

Onko web scraping laitonta? Se on se miljoonan dollarin kysymys, jota kuulen perustajilta, markkinoijilta ja datafriikeiltä joka viikko.
Kun 51 % kaikesta internetliikenteestä tulee nyt boteista — ensimmäistä kertaa automaattinen liikenne on ohittanut ihmisten toiminnan — ja suuri osa siitä on yritysten liiketoimintatiedon, myynnin ja AI-koulutuksen web scrapingia, ei ole ihme, että kaikki yrittävät selvittää, missä lailliset rajat kulkevat.
Yhtenä päivänä näet otsikon oikeuden ratkaisusta, jonka mukaan julkisen datan scrapaaminen on sallittua. Seuraavana sääntelyviranomaiset varoittavat sosiaalisen median "lainvastaisesta" datankeruusta. Tilanne on hämmentävä, jopa meille, jotka vietämme päivänsä AI web scraping -työkaluja rakentaen Thunderbitissä.
Onko web scraping siis laitonta? Vastaus ei ole yksinkertainen kyllä tai ei. Se riippuu siitä, mitä scrapaat, mistä scrapaat, miten käytät dataa ja mitä laki sanoo omassa maassasi.
Tässä syväluotaavassa katsauksessa käyn läpi oikeudellisen maiseman, puran auki yleisiä myyttejä ja jaan käytännön vinkkejä sekä muutaman opettavaisen tarinan siitä, miten pysyä lain ja käytäntöjen puolella — olitpa sitten yksinyrittäjä tai Fortune 500 -tason data-tiimi.
Web scraping ja laki: Onko olemassa selkeä raja?
Jos toivot yhden lauseen vastausta, säästän aikaasi: laki ei ole piirtänyt web scrapingille selkeää ja yksiselitteistä rajaa.
Sen sijaan kyseessä on päällekkäisten sääntöjen tilkkutäkki — omistusoikeus dataan, yksityisyys, immateriaalioikeudet, anti-hacking-lait ja pahamaineiset käyttöehdot (Terms of Service, ToS). Mikä tahansa näistä voi tulla kyseeseen, ja vastaus riippuu usein juuri sinun tilanteestasi (multilogin.com).
Puretaan asia kolmeen suureen oikeudelliseen koriin:
- Dataan kohdistuva omistusoikeus: Yleisesti ottaen faktat ja julkinen tieto (kuten hinnat tai puhelinnumerot) eivät nauti tekijänoikeussuojaa. Luova sisältö (artikkelit, kuvat) ja omat tietokannat voivat kuitenkin olla suojattuja — erityisesti EU:ssa, jossa "tietokantaoikeus" on oma juttunsa (cliffordchance.com).
- Yksityisyys: Nykyaikaiset tietosuojalait (esimerkiksi GDPR Euroopassa ja PIPL Kiinassa) käsittelevät henkilötietoja säänneltynä resurssina — vaikka ne olisi julkaistu julkisesti. Nimien, sähköpostien tai sosiaalisten profiilien scrapaaminen ilman lainmukaista perustetta voi viedä sinut hankaluuksiin (ico.org.uk).
- Sopimukset (käyttöehdot): Monet sivustot kieltävät scrapaamisen suoraan käyttöehdoissaan. Vaikka käyttöehdot eivät ole lakeja, tuomioistuimet voivat pitää niitä sitovina sopimuksina. Niiden rikkominen voi johtaa kanteisiin ja joissakin tapauksissa jopa anti-hacking-säännösten soveltumiseen, jos kierrät teknisiä estoja (cliffordchance.com).
Onko web scraping siis laitonta? Joskus kyllä, joskus ei — ja usein vastaus on "riippuu tapauksesta". Paholainen on yksityiskohdissa.
Oikeudelliset näkökulmat vertailussa: Yhdysvallat, EU, Iso-Britannia, Kiina
Tässä nopea taulukko siitä, miten eri alueet suhtautuvat web scrapingiin:
| Alue | Julkisen datan scrapaaminen | Henkilökohtaisen/yksityisen datan scrapaaminen | Täytäntöönpano ja olennaiset huomiot |
|---|---|---|---|
| Yhdysvallat | Yleisesti sallittua julkiselle datalle (katso hiQ v. LinkedIn). ToS:n rikkominen voi johtaa siviilikanteisiin. | Rajoitettua/laitonta, jos murtaudut kirjautumisen taakse tai käytät henkilötietoja väärin. Osavaltiokohtaiset lait (kuten CCPA) voivat tulla sovellettaviksi. | Kieltokirjeet, IP-estot, oikeusjutut. CFAA voi soveltua, jos ohitat tekniset esteet. |
| EU | Ehdollisesti sallittua ei-henkilökohtaista, julkista dataa varten. Tietokantaoikeudet voivat soveltua. EU AI Act (2026) tuo läpinäkyvyysvaatimuksia AI-koulutusdatalle. | Tiukasti säännelty GDPR:n alaisuudessa — jopa julkisesti saatavilla oleva henkilötieto tarvitsee lainmukaisen perusteen. | Tietosuojaviranomaiset voivat määrätä sakkoja tietosuojarikkomuksista. Myös tekijänoikeus- ja tietokantaoikeuksia valvotaan. EU AI Act kieltää kasvojen kuvien scrapaamisen AI:ta varten. |
| Iso-Britannia | Samanlainen kuin EU:ssa. Julkista, ei-henkilökohtaista dataa voi scrapata, mutta dataoikeuksia ja sopimuksia on kunnioitettava. | Tiukka henkilötietojen suhteen — UK GDPR soveltuu. Computer Misuse Act kriminalisoi luvattoman pääsyn. | ICO voi sanktioida tietosuojarikkomuksista. Tuomioistuimet voivat panna käyttöehdot täytäntöön. |
| Kiina | Tiukasti kontrolloitua. Julkista, ei-henkilökohtaista dataa voidaan scrapata sisäiseen käyttöön, mutta ilmapiiri on varovainen. | Erittäin rajoitettua — PIPL edellyttää henkilötietojen käsittelyyn suostumusta. Epäreilun kilpailun lait soveltuvat. | Rikosoikeudellisia tapauksia laajamittaisesta scrapaamisesta. Tuomioistuimet käyttävät epäreilun kilpailun lakia luvattoman scrapaamisen estämiseen. |
Onko web scraping laitonta? Keskeiset oikeudelliset tekijät, jotka kannattaa huomioida
Mikä siis oikeasti ratkaisee sen, onko scrapausprojekti laillinen vai riskialtis? Tässä tärkeimmät tekijät:
- Julkinen vs. yksityinen data: Datan scrapaaminen avoimesta webistä, jonka kuka tahansa voi nähdä, on yleensä turvallisempaa. Mutta jos data on kirjautumisen, maksumuurin tai teknisen esteen takana? Se on todennäköisesti laitonta (thunderbit.com).
