

Construire un bon modèle de machine learning commence rarement par l'algorithme. Cela commence par les données — et plus précisément par des données correctement étiquetées. Or, dans la plupart des équipes que je croise, qu'elles cherchent à prévoir des ventes, à recommander des produits ou à mesurer le sentiment des clients, c'est exactement là que tout coince. Étiqueter à la main, c'est lent, c'est cher, et c'est usant. J'ai vu des projets entiers patiner pendant des semaines, parfois des mois, faute d'avoir assez d'exemples annotés pour entraîner quoi que ce soit de sérieux. Quant aux étiquettes incohérentes, elles produisent des prédictions auxquelles on finit par ne plus accorder aucune confiance.
L'automatisation de cet étiquetage par le machine learning vient renverser cette logique. En confiant à l'IA le gros du travail répétitif, les entreprises ne se contentent pas d'aller plus vite : elles gagnent aussi en précision et en cohérence, deux facteurs qui décident souvent du sort d'un projet de ML. Ce guide explique comment fonctionne l'étiquetage automatisé, pourquoi il pèse autant dans la robustesse d'un modèle, et comment des outils comme Thunderbit permettent de mettre en place votre propre chaîne d'étiquetage automatisé — sans écrire une ligne de code.
Qu'est-ce que l'étiquetage automatisé des données avec le machine learning ?
Reprenons depuis le début. L'étiquetage automatisé des données avec le machine learning consiste à laisser des algorithmes et des outils d'IA attribuer des étiquettes — « spam » ou « non spam », « chat » ou « chien », « positif » ou « négatif » — à des données brutes, sans qu'un humain ait à traiter chaque exemple un par un. C'est la différence entre taguer manuellement des milliers de photos de vacances et laisser la reconnaissance faciale les classer toutes seules par personne, par lieu ou même par ambiance.
L'étiquetage manuel classique correspond à ce que son nom indique : des personnes parcourent les données élément par élément et leur affectent la bonne étiquette. Précis dans certains cas, mais lent, onéreux et difficile à faire monter en charge. L'étiquetage automatisé procède autrement : il s'appuie sur des modèles de machine learning — entraînés sur un échantillon réduit de données annotées à la main — pour prédire les étiquettes du reste du jeu de données. On obtient ainsi un étiquetage plus rapide, plus régulier et nettement plus évolutif (GeeksforGeeks).
Pour les équipes métier, le message est simple : de meilleurs modèles, plus vite, et beaucoup moins de tâches manuelles ingrates. À une époque où tout se joue sur la donnée, c'est un avantage concurrentiel à part entière.
Automatisez l'étiquetage des données avec Thunderbit Utilisez l'Extracteur Web IA de Thunderbit pour automatiser votre workflow d'étiquetage des données — sans code. Get Started Free
Pourquoi l'étiquetage automatisé des données est essentiel à des modèles de machine learning de haute qualité
La qualité de vos données annotées conditionne directement la performance de vos modèles. L'adage « garbage in, garbage out » résume parfaitement la situation : si vos étiquettes sont bancales ou erronées, le modèle apprendra les mauvais schémas, et ses prédictions s'en ressentiront (DataCamp).
