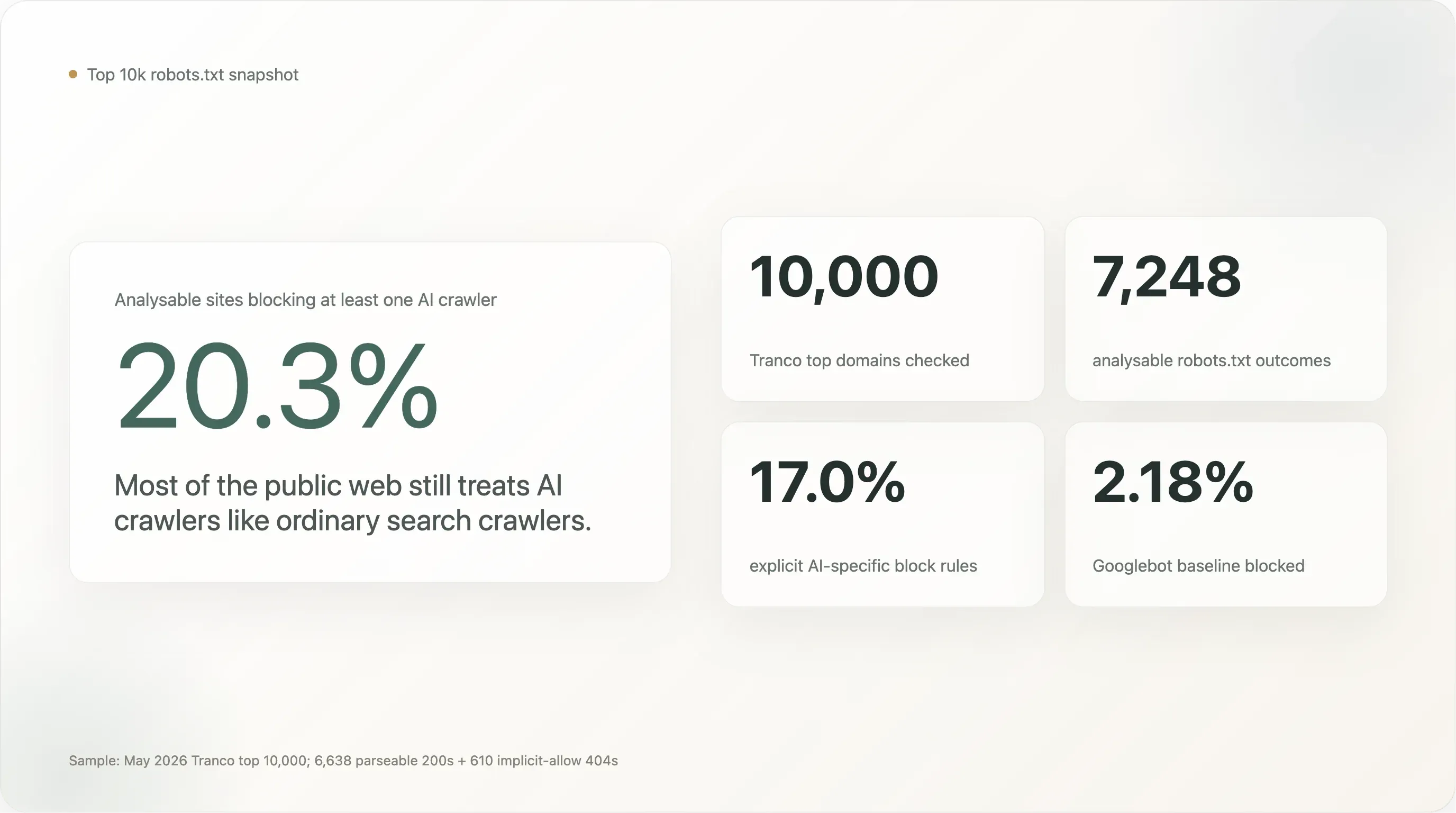
20,3 % des 10 000 sites les plus visités au monde bloquent au moins un crawler IA. 17,0 % ont rédigé exprès une règle explicite spécifique à l’IA. Les 80 % restants laissent les crawlers IA aussi bienvenus que Googlebot.
Six enseignements qui changent la lecture du sujet :
- Les médias atteignent 47 % de blocage — le niveau le plus élevé de tous les secteurs. Les médias allemands culminent à 88 %, les français à 80 %, les russes à 0 %. Le régime juridique, et non la technologie ou l’économie du secteur, est le principal moteur.
CCBot(Common Crawl) est le bot le plus bloqué, à 16,3 % — devantGPTBot(15,8 %) etBytespider(14,9 %). Les éditeurs visent le corpus d’entraînement, pas la marque du modèle. La règle sélective la plus adoptée est « bloquerCCBot, autoriserGooglebot» (14,1 % des sites).- La France mène tous les pays avec 50,6 % de blocage IA sur les sites en
.fr; le cluster UE dépasse de 16 points la moyenne mondiale. 275 fichiersrobots.txtcitent explicitement la directive UE 2019/790. L’article 4 est le seul régime juridique qui déplace nettement les chiffres. - 17,8 % ont rédigé leurs propres règles IA ; 4,5 % utilisent le modèle fournisseur de Cloudflare ; 75,7 % ne disent rien. Les grands sites rédigent leurs règles eux-mêmes ; la longue traîne utilise le bouton. The Atlantic et
cloudflare.comfigurent eux-mêmes dans la liste gérée par Cloudflare. - 108 sites autorisent explicitement
GPTBot— WordPress.org, Kaspersky, Norton, Avast, Sophos, The Verge, The Atlantic, NBA.com, The Sun, Branch.io. Les secteurs de la sécurité et des outils de dev sont surreprésentés. - La politique IA ne devient pas plus agressive à mesure qu’on monte dans le classement. Top 100, 101–1 000, 1 001–5 000, 5 001–10 000 se situent tous entre 19 % et 23 %. Le chiffre phare est une propriété du web public en 2026, pas un signal de la taille d’un site pris isolément.
L’histoire ne porte plus sur le fait de savoir si le web « riposte ». Elle porte sur les secteurs, les pays, les régimes juridiques et les fournisseurs d’IA qui sont visés par une politique active — et ceux qui ne le sont pas.
I. Contexte : comment robots.txt est devenu un artefact de politique IA
Trois forces ont redéfini la signification de robots.txt depuis la sortie de GPTBot par OpenAI en août 2023.
Les fournisseurs d’IA se sont multipliés. Google-Extended de Google, ClaudeBot d’Anthropic, Bytespider de ByteDance, Applebot-Extended d’Apple, Amazonbot d’Amazon, Meta-ExternalAgent de Meta ont suivi. CCBot, déjà existant chez Common Crawl, est devenu la cible de blocage la plus stratégique, car ses archives alimentent la plupart des modèles open-weight. Des bots non liés à un fournisseur sont aussi apparus : AI2Bot, cohere-ai, PerplexityBot, YouBot, DuckAssistBot, Diffbot, Omgili. Une liste de blocage exhaustive en 2026 compte environ 25 noms.
L’article 4 de la directive européenne 2019/790 sur le droit d’auteur a créé une exception de fouille de textes et de données qui ne s’applique pas si le titulaire des droits a « expressément réservé » ses droits de manière « lisible par machine ». Tout au long de 2024–2025, les éditeurs européens et leurs juristes se sont accordés sur robots.txt comme moyen canonique d’exprimer cette réserve. Notre jeu de données montre que 275 sites citent explicitement la directive 2019/790 et 87 mentionnent « TDM » — surtout sur les sites d’actualité européens, où cela prend la forme d’un préambule juridique de 4 à 8 lignes.
Cloudflare a industrialisé l’option. En 2024–2025, Cloudflare a lancé un tableau de bord « AI Audit », un bouton « Block AI Bots » et un modèle robots.txt géré avec le vocabulaire Content-Signal: search=yes,ai-train=no, plus le boilerplate de l’UE 2019/790. En mai 2026, ce modèle fonctionne sur 4,5 % du top 10k analysable. La feuille de route publique de Cloudflare évoque le fait de mettre l’option de blocage par défaut pour les nouveaux comptes — ce qui ferait bouger le taux global de blocage de 5 à 8 points sans qu’aucun éditeur individuel n’ait à prendre une décision.
En 2026, robots.txt n’est plus le fichier de configuration sans glamour qu’il était en 2022. C’est un mécanisme de réserve de droits d’auteur adossé à un cadre juridique dans l’UE, un artefact de politique façonné par un fournisseur dans la longue traîne, et la ligne de front d’une négociation lente entre les personnes qui exploitent des sites et celles qui entraînent des modèles.
II. Méthodologie
Nous avons essayé de rendre cette étude aussi ennuyeuse et reproductible que possible. L’intégralité de la chaîne de traitement (scripts Python, CSV analysés, archive brute robots.txt, graphiques) est publiée avec ce rapport.
Échantillon
Nous sommes partis de la liste Tranco de mai 2026, téléchargée en top-1m.csv.zip, puis nous avons extrait les 10 000 premières lignes. Tranco agrège quatre classements amont (Cisco Umbrella, Majestic, Farsight et Cloudflare Radar), filtre la stabilité sur une fenêtre de 30 jours et supprime le bruit évident des crawlers/CDN. La liste produite est ce qui se rapproche le plus d’un « top-10k mondial du trafic web » canonique dans l’écosystème ouvert, et c’est l’échantillon standard de la recherche académique sur le web (utilisé dans plus de 600 articles évalués par les pairs depuis son lancement par la KU Leuven en 2018).
La liste mélange (a) les sites principaux que les gens visitent, (b) des domaines d’infrastructure / API / DNS / CDN qui ne servent pas de /, et (c) des domaines utilisés en interne par de grandes plateformes (par ex. gvt1.com, apple-dns.net, googleusercontent.com). Au lieu de les filtrer au préalable, nous les avons tous conservés et étiquetés comme infrastructure dans la couche d’analyse. Ils disparaissent naturellement dès lors qu’on se limite aux « sites ayant renvoyé un robots.txt analysable ».
Récupération
Pour chacun des 10 000 domaines, nous avons émis un GET /robots.txt asynchrone en HTTPS, avec repli vers HTTP, redirections suivies jusqu’à quatre sauts, un délai total de 12 secondes, une limite de 500 Ko pour le corps et une chaîne User-Agent de navigateur réel avec Accept-Language: en-US. La concurrence était limitée à 80 requêtes simultanées. La tâche a été exécutée depuis une adresse IP résidentielle unique à San Francisco.
Résultat de la récupération :
| Statut | Nombre | Interprétation |
|---|---|---|
200 OK | 6 638 | Le corps de robots.txt a été renvoyé et peut être analysé. |
404 Not Found | 610 | Aucun robots.txt n’existe. La RFC 9309 définit cela comme un « autoriser tout » implicite. |
403 Forbidden | 563 | L’origine rejette activement les requêtes sur robots.txt. Exclu de l’analyse. |
429 Too Many Requests | 7 | Quasiment aucune limitation au niveau CDN à ce niveau de classement. |
fetch_failed (erreur TLS / DNS / TCP) | 2 065 | Surtout des domaines d’apex CDN (akamai.net, cloudfront.net, fastly.net, gtld-servers.net, apple-dns.net) qui n’exécutent pas de serveur web sur /. Ce n’est pas un « blocage » — ils n’ont simplement pas de robots.txt à servir. |
| Autres 4xx/5xx | 117 | Mélange d’erreurs serveur, de géorestrictions et de réponses mal formées. |
Nous obtenons ainsi 7 248 sites dans l’échantillon analysable (6 638 200 + 610 404). Les 2 065 fetch_failed sont de vrais domaines, mais il s’agit de points d’apex CDN/DNS, pas de sites visités par des humains, et les traiter comme s’ils avaient une « politique IA » n’aurait pas de sens. Ils figurent dans le jeu de données comme statistique d’accessibilité séparée.
Analyse syntaxique
Chaque corps en 200 a été analysé avec protego, une implémentation Python de la RFC 9309 utilisée en production par Scrapy. Pour chaque paire (site, bot), nous avons calculé trois éléments :
can_fetch_root— si le bot est autorisé à récupérer/, selon la sémantique standard des groupes d’enregistrements, la priorité de la règle la plus spécifique et la primauté d’unUser-agent: *lorsqu’une règle dédiée au bot existe aussi.has_specific_rule— si le fichier contient une ligneUser-agent:nommant exactement ce bot (insensible à la casse).disallow_count— le nombre d’instructionsDisallow:dans le bloc correspondant, utilisé pour distinguer les interdictions globales des restrictions au niveau d’un chemin.