- Datan luonne: Henkilötiedot (nimet, sähköpostit, profiilit) käynnistävät tietosuojalainsäädännön. Tekijänoikeuden suojaamaa sisältöä (artikkelit, kuvat) ei voi kopioida sellaisenaan. Puhtaat faktat (hinnat, sää) ovat yleensä vapaata riistaa (oxylabs.io).
- Käyttötarkoitus: Sisäinen analyysi tai tutkimus katsotaan yleensä sallivammaksi kuin scrapatun datan uudelleenjulkaisu tai myynti. Jos käytät scrapattua dataa suoraan kilpaillaksesi lähdesivuston kanssa, oikeusjuttu voi odottaa kulman takana (thunderbit.com).
- Sivuston sääntöjen noudattaminen: Tarkista aina robots.txt ja käyttöehdot. Robots.txt ei ole juridisesti sitova, mutta sen kunnioittaminen on hyvää käytäntöä. ToS-rikkomukset voivat johtaa siviilikanteisiin tai pahempaan (promptcloud.com).
- Tekniset toimet: On tärkeää scrapea ihmismäisellä nopeudella eikä kiertää turvatoimia. Palvelimen kuormittaminen tai CAPTCHA-haasteiden väistäminen voi siirtää toiminnan hakkeroinnin puolelle (cliffordchance.com).
Mitä muuttui vuosina 2024–2026: keskeiset oikeustapaukset ja sääntely
Web scrapingia koskeva oikeudellinen maisema on muuttunut rajusti vuoden 2023 jälkeen. Tässä kehityskulut, jotka jokaisen scrapan tekijän kannattaa tietää:
Suuret oikeuden ratkaisut
-
Meta v. Bright Data (2024): Yhdysvaltalainen liittovaltion tuomioistuin katsoi, ettei Metan käyttöehdot kiellä julkisen datan scrapaamista käyttäjiltä, jotka eivät ole kirjautuneet sisään. Tuomari totesi, että "vierailijaa ei pidetä 'käyttäjänä', ellei hänellä ole tiliä." Meta luopui jäljellä olleista vaatimuksista pian tämän jälkeen. Tämä on merkittävä voitto julkisen datan scrapaukselle.
-
X Corp v. Bright Data (2024): Twitter (nykyinen X) hävisi vastaavan oikeusjutun, mikä vahvisti saman periaatteen: julkisesti saatavilla olevan datan scrapaaminen ilman kirjautumista ei riko käyttöehtoja, koska scrapaaja ei koskaan hyväksynyt kyseisiä ehtoja.
-
Reddit v. Perplexity AI (lokakuu 2025): Reddit nosti kanteen Perplexity AI:ta ja useita scraping-palveluntarjoajia vastaan, vedoten DMCA:han ja väittäen anti-bot-järjestelmien kiertämistä. Tämä kertoo uudesta oikeudellisesta strategiasta: alustat siirtyvät tekijänoikeus- ja kiertämisen estämistä koskeviin vaatimuksiin CFAA:n sijaan.
-
NYT v. OpenAI (maaliskuu 2025): Liittovaltion tuomari salli New York Timesin tekijänoikeusjutun OpenAI:ta vastaan edetä, hyläten OpenAI:n hylkäysvaatimuksen. Tämä voi luoda merkittävän ennakkotapauksen sille, lasketaanko AI-mallien kouluttaminen scrapatulla sisällöllä "fair use" -käytöksi.
-
Anthropicin sovinto (syyskuu 2025): Anthropic suostui maksamaan 1,5 miljardia dollaria sovittaakseen Yhdysvalloissa nostetun ryhmäkanteen, joka koski tekijänoikeudella suojattujen tekstien käyttämistä sen AI-mallin kouluttamiseen — tämä viestii, että scrapaamisen kustannukset AI-käyttöä varten ovat hyvin todellisia.