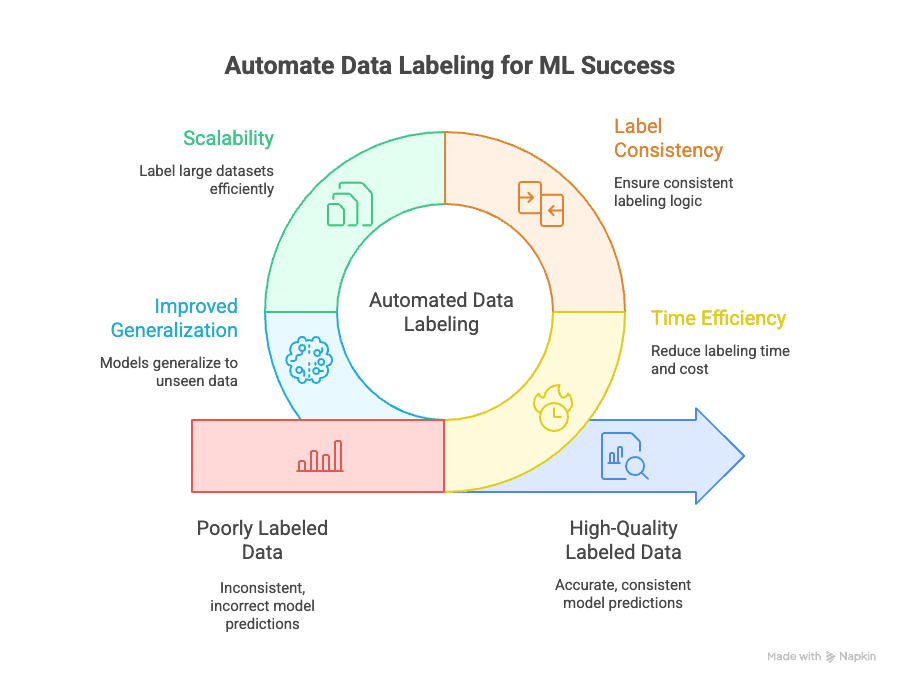
L'étiquetage automatisé répond à plusieurs enjeux concrets :
- Gain de temps : l'annotation manuelle peut absorber 70 % du temps total et du coût d'un projet de ML. L'automatisation réduit ce poids à une fraction et libère du temps pour itérer et déployer vos modèles.
- Cohérence des étiquettes : une machine ne fatigue pas et ne se déconcentre pas. Chaque point de données est traité selon la même logique, ce qui limite les erreurs humaines et les biais (GeeksforGeeks).
- Passage à l'échelle : étiqueter 10 000, 100 000 ou un million de points de données devient envisageable, sans recruter une armée d'annotateurs (Keylabs).
- Meilleure généralisation : des étiquettes régulières et soignées aident vos modèles à mieux se comporter face à des données inédites, ce qui reste l'objectif premier du machine learning (Kili Technology).
L'effet sur l'activité ne relève pas de la théorie : selon Keylabs, les chaînes hybrides combinant étiquetage assisté par IA et relecture humaine peuvent améliorer la précision jusqu'à 80 % par rapport à un travail purement manuel — d'où des cycles de modélisation plus courts et des prédictions plus fiables en aval.
Comparer l'étiquetage manuel et l'étiquetage automatisé des données
Voyons les deux approches en vis-à-vis :
| Facteur | Étiquetage manuel | Étiquetage automatisé avec ML |
|---|---|---|
| Vitesse | Lent (semaines/mois pour les grands jeux de données) | Rapide (minutes/heures pour les grands jeux de données) |
| Précision | Élevée, mais sujette aux erreurs/incohérences humaines | Élevée, avec une logique cohérente et moins d'erreurs |
| Passage à l'échelle | Limité par les ressources humaines | S'étend facilement à des millions de points de données |
| Coût | Coûteux (fortement lié à la main-d'œuvre) | Coûts à long terme plus faibles (Keylabs) |
| Idéal pour | Jeux de données petits, complexes ou ambigus | Jeux de données volumineux, répétitifs ou bien définis |
L'annotation manuelle garde tout son intérêt, en particulier pour les cas limites ou les données ambiguës. Mais pour la grande majorité des usages métier, l'automatisation l'emporte.
Les étapes de base de l'étiquetage automatisé des données avec le machine learning
Concrètement, comment cela se déroule-t-il ? Voici le déroulé de bout en bout que je recommande, et que j'applique moi-même :
- Collecte et prétraitement des données
- Extraction et préparation des caractéristiques
- Étiquetage automatisé à l'aide du machine learning
- Assurance qualité et relecture humaine
Détaillons chaque étape.
