Jos arvioit web scraping -työkaluja vuonna 2026, et yleensä etsi filosofiaoppituntia. Haluat luotettavan lyhytlistan, nopean tavan erottaa liiketoimintakäyttäjille tarkoitetut työkalut kehittäjäpainotteisista kokonaisuuksista ja riittävästi näyttöä, jotta et osta väärää ratkaisua. Tätä sivua varten tämä on juuri se tehtävä.
Olen Shuai Guan, Thunderbitin perustaja ja toimitusjohtaja. Työskentelen päivittäin tekoälypohjaisen scrapingin ja selainautomaation parissa, joten välitän vähemmän geneerisistä ranking-listoista ja enemmän sopivuudesta: mitkä työkalut auttavat myynti- tai operatiivista tiimiä etenemään tällä viikolla, mitkä kuuluvat kehittäjän työnkulkuun ja mitkä taas ovat järkeviä vasta silloin, kun mittakaava ja anti-bot-infrastruktuuri ovat pääongelma.
Nopea vastaus
Jos tarvitset vain päätöksenteko-ohjeen, käytä tätä:
- Valitse tekoälypohjainen web-kaavin, jos haluat nopeimman reitin verkkosivulta taulukkolaskentaan mahdollisimman vähällä käyttöönotolla.
- Valitse no-code-kaavin, jos tarvitset enemmän tehtävähallintaa, ajastusta tai pilviajoja ilman koodia.
- Valitse API-alusta, jos tiimisi tarvitsee renderöintiä, proxyjen kierrätystä, anti-bot-käsittelyä tai integrointia sisäiseen tuotteeseen.
- Valitse avoimen lähdekoodin kirjasto, jos haluat täyden hallinnan ja pystyt itse vastaamaan ylläpidosta, selektoreista, infrastruktuurista ja virheistä.
Tämä artikkeli käy läpi kaikki 20 työkalua, mutta suosituslogiikka on tarkoituksella yksinkertainen: aloita kevyimmästä työkalusta, joka hoitaa työnkulun luotettavasti, ja siirry raskaampiin ratkaisuihin vasta kun ylläpito, estot tai mittakaava pakottavat siihen.
Pikavertailutaulukko: parhaat web scraping -työkalut vuonna 2026
Hinnoittelu ja suunnitelmamallit tarkistettiin virallisilta tuote- tai hinnoittelusivuilta 7. toukokuuta 2026. Kun toimittajat käyttävät käyttöperusteista laskutusta tai räätälöityä yrityshintaa, kuvaan hinnoittelumallin sen sijaan, että esittäisin yhden muka universaalin listahinnan.
| Työkalu | Tyyppi | Sopii parhaiten | Miksi se päätyi vuoden 2026 listalle | Hinnoittelumalli (tarkistettu 5/2026) |
|---|---|---|---|---|
| Thunderbit | Tekoälypohjainen web-kaavin | Myynti, operatiivinen työ, verkkokauppa, kiinteistöt | Nopein reitti ei-koodaajille; AI-kenttäehdotukset, alasivut, vienti, selain- ja pilvityönkulku | Ilmainen taso, maksulliset suunnitelmat, yrityskohtainen hinnoittelu |
| Browse AI | Tekoälypohjainen web-kaavin | Liiketoimintakäyttäjät, jotka seuraavat verkkosivustoja | Vahvat no-code-robotit, seuranta ja taulukkolaskenta/API-tyyppiset tulosteet | Ilmainen suunnitelma, maksulliset suunnitelmat, premium-hallinnoitu taso |
| Bardeen | Tekoälyautomaatio + scraping | Revenue ops ja selaintyönkulut | Parempi silloin, kun scraping on vain yksi vaihe laajemmassa automaatioketjussa | Ilmainen suunnitelma ja maksulliset suunnitelmat |
| Diffbot | Tekoälyn poistoalusta | Yritykset ja data-tiimit | Paras vaihtoehto, kun haluat tekoälypoiston ja suurivolyymiset jäsennellyn datan työnkulut | Yritystason hinnoittelu |
| Instant Data Scraper | Kevyt selainkaavin | Satunnaiset käyttäjät ja nopeat taulukkopoiminnat | Yhä yksi yksinkertaisimmista tavoista viedä näkyvä lista tai taulukko nopeasti CSV:ksi | Ilmainen |
| Octoparse | No-code-kaavin | Analyytikot ja operatiiviset tiimit, joilla on suurempia toistuvia töitä | Kypsä visuaalinen rakentaja, pilviuutto, estojen kierrätys ja mallipohjat | Ilmainen suunnitelma, maksulliset alkaen 69 $/kk, yrityskohtainen |
| ParseHub | Low-code-kaavin | Analyytikot, jotka tarvitsevat logiikkaa ja työpöytähallintaa | Joustava projektilogiikka ja sisäkkäinen navigointi, mutta jyrkempi oppimiskäyrä kuin uudemmissa AI-first-työkaluissa | Ilmainen suunnitelma ja maksulliset suunnitelmat |