La combinaison importe, car un simple « taux de blocage » masque deux phénomènes très différents : des marques qui ont délibérément écrit User-agent: GPTBot \n Disallow: / parce qu’elles ont décidé de résister, et des marques dont le bloc générique User-agent: * \n Disallow: / (mis en place il y a des années pour le staging ou la maintenance) interdit aussi, par effet collatéral, tous les bots IA qui n’existaient pas encore lorsque la règle a été écrite. Dans ce rapport, le chiffre « tout blocage IA » inclut les deux cas ; le chiffre « blocage IA explicite » correspond au sous-ensemble volontaire.
Bots couverts
Nous avons suivi 25 bots, regroupés en trois catégories :
- Crawlers d’entraînement IA (16) :
GPTBot,ClaudeBot,anthropic-ai,CCBot,Google-Extended,Meta-ExternalAgent,Bytespider,Applebot-Extended,Diffbot,Amazonbot,ImagesiftBot,FacebookBot,cohere-ai,AI2Bot,Omgili,Omgilibot. - Bots d’inférence / de récupération en temps réel (7) :
PerplexityBot,Perplexity-User,ChatGPT-User,OAI-SearchBot,ClaudeBot(qui sert à la fois pour l’entraînement et l’inférence),YouBot,DuckAssistBot. - Base de référence pour la recherche (6) :
Googlebot,Bingbot,DuckDuckBot,Slurp(Yahoo),Baiduspider,YandexBot.
Certains bots se situent à cheval entre entraînement et inférence. ClaudeBot est le plus emblématique : Anthropic a abandonné l’ancien UA anthropic-ai en 2024 et utilise désormais ClaudeBot pour l’entraînement comme pour la récupération en direct. Une règle Disallow: ClaudeBot ne se traduit donc plus proprement par « bloquer l’entraînement tout en gardant la visibilité ». Nous avons conservé l’attribution telle quelle et en signalons la conséquence plus loin.
Classification sectorielle
Nous avons classé chaque domaine dans l’une de 16 catégories sectorielles (news, social, streaming, ecommerce, search, finance, infrastructure, saas, academia, dev, gov, adult, gambling, travel, telecom, unknown) à l’aide d’une approche en couches :
- Dictionnaire de domaines connus — une cartographie établie à la main d’environ 500 domaines à fort trafic vers des secteurs.
- Motifs de TLD / suffixe —
.gov→gov,.eduet.ac.*→academia, suffixes CDN reconnus →infrastructure. - Mots-clés dans le nom de domaine — news, post, shop, bank, porn, casino, etc. comme signaux de repli.
- Scraping de la page d’accueil — pour les sites que les trois premières couches ne parvenaient pas à classer et qui renvoyaient un
robots.txten200, nous avons récupéré le HTML de la page d’accueil, extrait<title>,<meta name="description">,<meta property="og:type">, puis appliqué un scoring par mots-clés inspiré des signaux de catégorisation utilisés par les modèles de langage.
Cela a permis d’obtenir 3 407 sites (34 %) avec des étiquettes sectorielles fiables et 6 593 laissés en unknown. La catégorie unknown est dominée par des portails régionaux non anglophones, des sites de marques corporatives en .com qui n’entrent dans aucune case unique, et des éditeurs traditionnels de petits marchés linguistiques pour lesquels nous n’avions pas d’entrée dans le dictionnaire. Quand ce rapport cite un pourcentage par secteur, le dénominateur est l’échantillon classé de ce secteur, et non les 10 000 sites complets.
III. Résultats
Résultat 1 — Un site très visité sur cinq bloque au moins un bot IA
Parmi les 7 248 sites analysables, 1 472 (20,31 %) bloquent au moins un bot IA. 1 230 (16,97 %) ont une règle volontaire spécifique à l’IA. La base de référence Googlebot est de 2,18 % (158 sites — la plupart bloquant tout par défaut pour maintenance, ou, dans trois cas, des moteurs de recherche bloquant leurs concurrents).
Le chiffre phare de 20 % est 9 fois la base Googlebot. C’est un vrai signal — les sites à fort trafic ont un ordre de grandeur de plus de chances de bloquer un crawler IA qu’un crawler de recherche — mais c’est aussi un chiffre nettement plus faible que le récit « le blocage IA devient universel » qui circule dans la presse depuis 2024. Même parmi les 10 000 sites les plus visités du web, la majorité de cinq sur six ne dit rien sur l’IA.
L’écart entre « tout blocage IA » (20,3 %) et « blocage IA explicite » (17,0 %) est faible en valeur absolue mais important conceptuellement. Les 3,3 points d’écart correspondent aux sites qui bloquent les bots IA uniquement parce que leur règle existante User-agent: * \n Disallow: / englobe tout ce qui passe, y compris des bots qui n’existaient pas quand la règle a été écrite. Le chiffre volontaire de 17,0 % est la lecture la plus propre de « combien des plus grands sites du monde ont pris une décision spécifique à l’IA ».
À mettre en regard de la littérature précédente :
| Source | Date | Échantillon | Taux de blocage |
|---|---|---|---|
| Originality.ai | Mar 2025 | 1 000 médias les plus populaires (anglais) | 35,7 % bloquent GPTBot |
| Palewire | Août 2024 | 1 500 organisations de presse | 36,0 % pour tout crawler IA |
| Reuters Institute | Printemps 2025 | 50 grandes marques d’actualité, 10 pays | 78 % pour tout crawler IA |
| WIRED / NYT | Fin 2023 | Top 50 des médias américains | 26 % bloquent GPTBot |
| Ce rapport (Thunderbit) | Mai 2026 | Tranco top 10 000 (tous secteurs) | 20,3 % / 17,0 % explicite |
Notre chiffre explicite de 17,0 % est inférieur à toutes les études centrées sur la presse, parce que les deux tiers de notre échantillon ne sont pas des médias. Restreint aux 650 sites d’actualité, on obtient 47 % — dans la même zone que les études précédentes une fois la composition de l’échantillon prise en compte. Le tableau structurel reste le même : le sous-ensemble des médias bloque l’IA à un rythme 3 à 4 fois supérieur au reste du web.
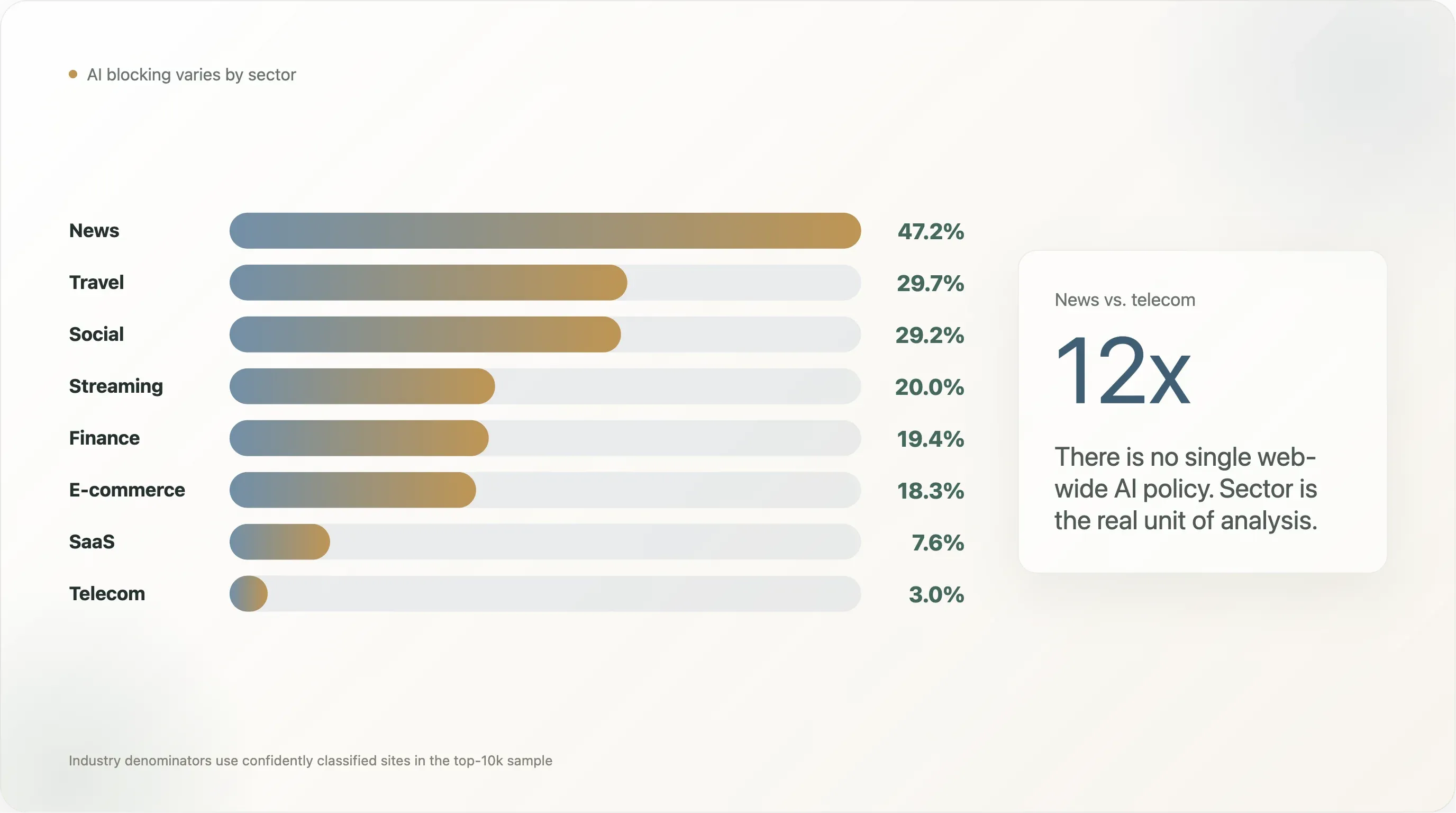
Résultat 2 — Analyse par secteur : un écart de 12x entre médias et télécom
Le constat le plus cité dans deux ans de couverture sur le « scraping IA » a été le chiffre des 80 % de médias bloquant GPTBot issu d’Originality.ai et de Palewire. Notre découpe donne une valeur plus basse, mais toujours distinctive : 47,2 % des sites d’actualité du top 10 000 bloquent au moins un bot IA, et 45,2 % ont rédigé une règle IA explicite.
Mais « médias contre tout le reste » est trop grossier. La ventilation complète (secteurs avec n ≥ 10 dans l’échantillon) raconte une histoire bien plus riche :
| Secteur | n | Tout blocage IA | Explicite | Googlebot bloqué | Règles DIY | Cloudflare Managed | Silencieux |
|---|---|---|---|---|---|---|---|
| Médias | 650 | 47,2 % | 45,2 % | 1,5 % | 46,9 % | 1,5 % | 48,5 % |
| Voyage | 64 | 29,7 % | 29,7 % | 0,0 % | 35,9 % | 3,1 % | 54,7 % |
| Social | 65 | 29,2 % | 23,1 % | 4,6 % | 23,1 % | 6,2 % | 66,2 % |
| Streaming | 440 | 20,0 % | 17,7 % | 0,7 % | 16,8 % | 3,6 % | 75,5 % |
| Finance | 129 | 19,4 % | 12,4 % | 0,8 % | 14,7 % | 2,3 % | 75,2 % |
| E-commerce | 224 | 18,3 % | 17,4 % | 0,4 % | 24,1 % | 1,3 % | 66,1 % |
| Adultes | 254 | 17,3 % | 14,6 % | 0,4 % | 10,2 % | 7,9 % | 79,5 % |
| Recherche | 12 | 16,7 % | 0,0 % | 0,0 % | 0,0 % | 0,0 % | 100,0 % |
| Académie | 268 | 14,6 % | 13,8 % | 0,4 % | 13,4 % | 3,4 % | 77,2 % |
| Jeux d’argent | 100 | 14,0 % | 13,0 % | 0,0 % | 18,0 % | 4,0 % | 77,0 % |
| Outils dev | 129 | 10,1 % | 7,8 % | 0,0 % | 8,5 % | 5,4 % | 77,5 % |
| SaaS | 369 | 7,6 % | 6,2 % | 0,3 % | 9,5 % | 0,8 % | 87,5 % |
| Gouvernement | 172 | 5,2 % | 3,5 % | 0,0 % | 4,1 % | 0,6 % | 83,1 % |
| Infrastructure | 47 | 4,3 % | 0,0 % | 0,0 % | 4,3 % | 2,1 % | 72,3 % |
| Télécom | 33 | 3,0 % | 3,0 % | 0,0 % | 12,1 % | 0,0 % | 78,8 % |
L’écart de 12x entre médias et télécom montre pourquoi parler de « la politique IA du web » n’est pas la bonne unité d’analyse. Il n’existe pas un chiffre unique ; il existe des chiffres sectoriels qui divergent d’un ordre de grandeur. Nous détaillons ci-dessous les quatre constats les plus marquants.