Étape 1 : collecte et prétraitement des données
Avant d'étiqueter quoi que ce soit, il faut rassembler et nettoyer vos données. Selon les cas, cela revient à extraire des fiches produits depuis des sites web, à exporter des avis clients ou à récupérer des images dans des bases internes. L'essentiel se joue sur la qualité : des données médiocres donnent des étiquettes médiocres, qui donnent à leur tour des modèles médiocres (Snorkel AI).
Bonnes pratiques :
- Supprimer les doublons et les éléments non pertinents
- Standardiser les formats (dates, devises, etc.)
- Gérer les données manquantes ou incomplètes
Étape 2 : extraction et préparation des caractéristiques
Vient ensuite l'identification des caractéristiques qui comptent pour votre tâche. Si vous étiquetez des fiches produits, vous extrairez par exemple le prix, la marque, la catégorie et la description. En vente ou en marketing, il s'agira plutôt de récupérer des noms d'entreprises, des coordonnées ou le sentiment exprimé dans des e-mails.
Exemple métier : avec Thunderbit, vous extrayez des données structurées depuis des pages web — caractéristiques produits, avis, coordonnées — sans rédiger la moindre ligne de code.
Étape 3 : étiquetage automatisé à l'aide du machine learning
C'est le cœur du dispositif. Vous mobilisez des modèles de machine learning, entraînés sur un échantillon réduit de données annotées à la main, pour prédire les étiquettes du reste de vos données. Les techniques les plus répandues :
- Modèles supervisés : entraîner un classifieur sur des exemples étiquetés, puis l'utiliser pour étiqueter de nouvelles données.
- Étiquetage basé sur des règles : appliquer des règles prédéfinies (par exemple, « si le prix > 1 000 $, étiqueter comme “premium” ») pour les cas simples.
- Apprentissage actif : le modèle sollicite un avis humain sur les cas incertains et progresse au fil du temps (GeeksforGeeks).
- Transfert d'apprentissage : réutiliser des modèles préentraînés pour amorcer plus vite l'étiquetage dans de nouveaux domaines (GeeksforGeeks).