| Web Scraper | No-code-kaavin | Aloittelijat ja kevyet pilvityöt | Hyvä lähtökohta, jos pidät sivustokarttaan perustuvasta scrapingistä ja selainlähtöisestä käyttöönotosta | Ilmainen selainlaajennus, maksulliset pilvisuunnitelmat |
| Data Miner | Selainkaavin | Tutkijat ja kasvuhakuiset tekijät | Edelleen hyödyllinen nopeaan reseptipohjaiseen poimintaan suoraan selaimessa | Ilmainen suunnitelma ja maksulliset suunnitelmat |
| Apify | API- ja Actor-alusta | Teknisiä tiimejä ja hybriditoimijoita | Erinomainen Actor-ekosysteemi sekä oma suoritusympäristö, kun selainlaajennukset eivät enää riitä | Ilmainen suunnitelma, alkaen 29 $/kk + käyttö, suuremmat maksulliset tasot |
| ScrapingBee | Scraping API | Kehittäjät, jotka kaapivat JavaScript-painotteisia sivustoja | Hyvä valinta, kun haluat renderöinnin ja proxy-käsittelyn ilman että rakennat selainkerroksen itse | Ilmainen kokeilu ja maksulliset suunnitelmat |
| ScraperAPI | Scraping API | Kehittäjät, jotka skaalaavat pyyntöjä nopeasti | Selkeä API, kokeilukrediitit, jäsennellyt tuotteet ja helpompi infrastruktuurin ulkoistus | 7 päivän kokeilu 5 000 kreditillä, maksulliset alkaen 49 $/kk |
| Bright Data | Yritystason API- ja proxy-alusta | Suurivolyymiset, vaatimuksiltaan tiukat ohjelmat | Laajin datankeruukokonaisuus, kun estojen kiertäminen, proxyt ja hallinnoitu keruu ovat tärkeämpiä kuin yksinkertaisuus | Käyttöperusteinen ja tuotekohtainen hinnoittelu |
| Oxylabs | Yritystason API- ja proxy-alusta | Tiimit, jotka ostavat scrapingin infrastruktuurina | Vahva suurivolyymiseen keruuseen, erityisesti hinta-, SEO- ja markkinatutkimustyössä | Web Scraper API alkaen 49 $/kk; laajempi proxy-hinnoittelu vaihtelee |
| Zyte | API- ja anti-bot-kokonaisuus | Kehittäjä- ja data-tiimit | Hyvä valinta, jos haluat API-first-poiston vahvoilla selain-, kierrätys- ja anti-detection-ominaisuuksilla | Kokeilu 5 $ ilmaisella krediitillä, käyttöperusteiset sitoumukset |
| Selenium | Avoimen lähdekoodin selainautomaatio | QA-tyyppinen automaatio ja vaikeat vuorovaikutuspolut | Yhä hyödyllinen, kun käyttäjävuorovaikutuksen tarkkuus on tärkeämpää kuin kaapimen läpimeno | Ilmainen ja avoimen lähdekoodin |
| BeautifulSoup4 | Avoimen lähdekoodin parseri | Aloittelijat ja kevyt parsing | Paras parserina yksinkertaisessa pinossa, ei täysimittaisena scraping-alustana | Ilmainen ja avoimen lähdekoodin |
| Scrapy | Avoimen lähdekoodin crawlauskehys | Tuotantokäyttöön tarkoitetut omat crawlerit | Paras tasapaino tehon ja kypsyyden välillä, jos haluat omistaa putken itse | Ilmainen ja avoimen lähdekoodin |
| Puppeteer | Avoimen lähdekoodin selainautomaatio | Node-ensinen scraping ja selain-skriptitys | Erinomainen, jos tiimisi viihtyy jo valmiiksi Chrome/Node-ekosysteemissä | Ilmainen ja avoimen lähdekoodin |
| Playwright | Avoimen lähdekoodin selainautomaatio | Moderni moniselaimiautomaatio | Usein siistein valinta nykyaikaiseen selainautomaatioon ja vahvaan kehittäjäkokemukseen | Ilmainen ja avoimen lähdekoodin |
Miten arvioin nämä työkalut
Käytin neljää suodatinta:
- Aika ensimmäiseen onnistuneeseen scrapaukseen
Jos ei-tekninen tekijä ei saa hyödyllistä dataa nopeasti, sillä on väliä. - Ylläpitotaakka
Nopea käyttöönotto ei merkitse mitään, jos työnkulku hajoaa aina, kun sivusto muuttuu. - Skaalan yläraja
Jotkin työkalut sopivat erinomaisesti 50 sivulle viikossa ja huonosti 5 miljoonaan pyyntöön kuukaudessa. - Työnkulun sopivuus
Paras työkalu revenue ops -tiimille on harvoin paras työkalu data platform -tiimille.
Tulos ei ole universaali ranking-lista. Tämä on päätössivu, jonka avulla valitaan ensin oikea työkaluluokka ja vasta sitten oikea tuote sen sisältä.