Suuri trendi: CFAA:sta sopimus- ja tekijänoikeuslakiin
Kaava on selvä: CFAA (Computer Fraud and Abuse Act) menettää tehoaan aseena julkisen datan scrapaajia vastaan. Yritykset, jotka yrittivät käyttää CFAA:ta julkisen datan scrapingia vastaan — Meta, X, LinkedIn — ovat enimmäkseen epäonnistuneet. Sen sijaan oikeustaistelu siirtyy kohti:
- Sopimusoikeutta (ToS-rikkomukset — mutta tuomioistuimet sanovat, etteivät ei-käyttäjät ole sidottuja käyttöehtoihin)
- Tekijänoikeusvaatimuksia (erityisesti AI-koulutusdataa koskien)
- Kiertämisen estäviä säännöksiä (DMCA:n 1201 §)
Scrapaajalle tämä tarkoittaa, että oikeudellinen riski ei ole kadonnut — se on vain siirtynyt toiseen paikkaan.
Sääntelymuutokset
- CCPA:n vuoden 2026 päivitykset: Kalifornian uudistetut CCPA-säännökset tulivat voimaan 1. tammikuuta 2026, ja ne toivat uusia sääntöjä automatisoidulle päätöksenteolle (ADMT), riskienarvioinneille ja data broker -velvoitteille.
- Uudet Yhdysvaltain osavaltioiden tietosuojalait: Indiana, Kentucky ja Rhode Island säätivät laajat tietosuojalait, jotka tulivat voimaan vuonna 2026.
- EU AI Act: Täysi täytäntöönpano alkaa 2. elokuuta 2026 — AI-kehittäjiltä edellytetään koulutusdatalähteiden ilmoittamista, tekijänoikeuksien opt-outin kunnioittamista ja kasvojen kuvien scrapaamisen kieltämistä AI-järjestelmille.
- AI Accountability for Publishers Act (helmikuu 2026): Ehdotettu Yhdysvaltain laki, joka velvoittaisi AI-yhtiöt hankkimaan luvan ja maksamaan julkaisijoille ennen heidän sisältönsä scrapaamista.
Suurten alustojen scrapaamiskäytännöt: mitä sinun on tiedettävä
Kaikki sivustot eivät suhtaudu scrapaamiseen samalla tavalla. Tässä alustakohtainen erittely siitä, mitä suurimmat sivustot sallivat, mitä ne estävät ja mitä tuomioistuimet ovat sanoneet:
| Alusta | ToS scrapaamisesta | Tekniset puolustukset | Oikeudellinen täytäntöönpano | Mikä on käytännössä turvallista |
|---|---|---|---|---|
| Google (Haku & Kartat) | Kieltää automaattisen käytön käyttöehdoissa. Maps Platformissa on nimenomainen "No Scraping" -ehto. | SearchGuard JS -haasteet, CAPTCHA:t, rate limiting. Päivitti robots.txt:n vuonna 2025 estääkseen AI-crawlerit. | Kanteen scraperit vastaan joulukuussa 2025 DMCA:n perusteella. Estää aktiivisesti AI-crawlereita (Anthropic, Meta, OpenAI). | Julkisen Google Maps -yritysdatan scrapaaminen on juridisesti puolustettavissa (hiQ-ennakkotapaus), mutta odota teknisiä estoja. Käytä virallisia API-rajapintoja aina kun mahdollista. |
| Amazon | Kieltää kaiken scrapaamisen käyttöehdoissa ("ei bottia, spideriä, scrapperia tai muita automatisoituja keinoja"). | Aggressiivinen bottien tunnistus, CAPTCHA, IP-estot. robots.txt estää kaikki botit paitsi Googlebot/Bingbot. Estää eksplisiittisesti AI-crawlerit vuodesta 2025 alkaen. | Nosti kanteen Perplexity AI:ta vastaan marraskuussa 2025. Lähettää säännöllisesti kieltokirjeitä. Päivitti BSA:n maaliskuussa 2026 AI-agenttisäännöillä. | Julkinen tuotetieto (hinnat, listaukset) on faktapohjaista ja Yhdysvaltain lain mukaan scrapattavaa, mutta Amazon taistelee vastaan kovaa. Rajoita pyyntötahtia ja vältä henkilötietoja. |
| Kieltää scrapaamisen käyttöehdoissa; palveluiden käyttö edellyttää käyttäjän hyväksyntää. | Kirjautumismuurit useimmille profiilitiedoille, anti-bot-tunnistus, rate limiting. | hiQ-tapaus vahvisti, ettei julkisten profiilien scrapaaminen ole CFAA-rikkomus, mutta LinkedIn voitti sopimus- ja epäreilun kilpailun vaatimuksissa, kun käytettiin valetilejä. | Julkiset profiilit (näkyvissä ilman kirjautumista) ovat juridisesti puolustettavissa scrapata. Älä koskaan luo valetilejä tai scrapea sisäänkirjautunutta dataa. | |
| Meta (Facebook & Instagram) | ToS kieltävät scrapaamisen; erilliset säännöt kirjautuneelle ja kirjautumattomalle datalle. | Kirjautumismuurit useimmalle sisällölle, kehittynyt bottien tunnistus. | Hävisi Bright Datalle vuonna 2024 — tuomioistuin katsoi, etteivät ToS:t koske käyttäjiä, jotka eivät ole kirjautuneet sisään. Luopui jäljellä olleista vaatimuksista. | Julkinen data (yrityssivut, julkiset julkaisut), joka on nähtävissä ilman kirjautumista, on turvallisemmalla pohjalla. Älä koskaan scrapea yksityisiä profiileja tai kirjautumisen takana olevaa dataa. |
| X (Twitter) | Päivitti ToS:n vuonna 2023 kieltämään kaiken scrapaamisen ja crawlauksen ilman kirjallista suostumusta. Poisti vanhan robots.txt-poikkeuksen. | robots.txt estää kaikki crawlerit (Disallow: /). Cloudflare Turnstile -haasteet. Tiukat rate limitit (300 pyyntöä/h). IP-maineen pisteytys. | Hävisi Bright Datalle julkisen datan osalta, mutta rajoittaa teknistä pääsyä erittäin aggressiivisesti. | Julkiset twiitit ja profiilit ovat juridisesti puolustettavissa, mutta X:n tekniset esteet ovat vuonna 2026 kaikkein kovimpia. Odota estoja ilman premium-tason proxy-infrastruktuuria. |
Ydinviesti: Tuomioistuimet ovat johdonmukaisesti linjanneet, että julkisesti näkyvän datan scrapaaminen ilman kirjautumista ei riko CFAA:ta. Alustat voivat silti haastaa sinut sopimusoikeuden, tekijänoikeuden tai kiertämisen estävien sääntöjen perusteella — ja ne tekevät elämästäsi teknisesti hankalaa. Scrapaa aina vastuullisesti.