À la clé : des étiquettes régulières et soignées, à grande échelle.
Étape 4 : assurance qualité et relecture humaine
Même les meilleurs modèles réclament un contrôle de bon sens. Une relecture humaine régulière permet de repérer les cas limites, les données ambiguës ou la dérive du modèle. Côté assurance qualité, quelques gestes concrets :
- Échantillonner au hasard des données étiquetées pour une relecture manuelle
- Confronter les étiquettes automatiques à un jeu de référence « gold standard »
- Mesurer la cohérence à l'aide de métriques d'accord entre annotateurs (Kili Technology)
Comment utiliser Thunderbit pour l'étiquetage automatisé des données avec le machine learning
Place à la pratique. Thunderbit est un Extracteur Web IA doublé d'un outil d'étiquetage, pensé pour les équipes métier — sans code requis. Voici comment l'utiliser pour automatiser votre chaîne d'étiquetage :
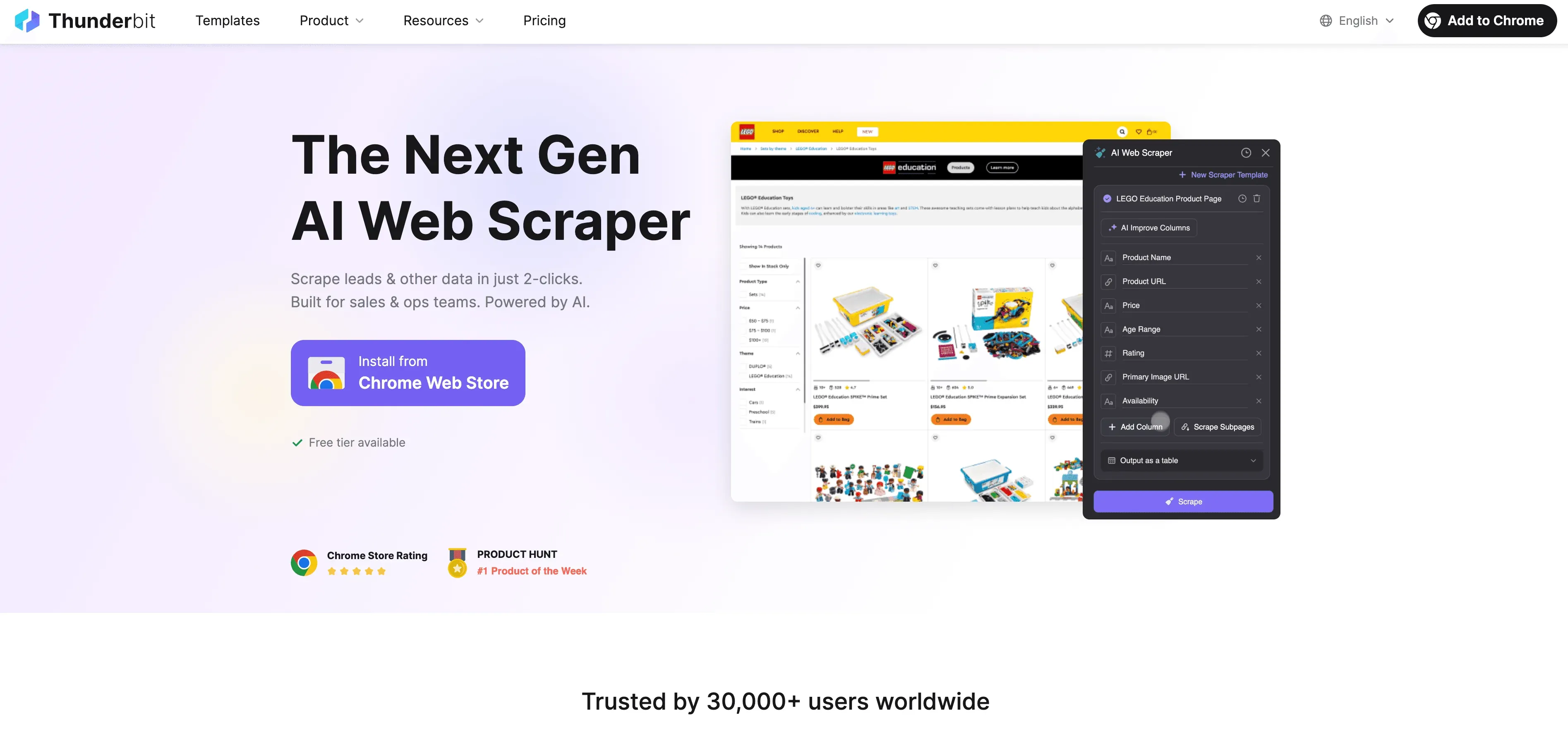
Guide étape par étape
- Extraire les données d'un site web : servez-vous de l'extension Chrome Thunderbit pour collecter des données structurées sur n'importe quel site. Ouvrez l'extension, indiquez votre source, et laissez l'IA de Thunderbit proposer les champs les plus pertinents à extraire.
- Définir les consignes d'étiquetage : dictez à l'IA la marche à suivre en langage naturel. Par exemple : « Étiquetez tous les produits à plus de 500 $ comme “premium” » ou « Marquez les avis au sentiment positif. »
- Lancer l'étiquetage automatisé : la fonctionnalité Field AI Prompt de Thunderbit vous laisse personnaliser et affiner la manière dont les étiquettes sont attribuées — idéale pour les tâches multi-champs ou les étiquetages délicats.
- Exporter les données étiquetées : une fois le travail terminé, exportez directement vers Excel, Google Sheets, Airtable ou Notion — prêt pour l'entraînement du modèle ou l'analyse.
Le meilleur dans tout ça ? Thunderbit s'adresse aux profils non techniques des équipes commerciales, marketing, opérations et bien d'autres. Aucune ligne de code à écrire, aucun modèle complexe à apprivoiser.
