
Seamos sinceros: la web es un lugar salvaje, salvaje. Cada día siento que estoy delante de una manguera digital a presión: noticias, reseñas, listados de productos, tuits, ofertas inmobiliarias, lo que se te ocurra, todo saliendo en un flujo caótico y desordenado. Y si llevas un negocio, intentar poner orden en todo eso puede sentirse como buscar una aguja en un pajar… mientras el pajar arde. (Yo ya pasé por eso. Nada divertido.)
Pero aquí está la clave: enterrada en todo ese ruido online hay información de mucho valor que puede impulsar las ventas, adelantarte a la competencia y automatizar esas tareas aburridas que nadie quiere hacer. Ahí es donde entra el web scraping. Con las herramientas adecuadas, puedes convertir esa montaña de datos web no estructurados en hojas de cálculo limpias y accionables, listas para tu próximo gran movimiento. Y cualquiera que haya pasado años en SaaS y automatización te lo puede decir: el web scraping ya no es solo para programadores. Es para cualquiera que quiera trabajar de forma más inteligente, no más dura.
Qué significa Web Scraping: convertir el caos online en datos útiles
Entonces, ¿qué es exactamente el web scraping? Dejemos la jerga a un lado y vayamos al grano: el web scraping es el proceso de usar software para extraer información concreta de sitios web y convertirla en formatos estructurados, como Excel, Google Sheets o una base de datos. Imagina tener un asistente digital que copia sin parar la información exacta que necesitas de miles de páginas web y la organiza por ti. Eso, en pocas palabras, es el web scraping.
Quizá también oigas hablar de “data scraping”. La diferencia es esta: data scraping es un término amplio para extraer datos de cualquier fuente (sitios web, PDFs, imágenes, lo que sea). Web scraping se refiere específicamente a extraer datos de sitios web en internet. En otras palabras, todo web scraping es data scraping, pero no todo data scraping es web scraping. (Es un poco como decir que todos los cuadrados son rectángulos, pero no todos los rectángulos son cuadrados.)
Si quieres una definición más formal, el web scraping es “data scraping usado para extraer datos de sitios web” (Wikipedia). Pero, en la práctica, no es más que automatización para la investigación online: nada de copiar y pegar hasta que se te queden los dedos dormidos.
Por qué el Web Scraping es importante para las empresas modernas
Qué es el data scraping y cómo hacerlo en 2025 Get Started Free
Hablemos de negocio. ¿Por qué importa tanto el web scraping ahora mismo? Porque internet se está ahogando en datos no estructurados: alrededor del 80%–90% de todos los datos nuevos son no estructurados, desde publicaciones en redes sociales hasta listados de productos. IDC prevé que el volumen global de datos alcance los 175 zettabytes en 2025: son muchísimos ceros.
Y aquí viene lo fuerte: entre el 60% y el 80% del tiempo de los empleados se desperdicia solo buscando y preparando datos, no analizándolos. Es como contratar a un chef para pelar patatas todo el día en vez de cocinar. Como dijo Michael Shulman, jefe de Machine Learning en Kensho: “Dado que la mayor parte de los datos del mundo no están estructurados, la capacidad de analizarlos y actuar sobre ellos representa una gran oportunidad.”
El web scraping cambia las reglas del juego. En lugar de recorrer sitios web a mano, automatizas el proceso y recopilas datos en tiempo real desde cualquier rincón de la web. No es casualidad que el 71% de las empresas de servicios financieros y más de la mitad de las empresas minoristas y de comercio electrónico ya usen web scraping para obtener datos externos. Los datos no son solo el nuevo petróleo: son la nueva moneda, y el web scraping es la forma de cobrarlos.
Casos de uso comunes del Web Scraping en distintas industrias
El web scraping no es una herramienta de una sola función. Se usa en todas partes: desde equipos de ventas hasta analistas inmobiliarios. Aquí tienes algunos ejemplos reales:
- Leads de ventas y prospección B2B: extrae ofertas de empleo o directorios de empresas para crear listas de leads nuevas y segmentadas. Una empresa SaaS vio un aumento del 40% en leads cualificados al automatizar este proceso.