Médias : 47 % de blocage, 47 % de DIY. Les médias sont le groupe qui a écrit le mode d’emploi. Cloudflare Managed ne représente que 1,5 % dans les médias — ces éditeurs n’externalisent pas la règle. Le texte est particulièrement riche : le NYT commence par un préambule juridique de 14 lignes citant « Art. 4 of the EU Directive » ; la BBC par « Please use our site like a human, not a robot... TL;DR: Browse, read, watch, enjoy — like a human. » ; The Sun par « The Sun does not permit the unlicensed use of our content for large language models. » C’est robots.txt comme déclaration de politique, pas comme simple configuration.
Le voyage à 30 % — la surprise. Booking, Expedia, TripAdvisor, Kayak et les grandes compagnies aériennes bloquent à deux tiers du rythme des médias. Le schéma sélectif est cohérent : le bloqueur moyen du voyage interdit 5 à 7 UA d’entraînement mais laisse intacts les UA d’inférence (PerplexityBot, ChatGPT-User, OAI-SearchBot). Les données agrégées sur les prix et les avis sont la barrière défensive ; les citations vers le site sont la valeur ajoutée. C’est le schéma le plus net « entraînement dehors, inférence dedans » dans un secteur unique.
Adultes à 17 % — surprise également. Les petits échantillons antérieurs montraient 0 %. Les données complètes indiquent qu’un site adulte sur six interdit au moins un bot IA, avec le taux Cloudflare Managed le plus élevé de tous les secteurs (7,9 %). Plus de la moitié des blocages IA des sites adultes proviennent du bouton Cloudflare, pas d’une décision d’éditeur. L’entraînement des modèles d’images est la menace implicite — les modèles de type Stable Diffusion assimilent plus vite le style visuel que les modèles textuels n’assimilent le style rédactionnel.
SaaS à 7,6 % : contre-intuitif. Les éditeurs de logiciels sont le segment le plus bruyant dans le débat sur la politique IA, mais leur robots.txt est largement ouvert. La bonne lecture : les équipes marketing SaaS ont correctement identifié la recherche IA comme canal de distribution. Les éditeurs qui se sont réellement penchés sur la question autorisent, ils ne se retirent pas — la liste explicite d’autorisation pour GPTBot (Résultat 12) est dominée par les acteurs de la sécurité et des outils dev.
Gouvernement 5,2 %, télécom 3,0 %, infrastructure 4,3 %, dev 10,1 %. Les obligations d’archivage public rendent Disallow: / juridiquement délicat pour les domaines en .gov. Les sites marketing des télécoms veulent être découvrables. Les domaines d’apex CDN n’ont rien à protéger. Les outils dev optent explicitement pour l’inclusion (leur contenu prend de la valeur quand les LLM le citent).
La conclusion : il n’existe pas de chiffre unique du type « le web bloque/ne bloque pas l’IA » qui ne perde pas plus qu’il n’explique. Le découpage par secteur est la seule manière honnête de présenter ces données.
Résultat 3 — Par fournisseur d’IA : qui est le plus bloqué ?
L’autre découpage naturel des données est par entreprise d’IA plutôt que par bot. Plusieurs fournisseurs exploitent plusieurs bots (OpenAI en a trois : GPTBot, ChatGPT-User, OAI-SearchBot ; Anthropic en a deux : ClaudeBot, anthropic-ai ; Meta en a deux : Meta-ExternalAgent, FacebookBot). L’agrégation au niveau du fournisseur est ce qui se rapproche le plus de « que pense le web public de chaque entreprise d’IA ? »
| Fournisseur IA | Bots agrégés | Sites bloquant ≥ 1 bot | % de l’échantillon analysable |
|---|---|---|---|
| Common Crawl | CCBot | 1 178 | 16,25 % |
| OpenAI | GPTBot, ChatGPT-User, OAI-SearchBot | 1 172 | 16,17 % |
| Anthropic | ClaudeBot, anthropic-ai | 1 111 | 15,33 % |
| ByteDance | Bytespider | 1 082 | 14,93 % |
| Meta | Meta-ExternalAgent, FacebookBot | 989 | 13,65 % |
Google-Extended | 970 | 13,38 % | |
| Amazon | Amazonbot | 877 | 12,10 % |
| Apple | Applebot-Extended | 859 | 11,85 % |
| Webz.io (Omgili) | Omgili, Omgilibot | 731 | 10,09 % |
| Cohere | cohere-ai | 717 | 9,89 % |
| Perplexity | PerplexityBot, Perplexity-User | 715 | 9,86 % |
| Diffbot | Diffbot | 684 | 9,44 % |
| You.com | YouBot | 563 | 7,77 % |
| AI2 (Allen AI) | AI2Bot | 487 | 6,72 % |
| DuckDuckGo | DuckAssistBot | 482 | 6,65 % |
Common Crawl est l’entité la plus ciblée même si c’est une archive web à but non lucratif, et non un opérateur de LLM. La raison est simple : le levier. CCBot alimente presque tous les modèles open-weight et une part importante des modèles fermés. Bloquer CCBot en premier est la règle offrant la meilleure couverture qu’un éditeur puisse écrire.
OpenAI, Anthropic et ByteDance se regroupent entre 14 et 16 %. L’avance d’OpenAI est en partie un artefact de comptage (trois bots OpenAI contre un seul bot pour ByteDance). Les 14,9 % de Bytespider reflètent l’effet « comportement Bytespider » — son non-respect de robots.txt depuis 2024 a été documenté, et les éditeurs le bloquent comme signal public, pas parce qu’ils craignent TikTok.
Meta, Google, Amazon, Apple à 12–14 % forment le deuxième niveau — des règles écrites de manière défensive plutôt que comme prise de position. Les petits fournisseurs (Webz.io, Cohere, Perplexity, Diffbot, You.com, AI2, DuckDuckGo) à 6–10 % sont surtout tirés vers le haut par le plancher de 3,8 % tous usages confondus ; leurs règles explicites se situent plutôt entre 1 et 4 %.
xAI (Grok), Mistral et la plupart des laboratoires européens/chinois sont absents du tableau — ils n’ont pas publié d’UA documentés pour les crawlers d’entraînement. L’écosystème robots.txt actuel est un dialogue entre des fournisseurs américains/chinois qui ont publié des UA et des éditeurs américains/européens qui ont rédigé des règles ; les fournisseurs qui n’ont rien publié restent invisibles dans la négociation.
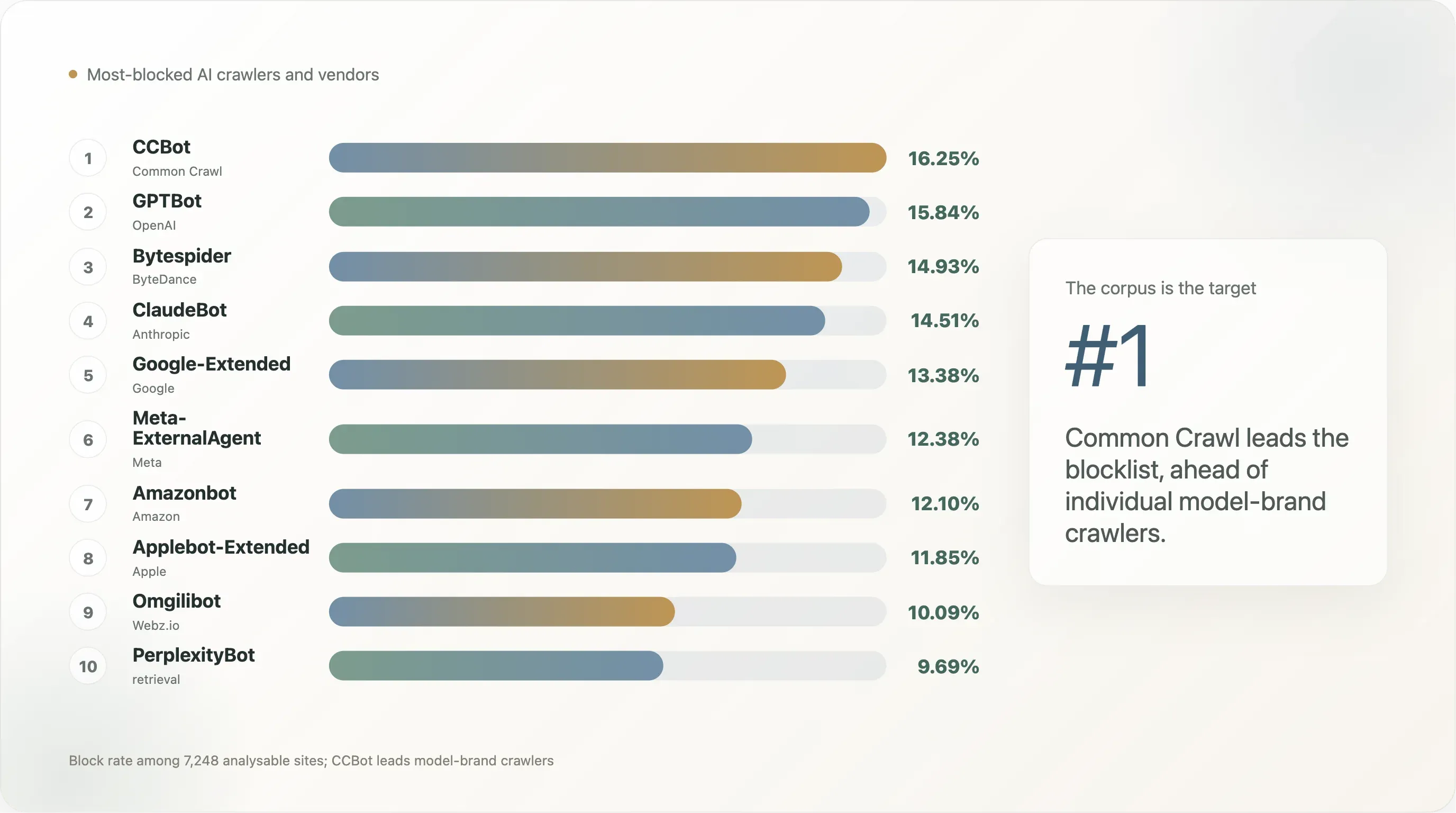
Résultat 4 — CCBot est la nouvelle cible, pas GPTBot
Le classement des bots dans le top-10k ressemble à ceci :
| Rang | Bot | Taux de blocage | Taux de règle explicite |
|---|---|---|---|
| 1 | CCBot (Common Crawl) | 16,25 % | 12,90 % |
| 2 | GPTBot (OpenAI) | 15,84 % | 12,72 % |
| 3 | Bytespider (ByteDance) | 14,93 % | 11,35 % |
| 4 | ClaudeBot (Anthropic) | 14,51 % | 11,13 % |
| 5 | Google-Extended | 13,38 % | 10,18 % |
| 6 | Meta-ExternalAgent | 12,38 % | 8,95 % |
| 7 | Amazonbot | 12,10 % | 8,66 % |
| 8 | Applebot-Extended | 11,85 % | 8,72 % |
| 9 | Omgilibot | 10,09 % | 5,31 % |
| 10 | anthropic-ai (obsolète) | 9,99 % | 6,55 % |
| 11 | cohere-ai | 9,89 % | 6,42 % |
| 12 | PerplexityBot | 9,69 % | 6,40 % |
| 13 | Diffbot | 9,44 % | 5,95 % |
| 14 | ChatGPT-User (inférence) | 8,90 % | 5,73 % |
| 15 | YouBot (inférence) | 7,77 % | 4,29 % |
| 16 | OAI-SearchBot (inférence) | 6,83 % | 3,66 % |
| base | Googlebot | 2,18 % | — |
| base | Bingbot | 2,27 % | — |
Ce tableau raconte que le bot que le web public bloque en premier n’est pas la marque du modèle — c’est le corpus. L’archive de 250 milliards de pages de Common Crawl a été le plus grand jeu d’entraînement de GPT-3, GPT-4, Llama 1 / 2 / 3, Falcon, Mistral, BLOOM, et de la plupart des modèles open-weight publiés depuis 2020. Un site qui veut se retirer du futur « en être dans le prochain modèle de frontière » optimise son exclusion en interdisant d’abord CCBot — une fois absent de Common Crawl, il est pratiquement exclu gratuitement de la chaîne d’entraînement open source. GPTBot et ClaudeBot arrivent ensuite parce qu’ils constituent la face visible de deux produits commerciaux précis ; l’UA au niveau du corpus est la cible structurelle.
Les bots IA les moins bien classés sont eux aussi instructifs. Omgilibot à 10 % est inhabituellement élevé pour un bot que la plupart des lecteurs ne connaissent pas — il est exploité par Webz.io, un courtier en données de contenu qui vend des archives web aux opérateurs de LLM, et une part importante d’organisations de presse a commencé à le nommer explicitement dans ses fichiers. AI2Bot à 6,7 % (et la règle correspondante Ai2Bot-Dolma sur les sites Squarespace) suggère que la communauté académique des LLM est elle aussi signalée par des éditeurs qui ne distinguent pas nécessairement « crawler de recherche non lucratif » et « crawler commercial ».