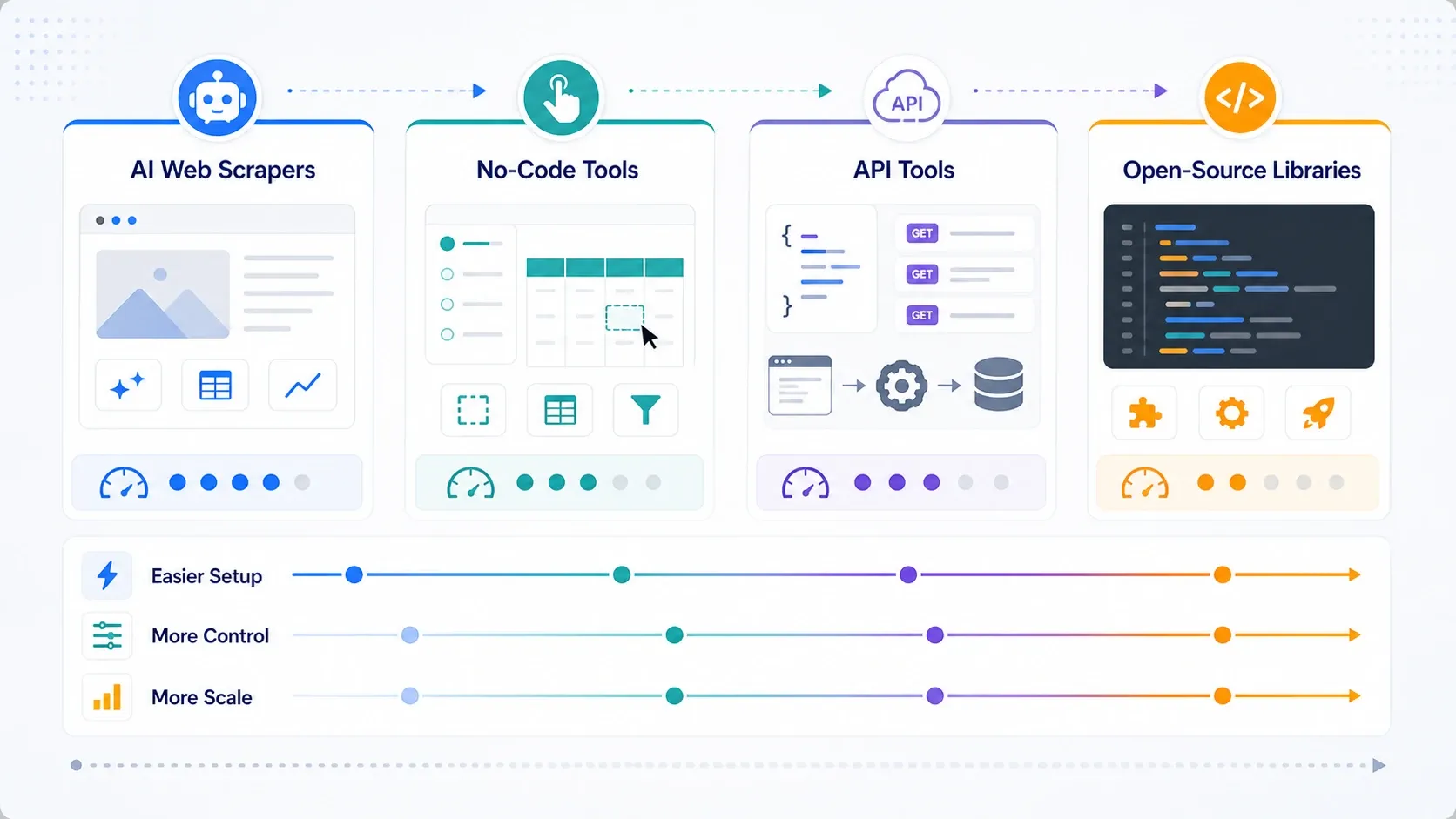
Minkä tyyppistä web scraping -työkalua oikeasti tarvitset?
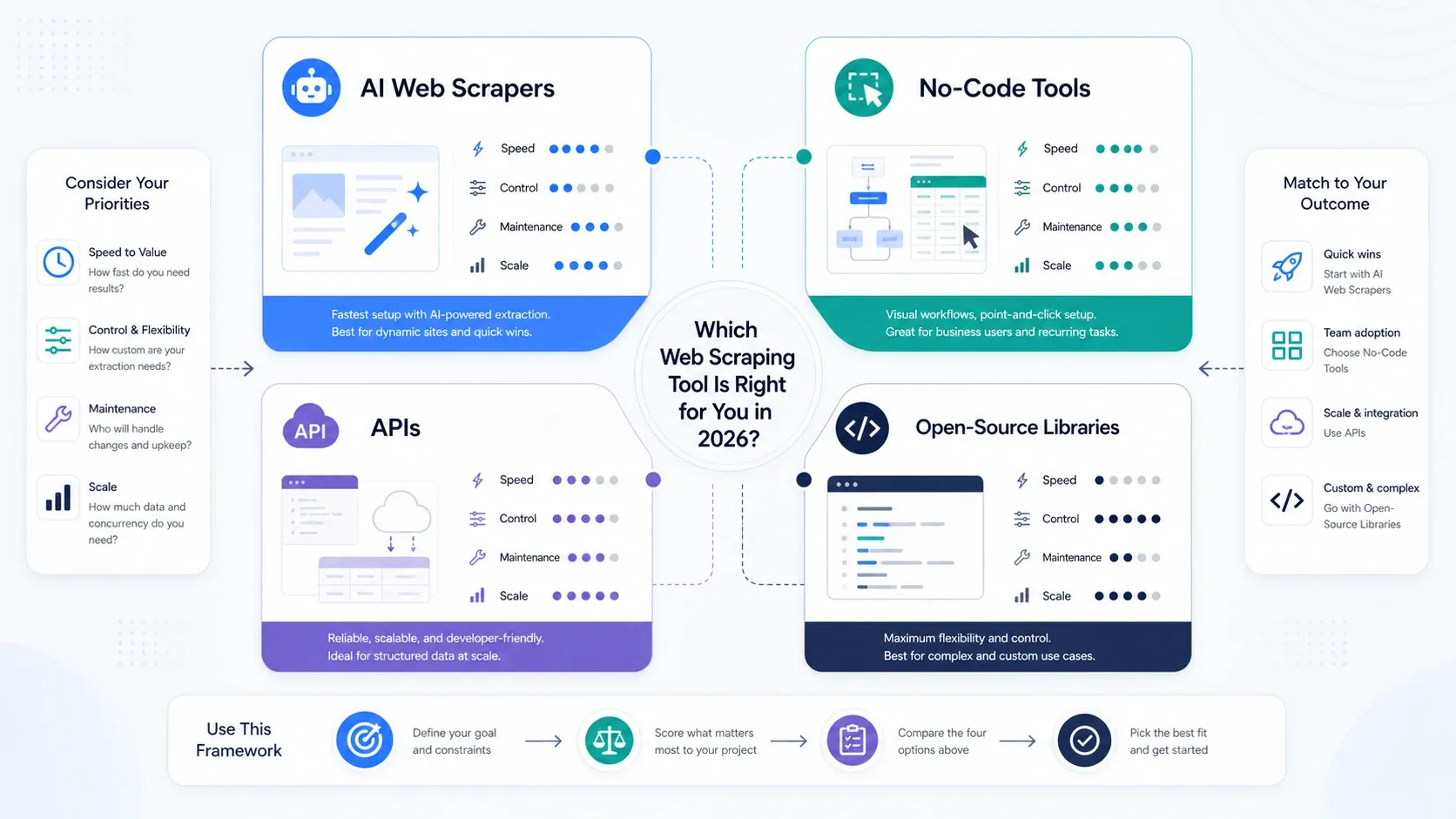
- Valitse tekoälypohjaiset web-kaapimet, jos ensisijainen tavoitteesi on operatiivinen nopeus.