- Precios y seguimiento de productos en comercio electrónico: los minoristas extraen precios y stock de sitios de la competencia y ajustan sus propios precios casi en tiempo real. ¿El resultado? Más ventas y clientes fieles.
- Listados inmobiliarios: agregadores e inversores extraen listados, precios y tendencias de portales inmobiliarios, lo que les ayuda a detectar propiedades infravaloradas y zonas en auge (caso práctico).
- Viajes y hostelería: extrae tarifas, disponibilidad y reseñas de aerolíneas y hoteles para alimentar herramientas de comparación de precios y análisis de sentimiento.
- Finanzas e inversión: los fondos de cobertura extraen desde informes de la SEC hasta reseñas de productos, buscando señales de datos alternativos. El 71% de las firmas financieras ya usa web scraping en sus operaciones.
En resumen: si hay datos valiosos en la web, hay una forma de extraerlos y convertirlos en valor para el negocio.
Cómo funciona el Web Scraping: del sitio web a la hoja de cálculo
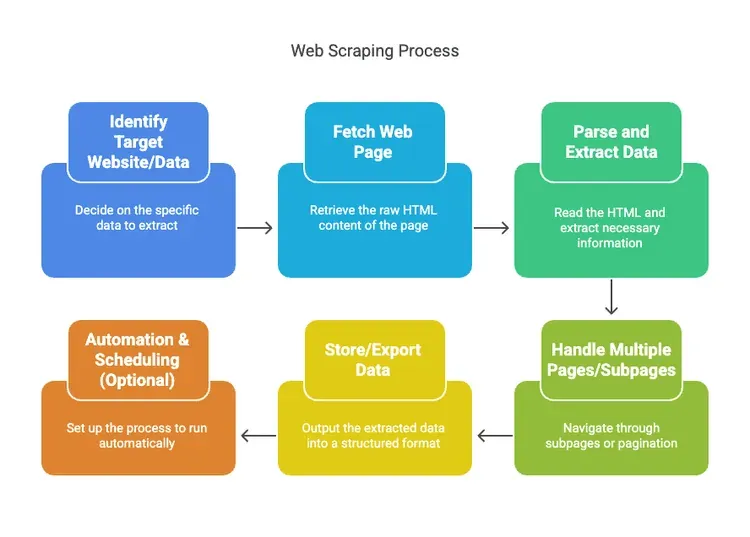
Vamos a desmitificar el proceso. El web scraping no es magia: es un flujo de trabajo. Normalmente funciona así:
- Identifica el sitio web o los datos objetivo: decide qué quieres (por ejemplo, nombres y precios de productos de xyz).
- Obtén la página web: el scraper recupera el HTML en bruto, igual que hace tu navegador.
- Analiza y extrae los datos: la herramienta lee el HTML y saca la información que necesitas (como precios, nombres, reseñas).
- Gestiona varias páginas o subpáginas: los scrapers pueden seguir enlaces a subpáginas o hacer clic automáticamente entre páginas.
- Guarda o exporta los datos: envía todo a un formato estructurado: CSV, Excel, Google Sheets o una base de datos.
- Automatización y programación (opcional): configúralo para que se ejecute según un calendario y mantén los datos actualizados sin mover un dedo.
Hacer esto manualmente llevaría una eternidad (y muchísimo café). Con el web scraping, automatizas todo el proceso y conviertes horas de trabajo pesado en minutos.
El papel de las herramientas de scraping y los servicios de Web Scraping
Ahora hablemos de herramientas. Hay un abanico enorme de opciones: desde extensiones del navegador hasta plataformas en la nube y software de escritorio. Aquí va un resumen rápido:
- Extensiones del navegador: herramientas ligeras de apuntar y hacer clic que viven en tu navegador. Geniales para trabajos rápidos y sencillos.
- Software de escritorio: aplicaciones completas con interfaces visuales; gestionan inicios de sesión, scroll infinito y más.
- Plataformas en la nube: ejecutan scrapers en servidores remotos; ideales para trabajos a gran escala y siempre activos.
- Código personalizado: para los más técnicos; escribe tus propios scripts para tener el máximo control (pero también el máximo dolor de cabeza).