AI-koulutusdata ja web scraping: uusi oikeudellinen rintama
Jos seuraat uutisia vuonna 2026, tiedät, että datan scrapaamisesta AI-mallien kouluttamiseen on tullut kuumin oikeudellinen taistelukenttä. Tässä mitä tapahtuu:
- Tekijänoikeusjutut kasaantuvat. New York Times, kirjailijat ja julkaisijat ovat haastaneet OpenAI:n, Anthropicin ja muita oikeuteen väittäen, että tekijänoikeuden suojaaman sisällön massiivinen scrapaaminen LLM-mallien kouluttamiseen ei ole "fair use". Anthropic sopi merkittävän ryhmäkanteen 1,5 miljardilla dollarilla vuonna 2025 — tämä kertoo, että scrapaamisen kustannukset AI:tä varten ovat hyvin todellisia.
- "Fair use" -puolustus on hatara. Yhdysvaltain tuomioistuimet eivät ole vielä antaneet lopullista ratkaisua siitä, onko scrapatun datan käyttäminen AI:n kouluttamiseen fair usea. Varhaiset ratkaisut viittaavat siihen, että paljon riippuu siitä, miten data hankittiin ja mitä AI:n tuotoksella tehdään.
- Uutta lainsäädäntöä on tulossa. AI Accountability for Publishers Act (esitelty helmikuussa 2026) pyrkii velvoittamaan AI-yhtiöt hankkimaan luvan ja maksamaan julkaisijoille ennen heidän sisältönsä scrapaamista.
- EU AI Act (täysi täytäntöönpano elokuussa 2026) edellyttää AI-kehittäjiltä koulutusdatalähteiden ilmoittamista, koneellisesti luettavien tekijänoikeuden opt-outien kunnioittamista (Tekijänoikeusdirektiivin TDM-poikkeuksen puitteissa) sekä AI:n tuottaman sisällön merkitsemistä. Se kieltää myös AI-järjestelmiä, jotka scrapaavat kasvojen kuvia internetistä.
- AI/LLM-crawlerit räjähtävät. AI-crawlerien osuus verkkoliikenteestä nelinkertaistui 2,6 prosentista 10,1 prosenttiin vain kahdeksassa kuukaudessa. Pelkästään OpenAI:n GPTBot kasvoi 305 prosenttia. Vastauksena suuret sivustot (Amazon, Reddit, NYT) päivittävät robots.txt-tiedostojaan estämään AI-crawlereita nimenomaisesti.
Mitä tämä tarkoittaa sinulle: Jos scrapaat dataa perinteisiin liiketoimintatarkoituksiin (liidien hankinta, hintaseuranta, markkinatutkimus), nämä AI-erityiset säännöt eivät välttämättä koske sinua suoraan. Mutta jos syötät scrapatun datan AI-malleihin, etene erittäin varovasti — ja hanki oikeudellista neuvontaa.
Web scraping -lait ympäri maailmaa: nopea vertailu
Katsotaan asiaa laajemmasta kulmasta ja hahmotetaan, miten säännöt asettuvat globaalisti:
- Yhdysvallat: Ei yleiskieltoa. Julkisesti näkyvien sivustojen scrapaaminen on yleensä laillista (hiQ v. LinkedIn), ja vuoden 2024 Meta- ja X Corp -ratkaisut ovat vahvistaneet julkisen datan scrapauksen asemaa entisestään. Mutta kirjautumisen takana olevan tai teknisten estojen ohittaminen voi silti laukaista CFAA:n. Suunta on nyt se, että yritykset käyttävät mieluummin sopimusoikeutta ja tekijänoikeusvaatimuksia. Tietosuojalait laajenevat nopeasti: CCPA sai merkittäviä päivityksiä 1. tammikuuta 2026, mukaan lukien uudet säännöt automaattiselle päätöksenteolle ja data broker -velvoitteille. Myös Indiana, Kentucky ja Rhode Island säätivät vuonna 2026 kattavat tietosuojalait.
- Euroopan unioni: Tiukat tietosuojalait. GDPR koskee jopa julkista henkilötietoa. Tietokantaoikeudet voivat estää jäsennellyn datan laajamittaisen scrapaamisen (cliffordchance.com). UUTTA: EU AI Act tulee täyteen täytäntöönpanoon 2. elokuuta 2026, ja se vaatii AI-kehittäjiä ilmoittamaan koulutusdatalähteet ja kunnioittamaan tekijänoikeuksien opt-outia. Laki kieltää kasvojen kuvien scrapaamisen internetistä AI-järjestelmiä varten.
- Iso-Britannia: Noudattaa Brexitin jälkeen pitkälti EU:n sääntöjä. Julkista dataa voi scrapata, mutta henkilötietojen scrapaamista säännellään tiukasti. Computer Misuse Act voi tehdä luvattomasta pääsystä rikoksen.