- Valitse no-code-työkalut, jos tarvitset enemmän sivutuslogiikkaa, ajastusta ja toistettavaa tehtävähallintaa.
- Valitse API:t ja scraping-alustat, jos renderöinti, kierrätys ja estojen kiertäminen ovat nyt pullonkaula.
- Valitse avoimen lähdekoodin kirjastot, jos tiimisi arvostaa hallintaa enemmän kuin helppoutta ja pystyy tukemaan pinoa sisäisesti.
Jos tiimisi vielä päättää, pitäisikö scrapingin kuulua operatiiviselle puolelle vai engineeringille, aloita ensin tekoäly- tai no-code-työkalulla. Opit, mikä on tärkeää, nopeammin ajamalla oikeita töitä kuin suunnittelemalla pinoa liian pitkälle etukäteen.
Parhaat tekoälypohjaiset web-kaapimet liiketoimintatiimeille
Nämä ovat ne työkalut, joita itse tarkastelisin ensimmäisenä, jos tavoitteena on taulukkolaskentaan valmista dataa mahdollisimman vähällä käyttöönotolla.
1. Thunderbit
Thunderbit on tässä joukossa helpoin vaihtoehto, jos tiimisi haluaa poimia jäsenneltyä dataa ilman että tarvitsee opetella selektoreita, selain-skriptitystä tai scraping-infrastruktuuria. Työnkulku rakentuu AI-kenttäehdotusten, alasivujen rikastamisen ja suoran viennin ympärille työkaluihin, joissa liiketoimintakäyttäjät jo valmiiksi työskentelevät.
- Sopii parhaiten: myyntiin, operatiiviseen työhön, verkkokauppaan, kiinteistöalaan ja muihin selainpainotteisiin tiimeihin.
- Miksi se erottuu: se tiivistää käyttöönottoa nopeammin kuin mikään muu tämän listan työkalu ei-koodaajille.
- Huomio: jos tarvitset syvää mukautettua crawler-logiikkaa tai erittäin erikoistunutta teknistä hallintaa, siirryt lopulta raskaampiin ratkaisuihin.
- Hinnoittelumalli: ilmainen taso, itsepalvelumaksulliset suunnitelmat ja yrityshinnat.
2. Browse AI
Browse AI on edelleen vahva valinta liiketoimintakäyttäjille, jotka haluavat piste- ja klikkaus -tyyppisen käyttöönoton sekä toistuvan seurannan. Sen robottimalli on erityisen hyödyllinen, kun scraping ja muutosten havaitseminen ovat yhtä tärkeitä.
- Sopii parhaiten: hintasivujen, kilpailijasivujen ja toistettavan listapoiminnan seurantaan.
- Miksi se erottuu: viimeistelty käyttöönotto, valmiit robotit ja selkeä polku verkkosivulta taulukkolaskentaan tai API-tyyppiseen tulosteeseen.
- Huomio: monimutkaiset, suurivolyymiset työt voivat muuttua kalliiksi tai operatiivisesti hankaliksi nopeammin kuin API-first-pinoissa.
- Hinnoittelumalli: ilmainen suunnitelma, maksulliset suunnitelmat, premium-/hallinnoitu taso.
3. Bardeen
Bardeen on kiinnostavin silloin, kun scraping on vain yksi toiminto laajemmassa selainautomaatiovirrassa. Jos viet dataa CRM-järjestelmiin, taulukkolaskentaan tai outbound-työnkulkuihin, sen automaationäkökulma on tärkeämpi kuin raakapoiston syvyys.
- Sopii parhaiten: revenue opsiin, liidien työnkulkuihin ja selainlähtöiseen tehtäväautomaatioon.
- Miksi se erottuu: vahvempi työnkulkuautomaation tarina kuin puhtaissa poimintatyökaluissa.
- Huomio: ei ole siistein valinta, kun itse scraping on monimutkaista ja liiketoimintakriittistä.
- Hinnoittelumalli: ilmainen suunnitelma ja maksulliset suunnitelmat.