¿Por qué usar estas herramientas en lugar de copiar y pegar? Por tres razones: velocidad, escala y fiabilidad. Un buen scraper puede procesar miles de páginas en el tiempo que tú tardas en calentar la comida. Además, obtienes datos limpios y estructurados: sin erratas, sin detalles perdidos.
Datos estructurados vs. no estructurados: por qué el Web Scraping es esencial
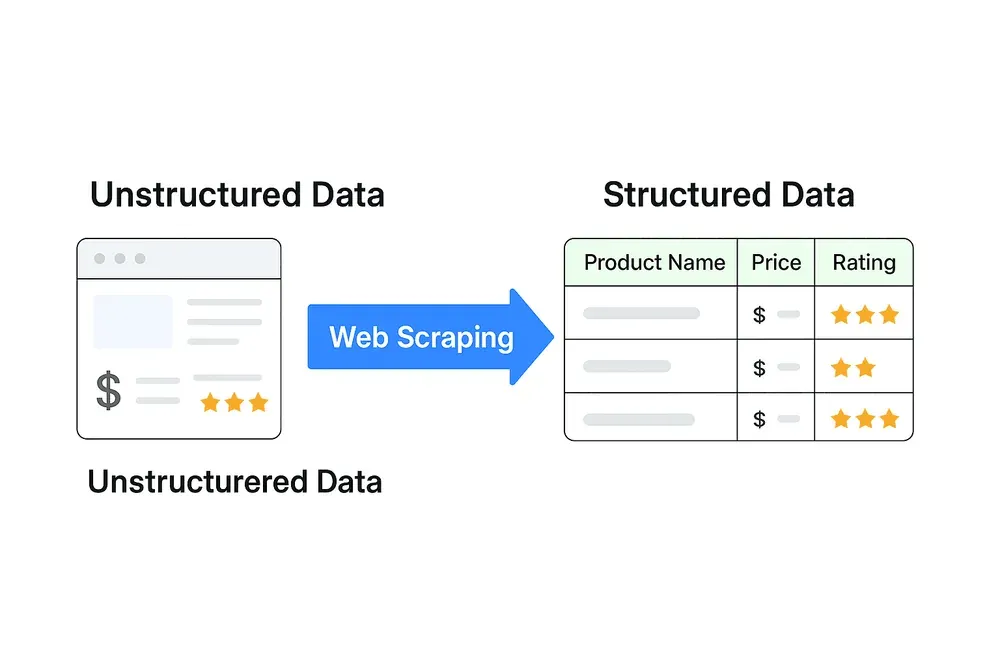
Aquí está el núcleo del asunto: la mayor parte de los datos web no están estructurados. Están pensados para personas, no para máquinas. Piensa en una página de producto con imágenes, reseñas y precios mezclados sin orden. No puedes simplemente volcar eso en Excel y empezar a analizarlo.
Los datos estructurados —como una hoja de cálculo con columnas para “Nombre del producto”, “Precio” y “Valoración”— son los que impulsan la analítica, los paneles y la toma de decisiones. El web scraping es el puente que transforma contenido web desordenado en información limpia y accionable.
Y aquí va un dato brutal: solo alrededor del 50% de los datos no estructurados de una organización llega a analizarse. ¿El resto? Potencial desaprovechado. El web scraping te ayuda a desbloquear ese valor.
Tipos de soluciones de Web Scraping: con código, sin código e impulsadas por IA
Veamos tus opciones:
- Soluciones con código: escribe scripts en Python (con bibliotecas como BeautifulSoup o Scrapy), JavaScript o R. Máxima flexibilidad, pero necesitarás soltura programando y paciencia cuando un sitio cambie y el script se rompa.
- Soluciones sin código: herramientas visuales (extensiones del navegador, apps de escritorio, plataformas en la nube) que permiten configurar scrapes con clics, no con código. Perfectas para usuarios de negocio que solo quieren resultados.
- Scrapers con IA: los nuevos del barrio. Estas herramientas usan IA para detectar automáticamente qué extraer, adaptarse a cambios en los sitios web e incluso sacar datos de PDFs o imágenes. Thunderbit es un ejemplo claro.