- Kiina: Hyvin rajoittava. PIPL ja Data Security Law edellyttävät henkilötietoihin suostumusta. Tuomioistuimet käyttävät epäreilun kilpailun lakia estämään scrapaamisen, joka vahingoittaa yrityksiä (malwarebytes.com).
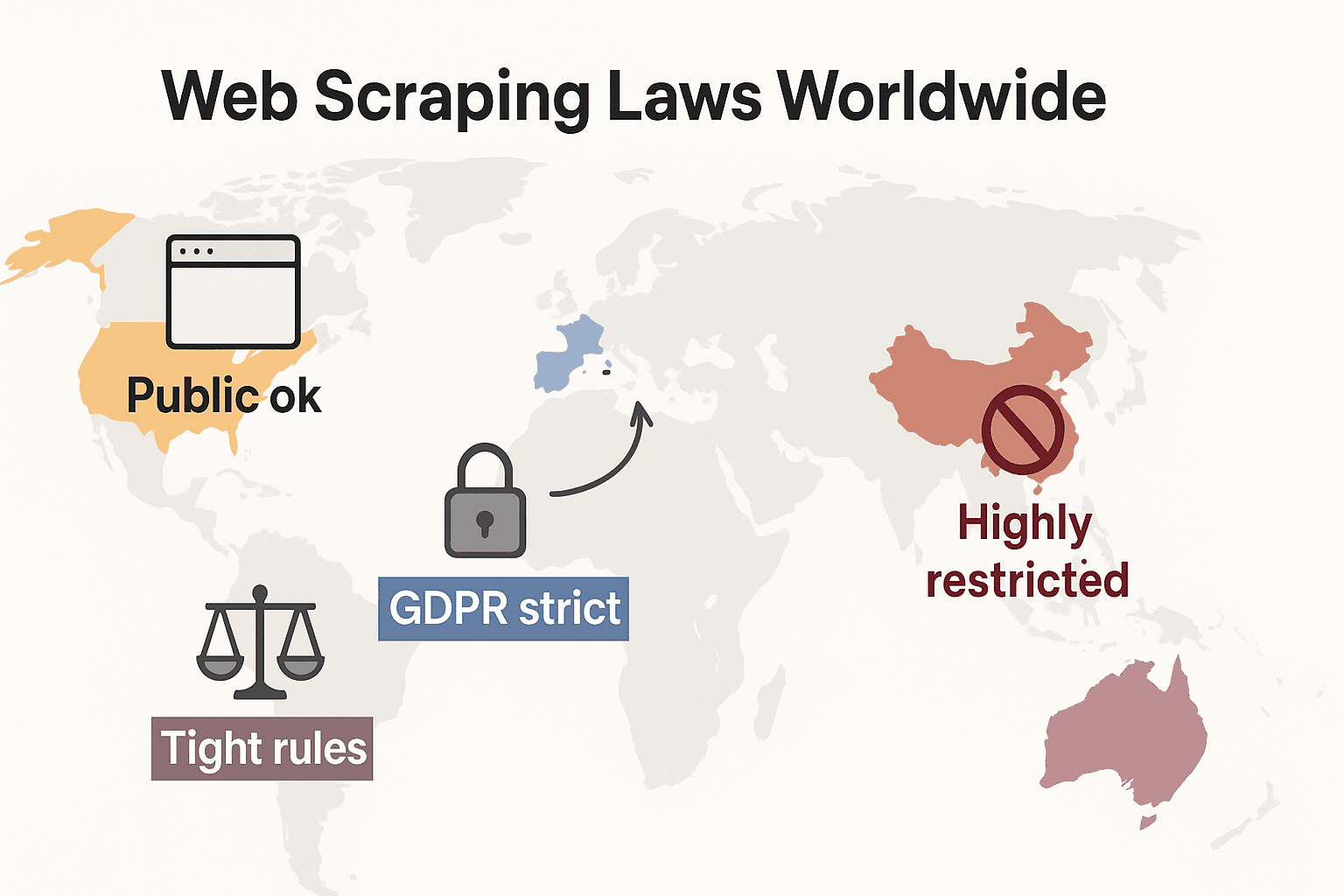
Yhteenveto: julkisen, ei-henkilökohtaisen datan scrapaaminen sisäiseen käyttöön on yleensä turvallisinta. Muuhun kannattaa tarkistaa paikalliset lait ja edetä varovaisesti.
Yleisiä myyttejä web scrapaamisen laillisuudesta
Muutama myytti, joita kuulen jatkuvasti, on syytä oikoa:
- Myytti 1: "Web scraping on laitonta, piste."
Väärin. Ei ole olemassa lakia, joka kieltäisi kaiken web scrapaamisen. Ratkaisevaa on se, miten ja mitä scrapaat (oxylabs.io). - Myytti 2: "Jos data on julkista, saan tehdä sillä mitä haluan."
Ei aivan. Julkista dataa voivat silti suojata yksityisyys- tai tekijänoikeuslait, ja käyttöehdot voivat rajoittaa tiettyjä käyttötapoja (ico.org.uk). - Myytti 3: "Web scraping on sama asia kuin hakkerointi."
Ei. Julkisten verkkosivujen scrapaaminen ei ole hakkerointia. Kirjautumisen tai teknisten esteiden ohittaminen on eri asia (calawyers.org). - Myytti 4: "Jos minua ei jää kiinni, kaikki on ok."
Riskialtista ajattelua. Monet sivustot käyttävät anti-bot-teknologiaa ja huomaavat toiminnan. Hiljaisuus ei ole suostumus. - Myytti 5: "Jos annan lähdemerkinnän tai käytän dataa sisäisesti, se on sallittua."