4. Diffbot
Diffbot on tässä niille tiimeille, jotka tarvitsevat tekoälypoistoa yritysskaalassa, eivät niille, jotka etsivät halvinta tai yksinkertaisinta reittiä. Se on järkevämpi silloin, kun jäsennellyn datan laatu ja laajamittainen sisäänvirtaus ovat tärkeämpiä kuin käytännönläheinen hallinta.
- Sopii parhaiten: yritysten data-tiimeille, sisältöä hyödyntävälle analytiikalle ja laajoille poisto-ohjelmille.
- Miksi se erottuu: tietokonenäkötyyppinen poiminta ja vahva jäsennellyn tulosteen painotus.
- Huomio: liioiteltu pienille tiimeille ja hankala, jos käyttötapaus on kevyt.
- Hinnoittelumalli: yritystason suunnitelmat ja räätälöity myyntiprosessi.
5. Instant Data Scraper
Instant Data Scraper ansaitsee yhä paikkansa, koska on paljon tilanteita, joissa tarvitset vain näkyvän taulukon, hakemiston tai listan heti nyt. Se ei ole alusta, mutta usein se riittää.
- Sopii parhaiten: kertaluonteiseen poimintaan, nopeisiin liidilistoihin, yksinkertaisiin hakemistoihin ja näkyviin taulukoihin.
- Miksi se erottuu: lähes nollakynnys oikeilla sivuilla.
- Huomio: automaatio on rajallista, syvyys on rajallinen ja soveltuvuus edistyneisiin työnkulkuihin on heikko.
- Hinnoittelumalli: ilmainen.
Parhaat no-code web scraping -työkalut toistuviin töihin
Kun työ on muuta kuin satunnainen poiminta, visuaaliset rakentajat ja pilvessa ajaminen alkavat merkitä enemmän.
6. Octoparse
Octoparse on edelleen yksi vahvimmista no-code-alustoista, jos tarvitset pilviajoja, mallipohjakattavuutta ja monipuolisempaa tehtävähallintaa kuin selainlaajennus pystyy tarjoamaan.
- Sopii parhaiten: analyytikoille, hinnoittelutiimeille ja operaattoreille, jotka ajavat toistuvia keruutöitä.
- Miksi se erottuu: kypsä tehtäväkone, pilviuutto, estojen kierrätys ja laaja mallipohjaekosysteemi.
- Huomio: se on tehokkaampi kuin AI-first-selaintyökalut, mutta se tarkoittaa myös enemmän käyttöönoton työtä.
- Hinnoittelumalli: ilmainen suunnitelma, maksulliset alkaen 69 $/kk, yrityskohtainen.
7. ParseHub
ParseHub on yhä relevantti käyttäjille, jotka haluavat enemmän hallintaa kuin AI-kaavin tarjoaa, mutta eivät halua rakentaa koodipohjaa. Se palkitsee kärsivällisyyden, ei nopeutta.
- Sopii parhaiten: analyytikoille ja teknisesti uteliaille tekijöille, jotka kestävät jyrkemmän oppimiskäyrän.
- Miksi se erottuu: joustava navigointilogiikka ja parempi hallinta kuin kevyissä selaintyökaluissa.
- Huomio: tuotekokemus tuntuu raskaammalta kuin uusilla tulokkailla, erityisesti nopeatempoisille liiketoimintatiimeille.
- Hinnoittelumalli: ilmainen suunnitelma ja maksulliset suunnitelmat.
8. Web Scraper
Web Scraper on edelleen järkevä aloituspiste, jos pidät sivustokarttamallista ja haluat työkalun, joka alkaa selaimessa ja kasvaa myöhemmin pilviaikatauluihin.
- Sopii parhaiten: aloittelijoille, harrastusprojekteihin ja pienempiin toistuviin töihin.
- Miksi se erottuu: helposti lähestyttävä sivustokarttatyönkulku ja helppo selainlähtöinen käyttöönotto.
- Huomio: se alkaa rajoittaa, kun tarvitset mukautuvampaa poimintalogiikkaa.
- Hinnoittelumalli: ilmainen selainlaajennus ja maksulliset pilvisuunnitelmat.
9. Data Miner
Data Miner kannattaa nähdä nopeana poimintatyökaluna, ei täydellisenä scraping-alustana. Se ansaitsee silti paikkansa, koska reseptipohjainen työ on hyödyllistä monissa tutkimus- ja prospektointitehtävissä.
- Sopii parhaiten: tutkijoille, kasvutiimeille ja nopeaan selaimessa tehtävään vientiin.
- Miksi se erottuu: reseptimalli, matala kynnys ja helppo vienti selaimesta.
- Huomio: ei oikea työkalu vakavaan alusta‑skaalan scrapingiin.
- Hinnoittelumalli: ilmainen suunnitelma ja maksulliset suunnitelmat.
Parhaat API-alustat, kun mittakaava ja estot ovat oikea ongelma
Tässä kerroksessa engineering-tiimit lakkaavat miettimästä “miten kaavin tämän sivun?” ja alkavat miettiä “miten teen tästä luotettavan suurilla volyymeilla?”
10. Apify
Apify on tämän ryhmän joustavin alusta, jos haluat sekä uudelleenkäytettävien kaapimien markkinapaikan että paikan ajaa omaa koodiasi. Se yhdistää no-code-löytämisen ja kehittäjäajon paremmin kuin useimmat kilpailijat.