Essayez Thunderbit pour l'étiquetage automatisé des données
Les invites en langage naturel et les fonctionnalités Field AI de Thunderbit
Parmi mes fonctionnalités préférées : la possibilité de formuler la logique d'étiquetage en langage courant. Classer des leads par région, taguer des produits par catégorie, signaler les e-mails au ton pressant ? Décrivez ce que vous voulez, l'IA de Thunderbit fait le reste.
Exemples d'invites :
- « Étiquetez tous les contacts dont l'e-mail se termine par “.edu” dans le segment “Éducation”. »
- « Si l'avis mentionne “expédition rapide”, taguez-le comme “Expérience d'expédition positive”. »
- « Regroupez les produits par marque et par gamme de prix. »
Field AI Prompt pousse la logique encore plus loin : règles propres à chaque colonne, combinaisons de conditions, voire traduction des étiquettes dans plusieurs langues.
Extraction de sous-pages et étiquetage multi-champs
Des structures de données touffues ? Aucun souci. L'extraction de sous-pages de Thunderbit récupère et étiquette des données issues de pages imbriquées — fiches produits, biographies d'auteurs — puis fusionne le tout dans un seul tableau structuré. Vous étiquetez plusieurs champs d'un coup, et vous gagnez encore du temps.
Cas d'usage concret : extraire des fiches produits sur un site e-commerce, puis suivre chaque lien produit pour récupérer et étiqueter les spécifications, les avis et les infos vendeur — le tout dans un même workflow.
Intégrer plusieurs outils d'étiquetage des données pour plus de précision et d'efficacité
Thunderbit couvre déjà un terrain considérable, mais certains types de données — annotation d'images, étiquetage vidéo — appellent des outils spécialisés. C'est là qu'interviennent des plateformes comme Label Studio ou Supervisely.
Conseil de pro : appuyez-vous sur Thunderbit pour l'extraction web et l'étiquetage initial, puis exportez vos données vers Label Studio ou Supervisely pour l'annotation poussée (boîtes englobantes sur les images, tags vidéo image par image). En jouant la complémentarité des plateformes, vous tirez le meilleur de chacune et améliorez à la fois la précision et l'efficacité (GeeksforGeeks).
Quand utiliser des outils spécialisés aux côtés de Thunderbit
- Annotation d'images : pour la détection d'objets ou la segmentation, tournez-vous vers Supervisely ou Label Studio.
- Étiquetage vidéo : les outils vidéo dédiés gèrent l'annotation et le suivi image par image.
- Tâches complexes multi-étiquettes : associez l'extraction de données structurées de Thunderbit à des outils d'annotation avancés pour de meilleurs résultats.
Bonne pratique : démarrez avec Thunderbit pour un étiquetage rapide et évolutif des données structurées et semi-structurées, puis ajoutez des outils spécialisés au besoin pour l'annotation en profondeur.
Comment extraire des données d'un PDF avec l'IA Découvrez comment extraire et étiqueter des données depuis des PDF grâce aux outils IA de Thunderbit. Get Started Free
Bonnes pratiques pour l'étiquetage automatisé des données avec le machine learning
Pour tirer le maximum de votre chaîne d'étiquetage automatisé, voici mes recommandations :
- Poser des consignes d'étiquetage claires : des étiquettes floues donnent des données incohérentes — précisez ce que recouvre chaque étiquette.
- Partir d'un jeu de départ de qualité : étiquetez à la main un petit échantillon représentatif pour entraîner votre premier modèle.
- Itérer et améliorer : servez-vous de l'apprentissage actif pour affiner le modèle dans la durée, en concentrant la relecture humaine sur les cas les plus épineux.
- Valider régulièrement : repassez périodiquement un échantillon aléatoire de données étiquetées au crible pour repérer erreurs ou dérive.