Le cluster d’inférence — ChatGPT-User, OAI-SearchBot, YouBot, Perplexity-User — se situe 4 à 8 points sous le cluster d’entraînement. Cet écart répond à une question de politique de longue date : oui, les sites à fort trafic font la différence entre un bot qui collecte des données pour l’entraînement futur et un bot qui fait de la récupération en direct pour répondre à la question d’un utilisateur tout de suite. Ils ne font pas toujours cette distinction (les règles génériques ne la font pas), mais une part significative rédige des règles qui ciblent spécifiquement le côté entraînement.
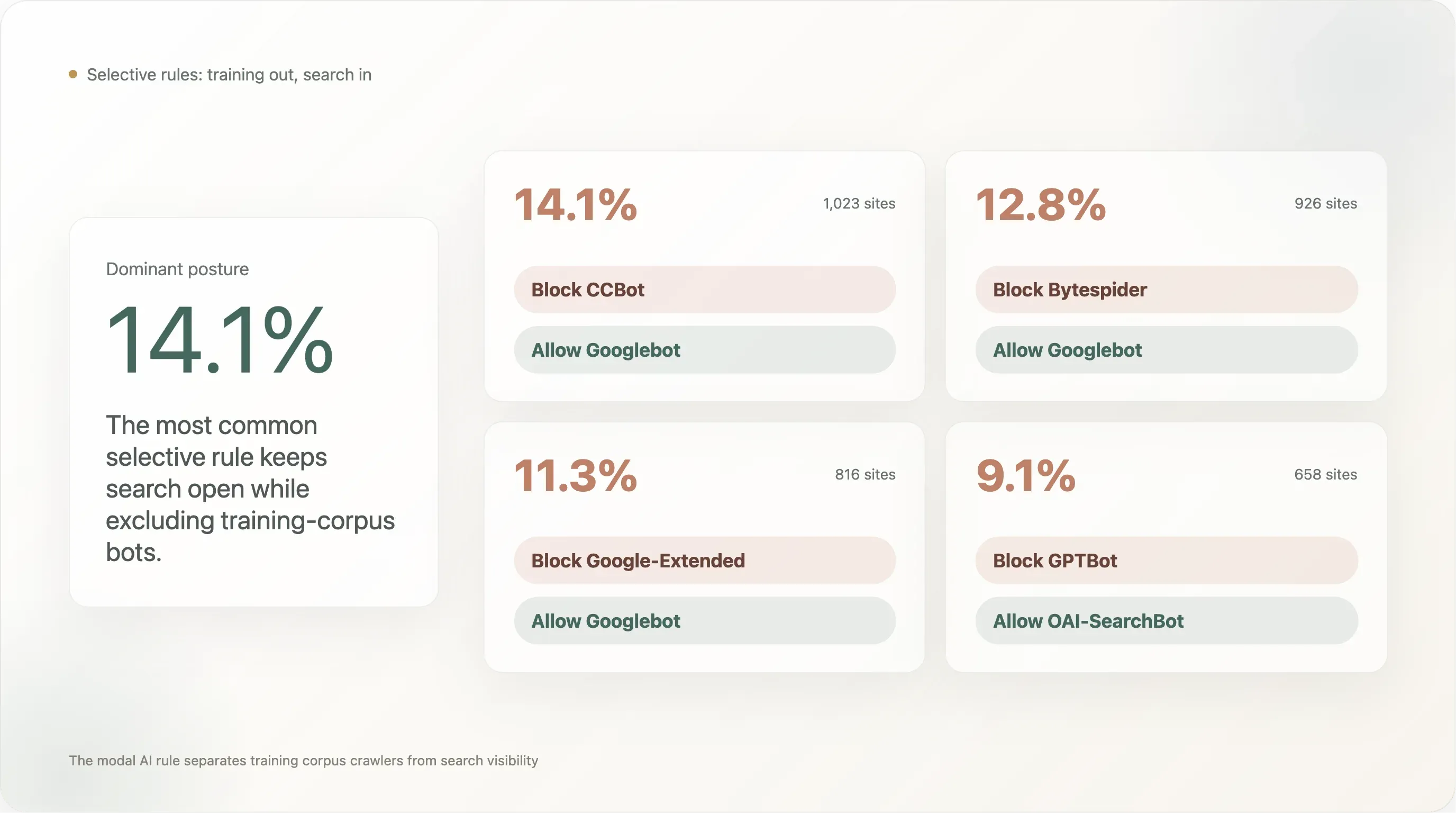
Résultat 5 — 14 % bloquent CCBot tout en laissant Googlebot bienvenu — le schéma « bloquer le corpus, garder la recherche »
La règle sélective la plus adoptée dans le top-10k :
| Schéma de règle | Sites | % de l’échantillon analysable |
|---|---|---|
Bloquer CCBot, autoriser Googlebot | 1 023 | 14,11 % |
Bloquer Bytespider, autoriser Googlebot | 926 | 12,78 % |
Bloquer Google-Extended, autoriser Googlebot | 816 | 11,26 % |
Bloquer GPTBot, autoriser OAI-SearchBot | 658 | 9,08 % |
Bloquer GPTBot, autoriser ChatGPT-User | 525 | 7,24 % |
Bloquer CCBot, autoriser PerplexityBot | 519 | 7,16 % |
Bloquer anthropic-ai, autoriser ClaudeBot | 59 | 0,81 % |
Le schéma le plus adopté (14,1 %) consiste à « bloquer Common Crawl, conserver la visibilité dans Google Search ». Le suivant (12,8 %) est « bloquer Bytespider, conserver la visibilité dans Google Search » — c’est-à-dire bloquer le crawler de ByteDance signalé comme problématique, tout en laissant intacte la base de recherche légitime. En troisième position (11,3 %) : « bloquer l’UA d’entraînement IA de Google tout en gardant l’UA de recherche de Google », ce qui correspond exactement à la séparation pour laquelle Google a conçu Google-Extended : le propriétaire du site se retire de l’entraînement de Bard / Gemini sans perdre son classement dans la recherche.
Ces trois chiffres décrivent ensemble la posture politique dominante sur le web du top-10k : interdire les bots de corpus d’entraînement, laisser intacts les bots de recherche et d’inférence. Le schéma minoritaire consistant à « interdire l’entraînement mais autoriser l’UA d’inférence en direct de ce LLM » — GPTBot ✗ / ChatGPT-User ✓ à 7,2 % — existe, mais il reste plus petit que les coupes au niveau du corpus.
La ligne anthropic-ai / ClaudeBot à 0,81 % reflète la dépréciation par Anthropic de son UA en 2024 : ClaudeBot sert désormais à la fois pour l’entraînement et l’inférence, ce qui supprime l’expression claire « bloquer l’entraînement, autoriser la citation » que permettait l’ancien UA anthropic-ai. C’est la décision de conception d’UA la moins discutée de 2024–2025 — elle a retiré de robots.txt toute une classe d’expression politique.
Résultat 6 — Détail des médias : par pays et par langue
Lorsque nous découpons la catégorie médias par TLD de code pays — en gardant à l’esprit qu’il s’agit ici de .de pour les médias allemands, .fr pour les médias français, etc., et non de la langue servie — la variance au sein des médias est plus grande que la variance entre médias et reste du web :
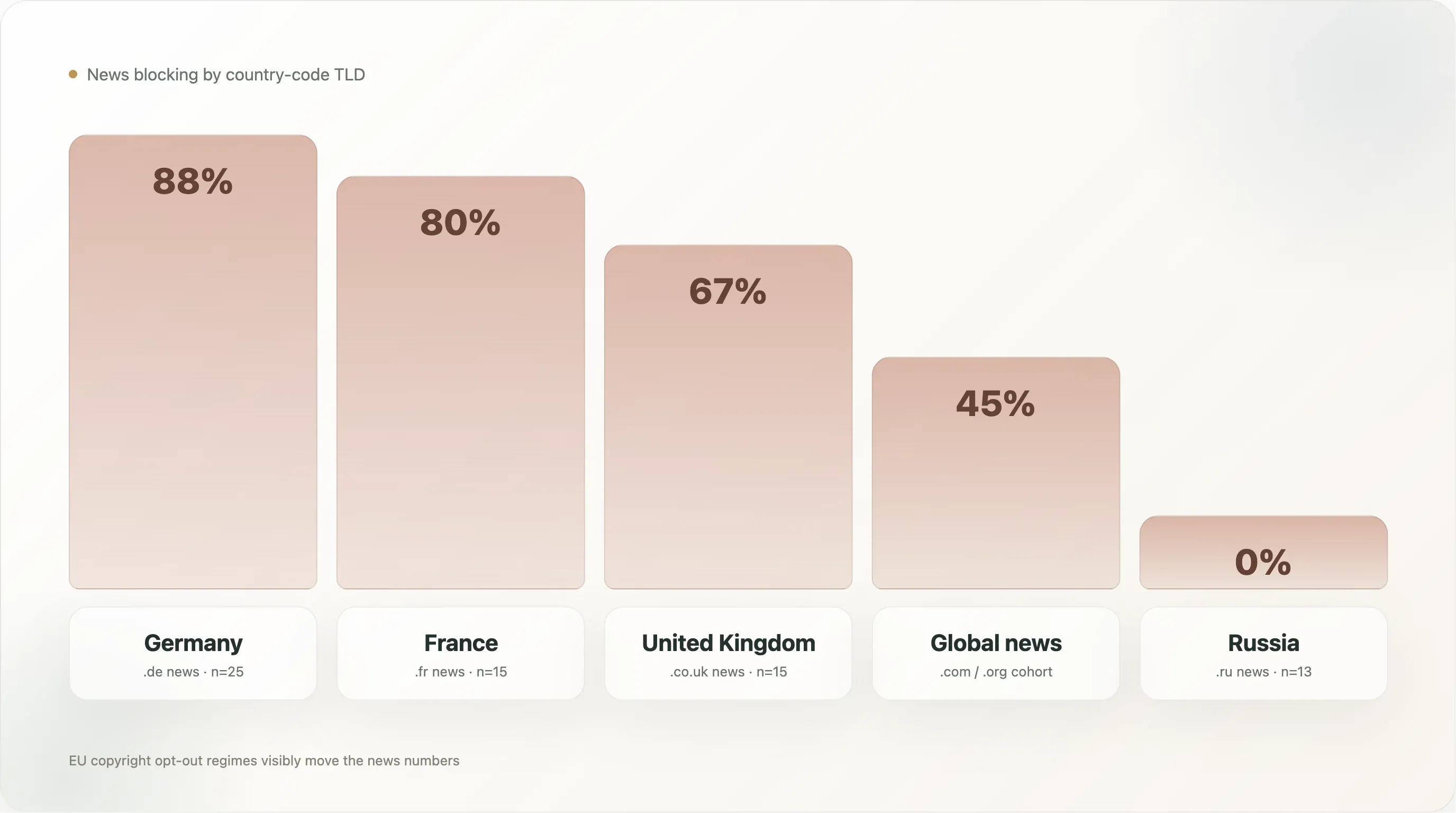
| Pays (médias uniquement) | n | Tout blocage IA | Explicite |
|---|---|---|---|
🇩🇪 Allemagne (.de) | 25 | 88,0 % | 88,0 % |
🇫🇷 France (.fr) | 15 | 80,0 % | 80,0 % |
🇬🇧 Royaume-Uni (.co.uk) | 15 | 66,7 % | 53,3 % |
🇪🇸 Espagne (.es) | 5 | 60,0 % | 60,0 % |
🇮🇹 Italie (.it) | 13 | 53,8 % | 53,8 % |
Médias mondiaux (.com/.org/etc.) | 500 | 45,0 % | 42,8 % |
🇵🇱 Pologne (.pl) | 7 | 42,9 % | 42,9 % |
🇯🇵 Japon (.jp) | 12 | 25,0 % | 25,0 % |
🇷🇺 Russie (.ru) | 13 | 0,0 % | 0,0 % |
🇬🇷 Grèce (.gr) | 6 | 0,0 % | 0,0 % |
Les médias allemands sont le sous-segment qui bloque le plus dans tout le jeu de données, avec 88 %, et c’est 88 % explicite — il n’existe pratiquement aucun site d’actualité allemand du top 10k qui laisse les crawlers d’entraînement IA accéder à son archive. Le groupe est mené par Spiegel, Bild, Welt, Zeit, FAZ, Süddeutsche, Heise, Golem, Stern, Focus — l’ensemble de l’establishment de la presse allemande, plus les éditeurs tech qui ont rédigé leurs propres règles. L’infrastructure politique sous-jacente est dense : VG Media, l’organisme allemand de gestion collective des droits des éditeurs, est le groupe de plaignants le plus offensif dans les litiges européens sur le droit d’auteur et l’IA, et l’article 4 de la directive européenne est transposé en droit allemand dans le §44b UrhG avec une formulation explicite d’opt-out lisible par machine. Quand les fournisseurs d’IA sont arrivés, les éditeurs allemands étaient les mieux préparés de tout le paysage national à traduire cette posture juridique en règles robots.txt.