Como alguien que ha visto ambos lados —programando y usando herramientas sin código— puedo decirlo así: para la mayoría de usuarios de negocio, lo mejor es optar por scrapers sin código o impulsados por IA. ¿Para qué pelearte con código si puedes obtener el mismo resultado en dos clics?
Funciones clave que debes buscar en una herramienta de scraping
Extrae datos de cualquier sitio web usando IA Get Started Free
No todos los scrapers son iguales. Esto es lo que yo busco (y lo que recomiendo a cualquier equipo de negocio):
- Facilidad de uso: ¿puedes empezar sin leer un manual del tamaño de una novela?
- Detección de campos con IA: ¿sugiere automáticamente qué extraer?
- Soporte para subpáginas y paginación: ¿puede manejar listas de varias páginas y entrar en páginas de detalle?
- Opciones de exportación: ¿puedes enviar los datos directamente a Excel, Google Sheets, Airtable o Notion?
- Programación: ¿puedes configurarlo y olvidarte, para que extraiga datos automáticamente según tu horario?
- Reconocimiento de tipos de datos: ¿detecta emails, números de teléfono, imágenes y más?
- Plantillas para sitios populares: scraping con 1 clic para Amazon, Zillow, Instagram, etc.
Para los equipos de ventas, ecommerce y operaciones, estas funciones significan menos trabajo manual, menos errores y mucho más tiempo para lo que de verdad importa.
Thunderbit: el AI Web Scraper más sencillo para todo el mundo
Bueno, toca un poco de autopromoción, pero solo porque de verdad creo en lo que estamos construyendo en Thunderbit.
Thunderbit es una extensión de Chrome con AI Web Scraper diseñada para usuarios de negocio, no solo para desarrolladores. Esto es lo que la hace diferente:
- Sugerencia de campos con IA: solo haz clic en “AI Suggest Fields” y Thunderbit leerá la página, recomendará las mejores columnas y dejará todo listo por ti. Nada de adivinar ni de pelearte con selectores.
- Scraping en 2 clics: abre la página, deja que la IA sugiera los campos y pulsa “Scrape”. Listo. Así de simple.
- Subpáginas y paginación: la IA de Thunderbit detecta y extrae automáticamente subpáginas y listas paginadas, sin configuración adicional.
- Scheduled Scraper: ¿quieres revisar precios o leads a diario? Solo describe la programación (“cada mañana a las 9”), añade las URLs y Thunderbit se encarga del resto.
- Exportación instantánea: envía tus datos directamente a Excel, Google Sheets, Airtable o Notion, sin costes ocultos ni complicaciones.
- Extractores especializados: extracción con 1 clic de emails, números de teléfono e imágenes, completamente gratis.
- AI Autofill: usa IA para rellenar formularios online y automatizar flujos de trabajo, no solo para extraer datos.
- Análisis de documentos e imágenes: sube PDFs, Word, Excel o imágenes, y la IA de Thunderbit extraerá tablas y estructurará los datos por ti.
Y sí, hay un plan gratuito (extrae hasta 6 páginas), así que puedes probarlo sin riesgo. Si necesitas más, los planes de pago empiezan en 15 $/mes por 500 filas, mucho más asequibles que la mayoría de herramientas empresariales.
No te fíes solo de mi palabra. Los usuarios nos han dicho cosas como: “Thunderbit es, con diferencia, el web scraper más fácil que he usado. Pasé de dedicar horas a escribir scripts a extraer sitios completos en minutos, con solo unos clics.” Ese es el tipo de feedback que hace que todas esas sesiones de programación nocturnas merezcan la pena.
¿Quieres ver Thunderbit en acción? Échale un vistazo a nuestro canal de YouTube o lee más en el blog de Thunderbit.
Prueba gratis la extensión de Chrome de Thunderbit
Buenas prácticas de Web Scraping para equipos no técnicos
El web scraping es potente, pero un poco de cautela ayuda mucho. Estos son mis mejores consejos para empezar:
- Respeta las políticas del sitio web: revisa siempre los términos de servicio y el archivo robots.txt. Limítate a los datos públicos y úsalos de forma responsable.
- No sobrecargues los servidores: sé cortés; no bombardees un sitio con peticiones. La mayoría de herramientas permiten ajustar la velocidad de rastreo o los retrasos.