Lähdemerkintä ei ohita tekijänoikeus- tai tietosuojalainsäädäntöä. Sisäinen käyttö on turvallisempaa, mutta ei mikään automaattinen vapautus. - Myytti 6: "Kaikki web scraping rikkoo yksityisyyttä."
Kaikki scraping ei koske henkilötietoja. Mutta suurten henkilötietomäärien scrapaaminen ilman suojauksia on lähes aina laitonta (oxylabs.io). - Myytti 7: "Jos sivuston ToS kieltää scrapaamisen, sen scrapaaminen on aina laitonta."
Ei välttämättä. Vuonna 2024 tuomioistuimet ratkaisivat Meta v. Bright Data- ja X Corp v. Bright Data -tapauksissa, ettei ToS sido käyttäjiä, jotka eivät ole koskaan hyväksyneet niitä — eli jos scrapaat ilman kirjautumista tai ilman tilin luomista, sivuston ToS ei välttämättä koske sinua. Tämä on edelleen kehittyvä oikeusalue, mutta muutos on merkittävä.
Miten scrapata dataa laillisesti: parhaat käytännöt vaatimustenmukaisuuteen
Tässä oma tarkistuslistani lainmukaiseen ja eettiseen web scrapingiin:
- Lue ja noudata sivuston käyttöehdot. Jos niissä sanotaan "ei scrapaamista", harkitse lopettamista tai pyydä lupa (ql2.com).
- Pysy julkisessa datassa. Jos tarvitset salasanan, data on rajattua — älä scrapea sitä (thunderbit.com).
- Tarkista robots.txt ja crawlkaa kohteliaasti. Ei juridisesti sitova, mutta hyvää käytöstä. Älä kuormita palvelimia — hajauta pyyntösi ajallisesti (promptcloud.com).
- Vältä henkilötietoja, ellet voi perustella käsittelyä laillisesti. Jos sinun on pakko kerätä niitä, noudata GDPR/CCPA-säännöksiä ja minimoi kerättävä määrä.
- Älä julkaise scrapattua sisältöä sellaisenaan. Lisää siihen arvoa tai analyysiä, tai hanki lupa (thunderbit.com).
- Älä syötä scrapattua sisältöä AI-malleihin tarkistamatta tekijänoikeuksia. Oikeudellinen maisema muuttuu nopeasti — hanki neuvontaa, jos tämä on käyttötapauksesi.
- Käytä virallisia API-rajapintoja tai dataexportteja, kun niitä on saatavilla. Ne on tehty tätä varten ja ovat yleensä turvallisempia (thunderbit.com).
- Ole läpinäkyvä ja vastuullinen. Jos keräät henkilötietoja, kerro siitä ihmisille ja pidä kirjaa toiminnastasi.
- Minimoi ja suojaa datasi. Kerää vain se, mitä tarvitset, pidä data ajan tasalla ja säilytä se turvallisesti.
- Pysy ajan tasalla ja hae oikeudellista neuvontaa rajatapauksissa. Lait ja oikeuden ratkaisut muuttuvat nopeasti — erityisesti EU AI Act ja Yhdysvaltojen osavaltioiden tietosuojalait. Kun epäilet, kysy ammattilaiselta.
Kokeile Thunderbit Chrome -laajennusta vaatimustenmukaiseen scrapaamiseen
Web scraping -työkalujen käyttö laillisesti: mitä yritysten on tiedettävä
Web scraping -työkalut, kuten Thunderbit, tekevät datankeruusta myös ei-koodaajille mahdollista, mutta niitäkin pitää käyttää vastuullisesti:
- Valitse vaatimustenmukaisuuteen keskittyvät työkalut. Thunderbit esimerkiksi scrapa ainoastaan sen, mitä näet selaimessasi — ei salaisia API-kikkoja tai luvatonta pääsyä (thunderbit.com).
- Pysy laillisissa käyttötapauksissa. Sisäinen analytiikka, markkinatutkimus ja kilpailijoiden hintaseuranta ovat yleensä turvallisia. Scrapatun datan uudelleenjulkaisu tai myynti? Paljon riskialttiimpaa.
- Määritä työkalut sääntöjen mukaisesti. Aseta crawl-viiveet, noudata robots.txt:tä ja käytä malleja, jotka keräävät vain tarvitsemasi.
- Pidä data talon sisällä. Scrapatun datan käyttäminen sisäisesti on turvallisempaa kuin sen julkaiseminen uudelleen.
- Kouluta tiimisi. Varmista, että kaikki ymmärtävät säännöt ja parhaat käytännöt.
- Hyödynnä sisäänrakennettuja vaatimustenmukaisuustoimintoja. Thunderbit varoittaa käyttäjiä riskialttiista sivustoista, scrapeaa ihmismäisellä nopeudella eikä tallenna dataasi palvelimilleen.
- Älä pakota väkisin. Jos työkalu ei pysty scrapingiin sivustolla, älä yritä kiertää sitä hakkaamalla järjestelmää. Kaikki data ei ole saatavissa ilman riskiä.
Thunderbitin lähestymistapa: vaatimustenmukaisen AI web scrapingin mahdollistaminen
Thunderbitissä olemme käyttäneet paljon aikaa vaatimustenmukaisuuden pohtimiseen. Näin AI Web Scraper auttaa käyttäjiä pysymään lain oikealla puolella:
- Scrapaa vain sen, mitä näet. Thunderbit toimii selainistunnossasi, joten se ei voi käyttää dataa, jota et voisi itse kopioida käsin.