Les médias français à 80 % suivent de près. L’environnement juridique français est similaire (directive 2019/790 transposée en droit français), et le comportement du groupe l’est aussi — lemonde.fr, lefigaro.fr, liberation.fr, lequipe.fr, 20minutes.fr, ouest-france.fr bloquent tous, et le fichier du Monde cite en plus le droit du producteur de base de données français (article L 342-1 du Code de la propriété intellectuelle) comme base juridique nationale parallèle. La France a en outre une spécificité : un jugement de 2024 du tribunal de commerce de Paris a considéré que les opt-out fondés sur robots.txt constituaient un avis suffisant au sens de l’article 4 ; cela fournit un appui jurisprudentiel direct qu’aucune autre juridiction n’égale encore.
Le Royaume-Uni à 67 % est plus bas, et la raison tient au fait que plusieurs grands éditeurs britanniques (thesun.co.uk, dailymail.co.uk, mirror.co.uk) utilisent des blocages User-agent: * de type deny-all plutôt que des règles spécifiques à l’IA, ce qui fait baisser le chiffre explicite à 53 %. L’effet agrégé reste le même — ces sites n’autorisent pas le crawling IA — mais la politique est exprimée sous la forme « pas de robots, sauf cette liste précise de moteurs de recherche autorisés » plutôt que par des interdictions nommées pour les bots IA. L’ossature juridique est aussi plus faible : après le Brexit, le Royaume-Uni a hérité de la logique de l’article 4, mais la jurisprudence domestique correspondante est moins fournie.
Les médias russes à 0 % constituent la ligne la plus surprenante. Treize sites d’actualité russes de l’échantillon (dzen.ru, rbc.ru, ria.ru, kommersant.ru, tass.ru, lenta.ru, gazeta.ru, interfax.ru, kp.ru, tass.com, etc.) — aucun ne bloque un seul crawler IA. L’explication probable : l’entraînement des LLM russophones est dominé par les propres modèles de type GPT de Yandex (qui utilisent des crawlers internes à Yandex, et non Common Crawl), l’environnement russe du droit d’auteur n’a pas adopté d’équivalent à l’article 4, et les principaux éditeurs russes considèrent les LLM occidentaux comme un sujet secondaire (les contrôles à l’exportation américains limitent déjà les services OpenAI/Anthropic en Russie) et Yandex comme un acteur domestique plutôt qu’un adversaire. La posture politique est fondamentalement différente.
Les médias japonais à 25 % dessinent un troisième schéma. Le Japon dispose d’exceptions explicites de fouille de textes et de données dans son droit d’auteur domestique (article 30-4 de la loi japonaise sur le droit d’auteur, amendé en 2018), plus permissives que l’article 4 de la directive européenne — elles autorisent la TDM à des fins de « non jouissance », y compris pour l’entraînement de l’IA, sans exiger le consentement du titulaire des droits. Les éditeurs japonais ont moins de levier juridique pour un opt-out, et les taux robots.txt correspondants sont plus faibles. Les 25 % qui bloquent sont surtout les plus grands éditeurs les plus internationaux (asahi.com, nikkei.com), positionnés davantage à l’échelle mondiale que domestique.
Les données transnationales sur les médias sont la preuve la plus nette du rapport que le régime juridique, et non la technologie ou l’économie sectorielle, est le principal moteur du blocage IA. Les cohortes médiatiques de l’UE se situent entre 54 % et 88 % ; les cohortes non européennes (Russie, Japon, et le groupe mondial .com) vont de 0 % à 45 %. Le pic à 88 % se trouve dans le pays où la mise en œuvre de l’article 4 est la plus avancée ; le plancher à 0 % se situe dans le pays où il n’existe pratiquement aucune loi de politique IA.
Résultat 7 — UE contre reste du monde : un écart de 16 points
En élargissant la lentille pays, la séparation UE / reste du monde est nette :
| Région | n | Tout blocage IA | Explicite |
|---|---|---|---|
ccTLD UE (.fr, .de, .es, .it, .nl, .pl, .se, .dk, .fi, .be, .at, .cz, .hu, .ro, .gr, .pt, .ie, .sk, .bg) | 617 | 35,2 % | 33,9 % |
ccTLD nationaux hors UE (.uk, .jp, .kr, .cn, .ru, .br, .in, .au, .mx, .ca, .tr, .ar, .cl, .co, .pe) | 897 | 17,2 % | 13,6 % |
Global (.com, .net, .org, etc.) | 5 734 | 19,2 % | 15,7 % |
Les sites en ccTLD de l’UE bloquent l’IA à deux fois le rythme du groupe national hors UE et presque deux fois celui de la base mondiale en .com. La différence est cohérente à travers les États membres de l’UE (aucun pays unique ne tire la moyenne) et cohérente à travers les secteurs (.de médias à 88 %, .de SaaS à ~12 %, .de e-commerce à ~25 % — tous plus élevés que leurs équivalents mondiaux).
Nous avons trouvé 275 fichiers robots.txt du top-10k qui citent explicitement la directive 2019/790 dans leurs commentaires — environ 3,8 % de l’échantillon analysable. Le groupe est dominé par les éditeurs de l’UE, mais déborde au-delà d’eux : plusieurs marques d’actualité américaines (notamment le NYT, qui cite directement « Art. 4 of the EU Directive »), quelques sites britanniques et une poignée de grandes plateformes e-commerce européennes reprennent ce langage juridique. 87 fichiers mentionnent « TDM » ou « text and data mining » par leur nom. 460 fichiers contiennent une forme de langage de réserve des droits d’auteur (« expressément refuse l’opt-out », « tous droits réservés », « pas d’usage commercial », « pas de machine learning »), même lorsqu’ils ne citent pas de texte précis.
Deux observations plus fines ressortent de cette coupe :
L’effet UE ne concerne pas que les médias. À secteur constant (hors médias), les sites de l’UE bloquent encore l’IA à des taux supérieurs à ceux des sites hors UE (environ 28 % contre 14 %). Une petite mais réelle part du SaaS, de l’e-commerce et de l’académie en UE a intégré le cadre de l’article 4 pour ses propres besoins sectoriels.
Le langage inspiré de l’UE devient un modèle de facto même hors UE. Le modèle robots.txt géré par Cloudflare — adopté mondialement — cite explicitement « ARTICLE 4 OF THE EUROPEAN UNION DIRECTIVE 2019/790 » dans son boilerplate. Un site américain qui active le réglage « Block AI Bots » de Cloudflare affirme, sans forcément le savoir, une réserve de droits statutaire de l’UE. C’est l’un des artefacts les plus intéressants de dérive politique que nous ayons trouvés : un concept juridique européen est mondialisé via l’interface produit d’un fournisseur d’infrastructure américain.
Résultat 8 — Modèles et origines de modèles
Répartition des modèles à l’origine des 6 638 sites ayant renvoyé un robots.txt analysable :
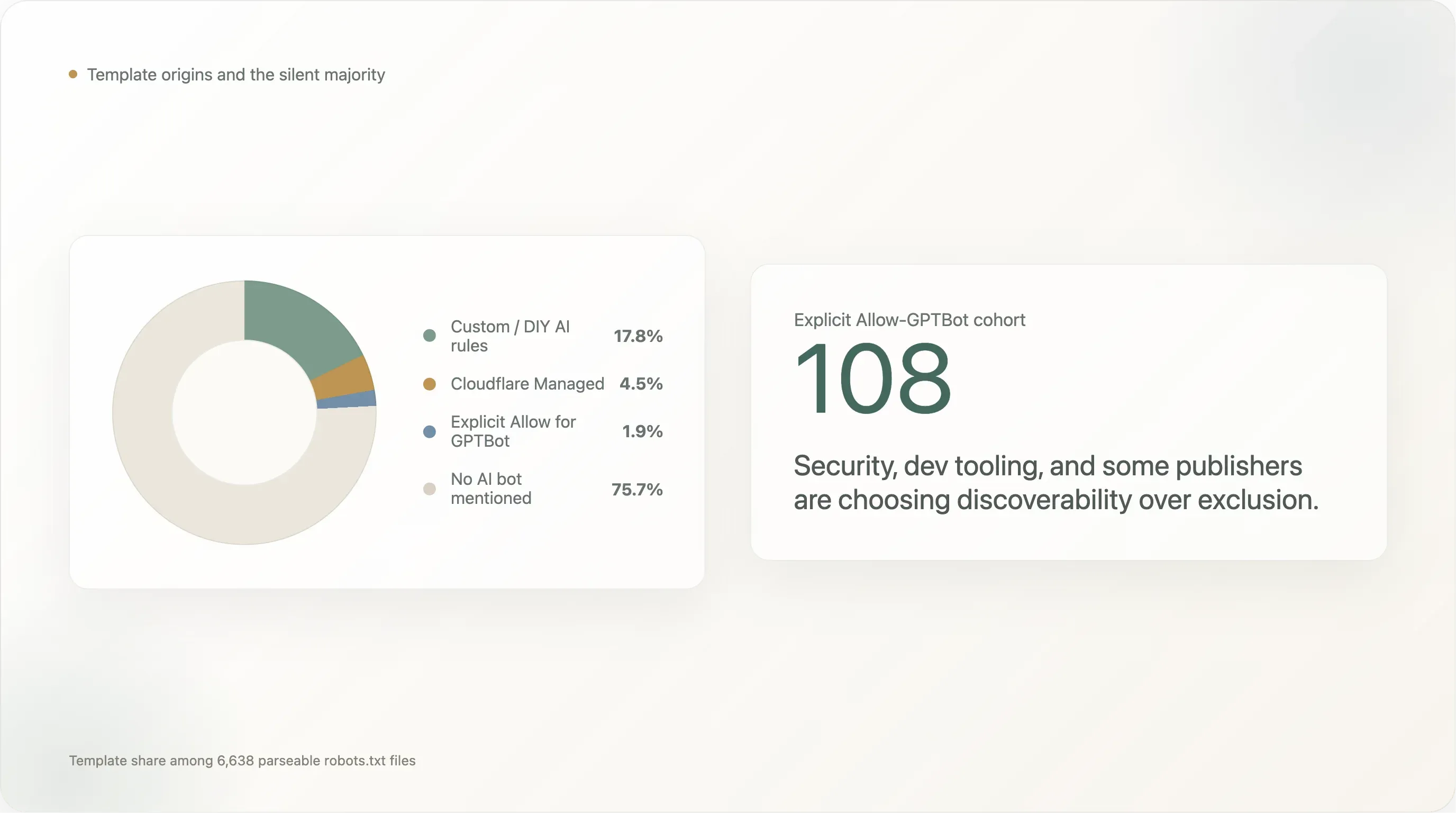
| Modèle | Sites | Part |
|---|---|---|
| Aucun bot IA mentionné (valeur par défaut type Shopify, Yoast, rédaction manuelle sans considération IA) | 5 024 | 75,7 % |
| Règles IA personnalisées / DIY | 1 183 | 17,8 % |
Cloudflare Managed (Content-Signal: search=yes,ai-train=no) | 302 | 4,5 % |
Allow: / explicite pour GPTBot | 124 | 1,9 % |
| Squarespace par défaut (28 UA IA dans le bloc restreint par chemin) | 5 | 0,1 % |
Les règles DIY dominent à 17,8 %. Le groupe des bloqueurs rédigés en interne est mené par toutes les plateformes sociales (facebook.com, twitter.com, linkedin.com, whatsapp.com, tiktok.com, snapchat.com, pinterest.com, x.com, chatgpt.com lui-même), les plus grandes destinations e-commerce (amazon.com, amazonvideo.com), les grandes marques d’actualité (nytimes.com, cnn.com, bbc.com, theguardian.com, forbes.com, reuters.com, bbc.co.uk, t-online.de, weather.com), des acteurs clés du streaming / médias (netflix.com, vimeo.com, soundcloud.com, imdb.com), et une longue traîne de sites de services professionnels (canva.com, medium.com).
Cloudflare Managed se situe à 4,5 % — bien plus haut que la pénétration de ce même modèle dans la toute première partie de la courbe, mais plus bas que sa pénétration dans la longue traîne hors de notre fenêtre. Le modèle est surtout adopté dans le segment classé 1 001–10 000 (4–5 %) et est quasiment absent du tout sommet de la courbe (Top 100 : 1 site l’utilise ; Top 101–1 000 : 5 sites). Les grandes propriétés mondiales rédigent leurs propres règles ; la longue traîne utilise le bouton.