- Sopii parhaiten: hybriditiimeille, kehittäjävetoiseen scrapingiin ja uudelleenkäytettäviin automaatiotyönkulkuihin.
- Miksi se erottuu: Actor-ekosysteemi ja oma suoritusympäristö antavat sille poikkeuksellisen laajan skaalan.
- Huomio: kun siirryt mukautettuun toteutukseen, olet taas engineering-maailmassa ja helppousetu haihtuu.
- Hinnoittelumalli: ilmainen suunnitelma, alkaen 29 $/kk + käyttö, suuremmat käyttöportaat ja yritysversio.
11. ScrapingBee
ScrapingBee on hyvä valinta, kun todellinen tarve on “anna minulle renderöity sivu ja hoida raskas infrastruktuuri puolestani”. Se sopii hyvin JavaScript-painotteisiin kohteisiin.
- Sopii parhaiten: kehittäjille, jotka kaapivat dynaamisia sivustoja eivätkä halua käyttää paljon aikaa infrastruktuuriin.
- Miksi se erottuu: yksinkertainen API renderöinnin, proxien ja selainautomaation ympärillä.
- Huomio: kyseessä on infrastruktuuripalvelu, joten vastaat silti parsinnasta, uudelleenyrittämisestä ja downstream-laadusta.
- Hinnoittelumalli: kokeilu ja maksulliset suunnitelmat.
12. ScraperAPI
ScraperAPI on yhä yksi helpoimmista tavoista ulkoistaa proxy-hallinta ja pyyntöjen onnistumisasteet, kun haluat skaalata nopeasti.
- Sopii parhaiten: kehittäjille, joiden pitää siirtyä prototyypistä volyymiin nopeasti.
- Miksi se erottuu: selkeä API, kokeilukrediitit, jäsennellyt tuotteet ja skaalaportaat.
- Huomio: kuten kaikissa API-first-tuotteissa, se ei poista engineering-päätösten tarvetta parsinnan ja datan validoinnin osalta.
- Hinnoittelumalli: 7 päivän kokeilu 5 000 kreditillä, maksulliset alkaen 49 $/kk.
13. Bright Data
Bright Data on raskaan sarjan vaihtoehto silloin, kun estojen kiertokyky, proxy-valikoima ja hallinnoitu keruu ovat tärkeämpiä kuin työkalun yksinkertaisuus.
- Sopii parhaiten: yritysohjelmiin, vaatimuksiltaan tiukkaan suurkeruuseen ja hallinnoituun datanhankintaan.
- Miksi se erottuu: laaja proxy-, scraper-, selain- ja dataset-tuotteiden kirjo.
- Huomio: kallis ja helppo ostaa yli tarpeen, jos ydintyönkulku on vielä suhteellisen yksinkertainen.
- Hinnoittelumalli: käyttöperusteinen ja tuotekohtainen hinnoittelu API:issa, proxeissa ja hallinnoiduissa palveluissa.
14. Oxylabs
Oxylabs on edelleen vahva valinta tiimeille, jotka ostavat scrapingin infrastruktuurina eivätkä selaintyökaluna. Se on erityisen relevantti, kun luotettavuus ja hankintaprosessin kypsyys ovat tärkeitä.
- Sopii parhaiten: yrityskeruuseen, hintaseurantaan, SEO-seurantaan ja markkinatutkimukseen.
- Miksi se erottuu: vankka infrastruktuuritarina, proxy-syvyys ja selkeämpi yritysmyynti.
- Huomio: ei ihanteellinen, jos tiimisi haluaa kevyen itsepalvelutyönkulun.
- Hinnoittelumalli: Web Scraper API alkaen 49 $/kk; muut tuotteet vaihtelevat yksikön ja käytön mukaan.
15. Zyte
Zyte ansaitsee edelleen vakavan harkinnan kehittäjä- ja data-tiimeiltä, jotka haluavat anti-detectionin, selain-toiminnot, JS-renderöinnin ja vaihtuvat IP-osoitteet yhden API-first-tarinan taakse.
- Sopii parhaiten: teknisille tiimeille, jotka rakentavat toistettavia poistojärjestelmiä.
- Miksi se erottuu: selain-toiminnot, JS-renderöinti, IP-kierrätys ja anti-bot-asenne samassa pinossa.
- Huomio: parempi tiimeille, joilla on engineering-omistajuus, kuin ei-teknisille käyttäjille.
- Hinnoittelumalli: kokeilu 5 $ ilmaisella kreditillä ja käyttöperusteiset kuukausisitoumukset.
Parhaat avoimen lähdekoodin kirjastot kehittäjille, jotka haluavat täyden hallinnan
Jos haluat omistaa scraper-pinon päästä päähän, nämä ovat hyödyllisimmät rakennuspalikat vuonna 2026.
16. Selenium
Selenium on yhä hyödyllinen, kun tarvitset QA-tyyppistä vuorovaikutuksen tarkkuutta, vanhoja selainautomaatio-työnkulkuja tai hyvin eksplisiittistä käyttäjäpolun hallintaa.
- Sopii parhaiten: vuorovaikutuspainotteiseen automaatioon, QA-käyttöön rinnakkain ja sivustoihin, joissa selaimen käyttäytyminen on tärkeämpää kuin crawl-läpimeno.
- Miksi se erottuu: kypsä ekosysteemi ja laaja selaintuki.
- Huomio: moniin scraping-työkuormiin se on raskaampi ja hitaampi kuin uudemmat selaintyökalut.
- Hinnoittelumalli: ilmainen ja avoimen lähdekoodin.