- Ohjaa käyttäjiä varoituksilla. Jos yrität scrapata sivustoa, jolla on tiukat anti-scraping-käytännöt, Thunderbit hälyttää sinua.
- Ihmismäiset scrapausnopeudet. Olitpa scrapaamassa paikallisesti tai pilvessä, Thunderbit välttää palvelinten kuormittamista.
- Mukautettava datavalinta. AI ehdottaa relevanteja sarakkeita, jotta keräät vain tarvitsemasi.
- Ala- ja sivunumeroiden käsittely. Thunderbit navigoi sivustoilla kuin oikea käyttäjä ja kunnioittaa niiden rakennetta.
- Yksityisyys ja turvallisuus. Datasi pysyy sinun hallinnassasi — Thunderbit ei tallenna sitä eikä käytä uudelleen.
- Vaatimustenmukaiset vientimuodot. Vie data suoraan Google Sheetsiin, Airtableen, Notioniin tai CSV-muotoon turvallista sisäistä käyttöä varten.
- Ajoitus ja automaatio. Määritä toistuvat scrapaukset vastuullisin aikavälein.
- Monikielinen tuki. Thunderbitin käyttöliittymä tukee 34 kieltä, mikä tekee vaatimustenmukaisuudesta saavutettavaa globaalisti.
- Säännölliset mallipäivitykset. Suosittujen sivustojen valmiit mallimme pidetään ajan tasalla oikeudellisista ja teknisistä muutoksista.
Kun vaatimustenmukaisuus on rakennettu tuotteeseen sisään, Thunderbit auttaa tiimejä keräämään tarvitsemansa datan ilman oikeudellista päänsärkyä.
Askeleen edellä pysyminen: sopeutuminen web scrapaamisen oikeudellisiin ja teknisiin muutoksiin
Tutustu lisää web scraping -oppaisiin Get Started Free
Web scraping ei ole “aseta ja unohda” -peliä. Lait ja sivustojen rakenteet muuttuvat jatkuvasti. Näin pysyt edellä:
- Seuraa oikeudellista kehitystä. Muutostahti kiihtyi vuosina 2024–2026 — seuraa teknologiaoikeuden uutisia, viranomaisten päivityksiä ja alan blogeja (kuten Thunderbitin). Pidä silmällä EU AI Actin täytäntöönpanoa (elokuu 2026), uusia Yhdysvaltain osavaltioiden tietosuojalakeja ja käynnissä olevia AI-tekijänoikeusjuttuja.
- Sopeudu teknisiin muutoksiin. Sivustot päivittävät jatkuvasti ulkoasujaan ja anti-bot-puolustuksiaan. Suuret alustat (Amazon, X, Google) tiukensivat puolustuksiaan merkittävästi vuosina 2025–2026. Thunderbitin AI ja valmiit mallit on suunniteltu mukautumaan automaattisesti.
- Hyödynnä virallisia API-rajapintoja, kun niitä on saatavilla. Jos sivusto siirtyy maksulliseen API-malliin, harkitse vaihtamista luotettavuuden ja vaatimustenmukaisuuden vuoksi.
- Tee scrapaamisen auditointi säännöllisesti. Dokumentoi lähteesi, tarkista ToS- tai politiikkamuutokset ja säädä strategiaasi tarpeen mukaan.
- Hyödynnä Thunderbitin mallipäivityksiä. Tiimimme pitää mallit ajantasaisina, joten sinun ei tarvitse huolehtia rikkoutuvista muutoksista tai uusista vaatimustenmukaisuusvaatimuksista.
- Pysy joustavana. Jos datalähteestä tulee liian riskialtis, vaihda toiseen tai etsi kumppanuutta.
Oikeilla työkaluilla ja asenteella voit pitää data-putkesi virtaamassa — ilman että astut oikeudellisiin miinoihin.
Yhteenveto: web scrapaamisen oikeudellisessa maisemassa navigointi
Web scraping ei ole lähtökohtaisesti laitonta — se on tehokas työkalu liiketoimintaan, tutkimukseen ja innovaatioon. Mutta kuten kaikilla työkaluilla, myös tällä on sääntönsä. Oleellista on ymmärtää, mitä scrapaat, miten scrapaat ja mitä teet datalla. Kunnioita paikallisia lakeja, noudata sivustojen käytäntöjä ja käytä vaatimustenmukaisuuteen keskittyviä työkaluja, kuten Thunderbit, jotta toimintasi pysyy asianmukaisena.
Vuoden 2024–2026 oikeuden ratkaisut (Meta v. Bright Data, X Corp v. Bright Data) ovat vahvistaneet julkisen datan scrapauksen asemaa, mutta uusia riskejä nousee AI-koulutusdatan, tekijänoikeusvaatimusten ja EU AI Actin ympärille. Alustakohtaiset käytännöt vaihtelevat paljon — Google, Amazon, LinkedIn, Meta ja X valvovat sääntöjään eri tavoin — joten tunne maisema ennen kuin alat scrapea.
Jos olet koskaan epävarma, hae oikeudellista neuvontaa — erityisesti suurissa tai arkaluonteisissa projekteissa. Ja muista: oikeudellinen maisema muuttuu jatkuvasti, joten pysy ajan tasalla ja ketteränä.
Haluatko oppia lisää web scrapinguista, vaatimustenmukaisuudesta ja automaatiosta? Katso Thunderbit Blogi saadaksesi lisää oppaita tai kokeile itse Thunderbitin Chrome-laajennusta.