Quelques sites Cloudflare Managed méritent une mention. cloudflare.com lui-même utilise le modèle, ce qui est cohérent (Cloudflare « dogfood » son propre produit sur son propre domaine). theatlantic.com utilise le modèle — la seule grande marque d’actualité américaine que nous ayons trouvée sans règle personnalisée. spankbang.com utilise le modèle — le site adulte le mieux classé à avoir adopté un blocage IA injecté par Cloudflare. linktr.ee utilise le modèle, bloquant l’entraînement IA sur toute l’économie des créateurs hébergée par Linktree en une seule décision de fournisseur. launchpad.net, nexusmods.com, vinted.fr, cookielaw.org, rustdesk.com, et une longue liste de petits médias complètent le groupe visible Cloudflare Managed.
Le schéma d’adoption de Cloudflare est la preuve la plus concrète que la majeure partie de « la politique IA du web » est décidée par les fournisseurs d’infrastructure. La part absolue est faible (4,5 %), mais structurellement importante : le modèle est celui que Cloudflare livre par défaut, et la trajectoire vers un activé-par-défaut sur les 12 prochains mois est ascendante. Si Cloudflare bascule l’option en mode activé par défaut pour les nouveaux comptes, le taux global de blocage augmentera sensiblement sans qu’aucun éditeur n’ait à prendre de décision.
Le défaut Squarespace (5 sites dans le top-10k, mais un groupe bien plus large hors de notre échantillon) est un schéma différent : Squarespace livre un robots.txt qui nomme 28 bots IA dans un seul bloc, mais ces bots héritent des restrictions de chemin de User-agent: * au lieu de recevoir une interdiction globale. Les crawlers IA peuvent récupérer /, la page d’accueil, les pages produit, le blog. Ils ne peuvent simplement pas récupérer /config ou /account. Nous avons déjà signalé cela comme source de faux positifs dans des scans tiers de sites Squarespace ; la même réserve s’applique ici.
Résultat 9 — La politique IA est uniforme selon la distribution des rangs
L’intuition classique pour ce type d’étude est que les sites les plus visités auraient la politique IA la plus agressive — ils ont le plus à perdre en matière de substitution d’entraînement, la plus grande capacité juridique, et la plus forte exposition publique. Les données ne confirment pas cette intuition.
| Tranche de rang | n | Tout blocage IA | Explicite | Cloudflare Managed |
|---|---|---|---|---|
| Top 100 | 67 | 22,4 % | 17,9 % | 1 site |
| Top 101–1 000 | 598 | 22,9 % | 19,2 % | 5 sites |
| Top 1 001–5 000 | 2 810 | 19,0 % | 15,3 % | 99 sites |
| Top 5 001–10 000 | 3 773 | 20,8 % | 17,8 % | 197 sites |
Les quatre tranches se situent entre 19 % et 23 %. Le Top 100 n’est pas plus agressif que la longue traîne 5 001–10 000. Le chiffre phare semble être une propriété du web public en 2026, pas le reflet de la taille ou de la notoriété d’un site individuel.
Deux facteurs y contribuent. D’abord, le sommet de la courbe est dominé par des domaines d’infrastructure / SaaS / recherche / portail (Microsoft, Apple, Google, etc.) qui ont eux-mêmes de faibles taux de blocage IA. Ensuite, la longue traîne comprend une forte proportion d’éditeurs régionaux et de sites soumis à la juridiction de l’UE qui — comme l’ont montré les résultats 6 et 7 — bloquent l’IA plus agressivement que la moyenne mondiale. Les deux effets se compensent à peu près, d’où un chiffre global uniforme.
La colonne Cloudflare Managed, elle, évolue le long de la courbe. Le Top 1 000 compte 6 sites gérés par Cloudflare (1,0 %) ; le Top 1 001–10 000 en compte 296 (5,7 %). Les grands sites rédigent eux-mêmes leurs règles ; la longue traîne utilise le bouton du fournisseur. C’est le seul signal pertinent dépendant du rang dans le jeu de données, et il suggère que plus on descend de la tête du web vers la longue traîne, plus la part de la politique IA définie par le fournisseur plutôt que par l’éditeur augmente régulièrement. Nous nous attendons à ce gradient au-delà du top 10k, jusque dans le top 100k et au-delà.
Résultat 10 — Cinq anatomies : à quoi ressemble robots.txt quand c’est vraiment une politique
Les chiffres décrivent la forme du jeu de données ; le caractère réel de la « politique IA sur le web public » se voit mieux en lisant des fichiers précis. En voici cinq qui méritent qu’on s’y arrête, choisis pour couvrir tout l’espace des politiques.
Anatomie 1 — The New York Times (nytimes.com)
Les 14 premières lignes de nytimes.com/robots.txt :
1# New York Times content is made available for your personal, non-commercial
2# use subject to our Terms of Service here:
3# https://help.nytimes.com/hc/en-us/articles/115014893428-Terms-of-Service.
4# Use of any device, tool, or process designed to data mine or scrape the content
5# using automated means is prohibited without prior written permission from
6# The New York Times Company. Prohibited uses include but are not limited to:
7# (1) text and data mining activities under Art. 4 of the EU Directive on Copyright in
8# the Digital Single Market;
9# (2) the development of any software, machine learning, artificial intelligence (AI),
10# and/or large language models (LLMs);
11# (3) creating or providing archived or cached data sets containing our content to others; and/or
12# (4) any commercial purposes.
13# Contact https://nytlicensing.com/contact/ for assistance.Ici, robots.txt devient une pièce juridique. Le fichier est structuré pour pouvoir être produit comme preuve dans le contentieux NYT v. OpenAI auquel il appartient. Les références à « Art. 4 of the EU Directive » — de la part d’un éditeur américain — illustrent l’observation du Résultat 7 selon laquelle les cadres juridiques de l’UE se diffusent dans le discours mondial. L’interdiction explicite de « créer ou fournir des jeux de données archivés ou mis en cache » vise directement Common Crawl. Le fichier dépasse 60 lignes avec des blocs User-agent nommés pour GPTBot, OAI-SearchBot, ChatGPT-User, anthropic-ai, ClaudeBot, CCBot, Google-Extended, Applebot-Extended, Bytespider, Diffbot, Meta-ExternalAgent, Amazonbot, Omgili, Omgilibot, et plusieurs autres — chaque bot nommé a son propre Disallow: /.
Anatomie 2 — Der Spiegel (spiegel.de) — permission IA au niveau des sections
Der Spiegel possède le robots.txt le plus sophistiqué sur le plan opérationnel que nous ayons trouvé dans tout le jeu de données. Le bloc pertinent :
1# TLP-6507: Testweise Freischaltung der OpenAI-Suchcrawler fuer ausgewaehlte Bereiche
2User-agent: OAI-SearchBot
3Allow: /ausland/
4Allow: /partnerschaft/
5Allow: /gesundheit/
6Allow: /familie/
7Allow: /reise/
8Allow: /psychologie/
9Allow: /stil/
10Disallow: /
11User-agent: ChatGPT-User
12Allow: /ausland/
13Allow: /partnerschaft/
14Allow: /gesundheit/
15Allow: /familie/
16Allow: /reise/
17Allow: /psychologie/
18Allow: /stil/
19Disallow: /Le commentaire se traduit par « activation à l’essai des crawlers de recherche OpenAI pour des sections sélectionnées ». Spiegel a mis sur liste blanche sept catégories de contenu précises — international, partenariats, santé, famille, voyage, psychologie et style de vie — pour les UA d’inférence d’OpenAI, tout en bloquant le reste. Les rubriques politiques, l’actualité allemande nationale et l’investigation sont explicitement exclues. Common Crawl, Bytespider, Cohere, Webzio-Extended et les autres UA d’entraînement reçoivent plus bas dans le fichier un Disallow: / complet.
C’est robots.txt comme politique éditoriale au niveau de la section. La théorie implicite est que les contenus lifestyle présentent moins de risque de substitution d’entraînement et plus de potentiel de citation par inférence, donc Spiegel autorise l’IA à faire remonter ces rubriques ; les contenus politiques et d’investigation constituent la barrière défensive, donc l’IA en est exclue. Nous n’avons vu ce schéma nulle part ailleurs. Il implique un niveau de coordination interne entre rédaction, juridique et infrastructure que la plupart des rédactions n’ont pas encore atteint. Nous nous attendons à ce genre d’expression granulaire au niveau des sections à se diffuser en 2026–2027 — le fichier de Spiegel est en pratique un indicateur avancé.
Anatomie 3 — BBC (bbc.com) — la forme « déclaration de politique »
Le robots.txt de la BBC s’ouvre par :
1# version: ec59bd036e5138eb4831a9ed44447b1ff310e235
2# The BBC's Terms of Use: https://www.bbc.co.uk/terms
3# - Explain the rules for using our services
4# - Tell you what you can do with our content
5#
6# In short: Please use our site like a human, not a robot.
7# That means:
8# - No scraping, crawling, or systematic extraction of content
9# - No use of BBC content for training or fine-tuning AI models, including LLMs
10# - No retrieval-augmented generation (RAG), AI-powered search, agentic AI or
11# grounding using BBC content
12# - No creating datasets from BBC content
13# - No text and data mining (TDM) under Article 4 of the EU Directive on Copyright
14# - No using BBC content to create summaries for your own use
15# - No business use without permission
16# - The BBC reserves all rights in its content and expressly opts out of any
17# statutory exceptions in any jurisdiction for text and data mining,
18# as permitted by law
19#
20# TL;DR: Browse, read, watch, enjoy - like a human.La BBC versionne son robots.txt (# version: ec59bd... est un hash de commit git), interdit huit usages spécifiques de l’IA qu’elle surveille, et conclut par un résumé en une ligne dans le ton narratif propre à la marque BBC. La formule « expressly opts out of any statutory exceptions in any jurisdiction » correspond à une réserve globale délibérée — cela revient à dire nous ne faisons confiance à aucun régime juridique unique pour nous protéger, donc nous revendiquons l’opt-out partout à la fois. C’est le robots.txt le plus rédigé du jeu de données, et il ressemble davantage à un communiqué de presse qu’à un fichier de configuration.
Anatomie 4 — WordPress.org — l’accueil explicite
Comparez tout cela à wordpress.org :
1User-agent: GPTBot
2Allow: /
3User-agent: ClaudeBot
4Allow: /
5User-agent: anthropic-ai
6Allow: /
7User-agent: Google-Extended
8Allow: /
9User-agent: Applebot-Extended
10Allow: /
11User-agent: PerplexityBot
12Allow: /
13User-agent: Bytespider
14Allow: /
15User-agent: CCBot
16Allow: /
17User-agent: Copilot
18Allow: /WordPress.org choisit explicitement d’inclure neuf crawlers d’entraînement IA, dont trois (Bytespider, CCBot, anthropic-ai) parmi les plus souvent bloqués ailleurs. La théorie implicite est que la documentation WordPress et l’écosystème des extensions constituent un bien public dont la valeur augmente lorsque les assistants IA peuvent répondre à des questions à son sujet. Chaque fois que quelqu’un demande à Claude « comment configurer les permaliens dans WordPress ? » et que Claude a été entraîné sur wordpress.org/documentation/, la mission de WordPress est servie. La Fondation semble avoir estimé qu’être dans le corpus d’entraînement de tous les modèles constitue un avantage stratégique, et elle a utilisé la grammaire expressive du fichier pour le dire.
Anatomie 5 — The Verge (theverge.com) — le hybride sponsorisé
Un autre schéma mérite d’être montré. The Verge structure ses règles IA comme Disallow: / \ Allow: /sp/ :
1User-agent: GPTBot
2Allow: /
3User-agent: Applebot
4Allow: /
5User-agent: Google-Extended
6Disallow: /
7Allow: /sp/
8User-agent: anthropic-ai
9Disallow: /
10Allow: /sp/
11User-agent: Bytespider
12Disallow: /
13Allow: /sp/
14User-agent: CCBot
15Disallow: /
16Allow: /sp/
17User-agent: ChatGPT-User
18Disallow: /
19Allow: /sp/
20User-agent: ClaudeBot
21Disallow: /
22Allow: /sp/Le chemin /sp/ correspond à la section de contenu sponsorisé / partenaire de The Verge. Le contenu éditorial est bloqué pour l’entraînement IA ; le contenu sponsorisé est autorisé. La logique économique est claire : les sponsors paient pour que leur contenu soit découvrable, y compris par l’IA ; la vitrine éditoriale reste la barrière défensive. GPTBot est entièrement ouvert (probablement en raison d’une relation directe avec OpenAI), Applebot est entièrement ouvert comme base de recherche, et les autres reçoivent un traitement hybride. C’est la seule structure de « hiérarchisation de l’accès IA » de ce type que nous ayons trouvée.