17. BeautifulSoup4

BeautifulSoup ei ole täysimittainen scraping-alusta, mutta se on edelleen yksi helpoimmista tavoista parsia sotkuista HTML:ää kevyissä työnkuluissa.
- Sopii parhaiten: aloittelijoille, nopeisiin skripteihin ja parser-lähtöisiin tehtäviin.
- Miksi se erottuu: yksinkertainen API ja pieni kognitiivinen kuorma.
- Huomio: yhdistä se request-, selain- tai crawler-työkaluun; yksinään se on vain parseri.
- Hinnoittelumalli: ilmainen ja avoimen lähdekoodin.
18. Scrapy
Scrapy on yhä paras vastaus, kun tarvitset oikean crawler-kehyksen etkä vain muutamaa skriptiä.
- Sopii parhaiten: tuotantokäyttöön tarkoitetuille omille crawlereille ja sisäisesti hallituille dataputkille.
- Miksi se erottuu: korkea suorituskyky, putket, middleware ja pitkäaikainen laajennettavuus.
- Huomio: siihen liittyy oikeaa engineering-työtä, ja JavaScript-painotteiset kohteet tarvitsevat usein rinnakkaistyökaluja.
- Hinnoittelumalli: ilmainen ja avoimen lähdekoodin.
19. Puppeteer
Puppeteer on edelleen vahva valinta Node-ensille tiimeille, jotka haluavat suoran hallinnan Chromiumiin ja selain-skriptitykseen.
- Sopii parhaiten: Node-pohjaiseen scrapingiin, kuvakaappauksiin ja selainautomaatioon.
- Miksi se erottuu: suora ja tehokas hallinta Chromiumin käyttäytymiseen.
- Huomio: selaintarina on kapeampi kuin Playwrightilla, ja se on silti resurssisyöppö suuressa mittakaavassa.
- Hinnoittelumalli: ilmainen ja avoimen lähdekoodin.
20. Playwright
Playwright on oletussuositukseni moderniin selainautomaatioon, jos tiimisi kirjoittaa koodia ja haluaa uudemman abstraktion kuin Selenium.
- Sopii parhaiten: moderniin selainautomaatioon, JavaScript-painotteisiin sivustoihin ja tiimeille, jotka arvostavat kehittäjäystävällisyyttä.
- Miksi se erottuu: vahva moniselainmalli, luotettava odotuskäyttäytyminen ja selkeät API:t.
- Huomio: vastaat silti selaininfrastruktuurista, rinnakkaisuudesta, selektorien muutoksista ja datan validoinnista.
- Hinnoittelumalli: ilmainen ja avoimen lähdekoodin.
Lyhytlistani tiimityypeittäin
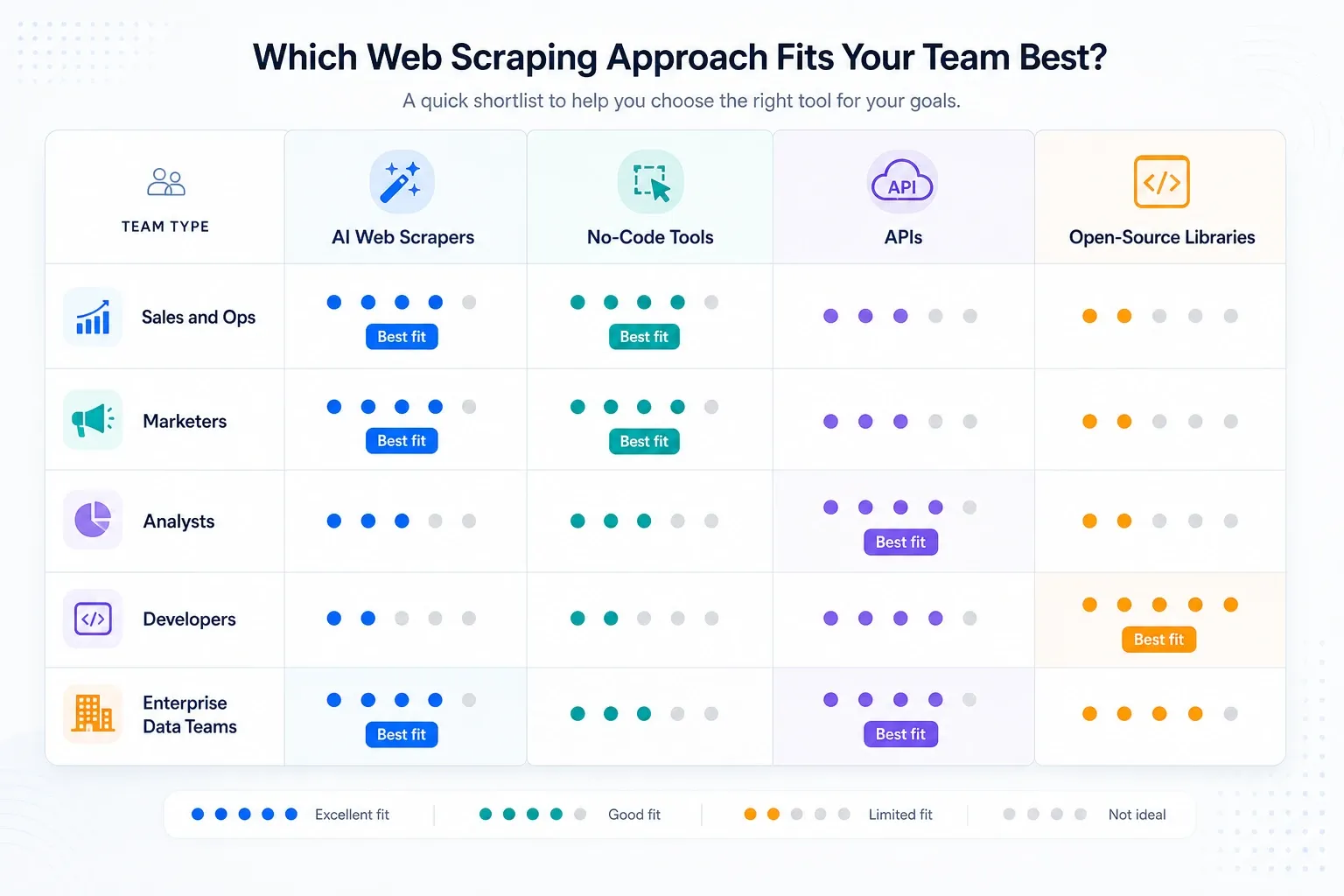
- Myynti- ja operatiiviset tiimit: aloita Thunderbitilla, ja katso sitten Browse AI:ta, jos seuranta on tärkeämpää kuin alasivujen rikastaminen.