Aloita vaatimustenmukainen web scraping Thunderbitillä
Usein kysytyt kysymykset
1. Onko web scraping laitonta kaikkialla?
Ei. Web scraping ei ole lähtökohtaisesti laitonta, mutta sen laillisuus riippuu siitä, mitä scrapaat, miten scrapaat sen ja missä olet. Julkisen, ei-henkilökohtaisen datan scrapaaminen sisäiseen käyttöön on yleensä sallittua useimmilla alueilla, mutta henkilötietojen tai tekijänoikeuden alaisten tietojen scrapaaminen tai sivuston ehtojen rikkominen voi olla laitonta (oxylabs.io).
2. Teenkö scrapaamisesta laitonta, jos jätän robots.txt:n huomiotta?
Robots.txt ei ole juridisesti sitova, mutta sen noudattaminen on paras käytäntö. Sen sivuuttaminen ei yksinään tee sinusta oikeudellisesti syyllistä, mutta jos asiasta tulee riita, se voi antaa sinusta "huonon toimijan" kuvan (promptcloud.com).
3. Voinko scrapea Googlea, Amazonia tai LinkedIniä?
Se on monimutkaista. Kaikki kolme kieltävät scrapaamisen käyttöehdoissaan, mutta tuomioistuimet ovat todenneet, että ToS ei välttämättä sido käyttäjiä, jotka eivät ole kirjautuneet sisään (katso Meta v. Bright Data ja X Corp v. Bright Data, molemmat vuodelta 2024). Julkisesti näkyvän datan (tuotteiden hinnat, yritystiedot, julkiset profiilit) scrapaaminen on Yhdysvalloissa yleensä juridisesti puolustettavissa. Jokainen alusta valvoo sääntöjään kuitenkin eri tavoin: Amazon on aggressiivisin oikeustoimissa (se haastoi Perplexity AI:n oikeuteen marraskuussa 2025); LinkedIn nojaa teknisiin esteisiin ja sopimusvaatimuksiin; Google käyttää yhä enemmän DMCA-pohjaista täytäntöönpanoa. Scrapaa aina vastuullisesti ja varaudu teknisiin vastatoimiin.
4. Voinko scrapea Facebookia tai Instagramia?
Meta v. Bright Data -tapauksen (2024) jälkeen julkisen datan scrapaaminen Facebookista ja Instagramista ilman kirjautumista on oikeudellisesti vahvemmalla pohjalla. Tuomioistuin katsoi, etteivät Metan käyttöehdot koske ei-käyttäjiä. Älä kuitenkaan koskaan luo valetilejä tai scrapea dataa kirjautumismuurien takaa — se menee jo liian pitkälle.
5. Voinko scrapea X:ää (Twitteriä)?
X päivitti käyttöehtonsa vuonna 2023 kieltämään kaiken scrapaamisen ilman kirjallista suostumusta ja on ottanut käyttöön aggressiivisia teknisiä puolustuksia (Cloudflare Turnstile, 300 pyynnön tuntirajat, IP-maineen pisteytys). Bright Data kuitenkin voitti oikeudessa vastaavilla perusteilla — julkinen data, joka scrapaattiin ilman tiliä, ei ole X:n ToS:n sitomaa. Teknisesti X on yksi hankalimmista alustoista scrapata vuonna 2026.
6. Onko AI-mallien kouluttamiseen käytetyn datan scrapaaminen laillista?
Tämä on vuoden 2026 suurin avoin kysymys. Suuret oikeusjutut (NYT v. OpenAI, Anthropicin 1,5 miljardin dollarin sovinto) viittaavat merkittävään oikeudelliseen riskiin. EU AI Act edellyttää koulutusdatalähteiden ilmoittamista ja tekijänoikeuksien opt-outien kunnioittamista. Ehdotettu AI Accountability for Publishers Act vaatisi lupaa ja maksua. Jos scrapaat AI-koulutusta varten, hanki oikeudellista neuvontaa ennen kuin jatkat.
7. Mikä on turvallisin tapa käyttää Thunderbitin kaltaisia web scraping -työkaluja?
Pysy julkisen datan scrapauksessa, kunnioita sivuston ehtoja, vältä henkilötietoja ellet voi perustella käsittelyä laillisesti, ja käytä dataa sisäisesti. Thunderbit on suunniteltu auttamaan sinua pysymään lain puolella scrapaamalla vain sen, mikä näkyy selaimessasi, ja varoittamalla riskialttiista sivustoista (thunderbit.com).
8. Voinko scrapea dataa kaupalliseen käyttöön?
Riippuu tapauksesta. Scrapatun datan käyttäminen sisäiseen analytiikkaan tai tutkimukseen on yleensä turvallisempaa. Scrapatun datan uudelleenjulkaisu tai myynti, erityisesti jos se on tekijänoikeuden alaista tai henkilötietoa, on paljon riskialttiimpaa ja voi vaatia lupaa tai lisenssiä.
9. Miten pysyn mukana web scrapaamisen oikeudellisissa ja teknisissä muutoksissa?
Seuraa teknologiaoikeuden uutisia, tarkkaile kohdesivustojesi ToS- tai politiikkamuutoksia ja käytä työkaluja, kuten Thunderbitia, jotka päivittävät mallinsa ja vaatimustenmukaisuustoimintonsa säännöllisesti. Vuonna 2026 tärkeimmät seurattavat asiat ovat: EU AI Actin täytäntöönpano (elokuu), käynnissä olevat AI-tekijänoikeusjutut ja uudet Yhdysvaltain osavaltioiden tietosuojalait. Kun olet epävarma, kysy lakiasiantuntijalta.
Kokeile AI Web Scraperia Get Started Free