Ces cinq fichiers décrivent l’éventail actuel des politiques IA dans robots.txt. La plupart des fichiers du top 10k ne ressemblent à aucun d’entre eux — ils sont soit silencieux, soit utilisent un modèle fournisseur. Ceux qui s’en rapprochent sont rédigés par des personnes qui ont décidé que le fichier valait la peine d’être lu attentivement.
Une note sur l’ampleur des fichiers : le corps médian de robots.txt dans notre échantillon fait 858 octets — trop petit pour encoder une politique IA significative. C’est dans la queue droite que se trouvent les règles : 1 005 sites (15,3 %) ont un fichier de plus de 5 Ko, 273 de plus de 20 Ko, et le maximum était de 248 Ko. 460 fichiers contiennent un langage de réserve des droits d’auteur ; 275 citent la directive 2019/790 par son nom. En 2026, robots.txt est de plus en plus un document versionné, relu par des juristes, et non une simple ligne de configuration.
Résultat 11 — 108 sites accueillent explicitement GPTBot
Une petite mais visible cohorte écrit une règle User-agent: GPTBot \n Allow: / — l’inverse du plus discuté « Disallow GPTBot ». Le total complet dans notre échantillon est de 108 sites avec une autorisation explicite pour GPTBot à la racine. Les 25 premiers par rang Tranco :
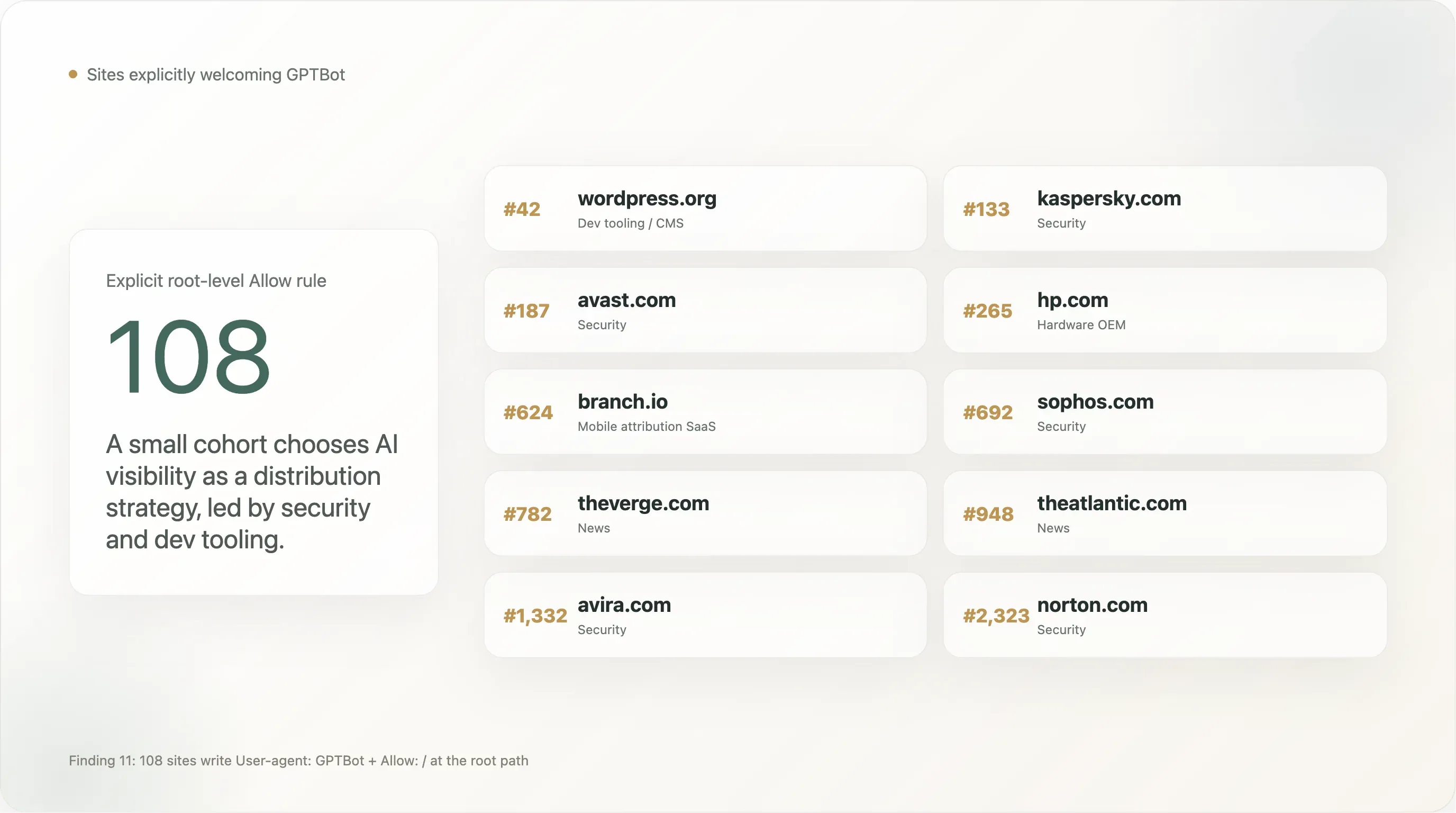
| Rang | Domaine | Secteur |
|---|---|---|
| 42 | wordpress.org | Outils dev / CMS |
| 133 | kaspersky.com | Sécurité |
| 187 | avast.com | Sécurité |
| 265 | hp.com | Fabricant matériel |
| 624 | branch.io | SaaS d’attribution mobile |
| 692 | sophos.com | Sécurité |
| 782 | theverge.com | Médias |
| 905 | rambler.ru | Portail russe |
| 945 | kleinanzeigen.de | Marketplace allemande |
| 948 | theatlantic.com | Médias |
| 1 092 | lge.com | LG Electronics |
| 1 300 | justdial.com | Recherche locale indienne |
| 1 332 | avira.com | Sécurité |
| 1 412 | youm7.com | Médias égyptiens |
| 1 530 | goodreturns.in | Finance indienne |
| 1 621 | publi24.ro | Petites annonces roumaines |
| 1 807 | geocomply.com | SaaS de conformité |
| 1 908 | nba.com | Sport |
| 1 956 | oneindia.com | Médias indiens |
| 1 974 | mindbox.ru | SaaS russe |
| 2 009 | thesun.co.uk | Médias |
| 2 126 | vox.com | Médias |
| 2 140 | mgid.com | Publicité native |
| 2 314 | ninjarmm.com | SaaS de gestion IT |
| 2 323 | norton.com | Sécurité |
Quelques tendances :
Les entreprises de sécurité sont manifestement surreprésentées. Kaspersky, Avast, Sophos, Avira, Norton, NinjaRMM autorisent toutes explicitement GPTBot. C’est une stratégie de distribution assumée : quand un utilisateur demande à ChatGPT « quel est le meilleur antivirus pour mon PC Windows ? », le fait que la marque soit dans le corpus d’entraînement du modèle influence directement la recommandation. La sécurité est l’un des rares segments B2C où la recherche IA remplace déjà le SEO comme canal d’acquisition principal, et ces marques ont agi en premier. Nous nous attendons à ce que le reste du secteur suive dans les 12 mois.
Certaines grandes marques d’actualité figurent sur cette liste, et non sur la liste noire. The Verge, The Atlantic, Vox, The Sun, NBA.com. Ce n’est pas une contradiction — ces éditeurs semblent avoir décidé qu’être cité dans la recherche ChatGPT valait mieux que d’être protégé de l’entraînement, et ils ont écrit la règle Allow explicite pour se prémunir contre un futur surblocage de la part de leur CDN ou de leur CMS. Comparez avec la posture NYT / Reuters / BBC / Forbes / Guardian d’un Disallow explicite. Les deux positions se défendent ; l’industrie des médias n’est pas monolithique.
La présence de The Sun est notable parce que le même site utilise ailleurs dans son fichier un bloc deny-all User-agent: *. La politique de The Sun se lit au mieux comme « l’entraînement IA est interdit, la recherche IA est permise, et nous avons explicitement mis GPTBot sur liste blanche comme exception au deny-all afin de nous assurer que ChatGPT puisse répondre à des questions en citant The Sun. » C’est la règle GPTBot-Allow la plus sophistiquée juridiquement — un opt-out plus un opt-in à fournisseur unique.
La présence de WordPress.org est l’entrée la plus déterminante de la liste. Une part non négligeable de l’écosystème CMS open source mondial pointe vers WordPress.org pour sa documentation ou héberge des extensions provenant de là. En autorisant explicitement GPTBot dans wordpress.org/robots.txt, la Fondation WordPress a de facto indiqué que l’écosystème de documentation WordPress est ouvert à l’entraînement — avec des effets en cascade sur la capacité de Claude, Gemini et ChatGPT à répondre aux questions « comment faire… » concernant WordPress.
Les 83 autres sites de la liste complète d’autorisation GPTBot forment une longue traîne de médias régionaux, de petits éditeurs de sécurité, de plateformes de petites annonces dans des marchés non anglophones et de SaaS B2B. À notre connaissance, il n’existe pas de coordination sectorielle équivalente « Allow-GPTBot » — la règle est adoptée site par site, par des opérateurs qui ont décidé que faire partie du corpus était la position stratégique.
Résultat 12 — llms.txt n’est à cette échelle qu’une rumeur
llms.txt, le format alternatif proposé pour la découverte de contenus compatibles LLM (promu par Mintlify, Anthropic, Vercel et quelques éditeurs d’outils dev depuis fin 2024), est quasiment absent de notre échantillon.
Parmi les 6 638 sites ayant renvoyé un robots.txt analysable, 83 (1,15 %) mentionnent llms.txt — généralement sous la forme d’une ligne Sitemap: https://example.com/llms.txt. C’est deux ordres de grandeur de moins que la même mesure observée sur des échantillons de commerce fortement orientés outils dev, où les valeurs par défaut de Vercel et Mintlify gonflent l’adoption.
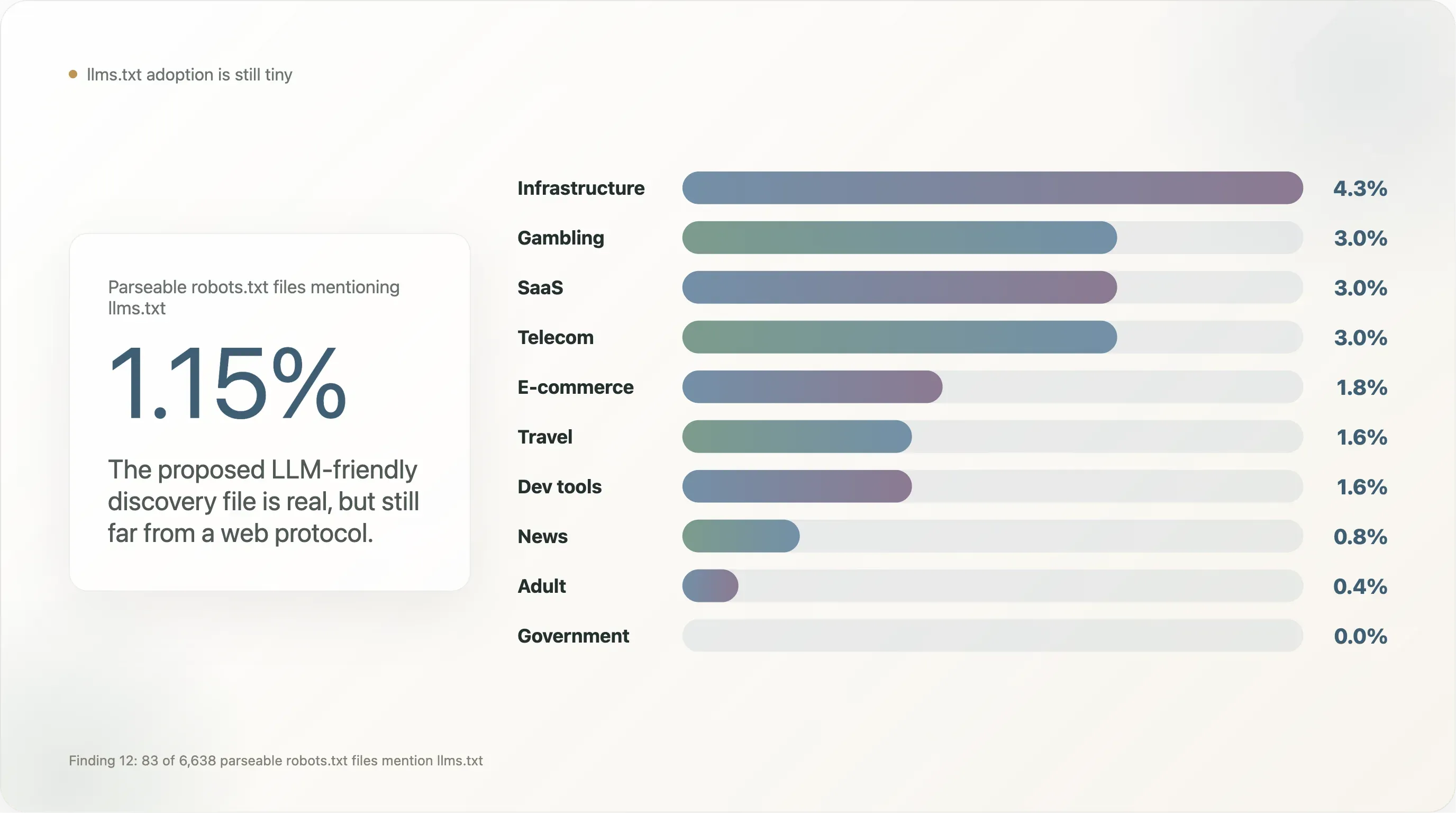
Répartition par secteur :
| Secteur | n | % mentionnant llms.txt |
|---|---|---|
| Infrastructure | 47 | 4,3 % |
| Jeux d’argent | 100 | 3,0 % |
| SaaS | 369 | 3,0 % |
| Télécom | 33 | 3,0 % |
| E-commerce | 224 | 1,8 % |
| Voyage | 64 | 1,6 % |
| Outils dev | 129 | 1,6 % |
| Médias | 650 | 0,8 % |
| Adultes | 254 | 0,4 % |
| Gouvernement | 172 | 0,0 % |
| Académie | 268 | 0,0 % |
| Recherche | 12 | 0,0 % |
llms.txt est concentré dans les SaaS proches des outils dev, les jeux d’argent (qui adoptent plus vite que d’autres secteurs régulés les nouvelles fonctionnalités robots.txt parce qu’ils disposent d’équipes conformité habituées à empiler des métadonnées) et l’e-commerce B2B. Son absence est frappante dans les médias et le gouvernement — les deux segments les plus impliqués dans la politique IA et dont l’adoption serait nécessaire pour que la norme passe du stade « expérience fournisseur » à celui de « protocole web ». D’ici là, llms.txt est bien réel mais encore marginal, et un audit de suivi fin 2026 sera un bon test de confirmation.