- Intégrer et automatiser : reliez collecte, étiquetage et export dans un même workflow grâce à des outils comme Thunderbit.
Défis courants et comment les surmonter
L'étiquetage automatisé n'avance pas sans obstacles. Voici comment franchir les plus fréquents :
- Données ambiguës : posez des définitions d'étiquettes claires et détaillées, accompagnées d'exemples pour les cas limites.
- Dérive du modèle : réentraînez régulièrement votre modèle d'étiquetage avec des données fraîches relues à la main.
- Cas limites : prévoyez un circuit de relecture humaine pour les points de données incertains ou nouveaux.
- Problèmes d'intégration : retenez des outils (comme Thunderbit) dotés d'exports faciles vers vos plateformes habituelles.
Conclusion et points clés à retenir
L'étiquetage automatisé par le machine learning est l'ingrédient discret qui se cache derrière les modèles d'IA les plus performants du moment. Il fait gagner du temps, réduit les coûts et, surtout, fournit les étiquettes régulières et soignées dont vos modèles ont besoin pour donner leur pleine mesure. En associant des outils comme Thunderbit à des plateformes d'annotation spécialisées, vous bâtissez une chaîne d'étiquetage rapide, précise et évolutive — quel que soit votre niveau technique.
Envie de mesurer la différence par vous-même ? Téléchargez Thunderbit, testez l'étiquetage automatisé sur votre prochain projet et regardez vos modèles gagner en pertinence, plus rapidement. Et pour creuser le sujet, le blog Thunderbit regorge d'analyses détaillées et de tutoriels.
Automatisez l'étiquetage des données avec Thunderbit
FAQ
1. Qu'est-ce que l'étiquetage automatisé des données avec le machine learning ?
C'est le recours à l'IA et à des modèles de ML pour attribuer automatiquement des étiquettes aux données, plutôt que de confier ce travail à des humains. L'approche accélère l'étiquetage, en renforce la cohérence et tient la charge sur de grands jeux de données.
2. Pourquoi la qualité de l'étiquetage est-elle importante pour le machine learning ?
Un modèle n'apprend que les schémas inscrits dans ses étiquettes ; des étiquettes incohérentes ou fausses lui enseignent donc les mauvaises choses. Des analyses sectorielles publiées par des fournisseurs d'étiquetage comme Keylabs montrent que les chaînes hybrides IA + humain peuvent relever la précision jusqu'à 80 % par rapport aux approches purement manuelles — un gain qui se répercute directement sur les performances du modèle.
3. Comment Thunderbit aide-t-il à l'étiquetage automatisé des données ?
Thunderbit vous permet d'extraire et d'étiqueter des données web grâce à l'IA, à des invites en langage naturel et à une logique de champ personnalisable — sans code requis. Il convient particulièrement aux équipes commerciales, marketing et opérations.
4. Puis-je combiner Thunderbit avec d'autres outils d'étiquetage ?
Tout à fait. Utilisez Thunderbit pour l'extraction de données structurées et l'étiquetage initial, puis exportez vers des outils comme Label Studio ou Supervisely pour une annotation avancée d'images ou de vidéos.
5. Quelles sont les meilleures pratiques pour l'étiquetage automatisé des données ?
Poser des consignes claires, partir d'un jeu de départ de qualité, itérer avec l'apprentissage actif, valider régulièrement et relier ses outils pour fluidifier l'ensemble du workflow.
Prêt à automatiser l'étiquetage de vos données et à donner un nouvel élan à vos projets de machine learning ? Essayez Thunderbit et constatez tout le temps — et toute la frustration — que vous pouvez vous épargner.
En savoir plus :
- Comment extraire des données d'un PDF avec l'IA
- Qu'est-ce que le data scraping et comment le faire en 2025
- Qu'est-ce que le list crawling et comment le faire avec l'IA
- Comment extraire n'importe quel site web avec l'IA
Essayez l'Extracteur Web IA pour l'étiquetage automatisé des données Get Started Free