- Analyytikko- ja tutkimustiimit: Octoparse ensin, jos toistuvat työt ovat suurempia kuin selainlaajennustyökalut pystyvät mukavasti hoitamaan.
- Automaatiopainotteiset GTM-tiimit: Bardeen, jos scraping on vain yksi vaihe laajemmassa työnkulussa.
- Kehittäjätiimit, jotka rakentavat sisäisiä työkaluja: Apify, Zyte, ScraperAPI tai Playwright sen mukaan, kuinka paljon haluat omistaa pinoa itse.
- Yritystason dataohjelmat: Bright Data, Oxylabs, Diffbot ja Zyte ovat ne vakavat infrastruktuurikeskustelut.
Milloin siirtyä raskaampaan stackiin
Käytä tätä sääntöä:
- Pysy tekoälytyökaluissa, kunnes törmäät toistettavuuden tai erikoistapausten rajoihin.
- Siirry no-code-työkaluihin, kun ajastus, sivutus, estojen kierto tai pilviajo ovat tärkeämpiä kuin yhden klikkauksen helppous.
- Siirry API:ihin, kun estojen läpäisyaste, JS-renderöinti ja rinnakkaisuus muuttuvat todellisiksi pullonkauloiksi.
- Siirry avoimen lähdekoodin kirjastoihin, kun toimittaja-abstraktion hinta on suurempi kuin koko pinon omistamisen hinta.
Useimmat tiimit siirtyvät raskaampaan stackiin liian aikaisin. Se on yksi yleisimmistä virheistä, joita näen.
Loppupäätelmä
Useimmille ei-teknisille tiimeille oikea vastaus vuonna 2026 ei ole “tehokkain kaavin”. Se on työkalu, joka saa tarkan datan seuraavaan työnkulkuun mahdollisimman vähällä ylläpidolla. Siksi AI-first-työkalut voittavat edelleen operatiivisessa käytössä, kun taas API:t ja avoimen lähdekoodin pinot sopivat paremmin teknisille tiimeille, joilla on selvät skaalausvaatimukset.
Jos haluat lyhimmän polun sivulta jäsenneltyyn tulosteeseen, aloita Thunderbitilla. Jos tiedät jo, että työsi tarvitsee raskasta infrastruktuuria, hyppää suoraan API- ja kehittäjäkerroksiin. Älä vain sekoita monimutkaisuutta ja edistyneisyyttä.
UKK
1. Mikä on paras web scraping -työkalu ei-teknisille käyttäjille vuonna 2026?
Useimmille ei-teknisille käyttäjille AI-first-työkalut, kuten Thunderbit ja Browse AI, tarjoavat nopeimman tien hyödylliseen dataan, koska ne vähentävät selektorityötä, käyttöönoton kitkaa ja ylläpitotaakkaa.
2. Mitä minun pitäisi valita, jos sivustoni ovat JavaScript-painotteisia tai estävät pyyntöjä aggressiivisesti?
Käänny kohti ScrapingBee:tä, ScraperAPI:a, Zytea, Bright Dataa, Oxylabsia, Playwrightia tai Seleniummia sen mukaan, haluatko hallinnoidun palvelun vai suoran teknisen hallinnan.
3. Ovatko no-code-työkalut yhä relevantteja, kun tekoälypohjaiset web-kaapimet ovat parempia?
Kyllä. No-code-työkalut, kuten Octoparse ja ParseHub, ovat edelleen tärkeitä, kun tarvitset tarkempaa hallintaa tehtävälogiikasta, pilviasioinnista ja toistuvasta tehtävähallinnasta.
4. Mitkä työkalut sopivat parhaiten engineering-tiimeille?
Apify, Zyte, ScraperAPI, Scrapy, Playwright, Puppeteer ja Selenium ovat luonnollisimmat valinnat, kun kehittäjät omistavat työnkulun.
5. Miten teen lyhytlistan nopeasti ilman että uppoudun liialliseen taustatutkimukseen?
Valitse ensin työkalutyyppi, ei toimittajaa. Päätä, tarvitsetko AI-yksinkertaisuutta, no-code-hallintaa, API-infrastruktuuria vai avoimen lähdekoodin omistajuutta. Vertaa sitten tuotteita kyseisen kerroksen sisällä.
Aiheeseen liittyvää luettavaa