Le problème structurel auquel llms.txt se heurte est qu’il n’est normalisé par aucun processus IETF et qu’aucun grand fournisseur d’IA ne s’est engagé à le respecter. Une règle robots.txt repose sur 30 ans d’infrastructure de crawl ; une règle llms.txt, non. Tant qu’au moins un grand fournisseur (OpenAI, Anthropic, Google, Cloudflare) ne déclarera pas un support formel, le fichier restera essentiellement un artefact marketing de l’écosystème Mintlify / Vercel. Nous ne pensons pas que cela change en 2026.
Résultat 13 — Accessibilité : robots.txt reste lisible pour les deux tiers du haut du web
Observation secondaire qui ne devait pas devenir un résultat : 66 % des 10 000 sites les plus visités ont renvoyé un robots.txt analysable à une seule IP de recherche, et seuls 7 sur 10 000 (0,07 %) ont renvoyé 429 Too Many Requests. C’est une bonne nouvelle pour robots.txt en tant que protocole public.
À titre de comparaison, la même chaîne exécutée deux mois plus tôt sur un échantillon commerce de 1 008 domaines de taille intermédiaire a reçu des 429 de 52 % des domaines résolus — les CDN Shopify et Cloudflare limitant agressivement le débit de tout UA qui n’est pas un grand moteur de recherche. Le web à fort trafic est bien plus accueillant : les grands sites ont plus de chances soit (a) d’avoir des niveaux de bot-management moins agressifs, soit (b) des listes blanches explicites pour des crawlers de recherche connus, soit les deux.
Le taux de fetch_failed de 21 % sur le top-10k est dominé par des domaines d’apex CDN (akamai.net, cloudfront.net, fastly.net, apple-dns.net, gtld-servers.net) qui n’exécutent pas de serveur web sur /. Ils ne nous bloquent pas ; ils n’ont simplement rien à servir. En les excluant, le vrai taux d’échec « nous avons essayé de lire mais n’avons pas pu » tombe à quelques points de pourcentage.
Cela signifie que les prochaines itérations de ce rapport — instantanés trimestriels, comparaisons d’une année sur l’autre — peuvent être exécutées à faible coût et de manière reproductible sur une seule machine. La fenêtre d’audit reste ouverte au sommet de la courbe. Le cas asymétrique est la longue traîne et le segment e-commerce, où la limitation au niveau CDN a déjà, de fait, privatisé robots.txt. Nous nous attendons à ce que cette divergence s’accentue : les grands sites resteront lisibles parce qu’ils sont indexés par des moteurs de recherche qui exigent la lisibilité ; l’e-commerce de longue traîne deviendra moins lisible à mesure que les niveaux de lutte contre les bots de Cloudflare seront déployés plus agressivement. L’auditabilité publique de robots.txt se scinde selon la même ligne qui sépare « le web visible » du « web opérationnellement protégé ».
IV. Ce que tout cela signifie
Quatre affirmations, classées selon la force avec laquelle les données les soutiennent.
1. L’internet a une politique IA par secteur, pas une politique globale. L’écart de 12x entre médias et télécom domine tous les chiffres agrégés. Rapporter « X % du web bloque l’IA » sans découpage sectoriel surestime SaaS / gouvernement / dev et sous-estime médias / voyage / social. Le découpage par secteur est la seule manière honnête de cadrer ces données.
2. L’article 4 de la directive européenne sur le droit d’auteur est le seul régime juridique qui déplace visiblement les chiffres. Les sites en ccTLD de l’UE bloquent à 35 % contre une base mondiale de 19 %. Le contentieux américain (NYT contre OpenAI, rapport de l’US Copyright Office de janvier 2025) a fait bouger la cohorte des médias américains, mais pas le web américain dans son ensemble. Le cadre européen se diffuse aussi à l’échelle mondiale via le modèle de Cloudflare, qui cite la directive 2019/790 dans son boilerplate quelle que soit la juridiction du client.
3. Deux « politiques IA » parallèles sont exprimées et elles ne coïncident pas. La politique délibérée, rédigée à la main (17,8 %, surtout médias / social / voyage / e-commerce) et la politique héritée gérée par Cloudflare (4,5 %) se recoupent sur le fond mais diffèrent en légitimité. Dans un monde où les opérateurs IA cherchent un habillage juridique pour ignorer robots.txt, l’argument « nous l’avons rédigée et relue » est structurellement plus fort que « je l’ai juste activée ». L’incitation contentieuse est d’amener la politique de la deuxième catégorie vers la première.
4. C’est le corpus, pas le modèle, que les éditeurs bloquent. CCBot à 16,3 % — plus élevé que n’importe quel bot de marque de modèle — est l’énoncé le plus clair de ce constat. Bloquer OpenAI ne suffit pas à sortir d’un entraînement ; bloquer CCBot, si. 14,1 % du top-10k du web bloque CCBot tout en laissant Googlebot bienvenu. Le schéma « bloquer l’entraînement, garder la recherche » est la règle IA dominante en 2026.
Pour les sites qui réfléchissent à leur propre posture : la posture médiane est le silence — 80 % du top 10k ne disent rien de l’IA. Les 17 % qui rédigent des règles se concentrent sur Disallow, mais une petite cohorte en croissance (la liste explicite Allow-GPTBot, 1,5 %, menée par les éditeurs de sécurité) choisit publiquement l’inverse. Il n’existe pas de consensus sectoriel, et il n’y en aura pas dans les douze prochains mois.
Pour les opérateurs IA : il devient de plus en plus difficile de soutenir que robots.txt est un protocole obsolète aux sémantiques ambiguës alors que 17 % des plus grands sites du monde ont rédigé des règles explicites et volontaires nommant des bots à la main, et que 3,8 % des fichiers citent un texte européen précis avec numéro d’article. Le choix de respecter ou non ces règles relève d’une décision d’affaires ; leur existence est désormais un fait empirique.
V. Perspective : ce que nous attendons d’ici fin 2026
Trois trajectoires visibles dans les données :
Cloudflare Managed doublera largement sa part, et pourrait atteindre 10 % ou plus du top-10k analysable. La feuille de route de Cloudflare évoque publiquement l’activation par défaut du blocage des bots IA pour les nouveaux comptes. Si l’option passe en mode activé par défaut, le taux global de blocage augmente de 5 à 8 points sans qu’aucun éditeur n’ait à prendre de décision. Nous saurons que cela se produit lorsque la part Cloudflare Managed de la tranche 5 001–10 000 dépassera son niveau actuel de 5,7 %.
Les politiques IA au niveau des sections (à la manière de Spiegel) se diffuseront parmi les grandes rédactions. La logique économique — laisser l’IA citer les contenus à faible enjeu, protéger les contenus barrière — est suffisamment convaincante pour que nous attendions au moins 10 autres grandes rédactions avec des règles au niveau des sections d’ici fin 2026. Surveillez d’abord la presse allemande et française de milieu de gamme ; le cadre juridique y récompense l’expérimentation.
La cohorte Allow-GPTBot explicite va s’agrandir, menée par le SaaS B2B et les outils dev. Quand la recherche IA deviendra un canal d’acquisition mesurable pour les éditeurs de logiciels (comme c’est déjà le cas pour la sécurité), le CMO marginal écrira User-agent: GPTBot \n Allow: / pour se prémunir contre un surblocage accidentel. Nous nous attendons à ce que la liste des 108 sites environ double d’ici la fin de l’année.
Ce que nous n’attendons pas : une évolution significative de la part silencieuse majoritaire. Les 80 % du web qui ne disent rien sur l’IA incluent des secteurs (gouvernement, télécom, infrastructure, SaaS B2B) qui n’ont aucune raison économique d’écrire une règle et aucune pression juridique pour le faire. Une politique IA universelle n’arrive pas.
VI. Limites
- Biais d’un seul instantané. Les récupérations ont eu lieu sur une fenêtre de 36 heures début mai 2026. Le fichier change quotidiennement dans le Top 100 ; attendez-vous à une dérive de 1 à 2 points de pourcentage par trimestre sur les chiffres phares.
- Lacunes de classification sectorielle. 6 593 des 10 000 sites sont restés
unknownaprès le classifieur à quatre couches. Les pourcentages par secteur sont robustes quand n est élevé (médias : 650, streaming : 440, saas : 369, académie : 268, adult : 254, e-commerce : 224, gouvernement : 172, finance : 129, dev : 129) et plus bruités sous n=30. La coupe des médias par pays est aussi limitée — DE/FR/UK ont n≥15, tandis que Corée/Suède/République tchèque reposent sur n=20–25. robots.txtest volontaire. UnDisallowest une demande, pas une barrière.Bytespider,PerplexityBotet d’autres ont été documentés comme ignorant les règles. Nous avons mesuré des déclarations de politique, pas leur application.- Audit sur IP unique, basée aux États-Unis. Nous n’avons pas pu lire 21 % des domaines résolus. La plupart sont des apex CDN sans serveur web ; une petite part correspond à des sites dont le CDN nous a signalés avant d’atteindre l’origine. Cela biaise légèrement l’échantillon vers des infrastructures plus anciennes et contre les sites géorestreints selon le pays d’origine.
- Sémantique de la liste Tranco. Tranco filtre pour la stabilité ; ce n’est pas un vrai classement fondé sur le comportement des utilisateurs. Les chiffres agrégés sont robustes au choix de la liste ; les positions de rang précises ne le sont pas.
- Aucune donnée de trafic. Nous avons mesuré la politique
robots.txt, pas le débit réel des bots IA. Politique et trafic ne coïncident pas toujours.
VII. Reproduire cette étude
Tout ce qui a servi à produire ce rapport se trouve dans le dossier de livraison.
- tranco_top10k.csv — liste d’entrée
- out/sites.csv — domaine × rang × secteur × langue × statut robots.txt (10 000 lignes)
- out/fetch_meta.csv — résultat de récupération par domaine (statut, schéma, octets, erreur)
- out/bot_status.csv — grille domaine × bot (250 000 lignes : bloqué, a_règle, statut_récupération)
- out/site_meta.csv — un enregistrement analytique par site (modèle, booléens de synthèse)
- out/analysis.json — chaque métrique citée dans le rapport
- 01_fetch_robots.py, 02_classify.py, 03_parse_and_analyze.py — chaîne Python complète
Les corrections de méthodologie, problèmes de jeu de données et analyses de suivi sont les bienvenues à l’adresse support@thunderbit.com. Ce rapport est publié indépendamment de toute position commerciale de Thunderbit ; nous construisons un extracteur Web IA, et nous avons un intérêt structurel à ce que robots.txt reste un contrat lisible par machine et significatif sur le web public. Les données de ce rapport se suffisent à elles-mêmes. — L’équipe de recherche Thunderbit, mai 2026.