- Empieza poco a poco: prueba tu scraper primero en unas pocas páginas. Asegúrate de que estás obteniendo los datos que quieres antes de escalar.
- Gestiona la paginación: no olvides extraer todas las páginas, no solo la primera.
- Valida tus datos: limpia y revisa los resultados; elimina duplicados, corrige el formato y comprueba que no falte nada.
- Mantén el orden: documenta qué extraíste, cuándo y de dónde. Te ahorrará dolores de cabeza más adelante.
- Comprueba si hay APIs: a veces existe una API oficial que te da los datos de forma más fácil y fiable que extrayendo el HTML.
- Vigila los cambios: los sitios web cambian. Si tu scraper deja de funcionar, quizá haya llegado el momento de actualizar la configuración (o dejar que la IA se encargue).
- Usa la herramienta adecuada: si una no funciona, prueba otra. No tengas miedo de experimentar.
- Mantén la ética: que puedas extraer algo no significa siempre que debas hacerlo. Respeta la privacidad y la propiedad de los datos.
Para profundizar más, consulta nuestra guía: Qué es el data scraping y cómo hacerlo en 2025.
Conclusión: desbloquear valor empresarial con Web Scraping

Vamos cerrando. La web está llena de datos valiosos, pero la mayor parte sigue atrapada en formatos no estructurados. El web scraping es la llave que libera esos datos: convierte el caos en claridad y el trabajo pesado en crecimiento.
Tanto si trabajas en ventas, ecommerce, inmobiliario u operaciones, el web scraping puede ayudarte a:
- Generar leads más frescos y de mayor calidad
- Supervisar competidores y mercados en tiempo real
- Automatizar flujos de trabajo tediosos y ahorrar horas cada semana
- Tomar decisiones más inteligentes, más rápidas y basadas en datos
Y gracias a las herramientas modernas —especialmente soluciones impulsadas por IA como Thunderbit— no necesitas ser programador ni científico de datos para empezar. Solo elige un proyecto, prueba una herramienta (nuestra extensión de Chrome es un gran punto de partida) y comprueba cuánto más puedes lograr cuando dejas que la automatización haga el trabajo pesado.
En un mundo donde “los datos son el nuevo petróleo”, el web scraping es tu bomba. Así que adelante: convierte esa manguera de datos online en un flujo constante de información útil y verás cómo tu negocio prospera.
¡Feliz scraping! Y si alguna vez te atascas, ya sabes dónde encontrarme (o, al menos, dónde encontrar Thunderbit).
Empieza a extraer datos con Thunderbit AI
Preguntas frecuentes
1. ¿Qué es el web scraping, en palabras sencillas?
El web scraping consiste en usar software para extraer automáticamente datos concretos de sitios web —como precios, reseñas o ofertas de empleo— y convertirlos en algo útil, como una hoja de cálculo. Piensa en ello como contratar a un becario robot para que haga por ti todo el trabajo aburrido de copiar y pegar, 24/7.
2. ¿Necesito saber programar para usarlo?
Ya no. Gracias a herramientas sin código e impulsadas por IA como Thunderbit, puedes extraer datos de sitios web con un par de clics: sin Python, sin depurar, sin problema. Si sabes navegar por la web, puedes extraer datos de la web.
3. ¿Qué tipo de datos puedo extraer?
Prácticamente cualquier cosa que sea pública online:
- Listados y precios de productos
- Propiedades inmobiliarias
- Ofertas de empleo
- Directorios de empresas
- Biografías en redes sociales
- Tablas e imágenes de PDFs (sí, también eso)
Si está en internet y es visible, hay una forma de extraerlo.
4. ¿Es legal el web scraping?
En general, sí: siempre que extraigas datos públicos de forma responsable. No sobrecargues servidores, respeta los términos de servicio y evita extraer información personal o protegida por inicio de sesión. Ante la duda, actúa con ética y mantén todo limpio.
Leer más
- 3 formas en que el web scraping impulsa el crecimiento empresarial
- Caso práctico: cómo un minorista usó scraping para aumentar las ventas
- Por qué los datos externos son el futuro de la estrategia competitiva
Prueba AI Web Scraper Get Started Free




